改進蜉蝣算法及其在腦電信號識別中的應用
2023-01-11 06:33:00趙夢玲楊心露殷新宇
河南科技大學學報(自然科學版) 2023年2期
趙夢玲,楊心露,殷新宇
(西安科技大學 理學院,陜西 西安 710054)
0 引言
腦-計算機接口(brain computer interface,BCI)是人類大腦和計算機交互的媒介。BCI的最初研究以提高人類獨立性和生活質量為目的。文獻[1]指出BCI在癲癇發作檢測/預測、藥物效應診斷、運動圖像監測、心理任務、睡眠狀態識別等多個領域應用廣泛。BCI具有多種范式,事件相關電位(event related potentials,ERP)是其中的一種,主要是大腦在經歷感覺刺激時產生的反應。文獻[2]提出P300已被證明是ERP成分中有效的活動位點。文獻[3]概述了P300技術的現狀,并通過對比實驗證明了在腦電信號(electroencephalogram,EEG)分類中支持向量機(support vector machine,SVM)的良好性能。文獻[4]提出了基于貓群算法(cat swarm algorithm,CSO)優化SVM模型,搜索優化特征子集,保留有益的特征作為SVM分類器的輸入。文獻[5]總結了多種機器學習方法在BCI分類上的應用,提出了極限學習機(extreme learning machines,ELM)和SVM方法在腦電信號識別領域的優勢。
蜉蝣算法(mayfly algorithm,MA)是2020年提出的一種新型智能算法,是一種以蜉蝣生物的飛行和社會行為為參照的元啟發式算法,結合了遺傳算法和粒子群算法的優勢。文獻[6]指出了MA中特殊的舞蹈和隨機飛行的過程可以增強算法探索能力,利用特性之間的平衡,幫助算法擺脫局部最優,而突變部分可以加強算法搜索新區域的能力。但是與其他啟發式算法相同,MA也存在如何提高收斂性的問題。與禁忌搜索和遺傳算法等其他元啟發式算法相比較,模擬退火算法(simulated annealing algorithm,SA)作為一種啟發式尋優算法,具有優于其他算法的局部搜索能力。文獻[7]提出了一種基于模擬退火的自適應粒子群優化,通過對權重的改進,提高算法收斂性。文獻[8]提出使用Tent混沌序列初始化種群的蜉蝣算法,提高了搜索精度和穩定性。但是從文獻統計來看,針對MA性能和實際應用上的研究較少。文獻[9]證明了啟發式算法可以提高機器學習算法的能力。
本文針對蜉蝣算法收斂性能欠佳和易陷入局部搜索的不足,提出一種基于混沌自初始化和模擬退火優化下的蜉蝣算法(chaos simulated annealing mayfly algorithm,SA-AMA)。對7個基準測試函數的仿真結果表明:與自適應模擬退火優化粒子群算法(simulated annealing adaptive particle swarm algorithm,BSAPSO)和標準自適應權重蜉蝣算法(adaptive mayfly algorithm,AMA)相比,改進后的算法尋優能力和收斂性能具有顯著優勢。為了證明提出的算法在實際應用上的能力,本文建立SVM分類器,并使用改進后的算法優化其參數,對5位受試者的P300腦電信號進行分類識別。實驗結果表明:與K-最近鄰(K-nearest neighbor,KNN)、ELM網絡和SVM分類器對比,使用改進后算法優化下的SVM分類器識別能力突出。
1 算法改進
1.1 混沌初始化種群
文獻[10]指出了混沌映射是一種確定性系統產生的隨機性序列,其特點在于相差微弱的初始值可能會帶來不同的結果,可以提高優化算法的種群多樣化。本文通過比較Logistic、Gaussi、Chebyshev、Tent等多個不同的混沌映射系統,選擇Logistic混沌映射生成初始化種群。在蜉蝣算法整體搜索過程中,慣性權重需要遵循逐漸遞減的趨勢。線性自適應慣性權重相比固定權重在一定程度上提升了算法的搜索能力。使用線性自適應慣性權重w:
(1)
其中:iter為當前迭代數;maxiter為最大迭代數;ωmax、ωmin分別為最大、最小慣性權重,范圍設置為[0.2,1.2]。
1.2 優化算法步驟
文獻[11]提出了SA的優勢在于既能增加種群的多樣性,又能跳出局部最優,可以有效與其他算法融合,進一步提高搜索能力。本文使用SA機制改進蜉蝣算法個體的速度更新方式,提高搜索速率和種群多樣性。
改進的蜉蝣算法具體實現步驟如下:
步驟1 Logistic混沌初始化各參數:
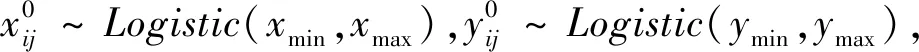
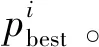
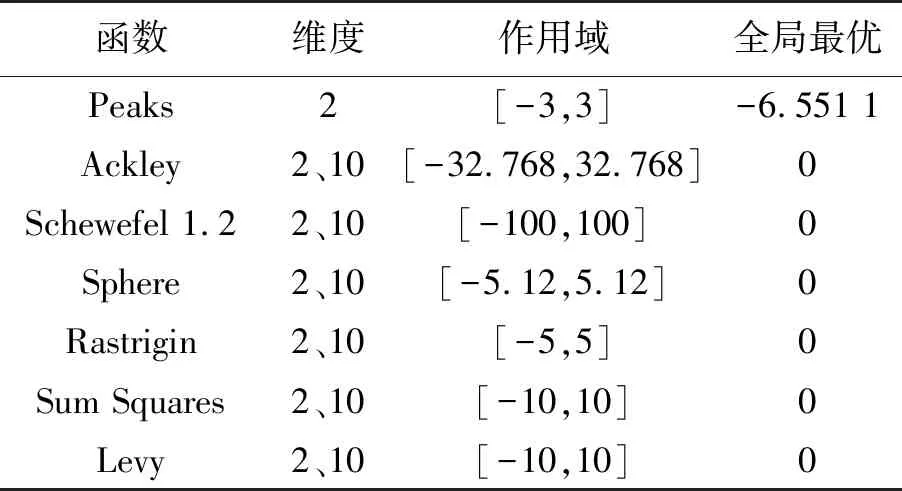
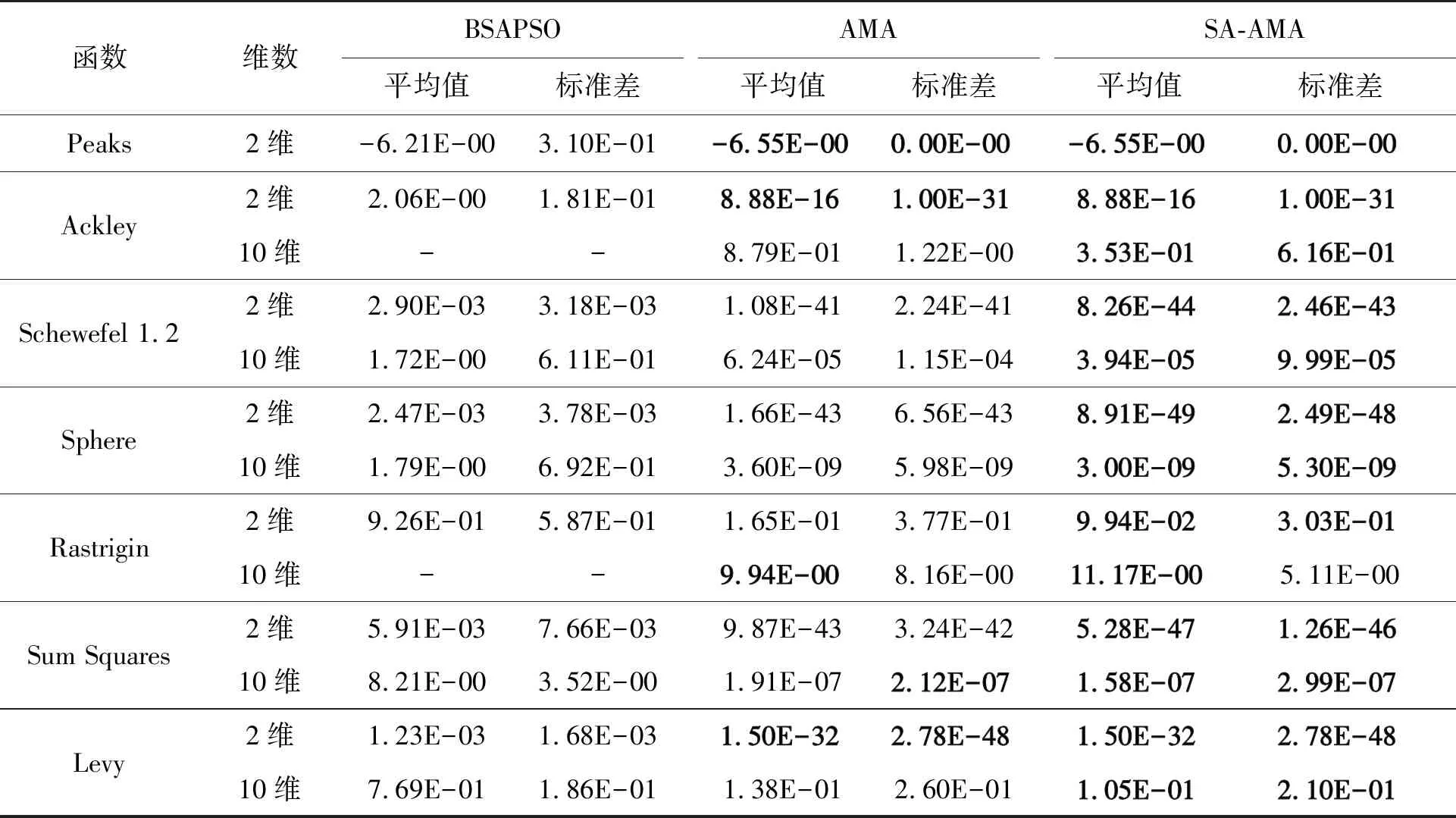
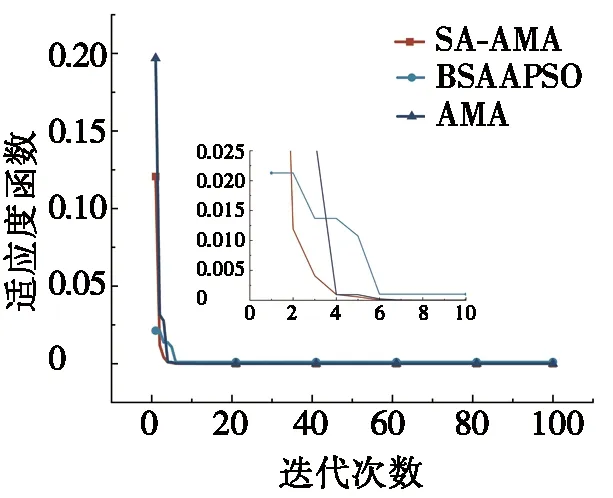
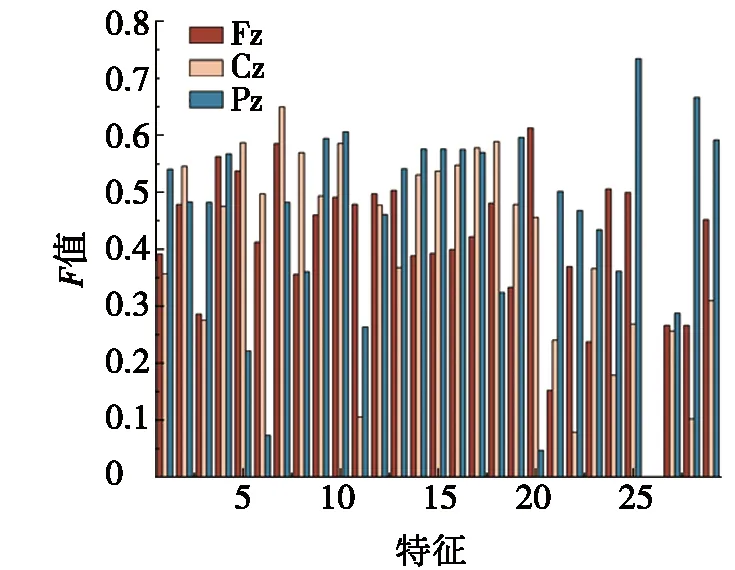
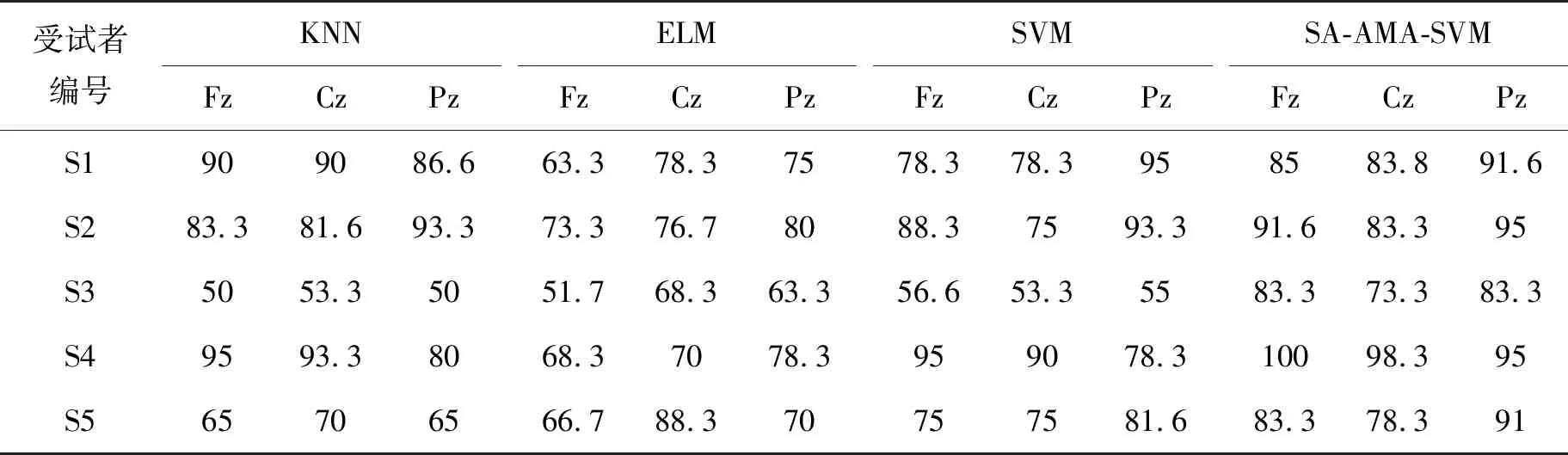
步驟3 迭代前期:iter (2) 式(2)表示雌蜉蝣被雄蜉蝣吸引和未被吸引下雄蜉蝣的速度更新。 雄蜉蝣位置更新公式為: (3) 雌蜉蝣速度更新公式為: (4) 式(4)分別表示雌蜉蝣未被雄蜉蝣吸引和被吸引下雌蜉蝣的速度更新。 雌蜉蝣位置更新公式為: (5) (6) 這里吸引程度通過適應度函數判定,f(yij)>f(xij)表示雌蜉蝣被雄蜉蝣個體吸引,反之,則未被吸引。假設最好的雌蜉蝣個體被最好的雄蜉蝣個體吸引,第二好雌蜉蝣個體被第二好雄蜉蝣個體吸引,以此類推。 步驟4 迭代后期:iter≥max(iter/2),定義概率 (7) 其中:fnew為當前退火階段的種群個體適應度;以概率p對速度進行調整;t為退火溫度,這里設置為100。如果f(yi)>f(xi),以式(2)和式(4)進行速度更新;如果f(yi)≤f(xi),以概率P>rand(0,1)接受個體間吸引更新速度方式,否則,更新進度: (8) 融合模擬退火機制既可以保留算法中的有效更新方式,又提高算法的搜索速度和種群多樣性。 步驟5 個體排序后進行交叉和變異產生子代: (9) 步驟6 分離雌性和雄性蜉蝣,更新個體最優各全局最優。返回步驟2,直到滿足終止條件。 本文基于MATLAB2020b軟件平臺進行仿真模擬實驗,分析了SA-AMA的計算和收斂性能。所有實驗算法的初始種群數量設置為100,最大迭代數設置為100,能見度系數為2,舞蹈系數為5,游走系數為1,a1為1,a2與a3為1.5,突變率為0.01。 為了驗證SA-AMA的有效性,本文基于7個測試函數,對SA-AMA、AMA和BSAPSO這3種算法在2維和10維上進行仿真對比,測試函數詳見表1。實驗獨立運行30次,分別計算平均值、標準差,仿真結果見表2。表2中加粗數值表示算法在對應測試函數上的最佳值,缺失數值表示此算法的仿真結果較差,沒有對比性。由表2可知:SA-AMA在低維和高維問題上具有優于其他兩種算法的搜索能力和收斂能力,可以快速收斂并得到最優解。改進后的算法在測試函數的平均值均達到最佳,標準差也反映了改進后的算法具有良好的魯棒性。MA擁有不同于粒子群算法的種群變異和交叉能力,因此標準AMA算法的能力較BSAPSO算法有優勢,本文所提算法的混沌與模擬退火機制使得算法的尋優速率進一步得到提升。圖1是部分測試函數收斂對比圖。由圖1可得:改進后的算法相比其他兩種算法可以快速收斂。由圖1a、圖1b和圖1c可知,基于快速收斂的優勢,改進后的算法具有更高的尋優能力。 表1 測試函數 表2 仿真結果 (a) Sphere(2維) 本文采用的P300數據集為5位平均年齡20歲的健康成年人(編號分別為S1、S2、S3、S4、S5),數據采集頻率為250 Hz。采用文獻[12]的實驗設計:每位受試者能觀察1個6行6列共36個字符組成的矩陣,并在實驗開始前確定1個目標字符。受試者需要注視目標字符,之后進入字符矩陣的閃爍模式,每次以隨機的順序閃爍字符矩陣的1行或1列,閃爍時長為80 ms,間隔為80 ms。當所有行和列均閃爍1次后,結束1輪實驗,每次實驗產生12個樣本。P300電位數據通常在刺激發生后300~450 ms產生正向波峰。每位實驗者的單個字符實驗P300刺激樣本為2個,非P300刺激樣本為10個,在受試者注視目標字符的過程中,目標字符所在行或列閃爍,腦電信號中會出現P300電位。而當其他行和列閃爍時,則不會出現P300電位。上述實驗流程為1輪,每位實驗者共重復5輪。截取每段信號200~500 ms的實驗數據,共76個采樣點。對負樣本的5輪實驗所獲數據取平均值。通過對12個字符5輪實驗數據整理可得,每位受試者完成實驗后各有P300和非P300樣本矩陣:76×20×120(采樣點×通道×樣本量)。 實驗數據采集基于20個通道:Fz、F3、F4、Cz、C3、C4、T7、T8、CP3、CP4、CP5、CP6、Pz、P3、P4、P7、P8、Oz、O1、O2。可以發現在Fz、Cz、Pz通道上腦電反應最為活躍,并且在刺激發生后300 ms左右出現正向波。文獻[13]指出腦電信號的部分通道刺激反映明顯。鑒于先驗知識,本文選取每位受試者的Fz、Cz、Pz通道數據進行研究。文獻[14]指出在腦電信號數據中存在大量干擾,如眨眼、眼動、肌電偽跡、心電偽跡等。經過濾波處理后的信號會過濾掉大多數的噪聲,明顯提高分類器的分類精度。根據P300的自身特征,其主要信息儲存在0~30 Hz的頻帶中。 獨立分量分析(independent component analysis , ICA)是一個線性變換,在獨立假設的條件下,可以把數據或信號分離成獨立的非高斯信號源的線性組合。ICA通過盲源分離提取有效信息,被廣泛應用于語音識別、圖像處理、生物醫學信號處理、通信、特征提取和降維等領域。ICA將原始信號降維之后,提取相互獨立的屬性,能夠最大程度上挖掘信號的隱藏因素。文獻[15]概述了ICA方法的理論過程,與主成分分析(principal components analysis,PCA)方法相比,ICA可以將信號處理為多個統計獨立分量的線性組合,應用性更強、更廣泛。本文建立低通和高通濾波器,保留0.1~30 Hz的原信號,使用ICA方法在經過濾波處理后的原始信號中分離出有效實驗數據。 3.2.1 特征提取 文獻[16]指出信號數據具有時域和頻域上的多重特性,想要充分研究信號信息,就需要挖掘其最底層的規律。人類大腦的有用信息主要來源于腦電波頻帶:delta波段(0~4 Hz)、theta波段(3.5~7.5 Hz)、alpha波段(7.5~13 Hz)、beta波段(13~26 Hz)、gamma波段(26~70 Hz)。根據先驗經驗,P300頻域能量主要存在于0~30 Hz頻帶中,采用功率譜分析/功率譜密度(power spectral density, PSD)方法提取[0.1,3]、[3,5]、[5,7]、[7,13]、[13,30]這5個波段的PSD。同時提取頻域特征,即香農熵(Shannon)、對數能量熵(Logenery)、近似熵(ApEn)、幅度最大值、幅度平均值。使用6層4階緊支集正交(db4)小波包分解原始信號,計算重構信號與原始信號的絕對誤差以及小波包分解后在0~30 Hz頻段的能量熵值之和。在此基礎上,本文還提取了最大值、最小值、中位數、平均值、絕對平均值、方差值、標準差、峭度、偏度、均方根、波形因子、峰值因子、脈沖因子、裕度因子、最大自相關系數、峰值時間、正面積等17個時域特征并進行研究。由此,共提取29個時頻域特征。為了便于后續研究,對29個時頻域特征進行標序,如表3所示。 表3 29個時頻域特征 3.2.2 特征評價 文獻[17]提出一種F值(F-score)方法,該方法可以衡量特征在兩類之間分辨能力,能夠實現最有效的特征選擇。每個特征的F值由式(10)計算得到: (10) 使用其對29個特征進行評分和降序重排。圖2給出了受試者S5的特征評分值,特征的F值越高,表明其分類能力越強。 圖2 S5受試者F-score特征評分 SVM最大的優點是其不受局部最小值的影響,克服了過度學習和高維數據,但這兩者都導致了計算復雜度和局部極值。SVM的性能高度依賴于各個參數的合理設定,文獻[18]證明了選擇合理的參數能有效提高分類模型的學習和泛化能力。 SVM最主要的思想是找到提供最小訓練錯誤數的超平面,并保持約束違反盡可能小,使得兩類數據之間的邊緣距離最大化,尤其對于線性不可分問題,將輸入向量xi通過高維映射(非線性映射)φ(xi)=xi→Η,SVM通過映射將低維線性不可分問題轉化為高維可分問題,高維空間H一般為Hilbert空間。 樣本xi線性不可分,i=0,1,…,n取整個樣本集,間隔最大化(maximal-margin)原則實現最優分類,超平面為: ωT·xi+b=0, (11) (12) 落在上述邊界上的樣本點(xi,yi)為支持向量,滿足: ωTxi±b0=±1。 (13) 軟間隔約束凸二次規劃問題為: (14) 其中:yi∈{-1,+1},為樣本的類別標記;實常數c>0,稱為懲罰參數,決定了最小化訓練誤差和最大化分類邊際之間的權衡;ξi≥0,為非負松弛變量,松弛變量可以通過允許違反約束來引入。 本文使用hinge替代損失函數: lhinge(z)=max(0,1-z)。 (15) 引入拉格朗日(Lagrange)乘子αi,只有少部分的樣本xi滿足yi(wxi+b)=1-ξi,這少部分樣本稱為支持向量,其對應的Lagrange乘子αi>0,其余樣本滿足αi=0,體現了稀疏性。優化問題的對偶問題為: (16) 最優決策函數(最優分類器)為: f(x)=sgn(ω*·φ(x)+b*), (17) 其中:ω*、b*均由支持向量決定。 本文使用最小分類誤差作為適應度函數,基于徑向基核函數(rodial basis function,RBF)作為核函數,使用改進后的算法對最小分類誤差進行尋優,得到SVM的最佳參數值并進行分類,使得分類器的性能得到了提升。 文獻[19]指出了RBF核函數: (18) 實驗的特征是基于最大精度值、最小特征數原則進行選取,這樣可以在降低計算成本的基礎上獲得最優的分類結果。原始數據在經過預處理和特征提取后,使用F值統計量對提取的特征進行評分和重新排序。在進行最終的特征選擇和分類前,實驗數據在二維平面上呈現出高混合性,若僅在二維空間進行線性分類,其分類難度大且結果欠佳。SVM的最大優勢就是使用恰當的核函數將二維數據映射為高維數據,建立最優的空間分類面提高分類能力,從而達到預期的效果。 實驗將預處理后的數據按照3∶1分為訓練數據和測試數據,使用測試數據的結果作為最終的結論。每位受試者在Fz、Cz、Pz這3個單通道下分別進行特征選擇和分類。根據測試集的分類精度,選擇出效果最優的特征組合。實驗結果表明:表3中的29個時頻域特征在最大精度值、最小特征數原則下,0.1~3 Hz的功率譜密度、正面積、裕度因子、香農熵、對數能量熵、中位數、絕對平均值、均方根對受試者分類效果的影響較為明顯,說明上述特征在識別中效能顯著。 文獻[20]指出在分類任務中KNN、ELM和SVM在不同的工程應用問題上具有良好的分類性能。為了比較優化后的分類器性能,本文對比KNN、ELM、SVM、SA-AMA-SVM這4種分類器在P300數據集上的識別能力。KNN采用1~10迭代選取最佳K值,SVM采用10折交叉驗證,不同分類器識別率見表4。由表4可知:KNN、ELM、SVM分類器識別能力在受試者S1~S5上各有優勢,但是SVM分類器的平均識別能力較高。使用改進后算法優化下的SVM分類的整體識別能力得到明顯提升,除在受試者S1上表現欠佳,在其余受試者實驗對比達到了最佳的識別率,單通道平均識別率達88%以上,進一步驗證了本文所提方法在腦電信號識別應用中的有效性。 表4 不同分類器識別率 % 在現有蜉蝣算法的基礎上,本文提出了SA-AMA,改進后的算法提升收斂速率和尋優能力。與AMA和BSAPSO相比,SA-AMA具有更強的魯棒性和更好的搜索能力。為了測試其實際應用能力,基于時頻域特征,使用改進算法優化SVM分類器。SA-AMA-SVM分類器比KNN分類器和ELM分類器識別率更高。因此,本文提出的方法為腦電信號識別提供了新的解決方案和思路。 由于改進算法仍具有一定復雜度,優化的運行時間較長,且雖然腦電信號的識別精度較高,但仍遠未達到零誤差。未來的研究將側重于降低算法的復雜性和提高其準確性。
2 仿真模擬
3 應用
3.1 數據處理
3.2 特征提取與選擇
3.3 分類器
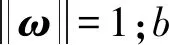
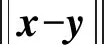
3.4 實驗
4 結束語
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
