基于改進Yolov5植物病害檢測算法研究*
2023-02-04 11:51:26楊文姬胡文超趙應丁錢文彬
中國農機化學報 2023年1期
楊文姬,胡文超,趙應丁,錢文彬
(江西農業大學軟件學院,南昌市,330045)
0 引言
農業是我國發展的重要產業,其中果蔬種植對于我國實現農業現代化具有重大意義。果蔬對于人類身體具有不可缺少的營養成分,同時還是我國經濟的重要來源。然而果蔬在生產過程中,由于自身對病害的抵抗能力有限,從而使得果蔬感染病害。植物病害不僅會減少產量,甚至造成巨大的經濟損失。植物病害主要發生在植物葉片,可以通過葉片病害特征判斷出植物感染病害類型。盡早地檢測出植物病害,能夠極大程度上減少產量損失、經濟損失。然而,人工檢測需要耗費大量時間和人力成本,檢測結果受人為主觀意識影響,且依賴專業知識。其次,專門從事病害識別的人才緊缺,且難以滿足市場需求,因此,需要用一種高效、快速的人工智能檢測方法解決這一難題。
傳統上的植物病害檢測是依賴擁有專業知識的專家用肉眼對感染病害的植物葉片進行人為判斷。然而,由于我國種植面積較大,這種方法過于依賴人工,不僅耗時費力,檢測結果受人為影響較大,失去客觀性。同時缺少大量的擁有專業知識的專家人才。
快速正確地檢測植物病害對提高果蔬種植產業的發展十分重要,已成為近幾年來農業發展的研究熱點。在此背景下,人們研究了用各種光譜[1]和成像技術[2-3]來檢測植物病害。Arnal等[4]考慮葉片和莖中可見癥狀,使用數字圖像處理技術從可見光譜的數字圖像中檢測和分類植物病害。這種方法需要前期的輔助數據處理,不能對多種植物多種病害類別進行檢測。
其次,該方法也需要精密儀器,不僅價格昂貴,體積過大不利于部署,同時檢測效果不是特別好。隨著硬件設備的快速發展,通過機器學習進行植物病害的自動檢測逐漸應用廣泛。Elangovan等[5]對植物病害圖像進行加載、預處理、分割、特征提取、SVM分類等步驟,從而檢測植物病害類別。支持向量機需要對數據進行復雜的預處理;并且該方法將檢測分為多任務分別進行,使檢測過程更加復雜。
傳統的機器學習方法需要通過復雜的數據預處理和特征提取步驟,大大地降低了病害檢測的效率,且深度學習在計算機視覺取得了巨大突破,研究者開始轉向基于深度學習的病害識別與檢測研究。Mohanty等[6]使用深度卷積神經網絡來識別14種作物物種和26種疾病。Sun等[7]提出基于改進神經網絡的植物葉片病害識別,通過對卷積層的輸入數據進行批歸一化處理,以便加速網絡收斂。Durmu等[8]測試了兩個深度學習網絡:AlexNet、SqueezeNet,檢測十個類別的番茄葉片圖像,取得了較好的效果。Fuentes等[9]將VGG網絡和ResNet(殘差網絡)兩種深度特征提取器相結合,并且提出一種局部和全局注釋和數據增強方式,提高訓練過程的準確性。Zhou等[10]針對水稻病害圖像噪聲、圖片模糊、檢測精度低等問題,提出基于Faster RCNN和FCM-KM融合的水稻病害檢測方法。該方法雖然有一個較高的精度,但雙階段目標檢測算法檢測速度慢。
因此,本文提出一種基于改進Yolov5的植物病害檢測算法。為了更好地提取病害特征信息,通過增加輔助主干網,將輔助主干網的深層特征與主干網的淺層特征進行融合,獲得特征提取能力更強的復合主干網。同時還修改原網絡的置信度損失函數,使用Varifocal Loss代替原來的Focal Loss。最后,將改進后的Yolov5檢測算法對蘋果、番茄常見病害進行檢測,驗證本文改進的Yolov5植物病害檢測模型的有效性。
1 Yolov5目標檢測算法
Yolov5網絡結構是由Input、Backbone、Neck、Prediction組成,具體結構如圖1所示。

圖1 Yolov5s結構圖
Yolov5的Input部分是網絡的輸入端,采用Mosaic數據增強方式[11],對輸入數據隨機裁剪,然后進行拼接。Backbone是Yolov5提取特征的網絡部分,特征提取能力直接影響整個網絡性能。Yolov5的Backbone相比于之前Yolov4[12]提出了新的Focus結構。Focus結構是將圖片進行切片操作,將W(寬)、H(高)信息轉移到了通道空間中,使得在沒有丟失任何信息的情況下,進行了2倍下采樣操作,具體操作如圖2所示。

圖2 Focus結構圖
Neck是采用了FPN+PAN結構,FPN[13]是自頂向下,將強語義特征傳遞下來;PAN[14]則是將淺層的定位信息傳遞給深層,增強多尺度定位能力。
Prediction是網絡的輸出端,Bounding Box損失函數采用的是DIOU_Loss[15],在原來IOU_Loss的基礎上增加了中心點距離作為懲罰項,DIOU_Loss如式(1)所示。
(1)
式中:ρ()——兩個中心點的歐幾里得距離;
Bpre——預測框中心點坐標;
Bgt——真實框中心點坐標;
C——預測框和真實框最小外接矩形的對角線長度;
IOU——預測框與真實框的交集和并集的比值。
2 基于改進的Yolov5網絡模型
改進后的Yolov5網絡模型如圖3所示。
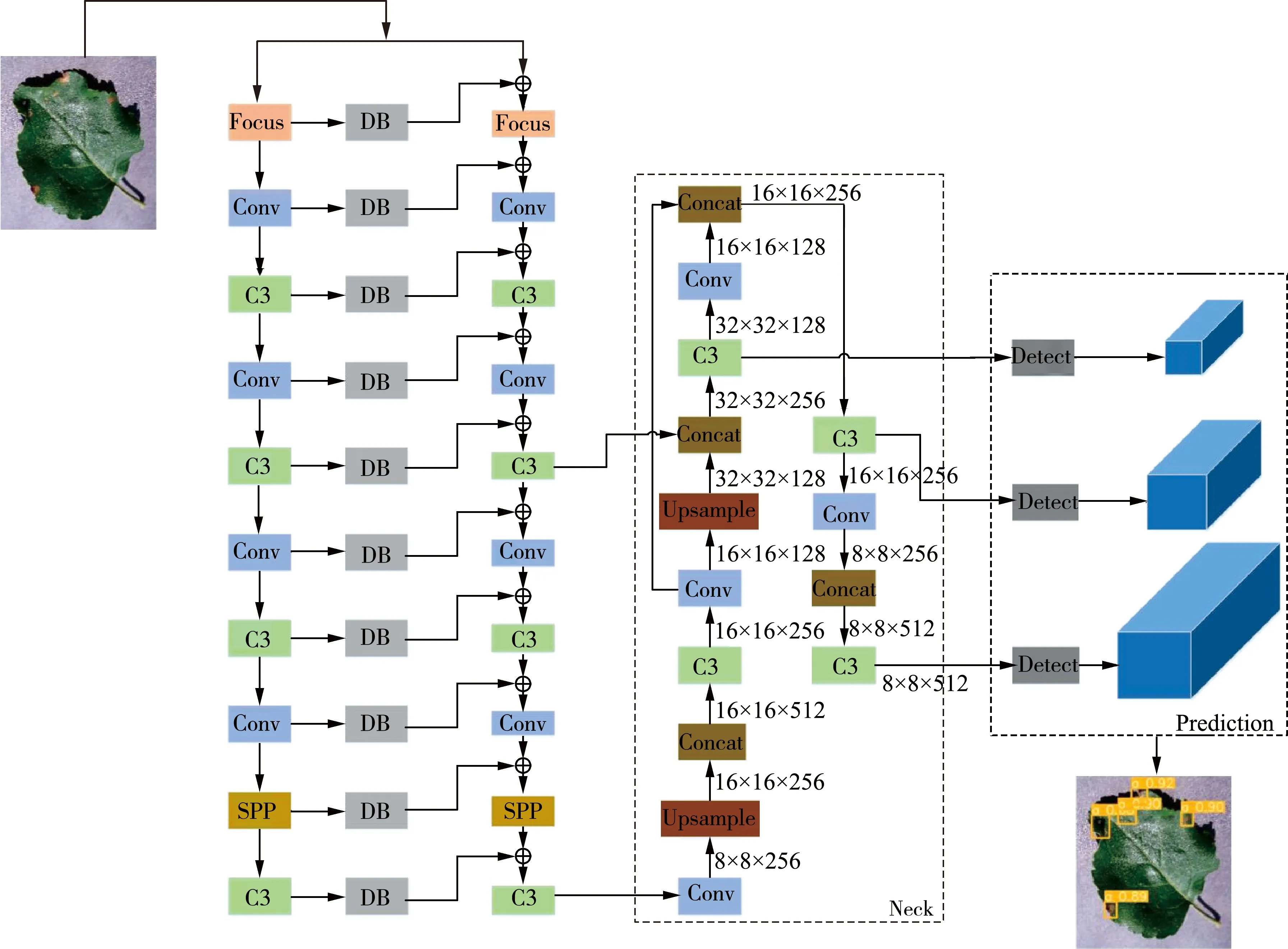
圖3 改進后的Yolov5模型流程圖
2.1 錨框重設
Yolov5采用的初始錨框是根據COCO數據集中物體真實框大小進行聚類生成。本試驗的數據集小目標尺寸占據大多數。因此,初始的錨框大小不適合本數據集。為了提高對象框和錨框的匹配概率,本文采用K-means聚類算法[16]對數據集對象框大小進行聚類。對數據集進行聚類之后,可以為Yolov5的小、中、大三個尺度中分別都提供3個預設錨框,共9個預設錨框。具體生成錨框大小如表1所示。
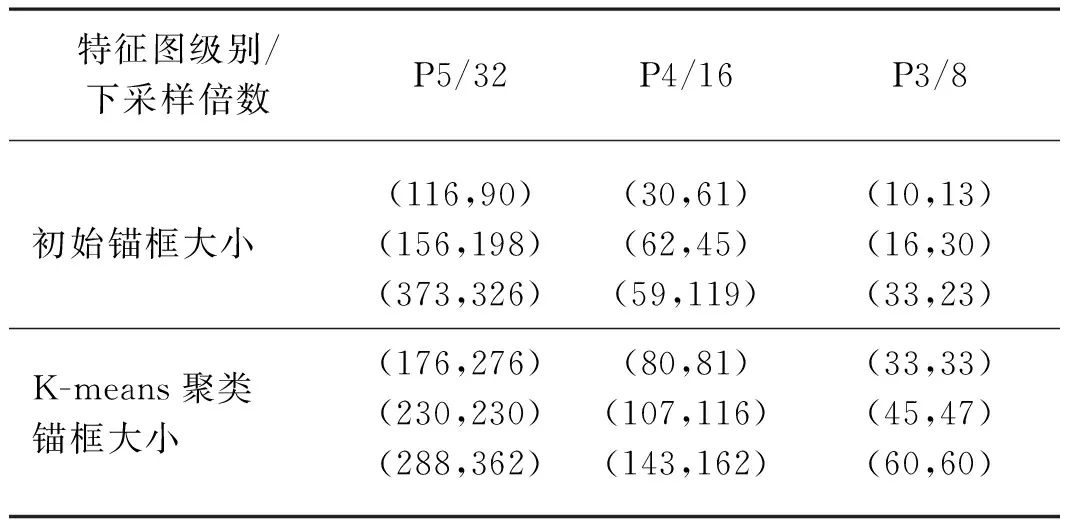
表1 植物病害數據集錨框大小對比Tab. 1 Comparison of anchor frame size of plant disease data set
K-means聚類算法主要分為3個步驟:首先,隨機設置K個特征空間內的點作為初始聚類中心,本文設置K為9;其次,計算每個點到聚類中心點的距離,把每個點都聚類到離該點距離最近的聚類中心點;最后計算每個聚類中的所有點的平均值,并且將該平均值作為新的聚類中心點。然后不斷循環第二步和第三步,直到聚類中心點不在移動為止。
2.2 Yolov5主干網結構改進
本文采用了復合主干網[17]的方法將Yolov5的主干網進行復合,增強主干網的特征提取能力,提升網絡識別植物葉片病害的精度。
傳統的卷積神經網絡的主干網一般只有一個。然而復合主干網是將一個和原主干網相同的主干網進行連接,增加的主干網稱為輔助主干網。原主干網設為B1,輔助主干網設為B2,主干網分為L1、L2、L3、…、Ln個模塊。傳統的主干網是將Ln-1層的特征圖通過非線性變換H()輸入到第Ln層,如式(2)所示。
FLn=HLn(FLn-1)
(2)
式中:FLn——第Ln層特征圖,n≥1。
與傳統主干網不同,復合主干網是以輔助主干網B2每個模塊的輸出作為原主干網B1中同級模塊的輸入。通過不斷迭代將每個輔助主干網模塊與原主干網進行連接,增強主干網特征提取能力。此操作可由式(3)表示。
FLn=HLn(FLn-1+G(FLn-1))
(3)
式中:G()——一種復合連接模塊,由一個1×1的卷積層和上采樣操作構成,其中卷積層的目的是用來減少通道數。
本文采用復合主干網來增強Yolov5網絡模型,提高模型對植物病害特征提取能力,修改后的主干網,如圖4所示。
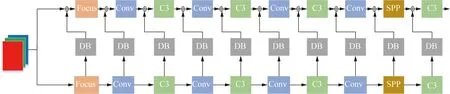
圖4 Yolov5復合主干網
2.3 Yolov5損失函數改進
目前Yolov5計算類概率和目標得分的損失函數采用的是平衡交叉熵損失函數,同時可以調用Focal Loss損失函數[18]來計算損失,并且通過設置gamma值的大小,對損失函數進行調整。平衡交叉熵損失函數改善了樣本不平衡問題,盡管平衡交叉熵損失改善了正、負樣本間的不平衡,但由于其缺乏對難易樣本的區分,因此沒有辦法控制難易樣本之間的不均衡,平衡交叉熵損失函數如式(4)所示。
BCE(Pt)=-αtlog(Pt)
(4)
然而,Focal Loss損失函數可以調節正、負樣本與難、易樣本。為了改善正負樣本的不均衡,引入了αt權重,提升精度;引入(1-Pt)γ用于調節難易樣本的權重,從而降低了一個框被錯誤分類所帶來的影響。Focal Loss損失函數公式如式(5)所示。
FL(Pt)=-αt(1-Pt)γlog(Pt)
(5)
本文針對蘋果、番茄葉片病害斑點分布密集的特點,引入VarifocalNet[19]中的Varifocal Loss代替原本的Focal Loss來訓練具有密集葉片病害區域的病害數據集。Varifocal Loss損失函數公式如式(6)所示。
(6)
這里的p表示預測得分,q是目標IOU分數。對于訓練過程中的正樣本,將q設為bbox和gt box之間的IOU值。然而,負樣本的q則設為0,通過對縮放因子γ的調整,來減少負樣本的影響。
3 試驗結果與分析
3.1 試驗環境
試驗使用一臺安裝了Intel i7-9700k CPU@3.60 GHz,顯存為11 GB的NVIDIA RTX2080Ti顯卡,64 GB內存的Win10系統的電腦。軟件環境包括Pytorch1.7.0、CUDA11.0、torchvision0.8.1。
網絡訓練過程中,網絡模型的學習率設置為0.01,權重衰減設為0.000 5,以16張圖片為一個批次進行300輪訓練,采用動量為0.937的SGD優化器對參數進行優化,Focal Loss的參數γ設為1.5,熱身次數(warmup)設置為3,預熱初始偏差為0.1。
3.2 數據集制作
為了能更早地檢測植物病害,及時減少植物病害帶來的經濟損失。本試驗的數據集是從2018 AI Challenger比賽中的農作物病害檢測數據集中用python程序提取總共7種常見病害的早期感染圖像,共計1 395張圖像。其中包含蘋果三種常見病害,分別是黑星病(apple scab)、灰斑病(apple frogeve spot)、雪松銹病(cedar apple rust);番茄四種常見病害,分別是早疫病(tomato early blight fungus)、晚疫病(tomato late blight water mold)、葉霉病(tomato leaf mold fungus)、斑枯病(tomato septoria leaf spot fungus),如圖5所示。本試驗使用Labelimg工具對數據圖像進行標注,標記葉片病害感染區域和類別信息,具體標注過程如圖6所示。然后通過翻轉、鏡像、亮度調整、高斯濾波、旋轉、縮放、平移等數據增強的方式,解決數據集不足的問題,增強訓練效果。最終增強后的數據集共有7 326張圖像,再按照6∶2∶2的比例劃分為訓練集、驗證集、測試集。

(a) 蘋果灰斑病 (b) 蘋果黑星病 (c) 蘋果雪松銹病

圖6 植物葉片病害標簽
3.3 評價指標
為了評價目標檢測算法的性能,本試驗采用了P、R、AP、mAP指標來進行綜合評估。精確率P反應預測為正的樣本中占有真正的正樣本比例,可以間接評價模型誤檢率,如式(7)所示。召回率R反應檢測出來的正樣本占總的真樣本的比例,可以間接評價模型漏檢率,如式(8)所示。AP表示某一個類別的平均精確率,如式(9)所示。mAP表示所有類別的平均準確率,如式(10)所示。
(7)
(8)

(9)
(10)
式中:TP——模型預測為正的正樣本;
FP——模型預測為負的負樣本;
FN——模型預測為正的負樣本。
3.4 試驗結果分析
為了驗證本文模型對蘋果、番茄病害的有效性,將模型在提供的數據集上進行訓練。改進Yolov5網絡和對照網絡訓練結果如圖7所示,最終訓練好的改進模型各病害識別精度如表2所示。
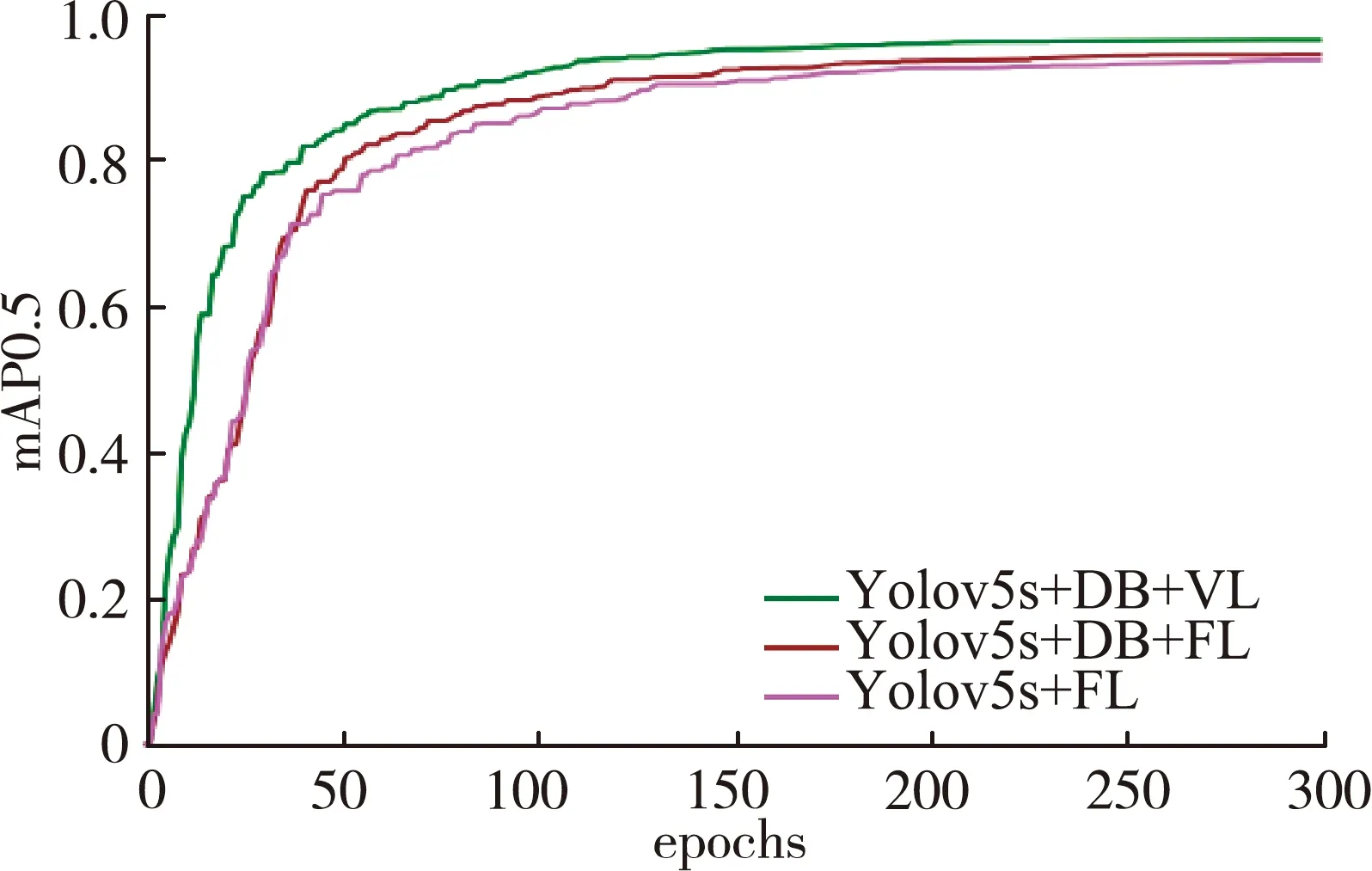
圖7 改進網絡訓練過程對比

表2 不同病害的識別精度Tab. 2 Identification accuracy of different diseases
本文提出的改進Yolov5算法在主干網上采取復合主干網,增加了輔助主干網,將每個模塊的輸出作為主主干網同級模塊的輸入。復合主干網增強對病害特征的提取能力,與原網絡對比實現精度提升,其對比結果如表3所示。

表3 引入復合主干網前后效果對比Tab. 3 Comparison of effects before and after the introduction of composite backbone network
由表3可得,加入復合主干網之后模型精確率比原來提高了0.5%,召回率從90.3%提升至91.0%,提高了0.7%,mAP@0.5提高了0.6%,mAP@0.5:0.95提高了3.6%。復合主干網有效的增強對葉片病害特征的提取能力,提高網絡模型精度。這里mAP@0.5表示IOU的閥值取0.5,mAP@0.5:0.95表示IOU閥值從0.5到0.95每隔0.05取一次,計算不同閾值平均mAP。
Yolov5在置信度損失、分類損失采用的是Focal Loss,解決了樣本不平衡問題。通過增加一個調制因子,減少易分類樣本的影響,更加注重困難、分類錯的樣本。本文對置信度損失、分類損失進行改進,采用的是變焦損失函數(Varifocal loss),對正負樣本的處理采用不對等的方式,使得訓練過程中聚焦在高質量的樣本。為了驗證更換為變焦損失函數(Varifocal loss)的有效性,測試不同Loss函數的各項性能,如表4所示。

表4 損失函數效果對比Tab. 4 Loss function effect comparison
由表4可得,在復合主干網的Yolov5網絡中引入變焦損失函數(Varifocal loss)可以使得網絡識別精度得到較大的提升。復合主干網Yolov5的P從原來90.8%提升至94.0%,提高了3.2%;R從原來的91.0%提升至93.1%,提高了2.1%;mAP@0.5從原來的94.6%提升至95.7%,提高了1.1%;mAP@0.5:0.95從原來的67.7%提升至70.6%,提高了2.9%。結果顯示,引入復合主干網對原模型性能具有一定的提升效果。通過添加復合主干網可以提升模型對病害檢測效果。具體如圖8所示,其中a和b分別表示蘋果灰斑病、蘋果黑星病。
為驗證本文改進Yolov5算法性能,選擇原始SSD算法[20]、Retinanet算法[21]、EfficientDet算法[22]、Yolov3算法[23]和本文的改進Yolov5算法在蘋果、番茄葉片病害數據集上進行6組測試,如表5所示。
由表5可得,本文提出的改進Yolov5檢測精度得到了一定程度的提高,說明本文改進方法的有效性。與原始的Yolov5算法相比,雖然檢測單張圖片的時間僅僅只增加了0.012 s,與其他網絡檢測速度相比依然有一定的優勢,但是本文提出的改進方法mAP得到了1.7%的提升。相比其他網絡,改進Yolov5具有很大的優勢。各算法檢測對比如圖9所示。

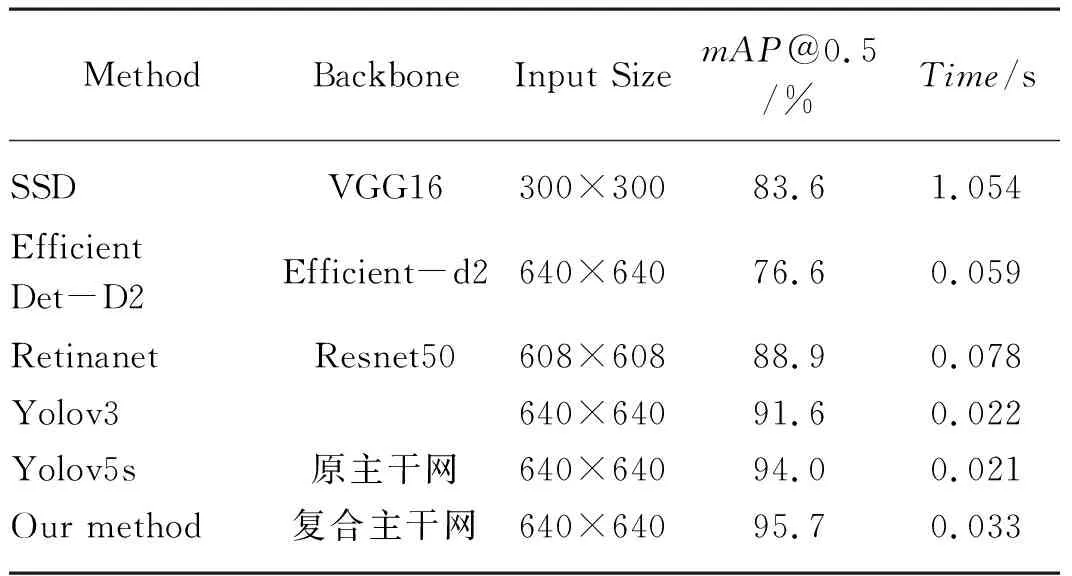
表5 各算法的mAP比較Tab. 5 mAP comparison of each algorithm

4 結論
本文提出一種基于改進Yolov5的植物病害檢測算法,對蘋果、番茄共7種常見病害區域進行檢測。首先是采用復合主干網來增強網絡對病害特征提取能力,然后在使用Varifocal Loss作為置信度損失函數。結果表明,本文方法能很好地檢測蘋果、番茄的病害區域,并且取得較高的檢測性能。
1) 本文對Yolov5的主干網進行改進,增加與原主干網相同的輔助主干網,將輔助主干網各個模塊的輸出作為原主干網同級模塊的輸入,形成復合主干網,增強主干網對植物病害特征的提取能力。相比原來的網絡結構,mAP提升了0.6%。
2) 本文在置信度損失、分類損失上將原來的Focal Loss替換為Varifocal Loss,對負樣本進行衰減,對正樣本的進行加權,使訓練聚焦高質量的樣本。結果表明,在復合主干網的Yolov5上,mAP進一步提高1.1%。
3) 本文提出的改進模型最終的檢測結果mAP為95.7%,在原始模型的基礎上提升了1.7%。在接下來的研究中,考慮葉片病害真實環境,對數據集進行擴充,減小網絡模型的計算量,采用更加高效的網絡結構,在輕量化的同時保證較高的準確率,利于部署移動設備。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
