深度對比學習綜述
2023-01-16 07:35:46張重生李岐龍鄧斌權陳承功
自動化學報 2023年1期
關鍵詞:方法
張重生 陳 杰 李岐龍 鄧斌權 王 杰 陳承功
近年來,以深度學習為代表的新一代人工智能技術取得了迅猛發展,并成功應用于計算機視覺、智能語音等多個領域.然而,深度學習通常依賴于海量的標注數據進行模型訓練,才能獲得較好的性能表現.當可用的標注數據較少、而無標注數據較多時,如何提高深度學習的特征表達能力是亟需解決的重要現實需求.自監督學習[1]是解決該問題的有效途徑之一,能夠利用大量的無標注數據進行自我監督訓練,得到更好的特征提取模型.
早期的對比學習起源于自監督學習,通過設置實例判別代理任務完成自監督學習的目標.具體而言,對比學習首先對同一幅圖像進行不同的圖像增廣,然后衡量得到的圖像對特征之間的相似性,旨在使同一幅圖像增廣后的圖像對特征之間的相似度增加,而不同圖像特征之間的相似度減小.隨著技術的發展,對比學習已經擴展到監督和半監督學習中,以進一步利用標注數據提升模型的特征表達能力.
近年來,基于深度學習的對比學習技術取得了突飛猛進的發展.典型的對比學習方法有SimCLR[2](Simple framework for contrastive learning of visual representations),MoCo[3](Momentum contrast),BYOL[4](Bootstrap your own latent),SwAV[5](Swapping assignments between multiple views of the same image),SimSiam[6](Simple siamese networks) 等算法.這些技術通常基于類孿生神經網絡的網絡架構,但訓練過程中所用的圖像對為同一幅圖像分別增廣后得到的圖像對 (正樣本對),或不同圖像分別增廣后構成的圖像對 (負樣本對).深度對比學習通過大量的正負樣本對間的比對計算,使得神經網絡模型能夠對數據自動提取到更好的特征表達.CPC[7](Contrastive predictive poding) 是深度對比學習的奠基之作,該算法通過最大化序列數據的預測結果和真實結果之間的相似度 (一致性程度),優化特征提取網絡,并提出InfoNCE 損失,該損失如今已廣泛地應用在對比學習研究中.Khosla 等[8]提出監督對比學習損失(Supervised contrastive learning loss,SCL loss),將對比學習的思想擴充到了監督學習中,旨在利用有標注的數據進一步提升模型的特征表達能力.Chen 等[9]設計了半監督對比學習算法,首先對所有數據進行對比學習預訓練,然后使用標注數據將預訓練模型的知識通過蒸餾學習的方法遷移到新的模型中.
目前,很少有系統總結對比學習最新進展的英文綜述論文[10-12],中文綜述論文更是極度缺乏.因此,學術界迫切需要對深度對比學習的最新文獻及進展進行全面系統的總結、歸納和評述,并分析存在的問題,預測未來發展趨勢.本文聚焦視覺領域的深度對比學習技術,系統梳理深度對比學習2018 年至今的技術演進,總結該方向代表性的算法和技術.如圖1 所示,本文首先將深度對比學習的相關技術歸納為樣本對構造方法層、圖像增廣層、網絡架構層、損失函數層及應用層5 大類型.然后,綜合歸納現有技術的特點及異同之處,并分析其性能表現,指出尚未解決的共性問題及相關挑戰,最后勾勒該領域的未來發展方向與趨勢.
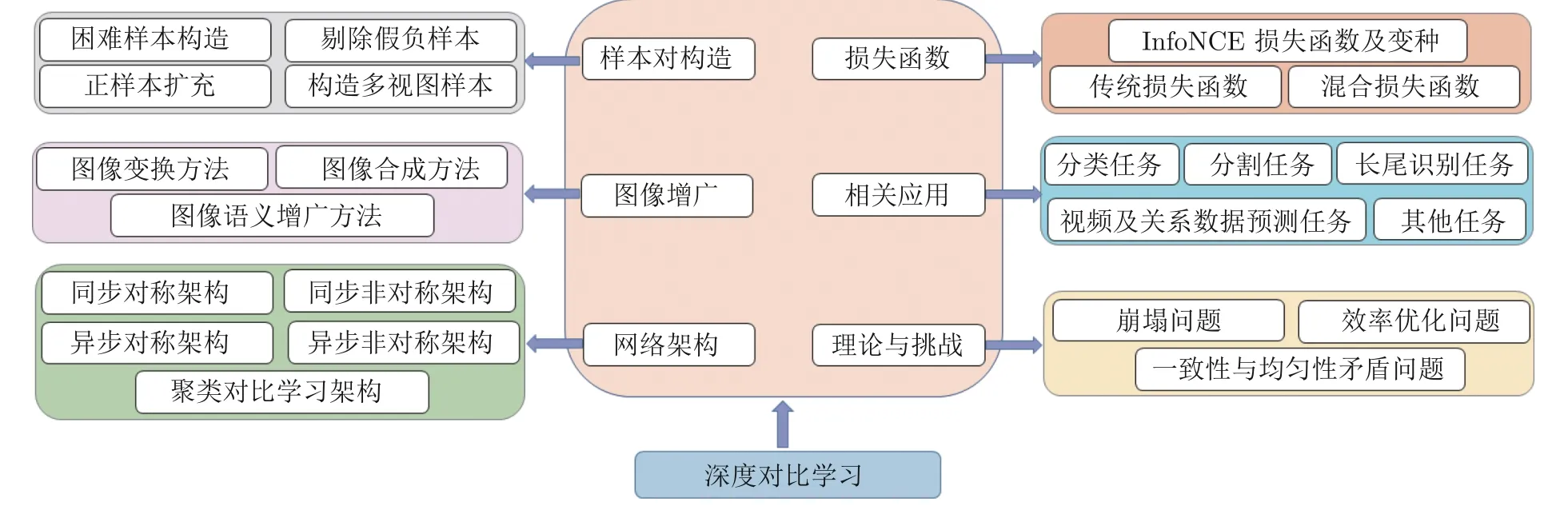
圖1 對比學習方法歸類Fig.1 Taxonomy of contrastive learning methods
本文的主要貢獻概括如下:
1) 基于一種新的歸類方法,將現有的深度對比學習工作進行了系統總結;
2) 比較分析了不同對比學習方法的區別和聯系,及其在基準數據集上的性能表現;
3) 討論了當前對比學習研究存在的挑戰,展望了未來的研究方向.
本文的剩余章節結構安排如下:第1 節介紹對比學習的背景知識.第2 節引入本文提出的歸類方法,并對每種類型的方法進行詳細總結.第3 節對現有的對比學習技術進行整體分析,并比較性能表現.第4 節探討對比學習當前存在的挑戰,及未來發展方向.最后是全文總結.
1 背景介紹
1.1 對比學習思想
對比學習的思想有兩個起源,一個是同類數據對比的思想[13],另一個是自監督學習中的實例判別任務[14].文獻[13]最早提出了使用兩幅圖像進行對比學習的思想,主要使用孿生神經網絡[15]進行訓練,旨在拉近同類圖像的特征之間的距離、推遠不同類圖像之間的距離,以獲得更好的特征提取模型.而自監督學習中的實例判別任務,將同一批次中的每個樣本視作一個獨立的類,故類別的數量與該批次的樣本數量相同.通過該設計,將無監督學習任務轉化為分類任務 (實例判別任務,尋找圖像集中與輸入圖像特征相似度最高的圖像).SimCLR[2]和MoCo[3]是最早結合上述兩個思想的方法,它們通過同一幅圖像分別增廣后的圖像對之間的特征比對計算,增強神經網絡模型的特征提取能力,再應用于下游任務中.
1.2 對比學習定義
對比學習的研究目前仍處于不斷發展的階段,尚無明確的定義.為了更清晰直觀的闡述對比學習問題,本文嘗試給出一個對比學習的公式化定義及常用網絡架構,如式(1)及圖2 所示.
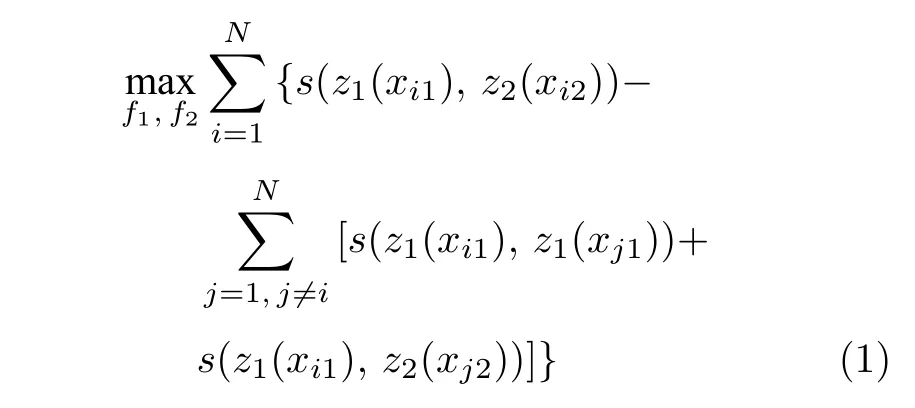
在式(1)中,xi表示數據集X={x1,x2,···,xn}中的一個樣本,z1(xi1) 是圖像xi先經過圖像增強方法T1,再經過圖2 中的分支1 (上部分支) 得到的特征,z2(xi2) 是同一幅圖像xi先經過圖像增強方法T2,再經過分支2 (下部分支) 得到的特征 (正樣本),z1(xj1),z2(xj2) 是另一幅圖像xj經過增廣得到的特征(負樣本).s為兩個特征向量之間的相似度度量方法,默認使用余弦相似度.該公式的目標是最大化相同圖像增廣后的兩個樣本之間的相似度,同時最小化不同圖像經過不同增廣后的特征之間的相似度及不同圖像經過相同增廣后的特征之間的相似度.圖2 是對比學習常用的網絡架構,采用了本文所歸納的同步對稱網絡架構,后續章節將進行詳述.

圖2 常用的對比學習網絡架構Fig.2 Commonly used contrastive learning network architecture
1.3 對比學習與度量學習的關系
對比學習與度量學習[16]之間有較高的關聯性.其相似之處在于學習目標類似,二者都在優化特征空間,使得數據在特征空間中類內距離減小、類間距離增大.度量學習通常需要基于標注數據,而對比學習則不要求樣本必須有標注,其目標是使得同一幅圖像的不同增廣之后的圖像對在特征空間中靠近.
兩者的不同之處在于:
1) 訓練數據構建方式不同
對一個數據集,度量學習通過標簽信息篩選樣本對,分別得到正樣本對和負樣本對.而對比學習的正樣本對是通過同一幅圖像的兩個隨機增廣得到.圖像增廣操作是對比學習的關鍵技術之一,多樣、有效的圖像增廣方法能夠提高對比學習的訓練效果[2].
2) 網絡架構不同
對比學習通常需要在特征提取網絡之后增加小型的投影頭網絡,將特征空間轉換到投影空間中進行損失計算.訓練結束后,將該小型投影頭去掉,僅保留特征提取網絡,用于下游任務.而在度量學習任務中,通常只有特征提取網絡,通過設計度量損失函數優化特征提取模型.
3) 適用情況不同
度量學習需要使用有標注的數據,適用于監督學習;而對比學習不要求數據有標注,適用于無標注的數據及有標注或部分標注的數據,支持監督、無監督和半監督學習.
1.4 對比學習與自監督學習的關系
初始的對比學習方法[2-3]是自監督學習的一種,目標是通過無標注數據的自我監督學習,獲得良好的特征表達.隨著技術的發展,對比學習研究已經拓展到監督學習和半監督學習中(如第1.3 節所述).
對比學習與無監督學習的關系.無監督學習大體可分為生成式學習和對比式學習.對比學習是實現無監督學習的一種重要途徑,能夠學習到更好的特征表示.
對比學習與監督學習的關系.隨著對比學習技術的發展,在構造對比學習所需的樣本對時,若數據有標注或部分標注,則屬于同一類的圖像都可以用于構造正樣本,而不再局限于同一幅圖像,這樣可以增加正樣本對的多樣性,有利于提取更好的特征表達.另外,對比學習也可以作為監督學習的前置,進行模型預訓練,以進一步提高監督學習的模型性能.
1.5 常用數據集介紹
本節所介紹的數據集總結如表1 所示:
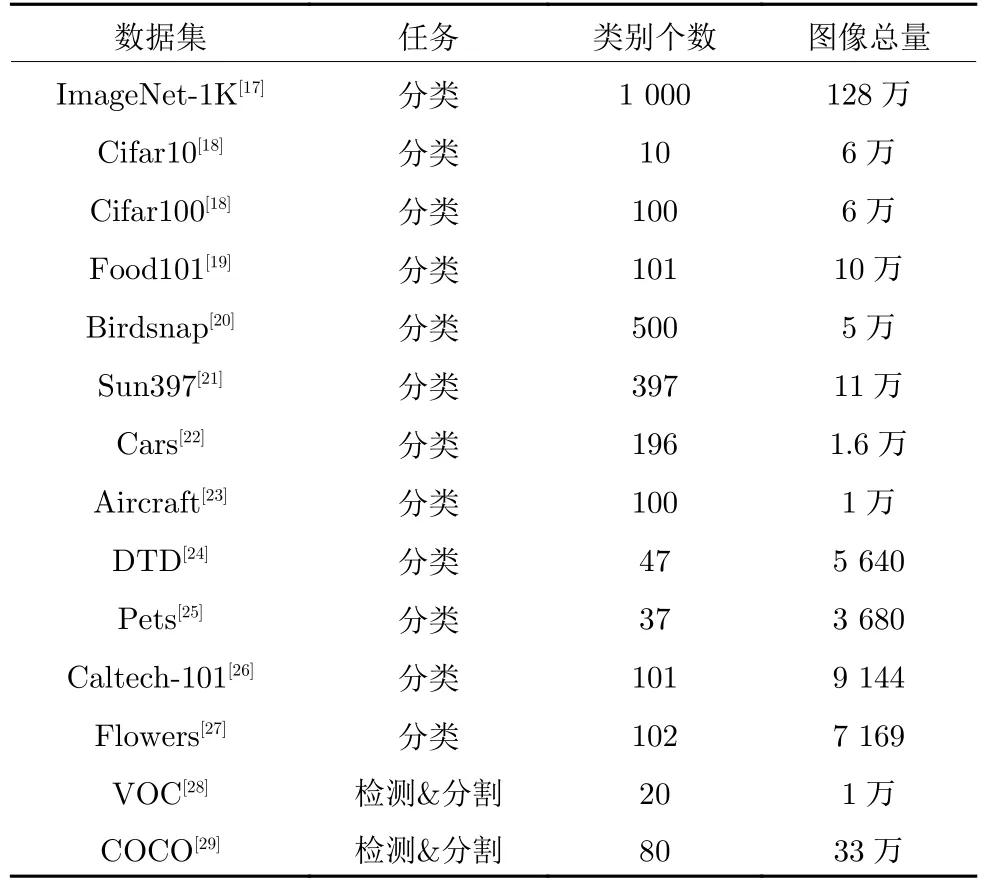
表1 對比學習常用數據集總結Table 1 Summary of common datasets
ImageNet-1K[17]是對比學習方法最常用的數據集,該數據集是ImageNet 數據集的一個子集,包含1 000 個類別,訓練集約128 萬幅彩色圖像.該數據集因其包含的圖像種類多、數量多以及樣本質量高的特點常常被認為是最有挑戰性的數據集之一.該數據集各類樣本數量分布相對均衡.
Cifar10和Cifar100[18]是常見的應用于圖像分類的數據集,Cifar10 包含10 個類別的6 萬幅彩色圖像,Cifar100 包含100 個類別的6 萬幅彩色圖像.Cifar10和Cifar100 的圖像尺寸均為 32×32 像素.
常用于分類任務評估的數據集還有:Food101[19]包含101 個類別的食物,共10 萬幅圖像.Birdsnap[20]包含500 個類別的鳥的圖像,共4.7 萬幅訓練集圖像.Sun397[21]包含397 個類別的場景圖像,共有近11 萬幅圖像.Cars[22]包含196 個類別的汽車圖像,共有1.6 萬幅圖像.Aircraft[23],包含102 個類別的飛行器圖像,共有約1 萬幅圖像.DTD[24],包含47個類別的紋理圖像,共有5 640 幅圖像.Pets[25],包含37 個類別的寵物圖像,共有3 680 幅訓練集圖像.Caltech-101[26],包含101 個類別的圖像,共有9 144 幅圖像.Flowers[27],包含102 個類別的花卉圖像,共有7 169 幅圖像.
VOC[28]數據集常用來評估目標檢測和分割任務,總共包含20 類圖像,共約1 萬幅圖像,包含13 000多個物體目標.
COCO[29]數據集是一個可用于大規模目標檢測、分割和關鍵點檢測的數據集,該數據集包含有80 個目標類別、91 個物品類別,約33 萬幅彩色圖像組成.
1.6 評價方法
目前,衡量對比學習模型的效果最常用兩種評估方法是線性評估方法和微調(Finetune)評估方法.在進行評估之前,將預訓練好的模型作為下游任務的主干網絡,然后,根據下游任務和數據集的要求,在主干網絡后加入對應的任務頭網絡,最后采用線性或微調方法進行評估.
線性評估方法.采用該方法評估主干網絡時,需要凍結主干網絡參數,只訓練下游任務頭網絡.然后采用下游任務數據集中的測試集對模型的能力進行評估.
微調評估方法.采用該方法評估主干網絡時,采用下游任務的數據訓練由主干網絡及任務頭組成的整體網絡,然后同樣采用下游任務數據集的測試集評估模型.
1.7 本文符號定義
本文中所使用的數學符號定義說明如表2 所示:

表2 本文所用符號總結Table 2 Summary of the symbols used in this paper
2 對比學習研究現狀
在本章內容中,首先引入所提出的歸類方法,在此基礎上歸納總結國內外對比學習研究成果.值得注意的是,對比學習亦深受我國學者的關注,很多優秀的對比學習論文雖然發表在國外學術會議和刊物上,但作者為國內學者.
2.1 歸類方法
本文提出一種新的歸類方法,以對最新的對比學習工作進行系統歸納總結.如圖1 所示,按照對比學習的整體流程,將現有方法劃分為樣本對構造層、圖像增廣層、神經網絡架構層、損失函數層以及應用層等類型.
圖3 將每種類型的對比學習方法進行細分及可視化表示.其中,樣本對構造層方法可以細分為困難樣本構造、剔除假負樣本、正樣本擴充及構造多視角樣本四種方法.圖像增廣層可以細分為圖像變換、圖像合成及圖像語義增廣三種方法.網絡架構層方法可以分為同步對稱、同步非對稱、異步對稱、異步非對稱對比學習,及基于聚類的網絡架構.特征提取網絡主要使用ResNet[30](Residual neural network)、Transformer[31]等主流神經網絡結構,損失函數層分為基于互信息的損失函數、傳統損失函數和混合損失函數.下面將分別介紹各類型的方法.

圖3 對比學習的整體流程及各模塊的細分類方法Fig.3 Overall framework of the contrastive learning process and the sub-category of each module
2.2 樣本處理及樣本對構造方法
在對比學習過程中,樣本對的選擇指的是對數據集的采樣過程.1) 對無標注數據集,通常采用隨機采樣的方法構建一個批次的數據,因此一個批次的數據可能存在類別分布不均勻的情況,導致假負樣本的出現及困難負樣本過少的問題;2) 對有標注數據集,通過標簽信息采樣訓練數據,能夠有效提高對比學習效果.下面將分別介紹各種細分的樣本處理及樣本對構造方法.
2.2.1 困難樣本構造
如圖4 所示,圖(a) 是狗,圖(b) 是狼,在選擇樣本進行模型訓練的時候,這兩種動物在視覺上相似度很高,同時在經過網絡提取特征之后,他們的特征之間的余弦相似度也比較高,容易被誤認為是相同類的樣本,而這兩張圖像并非同類,這種情況稱為困難負樣本對,同理,若兩張圖片屬于同一類,但特征相似度不高則稱為困難正樣本對.多個研究表明,困難負樣本和困難正樣本對在對比學習中具有至關重要的作用.

圖4 困難負樣本對示例Fig.4 Example of hard negative pair
Zhu 等[32]通過對MoCo 算法訓練過程的可視化分析,發現增加困難樣本在同批次中的比例能夠提升網絡在下游任務中的表現.通過這一現象,作者提出了在特征空間上將負樣本對圖像對應的兩個特征向量插值,正樣本對圖像對應的兩個特征向量外推,構造新的、更加困難的樣本對,最終提高了對比學習的效果.采用類似的思想,Kalantidis 等[33]提出了一種合成困難負樣本的方法,該方法也作用于特征空間中,首先通過余弦相似性度量方法將輸入樣本對應的所有負樣本進行降序排序并取前K個樣本,然后使用與文獻[32]相同的方法依次合成K個困難負樣本.但是該方法只適用于帶隊列存儲庫 (Memory bank) 的對比學習模型.Zhong 等[34]提出了一種結合圖像混合 (Mixup) 技術的困難樣本構造方法,該方法首先利用Mixup 方法合成新的樣本,然后通過余弦相似性度量方法挑選困難的合成樣本,加入到原始數據中進行對比學習訓練,提高了對比學習的訓練效果.
2.2.2 剔除假負樣本
如圖5 所示,在同一批次的訓練圖像中,如果輸入圖像和同一個批次的其他某一張圖像是同一類,但是在計算損失的時候把它們誤歸為負樣本對,這種情況就稱為假負樣本對.在對比學習中,負樣本的質量和數量是制約最后訓練效果的關鍵,如果在訓練的批次中出現假負樣本,會降低最后的網絡效果.

圖5 假負樣本示例Fig.5 Example of false negative pair
為了解決該問題,Huynh 等[35]提出一種啟發式的方法來避免假負樣本對訓練的影響.該方法將同一幅圖像使用多種增廣方法得到的所有圖像作為該幅圖像對應的支持集,然后將同一個批次中該圖像對應的每個負樣本依次與其支持集中的每幅圖像進行特征相似性計算,并將前K個最相似的負樣本視為假負樣本,認為這些負樣本與輸入圖像具有相同的類標簽.得到假負樣本后,可以直接剔除假負樣本,或將假負樣本移入到正樣本集合.通過大量實驗,作者證明了兩種處理方式都能提高對比學習的效果.針對相同的問題,Chuang 等[36]提出修正Info-NCE 損失函數中所有負樣本相似度的指數冪和,以降低可能采樣到的假負樣本對損失值帶來的影響.
2.2.3 正樣本擴充法
擴充正樣本有助于提高對比學習的效果.這里的擴充不包含圖像增廣方法,而是指從可用的數據資源中尋找隱藏的、與輸入樣本類別相同的圖像的方法.在監督對比學習中,由于同類樣本已知,一般無需擴充正樣本.而在無監督對比學習中,若圖像數據沒有標注信息,一般無法進行正樣本擴充.但在一些特殊場景下,如行人重識別、遙感圖像處理、視頻分析,可以基于某些假設,對正樣本進行擴充.
Kim 等[37]將Mixup 方法應用到了對比學習領域,提出MixCo 方法,該方法將經過增廣之后的兩幅異類圖像進行Mixup 操作合成新的圖像.然后對所有合成的圖像,計算其InfoNCE 損失,由于每幅合成圖像對應兩個類別,因此可以認為是擴充了每個樣本對應的正樣本個數.最終損失由原始圖像上的對比損失和上述合成圖像上的對比損失構成.
在行人重識別領域,王夢琳[38]提出一種度量不同相機中行人關聯性的方法,將關聯性強的樣本視作同類樣本,以擴充正樣本的數量.
在遙感圖像處理中,基于同一地點的遙感圖像中的內容隨時間變化較小的特點,Ayush 等[39]使用同一地點的不同時刻的遙感圖像擴充正樣本.
在視頻分析中,Qian 等[40]基于鄰近的視頻幀圖像可作為同類樣本的假設,擴充正樣本,用于對比學習.Kumar 等[41]同樣采用這一假設擴充正樣本.Han 等[42]發現對于兩個不同的視頻片段,做的動作相同時,在RGB 視角下,提取的特征相似度不高,但在光流 (Optical flow) 視角下,提取的特征相似度很高,反之亦然.基于以上發現,作者提出將光流視角下相似度高的視頻片段作為RGB 視角下的正樣本,同樣,可采用相同方法擴充光流視角下的正樣本.
在半監督學習領域,Wang 等[43]提出通過部分標簽訓練的分類器,在當前訓練批次中利用余弦相似度指標尋找正樣本的方法,擴充正樣本數量.Yang 等[44]采用同樣的思路設計類感知模塊,擴充正樣本數量.
2.2.4 構造多視圖樣本
多數對比學習方法所使用的數據只有一個來源(又稱為同一個視圖).針對該問題,研究人員探索使用多視圖數據的方法提升對比學習的效果.Tian等[45]提出基于多視圖特征的對比學習方法.該方法將同一幅圖像在多個不同視圖下的表達分別進行特征提取,然后進行對比學習,有利于提升模型的效果.在視頻分析中,Rai 等[46]對同一幅圖像分別提取光流、語義分割、關鍵點等多視圖特征,然后進行對比學習,提升了視頻特征表達能力.
2.3 圖像增廣方法
2.3.1 圖像變換方法
圖像增廣是對比學習的天然組成部分,以產生網絡所需的輸入樣本對.如圖6 所示,傳統的圖像變換方法有隨機裁剪、顏色失真、灰度化等方法.需要說明的是,單一的圖像變換方法不利于有效的對比學習.SimCLR 綜合對比了一系列圖像變換的效果,發現由隨機裁剪和顏色失真組成的變換組合能夠獲得更好的對比學習效果.

圖6 常用圖像變換方法示例Fig.6 Example of common image augmentations
在眾多的圖像變換方法之中,裁剪通常是必須的變換方法之一,但可能存在經過裁剪后的正樣本對信息重疊過多或者完全不重疊的情況.如圖7(a)所示,如果裁剪到的正樣本對是兩個矩形框中的區域,那么該圖像對并不能促進對比學習,這種情況稱為錯誤正樣本 (False positive,FP).圖7(b)給出了裁剪的兩個圖像區域重疊過多的情況,若選擇它們作為正樣本對,也無助于對比學習.Peng 等[47]針對以上問題,首先利用熱圖定位目標區域,然后采用中心抑制抽樣策略,在目標區域內離物體中心越遠的像素點被采樣到的概率越高.得到采樣點后,以采樣點為中心,并使用隨機生成的寬高,進行最終的圖像裁剪操作.在SwAV 中,作者提出了一種多裁剪策略 (Multi-crop),該策略給編碼器提供多個不同尺度的裁剪圖像作為正樣本,并驗證了該策略有助于提高對比學習算法的性能.

圖7 裁剪操作對正樣本對構造的影響示例Fig.7 The influence of constructing positive pairs by image crop
2.3.2 圖像合成方法
圖像合成不同于圖像變換,前者能夠生成新的內容.在視頻分析中,Ding 等[48]提出復制粘貼的圖像合成方法,將所選視頻幀的前景區域粘貼到其他視頻幀的背景圖像中,得到合成的視頻幀,通過這種簡單的合成方法,使得對比學習模型能夠更加關注前景信息,提取到更加良好的特征表達.
2.3.3 圖像語義增廣方法
圖像語義增廣是一種直接對圖像中物體的語義進行修改的圖像增廣方法,如將圖像中的物體的顏色或角度進行改變.現有的一些語義增廣算法[49-51]已證明其在不同問題和應用中的有效性.相較于圖像變換方法和圖像合成方法,圖像語義增廣是一種更強的圖像增廣方法.Tian 等[52]認為最小化在不同增廣下樣本間的互信息有利于提高對比學習的效果,為了最小化訓練樣本對之間的互信息,作者引入了對抗訓練策略尋找可以最小化訓練樣本對互信息的圖像變換編碼器Sg,通過與InfoNCE 聯合訓練,獲得了更適用于下游任務的模型,經過訓練得到的圖像變換編碼器Sg可認為是一個語義增廣器.
2.4 對比學習網絡架構設計
根據對比學習網絡架構的更新方式是同步或異步,及該網絡架構是對稱或非對稱,本文將對比學習所涉及的網絡架構劃分為同步對稱、同步非對稱、異步對稱和異步非對稱4 種類型.同步更新指的是對比學習網絡的兩個分支 (分支1和分支2) 同時進行梯度更新,異步更新指的是兩個分支網絡的權值更新方法不同.對稱指的是分支1和分支2 的網絡結構完全相同,非對稱則指相反的情況.除此之外,本節還將含有聚類算法的對比學習方法總結為聚類對比學習架構.
2.4.1 同步對稱網絡架構
典型的同步對稱網絡架構如圖8 所示,分支1和分支2 采用相同的網絡結構,并且同時采用梯度更新.
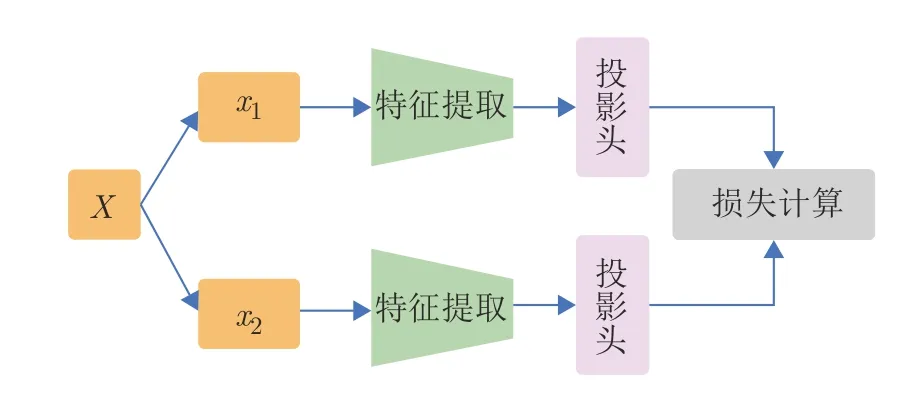
圖8 同步對稱網絡架構Fig.8 The architecture of synchronous symmetrical network
SimCLR[2]是最早提出采用同步對稱網絡架構的對比學習工作.該網絡架構采用了結構相同的兩個網絡分支,每一個分支都包含特征提取網絡和投影頭.特征提取網絡可以是任意的網絡結構,例如ResNet和Transformer,投影頭一般使用多層感知機 (Multilayer perceptron,MLP).如圖8 所示,使用該網絡架構進行對比學習的前向過程為:首先,輸入一個樣本,經過兩種圖像增廣方法產生成對的訓練樣本.然后,通過特征提取網絡和投影頭將樣本輸出到投影空間.最后,在投影空間進行損失計算并回傳梯度,更新特征提取網絡和投影頭的參數.同步對稱網絡架構除了可以用于自監督對比學習之外,Khosla 等[8]將該類網絡架構應用到了監督對比學習之中.值得注意的是,采用該類網絡架構的對比學習算法若想獲得良好效果,往往需要在訓練時采用很大的批次進行訓練,比如1 024 或2 048.
2.4.2 同步非對稱網絡架構
典型的同步非對稱網絡結構如圖9 同步非對稱網絡所示,分支1和分支2 采用不同的網絡結構,但同時采用梯度更新.同步非對稱網絡架構與同步對稱網絡架構的相同之處在于兩個分支都進行了梯度更新,不同之處在于前者的兩個分支的網絡結構不同,而后者相同.
Van 等[7]提出一種基于該種網絡架構的對比預測編碼方法CPC.在該方法中,分支1 的輸入為某一個時間點的數據,分支2 的輸入為未來某一個時間點的數據,訓練的目標是利用分支1 的輸出預測分支2 的輸出,如圖9 所示,然后計算對應的預測損失.在CPC 算法之后,衍生出很多改進的算法[41,53],這些方法均采用典型的同步非對稱網絡架構,其主要改進之處在于采樣方法或損失函數.
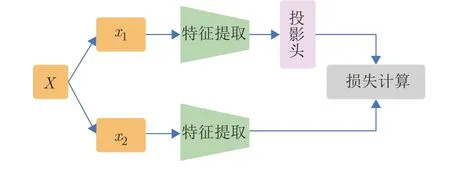
圖9 同步非對稱網絡架構Fig.9 The architecture of synchronous unsymmetrical network
除了如圖9 所示的同步非對稱架構之外,還存在一些其它形式的同步非對稱的網絡架構,主要有如下兩種形式:1) 分支1 與分支2 均含有投影頭,但投影頭結構不相同[54-55].2) 分支1和分支2 的特征提取網絡數量不相等[56-57].
Nguyen 等[54]將對比學習方法應用于網絡結構搜索任務 (Neural architecture search,NAS),提出CSNAS 方法,該方法構造了一個類似于上述第1 種形式的同步非對稱網絡架構.Misra 等[55]在分支2 中使用拼圖代理任務進行特征學習,因此在分支2 的投影頭之前還包含拼接操作以及多層感知機的映射,構成了符合上述第1 種形式的同步非對稱網絡架構.
Bae 等[56]提出自對比學習 (Self contrastive learning,SelfCon) 方法,該方法構造了一個類似于上述第2 種形式的同步非對稱網絡架構,在該方法中,將一個特征提取網絡和一個投影頭組合在一起,稱為一個主干網絡塊,分支1 采用多個主干網絡塊進行特征映射,分支2 從分支1 中的某個節點引出,通過一次主干網絡塊映射得到另一個視圖下的特征,最后進行損失計算.類似地,Chaitanya 等[57]提出可用于圖像分割的對比學習方法,在該方法中,分支1和分支2 共享編碼器,但分支1 直接在編碼器后加入投影頭,分支2 在編碼器后加入一個解碼器,然后再加入投影頭.
2.4.3 異步對稱網絡架構
在異步對稱的網絡架構中,分支1和分支2 采用相同的網絡結構,但是兩個分支的神經網絡權值更新方式不同,因此稱作異步更新,如圖10 所示.
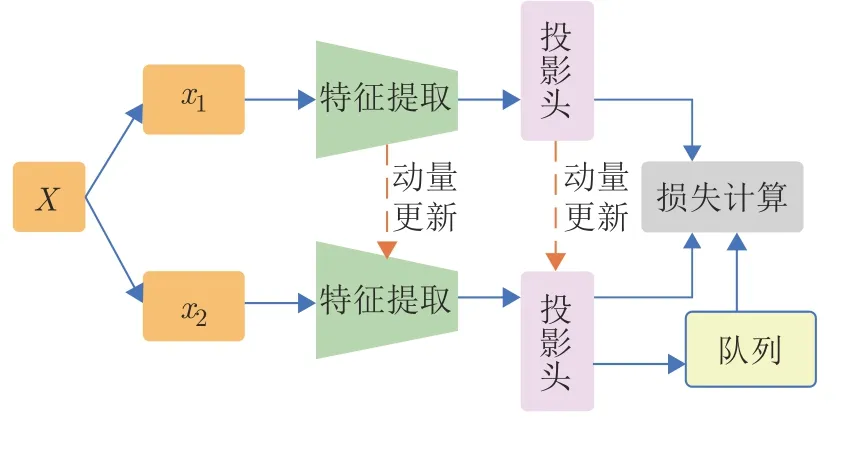
圖10 異步對稱網絡架構Fig.10 The architecture of asynchronous symmetrical network
MoCo 是經典的采用異步對稱網絡架構的對比學習方法.其中,分支1 中的特征提取網絡和投影頭采用SGD 等梯度更新方法更新權值,而分支2的特征提取網絡和投影頭采用動量更新的方式,動量更新的公式如式 (2) 所示:
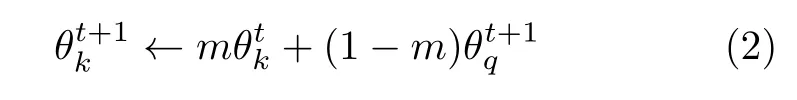
其中,是分支2 中動量特征提取網絡在時刻t的參數值,是分支1 中特征提取網絡經過t時刻梯度反傳訓練過后的參數值,m是 0-1 之間的動量系數.這種動量更新機制能夠有效防止極端樣本對參數更新影響過大的問題.
在對比學習中,負樣本的數量對最終的模型效果起決定性的作用.在原始的對比學習方法中,負樣本的來源是同批次的訓練數據,為了增加負樣本的數量,必須采用大批次的數據來支撐訓練,但這樣會造成存儲資源過大,計算消耗巨大的問題.MoCo設計了隊列 (Queue) 結構,存儲一定數量的之前批次用到的樣本的特征,當隊列容量滿時,最老樣本的特征出隊,最新樣本的特征入隊.在MoCo 方法中,對比學習所需的負樣本將從該隊列中抽樣產生,避免了原始對比學習方法為獲得較多負樣本而構建大的批容量帶來的問題.簡言之,該隊列結構減小了對存儲資源的要求,又取消了訓練必須采用大批次數據的約束,提升了計算速度.后續的基于異步對稱網絡架構的方法都將該隊列結構作為其默認的組成部分.
近年來,隨著Transformer 技術的發展,研究者將其引入到計算機視覺領域,例如ViT[58].在對比學習的研究中.Caron 等[59]提出了一種名為DINO(Self-distillation with no labels) 的異步對稱對比學習方法,該方法采用Transformer 作為骨干網絡,并將自監督對比學習轉換為蒸餾學習的任務,將分支1 視作學生網絡,將分支2 視作教師網絡.學生網絡采用梯度回傳更新參數,教師網絡采用動量更新方式更新參數.
2.4.4 異步非對稱網絡架構
異步非對稱網絡架構指的是分支1和分支2 采用不同的網絡結構,同時參數更新方式也不同.異步非對稱網絡架構與異步對稱網絡架構的相同之處在于兩個分支的更新方式相同,不同之處在于前者的兩個分支的網絡結構不同,而后者相同.
異步非對稱網絡架構存在兩種形式,一種是采用MoCo 作為主干網絡,但是投影頭數量不一致,以BYOL[4]方法為典型代表.另一種是網絡架構不對稱,同時采用梯度交叉更新的方法,以SimSiam[6]方法為典型代表.
BYOL 的網絡結構如圖11 所示.其主干網絡結構是MoCo,分支2 的網絡參數采用動量更新機制.BYOL 是首個只采用正樣本進行對比學習的工作,但由于訓練集中不存在負樣本,如果上下網絡分支結構完全相同,訓練就有可能出現 “捷徑解”的問題 (亦可稱為 “網絡崩塌”問題),“捷徑解”指的是對不同的輸入,輸出的特征向量完全相同.為了解決這一問題,BYOL 在分支1 中額外增加了一個預測頭 (MLP),構成了非對稱網絡架構,并將對比學習的實例判別代理任務替換為比對任務,即分支1 最終得到的特征與分支2 最終得到的特征要盡可能的相似.BYOL 的性能提升歸因于以下兩點設計:1) 良好的模型初始化.2) 在投影頭和預測頭中加入正則化技術.如果沒有這兩種設計,BYOL 仍可能出現 “捷徑解”的問題[60].

圖11 BYOL 網絡架構Fig.11 The architecture of BYOL
Chen 等[61]提出了一種基于視覺Transformer的異步非對稱網絡架構MoCov3.MoCov3 采了BYOL型異步非對稱網絡架構.在分支1 中額外加入了一個預測頭,分支2 的編碼器采用動量更新,獲得了更好的對比學習效果.
另一種代表性的異步非對稱架構是SimSiam.如圖12 所示,SimSiam 方法也不需要利用負樣本訓練網絡.為了避免網絡出現 “捷徑解”,該方法的兩個分支的網絡結構采用交叉梯度更新的方式.具體而言,訓練分支1 的時候,投影頭放在分支1 的編碼器之后,計算其損失,而分支2 的梯度停止回傳.在訓練分支2 的時候,將分支1 的投影頭接入到分支2 的編碼器之后,并計算損失,而分支1 的梯度停止回傳.這就是交叉梯度更新.
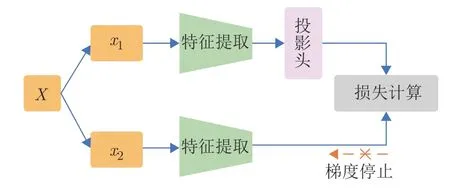
圖12 SimSiam 網絡架構Fig.12 The architecture of SimSiam
2.4.5 聚類對比學習結構
在上述四種網絡架構的基礎上,還可以結合聚類技術進行進一步的優化.
基于實例的對比學習算法在計算損失差別過大,不利于模型學習到良好的語義特征.而聚類算法能夠在無監督情況下自動學習數據的語義信息.因此,一些方法將對比學習與聚類方法結合在起來,嵌入到上述四種網絡架構中.
Caron 等[62]首次將K-Means 聚類算法與無監督深度學習結合,提出深度聚類算法 (Deep cluster),該算法通過K-Means 聚類產生偽標簽,然后利用偽標簽對模型進行自監督訓練.在該方法的基礎上,作者又提出了一種基于聚類的對比學習算法SwAV,該算法采用同步對稱網絡架構訓練特征提取網絡.在分支1和分支2 之間引入聚類中心信息,并計算相關損失,幫助網絡進行訓練.相關的細節在第2.5.2節中給出.
Li 等[63]提出原型對比學習算法 (Prototypical contrastive learning,PCL),該方法采用異步對稱網絡架構,分支1 采用梯度更新,分支2 采用動量更新.在PCL 的前向傳播過程中,當分支2 對輸入樣本提取特征之后,采用K-Means 算法依據樣本特征進行聚類.然后,將分支1 得到的每個樣本特征與分支2 的所有聚類中心計算聚類對比學習損失,將分支1 的樣本與其所屬的聚類中心的向量視作正樣本對,其余為負樣本對.最終的損失函數由聚類對比學習損失和原有 (實例) 對比學習損失構成.聚類對比學習損失計算的目標是最大化樣本實例與其相對應的聚類中心特征之間的相似度,因此這種設計也能在一定程度上緩解實例對比學習中的假負樣本問題.PCL 僅在分支2 上進行聚類計算,后續工作嘗試在兩個分支上都進行聚類,如Wang 等[64]提出的方法,將分支1和分支2 都進行聚類計算,然后進行交叉聚類對比學習損失計算.
在現實圖像數據集中,往往存在多層級的語義結構,例如在"狗"這個分類的數據中,還存在 “哈士奇”、“金毛”、“雪納瑞”等不同品種的狗.現有的很多對比學習方法沒有考慮到數據集的這個特點.針對這一問題,Guo 等[65]提出了一種分層聚類的對比學習方法(Hierarchical contrastive selective coding,HCSC),HCSC 的網絡架構如圖13 所示,和PCL 的神經網絡架構相同,都屬于異步對稱網絡架構.HCSC 通過多層聚類來實現對數據集中存在的分層語義現象的模擬.具體而言,在分支2 的特征提取操作之后,首先,通過K-means 算法計算第一層聚類中心,隨后針對第一層聚類中心再使用K-means 算法尋找下一層的聚類中心,循環N次,得到N個層次的聚類向量,完成對N層語義的模擬.同時HCSC 還提出一種新的負樣本采樣方法:在每一層語義結構中尋找與當前輸入樣本特征的原型相似度較低的樣本作為負樣本.這種采樣負樣本的方法能夠有效緩解采樣到假負樣本的問題.

圖13 HCSC 網絡架構Fig.13 The architecture of HCSC
此外,Li 等[66]提出了一種聚類中心可自動學習的聚類對比學習算法.該網絡設計了一個共享特征網絡的雙分支同步對稱網絡架構,兩個分支分別構建投影頭,即用于實例對比學習的投影頭I,和用于聚類對比學習的投影頭C.投影頭I采用線性激活,投影頭C采用softmax 激活.將投影頭C輸出的矩陣中的列向量作為聚類中心,通過InfoNCE 損失和交叉熵損失聯合訓練模型,在訓練過程中由于投影頭C參數在更新,聚類中心因此也獲得自動更新的能力.
Cui 等[67]提出了一種新的異步非對稱聚類網絡架構PaCo,該方法將聚類思想和MoCo 結合在一起,通過構建一個可隨著模型一同學習的參數化類別中心c,使數據少的類別在訓練中的重要性提升,從而在長尾學習中實現對損失的再平衡.
2.5 損失函數設計
為了實現對比學習的優化目標,研究者使用了多種針對性的損失函數,可以分為基于互信息的損失函數 (InfoNCE 類)、傳統損失函數和混合損失函數.
值得注意的是,對比損失[13]與對比學習損失很容易在字面上產生混淆,實際上,對比損失是一種度量學習損失,只能用于監督學習,且樣本對數據來源與對比學習不同,因此,對比損失不一定是對比學習的損失函數.
2.5.1 InfoNCE 損失函數及變種
對于深度學習模型來說,理想的訓練目標是獲得一個從樣本到特征的映射模型p(z|x;θ),其中x是樣本,z是模型輸出的特征,θ為需要學習的參數.很多自監督學習方法通過交叉熵或均方誤差訓練網絡達到上述目標.然而,基于交叉熵或均方誤差這樣的單峰函數的損失往往效果不好[7].因此Van 等[7]提出通過最大化互信息的方法訓練特征提取網絡.互信息I(X;Y) 是一個概率論中的概念,可以衡量兩個隨機變量X和Y之間的相關性.互信息的定義如式 (3) 所示:
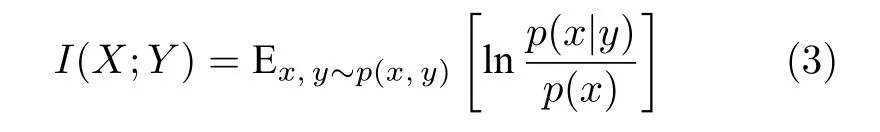
由于直接最大化互信息是十分困難的,因此作者提出了通過InfoNCE 損失來間接優化互信息的方法.InfoNCE 損失的思想是將最大化互信息轉換為真實分布占合成分布的概率密度比的預測問題[68].原始InfoNCE 公式 (4) 所示:
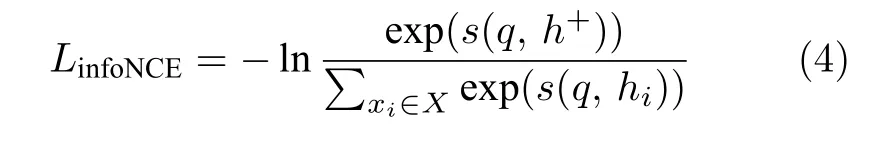
其中,X={x1,···,xN}為采樣的N個樣本,f為特征提取網絡,q=f(xq) 為查詢樣本的特征向量,h+=f(xi) 為xq為對應的正樣本的特征向量.在訓練中,每個查詢樣本xq只對應1 個正樣本xi,其余都視為從噪聲分布里面采樣的負樣本.s為相似度度量函數,這里采用余弦相似度.Van 等[7]和Poole等[69]證明了優化InfoNCE 損失等價于優化變量之間的互信息的下界,并且I(xq,xi)≥lnN -LinfoNCE,可知如果想獲得一個較高的互信息值,需要大批次的樣本參與訓練.
SimCLR 首先將InfoNCE 損失引入到對比學習中來,由于訓練所用的樣本對來自于同一幅圖像的兩次不同增廣,因此InfoNCE 的優化目標變為最大化同一個樣本的兩個不同增廣圖像之間的互信息,SimCLR 中采用的InfoNCE 如式 (5) 所示:
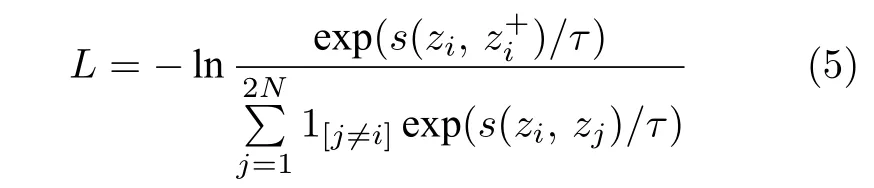
其中,X={x1,···,xN}為采樣的N個樣本,f為特征提取網絡,g為投影頭,T為圖像增廣函數,zi=g(f(T1(xi)))為樣本經過第1種圖像增廣之后產生的投影向量,=g(f(T2(xi)))為樣本經過第2種圖像增廣之后產生的投影向量,為一個指示器函數,當時為1,否則為0.s為相似度度量函數,此處使用余弦相似度函數,即s(u,v)=uTv/(||u||||v||).總結而言,在SimCLR的InfoNCE公式中,分子表示同一個樣本的兩種不同變換得到的正樣本對的特征相似度,分母是不同圖像組成的負樣本集合中的每個負樣本對的相似度的和.
在InfoNCE 引入到對比學習之后,許多方法[3,9,32-33,40,48,52-54,57,70]對其直接調用并擴展到更多的學習任務中.表3 列出了一些對InfoNCE 改動較大的方法,包括ProtoNCE[63],DCL[71],DirectNCE[72],SCL[8],FNCL[35].其中,第一行為原始的InfoNCE損失函數,其他部分為對其改進的損失函數,包括ProtoNCE,DCL,DirectNCE,SCL,FNCL 等損失函數.
1) ProtoNCE 損失函數.與原始InfoNCE 損失函數相比,ProtoNCE 的分子部分將正樣本實例之間的相似度修改為正樣本與其所在的聚類中心之間的相似度,分母部分改為計算樣本與其它聚類中心之間的相似度.具體而言,當前實例特征與其對應的聚類中心互為正樣本對,與其它聚類中心互為負樣本對.在實際操作中,通過設置不同的聚類中心個數對一個批次的數據進行M次聚類,計算M次ProtoNCE 損失,然后求其損失均值,最后得到的效果會更好.
ProtoNCE 方法是在同一個語義層級上進行聚類,但無法獲得分層的語義結構.Guo 等[65]針對該問題提出分層聚類的方法,該方法對每個聚類迭代地進行下一級細分聚類,使特征網絡能夠學習到分層的語義結構,獲得更好的效果.
2) DCL 損失函數.Yeh 等[71]通過對InfoNCE的反傳梯度進行分析,發現損失的梯度中存在一個負正耦合系數,該系數體現了采用InfoNCE訓練網絡時大批次樣本的重要性,同時揭示當訓練樣本中存在簡單正樣本對和簡單負樣本時,會明顯降低對比學習訓練的效率,因此作者提出了解耦對比學習損失 (Decoupled contrastive loss,DCL),解決上述問題.與InfoNCE 損失函數相比,DCL 去除InfoNCE損失函數中的負正耦合項,并將損失展開成兩部分,具體如表3 中的DCL 損失函數公式所示,該式展示的是單個樣本的DCL 損失計算公式,原InfoNCE包含的負正耦合系數在該式中已去除.該式的第一項表示正樣本對之間的相似度,第二項是當前樣本與同批次其他樣本組成的負樣本對之間的相似度之和.從該式可以看出,DCL 損失的計算相較于In-foNCE 損失更加簡單、高效.

表3 InfoNCE 損失函數及其變種Table 3 InfoNCE loss and some varieties based on InfoNCE
3) DirectNCE 損失函數.Jing 等[72]從解決對比學習中的網絡崩塌問題入手,經過一系列分析,提出去掉投影頭,然后將特征提取網絡輸出向量的前d個維度單獨取出,計算InfoNCE 損失.由于論文中并沒有給改動后的損失起名,因此為了便于對比,本論文中將其命名為DirectNCE.DirectNCE與InfoNCE 的區別在于所使用的樣本特征維度大小,在DirectNCE 中,樣本只取前d個維度計算損失.
4) FNCL 損失函數.針對在訓練對比學習模型時可能存在的假負樣本問題,Huynh 等[35]首先提出了一種假負樣本的檢測策略,然后對InfoNCE 進行改進,在損失函數中剔除了假負樣本的干擾.本文將該方法暫定名為FNCL.與InfoNCE 相比,FNCL方法首先確定當前正在處理的樣本對應的假負樣本,然后在分母中計算負樣本對之間的相似度時,去除假負樣本的部分.
5) SCL 損失函數.SCL[8]損失函數面向有監督學習,對InfoNCE 損失函數進行改進,旨在解決深度有監督學習中采用交叉熵損失時神經網絡對噪聲標簽敏感[73]的問題.
令P(i) 表示當前批中正在處理的樣本對應的同類樣本集合 (因為數據為有標注數據),|P(i)|表示該集合中樣本的數量,與InfoNCE 損失函數相比,SCL 損失函數的分子計算當前樣本與其對應的P(i)集合中每個正樣本之間的相似度的和,而分母部分并無變化.該損失在特定情況下可以等價于三元組損失[74]和N-Pair 損失[75].在SCL 的基礎上,研究者還研究了利用對比學習提升長尾學習效果的方法,此部分工作將在第2.6.4 節進行詳細介紹.
2.5.2 傳統損失函數在對比學習中的應用
如何衡量特征空間中不同特征點之間的距離是對比學習中一個很重要的問題.歐氏距離是衡量特征點之間距離的一個最直觀的方法.通過最小化均方誤差損失 (Mean square error,MSE),可以直接減小同類特征點之間的歐式距離,實現讓同類特征靠近的目的.BYOL 先對兩個分支的特征進行L2正則化,然后采用MSE 損失計算兩個特征之間的距離,對網絡進行優化.
除了歐氏距離外,余弦相似度也能夠衡量特征之間的相似性,因此直接最大化相同樣本的不同增廣的特征之間的余弦相似度也能達到對比學習的目標.SimSiam[6]對其中一個分支的投影向量z和另一個分支的特征向量h計算余弦相似度,直接將負的余弦相似度作為損失函數進行訓練,由于網絡結構是一個非對稱結構,為了平衡訓練,作者將投影頭依次放在兩個分支后面進行損失計算,從而提出對稱損失,其計算公式如式 (6) 所示:

歐式距離和余弦相似度都是非監督的特征相似度度量方法.除此之外,還有一些有監督的相似度計算方法.
在SwAV 方法中,首先初始化聚類中心,然后將聚類中心矩陣分別與分支1和分支2 的特征矩陣相乘,計算交換預測編碼矩陣Q1和Q2,最后,采用交叉熵損失訓練模型,訓練分支1 時將Q2作為標簽,訓練分支2 時將Q1作為標簽.聚類中心利用回傳梯度進行更新.
此外,Shah 等[76]將支持向量機與對比學習結合在了一起,采用改進后的合頁損失 (Hinge loss)優化對比學習網絡.
2.5.3 混合損失函數
在某些情況下,只采用InfoNCE 損失不能獲得良好的效果,而將多種損失函數結合,有助于提升對比學習的效果.
有監督混合損失.Wang 等[77]提出了一種將SCL 與交叉熵損失結合起來的損失.該方法采用一個平滑因子,在訓練早期,SCL 占據損失的主導地位,隨著學習過程的進行,交叉熵損失會逐漸占據主導地位.Li 等[78]將ProtoNCE 的思想帶入到SCL中,即在SCL的分子中計算每個樣本與其同類樣本所形成聚類中心之間的相似度.在該算法中,聚類中心直接由同類樣本的特征求平均值得到.最后,作者將上述損失與交叉熵分類損失聯合訓練,獲得了較好的遙感圖像分類效果.
半監督混合損失.Li 等[79]設計了一個基于偽標簽圖結構對比學習方法CoMatch.CoMatch 方法采用三部分損失訓練網絡.對比學習網絡中的一個分支,對于有標簽的數據,采用交叉熵計算損失,得到分類模型.在對比學習網絡的另外一個分支,首先利用分類模型對無標簽數據進行預測,產生軟標簽,該分支對每個無標注的數據,進行特征提取,并利用預測頭產生預測結果,當樣本對應的軟標簽的置信度較高時,采用交叉熵損失優化網絡,同時,每個無標簽的樣本還將采用InfoNCE 計算損失.Yang等[44]采用與CoMatch 相似的損失構建方法,對有標簽的數據采用交叉熵損失訓練,對軟標簽置信度高的無標簽數據采用交叉熵訓練,對其余數據采用InfoNCE 進行對比學習訓練,在該算法中,由于包含類感知模塊,可以獲得與當前訓練樣本相同類的樣本集合,因此對比學習損失部分采用實例InfoNCE和SCL 相結合的損失函數.此外,Wang 等[43]將交叉熵損失和SCL 結合在一起,獲得了良好的效果.
無監督混合損失.Park 等[80]將對比學習損失融合到基于GAN 的圖像風格遷移任務中,該方法對變換前后相同位置的圖像塊進行對比學習,將對比學習損失輔助于GAN 損失,訓練圖像風格遷移模型,獲得了良好的效果.
其他混合損失.Rai 等[46]對于具有多視圖特征的數據,對同一樣本在不同視角下的特征,分別采用InfoNCE、MSE和合頁損失計算這些特征之間的相似性,并將三個相似性度量結果進行混合,用于網絡模型優化.Kim 等[37]將Mixup 方法用在了對比學習中,該方法假定合成后的樣本同時屬于合成前的兩個樣本的類別,然后將合成樣本分別與合成前的樣本進行對比學習,得到兩個損失,這兩個損失的混合系數與合成圖像時所產生的混合系數一致.基于相似的InfoNCE 與交叉熵損失結合的思想,Kumar 等[41]解決了無監督視頻動作分割問題,Yang 等[81]解決了文本-圖像跨模態特征提取問題,Dong 等[82]實現對五種模態數據的跨模態特征提取.
2.6 相關應用
對比學習在分類、分割、預測等下游任務中均有重要應用.本文針對每種下游任務,按照數據的類型,介紹相關的應用.本文將數據的類型概括為靜態數據和序列數據,其中靜態數據主要有圖像、關系型數據、點云和圖結構等類型,序列數據主要有視頻、音頻、信號等類型.
2.6.1 分類任務
分類任務是對比學習最常見的下游應用.在靜態數據中,針對圖像分類任務,Hou 等[83]提出基于對比學習的半監督高光譜圖像分類算法,解決有標注數據不足時高光譜圖像分類問題.該算法分為2個階段對模型進行訓練,第1 階段,對于無標簽樣本,利用對比學習方法對模型進行預訓練.第2 階段,利用有標注的樣本對模型進行監督學習.針對小樣本遙感場景分類問題,Li 等[78]將無監督對比學習方法融合到小樣本學習的框架中,提高了模型的特征提取能力.郭東恩等[84]將監督對比學習方法引入到遙感圖像場景分類任務中,通過監督對比學習預訓練,提高了遙感圖像分類精度.Aberdam 等[85]將對比學習應用到文本圖像識別任務.由于對文本圖像采用隨機增廣的方法可能會導致文本內容的丟失等問題,因此,作者首先設計可對齊的文本圖像增廣技術,然后,基于同步對稱網絡架構進行對比學習訓練,最終提高了文本圖像識別的準確率.在細粒度分類問題中,Zhang 等[86]直接采用數據集中包含的分層語義標簽,利用SCL 損失構建了一個細粒度分類對比學習算法.對遙感圖像數據而言,同一個地理位置的圖像語義信息幾乎不隨時間的變化而變化.基于該特點,Ayush 等[39]設計了一個針對遙感圖像的對比學習方法,該方法將同一地理位置不同時間的兩幅圖像作為對比學習中的正樣本對.基于MoCo 架構,該方法將圖像定位的代理任務添加到其中一個分支的特征提取網絡之后,輔助模型訓練,從而提高了下游任務的預測性能.
盧紹帥等[87]將監督對比學習應用到了文本數據的情感分類研究中.在弱監督預訓練階段,采用三元組損失預訓練模型;隨后,在下游的分類器訓練階段,采用SCL 損失和交叉熵損失聯合優化網絡,獲得更好的分類結果.
在序列數據的分類中,也涌現出了一些基于對比學習的算法.李巍華等[88]將MoCo 方法遷移到故障信號診斷研究領域中,首先,通過對信號進行無監督對比學習預訓練,獲得良好的特征提取網絡.然后,再進行分類網絡訓練,解決了信號故障診斷問題.
自監督對比學習的訓練通常分為兩個獨立的階段,即特征提取網絡訓練和分類器訓練.在分類器訓練階段,有是否凍結特征提取網絡參數的兩種選擇.Wang 等[77]認為這種兩階段的學習方式會損害特征提取網絡和分類器的兼容性,因此提出一個混合框架進行特征提取和分類器的聯合學習.該方法的對比學習部分采用同步對稱網絡架構,并在特征提取網絡后面加入一個分類器.在訓練過程中,通過一個平滑因子來調整兩個損失的權重,使得對比學習在訓練開始時起主導作用,隨著訓練時間的推移,分類器學習過程逐漸主導訓練.
2.6.2 分割任務
分割任務指的是對圖像的語義分割、實例分割,視頻中的動作分割等任務.圖像分割任務關注像素級的分類,因此在此類任務中,特征提取網絡能否學習到良好的局部特征至關重要.Wang 等[89]為了更好地學習到圖像的局部空間特征,提出密集對比學習算法 (Dense contrastive learning,DenseCL).該方法提出全局對比學習框架和局部對比學習框架,每個框架均采用同步對稱網絡架構,兩個框架共享同一個特征提取網絡.其中,局部對比學習框架對卷積得到的特征取消拉平操作,從而保留特征的空間信息,使得學習到的特征提取網絡更適合于分割任務.在醫學圖像分割領域,由于數據的標注過程非常依賴專家知識,獲取大量的有標注數據代價十分高昂,因此,如何利用大量的無標簽醫學數據訓練圖像分割模型是一個很重要的研究問題.Chaitanya 等[57]將對比學習的思想應用到該領域,提出基于自編碼器框架的全局-局部對比學習網絡,在該方法中,全局對比學習目標是學習圖像的全局語義信息,局部對比學習目標是學習局部特征信息.全局網絡和局部網絡共享同一個編碼器.醫學圖像中有一個 “卷” (Volume) 的概念,對于全局網絡,正樣本對來自于同一幅圖像的不同卷.對于局部網絡,正樣本對來自同一幅圖像編碼后特征的同一個空間位置.兩個分支均采用InfoNCE 進行損失計算.康健等[90]采用監督對比學習方法解決高分辨率SAR 圖像的分割問題,通過改進的SCL損失提高同類建筑像素特征之間的相關性,最終提高模型對建筑物的分割精度.Wang 等[91]在Mask RCNN[92]框架中加入對比學習模塊,提高了像素級特征的可分辨能力,獲得更好的圖像分割結果.
在視頻動作分割問題中,Kumar 等[41]提出基于對比學習的無監督視頻動作分割方法.該方法對SwAV 算法進行改進,且不需要圖像增廣,利用 “視頻數據的相鄰幀為同類樣本”這一假設,將相鄰幀的圖像作為正樣本對進行對比學習,完成視頻動作分割任務.
2.6.3 視頻及關系數據預測任務
在視頻預測問題中,研究者使用密集預測編碼(Dense predictive coding,DPC)[53],預測視頻未來幀的信息.Han 等[42]將DPC 與存儲庫思想結合起來,提出存儲增強密集預測編碼方法,該方法將視頻的特征保存到存儲庫模塊中,并設計了存儲庫尋址機制.通過該存儲庫模塊的設計,網絡在訓練過程中能夠考慮更長時間段的特征,使預測結果更好.此外,為了更好地捕捉到視頻中的重要信息,Zhang 等[93]提出對編碼視頻同時進行幀間以及幀內的對比學習,Han 等[53]對不同視角的特征進行對比學習.
Bahri 等[94]將對比學習方法應用到了關系型數據預測任務中.為了構建訓練所需的正樣本對,作者提出了一種面向關系型數據的增廣方法.該方法受啟發于關系型數據中同一維度 (屬性) 下的信息語義相同的特點,先在輸入樣本的對應維度上隨機抹除一部分數據,然后,從其他樣本的相同維度的數據中隨機抽取信息填充到當前輸入樣本被抹除的位置中,最后,基于同步對稱架構的網絡進行對比學習.訓練得到的模型可用于預測關系型數據中丟失區域的信息.
2.6.4 長尾識別任務
粗略地說,長尾數據是指尾部類眾多的不均衡數據,而長尾學習的主要研究目標是提升尾部類的識別正確率.最近幾年,研究者們開始嘗試將對比學習的思想和技術應用到長尾學習任務中.
文獻[95]提出K-正樣本對比損失 (K-positive contrastive loss,KCL),將對比學習與長尾識別任務結合起來.具體而言,在長尾學習的特征學習階段,KCL 使用對比學習方法,但每個訓練樣本僅隨機選取K個同類樣本.而在后續的分類器訓練階段,仍采用傳統的交叉熵損失,但使用類均衡采樣,以平衡不同類的樣本量、提升少數類的分類準確度.文獻[96]提出目標監督對比學習 (Targeted supervised contrastive learning,TSC) 方法,將監督對比學習用于長尾識別的任務中.該方法首先在特征空間中設定均勻分布的聚類中心,然后,在KCL 損失的基礎上,增加樣本到其聚類中心之間的距離計算的損失項,以將樣本逼近其聚類中心,使得不同類別之間的分類界限更加清晰.
文獻[97]提出平衡對比學習損失 (Balanced contrastive learning,BCL),用于長尾識別.該方法將類別中心加入到對比學習計算中,并求批中每個類別的樣本的梯度的平均值,以減少多數類樣本在梯度方面的影響.
2.6.5 其他任務
對比學習除了在分類、分割、預測這些任務中有廣泛的應用以外,在多模態學習任務中,也有重要作用.多模態學習任務通常包含兩大類子問題,即模態內的特征學習問題和模態間特征對齊問題.
Yang 等[81]提出了一種視覺-語言跨模態對比學習方法.該方法提出將對比學習方法應用于模態內特征提取網絡的訓練,使各模態的特征提取網絡能力更強,解決了跨模態學習過程中模態內的特征學習問題.Dong 等[82]將對比學習運用在包含5 個模態數據的模型訓練中.針對模態內特征學習問題,該方法采用掩碼恢復任務作為模態內模型的代理任務.然后,針對不同模態特征之間的對齊問題,設計模態間對比學習模塊,利用模態間的對齊得分矩陣衡量不同模態間信息的相似度,進行更好的對比學習.Afham 等[98]將對比學習算法引入到3D 點云表示學習中.該模型采用兩個并行的對比學習方法,其中一個對比學習方法基于SimCLR 網絡結構,在點云數據內部進行對比學習,另一個對比學習方法引入二維圖像數據,將點云數據與對應的二維圖像數據進行跨模態的對比學習.
Laskin 等[99]將對比學習結合到強化學習中,用于提高特征提取網絡的能力.該方法基于MoCo 架構,分支1 的輸出,送入強化學習中;分支1和分支2 的輸出,組對送入對比學習中.
3 綜合對比分析
本節根據前文提出的對比學習歸類方法,對現有的方法進行歸納匯總和整體分析.表4 匯總了代表性的對比學習方法及其所屬歸類 (包括具體樣本對構造、圖像增廣方法、網絡架構類型和損失函數).另外,本節還對代表性對比學習方法的性能進行了對比分析.
3.1 整體分析
表4 以時間為序,依據前文提出的歸類方法,對主要的深度對比學習算法進行歸納匯總,從樣本對構造、圖像增廣、網絡架構和損失函數4 個層面進行分析.該表的最后一列主要是為了區分是否為有監督對比學習方法,“無標簽”表示數據無標注,對應無監督對比學習方法,“部分標簽”表示半監督對比學習算法,而 “有標簽”表示監督對比學習算法.

表4 對比學習方法整體歸類分析Table 4 Analysis of different contrastive learning methods based on our proposed taxonomy
圖14 從宏觀上統計各細分類所采用方法的占比情況.其中,1) 在樣本對構造層,最常采用的為隨機采樣方法,即將數據集打亂順序,從其中隨機抽樣一個批次進行訓練.但其它樣本對構造方法越來越受到研究者的關注 (尤其是正樣本擴充和困難樣本構造類方法);2) 在網絡架構層,最常用的是同步對稱網絡架構,但以MoCo 為代表的異步對稱網絡架構和同步非對稱網絡架構也得到了大量關注;3) 在損失函數層面,最常用的是InfoNCE 損失函數及其變種,占比約70%,但隨著對比學習下游應用的發展,混合損失函數不斷涌現;4) 在應用領域層面,目前對比學習最常用于無監督學習領域,但也有越來越多的工作將其應用在有監督學習和半監督學習中.需要說明的是,在圖像增廣層,大部分工作都是直接采用簡單的圖像變換方法,而數據合成及圖像語義增強方法較少,故未對其進行可視化展示.
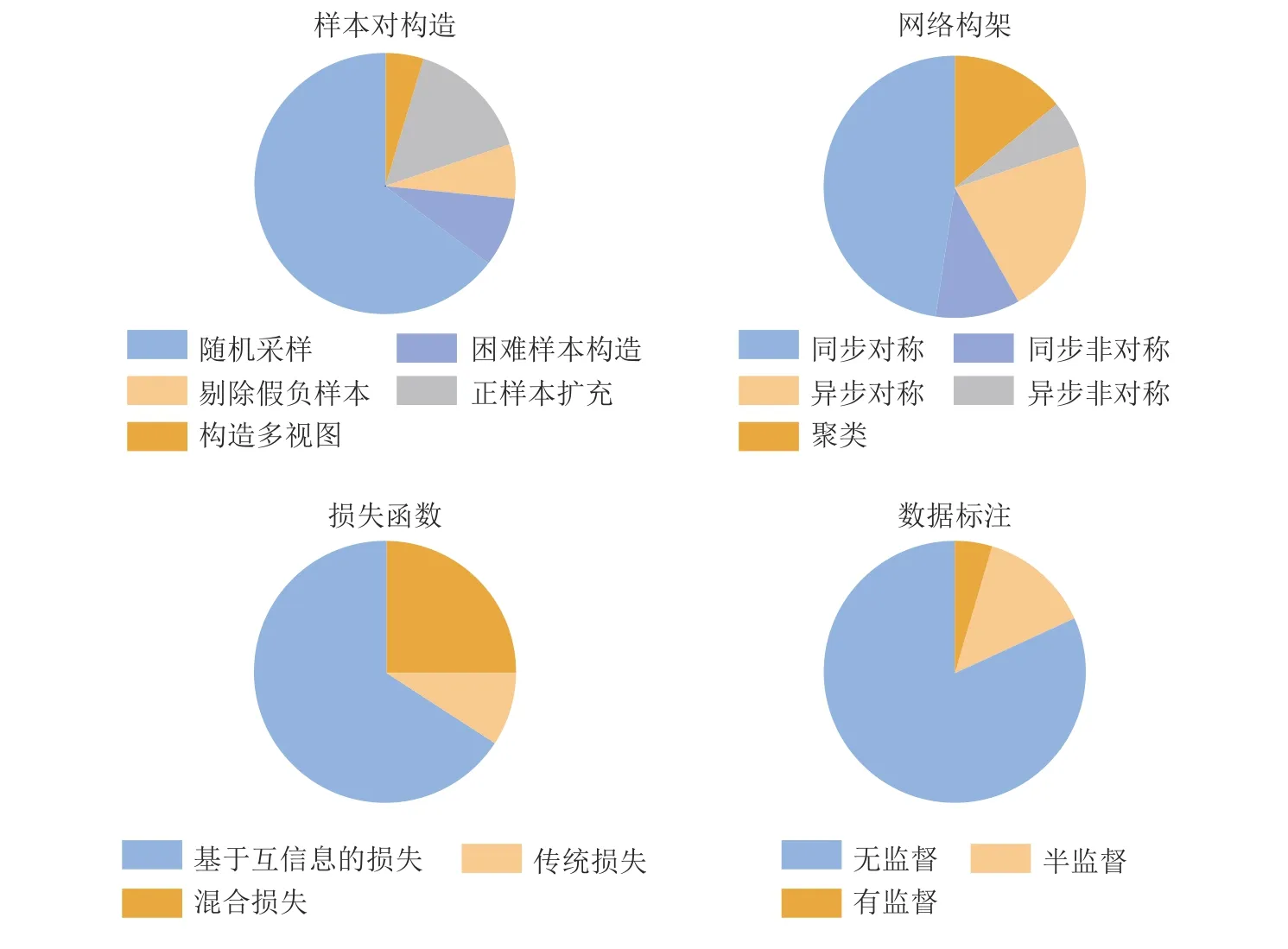
圖14 不同類型的對比學習方法統計展示Fig.14 The statistical results of different contrastive learning methods
分析不同對比學習方法隨時間演進的規律,發現對比學習呈現以下發展趨勢:從樣本對構造層面來看,對比學習從一開始需要大批次采樣負樣本,發展到通過隊列采樣負樣本,再發展到不需要負樣本的對比學習方法,以減輕對比學習對計算資源的要求,這亦是其必須解決的關鍵問題之一.
從網絡架構層面來看,對比學習有以下發展趨勢:最初的對比學習架構主要采用同步對稱和異步對稱架構,但隨著BYOL和SimSiam 等異步非對稱網絡發展,因其只需要正樣本和小批次數據就能進行對比學習訓練的優點,這種網絡架構得到了越來越多的關注.同時,由于聚類方法能夠有效地提取數據的語義信息,因此聚類方法與上述4 種架構的結合也越來越受到研究者的關注,并得到了一定的發展.此外,所采用的主干網絡的結構也逐漸從卷積神經網絡向Transformer 過渡.從損失函數層面來看,對比學習呈以下發展趨勢:從初始的InfoNCE 損失函數發展到各種變種,再到嘗試采用多種傳統損失函數進行對比學習,再到混合多種不同類型的損失函數進行訓練,以提升模型的性能.
從下游任務來看,對比學習從開始時只關注圖像分類,逐漸向視頻分析、遙感圖像處理、醫學影像分析、文本分析和多模態學習等任務拓展,且具有進一步的發展空間.
3.2 不同對比方法的性能分析
本部分內容將不同對比學習算法在常用數據集上的性能表現進行對比和分析.
1) 圖像分類.圖像分類是最常見的下游任務,現有方法通常在ImageNet 數據集上采用第1.6 節中給出的線性評估方法進行比較.表5 給出了不同算法在ImageNet 數據集上的分類準確度.可以觀察到,在ImageNet 數據集上的分類任務中,在無監督學習中,SwAV 方法獲得了最佳的分類效果,在有監督學習中,PaCo 獲得了最好的效果.除了ImageNet 之外,常用于圖像分類評估的數據集還有Cifar10和Cifar100,Food101,Birdsnap,Sun397,Cars,Aircraft,DTD,Pets,Caltech-101,Flowers等.為全面評估對比學習方法得到模型的可遷移性能,在這些數據集上采用第1.6 節中給出的評估方法進行對比分析,其中,主干網絡模型均采用Res-Net50,在ImageNet 數據集上訓練得到.結果如表6所示.表中VOC07 采用mAP (Mean average precision) 指標進行驗證,Aircraft、Pets、Caltech和Flowers 數據集采用平均準確率 (Mean per class accuracy) 進行驗證,其余數據集采用Top 1 分類進度進行驗證.半監督學習根據所采用的有標注數據的比例進行分類性能的評估.如表7 所示,1%指的是訓練過程中使用了1%的有標注數據,10%指的是訓練過程中使用了10%的有標注數據.其中,所有方法采用的主干網絡均為ResNet50.整體而言,SimCLRv2 取得了最佳的半監督分類效果.

表5 不同對比學習算法在ImageNet 數據集上的分類效果Table 5 The classification results of different contrastive learning methods on ImageNet

表7 不同半監督對比學習算法在ImageNet 上的分類效果Table 7 The classification results of different semi-supervised contrastive learning methods on ImageNet
2) 圖像檢測和分割.在圖像檢測和分割任務中,VOC和COCO 數據集是較為常用的數據集.不同對比學習算法在這兩個數據集上的分割性能在表8 中進行了匯總展示.
表8 中的所有模型均在ImageNet 數據集上進行預訓練,隨后在VOC 數據集或COCO 數據集上進行微調.表中所列出的算法均采用圖像變換方法進行圖像增廣.網絡結構方面,SimCLR 采用同步對稱結構,MoCo和DenseCL 采用異步對稱結構,BYOL和SimSiam 采用異步非對稱結構,SwAV采用聚類對比學習結構.損失函數層面,SimCLR、MoCo 以及DenseCL 均采用InfoNCE 損失函數;BYOL、SwAV 及SimSiam 均采用傳統損失函數(如第2.5.2 節所述).

表8 不同對比學習算法在圖像分割任務上的性能表現Table 8 The image segmentation results of different contrastive learning methods on VOC and COCO dataset
由于DenseCL 在訓練過程中加入了局部對比學習結構,使得學習到的模型對局部信息的提取能力提高,進而提高了模型的檢測和分割能力,獲得了目前最好的圖像檢測和分割效果.
4 現存挑戰和未來發展方向
4.1 現存挑戰
4.1.1 對比學習中的崩塌問題研究
崩塌問題是對比學習研究中經常會遇到的問題,崩塌包含兩種現象,第1 種稱為完全崩塌,第2種稱為維度崩塌.完全崩塌指的是對于任意輸入,模型會將其輸出到同一個特征向量上.維度崩塌是指特征向量只能占據特征空間的某一個子空間中的現象.完全崩塌如圖15(a)所示,維度崩塌如圖15(b)所示.
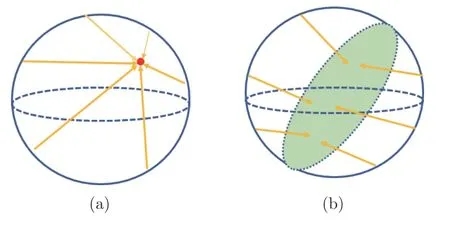
圖15 完全崩塌與維度崩塌示例Fig.15 Example of complete collapse and dimensional collapse
一般來說,有兩種辦法觀測網絡是否發生崩塌:1) 將訓練好的特征提取網絡應用到下游任務,若下游任務表現不好,則可能出現崩塌.2) 特征提取網絡訓練完成后,首先,將一個批次的測試數據進行特征提取.然后,計算該批次特征矩陣的協方差矩陣.最后,對協方差矩陣進行奇異值分解.如果奇異值矩陣對角線上的值在某一個維度開始發生斷層現象,則網絡發生了崩塌[72].
對于采用負樣本進行對比學習的方法來說,由于訓練過程中網絡可以見到大量不同的負樣本,因此在一定程度上可以避免維度崩塌問題.而對于只采用正樣本進行對比學習的算法來說,則需要一些特殊的設計以避免崩塌[4-6].SwAV 采用聚類的思想避免了不同的輸入輸出到同一個特征向量上的問題,從而防止了完全崩塌的出現.BYOL 采用了非對稱的網絡設計和動量更新方法避免網絡的完全崩塌.SimSiam 通過實驗證明了,通過交叉梯度回傳,能夠有效的防止網絡完全崩塌.在避免維度崩塌問題上,有一些論文專門對其進行研究和討論,根據這些論文的討論內容,可以將其分為兩種思路,即緩解維度崩塌思路和避免維度崩塌思路.
1) 緩解維度崩塌
Jing 等[72]探討了對比學習中出現的維度崩塌問題,作者發現,在對比學習中,強大的圖像增廣方法和隱式正則化可能是產生維度崩塌的原因.在該論文中,作者提出了一個簡單有效的解決維度崩塌辦法:DirectCLR.DirectCLR 采用與SimCLR 相似的同步對稱網絡架構,但進行了下述兩點改進:1) 拋棄投影頭.2) 在完成特征提取之后,只在特征向量的前d個維度上計算損失.對于這種方法的一個直觀的理解是:通過訓練,將沒有崩塌的維度全部集中到前d個維度中去,因此最后在前d個維度上就沒有了崩塌問題.在這種理解下,超參數d的物理意義為沒有發生崩塌的子空間維度.
DirectCLR 中的實驗證明,與沒有投影頭的SimCLR 相比,DirectCLR 的效果要好一些.然而當SimCLR 有一個兩層的非線性投影頭的時候,表現會比DirectCLR 要好很多.這個現象可能在一定程度上證明了如下觀點:投影頭在對比學習方法中承擔著尋找無崩塌子空間的任務.在該觀點下,首先,特征提取網絡將輸入樣本進行特征提取,獲得特征矩陣.然后,投影頭將高維特征矩陣映射為低維投影矩陣.最后,在低維的投影空間中計算損失.通過一次投影頭的降維變換,將在高維特征空間中可能出現的崩塌現象轉移到沒有崩塌的低維投影空間中,從而保證了損失計算的有效性.
2) 避免維度崩塌
對維度崩塌的直觀理解是特征空間中的部分維度失去了信息.為了避免這種情況的出現,Zbontar 等[101]等計算分支1 特征矩陣和分支2 特征矩陣的協方差矩陣,通過將協方差矩陣的學習目標設計為同形狀的單位矩陣,來完成以下兩個目標:1) 保證每個維度信息的有效性.2) 消除不同維度之間信息的相關性.通過設計上述學習目標,在訓練過程中,協方差矩陣的主對角線上的元素值會逐漸向1 靠近,其它元素的值會逐漸向0 靠近.由于協方差矩陣的主對角線元素可以代表該維度信息的信息量,大于0 可以保證該維度沒有發生崩塌,非對角線元素代表不同維度之間信息的相關性,等于0 即可保證各維度信息獨立.因此通過學習,在避免維度崩塌出現的同時也消除了維度間的冗余性,使得訓練過程更加穩定有效.Hua 等[102]深度分析了自監督學習中的特征崩塌問題,同樣提出特征去相關方法避免崩塌.
Bardes 等[103]進行了更加深入的探索,提出分別在分支1和分支2 的特征矩陣上采用與Zbontar類似的方法去除維度間的冗余性.與Zbontar 方法不同的是,Bardes 引入了特征矩陣的方差信息,當某一個維度的方差信息向0 靠近時,可以認為該維度發生了崩塌,因此作者通過合頁損失使得每個維度的方差信息向超參數γ靠近,從而避免了崩塌.此外,該方法還引入了不變項約束,該約束采用MSE 損失減小同一個樣本在分支1 中特征和在分支2 中特征之間的距離.
4.2 算法效率優化
在對比學習獲得成功的背后,因其需要大批次樣本參與學習的特點,從而對計算資源和存儲資源產生較高要求,這在一定程度上限制了對比學習的發展.Bao 等[104]將對比學習過程中使用的負樣本數量N與分類任務訓練過程進行聯合分析,發現增加N的值可以使得分類損失的上界和下界之間的截距減小.這篇論文從理論角度解釋了負樣本數量與下游任務性能之間的關系,證明了在無監督預訓練階段使用的負樣本數量越大,對后續的分類任務的訓練結果就越穩定.Yeh 等[71]通過對InfoNCE損失求解梯度發現對比學習存在負正耦合效應.此處的負正耦合效應指的是以下兩種情況:1) 當正樣本對相似度高 (簡單正樣本對) 時,損失對負樣本回傳的梯度變小.2) 當查詢樣本與所有負樣本相似度都很小 (簡單負樣本) 時,損失對正樣本回傳的梯度變小.以上兩種情況說明無論是訓練中采用簡單正樣本對或簡單負樣本集均會造成訓練效率低的問題.為了解決這個問題,論文提出解耦對比學習損失函數DCL.該損失去除了InfoNCE 中的負正耦合系數,從而可以用更小的批次來訓練對比學習網絡,同時提高計算效率.除此以外,很多經典的對比學習方法如BYOL,SimSiam 等都對訓練批次大小進行了不同的實驗.然而,如何利用更小的批次獲得更好的對比學習效果,這仍是未來的一個挑戰.
4.3 一致性與均勻性矛盾問題
在對比學習中,由于輸出特征經過正則化,因此所有圖像均會被映射到特征空間的單位超球面上.為了使模型具有良好的泛化能力,希望在超球面上分布的特征具有以下兩點特質:1) 同類樣本特征集合具有一致性;2) 所有特征分布具有均勻性[62].一致性指的是相同類的樣本特征應當集合在超球面的同一片區域內,均勻性指的是所有樣本的特征應當在超球面均勻分布,直觀理解如圖16 所示.避免神經網絡崩塌的最好辦法就是同時滿足一致性和均勻性.均勻性有助于對比學習學習到可分離的特征,但是過度追求均勻性,將會導致一些語義相似的樣本的特征一定程度上互相遠離.Wang 等[105]針對這個問題進行詳細分析,認為在對比學習訓練中,一致性與均勻性是一個互相對抗的關系.該論文通過對InfoNCE 損失函數中的溫度參數τ進行分析,發現溫度參數τ的取值影響一致性與均勻性的結果,因此對于采用InfoNCE 損失進行對比學習的方法來說,溫度參數τ的取值對模型最終的表現非常重要.

圖16 對比學習中一致性和均勻性的概念Fig.16 The concept of uniformity and alignment in contrastive learning
4.4 未來發展方向
本文在對目前的對比學習論文進行歸納和總結后,認為該研究領域還存在許多可以探索的問題,同時存在一些可以與其他領域互相借鑒和發展的方向,具有廣泛的研究前景,以下是對該領域發展的展望:
1) 對比學習中樣本對的選擇方法仍存在發展空間,在訓練過程中剔除假負樣本以及選擇合適的正樣本對能夠有效地提高特征學習網絡的學習效果.因此如何更加合理地剔除假負樣本和選擇正樣本對是一個值得研究的關鍵問題.
2) 解決對比學習訓練過程中的一致性與均勻性矛盾是一個十分重要的問題,如果該問題得到解決,能在很大程度上提高特征提取網絡在下游任務上的泛化能力.
3) 主動學習是一種通過最少的標注樣本獲得最好的訓練效果的學習技術[106].在深度主動學習領域,網絡模型需要首先在一個含有標簽的數據集L0上進行預訓練,然后通過查詢策略從無標簽數據集U中篩選最有用的樣本給專家進行標注,最后更新當前訓練的有標簽數據集L,采用L的數據繼續訓練網絡.重復以上過程直到標注預算耗盡或觸發停止策略[106].對比學習是一種良好的模型預訓練方法,可以自發的通過無標簽數據或少量標簽數據訓練出特征提取模型,因此可以將對比學習算法引入到主動學習的網絡模型預訓練過程中,或作為輔助主動學習挑選待標注樣本的方法.
4) 對比學習和無監督域自適應[107-108]的結合.在無監督域自適應問題中,源域數據存在標簽,目標域數據不存在標簽,源域數據和目標域數據分布相近或相同,且擁有相同的任務[107],如何將源域數據和目標域數據一同訓練,使得模型能夠在目標域上獲得良好的效果是無監督域自適應的核心問題.在無監督域自適應研究中,源域數據和目標域數據可以通過自監督訓練方法聯合訓練模型,對比學習就是一種先進的自監督訓練算法,因此如何將對比學習方法與無監督域自適應方法進行有效結合是一個值得研究的問題.
5) 目前對比學習主要的下游應用是分類任務,如何設計更多的對比學習方法應用到檢測、追蹤等下游任務中,也將是未來的發展方向之一.
5 結束語
對比學習是近年的研究熱點.本文系統梳理了對比學習的研究現狀,提出一種將現有方法劃分為樣本對構造層、圖像增廣層、網絡架構層、損失函數層和應用層的歸類方法,并從自監督對比學習算法入手,分析和歸納近四年主要的對比學習方法.而且,本文還全面對比了不同方法在各種下游任務中的性能表現,指出了對比學習現存的挑戰,勾勒了其未來發展方向.對比學習研究作為一個快速發展的研究領域,在理論依據、模型設計、損失函數設計及與下游任務結合等方面還有較大的研究空間.
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
