面向智能滲透攻擊的欺騙防御方法
2023-01-09 12:33:28陳晉音胡書隆邢長友張國敏
通信學報 2022年10期
關鍵詞:動作
陳晉音,胡書隆,邢長友,張國敏
(1.浙江工業大學信息工程學院,浙江 杭州 310023;2.浙江工業大學網絡空間安全研究院,浙江 杭州 310023;3.陸軍工程大學指揮控制工程學院,江蘇 南京 210007)
0 引言
隨著互聯網技術的不斷發展與廣泛應用,各種網絡攻擊行為帶來諸多網絡安全問題。網絡滲透測試[1]是一種用于評估網絡系統安全的有效方法,測試人員通過模擬黑客攻擊行為對網絡及其主機進行漏洞挖掘并展開安全評估[2]。然而,滲透測試的非法使用將成為威脅網絡安全的一種攻擊手段。因此,實施針對滲透攻擊的防御至關重要。
傳統的手動滲透攻擊依賴于安全專家的經驗與操作,自動化滲透攻擊則將現有的漏洞掃描工具(如Namp[3]、Nexpose[4]等)集成至同一滲透框架(如Metasploit[5]、Core Impact[6]等)內,來執行半自動化的滲透攻擊。智能滲透攻擊將滲透攻擊過程建模為馬爾可夫決策過程,利用不同的算法模型訓練攻擊者以不斷試錯的方式對目標網絡進行滲透,獲得最佳滲透策略和最優滲透路徑,從而實現高效滲透。現有對智能滲透攻擊的研究主要包括基于傳統強化學習(RL,reinforcement learning)[7]和基于深度強化學習[8]兩類算法模型。例如,Zhou 等[9]與Tran等[10]分別提出了新的深度強化算法模型來實現智能滲透攻擊,并以此提高其滲透性能;通過改進版深度Q 網絡算法(NDD-DQN,noisy double dueling-deep Q network)及分層深度強化學習(HRL,hierarchical deep reinforcement learning)來克服滲透攻擊在大規模場景下因動作高維離散[11]和獎勵稀疏導致滲透攻擊過程難以穩定收斂的問題。相比于手動滲透攻擊與自動滲透攻擊,基于強化學習的滲透攻擊具有更強的攻擊性能,因此本文針對這類滲透攻擊展開欺騙防御研究。
Yuill[12]和Gartner[13]等提出了網絡欺騙[14-15]的定義,網絡欺騙防御的核心是防御方通過干擾和誤導攻擊者的認知決策過程,使其采取有利于防御方的動作,從而有助于防御方檢測、延緩或中斷攻擊過程,實現增強目標網絡安全性的目的。王碩等[16]根據多階段滲透攻擊的特點將其全過程分為滲透攻擊初期、中期及末期3 個階段。在滲透攻擊初期,攻擊者利用掃描工具(如Nmap)對目標網絡進行掃描,獲取主機的IP 地址、端口號、操作系統版本號、潛在漏洞運行的服務等信息,并借助滲透工具(如Metasploit)實現對主機的入侵。在滲透攻擊初期,主要采取掩蓋真實信息和模擬虛假節點的方式來達到欺騙防御的目的,如Jafarian 等[17]設計的基于對手感知的地址隨機化方法和Wang 等[18]構造的隨機域名與地址跳變(RDAM,random domain name and address mutation)防御方法均使攻擊者掃描到錯誤的IP 地址,進而使攻擊者無法成功進行后續的攻擊行為。在滲透攻擊中期,攻擊者已經深入目標網絡內部,探測識別潛在的主機漏洞,進而滲透這些漏洞,并不斷橫向移動以逼近攻擊目標。在目標網絡內部部署蜜罐是抵抗滲透攻擊中期攻擊的主流方法,如Anagnostakis 等[19]將入侵檢測設備判定為異常的流量牽引至“影子蜜罐”來提高針對未知緩沖區溢出攻擊的檢測準確率。在滲透攻擊末期,防御方的重點是實現對攻擊目標的特殊防護,如Rowe 等[20]和石樂義等[21]提出的偽蜜罐和擬態蜜罐警戒色都是為了使攻擊者將真實系統當作蜜罐從而將攻擊者嚇退。
已有的滲透攻擊欺騙防御研究主要針對非智能滲透攻擊方法,而對于智能滲透攻擊被惡意利用對目標網絡所造成的安全威脅,目前尚無相關研究對其進行有效防御。基于此,本文針對基于強化學習的智能滲透攻擊在訓練過程中其經驗數據存在被欺騙的可能性,如狀態中的漏洞運行服務以及操作系統類型數據被修改等,提出一種面向智能滲透攻擊的欺騙防御方法。本文的主要工作如下。
首先,將滲透攻擊建模為馬爾可夫決策過程并利用強化學習算法Q 學習(QL,Q-learning)算法[22]對目標網絡進行智能滲透。其次,通過對該滲透環境下的狀態、動作以及獎勵所對應的實際含義進行分析,修改狀態、動作以及獎勵訓練數據中的關鍵信息,擾亂攻擊者的滲透策略生成,使其攻擊策略出錯或失效,從而實現對攻擊者的欺騙防御。最后,將修改攻擊者狀態、動作以及獎勵數據的過程對應于多階段滲透攻擊的前期、中期和后期3 個階段,并在同一網絡環境進行3 個階段的對比實驗,以此驗證所提方法的防御性能。
1 基于強化學習的智能滲透攻擊
1.1 強化學習
強化學習是一種基于智能體與環境之間序列交互的機器學習方法,智能體在給定時間內通過不斷試錯學習以最大化長期累積獎勵Gt[8]。該過程通常用馬爾可夫決策過程(MDP,Markov decision process)來描述,MDP 可以表示為一個四元組<S,A,R,P>,其中,S表示狀態空間集合,A表示動作空間集合,R表示獎勵函數,P表示狀態轉移矩陣,即從當前t時刻狀態st采取動作at轉移到下一個時刻狀態的概率P(st+1|st,at)。累積獎勵表示為
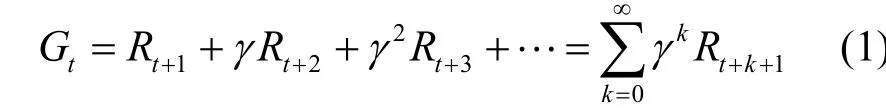
其中,γ∈ (0,1)表示折扣因子,用于衡量當前獎勵對未來獎勵的重要性。
QL[22]是一種基于Q值函數的強化學習算法,主要思想是將智能體不同時刻的狀態和動作構建為存儲Q(s,a)值的Q表,然后根據Q值來選取能夠獲得最大收益的動作。Q表的更新機制為
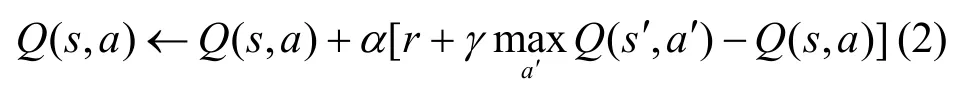
其中,s和a分別表示攻擊者當前的狀態和動作,s'表示攻擊者采取動作a后出現的下一個狀態,a'表示攻擊者在狀態s'下可能采取的動作,r表示即時獎勵,α和γ分別表示學習率和折扣因子。
1.2 智能滲透攻擊過程
強化學習在游戲領域的決策任務性能表現突出,例如 Alpha Go[22]、Dota2[23]和StarCraftⅡ[24],基于強化學習的攻擊者已經超過了人類玩家。與許多Gym 和Atari[22]游戲規則一樣,滲透攻擊也是一個基于環境狀態的動態決策過程。因此,可以訓練基于強化學習的智能滲透攻擊[26]智能體來觀察動態網絡環境并通過試錯學習最優策略。
在基于QL 算法實現智能化滲透攻擊[27]的過程中,攻擊者會不斷優化自動生成的滲透攻擊路徑,并最終得到一條最佳攻擊路徑[28]。攻擊者在訓練過程中會根據不同主機運行的不同漏洞服務,如安全外殼(SSH,secure shell)協議、超文本傳輸協議(HTTP,hypertext transfer protocol)、文件傳輸協議(FTP,file transfer protocol)等,選擇相應的具有代表性的漏洞來計算該漏洞利用的概率,本文根據通用漏洞評分系統(CVSS,common vulnerability scoring system)分別對SSH 服務和HTTP 服務設置0.9 的滲透概率,對FTP 服務設置0.6 的滲透概率。除了滲透操作外,針對提權操作和掃描操作的概率均設置為1。攻擊者在采取對應的操作后,環境會反饋其相應的獎勵值,該獎勵值計算式如式(3)所示,主要包括主機的價值以及對該主機進行漏洞利用、提權或者掃描操作所消耗的成本。
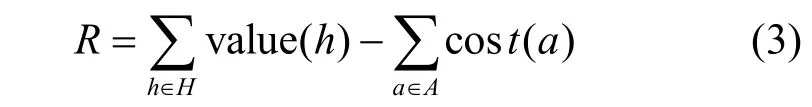
其中,H表示網絡中可以被攻擊者滲透的主機集合,A表示攻擊者的動作集合。在訓練過程中,攻擊者的目標就是最大化累積獎勵值,如式(4)所示,以此獲取對目標敏感主機的滲透路徑,即需要以盡可能少的操作來滲透最大價值的目標敏感主機。
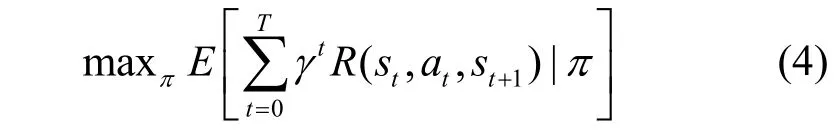
針對本文的蜜罐目標網絡環境,目標敏感主機獎勵值設為100,蜜罐主機的獎勵值設為-100,攻擊者在網絡中只能與相連的子網或者主機之間進行滲透,每個回合中攻擊者的結束條件有2 種情況:1) 獲得所有目標敏感主機的Root 權限;2) 回合訓練步數達到了設置的最大值。
攻擊者以不斷試錯的方式來獲得最大化累積獎勵值,從而學習到滲透目標敏感主機的最優滲透路徑。在蜜罐網絡中,由于蜜罐的獎勵值為負值,因此攻擊者在攻擊過程中會繞過蜜罐主機,最終學習到利用較少的操作步驟來攻擊目標敏感主機的最優滲透路徑。
2 欺騙防御問題建模
將滲透攻擊建模為馬爾可夫決策的過程中,智能體被視為滲透攻擊者,S={s1,s2,… ,si}表示攻擊者的狀態集合,其中si是攻擊者在某個特定時刻i利用掃描工具對目標網絡進行掃描,能獲取到關于主機的IP地址、端口號、操作系統版本號、潛在漏洞運行服務等信息,隨后攻擊者將進一步對目標主機進行滲透入侵。A={a1,a2,… ,ai}代表攻擊者的動作集合,其中ai是攻擊者根據其與環境交互獲得的狀態si所采取的動作。在滲透攻擊過程中,攻擊者采取的動作主要包括漏洞掃描、漏洞利用以及權限提升等操作。最后,根據此刻攻擊者采取的動作ai是否成功滲透至目標主機,環境將給予其獎勵反饋ri,R={r1,r2,…,rn}表示攻擊者獲得的即時獎勵集合。
定義1為欺騙防御方的狀態集合,即欺騙狀態,其中對應于攻擊方在i時刻被防御方欺騙的狀態,用一個x維的布爾向量d表示。維度x由目標網絡的子網數nsub、主機數nhost、不同子網中最大主機數nmax以及網絡配置信息類型數ncon確定。
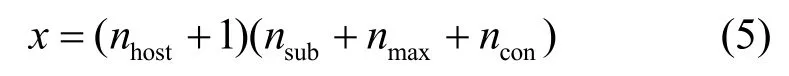
在本文的目標網絡場景下,其主機數為8,子網數為5,不同子網中最大主機數為5,網絡配置信息類型數為13,因此其狀態維度x=207。此外,對于1≤k≤x,欺騙防御方狀態向量的第k維分量d(k)∈{0,1}。當d(k)=1時,的第k維對應的網絡配置信息為True;當d(k)=0時,的第k維對應的網絡配置信息為Flase。例如,的第11N維、第12N維以及第13N維信息分別對應第N臺主機此刻是否被妥協、是否可到達以及是否被發現,若第1 臺主機此刻未被攻擊者妥協,但可到達已被攻擊者發現,此時'中的第11 維~第13 維的狀態向量為(0,1,1)。
定義2為欺騙防御方的動作集合,即欺騙動作,其中對應于攻擊者在狀態si下被防御方欺騙所采取的動作,由一個z維的整型集合c表示。維度z由目標網絡的主機數nhost、掃描動作數nscan、漏洞運行服務類型數nservice和權限提升進程數nprocess確定。其中,掃描動作包括對每臺主機的服務掃描、操作系統掃描、子網掃描、進程掃描這4 個固定動作,因此nscan=4。
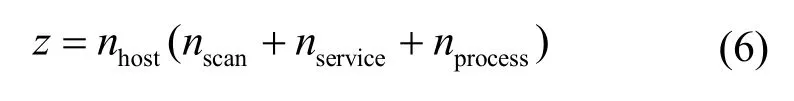
集合c中包含了攻擊者可能執行的所有動作,例如,本文的目標網絡場景中共有8 臺主機,所有主機包括2 種主機操作系統:Windows 和Linux,3 種漏洞運行服務:SSH、HTTP 和FTP,2 種權限提升進程過程:Tomcat 和Daclsvc,以及2 種防火墻限制服務:HTTP 和SSH。因此,根據定義2 可知,攻擊者采取的動作可以有 72 種操作組合,因此c={0,1,2,…,71}。
定義3為欺騙防御方的獎勵集合,即欺騙獎勵,其中ri' 對應于攻擊者在狀態si下執行動作ai所獲得的欺騙獎勵,由一個4 維的整型集合p表示,例如p={-1 00,0,100,200},不同的取值代表對攻擊者不同的欺騙獎勵。
3 面向基于強化學習的智能滲透攻擊的欺騙防御方法
本節將從攻擊者的狀態、動作以及獎勵數據為切入點,分別從多階段滲透攻擊的前期、中期及后期介紹面向智能滲透測試的欺騙防御方法,欺騙防御模型如圖1 所示。
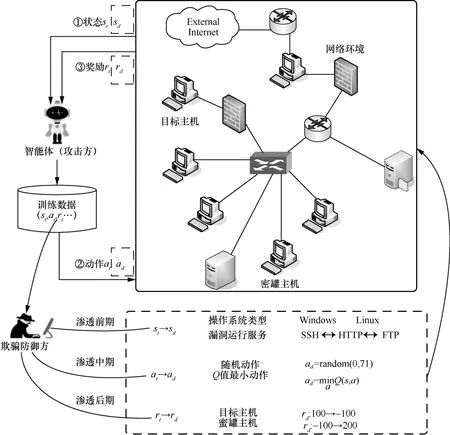
圖1 欺騙防御模型
欺騙防御方通過捕獲攻擊者訓練池中的狀態、動作及獎勵數據并對其分別修改后,將欺騙數據與攻擊者正常訓練數據替換,如將攻擊者的狀態替換成欺騙狀態,以此達到欺騙防御的目的。
3.1 狀態欺騙防御
滲透攻擊前期是多階段滲透攻擊的發起階段,也是其得以進行的前提和基礎。因此,有效防御滲透攻擊前期的攻擊行為對于抵抗多階段滲透攻擊起著至關重要的作用。在利用MDP 對基于QL 的滲透攻擊過程建模時,攻擊者從目標網絡環境中獲取到的狀態包括目標網絡中每臺主機的地址、該主機詳細配置信息,如該主機是否可到達、是否被發現以及是否被滲透等,此外,還包括該主機的實際滲透價值以及其漏洞服務信息和提權進程所組成的多維布爾向量。攻擊者狀態獲取的過程相當于其在滲透攻擊前期所采取的操作。
因此,從防御方角度來看,如何保護目標網絡信息不被攻擊者完全獲取成為抵抗滲透攻擊前期攻擊行為的關鍵。本文設計在滲透攻擊前期的掃描階段攻擊者獲取主機操作系統類型和漏洞運行服務時,通過掩蓋主機的真實配置信息,使攻擊者掃描不到主機的真實配置信息或掃描出錯,如將主機操作系統Linux 掃描成Windows;而對于不同的漏洞服務,如SSH、HTTP 及FTP 出現掃描不全或者掃描出錯的情況。具體而言,對狀態進行欺騙防御包括3 種情況:1) 掩蓋操作系統類型;2) 掩蓋漏洞運行服務;3) 同時掩蓋操作系統類型和漏洞運行服務。
在對攻擊者的狀態欺騙防御過程中,涉及對操作系統類型和漏洞運行服務的掩蓋,因此對于攻擊者狀態si,只需對其中的第Nk維分量d(Nk)進行取反操作RET 即可得到欺騙狀態
對應于情況1),k∈ [16,17],若d(16N,17N)={1,0},表明此時攻擊者掃描到第N臺主機的操作系統為Linux;若d(16N,17N)={0,1},則表明第N臺主機的操作系統為Windows,對狀態分量d(16N,17N)進行按維取反操作,將使攻擊者在掃描目標主機真實操作系統時出錯,從而達到掩蓋真實操作系統類型的目的。
對應于情況2),k∈ [18,20],d18N、d19N及d20N三維分量分別對應第N臺主機是否運行的3種漏洞服務SSH、HTTP 及FTP。若d(18N,19N,20N)={1,0,1},表明第N臺主機正運行SSH 和FTP 這2 種漏洞服務,同理,對狀態分量d(18N,19N,20N)進行按維取反操作,將使攻擊者掃描目標主機運行的漏洞服務出錯;若 RETd(18N,19N,20N)={0,1,0},表明第N臺主機正在運行的SSH 和FTP 漏洞服務均未被掃描到,而掃描到該主機正在運行HTTP 漏洞服務,以此達到掩蓋真實漏洞運行服務的目的。
對應于情況3),k∈ [17,22],為了達到同時掩蓋操作系統類型和漏洞運行服務的目的,只需同時對第N臺主機的五維分量d(Nk)進行按維置反操作。綜上,狀態欺騙防御算法的偽代碼如算法1 所示。
算法1狀態欺騙防御算法
輸入攻擊者狀態S,訓練回合數i=20 000,主機數nhost,狀態維度k
初始化Sd=S,i=1
1)循環
2) fori=0,1,2,…,do
3)判斷
4) if 掩蓋主機操作系統類型:
5)k={16,17}
6) elif 掩蓋主機漏洞服務類型:
7)k={18,19,20}
8) else 同時掩蓋主機操作系統和漏洞服務:
9)k={16,17,18,19,20}
10) end if
11) 結束判斷
12)取出對應維度的狀態分量d(Nk)=S[k]
13) 按維取反d(Nk)'=RETd(Nk)
14) 生成欺騙狀態Sd[k]=d(Nk)'
15) 以欺騙狀態更新攻擊者狀態S←Sd
16)更新當前回合i←i+1
17) 返回當前欺騙狀態Sd
18) end for
19)結束循環
3.2 動作欺騙防御
滲透攻擊中期是攻擊者實施行動的正式階段,它將直接影響攻擊者的滲透結果。因此,如何準確檢測攻擊者所處位置并干擾其攻擊進程將是防御滲透攻擊中期攻擊行為的關鍵。
在基于強化學習的智能滲透攻擊過程中,本文主要采用干擾攻擊者攻擊進程的方式來達到欺騙防御的目的。由定義2 可知,在本文的目標網絡下,攻擊者采取的動作存在72 種組合。例如,第16 個動作指攻擊者對子網2 中的敏感主機執行Tomcat進程的權限提升操作,該操作是滲透該網絡場景中十分關鍵的動作,因為子網2 內的敏感主機是該網絡場景中第一臺存在可利用漏洞服務的主機,攻擊者一旦將其攻破,便可通過權限提升操作獲得對該主機的管理權限,進而通過橫向移動不斷逼近目標主機。
因此,要實現在滲透中期對攻擊者的防御,關鍵在于干擾其采取具體滲透操作的過程。本文通過以下2 種干擾攻擊者動作生成方式進行欺騙防御。
1) 干擾攻擊者選擇隨機動作
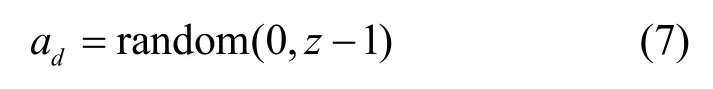
其中,z表示攻擊者可采取的動作數,已于定義2中給出。
2) 干擾攻擊者選擇Q值最小的動作
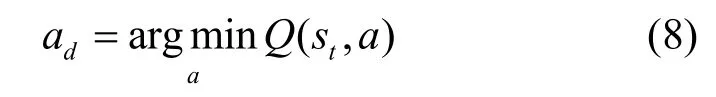
攻擊者在采取動作的過程中,令其采取隨機動作是最直接的干擾方式,如式(7)所示。具體而言,此時攻擊者不會根據在滲透前期掃描到的漏洞信息采取對應的攻擊操作,而是以隨機動作的方式生成攻擊策略,因此該攻擊策略存在一定的隨機性,進而導致攻擊者可能無法成功滲透至最終目標。此外,本文采取另一種干擾程度更高的方法,如式(8)所示,ad表示攻擊者在t時刻狀態st時以Q值最小的訓練方式所生成的干擾動作。在攻擊者正常的攻擊策略生成過程中,QL 算法為每一時刻的狀態和動作(s,a)建立Q表,并且每一組狀態動作對都對應不同的Q值,在訓練過程中選取Q值最大的動作為訓練最優解。為了達到干擾攻擊者策略生成的目的,本文通過將Q值最大的訓練方式修改為Q值最小,使攻擊者生成的策略無法達到攻擊效果,最終實現欺騙防御。動作欺騙防御算法的偽代碼如算法2 所示。
算法2動作欺騙防御算法
輸入訓練回合數i=20 000,主機數nhost,操作系統類型數nos,漏洞運行服務類型數nservice,不同子網間防火墻限制的服務類型數nfirewall
初始化Q表Q(s,a),學習率α∈ (0,1],折扣因子γ∈ (0,1),i=1
1)循環
2) fori=0,1,2,…,do
3) 初始化攻擊者狀態s
4) 基于e-greedy 貪婪策略從Q表派生的Q值最大策略中選擇s對應的動作a
5) 執行動作a,觀察攻擊者獎勵r及下一個狀態s'
6) 判斷
7) if 采取隨機動作
8) 以式(7)生成欺騙動作9) else 采取Q值最小動作
10) 以式(8)生成欺騙動作
11) end if
12) 結束判斷
13) 以欺騙動作替換攻擊者動作a=ad
14) 執行動作a
15) 觀察攻擊者獎勵r及下一個狀態s'
16) 以式(2)更新Q表
17) 更新攻擊者狀態s←s'
18) 更新當前回合數i←i+1
19) 返回攻擊者下一個狀態s'
20) end for
21) 結束循環
3.3 獎勵欺騙防御
在滲透攻擊后期,攻擊者已經錨定了目標主機并可能采取了相應的攻擊操作。針對攻擊者的行為,防御方的重點是實現對攻擊目標的特殊防護。鑒于獎勵值的設定是強化學習算法訓練的關鍵環節,可用于強化攻擊者學習到的滲透策略,因此,本文在訓練階段以修改獎勵值的方式對其進行欺騙防御,以獎勵值翻轉的方式強化錯誤的滲透策略,使其難以尋找到最優的滲透攻擊路徑,從而無法到達最終目標。
在該階段,考慮到蜜罐的存在是在滲透中期引誘攻擊者的一種方式,因此該階段不考慮對蜜罐的部署,而是將其作為一類特殊目標來輔助防御過程。因此,本節對是否存在蜜罐網絡場景的獎勵欺騙防御方法進行討論。
在無蜜罐網絡場景中,本文將敏感主機的獎勵值符號進行翻轉來降低攻擊者的滲透成功率,即將敏感主機的價值由100 修改為-100,同時將訓練過程每個回合的結束條件修改為回合訓練步數達到設置的最大值1 000 步,而獲得目標敏感主機的Root 權限時也并不表示回合結束。此時,攻擊者在訓練過程中即使滲透到了敏感主機,也不會產生滲透成功標志,并且獲得的獎勵回報很低,使攻擊者誤以為這種動作策略是無效的滲透策略,從而達到降低攻擊者性能的目的,影響敏感主機滲透攻擊的成功率。
在有蜜罐網絡場景中,本文同樣將訓練數據的獎勵值符號進行翻轉來對攻擊者進行欺騙防御,包括蜜罐主機和敏感主機,其中蜜罐主機的獎勵值由-100 修改為200,敏感主機的獎勵值修改為-100,這是由于網絡中存在2 個敏感主機,找到所有蜜罐主機獲得的獎勵值接近于200。當蜜罐主機的獎勵值修改為200 時,攻擊者在欺騙防御訓練過程中獲得的獎勵值訓練效果會接近于正常訓練,并且陷入蜜罐的概率也將加大。同時將每個回合的結束條件修改為:獲得蜜罐主機的User 權限,且回合訓練步數達到了設置的最大值。獎勵欺騙防御算法的偽代碼如算法3 所示。
算法3獎勵欺騙防御算法
輸入攻擊者當前狀態s,訓練回合數i=20 000
初始化Q表Q(s,a),欺騙獎勵池p={-1 00,0,200},學習率α∈ (0,1],折扣 因 子γ∈ (0,1),i=1
1)循環
2) fori=0,1,2,…,do
3) 初始化攻擊者狀態s
4) 基于e-greedy 貪婪策略從Q表派生的Q值最大策略中選擇s對應的動作a
5) 執行動作a,觀察攻擊者獎勵r及下一個狀態s';
6) 判斷
7) ifr=100
8) 欺騙獎勵rd=p[ 0]
9) elifr=-100
10) 欺騙獎勵rd=p[ 2]
11) else
12) 欺騙獎勵:rd=p[1 ]
13) end if
14) 結束判斷
15)r=rd
16) 以式(2)更新Q表
17) 更新攻擊者狀態:s←s'
18) 更新當前回合數:i←i+1
19) 返回攻擊者下一個狀態s'
20) end for
21)結束循環
4 實驗結果與分析
4.1 實驗環境設置
實驗環境的具體配置如下:CPU 型號為iE3-123v3@3.40 GHz,運行內存為32 GB,操作系統為Ubuntu 16.04,編程語言為Python 3.7.10,深度學習框架為PyTorch-1.5.0。本文在NASim 平臺[28]構建的模擬網絡環境中進行智能滲透攻擊和欺騙防御研究,利用QL 算法[22]進行實驗,共訓練20 000 個回合,并在每個回合都記錄滲透攻擊路徑生成所需要的時間步數和成本消耗,在訓練階段中每隔1 000 個回合計算一次平均值,采用的評價指標如下。
1) 平均回合獎勵。在訓練過程中,每隔1 000 個回合計算一次攻擊者的平均獎勵值,用于評估攻擊者的滲透性能。
2) 平均回合步數。在訓練過程中,每隔1 000 個回合計算一次平均回合長度,表示攻擊者滲透攻擊路徑生成所需的時間成本,用于評估攻擊者的滲透性能。
3) 陷入蜜罐概率。在有蜜罐網絡場景進行滲透攻擊和欺騙防御過程中,每隔1 000 個回合計算一次蜜罐主機入侵的平均概率,用于評價攻擊和防御效果。
4.2 目標網絡場景介紹
本文針對圖2 所示的目標網絡場景進行滲透攻擊,基于QL 算法訓練攻擊者尋找最優滲透路徑并實現智能滲透攻擊。
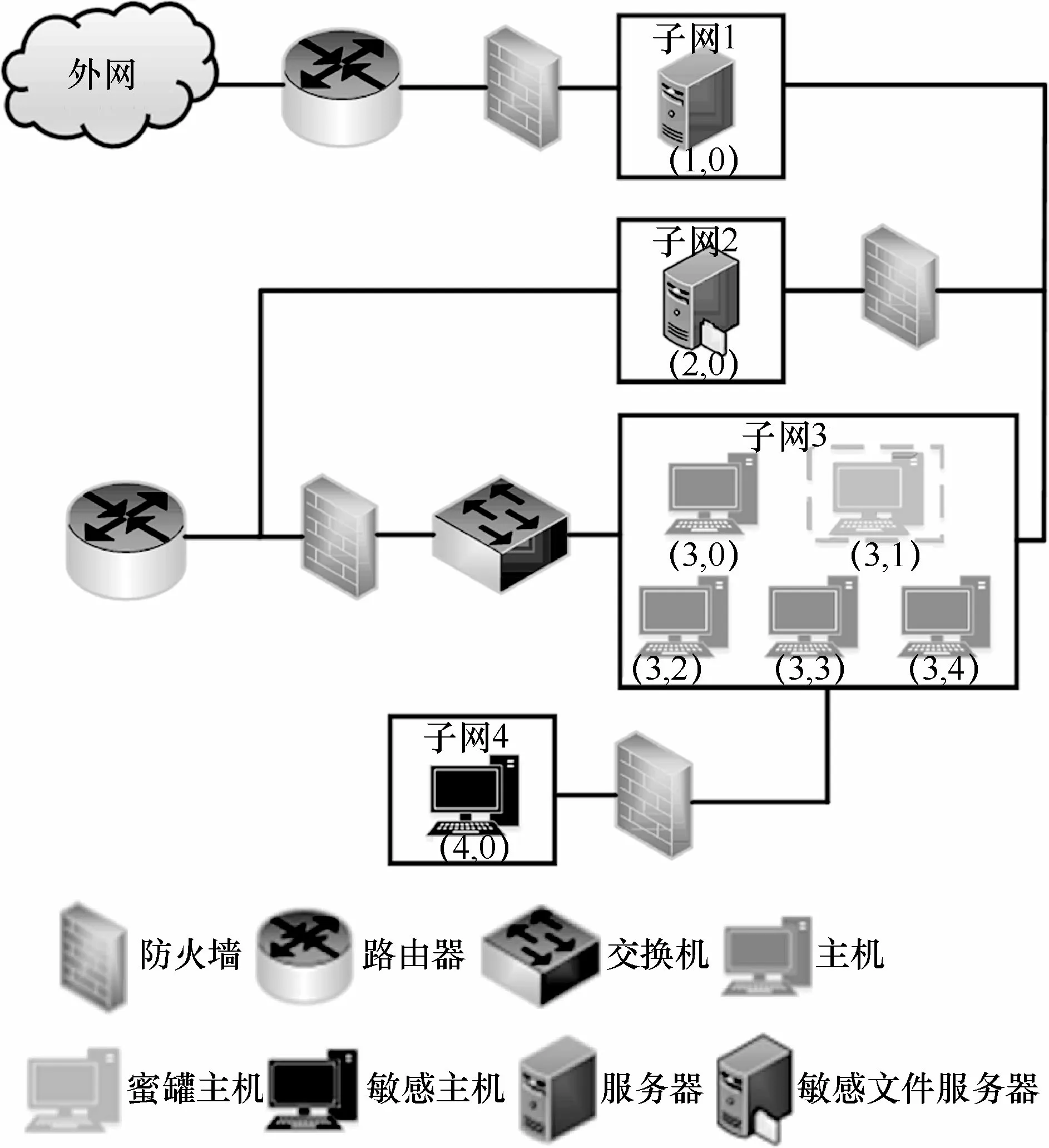
圖2 目標網絡場景
目標網絡場景中包含4 個子網絡、8 臺主機和服務器,其中有2 臺為敏感主機,分別為(2,0)和(4,0),其中(4,0)為目標主機,該2 臺主機均運行了不同的漏洞服務。只有子網1 可以和外網直接通信,不同子網間的通信被防火墻所限制的不同服務所阻隔,每次從一個子網滲透到另一個子網都需要消耗一定的成本。此外,子網內的主機可以相互通信,子網1 可以直接和子網2及子網3 進行通信,但不能與子網4 進行通信,所以攻擊者想要成功滲透目標敏感主機(4,0),就必須先滲透攻擊成功子網2 或子網3 內的主機,通過提權操作獲得滲透成功主機的Root 權限后,再利用橫向移動對子網4 的目標敏感主機進行滲透攻擊,直至滲透結束。
主機配置信息如表1 所示,包括主機地址、操作系統、漏洞服務、權限提升進程以及主機價值。為了模擬真實攻擊者的行為,本文假設攻擊者無法直接獲取網絡的拓撲信息和主機配置的相關信息,因此,除了漏洞利用(Exp,exploit)和權限提升(PE,privilege escalation)動作之外,還可以采用掃描動作獲取目標網絡主機的相關信息。對于每臺主機來說,攻擊者可以選取表2 中的動作,本文選用子網滲透過程中常被攻擊者利用的進程和服務來替代網絡安全漏洞。例如,攻擊者可以通過FTP 漏洞來得到主機的User 權限,利用Daclsvc 權限提升進程來獲得主機的Root 權限,從而實現對目標主機的滲透攻擊。
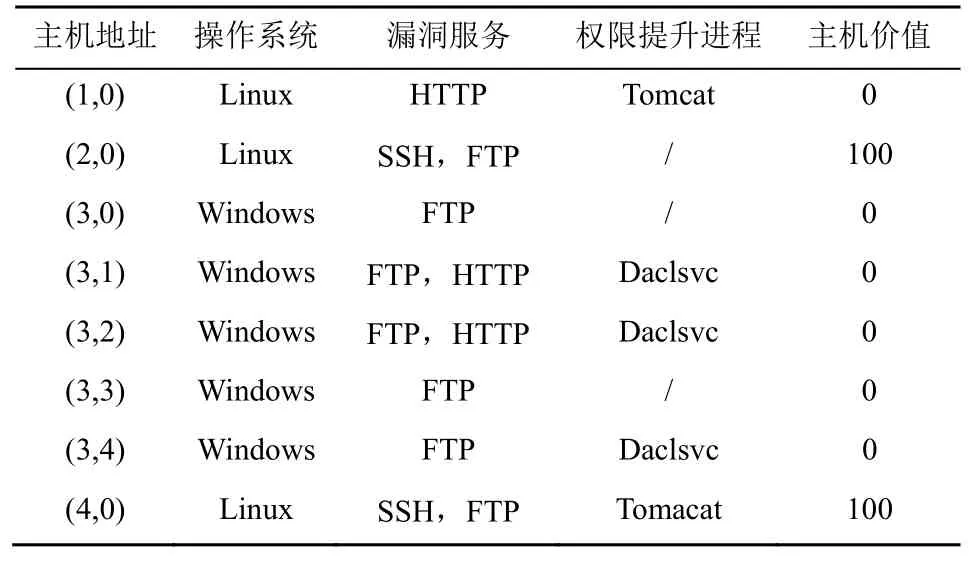
表1 主機配置信息
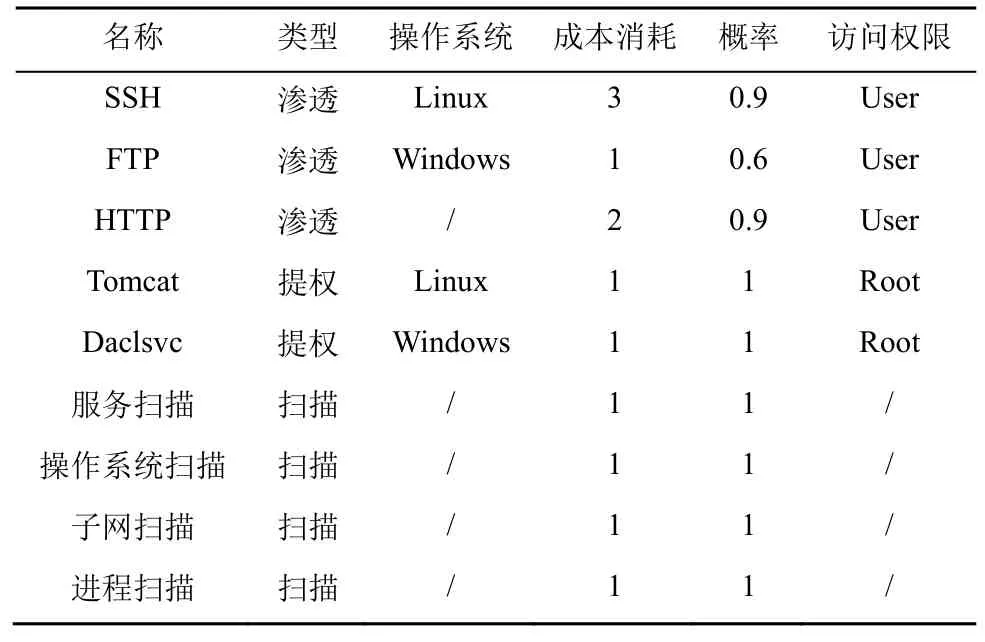
表2 攻擊者動作
此外,本文還研究了對蜜罐網絡的滲透攻擊,即將圖2 中(3,1)的普通主機替換為蜜罐主機。在傳統的滲透測試中,蜜罐可以偽裝成敏感主機來誘使滲透攻擊者對其進行滲透,從而有效保護網絡中的敏感主機。但是,在正常滲透攻擊該場景時,由于攻擊者事先知曉蜜罐的地址,并且蜜罐主機所賦價值為-100,所以攻擊者經過訓練后會以繞過蜜罐主機的方式對其余子網的目標主機進行滲透攻擊。
因此,在對攻擊者的狀態和動作進行欺騙防御的情況下,本文不對蜜罐主機的價值做修改處理,此時的蜜罐設置起不到輔助防御的作用,若攻擊者陷入蜜罐主機的概率提升,則恰巧說明是狀態或動作的干擾起到了欺騙攻擊者的效果,從而導致其陷入其中。為使防御實驗更充分,本文在有蜜罐的目標網絡場景中進行狀態和動作欺騙防御。相反,由式(3)可知,攻擊者獲得的獎勵與主機價值和滲透該主機的成本有關,在以修改主機價值對攻擊者進行獎勵欺騙防御的過程中,通過對蜜罐主機原本的低價值翻轉為高價值即可將該蜜罐主機偽裝成目標敏感主機,從而達到欺騙攻擊者的目的;同理,將敏感主機的高價值翻轉為低價值,攻擊者將敏感主機誤以為蜜罐主機,并選擇繞開該主機,不對其采取滲透操作,以此達到保護敏感主機的目的。因此,本文分別在無蜜罐和有蜜罐的網絡中展開獎勵欺騙防御實驗。
4.3 狀態欺騙防御時滲透攻擊性能分析
在滲透攻擊者掃描階段,本文通過掩蓋主機操作系統類型及漏洞運行服務干擾攻擊者對目標網絡正常狀態的獲取,如將主機操作系統Linux 掃描成Windows,而對不同的SSH、FTP 及HTTP 漏洞服務掃描不全或者掃描出錯,以此達到掩蓋真實網絡信息的目的。此外,針對在滲透前期常采用的地址跳變[17-18]欺騙防御方法,考慮到主機地址是攻擊者狀態中的第Nk維分量d(Nk),k∈ [0,9],本節結合地址跳變的思想,同樣采取對應維度置反的方法使攻擊者掃描到錯誤的IP 地址,并作為上述另外3 種狀態欺騙防御方法的對照基準。本節以4 組不同的數據干擾比例(20%、50%、80%及100%)分別對主機地址跳變、主機操作系統、主機漏洞服務以及對主機操作系統和漏洞服務均欺騙掩蓋的4種方法在有蜜罐的目標網絡下進行對比實驗,每組對比實驗均訓練20 000 回合。
對于4 種狀態欺騙方法而言,從圖5~圖8 可以發現一個共同現象:干擾比例越高,欺騙防御效果越好,當干擾比例超過50%時,欺騙防御效果愈加明顯。對于主機地址跳變、干擾主機漏洞服務以及同時干擾主機操作系統和漏洞服務的3 種狀態欺騙方法而言,圖5、圖7、圖8 存在一個共同現象:當干擾比例為20%時,從平均回合獎勵及平均回合步數來看其干擾效果并不明顯,攻擊者均能在6 000 回合左右尋找到最優路徑,訓練成本較正常訓練只增加1 000 回合。這也從另一方面說明強化學習模型以不斷試錯的訓練方式在20%的低干擾比例內,能通過“自愈”的方法恢復到正常性能。
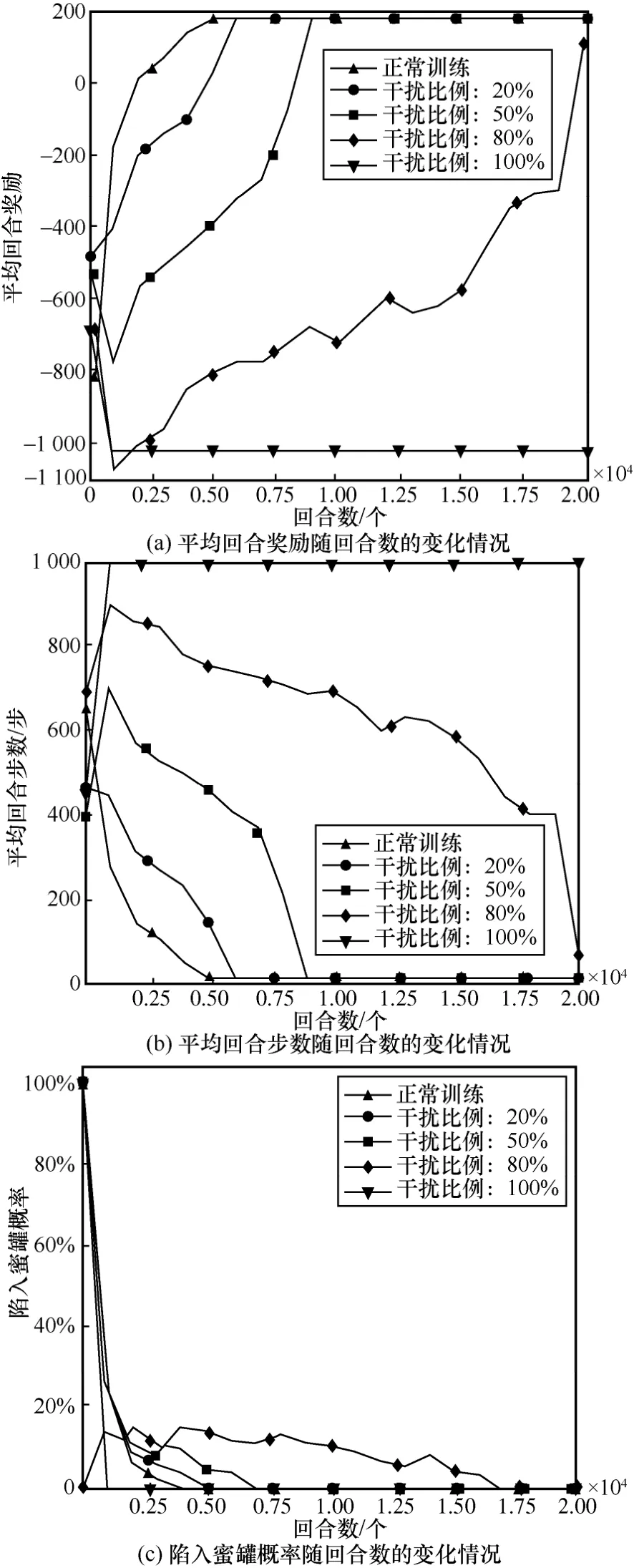
圖5 對主機地址跳變進行欺騙防御訓練效果隨回合數的變化情況
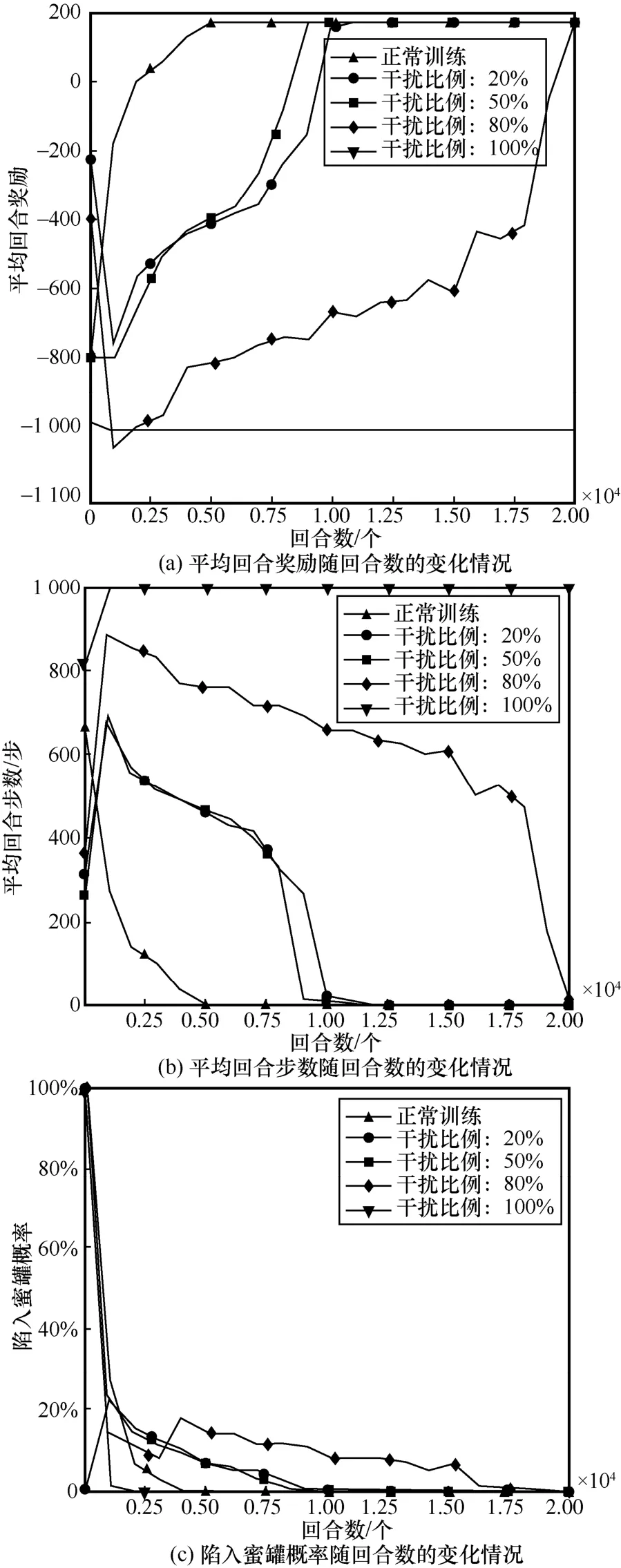
圖6 對主機操作系統進行欺騙防御訓練效果
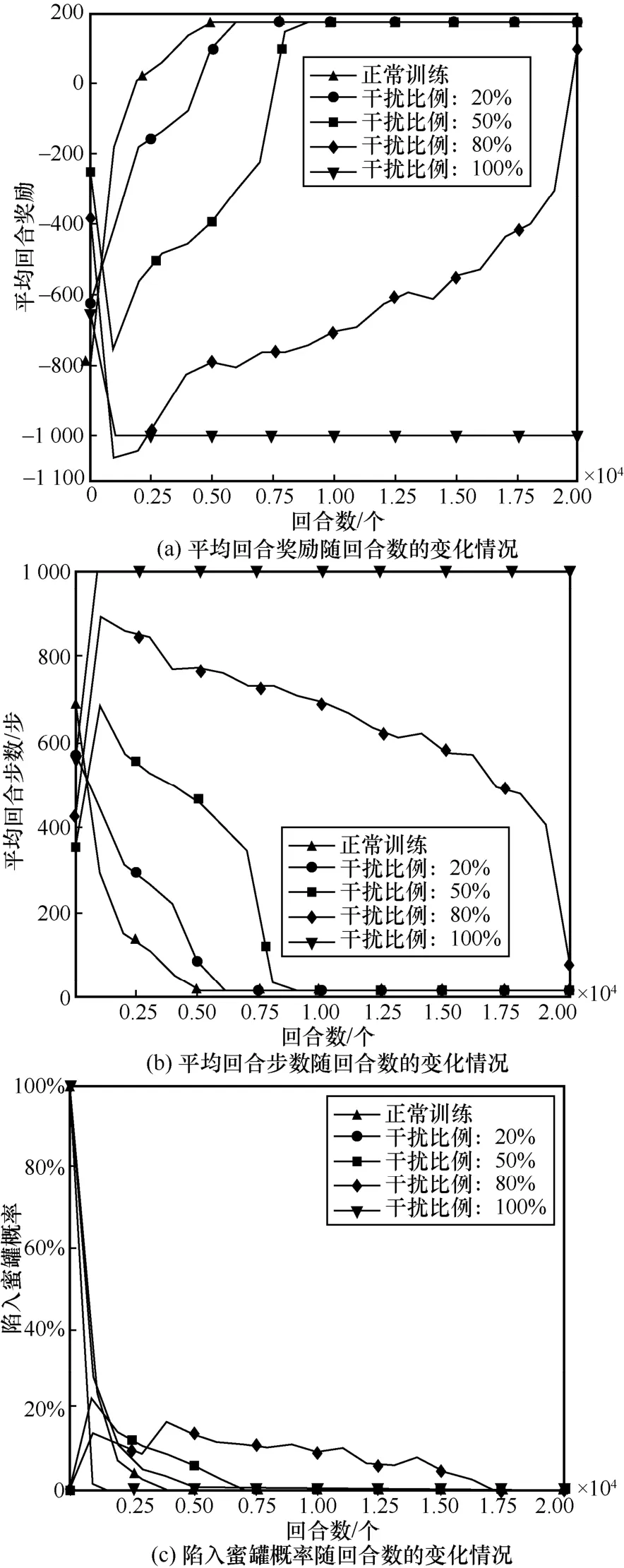
圖7 對主機漏洞服務進行欺騙防御訓練效果
對于主機操作系統而言,當干擾比例為20%時,其防御性能接近其余3 種狀態欺騙方法在干擾比例為50%時的性能,訓練成本較正常訓練增加近4 000 回合,這也說明通過干擾主機操作系統可以低干擾成本達到較高防御性能。攻擊者通過滲透與主機操作系統相匹配的漏洞服務獲取其相應的管理權限,只有在成功滲透該主機漏洞服務的前提下才能進行提權操作;一旦主機操作系統受到干擾,將導致主機操作系統與漏洞服務不匹配,攻擊者可能無法對該主機采取與其漏洞服務相匹配的滲透方式,最終導致無法成功滲透目標主機。
當干擾比例擴大至50%~80%時,對4 種狀態欺騙方法的防御效果都比較明顯,其訓練成本較正常訓練從10 000 回合增加至20 000 回合,隨著干擾比例的擴大,訓練成本增加了一倍,當干擾比例為80%時,就已經達到了很好的欺騙防御效果,4 種狀態欺騙方法均只能在訓練的最終階段接近正常訓練時的性能,而對于地址跳變和主機漏洞服務2 種干擾方式,攻擊者在后期也無法成功滲透至目標主機。而當干擾比例為100%時,無論從平均回合獎勵還是平均回合步數來看,攻擊者均不能找到最優的滲透路徑,每個回合均以失敗告終。
對于陷入蜜罐概率而言,圖5(c)、圖6(c)、圖7(c)以及圖8(c)呈現出較一致的變化趨勢。當干擾比例為50%時,4 種狀態欺騙方法的陷入蜜罐概率在8 000 回合左右逐漸降為0;當干擾比例為80%時,陷入蜜罐概率在訓練后期17 000 回合才逐漸降為0;當干擾比例為100%時,陷入蜜罐概率在2 500 回合就已經降為0,這是因為在高干擾比例下,攻擊者一開始就無法滲透成功,從而也不能陷入子網3 中的蜜罐,這也從另一方面驗證了蜜罐部署的防御手段不適合在滲透前期進行這一觀點。
從圖5~圖8 中可以直觀地發現,在不同的干擾比例下不同的狀態欺騙方法擁有不同的優勢。具體而言,當干擾比例在50%以內時,干擾主機操作系統的欺騙方法防御性能最佳;當干擾比例為80%時,干擾主機漏洞服務和主機地址跳變這2 種欺騙方的防御效果最好,在最終回合2 種欺騙方法均使攻擊者無法成功滲透至最終目標主機;當干擾比例為100%時,4 種方法的防御性能相當。此外,相比于主機地址跳變,干擾主機操作系統和漏洞服務的方法更貼近真實滲透場景,可操作性強;而主機地址跳變方法雖然本身具有一定的防御效果,但其需對狀態的前10 維信息均進行置反操作,且難以對干擾后狀態的實際含義進行合理解釋。
綜合上述4 種不同的狀態欺騙防御方法可知,無論是僅干擾一種網絡要素,或是同時對2 種關鍵網絡要素進行干擾,均較難達到以低干擾成本實現完全防御的目的,狀態獲取是攻擊者執行滲透的前期階段,在后續的中期及后期階段同樣也存在受到欺騙的可能,并且不同階段采取不同的欺騙方法也將產生不同的防御效果。
4.4 動作欺騙防御時滲透攻擊性能分析
在滲透攻擊前期和中期,攻擊者獲取到目標網絡的狀態信息后執行實際攻擊動作時,通過擾亂攻擊者動作生成的方式達到欺騙防御的目的。本節以干擾攻擊者采取隨機生成動作和干擾攻擊者采取Q值最小動作的方式在有蜜罐的目標網絡中進行欺騙防御,以4組不同的動作數據干擾比例(20%、50%、80%、100%)進行對比實驗,每組對比實驗均訓練20 000 回合,并以隨機動作的干擾方式作為對照基準。
如圖9 所示,欺騙攻擊者采取隨機動作的方式在干擾比例在50%以內時的防御效果與狀態欺騙防御效果相似,攻擊者以不斷試錯的訓練方式并通過其“自愈”的方法恢復到正常性能。當干擾比例擴大到80%時,其平均回合獎勵和平均回合步數均發生大幅度變化,攻擊者只能在后期找到滲透目標。當干擾比例為100%時,平均回合獎勵在2 000 回合后就開始呈現高負值且不斷波動的狀態,而其平均回合步數居高不下,這反映出攻擊者始終無法找到最優滲透路徑的局面。此外,從陷入蜜罐概率的情況來看,當干擾比例大于80%時,隨機動作的干擾在3 000 回合左右呈現小幅上升的趨勢,此時說明隨機動作的干擾對引誘攻擊者陷入蜜罐起到一定的正向作用。
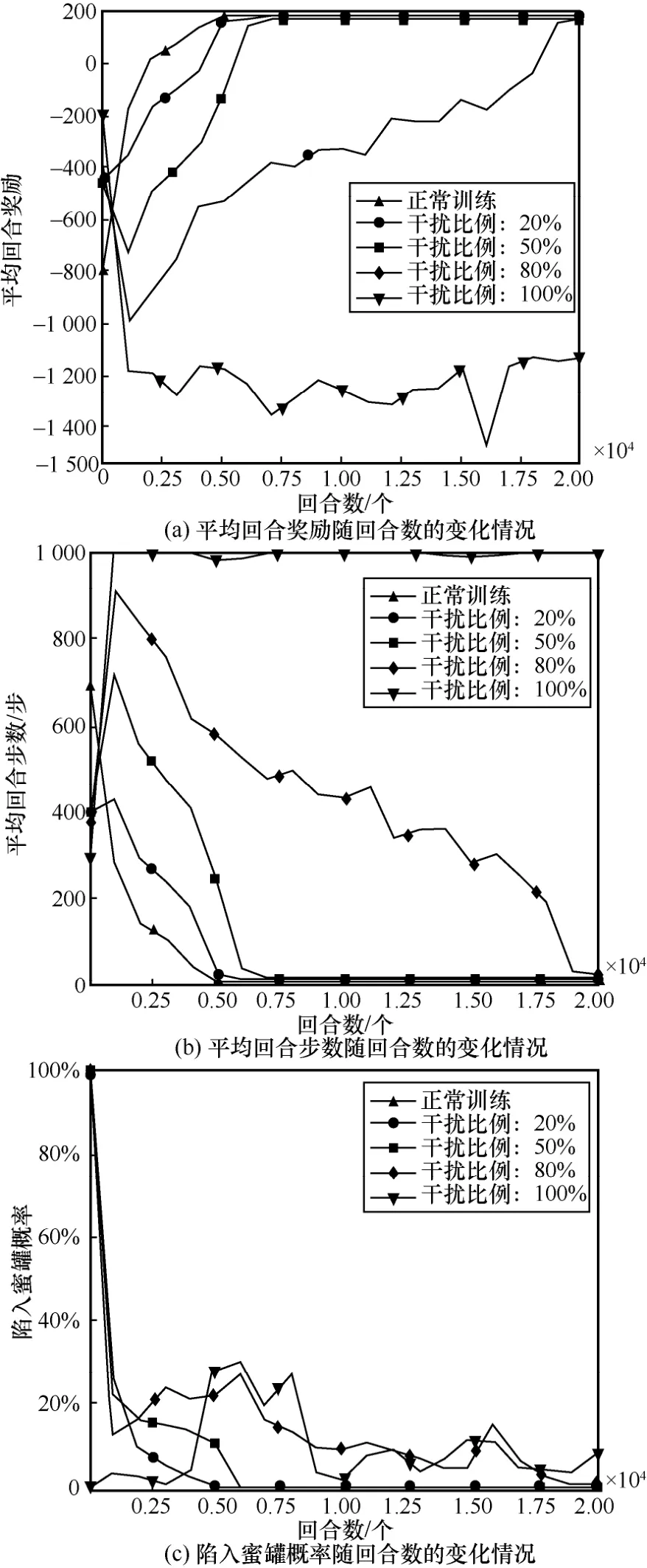
圖9 對攻擊者采取隨機動作進行欺騙防御訓練效果
采用干擾攻擊者選擇Q值最小動作的欺騙防御方法時,如圖10(a)和圖10(b)所示,與之前所采用的攻擊方法呈現出完全不同的結果。首先,當干擾比例在20%時,滲透攻擊成功率已降低為0,此時攻擊者的平均回合獎勵值已為負值,平均回合步數也增加至200 步。其次,隨著干擾比例的增加,平均回合負值獎勵及平均回合步數均在不斷增加,這說明干擾比例越高,欺騙防御攻擊者的效果越好。
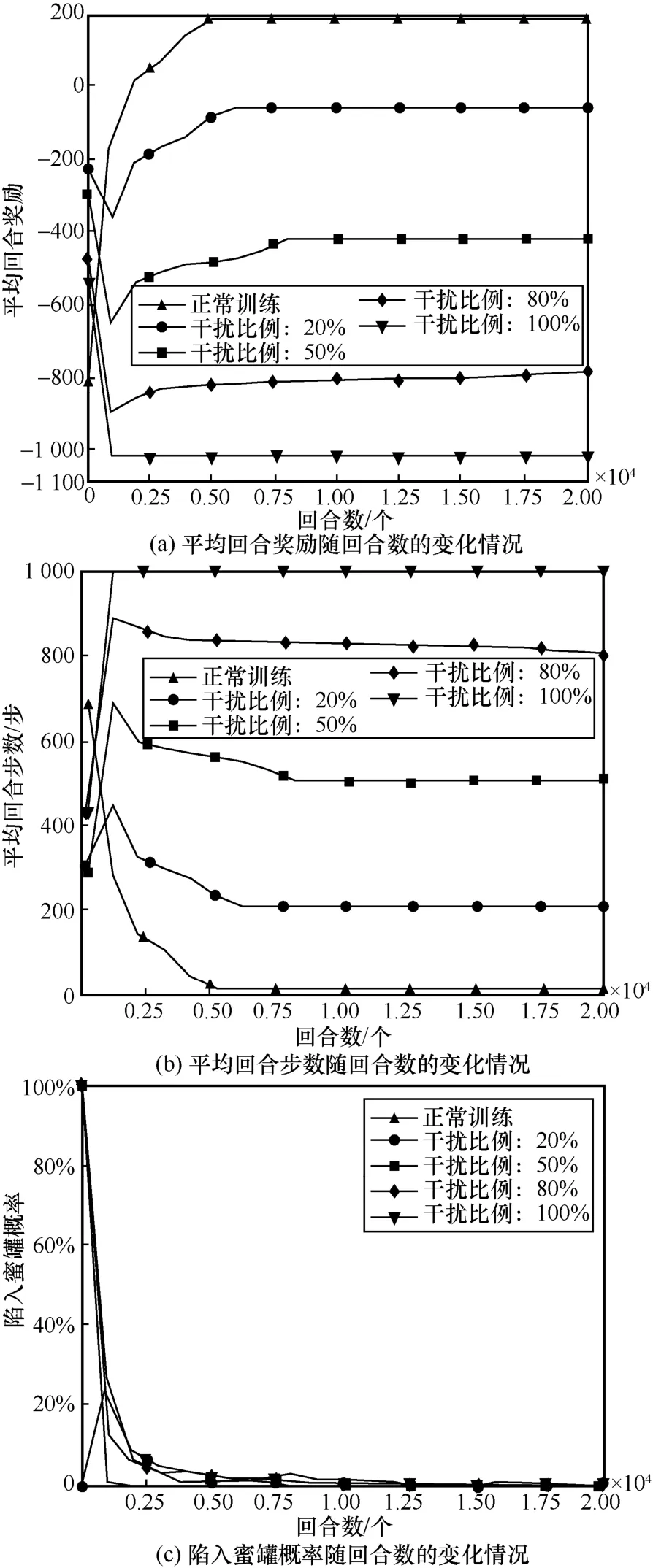
圖10 對攻擊者采取Q 值最小動作進行欺騙防御訓練效果
對于陷入蜜罐概率而言,如圖10(c)所示,4 種不同干擾比例下的陷入蜜罐概率在訓練前期就已全部為0,這并不代表蜜罐的部署沒有效果,而是說明攻擊者在訓練前期就無法執行正常的滲透過程,從而也無法滲透到達蜜罐主機所在的位置。這也說明了干擾攻擊者動作選擇的方式在訓練前期就能達到很好的欺騙防御效果。
總之,在滲透中期通過干擾動作的方式對攻擊者進行欺騙可實現以低成本達到高防御性能的效果,相比于隨機動作的干擾方式,以干擾攻擊者采取Q值最小動作的方式防御性能最好,但該方法的弊端在于需事先獲得攻擊者的訓練模型,也屬于白盒滲透的一種方式。本文繼續在滲透后期以對攻擊目標進行特殊防護的角度展開欺騙防御研究。
4.5 獎勵欺騙防御時滲透攻擊性能分析
本節以獎勵值符號翻轉的方式展開獎勵欺騙防御研究。具體而言,在無蜜罐網絡場景下,將敏感主機的價值由100 修改為-100;在有蜜罐網絡場景下,為了達到訓練攻擊者不斷陷入蜜罐的同時獎勵值不影響模型整體性能的效果,將蜜罐主機的價值修改為200,而敏感主機的價值修改為-200。本節分別在無蜜罐網絡和有蜜罐網絡2 種場景進下行對比實驗,并同樣以4 組不同的獎勵數據干擾比例(20%、50%、80%及100%)進行20 000 回合訓練。
4.5.1 無蜜罐網絡場景獎勵欺騙防御性能分析
針對攻擊者對無蜜罐網絡的滲透過程,本節主要通過修改敏感主機的獎勵值達到保護敏感主機的目的。無蜜罐場景對獎勵數據進行欺騙防御訓練效果如圖11 所示。從圖11 中可以發現,隨著回合數的增加,數據干擾比例越高,攻擊者的平均回合獎勵越小,平均回合步數越高,當干擾比例為80%和100%時,平均回合步數接近最大值1 000。由此可知,干擾比例越大,防御性能越好。
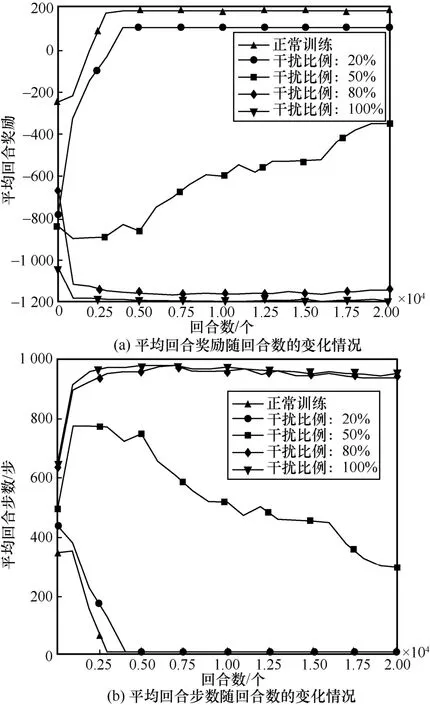
圖11 無蜜罐場景對獎勵數據進行欺騙防御訓練效果
此外,本節還記錄了測試階段的滲透攻擊效果,表3 展示了無蜜罐網絡場景不同干擾比例下的欺騙防御效果。從表3 中可以發現,當數據干擾比例為20%和50%時,攻擊者最終仍可成功滲透敏感主機。當數據干擾比例為80%和100%時,攻擊者即使在達到最大回合步數的情況下,還是無法對敏感主機進行有效滲透。可見,在無蜜罐網絡場景下,通過干擾獎勵數據的方式進行欺騙防御,可以有效擾亂攻擊者策略,增加其時間成本和漏洞利用成本使其策略失效,從而達到欺騙防御目的。
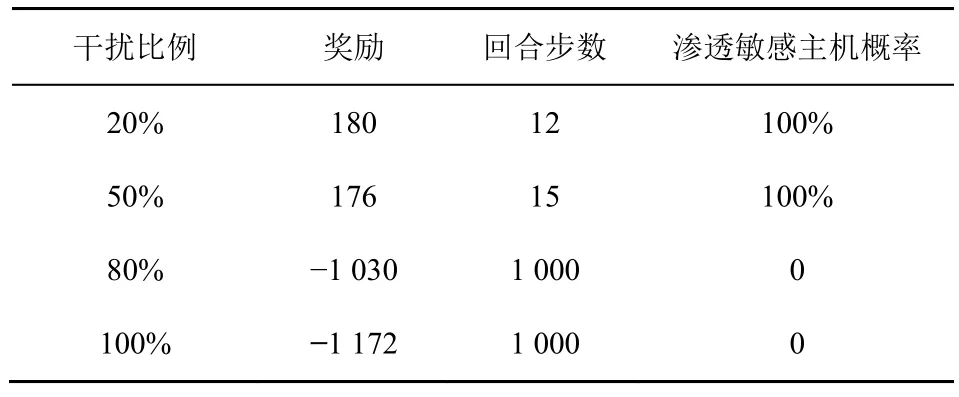
表3 無蜜罐網絡場景不同干擾比例下的欺騙防御效果
4.5.2 有蜜罐網絡場景獎勵欺騙防御性能分析
本節一方面對敏感主機和蜜罐主機的獎勵值進行修改,將蜜罐主機的獎勵值設為200 偽裝成敏感主機;另一方面將結束條件修改為獲得蜜罐主機的User 權限或回合步數達到最大值。圖12 展示了有蜜罐網絡對獎勵數據進行欺騙防御訓練效果。比較圖11 與圖12 的蜜罐網絡訓練效果可發現,在獎勵欺騙過程中,攻擊者滲透效果與正常滲透效果相差較小。此外,數據干擾比例越大,攻擊者最終的獎勵值越大。這是由于干擾比例越大,攻擊者陷入蜜罐概率越大,且步數越來越短,消耗的成本代價減小,使最終的獎勵值變大,欺騙防御效果越好。但該方法的不足之處在于需提前獲得敏感主機和蜜罐的地址,而不是利用主動探測或其他手段將這兩類主機進行區分。
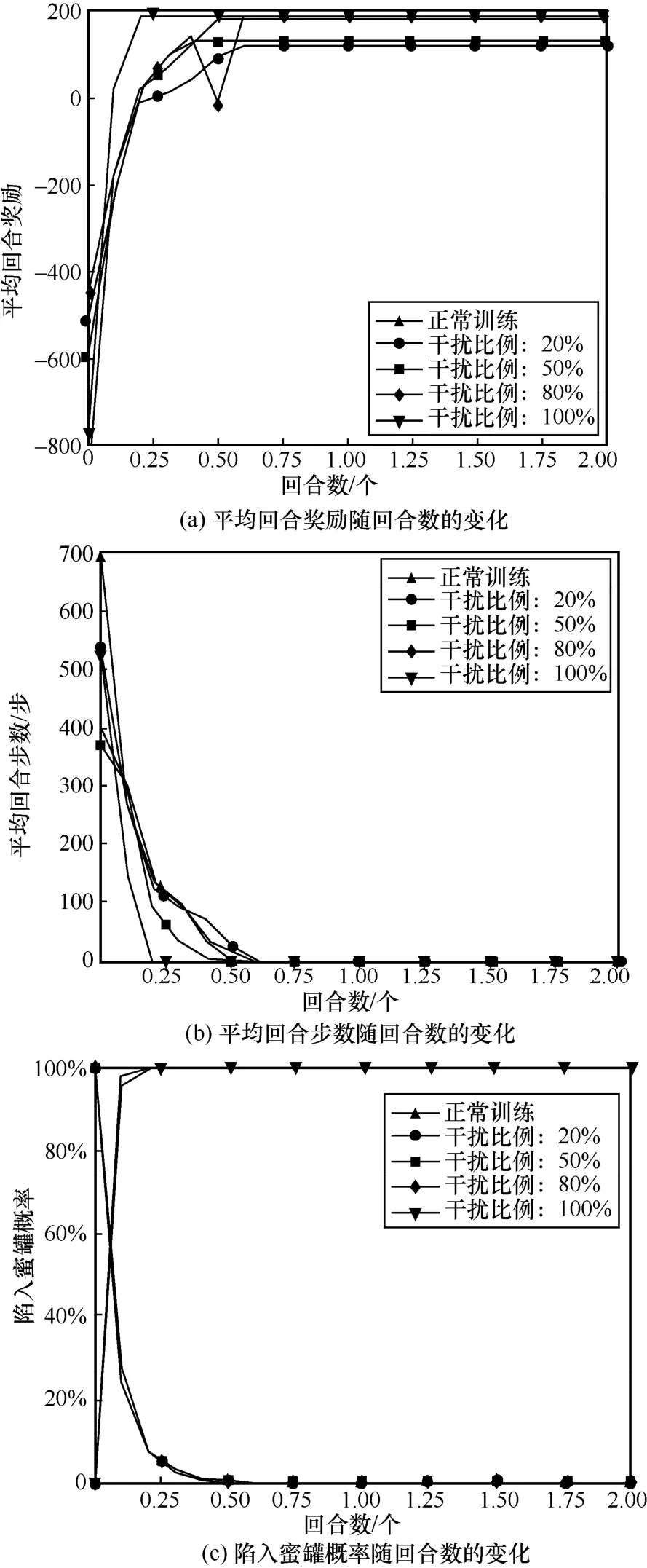
圖12 有蜜罐網絡對獎勵數據進行欺騙防御訓練效果
從圖12(c)可以發現,除了數據干擾比例為20%的攻擊者最終能躲過蜜罐主機的迷惑,其他干擾比例下攻擊者都把蜜罐主機作為網絡中的脆弱節點進行滲透,進而陷入其中。
表4 展示了有蜜罐網絡場景不同干擾比例下的欺騙防御效果。從表4 中可以發現,在測試過程中,當干擾比例為50%、80%和100%時,攻擊者由于在欺騙防御后能很快地找到蜜罐主機,從而回合步數基本很短,并且最終經過欺騙防御后的策略100%的偏向于陷入蜜罐主機,與正常滲透的趨勢吻合。與表3 相比,有蜜罐網絡中干擾比例為50%時就能達到欺騙防御攻擊的目的,比無蜜罐網絡中的防御效果更好。

表4 有蜜罐網絡場景不同干擾比例下的欺騙防御效果
5 結束語
本文對基于強化學習的智能滲透攻擊進行欺騙防御研究,分別從攻擊者的狀態、動作及獎勵3 個角度出發,對應于滲透攻擊的前期、中期及后期3 個階段展開實驗分析。針對無蜜罐和有蜜罐的不同目標網絡場景,本文首先基于強化學習實現智能滲透攻擊。其次,通過修改攻擊者狀態、動作及獎勵訓練數據的方式來對攻擊者進行欺騙防御。最后,通過實驗證明在智能滲透攻擊過程中利用污染強化學習模型訓練數據的思路,可對攻擊者達到很好的欺騙防御效果,其中,干擾攻擊者動作生成和修改不同主機獎勵值的防御方法的防御性能最顯著。
猜你喜歡
作文周刊·小學一年級版(2022年16期)2022-05-07 11:28:30
作文周刊·小學一年級版(2021年8期)2021-07-07 11:00:47
動漫界·幼教365(大班)(2021年4期)2021-05-23 21:33:16
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文周刊·小學一年級版(2016年28期)2017-06-03 00:28:49
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
少兒科學周刊·少年版(2015年4期)2015-07-07 20:56:37
電影故事(2015年30期)2015-02-27 09:03:12
七彩語文·低年級(2014年10期)2015-01-14 14:46:27
