基于半監(jiān)督學習-多通道卷積神經(jīng)網(wǎng)絡(luò)的加氫裂化產(chǎn)品性質(zhì)預測
2023-02-02 07:25:18羅文山陸鵬飛李保良曹曉紅
石油學報(石油加工) 2023年1期
王 晨, 羅文山, 陸鵬飛, 李保良, 曹曉紅, 楊 紀
(中海油 惠州石化有限公司,廣東 惠州 516086)
加氫裂化工藝是在高溫、高壓和催化劑存在下,使重油發(fā)生裂化反應,轉(zhuǎn)化為氣體、汽油、柴油等的石油二次加工過程,與其他加工工藝相比,其具有液體產(chǎn)品收率高、飽和度高等特點[1]。加氫裂化作為煉油廠重要的二次加工工藝可加工從石腦油到渣油范圍的油品,并提供優(yōu)質(zhì)高辛烷值汽油、中間餾分油或化工料,通過靈活調(diào)節(jié)進料與產(chǎn)品方案在企業(yè)降本增效中發(fā)揮著巨大作用[2]。同時加氫裂化也是滿足日益嚴格的油品清潔標準的最有力手段,因此對加氫裂化產(chǎn)品性質(zhì)進行實時預測具有重要意義[3-4]。
然而對加氫裝置全部升級安裝在線分析儀成本高,且儀器需定期校準維護,導致推廣實施受限。隨著煉油化工企業(yè)信息化水平不斷提高、數(shù)字化轉(zhuǎn)型不斷深入,煉油化工企業(yè)已逐漸積累大量生產(chǎn)數(shù)據(jù),通過數(shù)據(jù)驅(qū)動的機器學習等人工智能(AI)算法對生產(chǎn)大數(shù)據(jù)進行挖掘建模,實現(xiàn)生產(chǎn)過程故障診斷、關(guān)鍵參數(shù)預警、產(chǎn)品性質(zhì)預測等智能化應用,已逐漸成為目前流程工業(yè)界在智能控制優(yōu)化領(lǐng)域的研究、應用熱點[5-7]。機器學習,尤其以卷積神經(jīng)網(wǎng)絡(luò)(Convolutional neural network, CNN)為代表的深度學習技術(shù)通過逐層特征學習,由低級到高級自動提取與預測任務相關(guān)聯(lián)的潛在表示,已在計算機視覺(Computer vision, CV)、自然語言處理(Natural language processing, NLP)等領(lǐng)域獲得巨大成功[8-10]。
近幾年得益于深度學習理論、開源框架、GPU等加速計算硬件的不斷突破創(chuàng)新,利用深度學習等先進AI算法對煉油化工裝置數(shù)據(jù)的潛在結(jié)構(gòu)、分布特征進行自動學習和逐層特征提取,從而最終實現(xiàn)KPI預測等相關(guān)智能應用的研究日益深入。楊帆等[11]綜述了神經(jīng)網(wǎng)絡(luò)在催化裂化過程模型的構(gòu)建與分析,并探討了神經(jīng)網(wǎng)絡(luò)與智能優(yōu)化算法結(jié)合方面的優(yōu)勢。李詔陽等[12]基于Aspen HYSYS軟件建立了潤滑油加氫裝置機理模型,并基于機理模型擴展了裝置運行數(shù)據(jù)集,在擴展數(shù)據(jù)集構(gòu)建了長短時記憶網(wǎng)路(LSTM),對潤滑油產(chǎn)品運動黏度、閃點等性質(zhì)實現(xiàn)了準確預測。田水苗等[13]基于Aspen HYSYS機理模型擴充而來的蠟油加氫裂化數(shù)據(jù)集,構(gòu)建了BPNN用于精制蠟油流量、性質(zhì)等預測,并通過多目標優(yōu)化給出了最佳操作工況參數(shù)。在堆疊式自編碼(Stacked auto-encoder, SAE)應用方面,Yuan等[14]基于SAE對加氫裂化航空煤油產(chǎn)品10%和50%體積沸點進行預測,并結(jié)合線性插值通過對SAE逐層預訓練實現(xiàn)了小樣本學習任務的數(shù)據(jù)增強(Data augment, DA),所提出的逐層數(shù)據(jù)增強-堆疊編碼器(Layer-wise data augment-SAE, LWDA-SAE)有效提升了模型預測性能。Wang等[15]基于SAE開發(fā)了一種有監(jiān)督堆疊式自編碼器(Supervised stacked auto-encoder, SSAE),克服了SAE無監(jiān)督預訓練階段欠缺提取與目標變量相關(guān)特征信息的不足,并在加氫裂化裝置工藝參數(shù)波動診斷中驗證了其有效性。CNN在流程工業(yè)建模中表現(xiàn)出良好的局部特征學習能力,Wu等[16]基于樸素CNN算法對田納西伊斯曼化工過程進行了仿真驗證;Zhu等[17]構(gòu)建了滑動窗卷積網(wǎng)絡(luò)(Moved-window convolutional neural network, MWCNN),通過等寬滑動窗卷積操作學習乙烯裂解過程時域和空間域特征信息,并最終實現(xiàn)乙烯裂解產(chǎn)物氣相組分含量預測。考慮到影響加氫產(chǎn)品質(zhì)量的因素貫穿從進料、反應、分離到分餾整個工藝流程,任一流程環(huán)節(jié)波動均會影響產(chǎn)品質(zhì)量,且加氫裂化工藝流程復雜,工況多變,煉化機理和理化性質(zhì)使得整個工藝過程呈高維、大時滯、非線性等特點[18-19],使得應用深度學習算法實現(xiàn)加氫裂化產(chǎn)品性質(zhì)預測仍面臨諸多挑戰(zhàn)。首先在多維度特征學習方面,單純應用CNN、LSTM等難以同時對加氫裂化工藝流程的時域和空間域特征進行多維度特征抽取,而在樣本尺度方面,受限于大部分加氫產(chǎn)品性質(zhì)的人工化驗數(shù)據(jù)量不足,化驗數(shù)據(jù)不能與裝置DCS實時數(shù)據(jù)在時間維度對齊,大大降低了裝置實時數(shù)據(jù)的利用率,所導致的小樣本學習問題將顯著影響深度學習模型性能[ 20-21]。
針對上述時空域多維特征抽取問題,提出了將多通道卷積神經(jīng)網(wǎng)絡(luò)(Multi-channel convolutional neural network, MCCNN)用于加氫裂化裝置建模,通過對歷史生產(chǎn)數(shù)據(jù)的多通道時序采樣實現(xiàn)加氫裂化流程的時序特征學習,通過CNN實現(xiàn)加氫裂化流程的空間域特征學習。針對小樣本學習問題,提出了基于教師-學生半監(jiān)督學習(TS-SSL)算法創(chuàng)建虛擬性質(zhì)數(shù)據(jù),并與裝置DCS實時數(shù)據(jù)對齊,從而實現(xiàn)樣本數(shù)據(jù)擴充,最終提出半監(jiān)督學習-多通道卷積神經(jīng)網(wǎng)絡(luò)(SSL-MCCNN),進一步提升對加氫裂化產(chǎn)品性質(zhì)預測性能。以某煤油-柴油加氫裂化工業(yè)裝置為研究對象,對裝置產(chǎn)品的重石腦油密度、柴油閉口閃點進行預測,結(jié)果與BPNN、徑向基神經(jīng)網(wǎng)絡(luò)RBFNN對比,驗證了所提出SSL-MCCNN算法的優(yōu)越性。
1 MCCNN算法
1.1 CNN與加氫裂化數(shù)據(jù)維度重塑
Lecun等[22]提出的LeNet5是CNN算法最早用于手寫數(shù)字識別的研究,LeNet5結(jié)構(gòu)如圖1所示。輸入為32×32的手寫圖片依次通過卷積層(Convolutions)、下采樣層(Subsampling)和全連接層(Full connection),最終輸出預測分類結(jié)果。其中C1卷積層包含6個卷積核,用于卷積計算提取圖片像素間的局部特征信息,得到6個輸出特征圖;下采樣層用于對輸出特征圖的降維,進一步提取關(guān)鍵特征表示;最后的全連接層與傳統(tǒng)BP網(wǎng)絡(luò)相同,用于之前卷積結(jié)果的一維重塑并輸出最終預測結(jié)果。
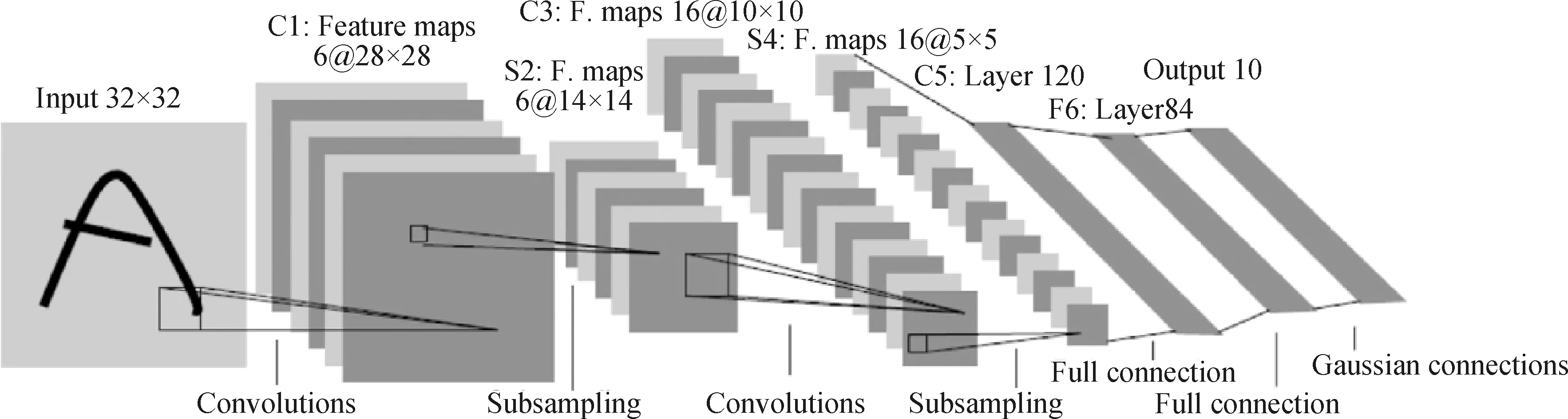
圖1 LeNet5模型結(jié)構(gòu)圖Fig.1 Structure chart of LeNet5 model
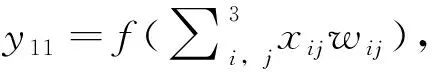
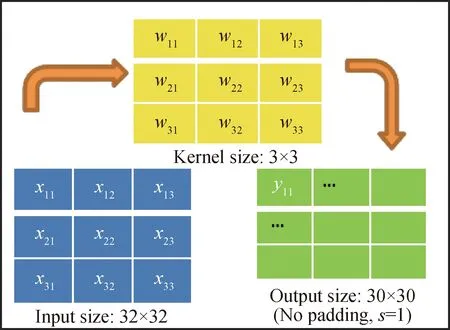
圖2 典型卷積操作示意圖Fig.2 Typical convolution operation diagram
某煉油廠煤油-柴油加氫裂化裝置工藝流程如圖3所示。考慮到加氫裂化不同工藝流程部位的參數(shù)存在復雜機理關(guān)系,提出了應用CNN算法逐層提取這些隱含在空間域的關(guān)系信息,所提取的信息作為最終預測任務的輸入表示。為滿足圖2所示輸入數(shù)據(jù)的二維矩陣格式,首先對加氫裂化樣本數(shù)據(jù)進行二維重塑,如圖4所示。以煤油-柴油加氫裂化裝置為研究對象,按照加氫裂化裝置從進料、預熱、反應、分離、分餾整個流程全面選取126個主要工藝參數(shù),并根據(jù)局部工藝子流程順序按行排列,其中每1行表示1個加氫裂化局部子流程,最終將126維向量數(shù)據(jù)重塑為9×14二維矩陣作為SSL-MCCNN的輸入。
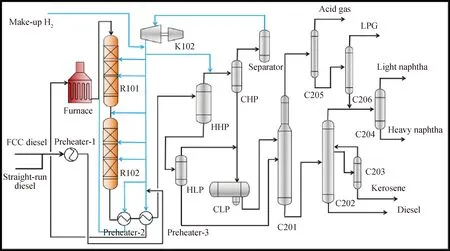
C201—H2S stripper; C202—Main fractionator; C203—Side stripper; C204—Naphtha fractionator; C205—Adsorption-desorption tower; C206—Debutanizer; CHP—Cold high pressure separator; CLP—Cold low pressure separator; HHP—Hot high pressure separator; HLP—Hot low pressure separator; K102—Recycled gas compressor; R101—Hydrotreating reactor; R102—Hydrocreacking reactor圖3 煤油-柴油加氫裂化工藝原則流程圖Fig.3 Flowchart of kerosene-diesel hydrocracking process
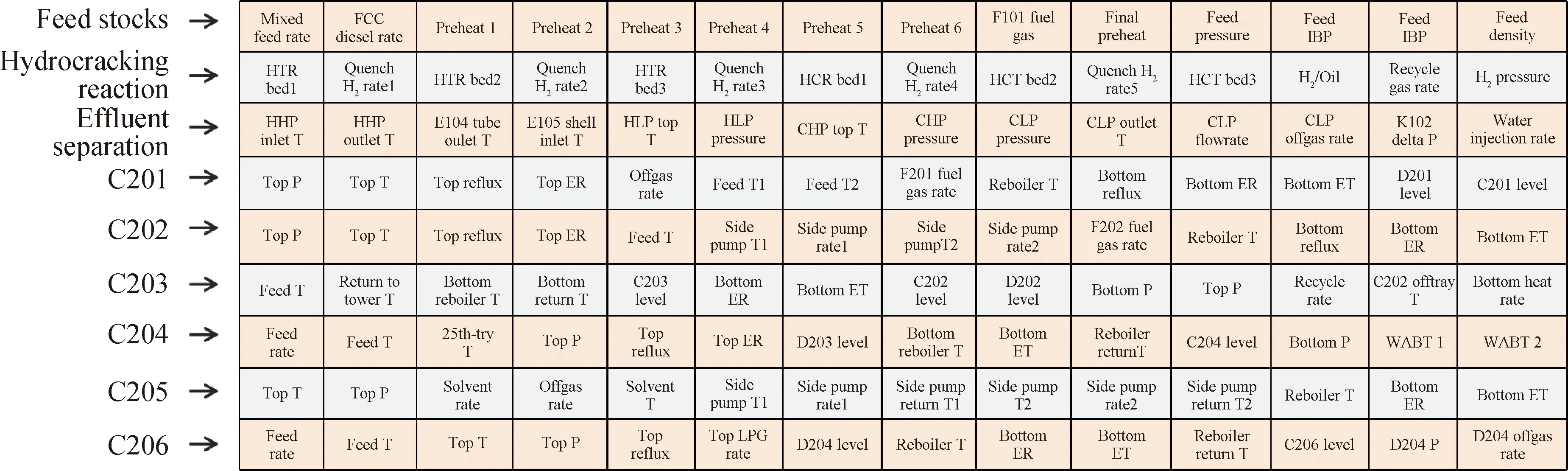
D201—Condensation tank of C201; D202—Condensation tank of C202; D203—Condensation tank of C204; D204—Condensation tank of C206; ER—Effluent rate; ET—Effluent temperature; F101—Feeding furnace; F201—Reboiler of C201; F202—Fractionation furnace; FBP—Final boiling point; FCC—Fluid catalytic cracking; H2/Oil—Volume ratio of hydrogen to oil; IBP—Initial boiling point; K102—Recycle gas compressor; LPG—Liquefied petroleum gas; P—Pressure; delta P—Pressure difference; T—Temperature; WABT—Weighted average bed temperature圖4 加氫裂化樣本數(shù)據(jù)維度重塑Fig.4 Dimension remodeling of hydrocracking data sample
1.2 基于多通道采樣的CNN算法(MCCNN)
考慮傳統(tǒng)CNN算法常用于圖像識別、目標定位等空間像素特征提取,首先基于CNN算法特點實現(xiàn)了加氫裂化工藝流程空間域的局部特征提取,而研究表明時域特征對流程工業(yè)特征學習依然至關(guān)重要[24-25]。煉化生產(chǎn)屬典型流程工業(yè),數(shù)據(jù)樣本的產(chǎn)生具有時間連續(xù)性特點,一段時間內(nèi)的裝置數(shù)據(jù)樣本蘊含了加氫裂化流程中包括進料、反應、分餾等各工藝段的運行、變化趨勢等時序特征信息,對預測未來時間點的產(chǎn)品性質(zhì)具有重要意義。以長短時記憶網(wǎng)絡(luò)(Long shot-term memory, LSTM)為代表的RNN類神經(jīng)網(wǎng)絡(luò)等時序建模研究,廣泛應用于煉油化工裝置的時序特征提取[26-27],然而受限于RNN處理復雜工藝流程序列數(shù)據(jù)時的“梯度消失”、“梯度爆炸”等問題[28],隨著序列數(shù)據(jù)增長,單純RNN類模型性能發(fā)生退化;另一方面,作為序列到序列的建模范式,LSTM等RNN算法因不適于并行加速而導致訓練與推理時間成本的增加,已逐漸被注意力模型取代[29]。
考慮CNN算法對RGB 3通道彩色圖像的學習特點[30],提出了如圖5所示的多通道采樣算法,用于加氫裂化裝置生產(chǎn)數(shù)據(jù)樣本獲取。基于圖4所述單個時間點的二維矩陣數(shù)據(jù)樣本,通過增加時間維度方向的采樣,以固定采樣頻率(例如15 min)實施裝置歷史數(shù)據(jù)采集,并在時間維度上疊加多個時間點樣本,整體得到1個3D樣本作為CNN算法的多通道輸入,用于多維度描述加氫裂化裝置生產(chǎn)工況,最終實現(xiàn)提取裝置空間域和時域潛在特征信息,提高模型對產(chǎn)品性質(zhì)的預測性能。
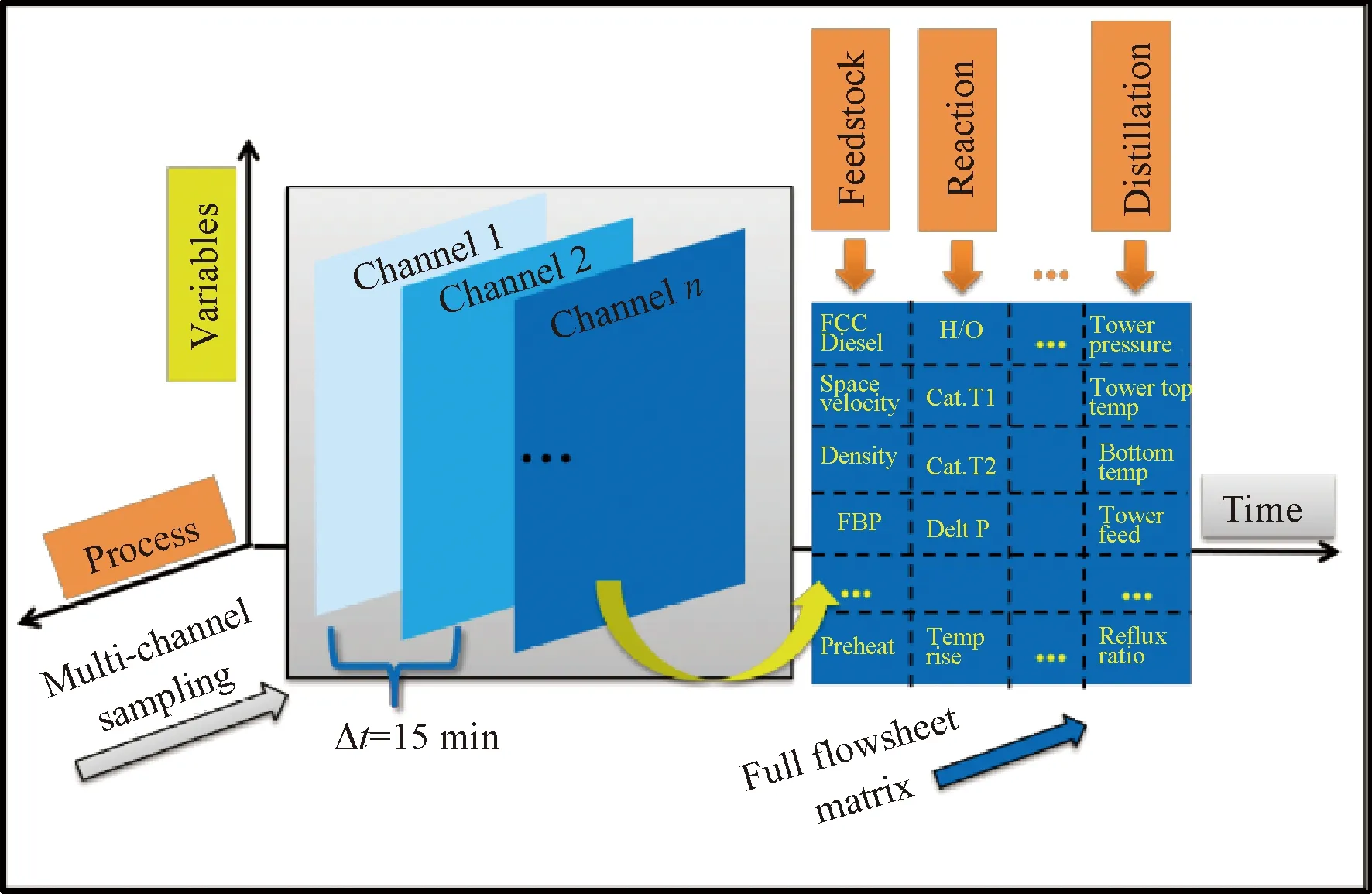
圖5 多通道采樣示意圖Fig.5 Schematic diagram of multi-channel sampling
1.3 MCCNN算法流程框架
根據(jù)上述CNN算法用于加氫裂化工藝流程建模方案的描述,結(jié)合多通道采樣方案,MCCNN算法整體流程如圖6所示。經(jīng)過二維重塑的多通道3D樣本數(shù)據(jù)輸入到卷積層,根據(jù)預測目標自適應提取工藝流程潛在特征信息,例如對航空煤油性質(zhì)進行預測,模型自動提取航空煤油分餾塔特征信息;對重石腦油終餾點(FBP)預測,則模型自動提取加氫裂化反應器和石腦油分餾塔特征信息。經(jīng)卷積計算所提取的特征信息通過全連接層的非線性轉(zhuǎn)換,最終實現(xiàn)對加氫產(chǎn)品各項性質(zhì)的回歸預測。
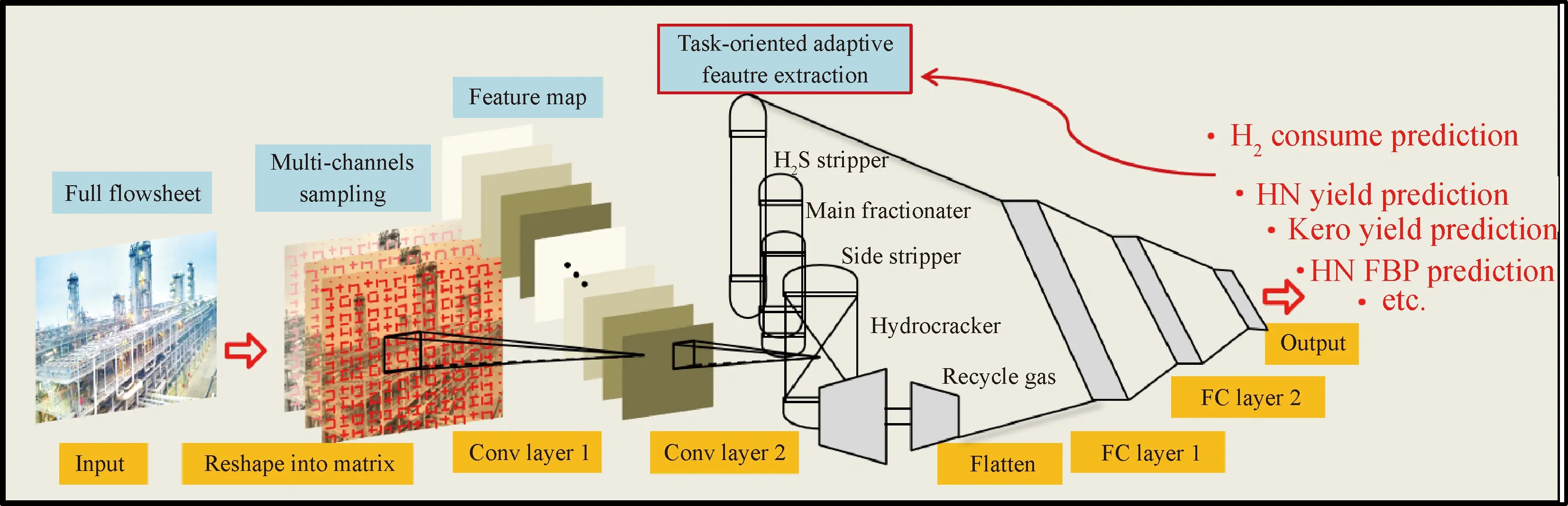
Conv—Convolutional; FC—Full connected; HN—Heavy naphtha; Kero—Kerosene圖6 MCCNN算法流程圖Fig.6 Flowchart of MCCNN algorithm
MCCNN模型訓練和推理流程如圖7所示,分為離線訓練和在線推理預測2個階段。
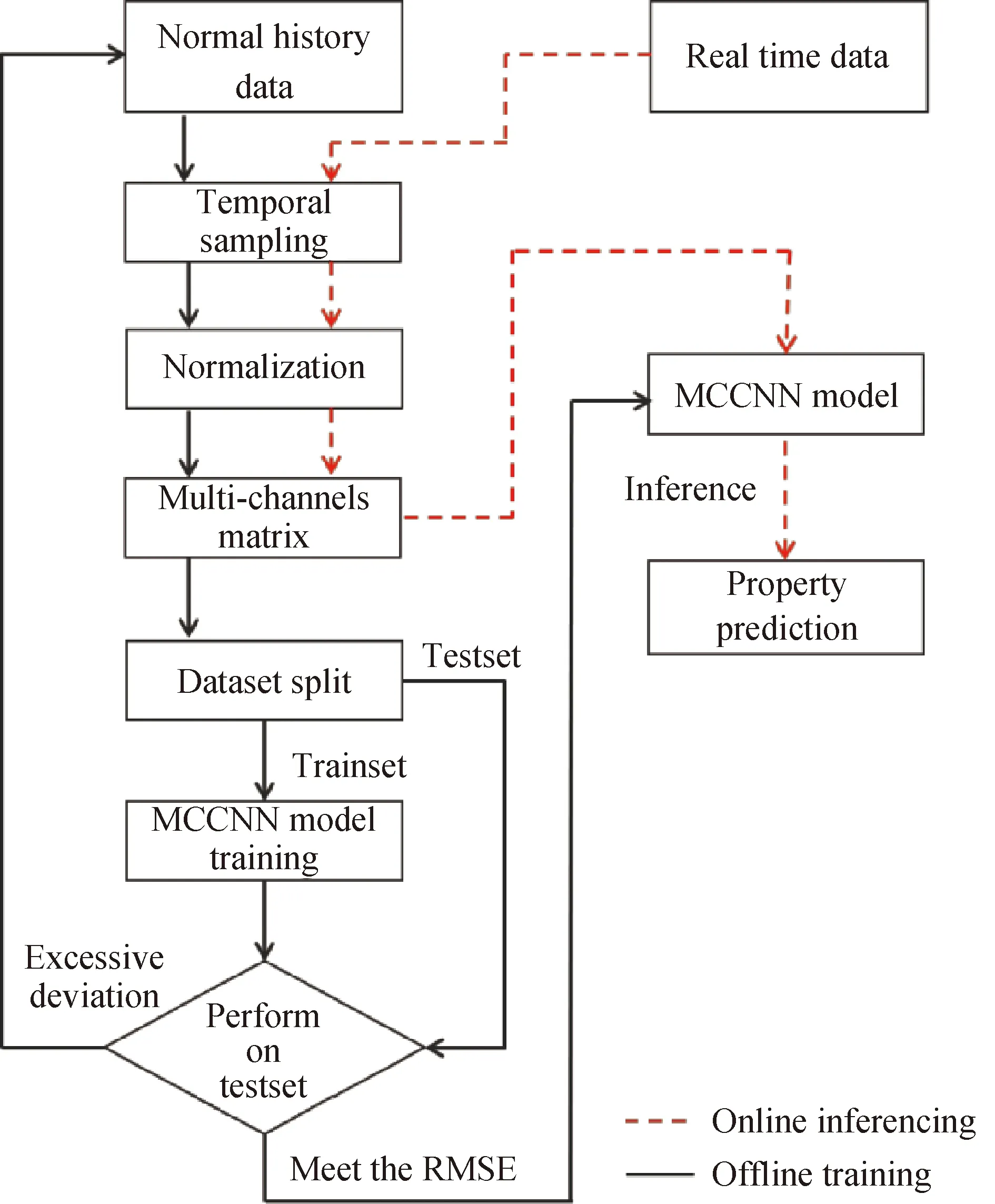
圖7 基于MCCNN產(chǎn)品性質(zhì)預測流程框架Fig.7 Framework of product properties predicted based on MCCNN
離線訓練階段:
Step1:裝置歷史數(shù)據(jù)采集;
Step2:樣本數(shù)據(jù)多通道采樣;
Step3:樣本數(shù)據(jù)歸一化;
Step4:多通道樣本數(shù)據(jù)二維矩陣重塑;
Step5:樣本數(shù)據(jù)集分割為訓練集、測試集;
Step6:模型訓練,驗證結(jié)果滿足RMSE指標則部署模型,否則回到Step5。
在線推理預測階段:
Step1:實時數(shù)據(jù)讀入;
Step2:實時數(shù)據(jù)多通道采樣;
Step3:實時數(shù)據(jù)歸一化;
Step4:多通道實時數(shù)據(jù)二維矩陣重塑;
Step5:MCCNN模型推理預測,獲得產(chǎn)品性質(zhì)預測結(jié)果。
2 加氫裂化產(chǎn)品性質(zhì)預測
2.1 樣本數(shù)據(jù)集構(gòu)建與模型參數(shù)配置
基于2019年6月—2021年9月煤油-柴油加氫裂化裝置歷史數(shù)據(jù),以重石腦油密度、柴油閉口閃點作為預測目標,選取126個工藝參數(shù)基于MCCNN全流程建模。樣本數(shù)據(jù)的時序采樣采用多通道采樣算法(見圖5),考慮加氫裂化裝置從進料到餾出產(chǎn)品整個工藝流程耗時約30 min,因此選取3個相互間隔15 min的時間點即可對從進料到產(chǎn)品整個工藝流程時序的覆蓋。3D采樣頻率為3 h,每個3D樣本的時序通道間隔15 min,每3個時序通道作為1個3D樣本并以最后1個時序通道對應的產(chǎn)品性質(zhì)作為3D樣本的標簽,如圖8所示為時鐘6∶00、9∶00、12∶00共3個3D樣本。總共獲取包含LIMS化驗性質(zhì)標簽數(shù)據(jù)共1552組,按照比例7∶1∶2分割為訓練集、驗證集和測試集,整個數(shù)據(jù)集在各工藝流程段的分布如表1所示。
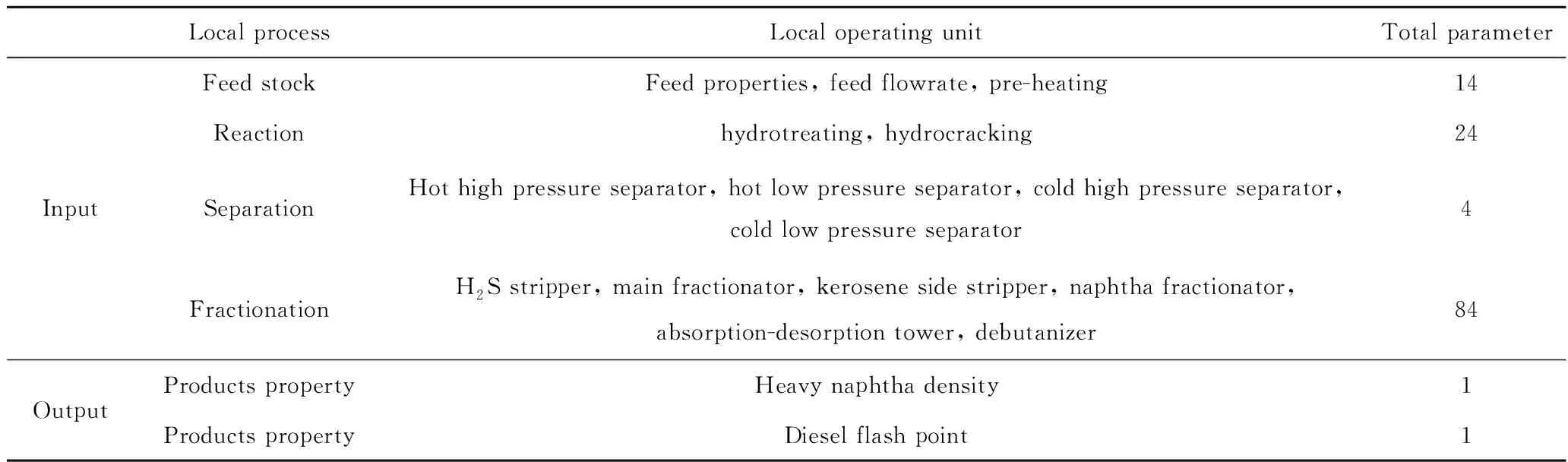
表1 煤油-柴油加氫裂化裝置數(shù)據(jù)集分布Table 1 Distribution of kerosene-diesel hydrocracking unit data set
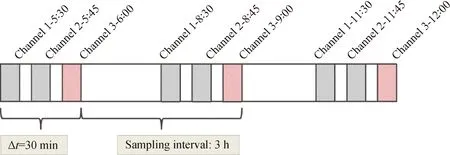
圖8 歷史數(shù)據(jù)多通道時序采樣示意圖Fig.8 Schematic diagram of multi-channel temporal sampling for historical data
根據(jù)圖6,MCCNN算法包括卷積層、全連接層,考慮煤油-柴油加氫全流程樣本矩陣為9×14,尺寸不大,故不采用池化層降維,模型訓練優(yōu)化器(Optimizer)采用Adam[31],設(shè)定學習率(Learning rate)為0.001,基于Tensorflow深度學習框架[32]經(jīng)試錯法(Trial-and-error)得到含有3個卷積模塊(Conv)和3層全連接網(wǎng)絡(luò)(FC)的網(wǎng)絡(luò)模型結(jié)構(gòu),如表2所示。3通道矩陣樣本經(jīng)歸一化預處理后送入含有64個卷積核的第一卷積層(Conv_1(64))進行初步特征提取,然后經(jīng)批歸一化(Batch normalization, BN)和ReLU激活函數(shù)(Activation function, AF),對第一次卷積結(jié)果進行中心歸一化和非線性轉(zhuǎn)化,從而完成第1個卷積模塊操作,樣本數(shù)據(jù)完成3個Conv模塊的表示學習后,將特征提取結(jié)果依次送入3層FC(64,128,1)網(wǎng)絡(luò),完成最終預測。考慮重石腦油密度和柴油閃點均為實值類回歸預測任務,故模型在訓練過程中的度量指標(Metrics)采用均方誤差(Mean square error, MSE);模型測試評估指標采用RMSE和判定系數(shù)R2,分別見式(1)和式(2)。
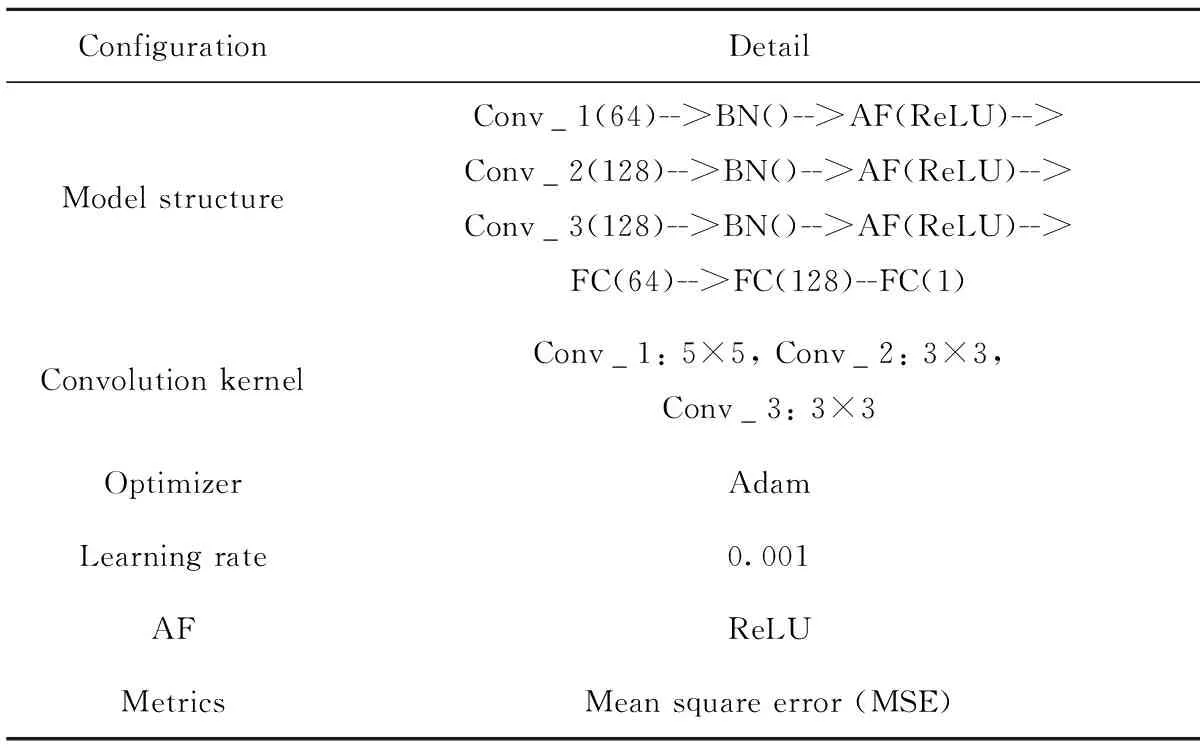
表2 MCCNN模型參數(shù)配置Table 2 Parameter configuration of MCCNN model
(1)
(2)
式中:N為樣本數(shù)據(jù)容量;Yobs,i為標簽變量(此處指加氫裂化產(chǎn)品性質(zhì))真實值;Ymodel,i為標簽變量預測值;Ymean為標簽樣本平均值。RMSE為預測值與真實值之間的均方根誤差,RMSE值越小,則模型越精確,量綱與標簽變量相同。R2指MCCNN模型自適應學習到的特征信息對標簽變量整體變化方差的解釋程度,表征模型學習到的特征信息用于預測產(chǎn)品性質(zhì)的合理程度,R2值越大,模型越合理[33]。
2.2 重石腦油密度預測
基于MCCNN模型對重石腦油產(chǎn)品密度預測值(Predicted values, PVs)、真實值(Actual values, AVs)及絕對誤差(Absolute error, AE)如圖9(a)所示,CNN、BPNN、RBFNN對比模型預測結(jié)果如圖9(b)、(c)、(d)所示。CNN算法對加氫裂化全流程參數(shù)空間域的局部潛在關(guān)系和特征知識進行自適應特征提取,深入學習到了加氫裂化反應深度、石腦油分餾過程等關(guān)于預測重石腦油密度對應的特征表示,RMSE和R2分別為1.61和0.62,性能顯著優(yōu)于BPNN和RBFNN。MCCNN模型基于CNN算法在提取加氫裂化流程空間域特征基礎(chǔ)上,通過多通道采樣增加了對加氫裂化動態(tài)時域特征的學習提取,使得RMSE和R2分別達到1.30和0.75,性能最優(yōu)。
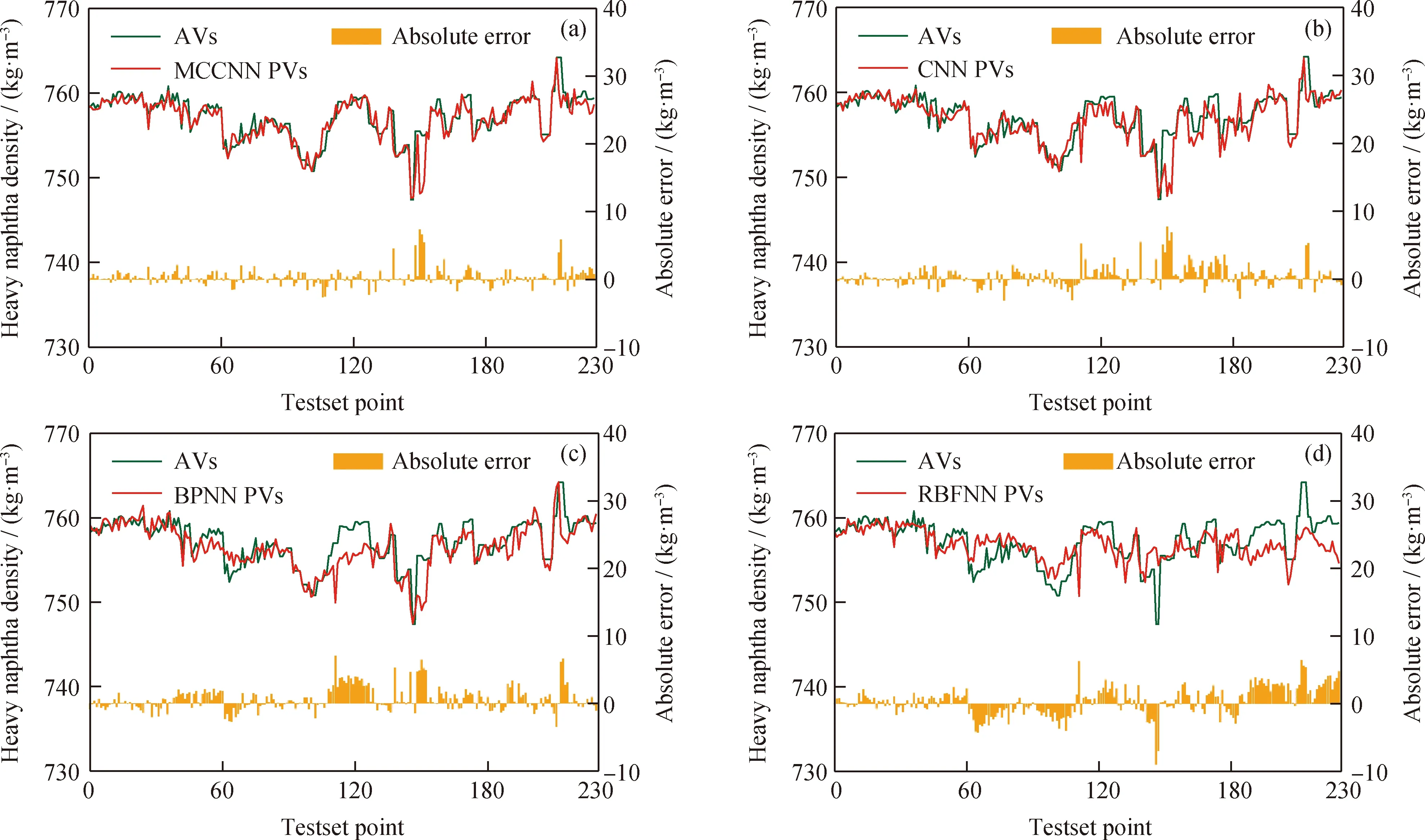
AVs—Actual values; PVs—Predicted values圖9 不同模型預測的重石腦油密度(20 ℃)對比Fig.9 Comparison of heavy naphtha density (20 ℃) predicted by different models(a) MCCNN: RMSE=1.30, R2=0.75; (b) CNN: RMSE=1.61, R2=0.62; (c) BPNN: RMSE=1.83, R2=0.51; (d) RBFNN: RMSE=2.11, R2=0.34
2.3 柴油閃點預測
MCCNN模型對柴油產(chǎn)品閃點預測結(jié)果如圖10(a)所示,CNN、BPNN、RBFNN對比模型預測結(jié)果如圖10(b)、(c)、(d)所示。與對重石腦油密度預測原理相同,CNN算法對加氫裂化全流程參數(shù)空間域的局部潛在關(guān)系和特征知識進行自適應特征提取,深入學習到了加氫裂化反應深度、主分餾過程等關(guān)于預測柴油產(chǎn)品閃點對應的特征表示,RMSE和R2分別為2.20和0.91,性能顯著優(yōu)于BPNN和RBFNN。MCCNN模型基于CNN空間域特征提取基礎(chǔ)上,通過多通道采樣增加了對加氫裂化動態(tài)時域特征的學習提取,RMSE和R2分別為1.70和0.94,性能達到最優(yōu)。
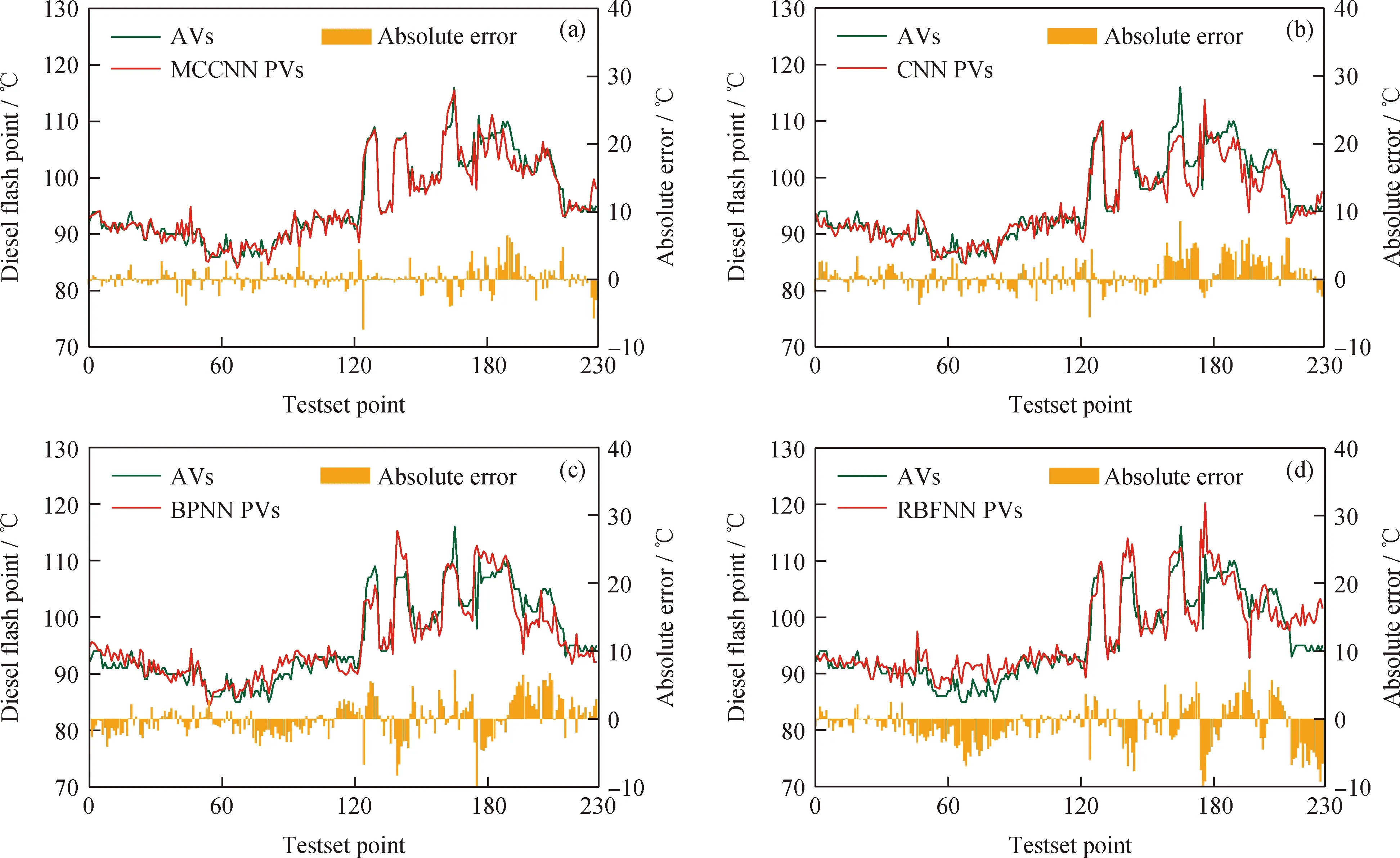
AVs—Actual values; PVs—Predicted values圖10 不同模型預測的柴油閃點對比Fig.10 Comparison of diesel flash point predicted by different models(a) MCCNN: RMSE=1.70, R2=0.94; (b) CNN: RMSE=2.20, R2=0.91; (c) BPNN: RMSE=2.69, R2=0.86; (d) RBFNN: RMSE=3.18, R2=0.81
3 TS-SSL實現(xiàn)MCCNN性能提升
3.1 TS-SSL算法及SSL-MCCNN算法
目前大部分加氫裂化裝置產(chǎn)品性質(zhì)為人工化驗分析,產(chǎn)品性質(zhì)數(shù)據(jù)作為MCCNN模型訓練的樣本標簽,數(shù)量遠小于裝置生產(chǎn)運行的DCS數(shù)據(jù),因此基于裝置歷史數(shù)據(jù)訓練MCCNN模型實現(xiàn)對產(chǎn)品性質(zhì)預測屬典型小樣本學習問題。相關(guān)研究表明,基于SSL算法生成虛擬樣本集,可有效解決模型有監(jiān)督訓練標簽不足的問題,從而提升模型性能[34-35]。SSL用于應對小樣本學習問題原理如圖11所示。隨著每一輪半監(jiān)督訓練產(chǎn)生新的虛擬樣本集,使得總樣本集的分布逐漸接近整體分布,從而提升分類超平面精確度。
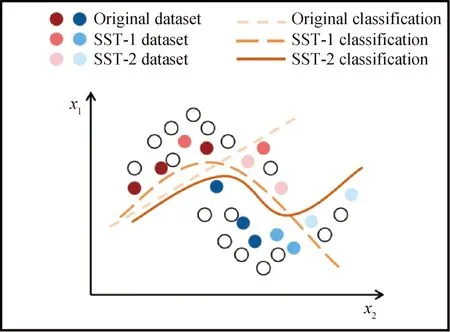
圖11 SSL提升小樣本學習性能示意圖Fig.11 Schematic diagram of improving the learning performance of small samples by SSL
在流程工業(yè)小樣本學習建模研究中,Yuan等[36]通過半監(jiān)督堆疊自編碼器(Semi-supervised stacked auto-encoder, SS-SAE)在半監(jiān)督訓練階段實現(xiàn)了流程工業(yè)無標簽數(shù)據(jù)和有標簽數(shù)據(jù)的合理利用,并在脫丁烷塔和加氫裂化過程建模中驗證了算法的有效性。Zhu等[21]基于局部線性嵌入(Local linear embedding, LLE)生成虛擬樣本并使用BPNN模型對虛擬樣本打標,最終構(gòu)建虛擬數(shù)據(jù)集,用于再次訓練BPNN模型以提升性能,提出的算法有效性在對苯二甲酸純化和聚乙烯2個工業(yè)裝置得到驗證。Zhang等[37]基于等距特征映射(Isometric mapping, ISOMAP)和插值算法生成虛擬樣本,并使用基于有監(jiān)督訓練的極限學習機(Extreme learning machine, ELM)對虛擬樣本打標,從而構(gòu)建虛擬數(shù)據(jù)集實現(xiàn)ELM性能提升,該算法在對苯二甲酸純化裝置得到驗證。
考慮加氫裂化裝置已存在足量DCS裝置運行數(shù)據(jù)而缺乏相應產(chǎn)品性質(zhì)化驗數(shù)據(jù),提出TS-SSL用于構(gòu)建虛擬標簽,最終提升MCCNN模型性能,圖12 為TS-SSL小樣本學習算法示意圖。TS-SSL算法的步驟如下:
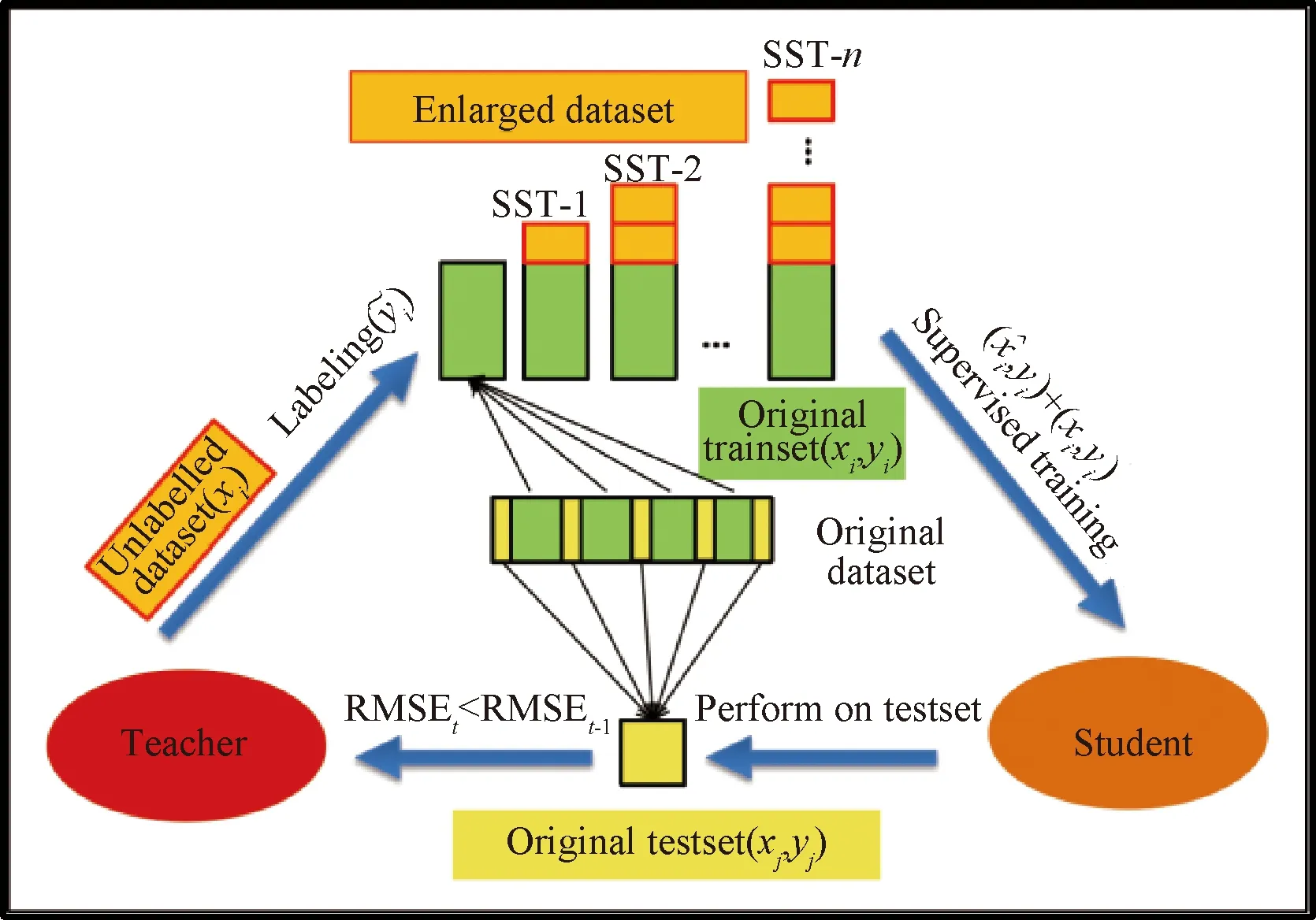
圖12 TS-SSL小樣本學習算法示意圖Fig.12 Schematic diagram of learning algorithm based on TS-SSL for small samples
Step1:對原始樣本集(xi,yi)分層抽樣,得到原始訓練集(Original trainset)和原始測試集(Original testset);
Step2:基于Original trainset訓練MCCNN得到教師模型(Teacher);
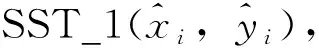
Step5:基于Original testset對Student模型評估得到RMSE1;
Step6:若RMSE1小于當前最優(yōu)RMSE,則Student模型作為Teacher模型,繼續(xù)Step3,否則回到Step4;
Step7:持續(xù)迭代TS-SSL過程直到滿足RMSE所設(shè)定的閾值或達到設(shè)定的SSL輪數(shù)。
3.2 SSL-MCCNN用于加氫裂化產(chǎn)品性質(zhì)預測
基于TS-SSL算法對煤油-柴油加氫裂化裝置重石腦油密度預測樣本數(shù)據(jù)集和柴油產(chǎn)品閃點預測樣本數(shù)據(jù)集進行擴充,如表3所示,2個預測案例數(shù)據(jù)
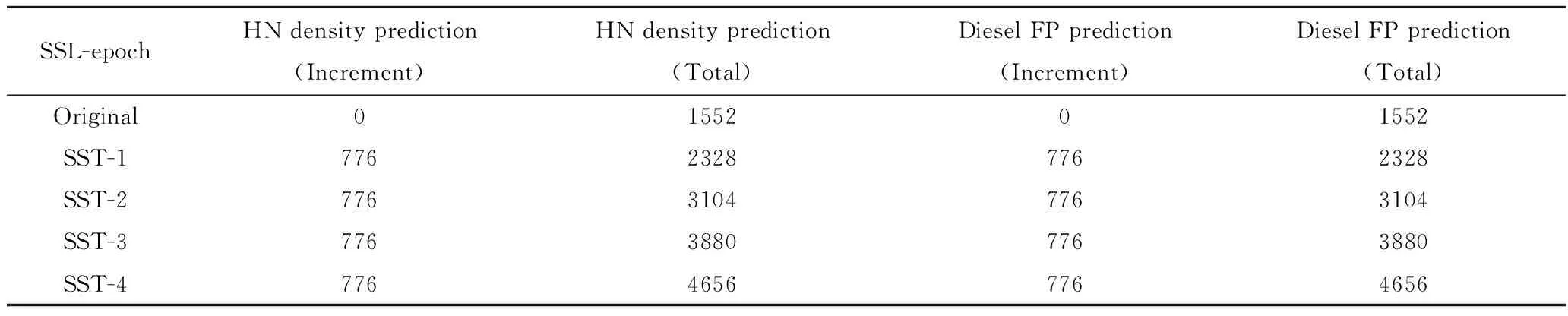
表3 基于TS-SSL數(shù)據(jù)集擴充Table 3 Data set enlargement based on TS-SSL
集經(jīng)4輪TS-SSL半監(jiān)督學習打標,樣本容量由最初1552擴充到4656,顯著增大了用于MCCNN有監(jiān)督訓練的樣本數(shù)據(jù)。
應用表3所示每輪數(shù)據(jù)集訓練MCCNN并分別對重石腦油密度和柴油閃點進行預測,預測值(PVs)和實際值(AVs)如圖13所示。由圖13(b)、(d)可見,隨著SST輪數(shù)增加,與單純MCCNN相比,得益于訓練樣本擴充,SSL-MCCNN對重石腦油密度的預測結(jié)果RMSE由1.3降低為0.83,R2由0.75提升為0.90,同時對柴油閃點的預測結(jié)果RMSE由1.7降為1.03,R2由0.94提升為0.98,表明隨著虛擬樣本數(shù)據(jù)的增加,模型提取到了更多工況下的特征信息,在預測性能得到提升的同時,所提取特征信息的合理性也顯著增強。
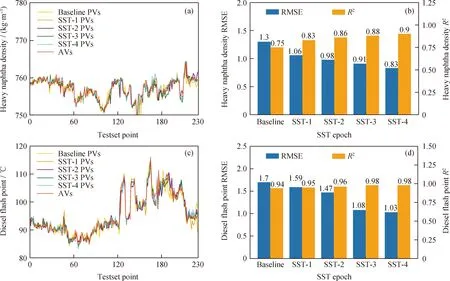
AVs—Actual values; PVs—Predicted values圖13 重石腦油密度和柴油閃點的SSL-MCCNN預測對比Fig.13 Comparison of heavy naphtha density and diesel flash point predicted by SSL-MCCNN(a) Prediction result of heavy naphtha density; (b) Prediction performance of heavy naphtha density; (c) Prediction result of diesel flash point; (d) Prediction performance of diesel flash point
4 結(jié) 論
(1)根據(jù)加氫裂化工藝流程特點,提出了多通道卷積神經(jīng)網(wǎng)絡(luò)(MCCNN)算法用于全流程建模,并通過多通道二維矩陣樣本采樣,自適應提取加氫裂化過程與產(chǎn)品性質(zhì)預測相關(guān)的空間域和時域特征信息,對重石腦油密度預測的RMSE和R2分別為1.30和0.75,對柴油閃點預測的RMSE和R2分別為1.70和0.94,與CNN、BPNN和RBFNN模型相比顯示出優(yōu)越性能。
(2)針對加氫裂化產(chǎn)品性質(zhì)預測的小樣本學習問題,提出了教師-學生半監(jiān)督學習(TS-SSL)算法生成虛擬數(shù)據(jù)樣本集,通過數(shù)據(jù)增強促進模型提取到豐富的特征信息,所提出的半監(jiān)督學習-多通道卷積神經(jīng)網(wǎng)絡(luò)(SSL-MCCNN)對重石腦油密度預測的RMSE和R2分別為0.83和0.90,對柴油閃點預測的RMSE和R2分別為1.03和0.98,與單純MCCNN相比,預測性能進一步得到提升。
(3)加氫裂化工藝流程復雜,不同工藝參數(shù)的相互影響橫跨整個工藝流程,所提出的MCCNN算法能夠提取工藝流程空間中的局部特征信息,但對于全局特征信息和核心催化劑反應特征信息的提取有待進一步研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
