基于優化核極限學習機的泥石流危險性評估
2023-02-25 13:45:24尚艷芳李麗敏溫宗周王朝陽夏夢凡
科學技術與工程 2023年2期
關鍵詞:模型
尚艷芳, 李麗敏, 溫宗周, 王朝陽, 夏夢凡
(西安工程大學電子信息學院, 西安 710600)
中國地形地貌較為復雜,其中山區地形所占比例占70%,且處于地震多發帶,再加之不合理的工程活動,使中國山區居民飽受泥石流災害的困擾,泥石流災害破壞力巨大,容易導致大量人員傷亡和經濟損失。因此,采用科學、先進的泥石流危險性評價方法,建立有效的預測預報系統是非常必要的。
針對泥石流危險性評價的研究開始較早,已取得較為豐富的成果,并且,隨著泥石流的研究不斷深入,各種其他學科理論和方法不斷引入泥石流研究領域,中外許多學者對泥石流危險性評價也有了更透徹認識。李麗敏等[1]針對泥石流多因素影響,提出最小二乘支持向量機的泥石流災害預報模型,但模型輸入多維數據,計算機占用較多時間資源和內存資源,造成網絡迭代速度較慢。根據泥石流形成條件不同,鄧恩松等[2]針對兩大不同類型的(降雨型和冰川型)泥石流進行研究,以中巴公路奧布段為研究區,結合了主成分分析法和灰色系統理論建立評估模型,但此種研究方法只適用于降雨型和冰川型泥石流災害預測,具有一定的局限性。王俊豪等[3]使用層次分析法來確定泥石流危險性評價中各影響因素的權重,通過引用多位專家的評判標準減小主觀誤差對結果的影響,但沒有進行進一步的驗證性分析,可能導致多變量之間相互疊加,影響預報準確性。王艷錦等[4]使用特征金字塔網絡對成康鐵路沿線泥石流進行危險性評估,研究結果表明了機器學習理論在突發性地質災害領域的有效性和可行性。張曉東[5]以寧夏鹽池縣作為地質災害研究區,使用遙感和多源信息融合技術進行泥石流危險性評價,這一方法雖然效果較好,但由于需要借助遙感技術,因此不具有普適性。王晨輝等[6]采用支持向量機模型預測泥石流的危險程度,有大量數據可以供模型訓練學習,這種方法雖然精度得到了保證但模型建立過程復雜,計算量較大。
針對上述預測方法中存在的問題,現采用主成分分析(principal component analysis,PCA)線性降維算法,對數據集做特征壓縮;之后,使用核極限學習機(kernel based extreme learning machine,KELM) 預測泥石流危險性,并利用螢火蟲算法(firefly algorithm,FA)對其進行參數尋優,從而得到泥石流危險性的分類結果;最后,將本文方法與核極限學習機模型、多分類支持向量機模型和BP(error back propagation,BP)神經網絡模型進行比較,驗證FA-KELM模型的優越性。
1 研究方法介紹
1.1 主成分分析算法(PCA)
主成分分析(PCA)采用幾個互相正交的變量信息代替多源的信息量,目的是以最少的新變量揭示原可觀測指標,在數據特征壓縮的同時,最大程度避免特征信息間重疊,盡量減少原指標包含信息的損失[7-8]。包含如下步驟。
(1)設i組j維變量構成的數據矩陣為

(1)
式(1)中:xij為j維變量的第i個樣本,將xij標準化處理,得
(2)
(2)計算相關系數矩陣R。
R=[rij]m×n
(3)
(3)計算累計貢獻率βi。

(4)
式(4)中:λj為特征矩陣R對應的特征值。
(4)選定主成分個數。一般情況下,當累計貢獻率不少于85%時,則選定有m維主成分[9],與之對應的有m個特征值Λm=diag[λ1,λ2,…,λm]和m個特征向量Wm=[w1,w2,…,wm]。
1.2 核極限學習機(KELM)
核極限學習機(KELM)和其他傳統前饋神經網絡的結構類似,但在訓練學習時,所需迭代參數少,學習速度快,其輸出樣本函數F(x)可用矩陣[10]表示為
F(x)=h(x)β=Hβ=L
(5)
β=H*L
(6)
式中:x為給定的模型輸入因子;h(x)、H為隱含層神經元的輸出;β為隱含層和輸出層之間的連接權重;L為網絡學習后的期望輸出;H*為H的廣義逆矩陣。通過求解最小二乘解[式(7)]可以得到輸出權重矩陣的結果。

(7)
式(7)中:I為單位矩陣;C為正則化系數;本文研究中的核函數選用高斯核函數,即

(8)
式(8)中:g為核參數;xi、xj為模型輸入因子,引入核函數后,核矩陣為
QELM=h(xi)·h(xj)=K(xi,xj)
(9)
則表達式(5)網絡輸出可描述為

(10)
1.3 基于FA算法訓練KELM模型
雖然KELM算法克服了傳統ELM算法的缺點,但基于核的ELM則存在模型參數選擇問題,本文研究中通過螢火蟲算法[11-12](firefly algorithm,FA)調整KELM模型中的超參數,解決因人工設置參數而導致預測結果的隨機性和不確定性,提高建模精度和預測性能。該模型的訓練過程如表1所示。

(11)

(12)
rij=‖xi-xj‖
(13)
式中:I0為最大亮度;m0為最大吸引度;γ為光強吸收系數;xi和xj分別為螢火蟲個體i和j的所在位置。個體i向另一個個體j空間轉移的依據公式為

表1 FA算法訓練KELM模型過程Table 1 FA algorithm training KELM model process
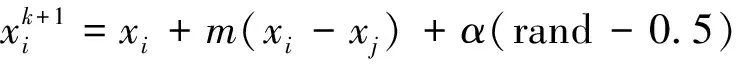
(14)
2 研究區概況
北川縣坐落于四川省盆地西北部向川西高原的過渡帶上,峰巒起伏,山地自然景觀占全縣一半以上的面積,溝壑縱橫,季風氣候明顯,陰雨天氣較多,年均降雨量1 399.1 mm,空間分布不均,具有東南向西北變小的規律[13],同時,區內最高海拔4 769 m,最低點540 m,不穩定溝床比有明顯規律,易于泥石流輸移,流域切割密度較大,使得固體物源更易于參與泥石流活動。根據唐川等[14]、汪月鵑[15]調查,該區域內相對高差超過1 000 m,溝谷斜坡坡度多為15°~40°,地形險峻,地層巖性多樣,復雜的地質構造為流域的支溝發育和泥石流的發生提供有利條件(圖1)。
3 建模過程和結果分析
3.1 數據預處理
本文中數據摘自四川省北川縣國家重點地質災害監測項目的歷史數據,選取其中72條泥石流溝基礎數據作為研究樣本。綜合《泥石流危險性評價》[16]等,最終選擇8種初始影響因子,分別為流域切割密度X1、流域面積X2、流域相對高差X3、不穩定溝床比X4、松散固體物質儲量X5、年均降雨量X6、地震烈度X7和主溝長度X8。
為了克服輸入影響因子丟失或者異常值對地質災害預報準確性的影響,分別針對噪聲大、存在野值、數據種類多的問題,使用以下3種方法進行解決。
(1)適當濾波法。本文使用移動平均濾波器對原始數據進行平滑處理,使用smooth函數,設置移動平均濾波器的默認窗寬為5。

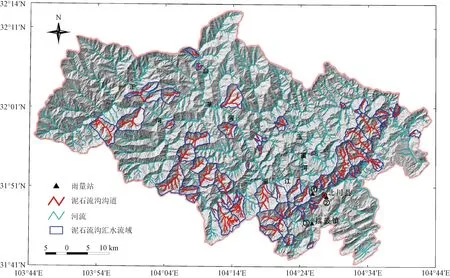
圖1 北川縣泥石流分布圖Fig.1 Debris flow distribution map in Beichuan County
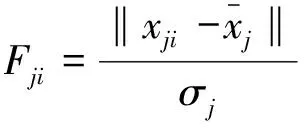
(15)
若Fji>F(n,a),則判定該數據屬于異常值,應該丟棄對應的數據xji。
(3)歸一化。在本數據集中有8種數據,為避免對后續變量的運算和分析造成很大的干擾,加快模型的求解速度,得到合理的結果,將所有綱量映射至[0,1]區間。轉換函數公式為

(16)
式(16)中:x′為經過歸一化后的數據;x為樣本原始數據;xmax、xmin為樣本數據中的最大值、最小值。
為了驗證預處理方法在本模型中的有效性,將預處理前后的數據分別作為FA-KELM預測模型的輸入,對比了數據預處理前后的分類結果,如圖2 所示。
從圖2對比結果可知,通過必要的預處理工作,剔除了異常值,數據的取值范圍均在客觀合理范圍內,模型預測準確率達到90.47%;然而,把不規范的數據作為輸入時,其預測準確率僅有71.42%。仿真結果表明,在數據輸入模型前,確保數據格式一致化以及數據的完整性是十分有必要的。
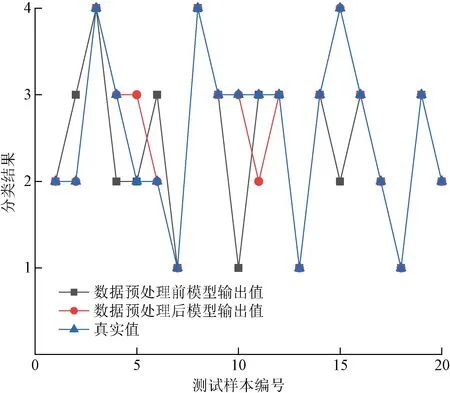
圖2 數據預處理前后FA-KELM模型預測結果對比Fig.2 Comparison of FA-KELM model prediction results before and after data pretreatment
3.2 PCA降維
在數據集中隨機選擇51條泥石流溝數據作為網絡模型訓練,剩余數據用于驗證模型。選擇累計貢獻率不少于85%的成分作為主成分,利用PCA算法選擇出4種綜合指標,涵蓋了8個原始指標體系的絕大部分信息,達到了數據信息精煉化,提取后的變量如圖3所示,將線性組合后的新變量輸入到FA-KELM模型中進行訓練學習并驗證,降維前后的測試時間分別為100.69、82.47 ms。有效提高KELM模型的學習能力。
由圖3中PCA主成分提取變量結果可得,前4個成分的累計貢獻率為45.428%、63.297%、76.132%、86.259%,且到第4個成分時的累計貢獻率達到了86.259%,大于定義主成分臨界值85%。因此利用PCA主成分分析法能夠將初始8維變量數據降至4維,模型數據結構復雜度控制到更低且消除了各因子之間的相關冗余度。所得到的主成分系數矩陣如表2所示。
根據表2中主成分系數矩陣可得,原始變量和主成分之間的線性關系表達式為
(17)

表2 主成分系數矩陣Table 2 Principal component coefficient matrix

圖3 PCA主成分提取變量Fig.3 PCA principal component extraction variables
式(17)中:F1~F4為降維后的4維主成分變量;X1~X8為原始8維影響因子數據。
3.3 仿真驗證及結果分析
3.3.1 參數選擇
KELM算法性能優劣取決于懲罰系數C和核函數參數g的選擇,利用FA優化算法對以上參數進行優化選擇,分類器的懲罰系數和核參數優化范圍設置為(C,g)∈[2-5,210],為避免實驗的偶然性且計算量適中,種群規模n設置為35,最大迭代次數為50,得到的最優參數C和g分別為142.413和1.802,優化參數花費時間為21.62 s,圖4為尋優算法適應度值曲線圖,螢火蟲算法以極快的收斂速度取得更高的適應度函數值,尋優效率高,整體收斂能力強。基于Python3.7以及MATLAB2017b進行編程實現網絡模型和優化算法,CPU為Intel(R) Core(TM) i7-10700F CPU@2.90 GHz,RAM為16.0 GB。
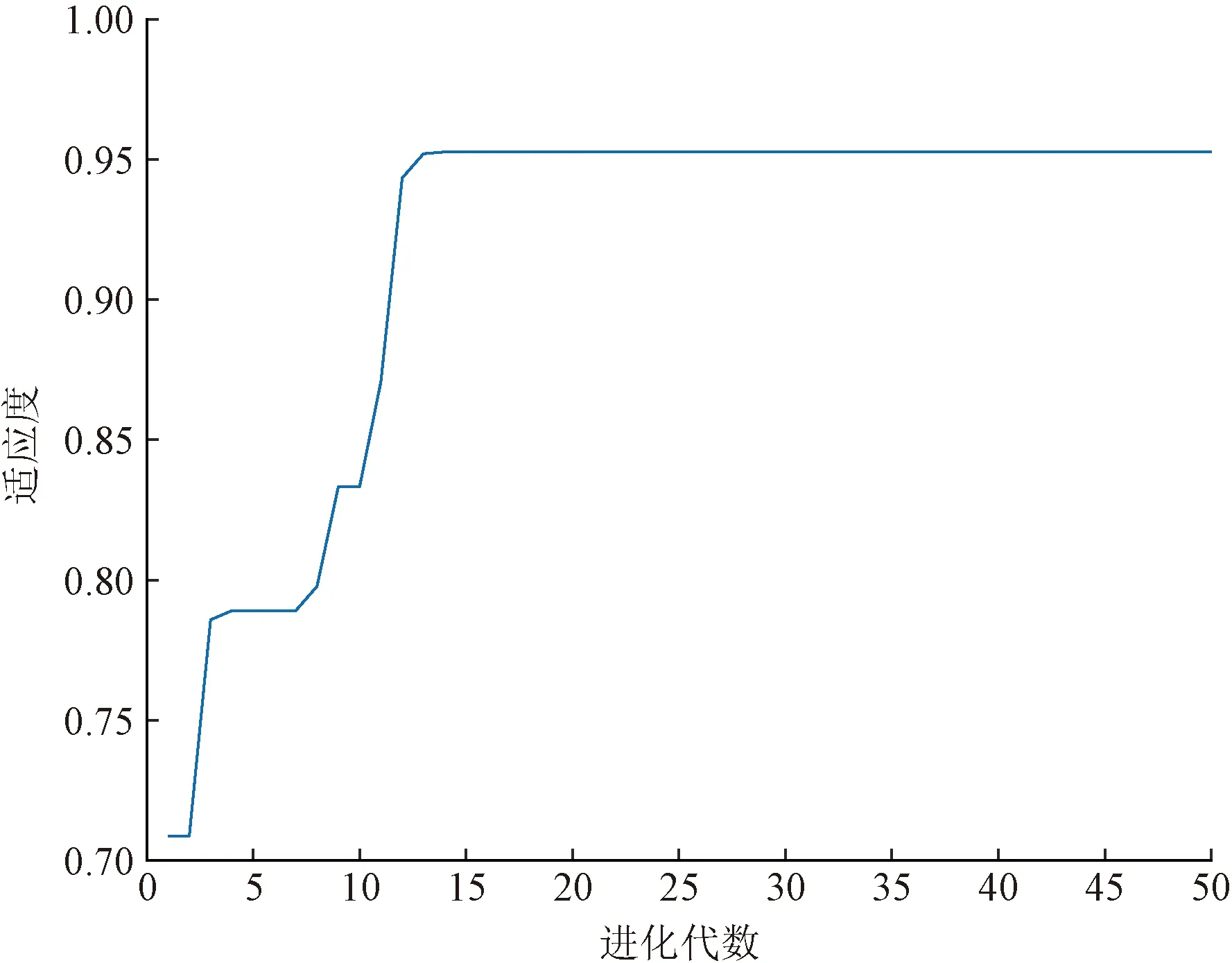
圖4 尋優算法適應度曲線Fig.4 A chart of the adaptability curve of the optimization algorithm
3.3.2 評估模型訓練
首先通過PCA對泥石流數據做特征提取,將訓練集和測試集按3∶1劃分,并且將危險性劃分為4個等級,分別為: 低度危險、中度危險、高度危險、極高危險,其級別分別對應1級、2級、3級、4級。基于FA-KELM的泥石流危險性預測模型的流程如圖5所示。初始時,使用隨機產生的參數作為FA的初始種群,將訓練集輸入FA-KELM網絡進行訓練。預測準確率作為個體適應度函數,為去除較差子群,更新螢火蟲位置,以最大適應度函數為標準選擇,使得模型獲得最佳調優的參數,最后利用測試集測試該模型的準確性。
3.3.3 性能評估
選取在泥石流預測方面應用較為廣泛的核極限學習機[17](kernel based extreme learning machine,KELM)、多分類支持向量機[18-19](multi-class support vector machine, MSVM)以及誤差逆傳播算法[20-21](error back propagation,BP)作為對比模型,并采用混淆矩陣、曲線下面積(area under curve, AUC)、ROC曲線(receiver operating characteristic curve, ROC)評價分類器性能,在相同條件下FA-KELM模型與預測模型進行效果對比。圖6和圖7給出了各對比模型在相同數據集下泥石流危險性分類的混淆矩陣和ROC曲線。

圖5 基于FA-KELM的泥石流危險性評價流程圖Fig.5 Flow chart of debris flow hazard assessment based on FA-KELM
由圖6對比可知,本文提出的模型在對角線上的值均高于其他模型在對角線上的值,得到最佳混淆矩陣,KELM預測性能稍好,MSVM算法的預測標簽與真實標簽之間存在較明顯的出入,BP算法預測結果偏離實際泥石流危險性等級,并且預測模型的優劣與ROC曲線下方面積的大小有關,面積越大,說明模型表現出色,根據圖7的ROC曲線結果可知,FA-KELM曲線的面積為最大,對角線代表分類能力為0的一條線,ROC曲線離對角線越遠,AUC越大,表明模型的分類能力越強。各模型具體AUC如表3所示。
根據表3對比可知,本文提出的FA-KELM模型在ROC曲線下面積AUC均值為90.6%,因此,與其他網絡相比,其擁有最大AUC 均值,說明該算法更優,在泥石流危險性評估中具有較強競爭優勢,有效提高分類效果。
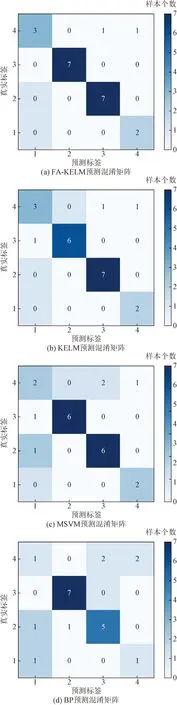
圖6 不同模型結果的混淆矩陣對比圖Fig.6 Comparison of confusion matrix of the prediction results by different methods

圖7 不同模型ROC曲線對比Fig.7 Comparison of ROC curves of different models
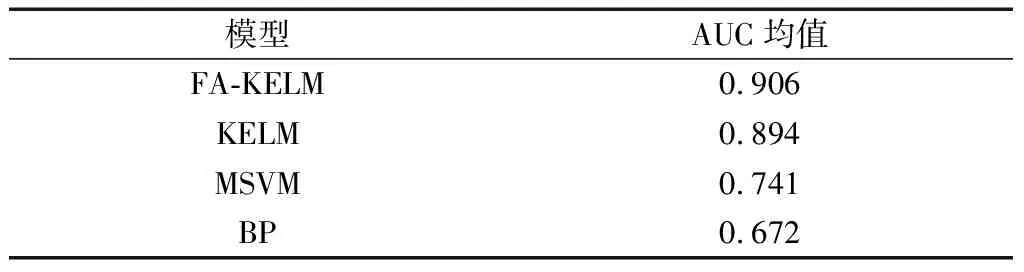
表3 4種模型AUC均值對比Table 3 Comparison of AUC mean for 4 models
4 結論
以泥石流危害程度為研究對象,建立了基于PCA算法和經過FA算法參數優化的KELM地質災害評估模型。利用四川省北川縣監測點數據進行實驗驗證,同時,將本文方法與未進行優化改進的KELM模型、多分類支持向量機模型、BP神經網絡預測模型的輸出結果進行比較,通過對比驗證,表明本文選用的FA-KELM模型在泥石流危險性評估方面效果更優。具體結果如下。
(1) 泥石流災害的成因是復雜的,致災因子較多,因此利用PCA進行數據變換和降維處理,經過特征選擇的數據更適應模型的訓練,去除了因子之間的冗余信息,降低了網絡運算量,消耗更少運算時間資源,提高模型準確性。
(2) 由于數據是在復雜嚴峻的外部環境下采集到的,不可避免地存在不符合要求、重復、錯誤數據等現象,對輸出結果會產生影響,因此對數據集進行了預處理,將預處理前后的數據分別作為模型的輸入,得到不同的結果,驗證了預處理工作是模型訓練前的重要環節,經過數據處理后,提高了數據質量,模型的準確率得到了提高。
(3)將FA優化的KELM方法應用于泥石流危險性評估中。選用FA優化算法對KELM中的參數尋優,并通過ROC曲線和對應的AUC均值對模型進行評估效果的評價,相較于其他3種傳統算法,FA-KELM算法展現出更好的效果,評估結果與實際情況基本一致,在實際工程中是可行有效的。
(4)地質災害的成功預報是極其復雜的系統工程,本文研究主要針對泥石流的危險性進行評估,而對于災害發生強度、范圍和時間的預測也是工程中的難題。同時泥石流災害從孕育到致災過程受多種因素導致,且受地形地貌、氣象水文影響巨大,本文提出的模型提供一定的參考價值,但還需進一步提高與完善,以便更好地運用于其他流域地區的實際工程中。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
