基于關鍵點檢測的交通監控相機標定方法
2022-12-28 07:52:52肖子遙朱肖磊熊鑫州
農業裝備與車輛工程 2022年12期
肖子遙,朱肖磊,熊鑫州
(201620 上海市 上海工程技術大學 機械與汽車工程學院)
0 引言
實現目標的空間定位是智能交通系統的關鍵能力,然而高精度定位傳感器價格昂貴,例如基于激光的設備或微波多普勒雷達。考慮到視覺傳感器分辨率和成像質量的提升,基于計算機視覺和多幾何視圖相結合的空間定位解決方案極具成本效益。然而,監控攝像機通常放置在難以接近的位置,并且缺乏標準化的校準過程[1]。雖然目前可以較準確地估計攝像機的外部參數,但缺乏一種可靠的監控攝像機內部參數的估計方法,導致一些基于已知圖形尺寸[1-5]的外參標定方法不可用,而其他基于消失點的標定方法[6-8]通常對相機內參數有很強的假設,從而限制了校準精度的進一步提高。
本文提出了一種通用的交通監控場景內參數自動標定方法(Automatic Calibration of Internal Parameters,ACIP),該方法結合不同的外部參數估計方法實現相機全標定。相機標定涉及估計2 種類型的相機參數:相機內參(如相機焦距、畸變系數)與相機外參(旋轉矩陣 R 和平移矩陣 T)。目前,大多數交通攝像機標定方法對內部參數都有很強的假設,例如攝像機主點在圖像的中心,攝像機的像素無畸變[9],或者一些方法假設攝像機已在實驗室校準或相機參數已知[5],但這些條件對于已大規模部署完成的交通相機來說是暴力或不現實的[10]。
針對以上問題,本文專注于自動估計交通攝像機內部參數。首先通過YOLOv4[11]來檢測車輛;其次通過改進Res-Net18[12]構建全卷積網絡FCN來估計車牌的關鍵點位置;接下來,ACIP 利用Levenberg-Marquardt 算法[13,14]將已知車牌尺寸與圖像車牌坐標對應求解相機內參;最終,通過現有的自動或手動相機外參估計方法對相機進行全面標定,并進行了對比試驗。系統流程圖如圖1 所示。
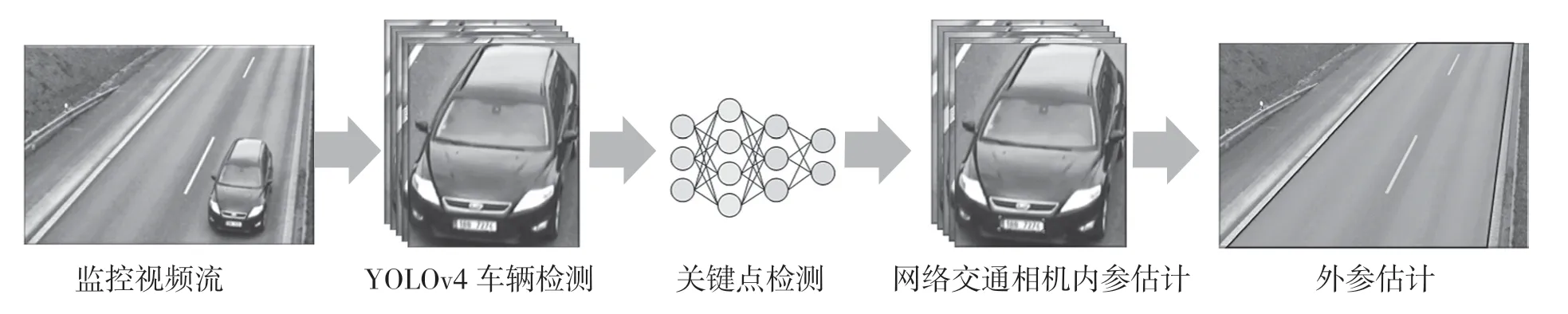
圖1 基于關鍵點檢測的交通相機標定流程圖Fig.1 Diagram of traffic camera calibration based on key point detection pipeline
1 基于YOLOv4 車輛檢測
本文使用目標檢測的SOTA 算法YOLOv4 用于車輛檢測,其包括骨干網絡CSPDarknet53,頸部網絡SPP 及PAN-Net,頭部網絡YOLOv3 三部分。其網絡架構如圖2 所示。
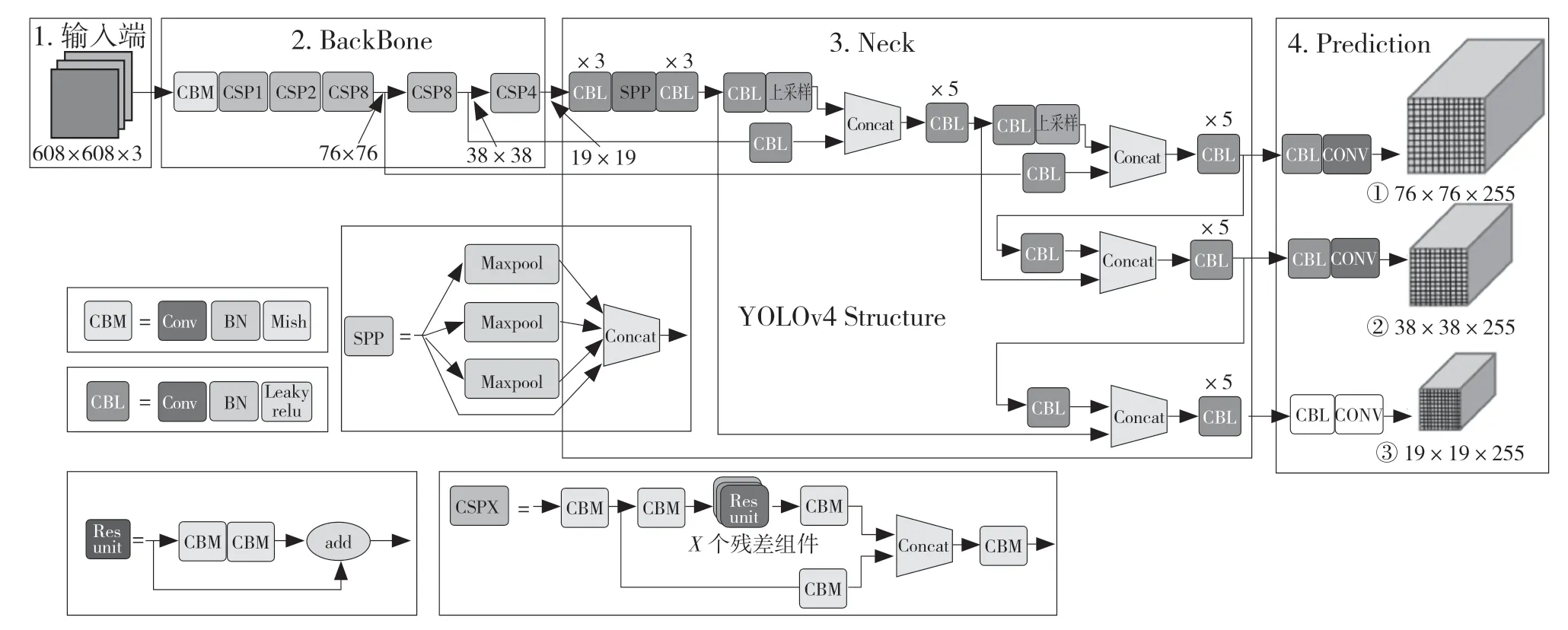
圖2 YOLOv4 網絡框架圖Fig.2 YOLOv4 network architecture diagram
在主干網絡中,相較于原始DarkNet53,YOLOv4 引入了CSP 模塊,其將基礎層的特征映射劃分為兩部分,再通過跨層次結構將其合并,減少了推理計算的梯度信息重復,使其網絡輕量化的同時保持準確性。此外,主干網絡還使用了Dropblock 以及Mish 激活函數,對網絡的正則化及泛化能力進行優化。
在頸部網絡中,YOLOv4 主要采用了SPP 模塊與FAN+PAN 模塊。其中,SPP 模塊使用的最大池化卷積核大小為k={1×1,5×5,9×9,13×13},將不同池化的特征結果串聯在一起輸出,有效地增加了不同尺度的感受野。相較于YOLOv3 單純地采用FPN 層,YOLOv4 額外串聯了2 個PAN 結構組成特征金字塔。此時,FPN 層自頂向下輸出強語義特征,而特征金字塔結構自底向上輸出強定位特征,從而對不同的特征進行聚合,提高了檢測效果。
本研究在上海松江區8 個交通路口搜集標注了2 000 張不同監控視角的車輛圖片,并根據車型將標注數據分為4 類(car,truck,bus,lorry)。在訓練模型階段中,使用在VOC 數據集上訓練過的預訓練模型進行遷移學習;在數據輸入階段,使用mosaic 數據增強,以提高模型的泛化能力。此外,為了跳出局部最優解,學習率使用余弦退火策略。
2 車牌關鍵點檢測
在交通場景中,傳統的基于標準圖案的標定對象(如棋盤格)不易獲取和放置,但車牌在同一個行政區域內有相同的標準,所以其是交通場景中相機校準的天然圖案。例如,中國汽車牌照尺寸為440×140 mm(小型車車牌)、440×220 mm(大型車車牌)。一旦YOLOv4 檢測出已知型號的車輛,即將檢測到的車輛區域作為感興趣區域(ROI),并通過建立基于ResNet-18 改進的全卷積網絡來回歸車牌4 個角在 ROI 區域中的位置。
ResNet-1 是最為經典的分類網絡之一,雖然其網絡結構較為輕量化,但經過實驗發現,對于回歸特征明顯的車牌關鍵點等任務來說已經足夠。對于識別車牌其4 個角點的任務,將最后一個全連接層更改為卷積核大小為1×1 的全卷積層,其輸出長度為9(第一個輸出對應車牌的類別),隨后每兩個輸出對應車牌x,y 圖像位置的一個關鍵點。
本文使用在 ImageNet 數據集上訓練得到的預訓練模型提取圖像的淺層特征。對相機參數任務,需具有已知幾何信息的標定對象。本研究從上海高速公路和街道監控中收集車輛數據,并手動注釋了1 500 個車牌位置(4 個車牌關鍵點)和類型用以訓練。對于每個注釋圖像,實驗中使用以下圖像增強方法生成 8 個圖像,包括原始圖像、2 次隨機旋轉0~60°之間任意角度、通過改變圖像的亮度、對比度、飽和度和色調來獲得 5 種隨機色彩空間,即提供了總共 12 000 張用于車牌關鍵點檢測的圖像。
3 交通相機標定
3.1 攝像機模型
在描述交通攝像頭標定之前,首先介紹針孔攝像頭模型。相機是3D 世界和2D 圖像之間的一種映射,針孔相機模型是應用最廣泛的一種。
將圖像平面由 MN 平面表示,世界坐標系(WCS)由XYZ 空間表示。針孔相機模型使用式(1)描述像素位置(m,n)及其在 WCS 坐標中的對應位置:
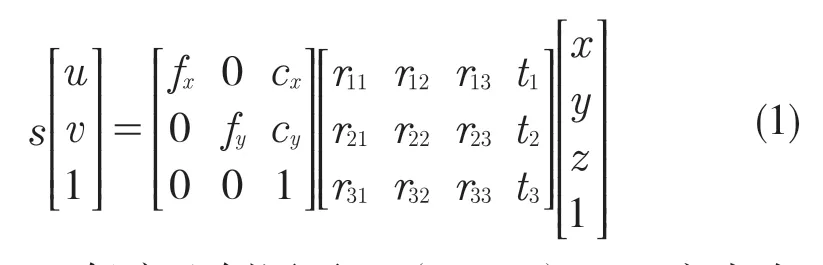
式中:s——任意比例因子;(cx,cv)——主點在MN 平面上的偏移值;fx,fv——相機沿X 軸和Y 軸的焦距。
R 和 T 是相機的旋轉和平移矩陣,式(1)可以用矩陣表示法簡寫為:

相機標定問題是估計 C、R 和 T 的問題。相機矩陣 C 僅取決于相機(而不取決于其位置或方向),而 R 和 T 表示相機的位置和方向,因此C 被稱為相機的內在參數,而 R 和 T 被稱為相機的外在參數。本文的主要工作重點是利用相關技術估計相機內部參數,然后使用Perspective-n-Point(PnP)技術手動或自動外部參數估計方法來標定外參。
3.2 基于車牌關鍵點相機標定
車牌關鍵點檢測將產生大量用于校準的校準牌照點對。不失一般性,我們假設車牌平面在世界坐標系的Z=0 上,用ri和t 表示旋轉和平移矩陣的第i 列。從式(1)可得:
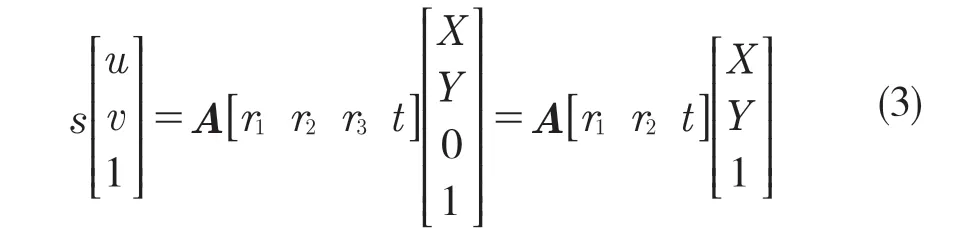
因為Z=0,所以世界坐標可簡化為[X Y 1]T,車牌的角點坐標對應的世界坐標與一個單應性矩陣H 相關,沿用式(2)的記法:
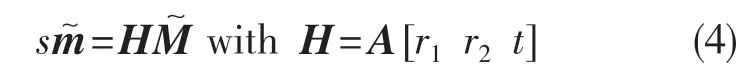
給定已知尺寸車牌的像素坐標,可以計算出單應矩陣的精確解,記為H=[h1,h2,h3],則有
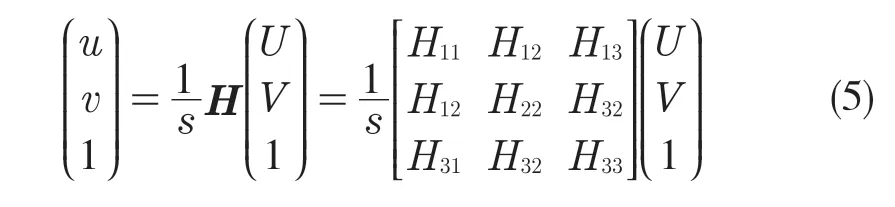
使用式(4),消除比例因子s,得到
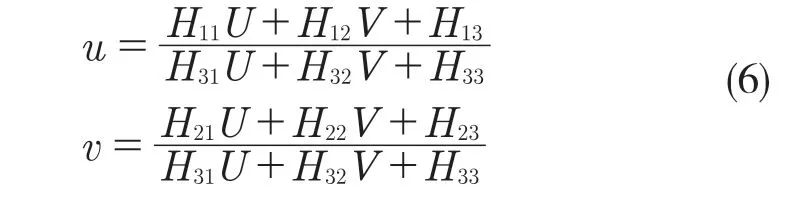
H 是具有8 個獨立未知元素的齊次矩陣。由式(6)可知,車牌每個角可以提供2 個約束(u、X、Y 的對應關系和v、X、Y 的對應關系),因此當車牌提供4 個角點時,就可以得到圖片對應的單應矩陣H。對式(3)進行移位變換,有H=λ[r1r2r3]。
其中λ是一個任意標量。利用r1和 r2正交可得:
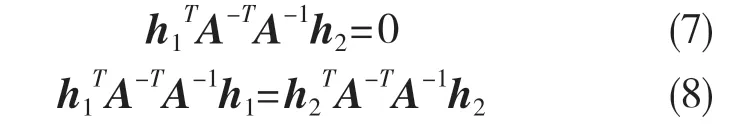
由式(7)、式(8)可得,給定一個單應性,可以獲得對固有參數的2 個約束。使用張正友的方法[15],當單應矩陣H ≥ 3 時,通常會有一個唯一的解 B 和比例因子。可以計算所有相機內在參數和λ。令B=A-TA-1,推導得
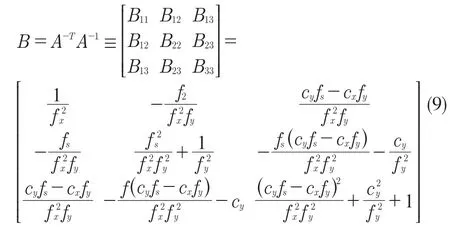
當檢測到的車牌超過 3 個時,假設其中每個車牌角點被獨立且均勻分布的噪聲破壞。使用Minpack[13]中實現的 Levenberg-Marquardt 算法最小化式(10)的非線性問題,從而使用最大似然估計值修改獲得的內部參數:
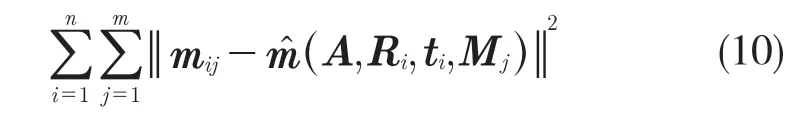
其中,(A,Ri,ti,Mi)是點Mi在圖像 i 中的投影,旋轉 R 由3 個參數的向量參數化,它與 r 的關系由 Rodrigues 公式[7]得出。
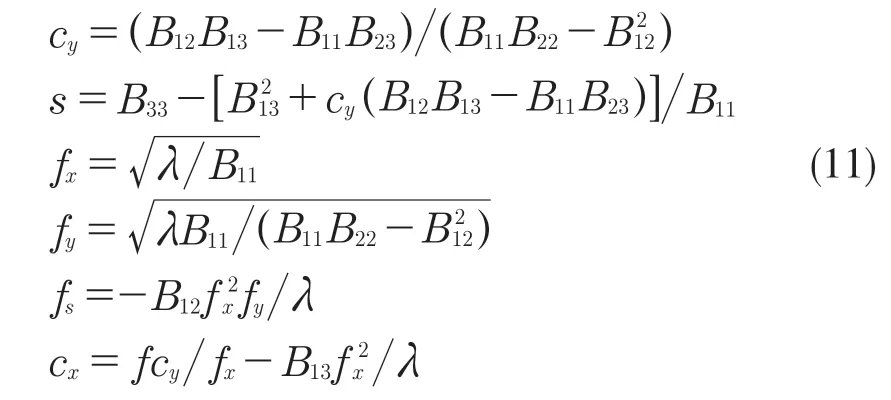
至此,已經估計獲得監控相機的內部參數。假設道路是平坦的,可以使用手動或自動的外部參數估計方法。當監控場景比較簡單時,比如高速公路,可以使用消失點法校準外部參數[7,9];當監控場景復雜時,可以通過求解Perspective-n-Point 問題估計外部參數。例如通過道路上靜態物體的幾何特征,如獲取真實世界坐標以及 n ≥4 個不同點的對應圖像坐標,然后使用EPnP[15]方法估計外部參數。
圖像平面到三維坐標系再投影到特定平面(道路)可以使用式(1)改寫公式:

4 實驗分析
為了評估ACIP 的內部參數估計的準確性和結合2 種外部參數估計方法(基于消失點和PnP)的完全校準效果,本實驗收集了不同交通路口的場景,以進一步探索不同校準方法組合的影響。圖3 顯示了所收集的場景數據集示例。

圖3 在 P1 場景中手動測量道路平面標記之間距離的示例Fig.3 An example of manually measuring distances between road plane markers in P1 scene
圖3中,水平(豎直)方向上的虛線是第1個(第2 個)消失點方向的水平線,四邊形是距離測量標記的示例,黑點是實際坐標測量點,用于距離測量誤差估計。
下文介紹類似場景下的交通攝像頭標定方法,并將這些方法定義如下:
ManualCalib(Checkerboard):采用張正友提出的方法[14]作為標準的內參標定方法。相機在理想條件下用棋盤格校準后,將其與EPnP 方法結合作為本研究中校準方法的基準;
ACIP:本文相機參數標定方法。
為了研究結合 ACIP 對基于消失點的方法(那些對相機內部參數進行強制假設的方法)的影響,比較了具有代表性的手動和自動消失點估計方法進行校準:
ManualVP:利用道路上已知的距離,根據He和Yung 的方法[7]測量消失點并校準相機。對于具有多個消失點方向的平行線段,使用 Levenberg-Marquardt 算法進行消失點的最大似然估計 (MLE);
ManualScale:比例尺是通過手動測量道路標記到第1 個消失點得到的。它通過式(10)計算,比例尺計算為一系列端點之間的實際距離與消失點的比值的平均值。像素點距離(方向沿著消失點的方向):
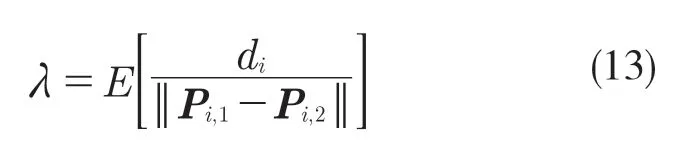
4.1 車牌角點準確性
ACIP 利用DNNs 來識別車牌的4 個關鍵角點,并通過這些關鍵角點與對應車型的實際車牌尺寸匹配來計算校準相機參數。但是來自DNN 的注釋可能出錯。為了進一步分析DNN 的性能,按照DNN評估的標準做法將人工注釋的車牌數據集分為訓練集、驗證集、測試集。在中間層采用BN,全連接層采用Dropout 正則化,防止模型過擬合。用于訓練和驗證數據集共2 000 張,采集于中國上海高速與街道監控,其中包含姿態元數據和車牌4 個角點的注釋。圖4 為Loss 訓練時的收斂圖,在epoch到150 左右時,模型在驗證集上已收斂。圖5 為模型對測試車輛的關鍵點推理圖,注意觀察車牌角點部分,已經達到手工注釋的效果。
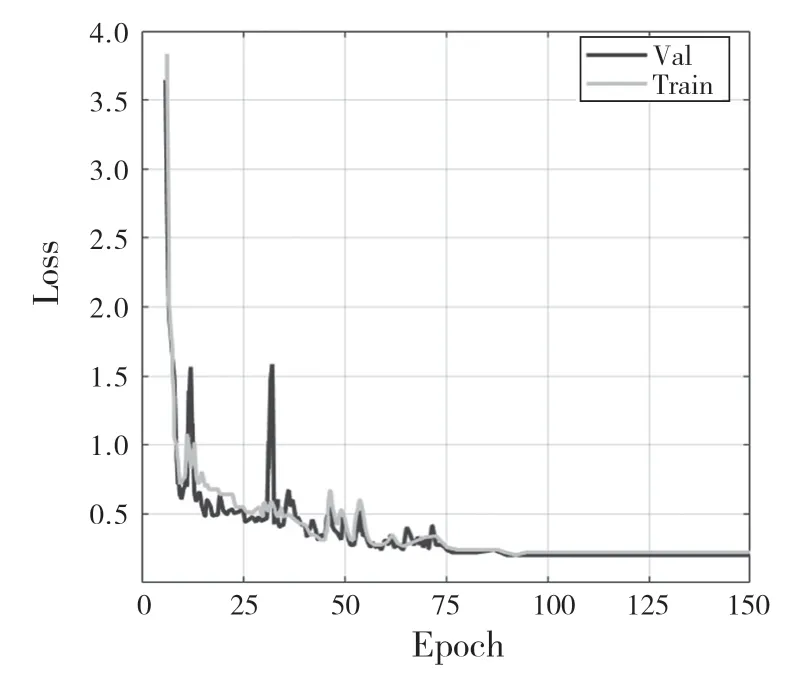
圖4 車牌關鍵點檢測的訓練驗證損失Fig.4 Training verification loss of key point detection of license plate

圖5 測試數據中的推理示例Fig.5 Infer examples in test data
4.2 交通相機標定誤差估計
得到車牌關鍵點后,將其車牌規格與其匹配,相機內參便被標定。通過分析其在世界坐標系中地平面上的距離重投影誤差,可以估計標定的準確度。令dreal為測試路面上所測點對的實際距離,dreproj為2D 圖像對應點對投影到地平面上估計的距離。對每個實際與估計的點對,可以計算其歸一化誤差為
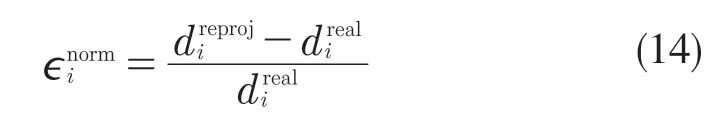
由此,定義標定的均方根誤差為
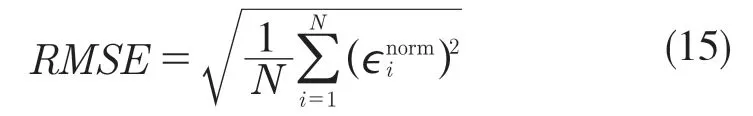
式中:N ——所有測試點對的數量。
RMSE 提供了評估這種校準方法準確度的指標。基于標準圖形+EPnP 的手動校準方法和基于ACIP+ManualVP+ManualScale 仍然存在重投影錯誤。誤差的主要來源有2 個:(1)標注誤差,在匹配圖像上的道路測量點和測量地面實況時引入的隨機誤差。(2)估計方法本身的誤差,計算場景消失點和EPnP 方法本身的誤差。這些誤差反映在圖6 中。首先,實驗室條件下的標定方法組合ManualCalib(Checkerboard)+EPnP的RMSE 為1.50%,可以作為校準基準;其次,ACIP+EPnP 作為一種半自動校準方法,在工作量很小的情況下,比相同交通場景下手工標定方法ManualVP+ManualScale 的RMSE僅高0.14%,可見其有效性。最后,將 ACIP 測量的相機參數作為先驗知識加入到基于消失點的標定方法中。ACIP+ManualVP+ManualScale 的組合方法比ManualVP+ManualScale 的RMSE 低0.38%,證 明ACIP 對基于消失點標定方法的效果進行了提升。
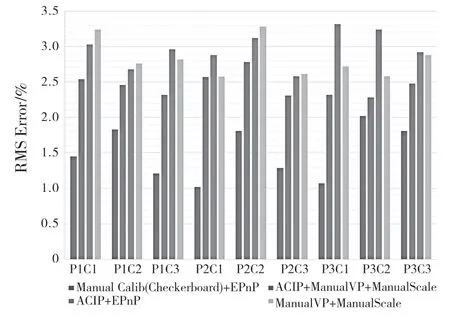
圖6 ACIP+EPnP 準確度與2 種手動標定方法的對比Fig.6 ACIP+EPnP accuracy comparison with two manual calibration methods
其中,橫坐標P1—P3 為3 種不同的測試場 地(舉例,圖3為P1場景),C1—C3 為不同的交通相機。地面真值校準的距離誤差(Manual calibration(Checkboard)+EPnP)在 所有攝像機與場景中的平均RMS 誤差為1.50%,ACIP+ManualVP+ManualScal 為2.45%,直接使用ManualVP+ManualScal 的平均誤差為2.83%,ACIP+EPnP 的平均誤差為2.97%。
5 結語
本文的研究為已部署的交通相機提供了系統的無接觸式快速標定方法,并與現有交通相機標定方法進行了橫向比對,其大大提高了交通相機的標定效率,且在相同場景下,僅略高于手動標定的誤差0.14%,而將估計出的內參信息作為先驗知識提供給基于消失點的標定方法后,減少了該類方法0.38%的重投影誤差,驗證了該標定方法的可行性。
猜你喜歡
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
河南畜牧獸醫(2016年24期)2016-11-29 01:28:30
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中國衛生(2014年2期)2014-11-12 13:00:16
語文知識(2014年7期)2014-02-28 22:00:26
