基于機器學習的球團礦質量預測模型研究現狀
2022-12-29 10:52:00楊會利張建良劉征建王耀祖孫慶科
天津冶金 2022年6期
楊會利,李 躍,趙 克,張建良,劉征建,王耀祖,孫慶科
(1.鞍山鋼鐵集團有限公司大孤山球團廠,遼寧 鞍山 114046;2.北京科技大學冶金與生態工程學院,北京 100083;3.北京科技大學人工智能研究院,北京 100083;4.北京科技大學自動化學院,北京 100083)
0 引言
隨著國家供給側結構性改革和低碳節能戰略發展目標的實施,鋼鐵行業的發展和生存面臨著嚴峻的挑戰。對于高爐煉鐵來說,球團礦是高爐冶煉必備的原料,球團礦的質量直接影響著高爐的正常運行和鐵水的質量。因此對入爐球團礦的質量要求越來越高,這也就促進了球團礦工業的發展。球團礦入爐前的質量檢測是必不可少的環節,而目前球團礦的質量檢測結果大多是在成品球團礦生產出來后經現場人工采樣,送化驗室檢測后得到。由于球團礦質量檢測時間長,現場獲得質量數據時間滯后,很難及時快速對成品球團礦的質量進行控制和調整,當發現球團礦質量不合格時,已經造成了巨大的損失。因此建立成品球團礦質量實時預測系統對球團礦質量、高爐生產及環境保護都有非常重要的意義。
目前計算機和人工智能技術已被廣泛地應用于工業各個領域,進一步加強生產方式智能化綠色發展已成為諸多鋼鐵企業的研究熱點。近年來,隨著大數據、機器學習、深度學習的發展,基于大數據開發的智能控制、智能預測算法也被應用到工業的各個領域,例如燒結礦質量預測[1],球團礦質量預測[2]。為了能夠實時監測成品球團礦的質量,國內外學者做了大量的研究。本文總結了近些年球團礦質量預測算法研究,主要包括案例推理、神經網絡、遺傳算法以及其他改進算法等,以期為鋼鐵企業球團礦質量預測的智能化提供參考。
1 球團礦質量預測研究現狀
國內外對球團礦質量預測主要分為兩大類,如圖1所示。一類是對成品球團礦質量化學成分預測的研究,另一類是對球團礦質量物理性能預測的研究。

圖1 球團礦質量預測Fig.1 Pellet ore quality prediction
國內外對球團礦質量化學成分的預測研究比較多。文獻[3]通過搭建BP 神經網絡模型預測堿度,國外有學者通過對風箱廢氣分析來預測FeO 含量。Liu Bin[4]等人建立了3 種不同的人工神經網絡模型來預測球團礦的熱狀態指數(RDI、RI、RSI),根據球團礦理論確定網絡輸入,然后使用靈敏度分析來量化每個輸入變量的重要性,并逐漸降低網絡的輸入維數,最后通過最小網絡輸入因子來提高網絡預測的準確性,仿真結果表明,預測模型符合實際工程應用要求。
在球團礦質量物理性能方面主要預測的是轉鼓指數和抗壓強度。在球團的最佳粒徑方面德國人做過深入研究,球團礦生產要盡可能滿足粒度均勻,大小適中,粒度不均勻會降低球團的透氣性,會在焙燒和預熱過程中影響球團的干燥和預熱速度,同時也影響冷卻的速度,從而使得球團礦質量下降。Wang Yukun[5]等人提出一種基于核主成分分析(KPCA)和RBF 神經網絡結合模型,通過分析鏈篦機-回轉窯球團礦生產過程的熱工參數,確定輸入輸出變量,利用核主成分分析算法(KPCA)處理樣品數據并簡化模型結構,然后利用RBF神經網絡建立了球團抗壓強度預測模型,利用全局優化的模擬退火算法對網絡模型的參數進行優化,得到高精度的預測模型。仿真結果表明,該模型能夠準確預測球團礦的抗壓強度,克服原有球團礦抗壓強度測量試驗方法滯后的缺點。
2 球團礦質量預測模型
2.1 基于案例推理模型
案例推理(Case-based Reasoning)技術起源于Roger Schank 于1982年在Dynamic Memory 中的描述,在1988年由Roger C.Schank,Robert P.Abelson提出[6],是人工智能領域中新崛起的一種基于知識問題求解和學習的方法[7]。圖2為案例推理流程,由圖2可以看出,該方法是基于案例庫中存儲的過往案例的解生成新的問題的解,從而解決現實中隨機出現的難以量化的解[8]。案例推理主要包括四個步驟,即案例描述、案例檢索、修改重用、保存更新。由于鋼鐵企業在過去的生產過程中生成大量的歷史數據,結合案例推理的方案將歷史生成的大數據得以利用從而對以后產品質量的預測有著很大的生產意義。

圖2 案例推理流程圖Fig.2 Case inference flowchart
2.1.1 案例描述
將案例推理(CBR)引入到焙燒球團質量預測中就是找出球團礦的質量與各生產參數指標之間的關系。根據現場專家經驗和歷史數據的分析,可以用向量對球團礦案例進行描述,同時將問題特征向量的元素設定為焙燒性能指標,可以將入爐生球量、煤氣流量、主引風機風量、風箱溫度、煙罩溫度、和燒嘴溫度等設定為焙燒性能指標;將解的特征向量元素設定為球團質量指標[9]。基于主成分分析法對影響球團質量的指標進行處理[10],從球團礦24個性能指標中得到3 個綜合特性指標,分別為化學成分FeO 質量分數(ym1)、轉鼓指數(ym2)、抗壓強度(ym3)。根據以上設定,影響球團礦質量因素指標和球團礦質量評價指標可以用向量表示為:

2.1.2 案例檢索
案例檢索與匹配是實現案例推理中非常重要的環節,案例檢索的速度大小和案例檢索的精度會影響案例推理的最終效果。為了滿足速度和精度的要求,要在案例庫盡可能檢索出與待求解問題相同或類似的集合,且要盡可能減少檢索次數。案例檢索方法主要有最近鄰、聚類分析、人工神經網絡等,最常用的方法就是最近鄰算法[11],最近鄰算法(k-Nearest Neighbor,KNN)是機器學習的經典算法之一。最近鄰算法基于N 個已經標注好的訓練集樣本T={Xi,i=1,…,N},對于新輸入的測試集樣本,通過計算其與訓練樣本之間的距離進行分類。在案例檢索中認為每個案例的特征是相同的且都有各自的權重w,每個案例都可以用與其最接近的案例來近似表示,通過求解二者之間的距離來評價當前案例與案例庫中案例的接近程度[12]。計算案例之間最常用的距離是歐幾里得距離,則案例庫中第m條案例xm和當前案例x0之間的歐幾里得距離為[13]:
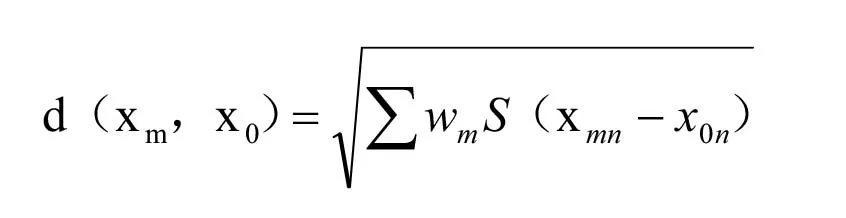
其中d 的值越小,表明當前案例與案例m 越相似。
2.1.3 修改重用
所謂案例重用,就是用在案例庫中檢測到的案例所提供的解決方案來解決目標案例的問題,對匹配信息好的案例可以直接套用案例庫案例的解決方法作為目標案例的解決方法。大多數情況下,沒有完全匹配的案例,只能通過對相似案例的解決方法進行調整得出新的解決方案。
2.1.4 保存更新
修改重用后的目標案例即使是與案例庫的一些案例極為相似,但依然會存在細微的差別,因此該目標案例可以作為新的案例加入到案例庫中,從而達到更新案例庫的功能[14]。
劉丕亮[9]等人基于某煉鐵廠的生產數據建立初始案例庫,利用主成分分析法和k-means 算法建立索引結構,采用最近鄰算法進行檢索,修改重用,更新案例庫。最后用球團焙燒實際數據仿真驗證,對FeO 質量分數、轉鼓指數、和抗壓強度進行預測,并將預測結果和多元線性回歸對比,結果表示案例推理預測精度高于多元線性回歸。兩種算法各質量指標參數預測相對誤差絕對平均值如表1所示。

表1 兩種算法各質量指標參數預測相對誤差絕對平均值Table 1 Absolute average value of the prediction relative error of each quality index parameter of the two algorithms%
東北大學的胡睿[11]為了分析影響球團礦抗壓強度的各段溫度,選取了預熱一段、預熱二段、窯頭和窯尾的溫度作為輸入,以球團礦成品球抗壓強度作為輸出,建立了基于案例推理的球團礦質量預測模型,從而得出抗壓強度預報值和噴煤量應該輸出值。李東喆[15]改進了案例推理預測球團礦抗壓強度的模型,通過搭建球團礦抗壓強度的質量控制器和球團礦生產過程的PID 控制器,以達到控制影響預熱球團抗壓強度的過程參數的目的,并驗證了控制系統能達到設定的控制要求。
2.2 基于BP神經網絡模型
BP(Back-propagation)神經網絡是最傳統的神經網絡,是Rumelhart 和McClelland 在20世紀八十年代提出的一種誤差反向傳播的多層前饋神經網絡[16]。BP 算法解決了多層神經網絡中隱單元層權重連接的問題,得到了廣泛的應用[17]。BP神經網絡結構如圖3所示。
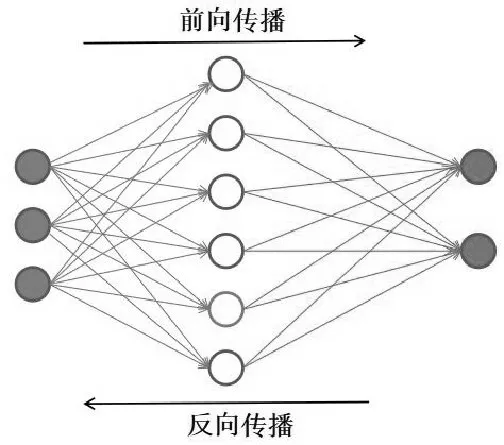
圖3 BP神經網絡結構Fig.3 BP Neural network structure
BP 神經網絡是深度學習的基本組成部分,輸入向量和輸出向量都是已知的,其任務是完成輸入X和輸出Y之間的非線性映射[18],如等式(1)所示。

BP 神經網絡屬于監督學習,圖3顯示的是一個標準神經網絡結構,左邊藍色的為輸入層,該輸入層有三個神經元,中間為隱含層,通常神經網絡有較多的隱含層,最右邊紅色的部分為輸出層。每個神經元在計算線性加權后輸出,然后經過激活函數將計算結果傳輸給下一層,在訓練過程中,從輸入層依次經過隱藏層到輸出層從前往后的過程叫做前向傳播。通過輸出層預測值和真實值之間的誤差,不斷計算損失函數,不斷地更新神經網絡的權重和偏置項,該過程是從輸出層反向傳播的,故不斷地更新神經網絡參數的過程叫做反向傳播。訓練神經網絡的過程包括前向傳播和反向傳播兩個過程。
東北大學王武海[19]將球團礦生產過程按工藝劃分為焙燒、預熱、環冷等各個階段,并找出影響每段的主要參數,根據各個分段的特點進行建模,分別建立了鏈篦機、回轉窯、環冷機三個部分的球團抗壓強度BP 神經網絡模型,并從不同的角度對模型進行驗證,結果顯示模型性能較好。金達爾剛公司[20]建立了一個三層的BP 神經網絡模型來預測球團礦的冷壓強度,該網絡的輸入變量分別為給料率、料層高度、焙燒溫度等12 個變量,輸出為成品球的冷壓強度。經過神經網絡訓練和測試表明,該網絡的預測結果與實際結果的誤差在3%以內,同時得出了輸入變量對成品球團礦冷壓強度的影響程度關系。閆洪偉[21]搭建BP 神經網絡對球團礦抗壓強度、轉鼓指數和篩分指數進行預測,獲得一定的效果,但預測精度還有待提升。東北大學的李明[22]依托弓長嶺球團公司現場生產數據,搭建了基于BP 神經網絡的抗壓強度和轉鼓指數的預報模型,結合球團的固結機理,構建了抗磨指數預測模型,該模型能夠及時準確預測成品球團礦冷的物理質量,可以指導生產及時調整控制參數從而達到提高球團礦物理性能的目的,最后結果表明所建立的預報模型可應用于實際工程中。
2.3 基于遺傳算法模型
遺傳算法是在20世紀60年代由美國密歇根大學的John Holland 提出的,遺傳算法的主要思想是模擬達爾文生物進化論,是一種用于解決最優化的一種搜索啟發式算法,主要包括選擇、交叉、變異三個過程[23]。遺傳算法流程如圖4所示。
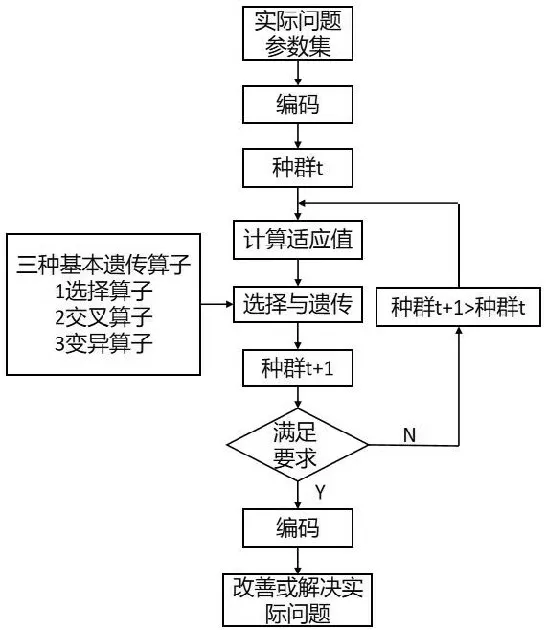
圖4 遺傳算法流程圖Fig.4 Genetic algorithm flowchart
李東喆[15]搭建了BP 神經網絡模型來預測預熱球團抗壓強度質量,同時結合遺傳算法對BP 神經網絡參數進行優化,并設計了預熱球團抗壓強度的質量控制系統。徐建有等人[24]利用遺傳算法對神經網絡的初始權值和閾值進行優化,搭建了基于遺傳算法優化的BP 神經網絡,并以實際生產數據為依據,對抗壓強度、轉鼓指數和篩分指數等質量指標值進行預測。結果表明該模型收斂快,精度高,對球團礦的生產有重要指導意義。閆洪偉[21]在BP算法的基礎上搭建了GA-BP 網絡模型,結果表明相對于BP 神經網絡,經過遺傳算法的優化,該模型對球團的抗壓強度、轉鼓指數和篩分指數的預測準確率都有較大的提高,同時遺傳算法加快了模型的收斂速度。邱波[25]等人利用遺傳算法優化的BP 神經網絡建立預熱球團的質量預測模型,仿真驗證結果表明,球團質量模型精度達到了質量控制要求。
2.4 其他模型
江山[26]等人提出并建立了基于非線性主成分分析方法與自適應小波神經網絡相結合的球團礦質量預測模型,對轉鼓指數和抗壓強度進行預測,結果表明該網絡比傳統的BP 網絡對質量的預測準確率更高。閆洪偉[21]在BP 算法的基礎上,將粒子群算法應用到網絡中,結果表明,粒子群-BP 算法的預測精度非常高,但是其收斂速度偏慢。韓陽[27]在SVM的基礎上進行改進,提出了一種球團礦冶金性能預測的SVM 改進模型,將球團礦相的紋理特征、顏色特征和分形特征構成的特征向量進行主成分提取并將其作為輸入,探索了礦相主特征與其冶金性能的關系。Jie-sheng[28]等人提出一種基于生物地理學優化算法的徑向基神經網絡模型,該模型以成品球團礦質量最相關的物料厚度、窯頭的溫度、窯尾的溫度等六個變量作為輸入,以成品球團礦的質量指數作為輸出。仿真結果表明,該模型具有較好的泛化能力和較高的預測精度。Xiao-hui Fan[29]等人根據回轉窯溫度變化曲線預測了球團抗壓強度,從而輔助工藝的優化過程。部分球團質量預測算法的預測效果如表2所示。

表2 部分球團質量預測算法的預測效果Table 2 Prediction effect of some prediction algorithms on the pellet quality
3 結論
本文介紹了國內外球團礦質量預測研究的現狀,重點總結了各種球團質量預測的算法模型,并對各算法模型在球團礦質量預測上的效果進行了對比分析。目前的算法都是在大數據基礎上開發出的智能算法,在現實生產過程中,隨著工況的變化,模型預測精度就會出現振蕩。因此可以考慮將球團礦生產過程機理加入智能算法模型中,與算法相結合使得球團礦質量預測模型更加精確。
隨著近些年計算機技術和人工智能的發展,各種智能算法都在不斷地優化升級,智能算法在球團礦質量預測上的精度也在不斷地提高。隨著數字化時代的到來,在保證預測精度的情況下,建立全面的球團礦質量預測孿生系統是未來發展的方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
少先隊活動(2021年2期)2021-03-29 05:40:48
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
中國公路(2017年7期)2017-07-24 13:56:38
光學精密工程(2016年6期)2016-11-07 09:07:19
