一種穩定的2D骨骼捕捉策略及摔倒檢測方法*
2023-01-10 03:25:24陳文軒郭植星
機電工程技術 2022年12期
陳文軒,曾 碧,郭植星
(廣東工業大學計算機學院,廣州 510006)
0 引言
根據數據顯示,我國老年人口預計到2025年將達到2.8億左右,約占全國總人口的19.3%。到21世紀中葉,65周歲以上的老年人口將接近峰值,老年人口達到4.83億,占全國總人口比重將達到34.1%,屆時我國老年人口將占到亞洲老年人口的40%[1]。隨著人口老齡化現象不斷加劇,用于服務老年人的公共設施的數量和規模將不再能滿足社會的需求。老年人身體機能差,平衡能力不強,應變能力弱,就容易出現摔倒的情況,而老年人骨骼就像玻璃般脆弱,一旦摔碎,再難粘合恢復,從而引起嚴重后果[2]。
在過去20年間,一直都有學者在研究跌倒檢測方法。國內外摔倒檢測方法分3類:基于環境傳感器的方法、基于視頻的方法及基于可穿戴傳感器的方法。基于環境的方法[3]有侵犯性小、算法效率高和實時性好的優點,但缺點也相當明顯,它難以判定掉落的是人還是物體,導致誤判率非常高,且場地需要有一整套完整的部署,造價昂貴,限制比較大,難以普及到大多數人的家庭中。基于穿戴式的摔倒傳感器[4-6]容易對使用者造成不便,而且傳感器的電源供應也有局限,導致老人并不喜歡佩戴該類傳感器。基于視覺的方法有更好的研究前景,在于它全自動、普適性強且視頻流能提供更多的場景信息。而在基于視覺的方法中,將RGB圖像[7]作為輸入的方法需要依靠深度網絡學習排除圖像中的冗余信息而導致模型規模較大,模型算力需求大而在現實中無法達到實時性;基于RGBD的方法需要特殊的深度傳感器設備,成本較高;基于光流法需要基于前后兩幀圖像計算稠密光流圖像,這個過程就會消耗大量的時間,在現實中也并不具有實用性。Johansson[8]在生物學觀察中表明,即使缺乏外觀信息,人類也能夠從人體幾個關節連續的運動中識別出不同的動作。這是因為在人的主觀視角中,人體骨骼是一種簡潔的數據形式,且序列化的骨骼數據也能較好地描述人的動態變化信息。骨骼數據是所有人體內所有關鍵關節的三維坐標,其可以通過不同的姿態估計方法從多幀圖像或直接由Kinect等傳感器采集得到,時效性好,因此基于骨骼點的摔倒檢測方法具有良好的應用前景。
但目前公開的摔倒數據集大多沒有骨骼點數據,而且視頻中存在多人走動、背景復雜等干擾因素,需要摔倒領域的研究者付出大量的人力成本才能標注好。再者目前基于骨骼點的摔倒檢測算法并沒有較好的邏輯鏈條,如Yin Zheng[9]和衛少潔[10]都使用目標檢測與姿態估計方法對現實場景中的人物進行骨骼提取,獲取一段骨骼序列后輸入到不同的判別模型進行判別。Yin Zheng[9]使用ST-GCN圖卷積模型,而衛少潔[10]使用的是LSTM對摔倒行為進行判別,雖說這些方法能在公開數據集上得到很好的效果,但都僅針對判別模型進行改進,都沒有考慮目標檢測與目標跟蹤對骨骼提取的穩定性問題。上述兩個問題都會導致在摔倒數據集上訓練的算法系統難以泛化到現實世界中。
本文主要研究解決如何將基于摔倒數據集訓練出來的模型,能確切地應用在現實世界的問題:(1)為減少研究者在標注過程中的人力成本,本文提出了一種骨骼捕捉策略,它利用單目標跟蹤算法與目標檢測相結合,自動捕捉場景中人物骨骼點,從而穩定有效地提取出可用的訓練骨骼點,使得后續的模型訓練更加有效;(2)針對現有摔倒檢測系統存在的缺點,本文提出一種優化的摔倒檢測方法,它利用SORT多目標跟蹤算法跟蹤姿態估計方法生成的BoundingBox,并采用閾值法消取多余的骨骼點,該方法不僅有較好的時效性,且能提高整體的摔倒檢測系統的穩定性,降低系統誤判率。
1 相關工作
目前所有針對摔倒行為的公開數據集并無骨骼點數據。較大規模的摔倒數據集,如Le2i Fall Dataset、UP Fall Dataset、Multiple Cameras Fall Datasets等[11-13],除了UP Fall數據集會有一些加速度傳感器或光流圖像數據其他都只是視頻流數據。而骨骼點坐標數據有2D或3D。一般來說2D姿態的質量優于3D姿態。如圖1所示,圖1(a)中是HRNet[14]估計的2D姿勢可視化。顯然,它們的質量比圖1(b)所示的Kinect傳感器收集的3D姿態估計要好得多。因此主要使用與現實任務關鍵點匹配度較高的2D姿態估計算法來將摔倒數據集轉換為骨骼點坐標。

圖1 2D與3D可視化骨骼對比圖
姿態估計算法分為兩類,一種是自頂向下,較好的算法是CPN[15]和HR_Net,算法的大概邏輯是先檢測畫面中的所有人物,將每一個BoundingBox中的圖片輸入到單人姿態估計網絡中進行估計。另一種是自下而上,較好的代表是Openpose[16],算法邏輯是檢測畫面中所有的關節點,再使用匈牙利算法等聚類算法進行最優匹配。
摔倒數據集中的視頻流數據會有不同程度的干擾問題。如Multiple Cameras Fall數據集數據集擁有8個不同的視角,為反映真實的生活狀態,視頻中會有背景復雜、目標遮擋、目標尺度過小等難點。而Le2i Fall數據集和UP Fall數據集中有多人走動、背景陰暗、動作執行者缺失等難點。如圖2所示。這是從UP Fall數據集中截取正向視角與側面視角的幾幀圖像,展示一個人模擬摔倒的全過程。正向視角中出現了一個坐著的人,而側面視角的玻璃外面有一個行走的人,他們的行為都并不符合當前幀動作執行者的標簽。如果僅用姿態估計算法進行骨骼提取,會污染訓練數據并且難以進行篩選。

圖2 UP Fall數據摔倒視頻部分截圖
摔倒判別系統有基于光流法[17-18]或基于深度圖像[19]的方法,但它們受到環境中的光照或移動的物品影響較大,且相對于基于骨骼點的摔倒檢測系統不夠魯棒或達不到時效性。一般基于2D人體姿態骨骼點的摔倒判別系統框架主要分成4個部分,分別是檢測、跟蹤、姿態估計以及摔倒檢測。分類模型可以是傳統的SVM[21]或者LSTM。算法邏輯是先用目標檢測檢測環境中的人物,再用單目標或多目標追蹤算法累積骨骼序列,最后進行分類判斷。基于實時性考慮,目標檢測算法會選擇單階段的YOLO系列的算法。出于在實際家庭場景中多于兩個人的情況較多,即便單目標跟蹤能力要好于多目標跟蹤法也并不適用于現實。此時這個摔倒系統在現實應用時極容易因為目標檢測算法的不穩定而丟失跟蹤,導致后續的判別模型無效。因為如今深度學習的模型在追求速度的前提下就會損失一定的精度。圖3所示為YOLOv5[21]和MiniYOLOv3[22]目標檢測算法對UP Fall數據集的人物檢測結果顯示,可以看到第26幀側視角畫面出現了誤檢的情況,對比后兩幀正視角的連續畫面,雖然兩者都沒有誤檢或漏檢,但YOLOv5對于檢測人物邊界的精確度要遠高于MiniYOLOv3且MiniYOLOv3對后兩連續幀檢測的BoundingBox形變較為嚴重。這種情況容易導致跟蹤算法丟失追蹤目標,出現頻繁切換運動目標ID的情況,進一步影響整體系統對摔倒系統的判斷。但YOLOv5的高精度源于其大參數模型,它的速度遠不如MiniYOLOv3高。因此本文針對上述問題提出了一種骨骼捕捉策略以及摔倒檢測方法。這兩個方法都能使摔倒系統能更好地應用在現實世界中

圖3 YOLO目標檢測算法對比圖
2 本文算法
2.1 骨骼捕捉策略
骨骼捕捉策略使用的是自頂向下的HRNet方法。基于以下幾點原因,第一是自下而上的姿態估計算法依靠聚類算法去劃分關節點,當目標顯示不完全或兩個多人目標重疊的時候,提取到的骨骼數容易缺失或錯亂,無法轉換為有效的訓練數據;第二是目前SOTA算法中自下而上的姿態估計算法并無自頂向下的姿態估計算法精度高。為了獲得置信度更高且精確的骨骼坐標數據,本文使用的是自頂向下的姿態估計算法。針對視頻中的多人走動、動作者不在畫面中、遮擋或背景陰暗的問題,本文的骨骼捕捉策略引入了RiamRPN++[23]單目標追蹤算法。整體算法流程的描述如下:遍歷每一個數據集的動作視頻,人工框選動作執行者出現的第一幀畫面,利用單目標跟蹤算法對其進行跟蹤并輸入到姿態估計算法中,這樣就可以過濾掉多余的人,篩選出主要的動作執行者。但在Multiple cameras Fall數據集中拍攝的場景比較復雜,UP Fall數據集動作執行者速度較快,這些情況都容易導致單目標跟蹤算法丟失目標,難以重捕獲跟蹤目標導致轉換出錯誤的骨骼數據污染訓練數據。因此本文引入目標檢測算法,利用目標檢測得到的目標預測框不斷糾正單目標算法的跟蹤區域。當目標檢測框與單目標跟蹤框的IOU重合在[0.8,0.9]的區間內時,對單目標跟蹤框進行修正,使得跟蹤更加穩定。當動作執行者消失在畫面中時,提取到的骨骼點整體均值會小于0.3且無IOU重合度高的檢測框,此時應當拋棄當前幀的骨骼數據。整體骨骼捕捉策略流程如圖4所示。
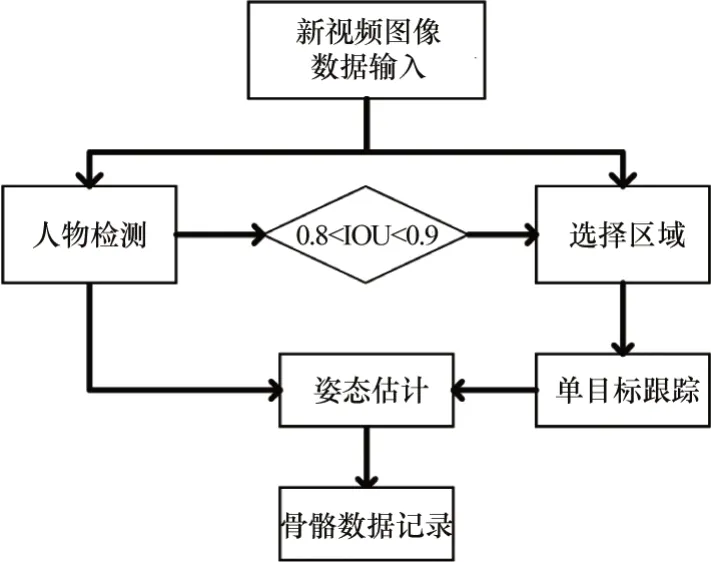
圖4 骨骼捕捉策略流程
2.2 摔倒檢測優化方法
摔倒檢測系統優化框架分兩部分,數據預處理優化及系統邏輯優化。在數據預處理部分,要想在現實世界中達到更好的泛化性,就需要引入大量的數據訓練。但不同的摔倒數據集中標簽和標注的方式并不統一。這就需要對標簽進行重標注,而重標注需要選擇合適的方式。Le2i Fall數據集只對摔倒的開始幀和結束幀作了編號。Multiple Cameras Fall數據集用數字1~9分別代表了Falling、Lying on the ground、Crounching、Moving down、Moving up、Sitting、Lying on a sofa以及Moving horizontaly這9種標簽,數據集對每一幀圖像都標上了數字。而UP Fall數據集中則將摔倒分成了5種類型,分別用數字1~11代 表Falling forward using hands、Falling forward using knees、Falling backwards、Falling sideward、Falling sitting in empty chair、Walking、Standing、Sitting、Picking up an object、Jumping、Laying共11種標簽,但數據集作者在錄制時限制了每個志愿者做的每個動作視頻在10~60 s以內,并對整個視頻標注為當前的動作的數字。圖2UP Fall數據集中的第1幀中志愿者是站立狀態,在第17幀開始有向前傾的動作,在47幀時已經完全躺在保護墊上并維持躺倒姿勢直到視頻結束的172幀。摔倒動作發生在一瞬間,僅持續了大概30幀的時間。如果標注方式如UP Fall數據集那樣將整個10 s視頻都納入摔倒標簽中,容易和躺倒的動作混淆,因此本文基于現實應用的考慮采取了Multiple Cameras Fall的標注方式,對每一幀圖像都標上一個動作標簽,人為判斷每個動作之間分離的界限。摔倒檢測的任務集中在識別摔倒行為而非區分眾多不同的動作。因此本文結合了三個數據集的動作標簽描述,在重標注數據集的時候將其簡單概括為7類(分別對應數字1~7),Standing、Sitting、Falling down、Waliking、Standing、Sitting、Lying down。例如Le2i Fall數據集中目標對象展示是一個掃地的動作,就可以使用Walking或者Standing替代。UP Fall數據集中摔倒視頻的后半段就會換成Lying標簽。標注實例如圖5所示。
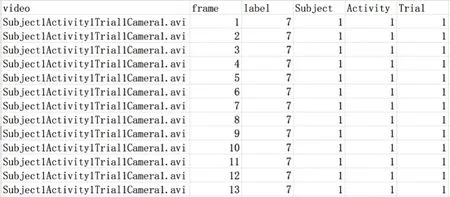
圖5 UP Fall數據集重標注示例
姿態估計算法會因為畫面中遮蔽或光線等因素而對當前關節點的準確度進行評估,得到置信度Ci。現實中對一個動作是否發生的判斷也應當是一個概率值。因此置信度較差的骨骼點難以作為判斷動作的有效依據,因此需要減少錯誤骨骼點對整體算法框架的影響。將標簽乘上當前幀所有骨骼點的置信度平均值,使得標簽值成為會根據姿態估計得到的可信度進行調整的概率值。計算過程如下式所示:

式中:Ctave為t時刻下所有骨骼置信度的平均值,融合到t時刻下的Labelt并使其成為一個概率值。
不同的數據集的視頻畫面分辨率不同,如UP Fall數據集是640×480,而Le2i Fall數據集是320×240。姿態估計算法得到的是骨骼點在像素坐標系下的位置。需要將骨骼點數據除以視頻幀的長度和寬度,縮放到基于數據集視頻幀的相對大小。此時需要進一步消除人物在不同位置做動作帶來的誤差。以每幀所有骨骼點為單位作Max-Min歸一化:

式中:xmax、xmin為單幀中最大、最小的關節點數據,
一般基于骨骼的動作識別算法,如文獻[24],使用的是公開的NTU120[25]數據集。雖說NTU120數據集對于每一類動作的數據收集并無統一時間序列長度,但為了統一輸入數據維度,多數基于骨骼的動作識別文獻會以300幀(若不足300則填充0~300)作為時間維度的長度,然后選擇其中的關鍵幀確立為更加短的時間維度長度。本文主要任務是檢測摔倒行為,它是一種短暫甚至是瞬時發生的行為。本文使用的數據集是設定攝像機在18~30 fps,在標注所有數據集的過程中,本文總結出了發生一次摔倒行為的視頻中可供標注的畫面在30~75幀(取決于攝像機的幀率)。因此可以斷定摔倒行為的持續時長約在1~2.5 s,它可以簡單概括為向下傾斜、倒下以及完全躺倒3個狀態。參考目前家庭監控攝像機多在25 fps以及摔倒行為持續的時長。本文選擇將一次動作的判斷定義在30幀,并參考文獻[10]采取窗口滑動法提取用于后續訓練的骨骼序列樣本。窗口滑動法如圖6所示。其中size大小為30。窗口沿幀順序方向滑動一個單位即可獲得一個訓練樣本Xi以及對應標簽Li,其中Xi由30個連續幀的14個骨骼點的x坐標、y坐標以及骨骼置信度組成,Li則是融入骨骼置信度的標簽。
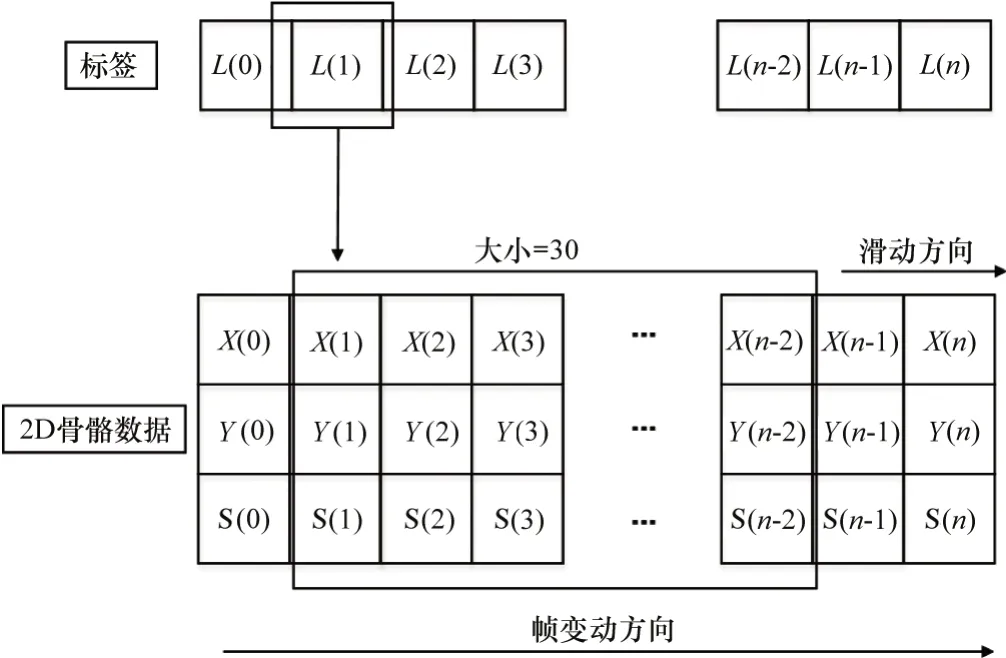
圖6 訓練樣本處理
摔倒檢測系統優化方法的整體流程如圖7所示。多目標跟蹤算法為SORT[26],它是2016年中多目標跟蹤領域的SOTA方法。它沒有使用深度學習,但有極為良好跟蹤效果且能達到很高的時效性。針對圖3中第26幀中誤檢的問題,如果只是單幀出現,則不會被追蹤算法分配ID,更不會集滿30幀連續骨骼數據并輸入到摔倒檢測網絡中,但如果在家庭中出現連續超過30幀誤檢時,不僅占據內存還會提高系統的誤判率,一直觸發警報。因此本文使用了閾值法對提取到的骨骼置信度進行篩選,計算姿態估計算法提取的骨骼點的置信度均值,如果骨骼點的置信度均值連續20幀小于0.35,則將其ID標記FalseSkeleton,不輸入到最后的判斷中。針對圖3第27、28幀前后形變嚴重的問題,因為姿態估計算法得到的骨骼點形成的外邊框比目標檢測的BoundingBox變化更小更穩定,因此本文利用多目標跟蹤算法跟蹤人體姿態估計生成的人體框。
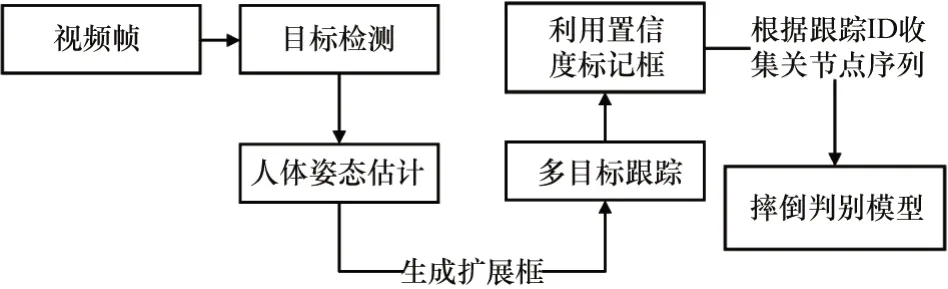
圖7 摔倒檢測優化方法流程圖
3 實驗
3.1 實驗設置
本文的實驗環境是將GTX2080Ti 11G獨立顯卡作為訓練設備和骨骼提取設備,而摔倒檢測算法的測試設備為Intel Core i5-6300HQ 2.3GHz處理器與GTX1060 6GB獨立顯卡的筆記本電腦。摔倒檢測算法的實驗模型LSTM是基于上述捕捉骨骼策略提取的所有摔倒骨骼數據集進行訓練。將整體3個數據集按8:2比例分成訓練集和測試集。模型訓練批次大小為256,初始學習率設置為1×10-4,訓練80輪,在第20輪與第40輪微調學習率為原來的0.5倍,使用Adam優化梯度下降,權重衰減1×10-4,其余采用默認參數。
3.2 實驗分析
對骨骼捕捉策略進行實驗,實驗效果如圖8所示。綠色框是RiamRPN++單目標跟蹤框,為了跟蹤算法能更穩定地跟蹤目標,人工框的區域應該盡量小。因為姿態估計算法需要較為完整的人物圖像輸入才會有更好的結果,因此采用基于跟蹤框延伸的紅色擴展框作為姿態估計算法的輸入數據,綠色框僅作跟蹤使用。藍色框為YOLOv5的目標檢測算法的檢測框。當檢測框與擴展框的IOU在0.8~0.9區間時,就會使用檢測框為跟蹤框進行修正。當IOU大于0.9時,選擇目標檢測算法作為姿態估計算法的輸入,當檢測框沒有或者其小于0.8時,則使用擴展框作為姿態估計算法的輸入,起到互補的作用。這樣一方面可以過濾掉場景中的其他檢測框,另一方面可以糾正單目標跟蹤算法的跟蹤軌跡,使輸入到HRnet姿態估計算法中的畫面更適合,從而提取更適用的骨骼數據。從圖8第一行視角也可以看到追蹤算法始終穩定地跟蹤著動作執行者,而且圖8中第一行全部幀以及Frame126與Frame127背景都出現了額外的目標,但并無提取出多余動作者的骨骼點。當第二行Frame159運動目標消失在畫面時,目標跟蹤框依舊在提取骨骼點,但畫面右上角顯示出骨骼的平均為0.213 8且并無高IOU的檢測框,此時并不會存儲到訓練數據中。當Frame197重新出現運動目標時,單目標跟蹤算法會重新捕捉并追蹤。實驗效果表明骨骼捕捉策略可提取較高質量的骨骼數據,減少大量的人工標注成本。
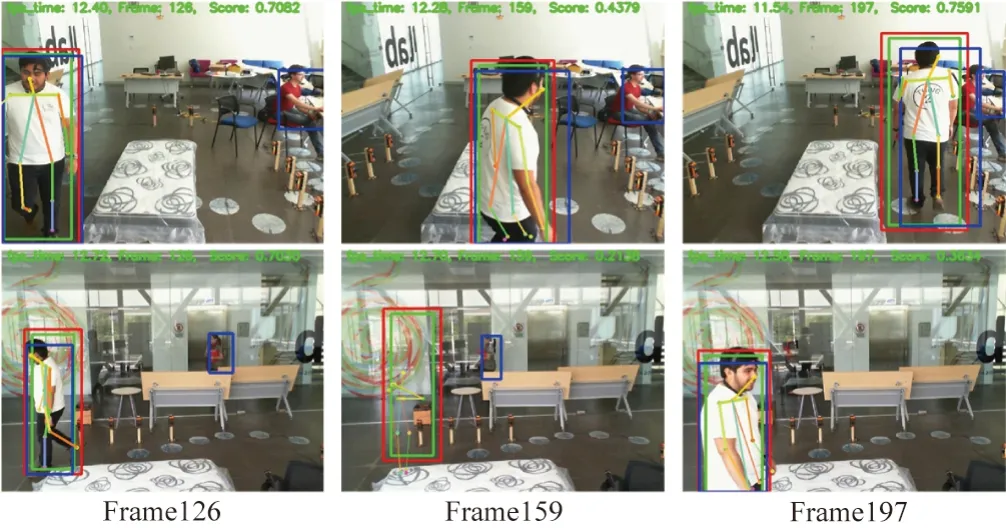
圖8 RiamRPN+Yolo骨骼數據提取效果圖
對摔倒檢測優化框架中的系統邏輯優化進行效果實驗對比,實驗效果如圖9所示。本文將同一個視頻輸入到經過摔倒檢測優化框架(第一行)以及沒有經過優化框架的摔倒檢測系統(第二行)進行測試。從第144幀、204幀和第214幀可以看到,第一行與第二行人物的Bounding Box都不相同。優化策略的Bounding Box要比Yolo檢測框小且變化是更加穩定的,這是因為優化策略的Bounding Box是基于骨骼點向外延伸。檢測框更小的變化更有利于跟蹤。從后面144幀摔倒到295幀的完全站立可看到,優化策略一直捕捉到跟蹤目標并穩定分配為ID2。而普通策略在260幀中已丟失了原來的ID4,并在295幀開始重新分配了ID5。雖然從204幀中多目標跟蹤算法跟蹤了YOLOv3誤檢的環境中的凳子,使得第一行和第二行所分配的ID都不是從1開始。但從144幀開始,普通策略的系統對凳子和人物的ID分配已經歷多次的變化。這是因為優化策略可繼續對凳子進行跟蹤并對低置信度的骨骼點進行FalseSkeleton的標記,從而不會輸送到后續的動作判斷模型中。此實驗說明本文的摔倒檢測優化方法可以不犧牲算力的前提下使得摔倒檢測系統對目標的跟蹤更穩定,使得誤判率更低。

圖9 摔倒優化框架(第一行)及非優化框架(第二行)對比效果圖
圖9同樣是對經過摔倒檢測優化框架中的數據預處理的實驗效果對比。本文的研究目的并非是摔倒檢測模型,因此只選擇了簡單的3層LSTM模型進行訓練。模型對數據集的測試集精度達到了93%。可以看到在模型很好地學習到了本文基于骨骼捕捉策略所獲得的較高質量的數據集,并能在現實視頻中很好地檢測出人物的動作。如144幀中的Fall Down,204、214、260的up(第一行中因丟失目標而失去up動作判斷)以及295幀的walking動作。在顯示黑框中,動作可視化后面都是模型輸出對于當前動作的概率值,如第二行的260幀與295幀,因為當前幀提取到的骨骼點置信度較高,模型對其動作概率值判斷約65%和78%。這樣更加貼合現實的邏輯。
4 結束語
為了將在摔倒數據集上訓練的老人摔倒檢測系統能更好地泛化到現實世界中,本文提出了一種骨骼捕捉策略,經試驗效果顯示,它能過濾摔倒數據集的干擾,并提取出適合訓練的骨骼數據,可以大幅度減少標注者的工作量。為了進一步使得摔倒檢測系統能更適用于現實世界,本文還介紹了一種摔倒檢測優化方法,它包括數據預處理優化及系統邏輯優化。經實驗對比驗證,基于數據預處理優化策略訓練的LSTM模型,在邏輯優化的系統中能準確識別自拍攝的測試視頻,在GTX1060顯卡中達到約45 fps,模型的準確率達到93%。優化檢測方法不僅提高整體系統的穩定性,還降低系統誤判率。本論文的工作離部署到邊緣設備上還有一定的距離,因此未來的工作中需要在保證摔倒系統各部分精度的前提下進行更加輕量化的實驗,以更低的算力成本植入到嵌入式設備中。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
小學生作文(低年級適用)(2018年3期)2018-04-17 00:58:35
少年博覽·小學低年級(2017年4期)2017-06-09 16:22:28
作文評點報·低幼版(2017年7期)2017-03-11 20:49:41
