基于深度學(xué)習(xí)的工業(yè)生產(chǎn)安全行為分析技術(shù)
2023-01-06 13:09:48劉培妍
現(xiàn)代制造技術(shù)與裝備 2022年11期
劉培妍
(云南大學(xué),昆明 650206)
1 YOLOv5網(wǎng)絡(luò)結(jié)構(gòu)
YOLO算法是一種基于卷積神經(jīng)網(wǎng)絡(luò)的單階段目標(biāo)檢測算法。YOLO系列中的YOLOv5模型具有檢測精度高、速度快以及體積小等優(yōu)點(diǎn)。它的檢測速度達(dá)到了實(shí)時分析的要求,可滿足人們對高效、高精度目標(biāo)識別技術(shù)的需求,已被應(yīng)用于人臉識別、圖像識別等領(lǐng)域[1]。本文選擇YOLOv5算法實(shí)現(xiàn)對工業(yè)生產(chǎn)安全行為的分析[2],使用的模型是YOLOv5s。YOLOv5s由4個部分組成,分別為輸入端、模型融合特征提取網(wǎng)絡(luò)Backbone、Neck和Prediction。
1.1 輸入端
YOLOv5在訓(xùn)練圖片過程中使用Mosaic數(shù)據(jù)增強(qiáng)方法、自適應(yīng)錨框計(jì)算方法和自適應(yīng)圖片縮放方法[3]。
1.2 模型融合特征提取網(wǎng)絡(luò)Backbone
YOLOv5的Backbone包括Focus結(jié)構(gòu)、芯片級封裝(Chip Scale Package,CSP)結(jié)構(gòu)和空間金字塔池化(Spatial Pyramid Pooling,SPP),可用于從給定的輸入圖像中提取關(guān)鍵特征。其中:Focus結(jié)構(gòu)通過對圖像的切片處理加深圖像的特征維度;CSP結(jié)構(gòu)主要解決網(wǎng)絡(luò)優(yōu)化中梯度信息重復(fù)引起的推理計(jì)算過多問題,可以減少特征傳輸過程中的信息損失和計(jì)算量,減少每秒浮點(diǎn)運(yùn)算次數(shù),提高計(jì)算速度[4];SPP用于分離最重要的上下文特征,最初用來解決由于輸入圖像和卷積神經(jīng)網(wǎng)絡(luò)大小有限而導(dǎo)致的圖像特征重復(fù)提取問題。SPP結(jié)構(gòu)可以擴(kuò)展網(wǎng)絡(luò)所能處理的圖像類型,因此Backbone可以輸入任何長寬比或任何比例的圖像。
1.3 Neck
Neck結(jié)合了特征金字塔網(wǎng)絡(luò)(Feature Pyramid Networks,F(xiàn)PN)和路徑聚合網(wǎng)絡(luò)(Path Aggregation Network,PAN)[5],用于混合和組合圖像特征,并將圖像特征傳輸?shù)筋A(yù)測層。FPN將上層的強(qiáng)語義特征從上到下傳遞,以增強(qiáng)整個金字塔。PAN在FPN后面添加了一個自底向上的金字塔,以補(bǔ)充FPN,可以加快網(wǎng)絡(luò)中推理信息的傳輸,促進(jìn)網(wǎng)絡(luò)特征融合。
1.4 Prediction
Prediction進(jìn)行損失函數(shù)計(jì)算,預(yù)測圖像特征并生成邊界框。YOLOv5使用的損失函數(shù)由3部分組成,分別為GIoU損失函數(shù)、總的目標(biāo)損失函數(shù)和分類損失函數(shù)。
廣義交并比(Generalized Intersection over Union,GIoU)不僅解決了交并比(Intersection over Union,IoU)的問題,而且保持了IoU的優(yōu)點(diǎn)。GIoU不僅關(guān)注預(yù)測框和真實(shí)值之間的重疊區(qū)域,也關(guān)注非重疊區(qū)域。首先GIoU計(jì)算兩個框之間的最小閉合面積,其次計(jì)算不屬于任何一個框和IoU區(qū)域中閉合面積的比例,最后用這個比例減去IoU得到GIoU。
計(jì)算過程為

式中:I為交并比IoU;A為真實(shí)邊界框;B為預(yù)測邊界框;G為交并比IoU;C為A和B用最小矩形框起來的邊界;L為GIoU損失。
2 YOLOv5實(shí)現(xiàn)工業(yè)生產(chǎn)安全行為分析
2.1 數(shù)據(jù)集
選擇對兩個數(shù)據(jù)集進(jìn)行數(shù)據(jù)集融合,以識別工業(yè)生產(chǎn)人員是否同時佩戴安全帽和穿著反光衣。一個數(shù)據(jù)集是安全帽佩戴數(shù)據(jù)集SHWD,用來檢測安全帽。另一個數(shù)據(jù)集是反光衣數(shù)據(jù)集,用來檢測反光衣。
SHWD是開源的數(shù)據(jù)集,也是目前最大的安全帽檢測數(shù)據(jù)集,共包括7 581張圖像。反光衣數(shù)據(jù)集是Kaggle平臺上開源的數(shù)據(jù)集,共包括6 185張圖像。
通過對以上兩個數(shù)據(jù)集的融合,可以構(gòu)建一個更全面的工業(yè)生產(chǎn)場景數(shù)據(jù)集[6]。此數(shù)據(jù)集能夠同時檢測安全帽和反光衣。融合后的數(shù)據(jù)集共有13 766張圖像。
2.2 實(shí)驗(yàn)環(huán)境
在Pytorch框架下,利用統(tǒng)一計(jì)算設(shè)備架構(gòu)(Compute Unified Device Architecture,CUDA)實(shí)現(xiàn)模型的建立、訓(xùn)練和測試。硬件方面,采用Windows 10系統(tǒng),顯卡為NVIDIA GeForce GTX 1050,Intel(R) Core(TM) i5-8300H CPU@2.30 GHz。軟件方面,Python 3.8版本,配置深度學(xué)習(xí)框架Pytorch,CUDA 10.2版本。
2.3 模型性能評估指標(biāo)
一個合格的目標(biāo)檢測算法模型必須能夠以足夠高的置信度對圖像或視頻中目標(biāo)物體進(jìn)行分類和定位。此外,評估目標(biāo)檢測算法模型性能的參數(shù)有很多,包括精確率(Precision)、召回率(Recall)、平均精度(Average Precision,AP)以及平均精度均值(mean Average Precision,mAP)等。
精確率P是正確分類為正樣本數(shù)量與預(yù)測為正樣本總數(shù)的比率,表示在預(yù)測為正樣本的數(shù)量中有多少是真正的正樣本,表達(dá)式為

式中:TP為真正例;FP為假正例。
召回率R是預(yù)測為正樣本數(shù)量與總目標(biāo)測試集中正樣本總數(shù)的比率,表示從所有正樣本中正確預(yù)測出多少個正樣本,表達(dá)式為

式中:TP為真正例;FN為假負(fù)例。
對于YOLO算法,AP和mAP是衡量模型檢測精度的重要評價(jià)指標(biāo)。AP代表所檢測的每個類別在測試模型上的表現(xiàn)。mAP代表平均精度的平均值,被用作衡量目標(biāo)檢測算法總體檢測精度的指標(biāo),表達(dá)式為

式中:N為檢測類別總數(shù);P為精確率;R為召回率。
2.4 工業(yè)生產(chǎn)安全行為分析流程
本文使用YOLOv5實(shí)現(xiàn)工業(yè)生產(chǎn)安全行為分析的流程,如圖1所示。

圖1 工業(yè)生產(chǎn)安全行為分析流程圖
步驟1:初始化檢測算法,即使用融合后的安全帽與反光衣數(shù)據(jù)集訓(xùn)練YOLOv5目標(biāo)檢測算法模型。
步驟2:劃定危險(xiǎn)區(qū)域,用戶可以通過鼠標(biāo)點(diǎn)擊,自定義不規(guī)則的危險(xiǎn)區(qū)域,保存后,危險(xiǎn)區(qū)域的位置不再變動。
步驟3:獲取輸入的工業(yè)生產(chǎn)視頻圖像信息,讀取下一幀進(jìn)行分析。
步驟4:進(jìn)行YOLOv5目標(biāo)檢測。
步驟5:檢測安全帽和反光衣,識別當(dāng)前幀的工業(yè)生產(chǎn)場景,檢測工業(yè)生產(chǎn)人員安全帽和反光衣的穿戴狀態(tài)。
步驟6:進(jìn)行危險(xiǎn)區(qū)域入侵檢測,根據(jù)當(dāng)前幀圖像中安全帽和反光衣的目標(biāo)框判斷其與危險(xiǎn)區(qū)域的位置關(guān)系,分為高風(fēng)險(xiǎn)、中風(fēng)險(xiǎn)盒低風(fēng)險(xiǎn)3種危險(xiǎn)級別。
步驟7:顯示工業(yè)生產(chǎn)安全行為的檢測結(jié)果,包括安全帽佩戴狀態(tài)、反光衣穿戴狀態(tài)、3種風(fēng)險(xiǎn)級別的區(qū)域入侵狀態(tài)。
步驟8:判斷是否完成視頻讀取,若完成則結(jié)束檢測;否則,返回步驟3,繼續(xù)讀取視頻信息。
3 實(shí)驗(yàn)結(jié)果分析
3.1 模型訓(xùn)練
在YOLOv5模型訓(xùn)練中,將迭代次數(shù)設(shè)置為300次。圖2為訓(xùn)練過程中3種損失函數(shù)的變化情況。Box為預(yù)測框損失函數(shù)均值,Objectness為目標(biāo)檢測損失函數(shù)均值,Classification為分類損失函數(shù)均值。Box、Objectness和Classification值的降低,說明預(yù)測框、目標(biāo)檢測和分類越準(zhǔn)確。可以看到,3種損失函數(shù)均值在0~200次迭代過程中迅速下降。當(dāng)?shù)螖?shù)達(dá)到250左右時,損失值趨于穩(wěn)定,最后達(dá)到收斂狀態(tài)。Box值不斷接近0.03,Objectness值不斷接近0.047,Classification值不斷接近0.000,模型達(dá)到最優(yōu)狀態(tài)。

圖2 訓(xùn)練集3種損失函數(shù)變化曲線
圖3為精確率和召回率的變化情況。可以看到,精確率和召回率在訓(xùn)練前期迅速上升,當(dāng)?shù)螖?shù)達(dá)到250左右時趨于穩(wěn)定,且精確率和召回率都超過了0.9,達(dá)到了較高的水準(zhǔn)。
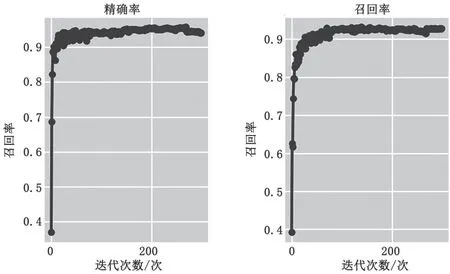
圖3 精確率和召回率變化曲線
圖4為mAP在訓(xùn)練過程中的變化情況。mAP@0.5指的是當(dāng)IoU閾值大于0.5時mAP的平均值,mAP@0.5∶0.95指的是當(dāng)IoU閾值為0.5∶0.95∶0.05時mAP的平均值。可以看到,mAP@0.5和mAP@0.5∶0.95在0~100次迭代過程中迅速上升,后逐漸穩(wěn)定。最終mAP@0.5趨于1,mAP@0.5∶0.95趨于0.6。
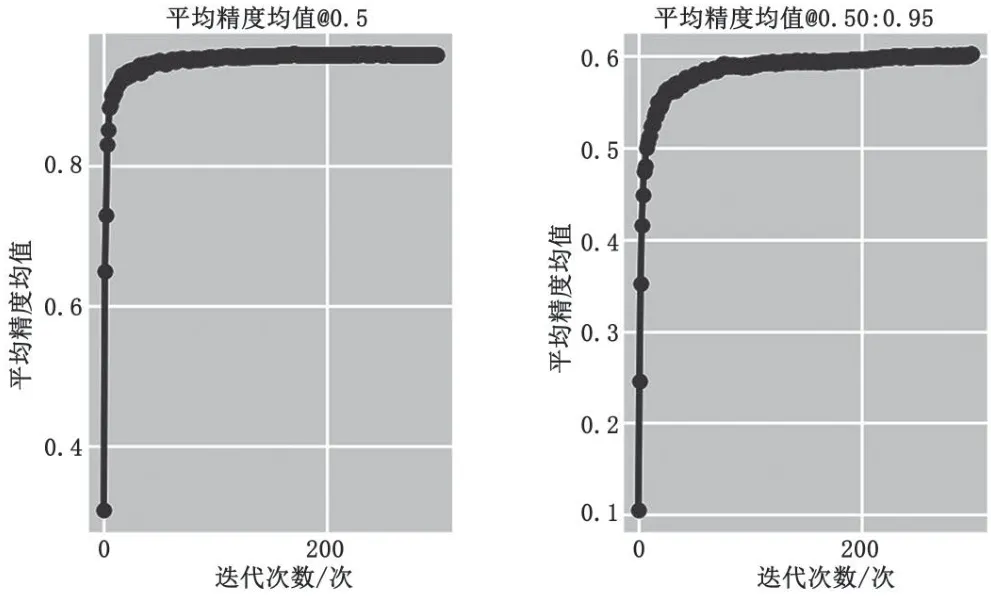
圖4 mAP變化曲線
經(jīng)過300次迭代訓(xùn)練,本文的安全帽和反光衣檢測模型能夠達(dá)到趨于收斂的狀態(tài),且訓(xùn)練集和驗(yàn)證集的損失函數(shù)都維持在較低值,能夠得到較高的精確率、召回率以及平均精度均值,整體訓(xùn)練結(jié)果達(dá)到了期望效果。
3.2 實(shí)驗(yàn)結(jié)果展示
實(shí)驗(yàn)使用訓(xùn)練得到的模型對工業(yè)生產(chǎn)場景的監(jiān)控視頻進(jìn)行檢測,對3種工業(yè)生產(chǎn)安全行為進(jìn)行分析,即檢測是否佩戴安全帽、是否穿著反光衣以及是否進(jìn)入危險(xiǎn)區(qū)域(分為高中低3種風(fēng)險(xiǎn))。圖5展示了工業(yè)生產(chǎn)場景下的檢測結(jié)果。

圖5 工業(yè)生產(chǎn)場景下的檢測結(jié)果展示
由圖5可知,工人的安全帽與反光衣能被準(zhǔn)確識別。自定義的危險(xiǎn)區(qū)域以黃綠色顯示,在危險(xiǎn)區(qū)域內(nèi)的工人都被識別為紅色的高風(fēng)險(xiǎn),離危險(xiǎn)區(qū)域較近的工人被標(biāo)為橙色的中風(fēng)險(xiǎn),較遠(yuǎn)的工人則是黃色的低風(fēng)險(xiǎn),具有良好的識別效果。圖6展示了光線較暗的工業(yè)生產(chǎn)場景下的檢測結(jié)果,證明了即使在光線較暗的工業(yè)生產(chǎn)場景下所提技術(shù)仍有不錯的識別效果。該模型檢測效果較好,基本能對視頻中的3種工業(yè)生產(chǎn)安全行為進(jìn)行正確分析,并且置信度較高。每一幀圖像的識別時間約為0.016 s,能夠達(dá)到實(shí)時監(jiān)測工業(yè)生產(chǎn)行為的效果。總體來說,實(shí)驗(yàn)結(jié)果達(dá)到了預(yù)期。

圖6 光線較暗工業(yè)生產(chǎn)場景下的檢測結(jié)果展示
4 結(jié)語
實(shí)驗(yàn)結(jié)果表明,提出的基于深度學(xué)習(xí)的工業(yè)生產(chǎn)安全行為分析技術(shù)能夠獲得較高的檢測準(zhǔn)確度,基本滿足在各種復(fù)雜工業(yè)生產(chǎn)場景下進(jìn)行安全行為分析的準(zhǔn)確性需求,且能夠達(dá)到視頻實(shí)時檢測的效果。首先,進(jìn)行數(shù)據(jù)集融合與數(shù)據(jù)增強(qiáng)。通過對兩個數(shù)據(jù)集的融合,得到一個能夠同時檢測反光衣和安全帽的完整數(shù)據(jù)集,并且進(jìn)行數(shù)據(jù)增強(qiáng),使其在較弱或較強(qiáng)光線下都能有良好的檢測結(jié)果。其次,使用YOLOv5實(shí)現(xiàn)安全帽和反光衣的檢測。300次迭代訓(xùn)練結(jié)果顯示,它對安全帽和反光衣的檢測效果較好。最后,檢測危險(xiǎn)區(qū)域入侵情況。用戶可以自定義危險(xiǎn)區(qū)域范圍,根據(jù)檢測目標(biāo)與危險(xiǎn)區(qū)域的距離,分為高風(fēng)險(xiǎn)、中風(fēng)險(xiǎn)和低風(fēng)險(xiǎn)3種風(fēng)險(xiǎn)級別。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
