一種面向口腔移植骨分割的SA-UNet 網絡
2023-02-28 16:09:56徐常鵬丁德銳
智能計算機與應用 2023年11期
徐常鵬,趙 宇,丁德銳
(上海理工大學光電信息與計算機工程學院,上海 200093)
0 引 言
在口腔種植領域,新骨體積量是判斷能否進行分期種植的主要依據。 近年來,由于低劑量、成像質量高、價格低廉等優點,錐束計算機斷層掃描(Convolutional Block Attention Module,CBCT)幾乎占據牙科領域的市場[1-2]。 在口腔醫學圖像分割中,移植骨區域的體積分割面臨較大考驗[3]。 究其原因是臨床使用的骨移植材料有個體差異,同時在新骨生成改建過程中伴隨有移植材料的吸收,使得CBCT 圖像中移植骨區邊緣與周圍組織很難清晰辨識[4-5],從而影響醫生對移植骨區域準確性的判斷。對口腔移植區的勾畫通常要求臨床醫生手工勾勒靶區的輪廓邊界。 一個標準的CBCT 圖像通常包含幾百張切片,傳統的手動勾勒需要耗費大量的時間和人力。 不同醫生對同一植體區域的勾畫也有可能存在一定的差異,這些差異會影響治療計劃的質量與優化。 另一方面,CBCT 圖像的質量也會受到多種因素影響[6],如CBCT 成像對移植體區域的圖像分辨率不高、圖像對比度低等。 因此,要想獲得比較精確的分割結果,仍然面對巨大的挑戰。
基于深度學習技術的圖像分割方法具有操作方便、準確性高等諸多優勢,在口腔醫學領域有著廣泛的應用前景和很高的經濟價值[7-8]。 目前,卷積神經網絡被廣泛用于醫學圖像分割任務中。 例如,Long 等學者[9]提出全卷積(Fully Convolutional Networks,FCN)網絡結構。 FCN 采用反卷積層對特征圖上采樣,使其恢復到輸入圖像相同的尺寸,實現了像素級的分類。 Ronneberger 等學者[10]提出了U-Net 網絡結構。 該網絡采用U 型編碼解碼結構,通過跳躍連接實現不同尺度特征圖低級細節與高級語義的結合,成為了醫學圖像分割的基準網絡。Oktay 等學者[11]提出Attention U-Net。 該模型以U-Net 為基礎,在解碼器部分通過注意力門(Attention Gates)控制特征的重要性,抑制不相關背景區域的影響。 Zhou 等學者[12]提出U-Net ++網絡,通過不同深度的U-Net 的有效集成來緩解未知的網絡深度,通過深度監督進行共同學習。 Alexey等學者[13]提出Vision Transformer (ViT)網絡。 這是首次將自然語言處理中的Transformer 模型用于計算機視覺中,并且在大規模數據集中取得較好效果。Chen 等學者[14]提出TransUnet,通過Transformer 的全局注意力彌補了U-Net 遠程建模依賴關系的局限性。
針對口腔CBCT 圖像,尤其是對于口腔骨移植區分割任務[15],傳統的實施方案主要依賴于醫生手動的線性勾勒,目前并無成熟的口腔移植骨分割網絡模型。 同時,移植區位于牙槽骨內部或表面,體積相對較小,因此口腔移植骨圖像具有樣本不均衡,邊緣模糊等特點。 雖然U-Net 網絡通過多尺度特征提取和跳躍連接層保留低層信息的特性,在網絡醫學圖像中有許多成功的應用,但由于低級特征層和高級特征層的語義差距較大,U-Net 應用跳躍連接來合并低級別和高級別的特征層,不僅容易導致特征映射模糊,而且還易導致過度和欠分割的目標區域。 此外,由于口腔移植骨CBCT 圖像數據集具有標記的數據量較少,加之樣本不均衡、邊界模糊等問題,U-Net 網絡分割方法會出現模型特征提取能力較差、邊界分割效果差等問題,導致網絡分割結果精度有限。
針對上述難點,本文提出一種基于U-Net 和注意力機制的新型網絡(SA-Unet),以提高口腔移植骨分割的準確率。 具體地,使用U-Net 網絡作為主體框架,將跳躍連接層簡單地復制操作改進為Depthwise 卷積,以銳化低級特征層并減輕特征拼接引起的語義差距。 其次,通過在解碼器部分特征拼接之后嵌入CBAM[16]模塊,增強模型對于特征的提取能力,使得模型更加關注目標區域的細節信息(如邊緣、紋理等),并抑制其它無用信息。 最后為解決數據正負樣本不均衡以及簡單困難樣本不均衡的問題,論文設計了新型的聯合損失函數。
本文主要貢獻如下:
(1)提出基于U-Net 和注意力機制的編碼解碼網絡(SA-UNet),以實現口腔移植骨的精準分割。在跳躍連接層設計的銳化操作不會引入任何額外的可學習參數。
(2)設計一種輕量級的Sharp-Attention 模塊。通過引入帶銳化卷積核的Depthwise 卷積和CBAM模塊,增強了圖像的細節信息,平衡了不同層間語義差距。 本模塊也適用于其他語義簡單的醫學圖像,也可集成到其他U 型網絡結構中用以提升模型性能。
(3)采用新型聯合損失函數,緩解正負樣本比例失衡帶來的影響。 在制作的口腔CBCT 圖像數據集上驗證本文提出模型的有效性。
實驗結果表明,相比其他方法,本方法在IoU、Dice系數、HD距離三個指標上均取得了最佳評分。
1 相關工作
由于U-Net 網絡結構在生物醫學圖像分割中的良好表現,通常被作為醫學圖像分割的基準網絡,并且陸續推出了基于U-Net 改進的系列成果。 受到殘差連接的啟發,Xiao 等學者[17]提出了Res-UNet 用于視網膜圖像的分割。 Guan 等學者[18]提出了Dense-UNet,將UNet 的每一個子模塊分別替換為密集連接的形式,并設計Fully Dense UNet 模型用于去除圖像中的偽影。 Alom 等學者[19]提出了循環卷積網絡(RU-Net)和循環殘差卷積網絡(R2UNet)。 這2 種網絡分別用循環卷積層(RCLs)和帶有殘差的循環卷積層(RCLs)代替正向卷積層。?i?ek 等學者[20]基于U-Net 提出了3DU-Net,實現了對于3D 圖像的醫學分割。 Milletari 等學者[21]在3DU-Net 的基礎上提出了V-Net,用卷積代替池化,通過轉置卷積上采樣,實現了基于體積的分割方法。
注意力機制的基本方式是通過啟發式搜索對卷積特征進行選擇,即通過學習要強調或抑制的特征來有效幫助信息在網絡內的流動。 Jaderberg 等學者[22]提出了Spatial Transformer Network,空間注意力主要關注圖像的空間位置信息,生成空間特征圖保存關鍵信息。 Hu 等學者[23]提出了SENet,通道注意力可以有選擇性地關注具有更多信息的特征通道,并對無用特征進行抑制。 Zhao 等學者[24]提出了PSANet。 該方法只計算每個像素與其同行同列、即十字上的像素的相似性,通過進行循環間接計算得到各像素間的相似性,有效降低計算復雜度。 Wang等學者[25]提出一種可堆疊的殘差注意力網絡(Residual Attention Network)。 Vaswani 等學者[26]提出自注意力(Self-Attention)機制,不使用RNN 或CNN 等復雜的模型,僅僅依賴于Attention 模型就可以實現訓練并行化且擁有全局信息。 Woo 等學者[16]提出了輕量級的卷積注意力機制模塊(CBAM),CBAM 模塊會依次沿著通道和空間維度推斷注意力圖,而后將注意力圖與輸入特征圖相乘以進行自適應特征優化。
2 方法
2.1 SA-UNet 網絡整體結構
本文以U-Net 為基準網絡,通過設計一種Sharp-Attention 機制,同時融入CBAM(Convolutional Block Attention Module)注意力模塊,提出了一種改進的SA-UNet 模型。 該模型是一種多尺度的對稱U 型結構網絡,如圖1 所示。
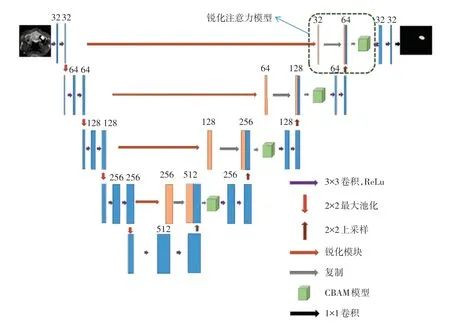
圖1 SA-UNet 網絡結構Fig. 1 The structure of SA-UNet
設計的SA-UNet 網絡由編碼器、跳躍連接層、解碼器三個部分組成。 具體地,編碼器部分包含了卷積、池化、下采樣等模塊;跳越連接層部分在淺層引入了Sharp 模塊[27];解碼器部分包含雙線性上采樣、CBAM 模塊、卷積和池化模塊。 此外,針對口腔移植骨圖像邊界模糊、樣本不均衡的特點,網絡的訓練采用了一個新設計的聯合損失函數,用以提升圖像分割質量。
在細節上,編碼器部分與傳統的U-Net 類似,由5 個模塊組成,每個模塊包含2 個3×3 卷積層和一個ReLU 激活層,隨后連接一個2×2 的最大池化層,且第5 個模塊不包含池化層。 分別使用32、64、128、128、256 和512 個卷積核,即在每個模塊之后,特征圖通道的數量都增加了一倍。
在U-Net 型網絡結構中,編解碼器網絡中的跳躍連接層對于恢復預測的細粒度細節方面起著至關重要的作用。 傳統的對淺層信息直接復制的跳躍連接方式在融合低層和高層不同的語義特征時,由于較大的語義差異容易導致模糊的特征映射,從而降低了分割精度。 為此,本文改進了這一連接方式,在前2 個模塊的跳躍連接層中引入了Sharp 模塊,使用帶銳化卷積核的Depthwise 卷積,從而在每個特征通道上對特征圖進行沿通道的卷積操作。Depthwise 卷積操作銳化了淺層特征以加強特征細節,使得在特征拼接時平衡了不同層間語義差距,同時也有助于減少早期階段在整個網絡層中傳播的高頻噪聲成分。 值得一提的是,Sharp 模塊不會引入任何額外的可學習參數。
解碼器部分通過嵌入CBAM 模塊,結合空間和通道的注意力機制,提高了模型對于感興趣區域的關注程度。 解碼器部分同樣由5 個模塊組成,每個模塊包含一個2×2 的反卷積(即對特征進行上采樣)、特征拼接、CBAM 模塊,然后是2 個帶有ReLU激活的3×3 卷積層,且第5 個模塊有一個額外的1×1 卷積層實現特征降維。 解碼器模塊的卷積層分別用256、128、64 和32 個卷積核,即每個模塊之后特征通道數減半,最后輸出與輸入圖像同等分辨率的輸出圖像。 輸出是對于每個像素類別的預測。 接下來將進一步闡述所設計網絡核心模塊。
2.2 Sharp-Attention 模塊設計
如前所述,本文的創新性工作之一是將Sharp模塊與CBAM 模塊結合,提出了Sharp-Attention 模塊,并應用于U-Net 網絡跳躍連接與解碼器部分。該模塊主要由2 個部分組成,如圖2 所示。 一部分是Sharp 模塊,通過帶銳化卷積核的Depthwise 卷積操作,對不同尺度的特征圖實現銳化操作;另一部分是CBAM 模塊,該模塊包含一個通道注意力單元和空間注意力單元,用來對不同特征圖賦予不同的關注程度。 對此擬做闡釋分述如下。
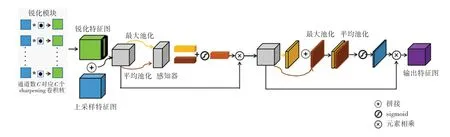
圖2 Sharp-Attention 模塊圖Fig. 2 Sharp-Attention block
(1)Sharp 模塊。 模塊中的Depthwise 卷積操作是在特征融合之前使用銳化卷積核對每個通道的特征圖獨立地進行卷積。 銳化卷積核是圖像拉普拉斯算子[28]的近似,是一個二階導數算子,能夠在任何方向上響應強度躍遷。 例如,帶有如下卷積核的一個拉普拉斯高通濾波器,考慮了輸入圖像中參考像素的所有8 個臨近值,如式(1)所示:
顯而易見,該卷積核的功能是增加了中心像素相對于相鄰像素的強度。 進而,設I是輸入圖像,則銳化圖像S為:
其中,“?”表示卷積。
由于編碼器的特征層是多維的,一般大小為W × H × C,其中W、H和C分別表示編碼器特征映射的寬度、高度和通道數。 因此,本文使用基于拉普拉斯濾波器核K的銳化空間核沿通道對每一個特征層進行卷積,即Depthwise 卷積操作。 具體地,使用C個濾波器,輸入特征圖的每個通道分別與核K進行卷積,步幅為1。 每一個卷積操作都產生一個大小為W × H ×1 的特征圖。 為了保持輸出維度與輸入的維度相同,在特征拼接的過程中執行填充操作。 稍后,將這些特征圖堆疊在一起獲得了尺寸為W × H × C的輸出。 由于銳化卷積核K沒有可調參數,因此在模型優化過程中沒有參數更新,不會產生額外的計算成本。
(2)卷積注意力模塊(CBAM)。 是一種簡單而有效的注意力模塊,如圖3 所示。
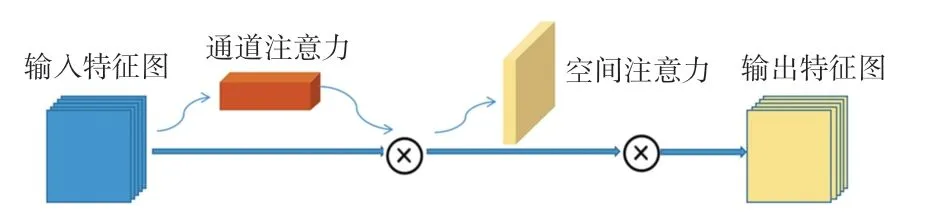
圖3 CBAM 模塊圖Fig. 3 CBAM block
在解碼器部分,把拼接之后的特征圖輸入到CBAM 模塊,此后沿著通道和空間維度依次推斷注意力圖,然后將注意力圖與特征圖相乘后的結果進行自適應優化。 給定大小為W × H × C的特征圖,CBAM 依次推斷出大小為1×1×C的一維通道注意圖Mc和大小為H × W ×1 的空間注意圖Ms。 具體地,通道注意力將輸入的特征圖Finput分別經過基于高度和寬度的全局池化和平均池化,而后再分別經過多層感知器、element-wise 加和操作、Sigmoid激活,最終生成通道注意力特征圖Mc。 通道注意力特征圖與輸入特征圖做元素相乘生成空間注意力模塊所需的輸入Fout1,數學定義如下:
空間注意力模塊包括全局池化和平均池化、拼接、卷積操作、降維以及Sigmoid激活而生成空間注意力特征圖Ms。 同樣地,與輸入特征圖Fout1相乘得到CBAM 模塊的輸出特征圖Fout2,其數學表達式為:
其中,“ ?”為對應像素值相乘。
對于一個特征圖來說,通道注意力模塊壓縮了輸入特征圖的空間維數,用于聚集空間信息。 空間注意力模塊是利用特征的空間關系來生成一個空間注意圖。 空間特征更多關注目標的位置信息,與通道注意力互為補充。 本文認為Sharp 模塊對編碼器特征的每個通道獨立地進行卷積操作,能夠增強淺層特征圖的細節信息,同時有助于減少早期階段整個網絡層中傳播的高頻噪聲成分。 進而,在解碼器部分高層與低層特征圖拼接之后嵌入的CBAM 模塊,使得通道注意力模塊能夠更加有效地關注經過Sharp 模塊增強的淺層特征通道的信息,從而加強對于淺層信息的提取,更好地平衡高層和淺層的語義差距。
2.3 損失函數
加權交叉熵常用來解決醫學圖像中的類別不平衡問題。 通過對每個類別加上適當的權重,從而抵消了數據集中存在的類不平衡。 進而,為了降低易分樣本對損失函數的貢獻,Lin 等學者[29]通過引入難易區分權重,使模型更加專注難分樣本的區分,得到了Focal Loss(FL):
其中,β表示類別平衡因子,γ是難易樣本平衡因子。 通過對β參數的調整,可解決正負樣本不均衡的問題;通過(1- pi)γ參數的調整,可改善難易樣本不均衡問題。
Hausdorff Distance(HD) Loss 可用于優化分割的最大距離誤差[30]:
其中,Ω表示圖像定義的網格;q,p分別表示預測圖與groud-truth;dq,dp分別表示預測圖與ground-truth 的距離變換圖; “?” 表示對應元素相乘。HDLoss 不是只關注最大的分割誤差,而是使用α作為懲罰因子,平穩地對于較大的分割誤差給予懲罰。
在醫學圖像分割任務中,類別不均衡問題很常見,即正負樣本比例失衡。 口腔移植骨圖像也是如此,背景像素約占95%以上,數據集具有顯著的正負樣本比例不平衡特征。 同時,由于二維圖像中移植骨區域較小,對于較小的樣本容易產生誤判。 考慮到基于邊界的損失函數能夠通過對最大距離的約束有效地減小誤判的產生,本文設計一種聯合FL與HDLoss 的損失函數,其定義如下:
這里,參數λ平衡了HDLoss 在訓練中的權重,以實現更好的分割性能。 經過實驗發現,γ參數設置為2,β設置為0.8,α值在1.0 和3.0 之間實驗結果較好。 本文的實驗中,α設置為1.5,λ設置為0.2。
3 實驗及結果分析
3.1 實驗環境與參數設置
本文實驗使用Python 編程語言,Pytorch 框架,硬件配置如下:處理器為Inter(R)Core(TM)i9 -10900X CPU @3.7 GHz,內存(RAM)為64.0 GB,GPU 為NVIDIA GeForce RTX 3090 24 GB 顯存,計算機系統為Linux 操作系統Ubuntu 18.04。
在訓練過程中,采用自適應動量估計( adaptive moment estimation,Adam) 優化器和反向傳播算法對網絡進行優化與梯度更新。訓練批次(batchsize) 設為16,初始學習率( learning rate) 設為0. 001,每100 個周期學習率下降0.2 倍,動量值設為0. 9,訓練次數設置為500。
3.2 實驗數據集建立
本實驗的CBCT 數據集來自上海交通大學醫學院附屬第九人民醫院,由不同年齡階段的10 例健康患者在術后經同一臺CBCT 掃描儀掃描得到(倫理批號:SH9H-2022-TK53-1),剔除無關部位的掃描切片后,共計505 張圖片。 掃描時的參數設置:電壓120 kV、電流5 mA、掃描時間16 ~20 s、voxel size:0.25 mm;FOV: 25 cm(D)×17 cm(H) 分辨率,圖像矩陣為651×651×651 體素。 考慮到人工標注的骨移植區域作為標注金標準的可信度和深度學習的可解釋性,對于每張原始CBCT 圖像,口腔移植骨區域由經驗豐富的口腔專科醫生手工標注,并將最終標注結果以NIFTI 格式進行存儲。 為了提升模型泛化能力,采取旋轉、偏移、裁剪、水平翻轉、隨機旋轉等操作進行數據集擴充,最終得到尺寸為224×224的圖片1 830張。 進而可得,訓練數據集為1 464張圖片,測試數據集為366 張圖片。
3.3 評價指標
為了定量評估分割效果,本文使用Jaccard 指數(Intersection-over-Union,IoU)、 Dice 相似系數(Dice Similarity Coefficient,DSC)、 Hausdorff 距離(Hausdorff Distance,HD)、召回率(Recall)、精確率(Precision) 作為評估指標。 對于各評估指標的數學定義及表述詳見如下。
(1)IoU。 給定2 個集合G和P,對應表示真實標簽和預測標簽,IoU定義為:
其中,G∩P為真實標注區域與預測輸出區域的交集,G∪P為真實標注區域與預測輸出區域并集。 Jaccard 系數的范圍從0 到1,這里1 表示真實標簽和預測標簽之間的完全匹配,而0 表示真空標簽和預測標簽之間的完全不匹配。
(2)DSC。 定義為:
同樣地,DSC的值在[0,1]范圍內。 其值越大表示網絡的預測輸出與真實標注之間的重合率越高。
(3)召回率(Recall)。 定義為所有預測輸出像素中被正確預測出來的比例。 數學定義公式為:
其中,TP +FN表示數據集中的所有正例。
(4)精確率(Precision)。 表示在所預測的正樣本中,預測正確的正樣本所占的比例,其計算公式為:
(5)Hausdorff 距離。 是用來度量2 組點集的相似程度。 假設有2 組集合A ={a1,…,ap} 和B ={b1,…,bp},則這2 個點集合之間的HD為:
其中,
其中,‖·‖表示點集A和點集B間的距離范式。HD值越小,表示A、B之間的重疊度越高,分割性能越好。
3.4 消融性實驗
為了評估的SA-UNet 模型中不同模塊(即Sharp 模塊和CBAM 模塊)和不同損失函數(即LossFL和LossHD,記作FL和HD) 在口腔移植骨分割任務中的性能,本節設計了7 組不同實驗來進行對比。 表1 給出了在不同模塊組合下的不同模型對移植骨的平均分割性能。 從表1 不難看出,不同模塊的組合都能在一定程度上提升網絡模型的性能,且SA-UNet 網絡在性能上達到了最佳,DSC值達到0. 923 6,Hausdorff 距離為0.566 3。當同時考慮提出的聯合損失函數時,DSC值達到0.926 2,Hausdorff距離為0.509 2,在性能上進一步提升了0.28%和10.08%。
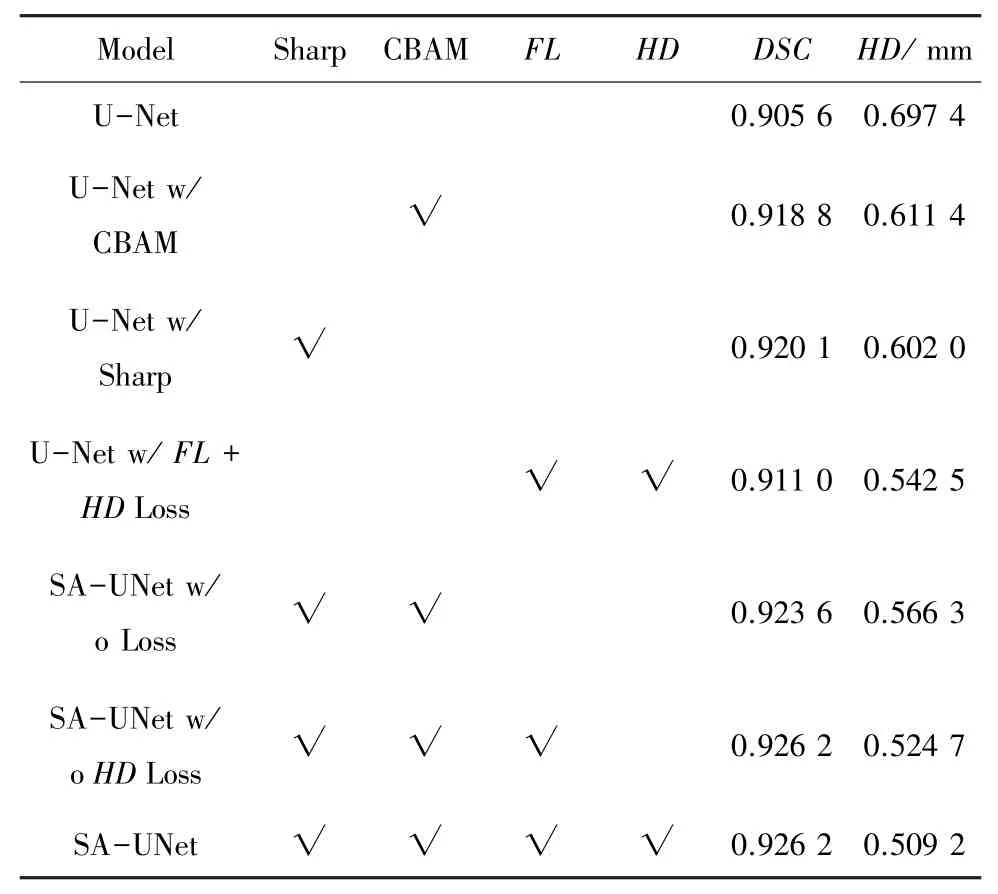
表1 不同改進方案下的網絡性能Tab. 1 The performance of network with different improved strategies
3.5 網絡模型對比實驗
本節將通過與U-Net、UNet ++、DeepLabV3、Attention U-Net、ResUNet 等當前主流分割模型進行對比分析,進一步驗證提出模型的準確性和有效性。表2 給出了不同網絡模型在測試集上指標IoU、DSC、Recall、Precision與Hausdorff 的得分情況。
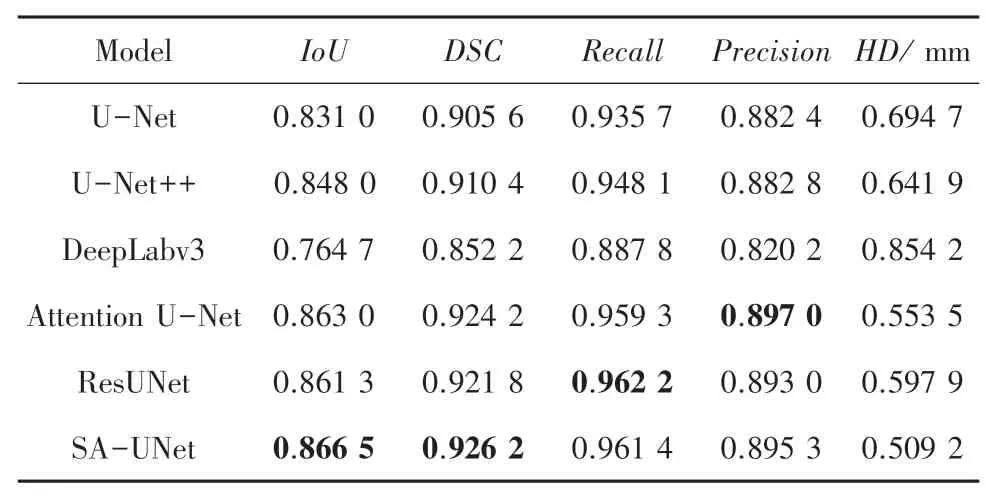
表2 不同網絡模型對比Tab. 2 Performance comparison of different network modules
根據表2 不難看出,本文提出的SA-UNet 在IoU、DSC、 Hausdorff 距離三個性能指標皆達到最優,其值分別為0.866 5、0.926 2、0.509 2。分別領先位于其后的Attention U-Net 網絡0.41%、0.22%和8.0%。ResNet 網絡的Recall指標最優為0.962 2,Attention U-Net 網絡的Precision指標在所有模型結果中最優為0.897 0。 本文的SA-UNet 性能皆位居第二,略低0.08%和0.19%。 DeepLabv3 模型由于網絡層數較深,模型參數量較大,難以有效關注到圖像低層的細節信息,導致分割效果較差,從而反映了U型網絡中跳躍連接的重要性,側面驗證本文通過跳越連接層的改進與注意力機制的結合,加強圖像細節信息而提高分割結果的合理性和優越性。
3.6 模型復雜度實驗
為了進一步檢驗模型的復雜度,本節將SAUNet 與 U - Net、 U - Net ++、 Attention U - Net、DeepLabv3[31]、ResUNet 等5 種經典分割網絡模型的參數量和浮點運算量進行了分析,結果見表3。 結合表2 可以看出,與基準網絡U-Net 相比,本文提出的SA-UNet 參數量只增加了0.03 M,計算量只增加了0.4 G,而IoU指標提升了4.27%,DSC指標提升了2.27%。 也就是說,在幾乎沒有增加開銷的情況下,圖像分割精度得到了有效的提升。 進而,相比于Attention U-Net,本文研究的模型參數量減少了0.06 M,計算量降低了1.53 G,而IoU指標提升了0.41%,DSC指標提升了0.22%,網絡的分割精度和計算效率也得到了有效的改善。 這進一步驗證了Sharp 模塊沒有額外可學習參數,CBAM 模塊只有極少數的額外參數。 因此,SA-UNet 作為輕量級的模型在小樣本醫學圖像數據集中更加適用。
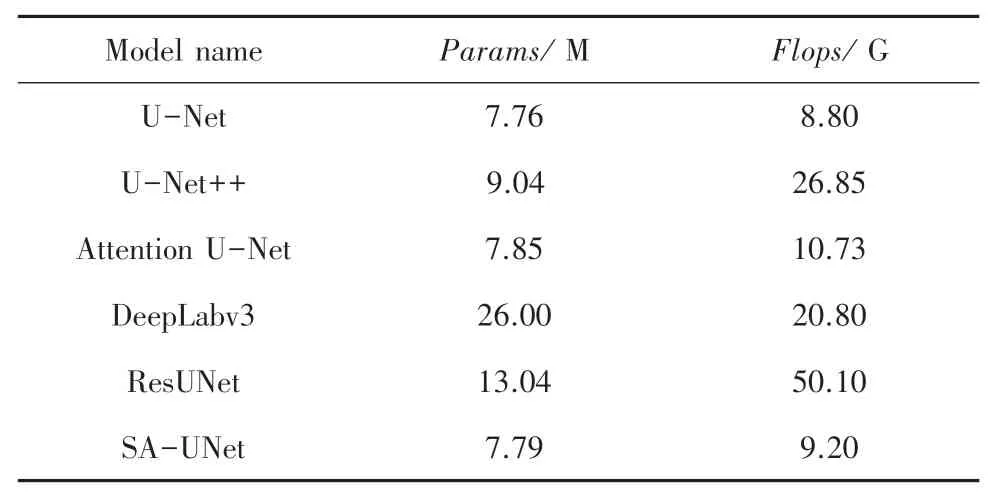
表3 模型參數Tab. 3 Model parameters
3.7 可視化分割結果分析
本節將給出不同網絡模型對口腔CBCT 圖像移植骨分割的可視化結果,如圖4 所示。 圖4(a)中第1~5 列分別表示來自5 位不同病人的口腔CBCT 圖像,(b)為移植骨的真實標簽,(c) ~(h)分別為U-Net、U -Net ++、DeepLabv3、Attention U - Net、ResUNet、SA-UNet 的分割結果。
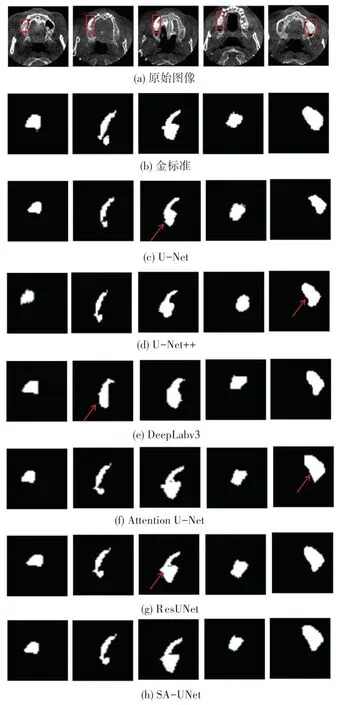
圖4 不同患者口腔CBCT 圖像的分割結果Fig. 4 Segmentation results of CBCT images from different patients
U-Net 和U-Net++網絡能夠基本實現對移植骨的分割。 但是U-Net 只是通過跳躍連接實現低層特征信息和高層特征信息的拼接,忽略了二者較大的語義差距帶來特征信息的丟失;U-Net++網絡通過大量的短連接實現多尺度特征信息的整合,但并沒有加強低層特征的重要性。 由圖4(c)、(d)可以發現,在U-Net 與U-Net++網絡模型的分割結果中,容易發生欠分割,并且對于移植骨凸出的邊緣分割效果不佳。 DeepLabv3 模型由于網絡層數較深,且在解碼部分使用多次的雙線性采樣。 由圖4(e)可以看出,該模型難以捕捉到移植骨圖像的細節信息(如圖像的邊緣,紋理信息),分割邊緣過于平滑,整體分割效果較差。 ResUNet 通過殘差連接的方式保留低層特征信息,Attention U-Net 通過注意力門的方式抑制不相關的區域,但仍然有特征學習不充分,在分割區域內有少量噪聲產生。 由圖4(f)、(g)可知,2 個網絡對于移植骨的整體輪廓分割效果較好,但依然有噪聲的殘留(見第三列),并且對于移植骨凸出部分分割不夠平滑,過于尖銳(見第五列)。 與這些網絡模型相比,本文提出的SA-UNet可以獲得更優的分割性能,在分割中能夠更準確地捕捉邊界信息過濾分割區域中的細小噪聲(見圖4(h)中的第二列、第三列);此外,本文網絡還能夠平滑地處理模糊邊界的情況,獲得更為精細的分割結果(見圖4(h)中的第四列、第五列)。
4 結束語
本文提出了一種基于U-Net 和注意力機制的新型編碼解碼網絡模型,該模型通過構建Sharp 模塊改進跳躍連接簡單的復制操作,增強低層圖像細節信息,平衡拼接操作產生的語義差距,通過在解碼器部分的每一層嵌入CBAM 模塊,通過注意力機制分配不同權重使得模型更加關注重要信息,抑制無用信息。 通過實驗表明,本文提出的SA-UNet 網絡結構能夠通過Sharp 模塊的銳化操作增強低層特征,并通過注意力機制提高對于圖像細節信息的關注度,同時設計了聯合損失函數對不平衡數據集進行優化,在移植骨圖像分割結果中有較好的性能。在模型復雜度方面,與U-Net 相比,幾乎沒有增加計算開銷,并且參數量遠小于其他醫學模型,同時分割精度與U-Net 相比在IoU,Dice系數兩個指標上分別提高了0.035 5,0.020 6;在分割精度方面,與現有的主流分割模型對比,在IoU、Dice系數、Hausdorff 距離三個評價指標上的表現最佳,得分達到了0.866 5、0.926 2、0.509 2。 由于本模型能夠有效提升圖像細節信息的特征提取能力,且模型參數相對較少,因此同樣適用于語義簡單、結構固定的其他小樣本醫學圖像數據集的分割以及輔助診斷應用。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
