融合時間和地理信息的興趣點推薦研究
2023-01-11 00:43:02李建波呂志強董傳浩
復雜系統(tǒng)與復雜性科學 2022年4期
趙 薇,李建波,呂志強,董傳浩
(青島大學計算機科學技術學院,山東 青島 266071)
0 引言
隨著智能手機和平板電腦等帶GPS定位的移動終端設備的普及,位置社交網絡(Location-Based Social Network,LBSN)得到了快速發(fā)展,用戶可以輕松地獲取已訪問興趣點的地理信息,并進行實時簽到。由此產生了海量的簽到數(shù)據(jù),引起了學者的廣泛關注[1-5]。如何從海量的簽到數(shù)據(jù)中篩選出用戶感興趣的內容是一個值得研究的問題。對于興趣點推薦的研究則可以解決這一難題。興趣點推薦是一項致力于從大量的候選位置中為用戶推薦滿足其訪問需求的興趣點的研究,它既可以幫助用戶制定合理的出行計劃,探索未知的地理區(qū)域;也可以幫助商家向潛在的用戶提供個性化服務,提高其營業(yè)收入;同時可以讓政府提前進行交通規(guī)劃,避免出行高峰期造成的道路阻塞。
現(xiàn)階段,關于興趣點推薦的研究主要是根據(jù)歷史簽到數(shù)據(jù),挖掘用戶潛在的移動模式,模擬用戶訪問下一個地點的決策過程,達到為用戶推薦滿足其訪問要求的興趣點的目的[6]。不同于傳統(tǒng)的推薦任務,興趣點推薦是一個融合時間和地理信息的推薦。例如,用戶在每天早晨8點去早餐店吃早餐,在工作日下午3點去咖啡店買咖啡,在每周日晚上7點和朋友去電影院看電影。對于即將到來的一天,如何為用戶合理地安排行程,推薦其感興趣的地點。這時的興趣點推薦任務一定是融合時間和地理信息的推薦。
在融合時間信息的興趣點推薦工作中,He等[7]認為用戶與興趣點交互的時間戳是有規(guī)律的,它不僅是用戶訪問興趣點的時間節(jié)點,還隱藏著用戶訪問行為的周期性特征。因此,時間信息在興趣點推薦中起著重要作用[8]。Zhao等[9]通過門控機制來捕獲兩個相鄰興趣點之間的訪問時間間隔。Feng等[10]提出注意力機制來捕獲具有周期性特征的時間信息。另外,在融合地理信息的興趣點推薦工作中,考慮到興趣點之間的距離,Cheng等[11]將地理信息作為一種區(qū)域約束,結合馬爾可夫鏈,提出了FPMC-LR模型。Sun等[12]提出了一個針對短期建模的地理空洞循環(huán)神經網絡模型,該模型解決了已訪問興趣點在地理上分散的問題。Lian等[13]通過用戶訪問興趣點的地理信息來捕捉用戶訪問行為的空間聚類現(xiàn)象。
綜上所述,現(xiàn)有方法在一定程度上提高了興趣點推薦準確率,但忽略了時間和地理信息之間的關系。雖然按時間周期對簽到記錄進行了劃分,但忽略了不同時間用戶訪問行為受地點距離約束程度的差異性。例如,工作日用戶的訪問行為受區(qū)域限制較大,訪問地點受距離約束嚴重;節(jié)假日用戶的訪問行為相對自由,訪問的地點受距離約束程度相對較輕,訪問的地點更具有隨機性。
針對上述問題,本文對簽到數(shù)據(jù)進行了工作日和節(jié)假日的劃分,提出了一種融合時間和地理信息的興趣點推薦模型。該模型主要分為兩個部分:一是利用長短期記憶網絡(Long Short-Term Memory,LSTM)提取當前軌跡中序列特征的時空關系模塊;二是學習歷史軌跡中地理信息的地理關系模塊。在地理關系模塊中,利用卷積神經網絡捕獲用戶的局部地理偏好;根據(jù)用戶之間的訪問相似度,生成關于地理位置的評分矩陣。融合上述兩部分,獲得用戶下一步訪問興趣點的推薦意見。
1 預備知識
1.1 興趣點推薦
興趣點推薦被認為是推薦領域中的一個重要任務。與傳統(tǒng)的電影、音樂、新聞等推薦任務不同,興趣點推薦需要用戶去訪問物理世界中真實存在的地點,因此推薦難度更大。在基于傳統(tǒng)方法的研究中,協(xié)同過濾算法是被普遍認可的[14-16]。Ye等[17]基于用戶的協(xié)同過濾框架,采用線性插值的方法,結合地理與社會影響進行興趣點推薦。夏英等[18]先通過協(xié)同過濾算法模擬用戶的社交關系,然后通過加權矩陣分解學習地理信息,進而將兩者融合進行興趣點推薦。另外,由于簽到數(shù)據(jù)是連續(xù)的序列數(shù)據(jù),因此采用馬爾可夫鏈也可以很好地計算簽到序列之間的轉移概率。
近年來,深度學習的發(fā)展極大地推動了興趣點推薦的研究。針對簽到數(shù)據(jù)的特點,循環(huán)神經網絡(Recurrent Neural Network,RNN)及其變體(LSTM、GRU)在興趣點推薦領域的應用十分廣泛。Zhong等[19]利用LSTM基于流行度和社交網絡進行興趣點推薦。Liu等[20]利用GRU基于類別感知進行推薦工作。Liu等[21]擴張了RNN,使用時間轉移矩陣和距離轉移矩陣來分別捕獲時空上下文信息,并采用線性插值的方法緩解數(shù)據(jù)稀疏帶來的影響。另外,卷積神經網絡(Convolutional Neural Network,CNN)既可以從評論內容中獲取語義和情感信息[22],也可以從最相似的友誼關系圖中提取特征[23],因此在興趣點推薦中得到了廣泛應用。
1.2 興趣點推薦問題定義
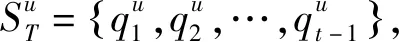
2 融合時間和地理信息的興趣點推薦模型
圖1展示了所提模型的總體架構,它主要由時空關系模塊、地理關系模塊和預測模塊三部分組成。
2.1 時空關系模塊
當前軌跡中的序列信息(位置、時間)反映了用戶最近一段時間內的興趣偏好,直接影響用戶下一步的決策過程。因此,將當前軌跡中的不同信息通過嵌入學習,映射成對應的嵌入向量。然后,將時空嵌入向量進行連接,利用LSTM學習當前軌跡中的時空轉換規(guī)律。計算公式為
(1)
ht=LSTM(elt,ht-1)
(2)
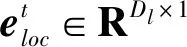
2.2 地理關系模塊
2.2.1 時間判別器
考慮到用戶的出行受時間和距離的影響程度不同,本文將簽到數(shù)據(jù)按時間劃分為工作日軌跡和節(jié)假日軌跡。在數(shù)據(jù)預處理時,為了減小訓練量,提高訓練效率,僅保留簽到時間的“時”,作為該條記錄的時間,例:“2021-7-1 12:34:23”,僅保留“12”作為該條簽到記錄的時間標簽。為了區(qū)分工作日軌跡和節(jié)假日軌跡,令工作日的簽到時間tday=t,0≤tday<24,節(jié)假日的簽到時間tend=t+24,24≤tend<48。在將軌跡輸入到地理關系模塊之前,先根據(jù)當前軌跡的第一條簽到記錄判斷該軌跡是工作日簽到還是節(jié)假日簽到,然后選擇對應的歷史軌跡。即:若t0<24成立,則選取歷史軌跡中屬于工作日的簽到軌跡,反之,選擇屬于節(jié)假日的簽到軌跡。另外,需要判斷獲得的歷史軌跡是否為空,這樣做可以排除已知的歷史軌跡中僅包含某一種時間軌跡,而當前軌跡是另一種時間軌跡的情況,如:歷史軌跡全部是節(jié)假日軌跡,而當前軌跡是工作日軌跡。針對這一情況,可以隨機生成一個集合P={l1,l2,…,l|P|}作為歷史軌跡,|P|為集合的長度。
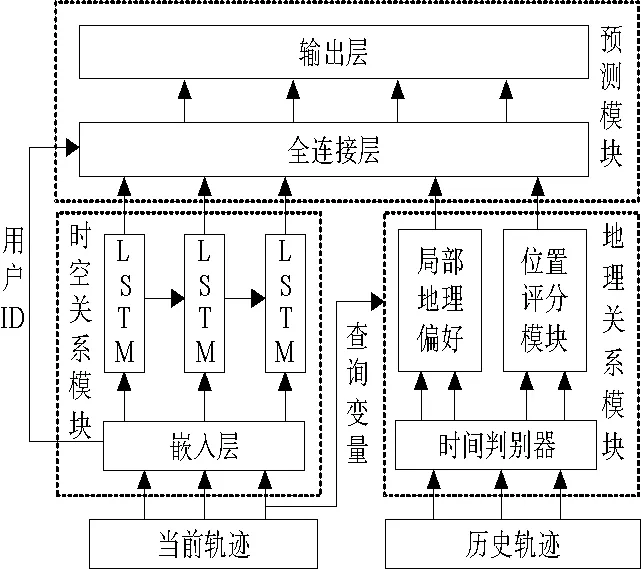
圖1 興趣點推薦模型Fig.1 POI recommendation model
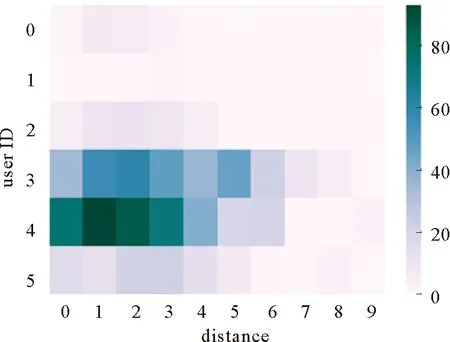
圖2 鄰居興趣點訪問次數(shù)Fig.2 Number of visits to neighbor POIs
2.2.2 局部地理偏好模塊
由于鄰居興趣點的距離可以滿足用戶的時間可行性,用戶下一步訪問的興趣點,極大概率是當前興趣點的鄰居興趣點。圖2為鄰居興趣點訪問次數(shù)的分布圖。可以看出:給定用戶訪問的興趣點li,用戶訪問li的次數(shù)與訪問li鄰居的次數(shù)呈正相關,與距離呈負相關(顏色深淺表示訪問次數(shù),顏色越深表示訪問次數(shù)越多)。
因此,根據(jù)距離,對時間判別器的輸出結果進行篩選,生成更小的興趣點候選集合Q。這里需要分別計算歷史軌跡中的每一個興趣點li,i∈{1,2,…,|P|}與當前軌跡中t-1時刻訪問的興趣點lt-1的距離:
(3)
其中,(lonli,latli)為歷史軌跡中第i個興趣點的經緯度,(lonlt-1,latlt-1)為當前軌跡中t-1時刻的興趣點lt-1的經緯度。若di<Δd成立(Δd為距離閾值),則將興趣點li添加到新的興趣點候選集合Q中。新生成的興趣點候選集合Q的長度要比歷史軌跡的長度短很多,這樣做既可以減少后續(xù)計算的成本花費,也可以避免某些距離較遠的興趣點對預測結果的影響。

圖3 局部地理偏好模塊結構圖Fig.3 Architecture of local geographical preferences module
為了進一步獲得鄰居興趣點的地理特征,將興趣點候選集合Q嵌入后可以得到Qe,然后通過卷積神經網絡實現(xiàn)特征提取,如圖3所示。
Z=ReLU(fconv(Qe))
(4)

2.2.3 位置評分模塊
該模塊主要是根據(jù)用戶的歷史軌跡,計算不同用戶之間已訪問興趣點的相似度,進一步生成用戶關于興趣點的評分矩陣。
(5)
(6)
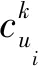
2.3 預測模塊
預測模塊由一個全連接層和一個輸出層組成。全連接層將時空關系模塊和地理關系模塊的所有特征結合到一個新的向量中,并進一步將特征向量處理成一個維度更小、更具有表征意義的向量。然后,由輸出層經過負采樣后,輸出預測結果。具體過程如下:

(7)
其中,y是一個融合時序特征、地理特征及用戶個性化特征的向量,將其與評分矩陣做最后的融合,并經過softmax層處理后,得到模型預測輸出,如式(8)所示:
out=softmax(y*W′*Cui)
(8)
其中,W′是一個可訓練矩陣。out表示概率分布,概率最大的興趣點是用戶最有可能訪問的位置。如果用戶真實訪問是興趣點lt,其對應的概率為plt,那么損失函數(shù)可以表示為
(9)
3 實驗
3.1 實驗數(shù)據(jù)
本文所用的數(shù)據(jù)集分別來自Foursquare、Weeplaces和Gowalla。其中,F(xiàn)oursquare數(shù)據(jù)集收集了2012年4月到2013年2月的845個真實用戶在紐約的簽到數(shù)據(jù),共包括12 649個位置上的99 205條簽到記錄;Weeplaces數(shù)據(jù)集收集了2009年7月到2010年9月的307個真實用戶在全球的簽到數(shù)據(jù),共包括18 288個位置上的127 974條簽到記錄;Gowalla數(shù)據(jù)集收集了2010年1月到2010年9月的384個真實用戶在全球的簽到數(shù)據(jù),共包括16 486個位置上的79 356條簽到記錄。這3個數(shù)據(jù)集具有與模型相關的所有屬性(用戶ID、經緯度、興趣點ID、簽到時間)。
為了降低數(shù)據(jù)稀疏性的影響,本文對數(shù)據(jù)進行了預處理,將用戶一天中所有的簽到記錄視為一條簽到軌跡,僅保留擁有不少于5條簽到軌跡且每條軌跡不少于3條簽到記錄的用戶。對于每個用戶的簽到軌跡,前80%用作訓練集,后20%用作測試集。
3.2 指標與參數(shù)設置
本文采用了3個常用的評估指標:準確率(Pre@K)、召回率(Rec@K),歸一化貼現(xiàn)累計收益(NDCG@K),定義為
(10)
(11)
(12)
其中,K為給每個用戶推薦的POIs數(shù)量,Ri為測試集中用戶訪問的真實位置集合,Vi為給用戶推薦的K個POIs,Gi為給用戶推薦的K個POIs的等級,|U|表示用戶的數(shù)量。本文取K={5,10}來分別計算準確率、召回率和歸一化貼現(xiàn)累計收益。
通過實驗,本文將隱藏層節(jié)點數(shù)設置為300,興趣點和用戶ID的嵌入維度設置為300,時間的嵌入維度設置為10,批量大小設置為32,學習率設置為0.000 1,距離約束設置為Δd=4 km,候選歷史軌跡長度設置為|P|=20。另外,本文采用了Adam優(yōu)化算法對模型中的參數(shù)進行優(yōu)化。
3.3 基線
本文選擇了一些經典方法與所提出模型進行了性能比較:
Markov:作為一種經典的序列預測方法,可以學習序列之間的轉移概率,從而預測用戶未來的訪問行為,是興趣點推薦常用的基線模型。
RNN:一種基礎的處理序列數(shù)據(jù)的循環(huán)神經網絡模型,由輸入層、隱藏層和輸出層組成,層間采用全連接的方式。
LSTM:在傳統(tǒng)RNN的基礎上,增加了3個門控機制(更新門、遺忘門、輸出門),可以用來捕獲長期依賴。
ST-RNN:基于RNN的興趣點推薦模型,將時間信息和地理信息同時融入循環(huán)結構中。
DeepMove:該模型利用歷史注意力模塊捕獲歷史軌跡中的周期性規(guī)律,并利用循環(huán)神經網絡捕獲當前軌跡的時空上下文。
LSTPM:該模型考慮了長期和短期偏好,使用上下文感知非局部結構來識別歷史軌跡中的時空相關性,可以捕獲當前軌跡中不連續(xù)興趣點的地理影響。
3.4 實驗分析
本文所提模型與基線模型在3個數(shù)據(jù)集上的實驗結果如圖4所示。從圖4可以得出以下結論:
1)在3個數(shù)據(jù)集上,本文所提模型在所有指標上都明顯優(yōu)于基線模型。而在基線模型中,LSTPM模型在3個數(shù)據(jù)集上表現(xiàn)最好,DeepMove模型次之。這兩個模型都將用戶的軌跡劃分為當前軌跡和歷史軌跡,將用戶的短期偏好和長期偏好分開考慮。其中,LSTPM模型的優(yōu)勢在于考慮了序列中的距離。因此,對于地理信息的處理在興趣點推薦中十分重要。本文模型既利用距離關系生成了一個小的候選興趣點集合,又對每一個興趣點進行了評分。由于本文所提模型充分學習了地理信息對于用戶選擇的影響,所以在推薦準確率方面有了較大提升。
2)ST-RNN在推薦表現(xiàn)上優(yōu)于LSTM、RNN,這說明除了學習序列信息,建模不同興趣點之間的時空關系同樣可以提高模型的預測能力。Markov方法的推薦效果最差,這表明僅使用用戶訪問位置的轉換矩陣來進行預測所包含的信息太少,導致模型無法實現(xiàn)較好的推薦效果。

圖4 3個數(shù)據(jù)集上的性能比較Fig.4 Performance comparison on three datasets
3.5 組件分析
為了驗證模型中不同組件對于性能的增益,本文進一步簡化了模型。
OURS-1:該模型移除了對于歷史軌跡處理的組件,僅保留了處理當前軌跡的組件。
OURS-2:該模型移除了對于當前軌跡處理的組件,僅保留了處理歷史軌跡的組件。

表1 不同簡化模型的性能比較Tab.1 Performance comparison of different simplified models
簡化模型在3個數(shù)據(jù)集上的實驗結果如表1所示,可以看出:
1)模型OURS-2在所有指標上的表現(xiàn)都優(yōu)于模型OURS-1。這說明OURS-2的推薦準確率更高。原因在于OURS-2可以更好地捕捉用戶簽到記錄中的地理信息,更好地模擬用戶的長期依賴。這說明地理信息在興趣點推薦中十分重要,也清楚地展示了本文建模個性化地理影響的優(yōu)勢。
2)雖然OURS-1比OURS-2略差。但是OURS-1的預測能力比圖4中的很多基線要好,如:RNN、LSTM。這說明對用戶短期依賴的捕獲,除了序列特征,對用戶個性化信息的建模也同樣重要。因此,本文所提模型將OURS-1和OURS-2組合在一起,在這3個數(shù)據(jù)集上都取得了最好的表現(xiàn)。
3.6 參數(shù)分析
本文分析了興趣點嵌入維度、候選歷史軌跡長度|P|對模型性能的影響。
圖5a顯示了在3個數(shù)據(jù)集上不同興趣點嵌入維度在Pre@5上的結果,可以看出:嵌入維度在[300,500]范圍內,模型性能基本是穩(wěn)定。這是因為維度過低時,會丟失很多特征;維度過高時,又會產生無關的噪聲信息。最終,本文將300作為興趣點的嵌入維度,一方面可以減少參數(shù)量,另一方面可以提高運算效率。
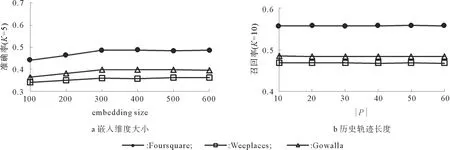
圖5 不同參數(shù)的性能比較Fig.5 Performance comparison of different parameters
圖5b顯示了在3個數(shù)據(jù)集上不同候選歷史軌跡長度|P|在Rec@10上的結果,可以看出,候選歷史軌跡長度|P|對于模型的預測性能幾乎沒有影響。這說明絕大多數(shù)用戶不存在2.2.1節(jié)中所提到的歷史軌跡不存在的情況。
4 結論
本文提出了一種融合時間和地理信息的興趣點推薦模型。首先,針對時間對用戶訪問行為的不同影響,本文將用戶軌跡劃分為工作日軌跡和節(jié)假日軌跡,并在此基礎上進行了當前軌跡和歷史軌跡的劃分。其次,模型分別利用時空關系模塊和地理關系模塊學習不同軌跡中的特征。具體而言,時空關系模塊利用長短期記憶網絡學習當前軌跡中的時空特征;地理關系模塊一方面通過卷積神經網絡學習鄰居興趣點的特征;另一方面根據(jù)用戶之間的相似度,生成用戶對興趣點的評分矩陣。實驗證明,本文所提模型在興趣點推薦性能方面優(yōu)于現(xiàn)有的其他模型。目前的興趣點推薦研究都是針對單個用戶,未來可以考慮根據(jù)社交關系以用戶組的形式進行興趣點推薦。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:55:08
創(chuàng)業(yè)家(2015年10期)2015-02-27 07:54:39
