知識蒸餾在神經網絡中的應用
2023-02-18 09:54:42牛小明
科海故事博覽 2023年3期
李 銳,周 勇,牛小明
(中國兵器裝備集團自動化研究所,四川 綿陽 621000)
近年來,深度神經網絡(Deep Neural Network,DNN)在智能機器人、汽車自動駕駛等領域獲得了廣泛的應用并取得了良好的應用成果。但性能優異的DNN 往往具有網絡結構復雜、節點數量巨大等特點。早在2012年ImageNet 競賽中獲得冠軍的AlexNet 就已具有超過6 千萬的參數,且模型占據的內存高達241MB。隨后涌現的優秀神經網絡如ResNet、VGG、GoogLeNet、DenseNet 等具有更加優異的性能,但隨之而來的是更加龐大的網絡模型、更加復雜的網絡結構,所以模型運行對內存需求和算力需求逐漸增加。目前來看將DNN 模型部署到一些存儲和算力相對較低的硬件設備上依舊具有一定的難度。所以,如何在保證神經網絡性能的同時盡可能降低網絡模型的復雜度,從而使得優秀的網絡模型能夠運行在更廣泛的硬件設備上是近年來學界的熱門課題,該項課題技術的進步也對人工智能的廣泛應用有著積極的意義。本文將介紹知識蒸餾的基本方法,并展示一種手寫體識別模型的蒸餾以及硬件設備的部署。
1 知識蒸餾
知識蒸餾的過程涉及教師模型(Teacher Model)、學生模型(Student Model)這兩個模型。教師模型選取大型神經網絡,具有網絡復雜度高、參數量巨大的特點,識別效果好但是不適合在低算力低內存設備中運行的模型,這類模型依賴大型服務器訓練這種高性能硬件。學生模型復雜度低,但需要結構與教師模型相近,是適合在硬件資源有限的平臺部署的一類模型。知識蒸餾的主要思想是以教師模型的高識別準確率經驗去指導并訓練學生模型,使得學生模型的識別準確率較傳統訓練方法大幅提升,從而達到精簡模型,降低模型部署門檻的目的。
Hinton 等人[1]在2015 年首次提出知識蒸餾(Knowl edge Distillation,KD)這一網絡壓縮技術。在現有的神經網絡訓練方法的基礎上,區別于傳統的硬標簽(hard-taget)只能給出唯一的識別結果,Hinton 等人提出了軟目標(soft-target),能夠給出分類結果屬于某一種類別的概率,這一參數用于計算出總損失函數用以指導訓練學生模型。軟目標(soft-target)的計算結果qi可從以下函數計算得出。

與傳統的softmax 函數不同,這里引入了蒸餾溫度T 這一參數,公式中的zi是輸入數據為第i 類結果的概率。在訓練的過程中需要計算蒸餾損失(Distillation Loss)以及學生模型損失(Student Loss)。其中蒸餾損失是在選定的蒸餾溫度下分別訓練教師模型和學生模型后,通過交叉熵損失函數[2]計算出的結果;學生模型損失是學生模型在選定蒸餾溫度T 為1 訓練后與已知的硬標簽(hard-taget)對比計算出的結果。結合以上兩個損失參數可計算出一個新的損失函數,用該函數對學生模型進行反向傳播。整個蒸餾過程如圖1所示。
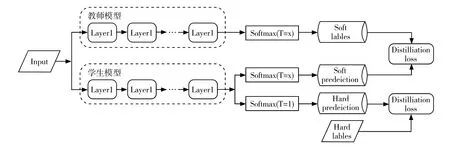
圖1 知識蒸餾基本流程
知識蒸餾壓縮效果的評價指標包含以下三種:(1)學生網絡中模型參數較教師模型的降低比率,這一指標直接體現知識訓練對網絡的壓縮率;(2)通過知識蒸餾訓練后學生模型識別效率與教師模型之間的差距;這一指標能夠直觀體現壓縮后網絡的精度損失量;(3)通過知識蒸餾這一訓練的學生模型與常規訓練后的學生模型性能之間的差異。這一標準能夠體現在一定壓縮率(本次蒸餾訓練)的情況下訓練學習過程的有效率。
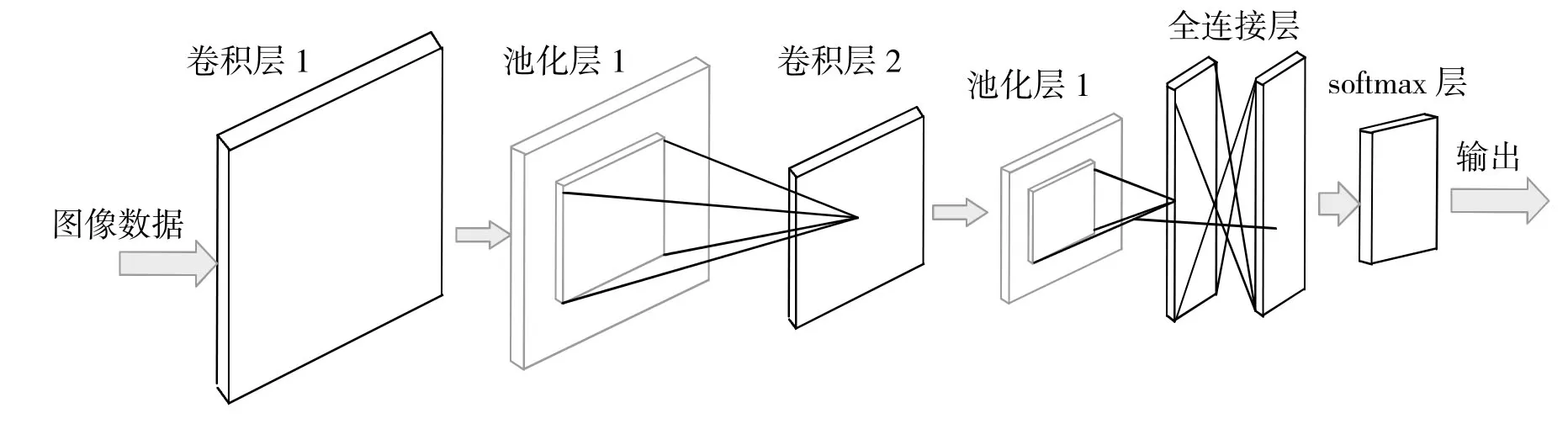
圖2 卷積神經網絡構成圖
通過知識蒸餾的過程獲得的學生模型,與教師模型相比復雜度明顯降低,模型性能損失可控在一定范圍,對低算力硬件平臺友好。但是由于知識蒸餾對softmax函數的改造以及軟標簽(soft-target)的特性,目前知識蒸餾在分類任務中能夠取得較好的效果,但在復雜的識別類任務中還有很強的局限性。并且學生模型的性能提升效果嚴重依賴一個性能良好且適用于該學生模型的教師模型進行訓練,所以知識蒸餾在實際應用中還有很多需要發展的方向。
2 手寫體分類的蒸餾與部署
2.1 手寫體分類算法
字符識別一直是圖像分類領域的一項重要應用,在簽字文件、金融票據、郵件信息等方面的手寫信息錄入有著良好的應用前景。特別是在實時應用場景中,手寫字母識別可以被認為是一種特殊的人機交互方式,具有很大的價值。本文中構建的手寫體卷積神經網絡構成如下。
2.1.1 輸入層
輸入層是神經網絡數據預處理層,當網絡的輸入數據為圖像數據時,圖像信息經過輸入層處理后會將轉換為一個三維矩陣。該矩陣第一個維度是輸入圖像的高度,第二個維度是圖像的寬度,第三個維度是RGB 數據通道。由于不同的圖像可能由不同的色彩分量主導,從而使得權值的主導權不斷變化導致收斂速度變慢,故需要對RGB 分量做標準化處理。
2.1.2 卷積層
卷積層的主要作用是對輸入層預處理過的圖像數據進行特征提取。具體規則是使用較小的矩陣對輸入層得到的三位矩陣進行卷積運算,這里使用到的小矩陣又稱做卷積核或濾波器,需要注意卷積核的深度需要與圖像數據矩陣的深度一致。選取不同卷積核對應提取不同的特征,一般卷積核不宜過大。
2.1.3 池化層
池化層實現的效果類似于圖片壓縮,可以在保留有效特征值的同時降低參數復雜度。最大池化將矩陣劃分為相同大小的區域,并在每個區域內選取最大的特征值,該過程忽略了提取的特征值的精確位置,而保留了特征值本生及其相對位置。通過該步驟網絡中的參數量會迅速下降,不但提升了后級的計算速度,也可防止過擬合,提高網絡模型的魯棒性[3]。
2.1.4 全連接層
全連接層就是一個分類器,經過網絡中輸入層、卷積層、池化層對數據的運算,可以將輸入數據映射到特征空間,但是并未與樣本標簽產生關聯。通過全連接層后,可直接將特征數據映射到樣本標簽,全連接層可直接由卷積操作實現。
2.1.5 Softmax 層
Softmax 層可以將全連接層算出的數值向量歸一化為得到概率分布向量,各類標簽的概率之和為 1。
2.2 蒸餾過程
1.首先使用MINST[4]數據集訓練每個隱藏層具有2000 個神經元基于Pytorch 搭建的教師模型,設置的訓練20 輪,得到在數據集上分類準確率為98.32%的onnx 模型。
2.構建一個每個隱藏層僅有50個神經元的學生網絡。
3.使用蒸餾溫度T=6 訓練教師網絡(此過程切斷反向傳播)得到soft target1,訓練學生網絡得到soft targ et2,結合以上兩個參數使用交叉熵損失函數得到蒸餾損失(Distillation Loss),即學生模型與教師模型之間的誤差。
4.在蒸餾溫度T=1 的情況下對訓練學生網絡得到soft target3,通過學生網絡的訓練情況與正確的標簽結果進行對比,得到學生模型損失(Student Loss),即學生模型與正確結果之間的誤差。
5.通過以上步驟獲得的蒸餾損失與學生模型損失利用以下公式得到學生模型反向傳播時使用的損失函數L。通過損失函數L 對學生模型進行反向傳播,即可完成對學生模型的知識蒸餾過程。
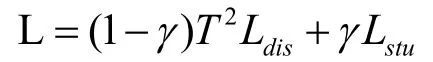
由于softmax 函數中引入了蒸餾溫度T,反向傳播過程中梯度受蒸餾影響變為原來的,為恢復梯度尺度,使其與真實標簽對應的交叉熵的尺度一致,需要在計算交叉熵時乘以T2。
2.3 晟騰310 平臺的部署及運行結果
本文的硬件部署平臺選取華為Atlas 200DK[5],它是基于升騰310 人工智能芯片的一個開發板產品。該開發板以Atlas 200AI 加速模塊為核心,可以適配種類眾多的機器學習模型對圖片視頻信息進行分類推理,該開發套件有良好的社區生態以及完備的技術指導資料,可快速搭建環境并進行開發,且支持的機器學習模型也較為廣泛。
首先,準備好一張容量大于32GB 的內存卡,一臺有Ubuntu18 系統并配置好交叉編譯環境的PC 機;使用讀卡器連接內存卡與該PC 機,使用weget 獲取制卡腳本make_sdcard.py 和make_sd_card.sh,并使用腳本制卡;制卡成功后使用ssh 連接到開發板,并用pip 安裝attrs、numpy、decorator、sympy 等相關依賴;之后安裝Ascend-cann-toolkit。至此開發板相關環境搭建完畢。
下面進行模型部署,模型部署的關鍵在模型轉換,有Mind Studio[6]開發工具平臺、ATC 命令這兩種方法,由于本文中已配置好CANN 環境和ATC 工具,可直接將上文中訓練好的上傳至開發套件,并使用ATC 命令將onnx 模型轉化為晟騰310 支持的om 離線模型。
蒸餾結果及結論:對于未蒸餾的學生模型,其在用MINST 數據集訓上的準確率為89.68%。而蒸餾后的學生模型在相同數據集上的準確率提升至91.63%。由此可以較為明顯地看出蒸餾對準確率的提升。
3 總結與展望
隨著人工智能的發展,神經網絡會被更多地部署到各種硬件平臺中,其中就包括大量資源有限的硬件,所以未來一定會對降低神經網絡復雜度及降低對硬件資源的需求設計產生巨大的需求,知識蒸餾技術作為一種高效的網絡壓縮技術,在未來一定會獲得更多的應用并獲得長足的發展。知識蒸餾的效果很大程度上取決于學生模型能夠從教師模型那里學到多少知識,即提取知識的效率。目前提取效率還有很大的提升空間。未來,如何讓學生模型更高效率地從教師模型中提取知識必然成為知識蒸餾的發展方向。隨著神經網絡規模的不斷增大,未來知識蒸餾將越來越多地和其他網絡壓縮方法結合交叉使用,例如剪枝、量化等方法。隨著具有AI 算力的硬件設備不斷發展,未來人工智能算法高效的硬件部署也將成為重要課題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
快樂語文(2021年27期)2021-11-24 01:29:04
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
甘肅教育(2020年22期)2020-04-13 08:11:16
福建基礎教育研究(2019年3期)2019-05-28 23:14:43
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
