漢語作為第二語言的韻律組塊認知加工研究
2023-01-12 06:49:16陳夢恬王建勤
華文教學與研究 2022年4期
關鍵詞:句法
陳夢恬,王建勤
(1.昆山杜克大學,江蘇,昆山 215316;2.北京語言大學語言認知科學學科創新引智基地,北京 100083)
1.引言
組詞斷句是第二語言口語產出的難點。在即時的話語中,學習者很難確定單位邊界的位置和數量,以至于犯兩類錯誤,即停頓不當和停頓過多(曹劍芬,2011)。比如 “小明吃了一碗飯”,如果停頓(用斜線表示)是 “小明吃/了一/碗飯”,那么 “了一”這個單位不合句法,也沒有意義。如果是 “小明/吃/了/一碗/飯”,所有單位都符合句法且有意義,可是停頓過多、單位長度太短,會影響口語表達,致使交流受阻。
從語言層面上看,這兩類錯誤是由句法分析不當所導致的。口語單位是以句法詞為基礎,經長度、語速等調節而成的韻律組塊,其切分和組合需符合句法規則,否則會影響口語理解(Selkirk,2000)。長度則被用來平衡組塊邊界間的距離,使信息焦點分布更均衡,交流更順暢(周明強,2002)。從認知加工上看,這兩類錯誤還揭示了認知資源的在線分配問題,而這一問題在第二語言口語中更突出(Robinson,2003)。面對同一種語言,學習者沒有母語者那樣的詞匯和句法知識,提取和應用這些知識的過程尚未自動化,常通過增加停頓、縮短組塊等方法,來贏得更多的注意力資源和認知加工時間(MacWhinney,2012)。
這里的韻律組塊,并非語言學意義上的韻律詞、韻律短語等靜態的韻律結構的層級單位(Chu & Qian,2001;Frazier et al.,2006),而是動態的口語表達結構的加工單位,具有時間和空間特性(曹劍芬,2003)。空間特性表現在,口語表達結構由獨立于句法、語義等的韻律特征的心理表征構成,與句法結構關系密切(Ferreira,1993;Speer et al.,1993)。時間特性是指,實際的口語表達結構,會受長度、語速等因素的制約,在組塊上呈現二分趨勢,不完全與心理詞典中的韻律結構一致(Grosjean et al.,1979)。先前的韻律組塊研究,主要從組塊的分類和邊界特征入手,得出的韻律結構模型,多數基于靜態的空間層級描述,非動態的單位切分與組合(張家騄等人,2002;王永鑫、蔡蓮紅,2010),而后者正是韻律組塊在口語中的表現(MacWhinney,2008、2012)。因此,在認知加工層面探究口語的組詞斷句,應以口語表達結構中的韻律組塊為對象。
影響韻律組塊的因素主要有兩方面:從語言本身來講,句法的影響最大(Hirose,2003;Hirst,1993),其次是語義和語用(Astésano et al.,2004;趙瑾,2012);從認知加工上看,有長度、語速等(Bachenko & Fitzpatrick,1990;Jun,2003)。綜合考查語言和認知因素的研究,在計算機文語轉換領域較多(Bruce et al.,1996;Shriberg et al.,2000),得出的一些規則,例如句法成分的分類及其內部粘合程度,決定組塊邊界不該在哪里,成分長度則在此基礎上進行調節,根據語義和信息焦點去掉不必要的邊界(Bachenko et al.,1986),對漢語口語韻律組塊也有解釋力(陳默,2007;裴雨來等人,2009;張連文,2013)。然而,這些規則的設定沒有將組塊表現與其背后的認知加工聯系起來,而這正是學習者的口語產出有別于母語者的原因之一(Ullman,2001),也是第二語言教學的目標之一(魏巖軍,2017)。
因此,本研究以口語表達結構的韻律組塊為對象,從認知加工出發,通過分析學習者和母語者的句子停頓率和語流長度,來考查句法和長度對漢語口語韻律組塊的影響。句法因素由句法成分的性質來代表,長度由名詞修飾語的長度來代表(高思暢、王建勤,2019)。前人研究證實,韻律組塊中詞匯提取與句法計算效率的提高,可由停頓率的減少和語流長度的增加來體現(Rehbein,1987)。具體研究問題如下:
第一,學習者產出含不同句法成分的漢語句子時表現如何?句法成分的性質對其韻律組塊有何影響?
第二,學習者產出含不同長度修飾語的漢語句子時表現如何?句法成分的長度對其韻律組塊有何影響?
停頓率,即單位時間內的停頓次數,反映口語韻律組塊的切分情況。語流長度,即相鄰切分邊界間的組塊長度,反映組塊的組合情況。二者的計算公式如下:
停頓率=句內停頓次數÷音節總數
語流長度=句內句法詞個數÷組塊個數(單位:詞)
2.句法成分性質對口語韻律組塊的影響
2.1 實驗方法
2×3兩因素混合實驗設計。自變量:(1)句法成分性質,被試內變量,分為含附屬句法成分和不含附屬句法成分兩類。附屬句法成分是指介詞短語或副詞構成的狀語;(2)漢語水平,被試間變量,分為低水平、高水平和母語者三個水平。因變量是停頓率和語流長度。
2.1.1被試
低水平組15人(8男7女),高水平組15人(10男5女),母語者15人(5男10女)。兩組學習者的平均漢語學習時間分別為2年和5.3年,同一入學考試的平均分是83和93.3。根據Plonsky和Oswald(2014)對第二語言習得研究的平均數差異效應量評估,本研究將0.4、0.7和1.0視為低、中、高效應量的下限閾值。據G*power軟件估算,要達到中等效應量并具備0.80的多因變量混合實驗的檢驗效能,至少需要45名被試。本實驗的被試總量符合要求。
學習者和母語者均為中國大陸某高校學生,實驗前通過了工作記憶容量測試(Fortkamp et al.,1999;解文倩,2017),無過高或過低的情況。學習者來自美國、英國、加拿大和澳大利亞,16歲前未接觸過漢語,來中國以后只在目前就讀的大學學習漢語。
2.1.2材料
20個單句(見附錄1),根據工作記憶容量將音節數控制在9到16個之間(Miller,1956;Cowan,2001)。不含附屬句法成分的句子(M=7,SD=1.1)和含附屬句法成分的句子(M=7.4,SD=1.1)在句法詞數量上無顯著差異(χ2=1.143,p=.767,φ=.239)。句中字詞學習者被試都學過,但實驗句并非課文的句子。這樣做是為了降低其已將實驗句當成整個組塊來提取的概率,以便考查其在線組塊能力。實驗前一天,研究者會給每個被試一個詞表,解答詞和句法結構的疑問,保證其在實驗開始前具備所需的詞匯和句法知識,減少這些因素對實驗結果的影響。
2.1.3步驟
實驗任務是看后復述,即在無語境的情況下,看到并熟悉一個句子,等句子消失后,復述這個句子(Sternberg et al.,1978)。與朗讀相比,看后復述更能模擬自然的口語產出,又允許研究者控制材料和步驟(高思暢、王建勤,2020)。
實驗用E-prime 2.0操作,每個實驗句隨機呈現一次。正式實驗前有三組練習句。如果被試不能在規定時間內復述完,程序繼續運行,規定時間外復述的詞不被計入。復述完整率在85%以下的數據會被剔除。所有被試每個句子的復述完整率都在85%以上,故都為有效數據。整個實驗持續7到8分鐘。

圖1:句子復述任務步驟
2.1.4分析
研究者根據兩名不參與實驗的母語者聽感,確定被試的組塊邊界,據此計算出停頓率和語流長度。未經專業訓練的母語者依據聽感判斷出的邊界,與說話者的產出有較高一致性(王蓓等,2004)。判斷一致率為95%,分歧之處由兩人商議解決。停頓率和語流長度的計算基于實際產出的句子,包含原有語義基礎上的添減、替換詞。
因變量的分析由SPSS 25.0重復測量方差分析完成。邊界位置和增減、替換詞數據,由研究者手動統計。停頓率和語流長度均非嚴格意義上的定距變量,所以推論統計數據進行了對數轉換,公式為Y'=log10(Y+1)。方差分析的效應量由partial eta squared(η2p)表示,簡單效應檢驗的效應量由Cohen'sd表示。推論統計采用轉換后的數值,描述統計采用轉換前的數值。
1.2 實驗結果
停頓率的描述統計數據如下:
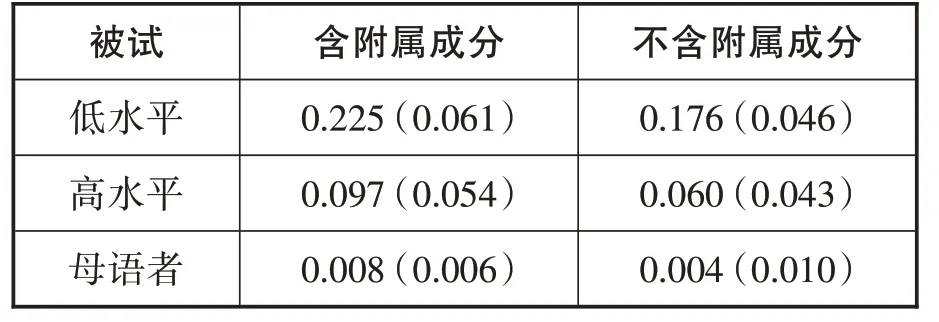
表1:實驗一停頓率的平均數和標準差
方差分析結果顯示,成分性質(F(1,42)=28.307,p<.001,η2p=.403)和漢語水平(F(2,42)=107.832,p<.001,η2p=.837)主效應均顯著,成分性質和漢語水平的交互作用顯著(F(2,42)=5.377,p=.008,η2p=.204)。經Bonferroni校正后的簡單效應檢驗顯示,低水平組含附屬句法成分的句子停頓率,比不含的高(t(14)=3.941,SE=0.004,p=.001,Cohen'sd=1.018,95%CI[0.008,0.027])。高水平組也一樣(t(14)=3.275,SE=0.004,p=.006,Cohen'sd=0.845,95% CI[0.005,0.024])。母語者兩類句子的停頓率無顯著差異(F(1,42)=.194,p=.662,η2p=.005)。
語流長度的描述統計數據如下:

表2:實驗一語流長度的平均數(單位:詞)和標準差
方差分析結果顯示,成分性質的主效應(F(1,42)=25.949,p<.001,η2p=.382),漢語水平的主效應(F(2,42)=141.033,p<.001,η2p=.870),成分性質和漢語水平的交互作用都顯著(F(2,42)=7.954,p=.001,η2p=.275)。經Bonferroni校正后的簡單效應檢驗顯示,低水平組含附屬句法成分的句子語流長度,比不含的短(t(14)=4.565,SE=0.013,p<.001,Cohen'sd=1.179,95%CI[0.043,0.088])。高水平組也一樣(t(14)=3.489,SE=0.020,p=.004,Cohen'sd=0.901,95% CI[0.027,0.115])。母語者兩類句子的語流長度無顯著差異(F(1,42)=.080,p=.778,η2p=.002),相反,含附屬句法成分的句子語流長度比不含的長。
邊界位置的分布數據如下:
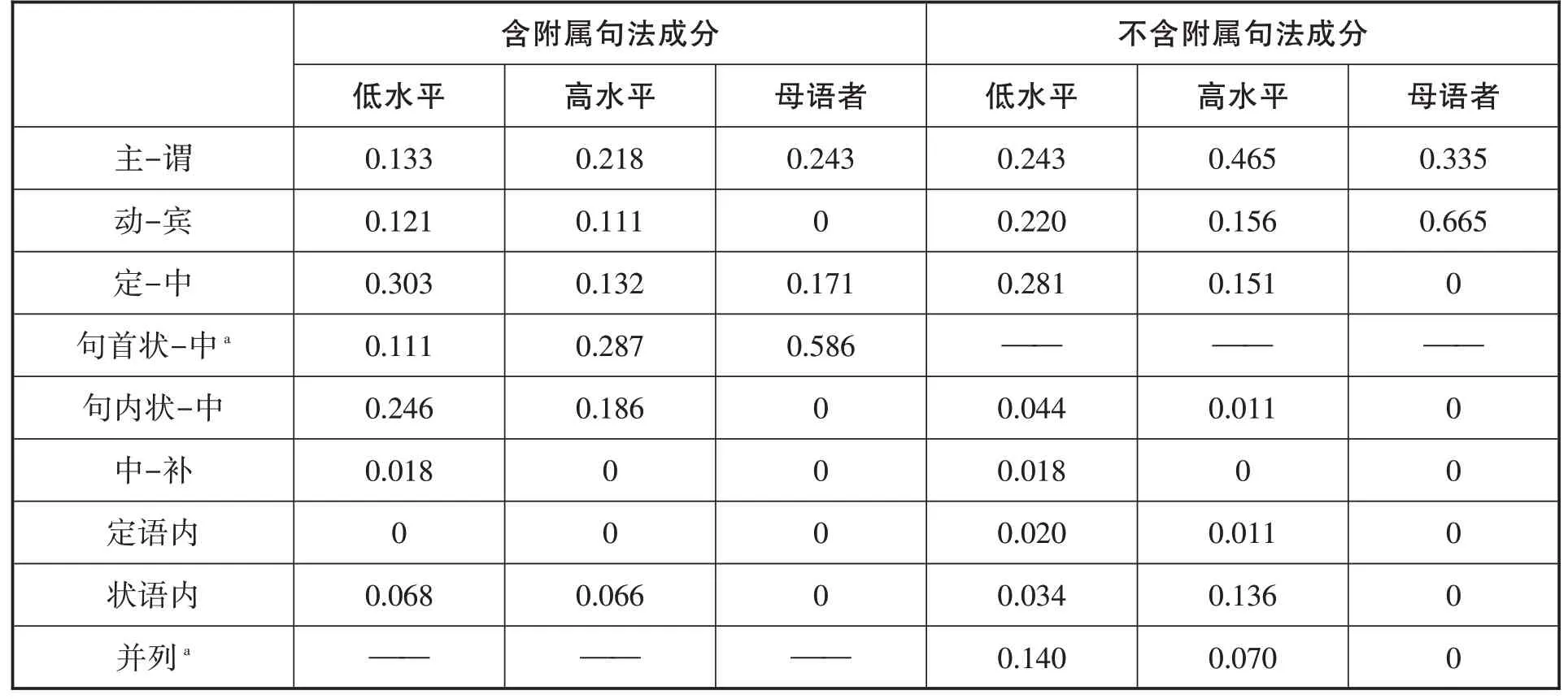
表3:實驗一韻律組塊邊界占句法成分邊界的比率
無論句中是否有附屬句法成分,低水平組在多數句法成分之間都會設定組塊邊界,其中以定語-中心語,即名詞性成分內部的幾率最大,例如 “冬天的/時候/外面/非常/冷”(含附屬句法成分) “我們/去了/北京的/胡同”(不含附屬句法成分)。高水平組也一樣,但其邊界主要設在主語-謂語、句首狀語-句子主干等較大的成分之間,例如 “冬天的時候/外面/非常冷” “我們/去了北京的/胡同”。母語者的邊界數量很少,會選擇在動詞-賓語等較大的句法成分之間設定邊界,例如 “冬天的時候/外面非常冷” “我們去了/北京的胡同”。
增減、替換詞的統計如下:
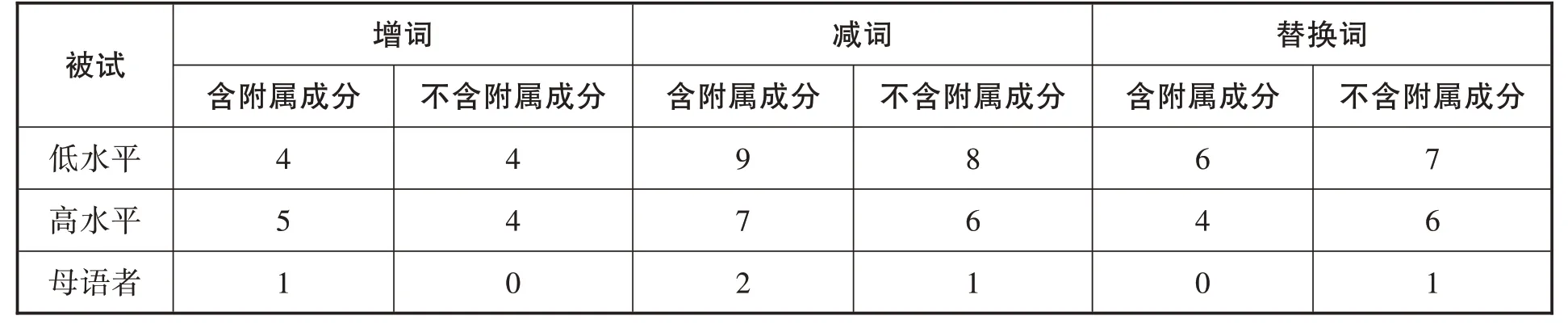
表4:實驗一增減、替換詞的總個數
附屬句法成分的有無,對三組被試的增減、替換詞操作沒有顯著影響。從數量上看,低水平組的操作最多,母語者的最少。從分類上看,減詞的概率最大,最少是增詞。減詞多發生在 “了” “的”等功能詞上。替換詞出現在 “妹妹” “媽媽”等親屬名詞上。增詞分兩種:(1)根據語義增加 “都” “要”等副詞,例如 “公園里的花(都)非常漂亮”;(2)重復某個詞,來獲得更多的回憶時間,例如 “在我老家(老家)那邊黃蘋果特別貴”。
2.3 討論
實驗一結果表明,句法成分性質對學習者的漢語口語韻律組塊有影響,附屬句法成分越多,停頓率就越高,語流長度也越短。這可以從組塊的句法加工上解釋。Ullman(2004,2005,2016)陳述性-程序性模型(Declarative/Procedural Model)和MacWhinney(2008,2012) “一語+二語”的聯合模型(Unified Model)均指出,組塊一旦形成,內部用于分析性組合的句法計算,即將多個成分依據句法規則組合成一個整體的過程就程序自動化,進而被整體組塊的提取所抑制,無需再消耗注意力資源。如果句法計算未程序化,成分組合就采用控制性加工,根據句法計算的難易程度來消耗注意力資源。反映到實驗一上,附屬句法成分的加入,使句法結構變復雜,在線組合句法詞形成韻律組塊的難度就增加(曹劍芬,2003)。由因變量數據可知,學習者在句子層面的韻律組塊,以多個句法詞的提取及其之間的分析性組合來實現,屬于多步驟的控制性加工,因此會受到句法結構復雜度的影響。不過,學習者在詞層面的韻律組塊,沒有因句法加工而過度消耗注意力資源,即附屬句法成分的有無,未對其增減、替換詞產生顯著影響。在重復詞時,學習者也傾向于重復整詞而不拆分詞。
實驗還發現了學習者和母語者在組塊邊界位置和數量上的不同:(1)附屬句法成分越多,學習者的邊界就越多,母語者則不受影響,其總體邊界數量也很少;(2)無論是否有附屬句法成分,學習者都會在各個句法成分之間設定邊界,母語者的邊界則主要在主語-謂語、句首狀語-句子主干等較大的句法成分之間。這種區別,在于二者的韻律組塊加工方式的不同。母語者依靠語義聯想來提取組塊,其內部的句法計算運用的是程序性知識,不消耗注意力資源,所以并非完全按照句法成分關系來進行,也就不易受句法結構復雜度的影響(Ullman,2001)。學習者的句法計算依賴控制性加工,雖其句法詞的提取憑借語義通達而近乎自動化,但將句法詞通過句法規則組合成韻律組塊時,依舊會消耗注意力資源(魏巖軍,2017),所以會按照句法成分的層級結構來設定組塊邊界,結構越復雜,邊界就可能越多,組塊就越小。除此之外,學習者所受的漢語教學也主要以句法詞為單位,通過分析句法結構來組詞造句,致使其口語產出過度依賴分析性的句法計算(MacWhinney,2018)。這一點可從高水平組和母語者的邊界位置差異中得到印證:雖與低水平組相比,高水平組的邊界數量較少,但仍傾向于在高一級的句法成分之間,例如 “我們/去了北京的胡同”的主語和謂語之間設定邊界,而不像母語者那樣,根據語義和長度,設定在 “我們去了/北京的胡同”的動詞和賓語之間。
3.句法成分長度對口語韻律組塊的影響
3.1 實驗方法
2×3兩因素混合實驗設計。自變量:(1)成分長度,被試內變量,分為短修飾語和長修飾語兩類;(2)漢語水平,被試間變量,分為低水平、高水平和母語者三個水平。
因變量、被試、步驟和數據分析,與實驗一相同。
材料為20個單句(見附錄2),分為短修飾語句(M=6.5,SD=0.7)和長修飾語句(M=8.9,SD=1.0)。短修飾語為單層定語,長修飾語為多層定語。一半的修飾語出現在主語位置,另一半出現在賓語位置。卡方檢驗顯示,兩種修飾語的句法詞數量存在顯著差異(χ2=16.571,p=.005,φ=.910),表明其長度有顯著區別。
3.2 實驗結果
停頓率的描述統計數據如下:

表5:實驗二停頓率的平均數和標準差
方差分析結果顯示,修飾語長度的主效應不顯著(F(1,42)=3.215,p=.080,η2p=.071),漢語水平的主效應顯著(F(2,42)=117.123,p<.001,η2p=。848),修飾語長度和漢語水平的交互作用顯著(F(2,42)=3.847,p=.029,η2p=.155)。經Bonferroni校正的簡單效應檢驗顯示,低水平組長修飾語句子的停頓率,比短修飾語的高(t(14)=2.507,SE=0.004,p=.025,Cohen'sd=0.647,95% CI[0.001,0.018])。高 水 平 組(F(1,42)=.012,p=.914,η2p<.001)和母語者(F(1,42)=.007,p=.932,η2p<.001)兩類句子的停頓率無顯著差異。
語流長度的描述統計數據如下:

表6:實驗二語流長度的平均數(單位:詞)和標準差
方差分析結果顯示,修飾語長度的主效應(F(1,42)=81.923,p<.001,η2p=.661),漢語水平的主效應(F(2,42)=144.345,p<.001,η2p=.873),修飾語長度和漢語水平的交互作用都顯著(F(2,42)=10.537,p<.001,η2p=.334)。經Bonferroni校正的簡單效應檢驗結示,低水平組兩類句子的語流長度無顯著差別(t(14)=1.704,SE=0.013,p=.111,Cohen'sd=0.440,95%CI[-0.050,0.006])。高水平組(t(14)=4.592,SE=0.016,p<.001,Cohen'sd=1.186,95% CI[0.040,0.110])和母語者(t(14)=13.401,SE=0.008,p<.001,Cohen'sd=3.460,95% CI[0.088,0.121])長修飾語句子的語流長度,比短修飾語的長。
邊界位置的分布數據如下:
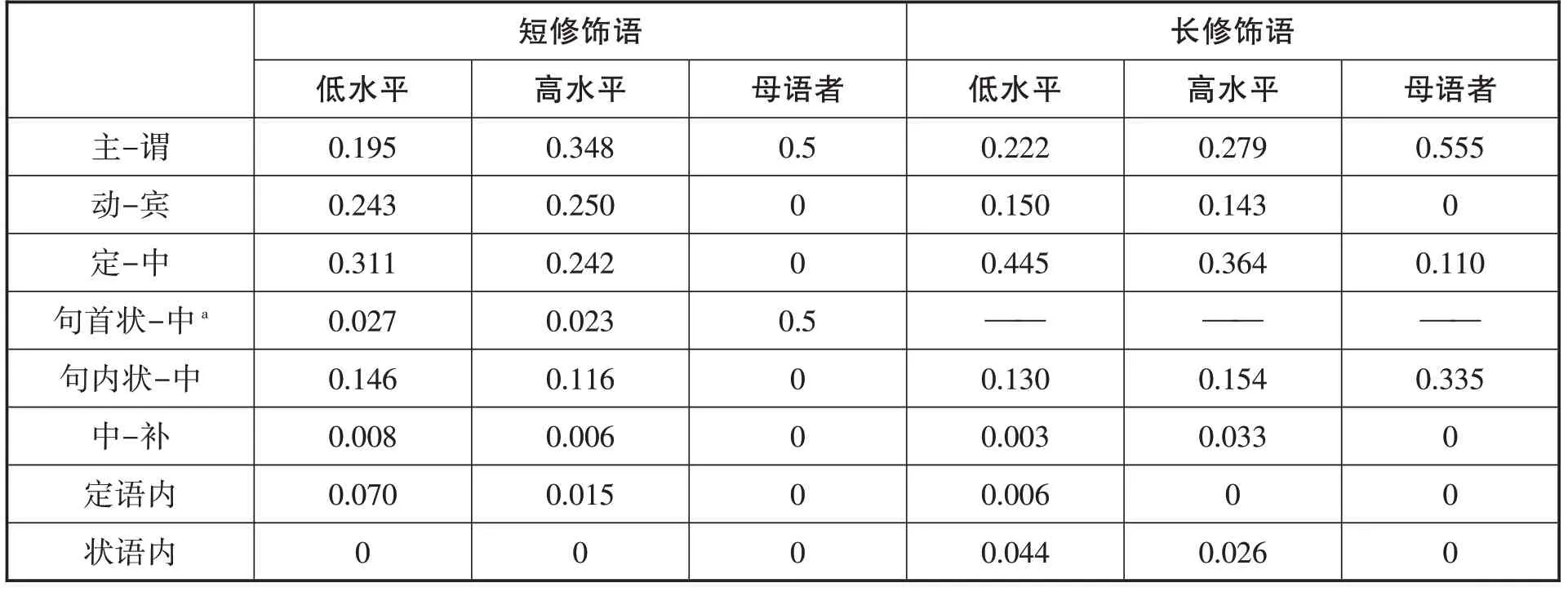
表7:實驗二韻律組塊邊界占句法成分邊界的比率
無論修飾語有多長,低水平組都會在多數句法成分之間設定組塊邊界,其中又以定語-中心語,即名詞性成分內部的幾率最大,例如 “她/媽媽/的眼睛/大大的”(短修飾語句)、 “這是/我在/上海/拍的/照片”(長修飾語句)。高水平組也一樣,但其除了定語-中心語,還會在主語-謂語等較大的句法成分之間設定邊界,例如 “她媽媽的/眼睛/大大的”、 “這是/我在上海拍/的照片”。母語者的邊界數量很少,也會選擇在主語-謂語、狀語-中心語等較大的句法成分之間設定邊界,例如 “她媽媽的眼睛/大大的” “這是我在上海/拍的照片”。
增減、替換詞的統計如下:
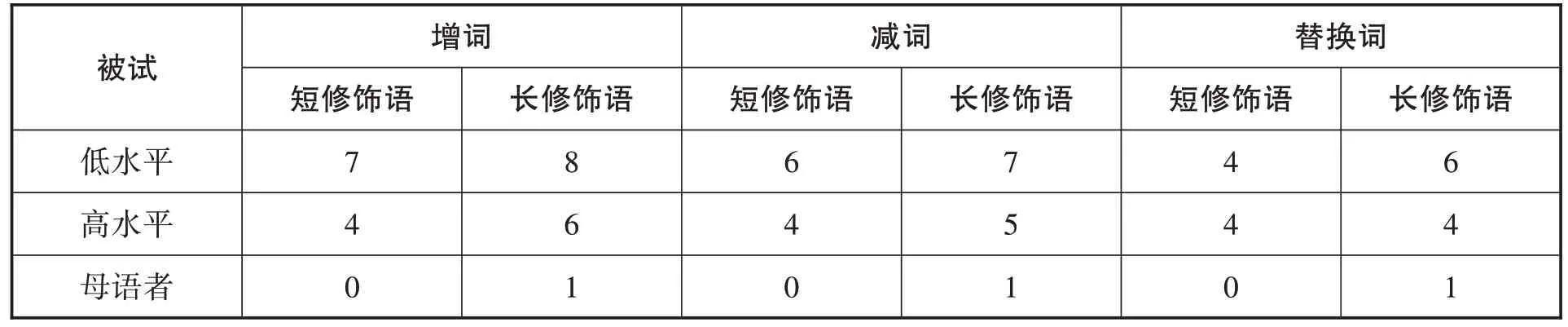
表8:實驗二增減、替換詞的總個數
修飾語的長短對增減、替換詞無顯著影響。減詞發生在 “的” “在”等功能詞上。替換詞出現在 “他” “這里”等代詞或是 “很” “非常”等副詞上。增詞也分兩種:(1)根據語義增加 “了” “的”等功能詞,例如 “我(的)朋友很喜歡踢足球”;(2)重復某個詞,以贏得更多的回憶時間,例如 “一斤這么小的蘋果應該(應該)不貴”。
3.3 討論
實驗二結果表明,成分長度對學習者的漢語口語韻律組塊有影響,這種影響要分不同的指標來看:修飾語越長,低水平組的停頓率就越高,語流長度則無明顯變化;修飾語的長短,對高水平組的停頓率無顯著影響,而修飾語越長,其語流長度也越長。
長度對第二語言韻律組塊的影響,與第一語言 “句法-韻律的間接關系論”一致,即韻律組塊依據的是口語表達結構而非句法結構(Gee&Grosjean,1983)。長度的調節,建立在詞匯和句法通達的基礎上,用來保證組塊的語義完整性和口語產出的自然性(Breen et al.,2011),因而不如語言本身特征,例如句法成分性質對韻律組塊的影響大。這一點可從實驗二中得到印證:學習者的組塊表現,與實驗一相比更接近母語者,受修飾語長度的負面影響較小。盡管如此,學習者的韻律組塊仍受其認知加工方式的制約:修飾語長度的增加,使組塊內部的句法結構變復雜,學習者依托控制性加工的句法計算就需要更多的注意力資源(Robinson,2003)。同時,復述時間也變長,完成復述任務也需要更多的注意力資源(Koelega,1996)。一旦這些過程消耗的注意力資源增加,韻律組塊的其他方面,例如語義通達所能動用的認知資源就會減少,組塊結果也就受影響。不過,學習者的增減、替換詞操作,依舊不受修飾語長短的影響,所以其句子層面的韻律組塊表現,與句法計算而非詞的組塊有關。
母語者的韻律組塊不受修飾語長度的負面影響,反而能根據其長短來調整組塊的大小。這種策略被稱為 “壓縮組合”策略,便于母語者充分利用注意力資源,減少不必要的組塊邊界。學習者,特別是高水平組,在本實驗中的組塊策略與母語者一致,但其邊界數量仍較多,且常出現在高一級的句法成分,例如主語和謂語之間。當修飾語長度增加時,又會在修飾語內部,即定語和中心語之間設定邊界。這表明,高水平組的韻律組塊仍受控制性加工的句法計算影響,而不是像母語者一樣,依靠語義聯想和長度調節來進行。
實驗還發現,長度在停頓率和語流長度上的作用不完全一致:低水平組的停頓率受修飾語長度的負面影響較大,高水平組的語流長度受其正面影響較多。這與Towell等人(1996)的研究結果一致,即存在 “語流長度增加但停頓率不變”或是 “語流長度不變但停頓率減少”的韻律組塊表現。這些不一致的現象反映了具體語言材料的認知加工難易度和第二語言認知加工能力的非線性發展趨勢。再者,停頓率與語流長度考查的韻律組塊的維度不同:停頓率的基本單位是音節,考查組塊的切分;語流長度的基本單位是句法詞,考查組塊的成分組合(曹建芬,2011)。二者在實驗中的不同表現也表明,韻律組塊存在切分與組合兩個子過程,而這兩個過程在認知加工上有何區別,值得進一步探究。
4.結語
研究通過兩個看后復述實驗,證實了句法成分的性質和長度,對學習者漢語口語韻律組塊的影響,這種影響可歸結為句子層面句法計算的注意力資源分配與認知加工方式的問題。學習者要想提高韻律組塊能力,需習得母語者的 “壓縮組合”策略,將句法計算程序化的同時,依靠語義聯想而非分析性的句法成分組合,來產出句子。
研究對第二語言口語教學的啟示如下:首先,應增加口語的韻律組塊而非句法詞和句法短語的輸入,例如魏巖軍(2017)中提到的 “最近幾天” “從來都不”等多詞短語,幫助學習者形成長時記憶里依靠語義聯想來整體提取的組塊。其次,應加強工作記憶作用下的即時組塊練習,例如在不同語境下重復同一組塊,或將其與不同的組塊組合,例如 “從來都不”+ “吃”, “從來都不”+ “說”。只有不斷激活組塊的句法計算過程,將控制性加工的句法成分組合,轉變為程序自動化的產出編碼,才能使學習者的漢語口語韻律組塊擺脫注意力資源的限制,將更多的工作記憶運用于語義聯想下的組塊加工。這樣一來,學習者就能依據句子的語言特征,例如句法結構和長度,來伸縮調整組塊的大小,進行語義完整且流利的口語表達。

附錄1:實驗一實驗材料

附錄2:實驗二實驗材料
猜你喜歡
時代英語·高三(2024年3期)2024-09-03 00:00:00
中華詩詞(2021年3期)2021-12-31 08:07:22
大連民族大學學報(2021年2期)2021-07-16 05:41:42
語言與文化論壇(2019年4期)2019-03-29 06:02:00
中華詩詞(2018年3期)2018-08-01 06:40:40
中華詩詞(2018年11期)2018-03-26 06:41:32
國際漢語學報(2016年2期)2016-05-17 04:04:13
國際漢語學報(2016年2期)2016-05-17 04:04:09
國際漢語學報(2016年2期)2016-05-17 04:04:08
瘋狂英語(雙語世界)(2015年1期)2016-01-08 06:07:37
