基于深度學習的多模型遙感影像檢索
2023-01-30 13:09:34郝明達普運偉
城市勘測 2022年6期
郝明達,普運偉
(1.昆明理工大學 國土資源工程學院,云南 昆明 650221; 2.昆明理工大學 計算中心,云南 昆明 650504)
1 引 言
隨著遙感數據的增加,從大規模遙感影像中自動化檢索感興趣區域顯得尤為重要,提高算法對感興趣區域檢索的質量和效率是核心問題。遙感影像檢索可以解決這樣的一些問題,如人們想要從數百平方公里范圍內的衛星影像中快速精準地定位、識別感興趣的目標,或是從樣本庫中,更進一步識別出地物目標的具體型號與類別,以獲得一個可解釋性的結果。
遙感影像數據檢索的發展主要包括兩個重要的階段,特征工程和特征學習。在特征工程階段,主要是通過人工設計特征描述符對遙感影像進行抽象描述,如尺度不變特征變換(SIFT)等[1,2]優秀的圖像檢索模型被提出,但是受限于需要人工設計特征,而且準確表示遙感影像語義信息的能力有限。之后,在特征學習階段,即自2012年以來的深度學習階段,始于人工神經網絡,特別是深度卷積神經網絡等優秀模型被提出后。如2016年5月,美國卡耐基梅隆大學的團隊發布了Terrapattern,使用在自然圖像上已訓練模型提取遙感影像特征,用于遙感數據檢索。2020年2月,Keisler等人[3]也通過使用卷積神經網絡抽取影像特征并與Google cloud提供的數據庫服務實現對遙感影像的實時檢索(https://search.descarteslabs.com/)。隨著Descartes Labs(https://descarteslabs.com/)、Google Earth Engine(https://earthengine.google.com/)、Sentinel Hub(https://www.sentinel-hub.com/)、PIE engine(https://engine.piesat.cn/)等平臺存儲了大量的遙感數據信息,遙感影像檢索算法與這些大型的數據庫平臺相結合,將有助于對大規模遙感數據檢索的應用分析,為了應對海量遙感數據感興趣區檢索,有必要提高遙感影像檢索的可擴展性。
針對影像檢索算法的改進可以分為模型級和特征級改進。在模型上進行改進包括模型架構改進和模型微調策略改進,特征級方法改進可以分為特征增強方法和特征提取方法改進,但更多的是,同時使用多種方法進行檢索。如網絡架構的改進,是利用堆疊的線性濾波器(如卷積)和非線性的激活函數,從數據中提取更高級的抽象和語義感知功能[4,5];因全連接層(FC層)和卷積層(CNN層)的神經元具有不同的接受域,可以實現模型特征提取方式的改進,如CNN層的局部特征[6,7],卷積層(通常是最后一層)的特征保留了更多的結構細節,在影像檢索中可以獲得更多區分性的特征;深度特征增強方法常用于提高深度特征的識別能力,如直接使用深度網絡[8]訓練哈希編碼,哈希方法[9]將實值特征編碼為二進制碼,可以提高檢索效率,特征增強策略對圖像檢索效率有顯著影響;基于模型微調的特征提取方法,是使用在自然圖像上已訓練的分類模型經過模型微調,遷移到新的數據集上進行檢索任務。然而,檢索性能受到數據集之間的域轉移的影響,因此,有必要將深度網絡調優到特定的域[10~12],這可以通過有監督的微調方法實現。
2 多模型遙感影像檢索方法
為了提高遙感影像檢索的精度和效率,以及對海量數據檢索的可擴展性,本文提出一種多模型檢索方法,其實驗設計流程如圖1所示。其中模型的訓練過程如圖2所示:首先使用Roy S等[13]提出的遙感影像有監督哈希編碼方法獲取影像哈希編碼值,其中通過使用在自然圖像上預先訓練過的Inception模型,對遙感影像進行預測,通過獲取模型最后一層的卷積特征提取遙感影像抽象特征,然后通過有監督方法對一個新的模型進行二次訓練,進一步通過三重損失優化模型在遙感影像語義空間上的特征表達,以壓縮特征編碼量,從而獲得多光譜遙感影像的哈希編碼值,提高遙感影像檢索的精度和效率。另外使用Chen Kun等人[14]提出的無監督整數索引方法以實現對局部最近鄰數據的檢索,其中在遙感影像上無監督訓練VQ-VAE模型,將訓練好的VQ-VAE模型對測試集遙感影像執行預測,然后通過對中間特征進行池化、求和、移位等操作獲取遙感影像的整數索引,以將整數索引通過Van Emde Boas tree(VEB)進行編碼,通過這步操作可以將相似的影像存儲為VEB tree中的最近鄰。最終測試時,遙感數據通過哈希編碼和整數索引,并通過漢明距離進行排序,可以從數據庫中獲取到與查詢影像相似的影像,其中測試時影像檢索的結果如圖3所示。
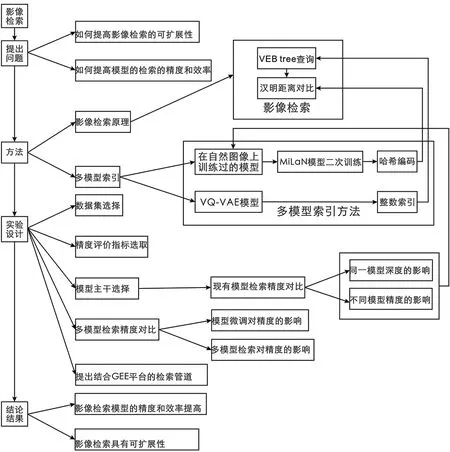
圖1 多模型遙感影像檢索流程圖
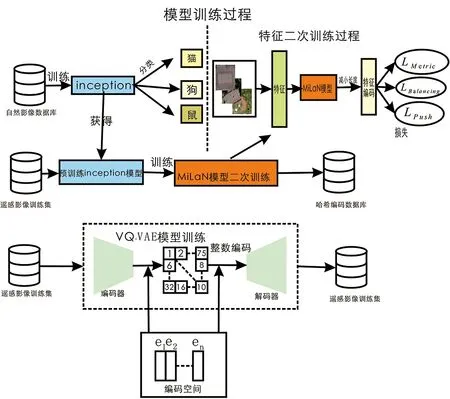
圖2 多模型遙感影像訓練過程
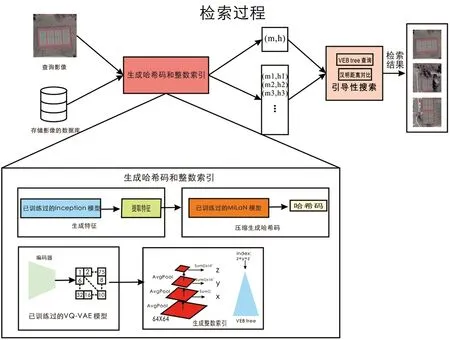
圖3 多模型遙感影像測試過程
2.1 遙感影像哈希編碼方法
當遙感數據的類標簽可用時,使用模型微調的方法可以實現更高的精度。可以選用VGG、Inception、Resnet、DenseNet等在自然圖像分類任務中已經訓練過的模型作為主干模型,然后在遙感數據集上訓練新的模型,從而通過損失函數對模型參數進行微調,產生優越的性能。基于深度學習的模型在訓練的時候可以使用三元組的方式優化哈希編碼精度,從而使得正樣本接近錨點,負樣本遠離錨點。其中三元組的構建思想如圖4所示。
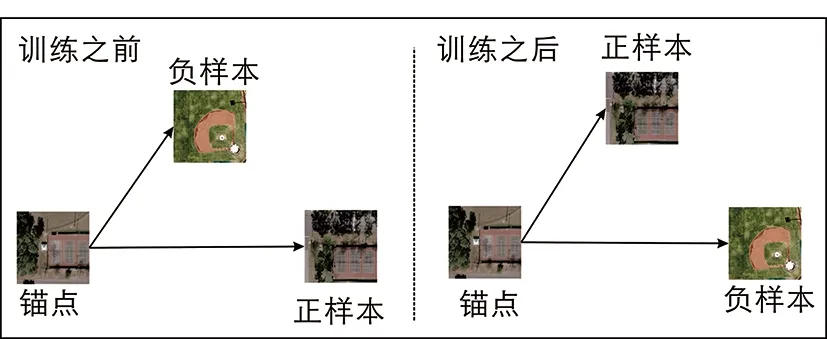
圖4 三重損失的構建思想(正樣本被移動到離錨點更近的位置,負樣本則遠離錨點。)
本文使用S Roy等人[13]提出的方法對已訓練模型提取的遙感影像特征進行二次訓練,其中三元組優化的方法是使用一個三重損失實現[15]的。其二次訓練使用的模型有三個全連接層組成,每層有 1 024、512、k個神經元,在最后一層中使用sigmoid激活函數來限制輸出到[0,1],其中k為所需的哈希編碼數(比特數),通過有監督哈希編碼的方式降低了特征的維數,這有助于提高檢索的精度和效率。其中三重損失的第一個損失公式如(1)所示:
(1)
第二個損失,為了使哈希編碼層可以達到激活函數的極值,其目標以最大化輸出層激活值與0.5之間的平方誤差之和,公式如(2)所示:
(2)
第三個損失,用以激勵每個輸出神經元有50%的概率觸發,這意味中圖像的二進制代碼將(平均)有一個平衡的0和1的數目,所有的位可以被同等地使用,從而使二進制碼均勻分布,最大限度地填充和利用哈希空間,從而使哈希碼攜帶的信息量最大化。公式如(3)所示:
(3)
其中,f(gi)是輸出激活值的平均值。
最終的目標函數是三種損失的加權組合,如(4)所示:
L=LMetric+λ1LPush+λ2LBalancing
(4)
其中λ1和λ2為損失的權重參數。對模型進行訓練后,通過哈希函數對輸入的測試集影像進行量化,可以獲得最終的影像哈希碼IRK。此時,對于給定的數據庫中的存檔影像x,設g為利用已訓練模型獲得的中間特征,v=f(g),v為新模型獲取到的特征值,最后的二進制碼b=h(f(g))為:
bn=(sign(vn-0.5)+1)/2,1≤n≤K
(5)
為了檢索影像xi在語義上相似的影像xq。可以用函數計算h(xq)和h(xj)之間的漢明距離以進行影像匹配。這樣模型通過先驗知識學習了一個度量空間,從而使語義空間中兩點之間的歐氏距離對應與像素空間中相應影像對之間的在視覺上的相似性距離。
2.2 模型主干選擇方法
使用模型二次訓練的方法,需要對比選取精度更高的模型主干。此時為了選取模型主干,可以先通過將在自然圖像上已訓練過的模型的中間特征通過一些方法投影到哈希空間,查看模型的遙感影像檢索精度。本文使用的投影方法是Tizhoosh H R等人[16]提出的MinMax Radon Barcodes碼對卷積層的特征直接進行哈希編碼。其中投影二值化的一種最簡單的方法是設置一個代表性(或典型的)閾值[17],這可以通過計算所有非零投影值的中值來完成。文章[16]中提出,通過檢查投影值是如何在局部極值之間轉換的,這能為捕捉在特定角度描述下場景中的圖像的形狀特征提供更有表現力的線索。圖5說明了在給定的角度θ下,MinMaxRadon條碼是如何生成的,當然,從min/max到max/min轉換的0/1的賦值順序只是一種慣例,因此在給定的程序中應保持一致。
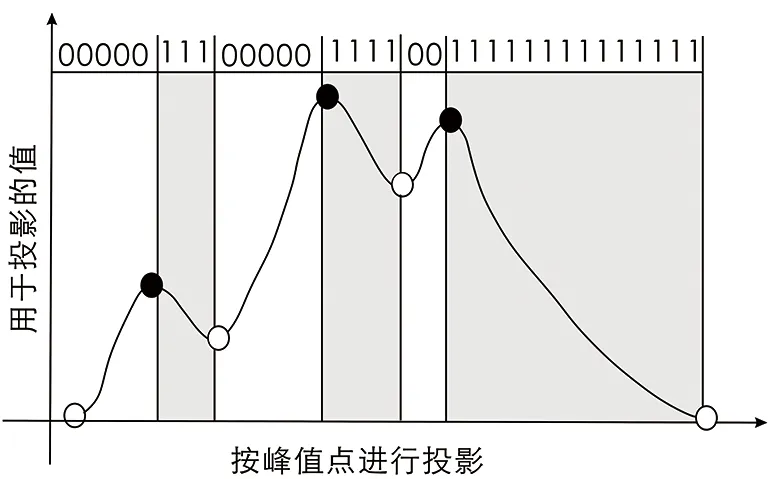
圖5 MinMax Radon條碼
在一定角度內的投影影像被平滑求最小值和最大值。最小值和最大值之間的值賦值為0,而在最大值和最小值之間的值都賦值為1。
2.3 整數編碼索引方法
為了提高海量遙感數據的可擴展性,本文引入了無監督的整數索引方法—通過無監督(VQ-VAE)模型獲取影像整數表示,然后通過VEB tree對整數編碼進行索引,在測試時可以獲取到相似的最近鄰影像。Chen Kun等人[14]提出了用于醫學的組織病理學快速無監督影像檢索(FISH)模型,使得對醫學影像病理切片的檢索具有擴展性、同時檢索速度恒定。FISH模型首先通過訓練無監督模型獲取到影像的潛在離散表示來創建整數索引,然后通過使用VEB tree對整數索引進行數據庫編碼,受益于VEB tree提供的O(loglog(M))搜索速度,其中M是一個固定的常數,FISH模型通過在自然影像上已訓練的DenseNet模型[18]提取卷積塊特征獲取哈希編碼特征來保證檢索精度。其中整數索引的獲得是通過將VQ-VAE中間特征進行平均池化、求和和移位操作組成,通過求和操作可以綜合不同層次特征之間的信息。在提取完測試數據庫中影像的特征后,通過提出的引導搜索算法可以獲得查詢影像最近鄰的相似性的結果。引導搜索算法的設計原則是利用VEB tree來求出一個固定數目的最近鄰,然后通過與預訓練模型提取的特征之間計算漢明距離,以獲得小于某個閾值θ的近鄰,最后再根據漢明距離從小到大排序,獲取最相似的影像。
3 實驗與分析
3.1 實驗數據選取與預處理
(1)實驗數據選取
本文在兩個RS基準上進行實驗,第一個是廣泛使用的UC Merced(UCMD)[19]數據集,其中包括21個類別的土地覆蓋類別的 2 100副航空影像,每張影像的像素大小為256×256,空間分辨率為 30 cm。第二個是航拍影像數據集(AID)[20],在AID數據集中影像來自在不同地點、不同時間和不同成像條件下的不同的傳感器,并且影像分辨率是不一樣的(0.5 m~8 m),這些圖像包含有 10 000張影像。每一副影像為600×600,每個類別的影像數量在220~420之間。數據集具有更高的類內變異性,不同地區、不同尺度、方向和成像條件的圖像存在其中,特別是同一地物上外觀上具有差異,這會給算法帶來更多的挑戰。更小的類間差異性,AID數據集中在不同場景類別中存在更多相似的地物、同時在場景的紋理和顏色上可能更加接近、在場景中存在更多相似的結構分布。更大規模的數據集,針對遙感影像進行標注是非常耗時的,但是如果數據集太小,會導致算法訓練不充分,從而影響到算法的精度。
(2)數據集預處理
在遙感影像檢索實驗中需要將整個數據集進行拆分為訓練集、驗證集、測試集,并且在驗證集、測試集中需要進一步拆分為查詢影像和數據庫。因此,本文首先從數據集中不同的類中隨機抽取,按照訓練集:驗證集:測試集(4∶3∶3)的比例進行拆分,在驗證集和測試集中按照查詢影像:數據庫(1∶2)的比例進行進一步拆分,從而保證檢索算法的精度,UCMD數據集可以直接加載到內存中用于模型訓練,對于AID數據集本文采用加載路徑的方法按批次加載到內存中以供模型訓練。
其中在UCMD數據集中訓練數據有830張影像,驗證集中查詢影像有126張,數據庫中影像有484張,測試集中查詢影像有126張,數據庫中影像有484張。在AID數據集中訓練數據有 4 000張影像,驗證集中查詢影像有612張,數據庫中影像有 2 388張,測試集中查詢影像有612張,數據庫中影像有 2 388張。
3.2 實驗設置
(1)已訓練模型遙感影響檢索精度評定(均使用MinMax Radon編碼進行哈希編碼)
①為了評定模型同一模型但不同型號的已訓練模型對遙感影像檢索的性能的影響,本文選定VGG模型、DenseNet模型、Resnet進行實驗;
②為了評定對于同一任務但不同精度的已訓練模型對遙感影像精度檢索的性能影響,本文增加了Inception-v3模型進行實驗。
③由于UCMD數據集和AID數據集的影像大小不同,因此不同的模型結尾處連接的池化層會有所不同,其中VGG模型使用7×7卷積核的池化層,Resnet模型不使用池化層,DenseNet模型在UCMD數據集中使用6×6卷積核的池化層,在AID數據集中使用11×11的卷積核,Inception-v3提取的是最后池化層的特征。
(2)對已訓練模型進行二次訓練(模型微調)
①使用S Roy等人[13]提出遙感影像訓練方法作為基準,查看在新數據集上遙感影像檢索的精度。
②使用本文提出的多模型遙感影像檢索方法,評定遙感影像檢索的質量和效率。由于UCMD數據集和AID數據集的影像大小不同,因此VQ-Vae編碼后的離散整數圖像大小不同,UCMD的整數圖像為(64×64),AID的整數圖像為(150,150),由于內存的限制,UCMD數據集池化層相乘的等級為[0,0,1e3,1e5],AID數據集池化層相乘的等級為[0,0,1e2,1e4]。算法在Tensorflow、Pytorch框架[21]上實現,在Colab平臺提供的Tesla K80 GPU上進行測試。
3.3 評價指標選取
本文采用平均精度(mean Average Precision,mAP)對所有的查詢圖像進行評估,
(6)
其中Q是查詢圖像的數量,平均精度(AP)是指在精度-召回曲線下的覆蓋面積。較大的AP意味著較高的查全率和較高的檢索精度。AP的計算為:
(7)
其中R表示查詢影像的相關結果數占總數N的比例。P(k)是檢索到的前k張影像的精度,rel(k)是一個指示函數,如果第k位內的圖像是相似圖像,則為1,否則為0。
4 實驗結果
由表1可知,直接使用已訓練的模型在遙感影像上進行檢索,對于遙感影像檢索任務仍可以發揮很好的性能,此時已訓練模型中的結構對遙感影像檢索具有重要影響,通過對比可知Inception_v3模型可以用于提取遙感影像特征,通過有監督方式訓練新的模型有助于提高遙感影像檢索的精度,本文提出的多模型遙感影像檢索方法,因檢索時采用的是局部最近鄰值,會比全局哈希檢索時精度有所下降,由圖6可知,無監督VQ-VAE模型生成測試影像數據庫的整數索引在類別和整數區間上呈現出一定聚類性,這有助于提高遙感影像檢索的可擴展性,但是某些類別仍是難以區分,這與VQ-VAE模型的訓練好壞具有密切聯系。其中在UCMD和AID數據集上的多模型檢索結果如圖7所示。

表1 遙感影像檢索精度
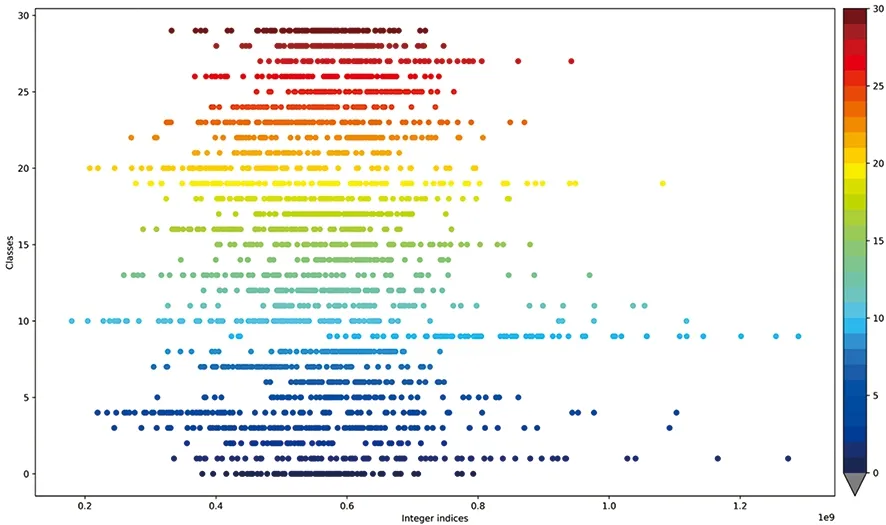
圖6 無監督模型生成整數索引(Integer indices)與類別(classes)關系圖(使用AID測試數據庫中的 2 388張影像的整數索引生成。)

圖7 多模型遙感影像檢索結果
5 結合GEE平臺的遙感數據檢索管道
本文通過與GEE遙感數據平臺相結合,提出了一個用于遙感影像檢索的管道,從而有助于使人們可以使用任何數據集和模型對遙感數據進行檢索實驗。其中GEE平臺上提供許多公開的遙感數據,本文選用NAIP航空遙感數據集的一部分進行實驗,首先選取感興趣區域,并對感興趣區域的柵格影像進行多層的格網劃分,從而獲取遙感影像塊,以影像塊的方式對遙感影像進行檢索,數據需要傳輸到Colab平臺中進行特征編碼,本文選用在自然圖像上已訓練的Densenet-121生成影像的特征編碼,并通過MinMax Radon編碼轉換成哈希編碼,以減少數據存儲和計算需求。通過選定查詢區域可以獲得相似的影像斑塊。這種方法的優點是具有更高的靈活性,可以通過生成格網自由的選定感興趣區域,有助于各種檢索算法在不同的數據集上進行實驗,且具有一個可視化界面,用于對檢索區域進行定位識別。但是這個檢索管道仍然有改進的空間,首先數據從GEE平臺傳輸到Colab平臺中進行特征編碼,這個過程受影像大小和網速的限制,本文使用多線程的方法傳輸數據,以彌補數據傳輸的速度。本文結合GEE平臺的遙感影像檢索管道如圖8所示。
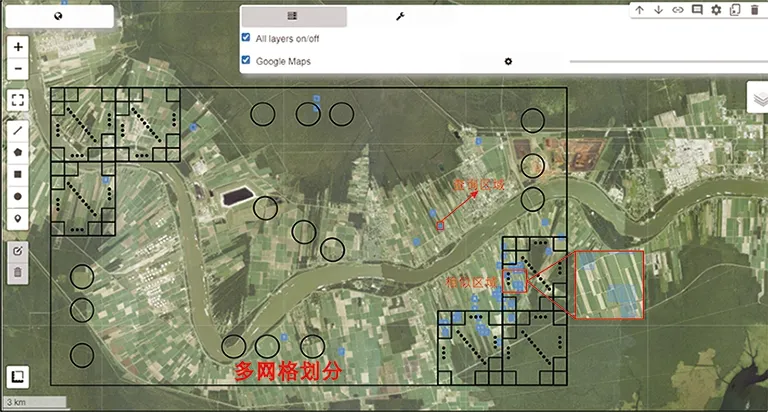
圖8 結合GEE平臺的遙感影像檢索管道
6 結 論
本文提出了多模型遙感影像檢索方法,通過有監督哈希編碼有助于提高遙感影像的檢索算法的質量和效率,同時采用整數索引方法,有助于應對海量遙感數據檢索,使其具有可擴展性。同時本文提出了一個用于遙感影像檢索的管道,有助于靈活地對多種遙感數據和檢索算法進行實驗。未來我們將針對無監督整數索引方法進行優化,提高遙感相似性聚類效果,并提出新的無監督遙感影像檢索訓練方法以自動化地提取遙感影像特征,減輕人工標注的工作量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
