基于隨機森林算法的配電網停電研判方案設計
2023-01-30 13:22:30余劍鋒何云良吳華華魏驍雄陳博鐘震遠
微型電腦應用 2022年12期
余劍鋒, 何云良, 吳華華, 魏驍雄, 陳博, 鐘震遠
(1.國網浙江省電力有限公司, 浙江, 杭州 311100;2.國網浙江省電力有限公司營銷服務中心, 浙江, 杭州 311100)
0 引言
隨著智能配電網的不斷應用,提高了電網的供電效率以及可靠性,同時可以實現獲取電網的相關數據,提高電網的搶修效率。智能電網平臺通常只能對于停電故障發生后進行業務處理的管理,無法實現根據故障數據的故障研判,因此一些研究者對配電網數據的研判方案進行了研究:文獻[1]提出了基于配電網拓撲結構等效耦合故障研判方法,分析了配電網故障研究與判斷的基本原理以及常見的配電網故障研究與判斷邏輯,實現了分布式配電網拓撲網絡結構單故障和多故障的準確判斷;文獻[2]提出了融入低壓智能電表的配電網故障研判,結合低壓GIS對配電網自動化系統等多源業務系統數據進行智能診斷,開發低壓整體故障分析儀,設置配電中的定位網絡,低壓故障類型識別和分析等功能模塊,實現低壓配電網的模塊化應急維修。通常采用的研判模式的開發接口較多,難以適應大型電網,且以上幾種研判方案均是在故障出現導致停電后才對單一節點的數據進行處理,無法對整體數據進行關聯查找。因此研判結果的準確性受到了影響,需要進一步的改進[3-4]。
1 基于隨機森林算法的配電網停電研判方法設計
1.1 隨機森林電網數據集樣本訓練
用隨機森林算法對配電網中的數據進行提取和訓練,包括電能運行數據、設備管理數據及故障數據,以此來獲得相對應的異常數據集,并作為未來停電研判的基礎[5-6]。首先設獲取到的配電網存在m個樣本的數據集G,而在進行數據集樣本采樣過程中獲得的數據集為D。在數據集G隨機提取樣本并將樣本拷貝至D內,并重復m次,得到存在數據集G內m個數據的數據集D。那么在進行m次的采樣時不會抽到的概率為(1-1/m),得到極限值:
(1)
該過程可以通過Bootstrap來進行反復抽取,并保證獲得數據集的集中率在37%左右。那么得出的樣本就可以作為OOB樣本,作為隨機森林算法的樣本。而在隨機森林算法中通過抽取后的樣本數據集D中的k類樣本占比為pk(k=1,2,…,|y|),那么D的信息熵則為
(2)
其中,特征集內的特征a屬于離散型的數據,則對于特征a的取值則存在V種可能,即{a1,a2,…,av},且對于樣本集D的劃分可以使用特征a來進行。并在其中產生出V個分支點。設在第V個分支中包含的數據集D中的特征a中取值av的樣本為Dv。計算得出離散特征a的數據集D劃分出的信息熵:
(3)
而當特征a屬于連續數據時,特征a則可以根據取得遞增情況來進行排序,并將取值得出的相鄰點看作不同可能下的分裂[7-8],則對數據集D的信息熵劃分則改變為
(4)
式中,DL以及DR代表通過分裂點分出的兩部分子集,并以此來獲得特征a所劃分的集合D的熵值。在確定不同特征下的數據類型并獲得相應的信息熵,進而則可以計算其中的信息增益:
Gain(D,a)=Ent(D)-Enta(D)
(4)
則增益率計算為
Gainratio(D,a)=Gain(D,a)/IV(a)
(5)
而其中IV(a)的計算式為
(6)
以此得出隨機森林運算的樣本訓練模式,用以進行停電事件研判。
1.2 配電網分層拓撲模型建立
配電網停電通常受到其中的故障原因,在對配電網停電的研判時,需要對配電網的故障情況進行考慮[9-10]。本文采用分層拓撲模型來進行配電網故障情況的運算,建立的配電網分層拓撲模式如圖1所示。
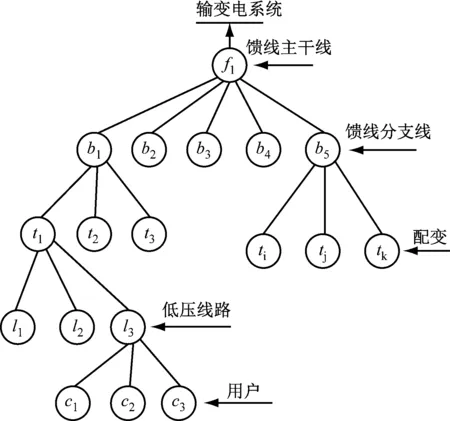
圖1 配電網拓撲模型示意圖


(7)
在配電網中,當用戶發出故障信息或觸發故障檢測設備的情況下,通常可以直接獲取到故障用戶的位置,實現對用戶的定位。在該條件下點子集為Ck=(ck1,ck2,…,ckn)T,而其中的故障信息向量為Pk=(pck1,pck2,…,pckn),那么配變層的父節點tk所對應故障信息pTk為
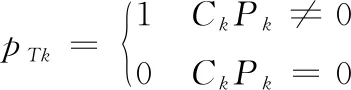
(8)
就此建立配電網的故障停電模型,來對故障情況下停電原因進行判斷。
1.3 停電事件研判實現
相關的配電網研判方案,在具體實現時,可以使用兼容性較高的自動數據處理方法來進行,以適應當前智能電網的需求。本文對于配電網的研判采用自動數據來進行,開發通過PMS2.0來進行,并在其中導入上文中的運算方式。研判過程如圖2所示。

圖2 停電數據研判流程圖
停電數據研判流程如下:
(1)首先使用上文中的完成訓練的隨機森林算法,處理配電網中的數據,得出會導致停電的故障樣本數據;
(2)將故障樣本數據導入至配電網的分層拓撲模型,得出得到具體的故障參數;
(3)依據配電網中帶有的監測對用戶的停電時間和用戶標識、停電起始時間和終止時間進行數據監測。同時進行判斷,在可靠性的停電中,獲取到用戶中的表示和在研判中的PMS2.0中的對配電網中故障停電的搶修ID,并對用戶的停電終止時間,進行故障研判,大致得出相應的預計電力恢復時間;
(4)最后將搭載研判方案的PMS2.0與配電網中的數據許可相聯系,使方案可以隨著搶修進度的推進校正得出的數據結果,從而得到實時的停電事件研判結果。
2 實驗論證分析
為了驗證配電網的研判方案的可行性,設計對比實驗。以某地變電站構成的配電網作為停電研判方案的驗證基礎。并采用文獻[1]、文獻[2]中的研判方案與本文方案中的算法對其中的數據進行運算。并判斷3種研判方案對于配電網故障數據的查全率以及查準率。
2.1 實驗變電站網絡
實驗的對象配電網絡,基于如下的變電站網絡而建立,網絡簡化圖如圖3所示。

圖3 簡化變電站網絡
配電網的信號域數據如表1所示。

表1 配電網絡信息域和數據
在該配電網絡中,T代表網絡中的變壓器,L1、L2均為用戶的輸電線路。A、B、C、D代表配電網絡母線,圖3中的M1~M8均代表配電網絡中的量測裝置,分別為變頻電源檢測器、電流檢測器、高壓開關裝置、集中處理器、功率檢測器、饋線終端裝置、遠程終端單元及數字量模塊。
2.2 配電網停電故障預測指標計算
實驗對配電網的故障網絡預測,過程中的使用數據相同,并依據其中的查準率以及查全率兩種指標來進行判斷,實驗評判指標計算方法如下:
(9)
(10)
式中,precision代表實驗中研判方案對故障數據的查準率,recall代表實驗中研判方案對故障數據的查全率,Np代表預測正確樣本數,Nt代表進行處理的樣本數,Nr代表真實樣本數。
2.3 實驗結果
本文實驗在進行數據預處理時,對于故障量進行區間劃分,共分為3類的故障量數據類別,分別為1~5、6~10、11~15。對于類別1的實驗結果如表2所示。
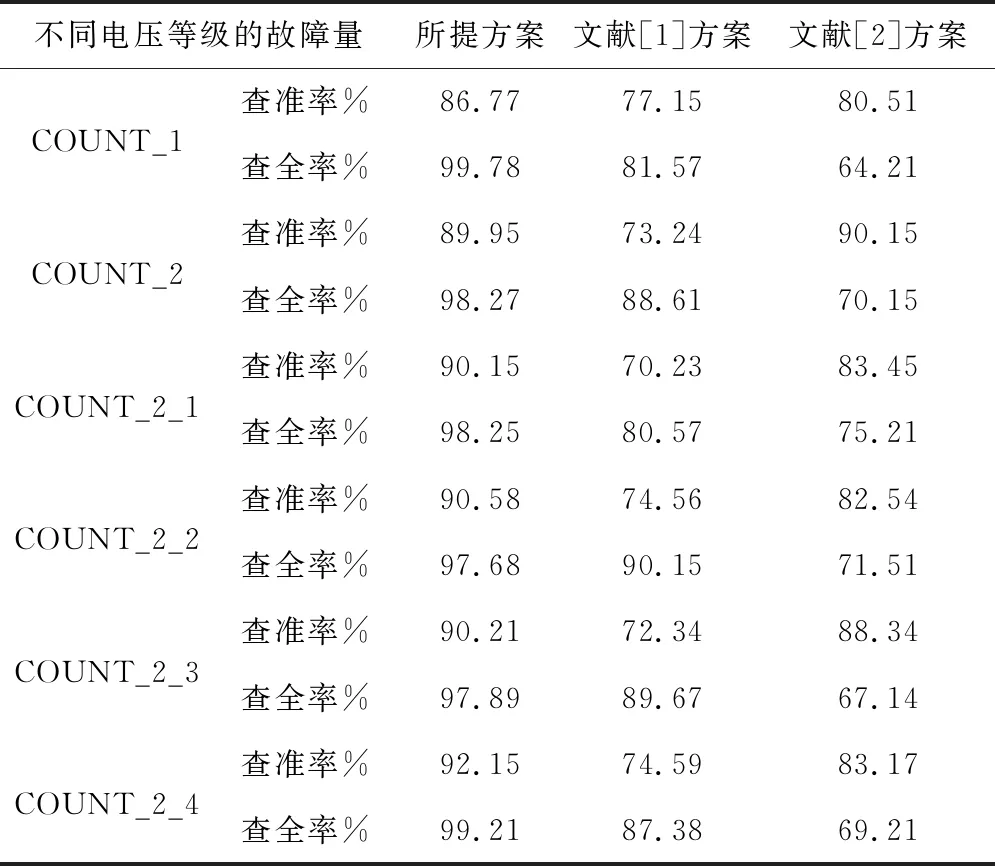
表2 類別1數據研判結果
在表2中,COUNT_2_1代表電壓等級為1的故障數據,COUNT_2_2代表電壓等級為2的故障數據,COUNT_2_3代表電壓等級為3的故障數據,COUNT_2_4代表電壓等級為4的故障數據,COUNT_2代表該配電網下的故障總故障數據,COUNT_1代表非配電網的用戶設備故障數據。在表2中可以發現,文獻[1]方法的查準率維持在69%~90%之間,查全率維持在80%~91%之間;文獻[2]方法的查準率較高,維持在81%~91%之間。但由于文獻[2]方法查全率較低,維持在65%~76%之間,查準結果置信程度不高,而所提研判方案的查準率維持在86%~93%之間,查全率在97%~99.78%之間,在查準和查全上均存在優勢。對于類別2的實驗結果如表3所示。
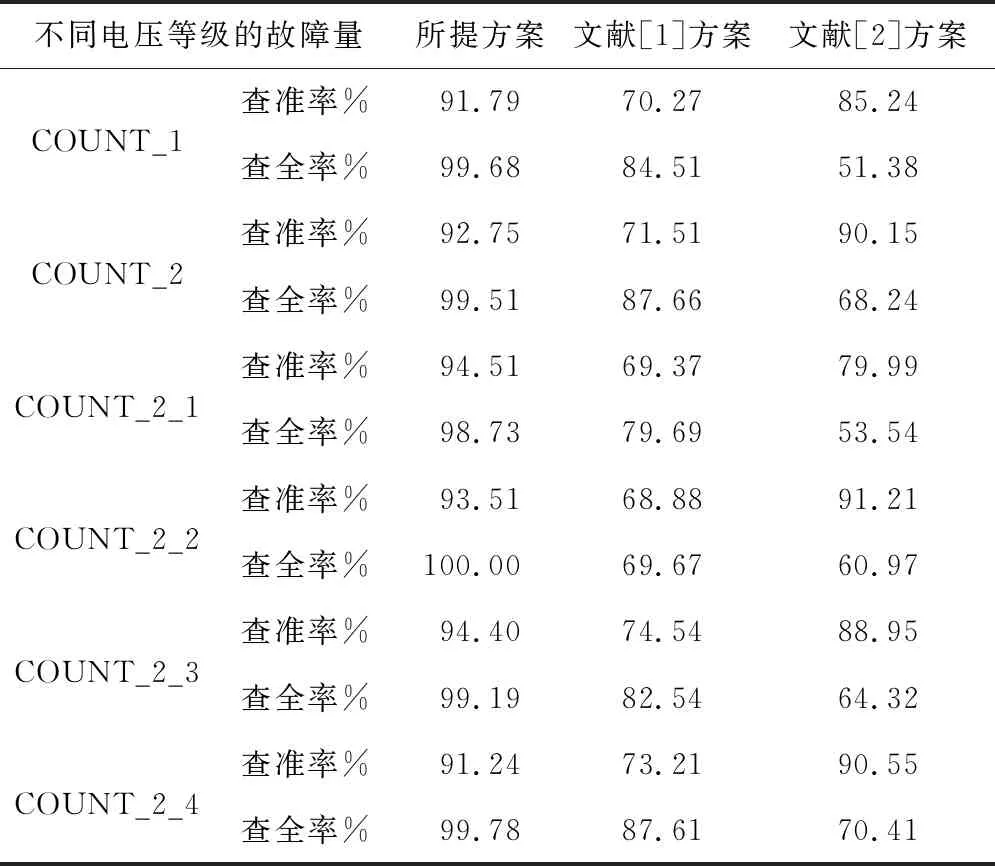
表3 類別2數據研判結果
從表3可知,文獻[1]方法的查準率維持在69%~75%,查全率在69%~88%;文獻[2]方法的查準率在66%~81%之間,查全率在90%~99.37%之間;所提方案的查準率在91%~95%之間,查全率在98%~100%。對類別3的數據研判結果如表4所示。

表4 類別3數據研判結果
從表4可以看出,文獻[1]方法、文獻[2]方法的性能下降嚴重,進行分析得出,類別3的故障數據通常是由于其他節點的故障,從而導致一系列故障,從而導致停電的出現,由于其他方法均針對單一節點進行數據研判,因此無法得到可靠的研判數據。同時可以證明本文設計的配電網停電研判方法的可行性。
3 總結
利用隨機森林算法,對配電網中的所有數據進行了過濾或監測,實驗表明所提方案提高了研判方案的數據查全率及查準率,對不同類別故障的研判精確度較高。但本文研究由于采用了對電網數據的實時監測,容易對服務器造成過多占用,因此未來將會結合云計算技術,將部分數據的計算分離,降低服務器的運算壓力。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
汽車維修與保養(2019年7期)2020-01-06 03:30:42
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
經濟技術協作信息(2018年32期)2018-11-30 01:43:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
汽車維護與修理(2016年10期)2016-07-10 08:17:41
電測與儀表(2016年5期)2016-04-22 01:14:14
河南電力(2016年5期)2016-02-06 02:11:24
汽車維修與保養(2015年6期)2015-04-17 03:31:50
