基于改進YOLOv7-Tiny 的工業缺陷檢測研究
2023-02-28 16:10:00劉凌峰陳洪剛卿粼波孫承行
智能計算機與應用 2023年11期
劉凌峰,陳洪剛,卿粼波,孫承行
(1 四川大學電子信息學院,成都 610065; 2 四川省隆鑫科技包裝有限公司,四川 遂寧 629200)
0 引 言
隨著工業4.0 的到來以及中國制造2025 的提出,國家大力支持工業的發展。 鋼材作為一種經濟高效的工業材料在各個領域得到廣泛應用,如建筑、化工、船舶、冶金、航空航天等行業。 擁有高質量的鋼材對我國工業的發展至關重要。 在鋼材的生產過程中,由于生產原材料、生產工藝和外部環境等不可控因素的影響,鋼表面可能會出現各種不同類型的缺陷[1]。 因此,對鋼材缺陷進行高效的檢測具有極其重要的意義。
基于傳統機器視覺的目標檢測算法使用滑動窗口的方法來獲取候選區域的HOG 特征[2]和SIFT 特征[3],并利用SVM 分類器[4]進行目標分類。 這種檢測方法主要適用于待測目標特征明顯、背景簡單的場景,并且在檢測精度以及速度上存在一定的局限。在鋼材缺陷圖像中,背景與目標的區分度較低且缺陷目標類型復雜多變,使用傳統的抽象特征很難完成對缺陷的準確檢出。
目前,基于深度學習的目標檢測算法根據其是否采用多階段的處理,主要分為2 類:Two-Stage[5]和One-Stage[6]。 Two-stage 典型算法代表為Faster R-CNN[7]和Mask R-CNN[8],其使用區域建議網絡生成候選框,而后進行分類和回歸;One-Stage 算法典型代表為SSD[9]、RetinaNet[10]、EfficientDet[11]、YOLO 系列等,是利用處理回歸問題的方法來有效解決目標邊框定位的問題,因此不需要事先產生候選框。 在Two-Stage 目標檢測算法領域,LUO 等學者[12]基于CNN 構建了一種解耦的兩階段的工業目標檢測網絡,并在缺陷定位任務中提出了多級聚合塊作為定位特征增強模塊,用于PCB 板的缺陷檢測。 Shi X 等學者[13]將ConvNeXt 架構作為特征提取主干,提出了一種基于Faster R-CNN 的改進網絡用于鋼表面缺陷檢測。 在One-Stage 目標檢測算法領域,KOU 等學者[14]基于YOLOv3 進行改進,使用無錨框(Anchor-free)的方式縮短了模型的計算時間,設計密集卷積塊(Dense block)用于提取更豐富的特征信息,從而提升模型的準確率與魯棒性。Yang 等學者[15]首先將鋼材缺陷圖像經過同態濾波預處理,然后將圖片送入融合了注意力機制的改進YOLOv5 算法中進行檢測,達到了更高的檢測精度。
YOLO 系列作為One-Stage 算法典型的代表網絡,不僅在速度上優勢明顯,而且模型體積小,同時維持較高的識別精度。 在2023年,Wang 等學者提出了YOLOv7 算法,相比于領域內其他算法,YOLOv7 在目標識別和定位方面具有更高的準確性和更快的速度。 但是YOLOv7 網絡使用了大量EELAN 模塊,導致模型的參數量和復雜度大大增加,同時鋼材表面缺陷通常是小目標,在圖像中所占的像素點很少,且變形類型多樣、缺陷類型多樣,很容易被忽略或誤判,導致漏檢的問題。
為了提高鋼材表面缺陷檢測的效率,本文基于YOLOv7 的輕量化版本YOLOv7-Tiny,進一步優化網絡對目標的特征提取能力,引入混合注意力機制,增強網絡的特征感知;將可變形卷積融合進網絡骨干層,構建ELAN-DCNv3 模塊,增強模型對不同尺寸和形狀的缺陷的特征提取能力;在網絡特征融合層加入了基于內容感知的特征重組模塊,更加充分地利用上下文語義信息;最后,采用基于歸一化Wasserstein 距離的損失函數實現對小目標缺陷更加精準的檢測。
1 YOLOv7-Tiny 網絡結構
YOLOv7-Tiny 保留了YOLOv7 基于級聯的模型縮放策略,并改進了高效長程聚合網絡(ELAN),是一種輕量級的目標檢測算法,在保證檢測精度沒有大幅降低的基礎上參數量更少、檢測速度更快,更適合應用于鋼材表面缺陷實時檢測的需求。 YOLOv7-Tiny 網絡結構如圖1 所示。
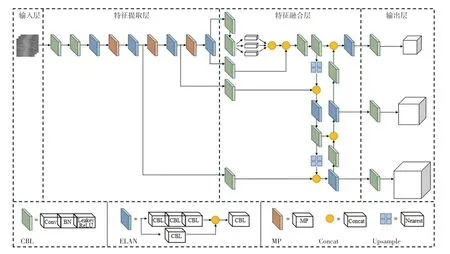
圖1 YOLOv7-Tiny 網絡Fig. 1 YOLOv7-Tiny network
Yolov7-Tiny 算法由輸入層、特征提取層、特征融合層及輸出層四個部分構成。 將固定尺寸的圖片作為輸入,首先將其送入由普通卷積層、MP 與ELAN 卷積層構成的特征提取層。 然后,將提取的特征圖送入在SPP 結構基礎上優化后的SPPCSPC模塊,進行處理后再送入特征融合層,采用聚合特征金字塔結構對整個金字塔特征圖進行增強,將下層的顯著性特征信息傳遞到上層,保留更豐富的特征信息。 最后,將這些語義豐富的特征圖送入輸出層,采用卷積對不同尺度的特征圖進行預測,在目標特征圖上應用錨框生成帶有類別概率和目標框的最終輸出向量。
盡管YOLOv7-Tiny 具有較少的參數和計算量,能保持較高的精度,但是針對鋼材表面缺陷這類小目標,存在特征提取能力不足的情況。 因此,本文提出改進方法,在不增加網絡參數的前提下加強特征感知,以滿足鋼材缺陷這類特征較弱的目標在實際應用場合的檢測需求。
2 改進型YOLOv7-Tiny 鋼材表面缺陷檢測算法
本文基于YOLOv7-Tiny,將可變形卷積融合進網絡骨干層,增強模型對不同尺寸和形狀的缺陷的特征提取能力;引入混合注意力機制,增強網絡的特征感知;在網絡特征融合層加入了基于內容感知的特征重組模塊,更加充分的利用上下文語義信息;最后采用基于歸一化Wasserstein 距離的損失函數實現對小目標缺陷更加精準的檢測。
2.1 構建ELAN-DCNv3 模塊
鋼材表面缺陷具有目標小、變形類型多樣、缺陷類型多樣的特點,普通卷積層對此類目標的特征提取能力較差。 本文中使用的DCNv3[17](Deformable Convolution Network v3)是在DCNv2[18](Deformable Convolution Network v2) 的基礎上進行改進的。DCNv3 首先借用了可分離卷積的思想,將原始卷積權重分離成深度部分和點部分,實現了卷積神經元之間的權重共享;其次,引入了多組卷積的機制,將空間聚合過程分成多組,每組具有單獨的采樣偏移和調制尺度,從而為下游任務帶來更強的特征;最后,通過用k個調制因子的softmax歸一化代替調制標量sigmoid,整個訓練過程變得更加穩定。 完整的DCNv3 運算符如式(1)所示:
其中,G表示卷積組的數量;Wg表示每組內的共享投影權重;mgk表示第g組中第k個采樣點的歸一化調制因子;xg表示切片輸入的特征圖; △pgk表示第g組中的網格采樣位置(g,k) 相對應的偏移量。
本文將可變形卷積DCNv3 與特征提取層的ELAN 結構融合,重建ELAN-DCNv3 結構,結構如圖2 所示。
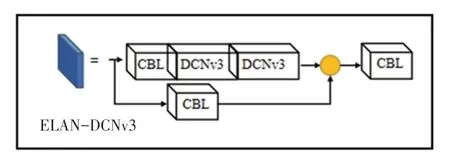
圖2 ELAN-DCNv3 結構Fig. 2 Structure of ELAN-DCNv3
使用DCNv3 算子可以彌補傳統卷積在長期依賴性和自適應空間聚合方面的不足,并可使卷積算子更適合于變化多樣缺陷的檢測,同時通過實現稀疏全局建模并適當地保留CNN 的歸納偏差,更好地實現了檢測復雜性和準確性之間的平衡。
2.2 構建ELAN-CBAM 模塊
注意力機制的原理是選擇性地關注更感興趣的領域,而忽略信息的其他部分。 在鋼材缺陷檢測中引入注意力機制可以提高缺陷目標區域的權重。 神經網絡可以更完整地區分待檢測的缺陷目標和背景信息,有效地解決由于網絡層次加深導致的鋼材缺陷目標信息丟失的問題,使網絡學習能夠朝著更有利的方向學習。
在真實的鋼材缺陷數據中,缺陷目標較多且種類繁雜,為了解決小目標漏檢、誤檢的問題,需要讓網絡更加關注裂紋、麻點等小目標缺陷。 本文選用CBAM 注意力機制(如圖3 所示),依次應用通道和空間注意力模塊,強化了通道和空間兩個維度上的缺陷特征,具體計算過程如下。
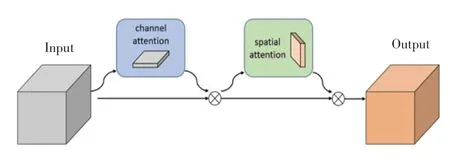
圖3 CBAM 注意力機制結構Fig. 3 Structure of CBAM attention mechanism
給出輸入特征圖為X∈RC×H×W,CBAM 模塊首先通過通道注意力模塊(FCH∈RC×1×1) 生成通道注意力特征圖,然后將其與輸入圖像相乘生成中間變量X′,計算過程可由式(2)來表示:
其中,“ ?”表示加權乘法。
此后通過二維空間注意力模塊(Fs∈R1×W×H)在特征圖X′的基礎上生成空間注意力特征圖,再將二維空間注意力模塊Fs與通道自適應化后的特征圖X′相乘,得到最終特征加強后的特征圖F″,計算過程可用式(3)來描述:
在特征提取層中,隨著網絡的逐漸加深,特征圖的尺度會變小,并且會丟失一些信息。 因此,本文將CBAM 注意力機制與卷積層融合,嵌入到特征提取層提取了特征后的特征圖輸出處,構建ELANCBAM 模塊(如圖4 所示),以強化隨著網絡深度而逐漸削弱的特征,增強網絡的表達能力,提高最終檢測的精度。

圖4 ELAN-CBAM 結構Fig. 4 Structure of ELAN-CBAM
2.3 引入輕量級特征重組模塊
在YOLOv7 的特征融合層中,使用了最近鄰上采樣算法進行特征圖的上采樣,是通過像素之間的空間距離來指導上采樣的過程,利用采樣點四周相鄰最近的像素點的灰度值,但卻忽略了其他像素點的影響,無法充分利用特征圖中的空間特征,可能會造成輸出圖像灰度值上的不連續,從而使得圖像灰度變化明顯區域出現噪聲,這會對鋼材缺陷這類小目標的檢測造成極大的困擾,導致檢測精度降低。基于此,本文引入了基于內容感知的輕量級特征重組算子CARAFE[19](如圖5 所示)來代替YOLOv7-Tiny 特征融合層中的最近鄰上采樣。 CARAFE 算子能夠在更大的感受野中聚合上下文信息,摒棄了最近鄰上采樣算法中使用單一內核采樣的方式,采用了基于自適應內容感知的采樣方式,其具體計算流程如圖5 所示。
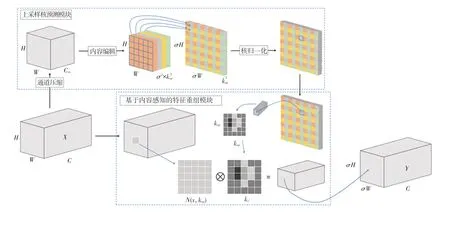
圖5 CARAFE 計算流程圖Fig. 5 Calculation flowchart of CARAFE
在經過CARAFE 模塊重建后的特征圖中,每個像素都是根據鄰域的特征內容進行上采樣的,充分利用了上下文信息,讓局部區域的相關點信息得到了更多的關注,使其語義信息更加豐富。
2.4 基于歸一化Wasserstein 距離的損失函數
本文所檢測的鋼材表面缺陷中存在許多小目標缺陷,這對目標檢測來說是一個難點,因為其中往往只包含幾個像素,因此,提高檢測小目標的能力對于提升整個鋼材缺陷檢測的效果十分重要。
目前,各類目標檢測算法通常使用基于IoU(Intersection over Union)的各類損失函數作為模型優化的指引,例如CIoU、SIoU等。 但是這些度量標準對小目標的位置偏差敏感度較高,很容易受小像素分布的影響。 預測框P中幾個像素的偏差就會導致P與標注框GT之間的重疊部分變化特別大,導致基于IoU的損失函數并不適用于小目標物體的檢測。
針對這個問題,本文采用了一種基于歸一化Wasserstein 距離[20](NWD,Normalized Wasserstein Distance)的損失函數。
首先將建模為二維高斯分布,然后使用歸一化Wasserstein 距離(NWD)的計算標準來計算其相應高斯分布之間的相似性;接著將NWD 度量標準嵌入到模型的損失函數中,取代YOLOv7-Tiny 原始的CIoU損失函數。 基于NWD 的損失函數計算過程如下:
其中,Np是預測框P的高斯分布模型,Ng是標注框GT的高斯分布模型。 基于NWD 的損失函數即使在小目標缺陷檢測時像素點偏差的情況下也能夠擁有梯度,進一步提高鋼板缺陷目標檢測的精度。
2.5 改進后的YOLOv7-Tiny 模型
本文改進后的YOLOv7-Tiny 網絡結構圖如圖6所示。
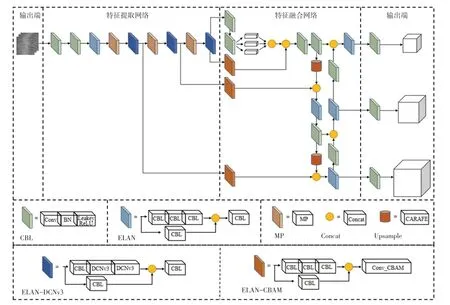
圖6 改進后的YOLOv7-Tiny 網絡結構圖Fig. 6 Structure of improved YOLOv7-Tiny network
3 實驗結果與分析
3.1 實驗數據集
本文采用了東北大學發布的鋼材表面缺陷數據集來驗證改進的YOLOv7-Tiny 算法的有效性。NEU-DET 包含6 種鋼材表面缺陷,包括裂紋(crazing)、夾雜(inclusion)、斑塊(patches)、麻點(pitted surface)、軋入氧化皮(rolled in scale)以及劃痕(scratches)。 每種缺陷圖片的數量為300 張,共1 800張,圖像大小均為200?200。 6 類缺陷樣例如圖7 所示。

圖7 鋼材表面缺陷樣例Fig. 7 Examples of steel surface defects
實驗以每類8 ∶1 ∶1 的比例隨機劃分,選取1 260張圖片作為訓練集,260 張圖片作為驗證集,260 張圖片作為測試集。
3.2 實驗環境及訓練參數
本文提出的鋼材表面缺陷檢測算法的實驗硬件環境以及軟件環境見表1,訓練參數見表2。

表1 實驗采用的硬件環境與軟件環境Tab. 1 The hardware environment and software environment adopted in the experiment
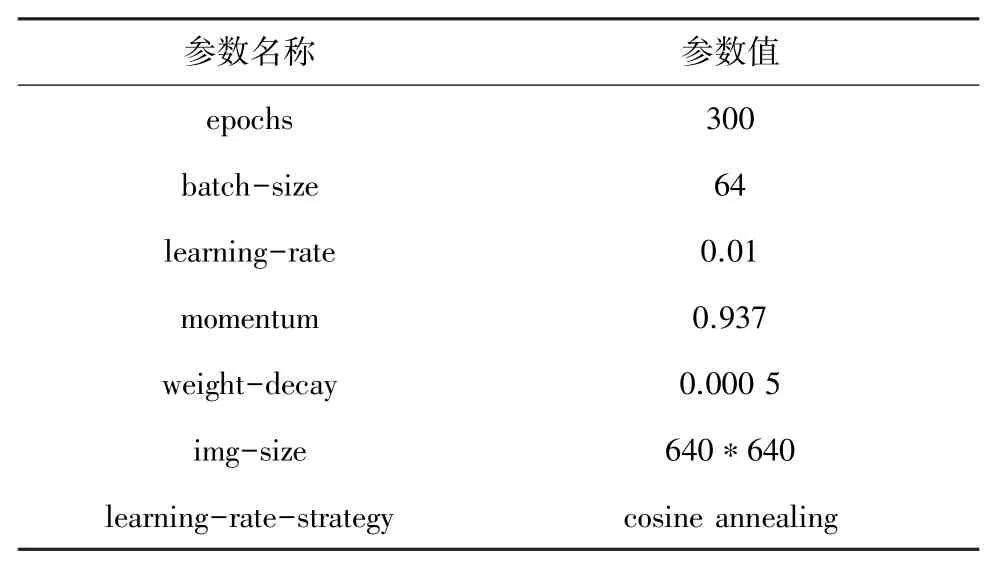
表2 實驗采用的訓練參數Tab. 2 The training parameters used in the experiment
3.3 模型評價指標
本文采用平均準確率(mAP@0.5)、 模型大小(Model Size)作為算法性能的衡量指標。 其中,mAP是各類缺陷準確率AP的均值,AP則由各類的精準度(Precision,下文簡稱P) 以及召回(Recall,下文簡稱R) 計算得到,其值為P -R曲線與坐標軸圍成的面積;研究推得的數學定義公式具體如下:
其中,TP為正確檢測到缺陷的樣本數量;FP是錯誤地將非缺陷目標檢測為缺陷目標的數量;FN是錯誤地將缺陷目標認作非缺陷的數量。mAP@0.5表示IoU閾值在0.5 的mAP。
3.4 對比實驗設計
為了驗證本文提出方案的效果,在NEU-DET數據集中測試了多種目前主流的目標檢測算法,包括SSD、RetinaNet、YOLOv5s、YOLOv7 以及文獻[21-22]。 選取平均精度mAP@0.5 以及網絡模型大小作為評價指標。 對比實驗結果見表3。 通過表3 可以看出,本文提出的改進算法平均準確率mAP@0.5比YOLOv7-Tiny 高4.3%,模型大小壓縮了11.3%,實際檢測效果對比如圖8 所示。 圖8(a)~(c)中,從左到右分別是裂紋、夾雜、斑塊、裂紋、軋入氧化、劃痕。 可以看到,經過改進之后的網絡對小目標的缺陷識別能力有著明顯的提升,識別精度也有所提高。 相較于Faster-RCNN、RetinaNet、YOLOv3-Tiny、YOLOv7 算法,評價指標有著不同程度的領先。 相較于文獻[21-22],在檢測精度上也有著明顯的優勢。 由此證明,本文提出的改進算法的性能優于目前領域內的主流算法。
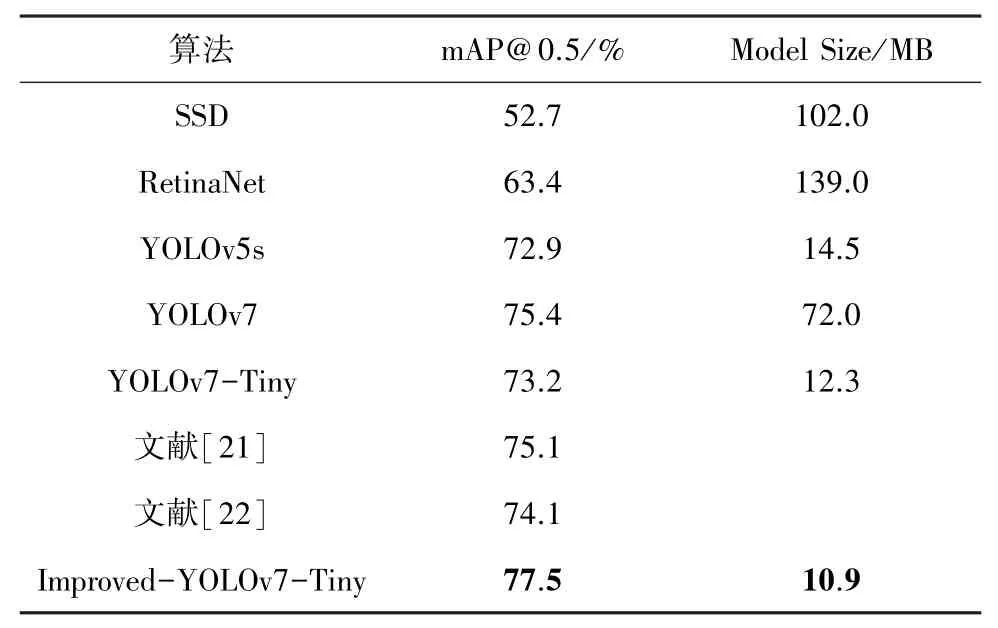
表3 對比實驗結果Tab. 3 Comparative experimental results

圖8 實際檢測效果圖Fig. 8 Actual test effect drawing
3.5 消融實驗設計
為了進一步驗證本文提出的改進方法對模型的有效性,對改進算法進行消融實驗。
消融實驗結果分析見表4。 從表4 的結果可知,引入DCNv3 構建ELAN-DCNv3 模塊后,模型的識別準確率有著明顯的提升,mAP@ 0.5 提升了1.1%,同時,由于DCNv3 采用了可分離卷積以及分組卷積的思想,模型的大小也有了一定程度的壓縮;在ELAN-DCNv3 的基礎上進一步引入CBAM 注意力機制,加強網絡對鋼材表面缺陷目標的特征感知,學習通道與空間兩個維度間的相關性,使mAP@0.5提升了0.6%,但是參數有了小幅度的增加;將網絡特征融合層原始的最近鄰上采樣改進為基于內容感知的輕量級特征重建模塊CARAFE 后,更加豐富了上采樣后特征圖的語義信息,進一步增強了利于網絡的識別能力,使得mAP@0.5 提升了0.9%;最后將網絡原始的CIoU損失函數改進為更適用于小目標檢測的基于NWD 的損失函數,將mAP@0.5 在之前的基礎上再次提升了1.7%,達到77.5%。
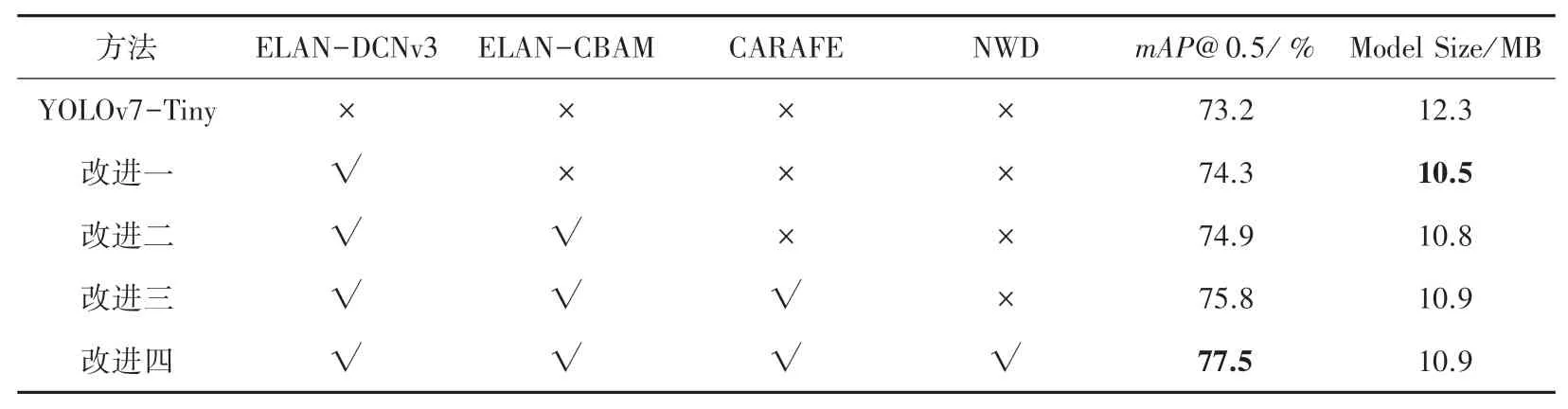
表4 消融實驗結果分析Tab. 4 Analysis of ablation experimental results
經過消融實驗結果分析,本文確定了最終的改進方案為構建ELAN-DCNv3、構建ELAN-CBAM 模塊、引入CARAFE 和采取基于NWD 的損失函數。YOLOv7-Tiny 改進前后訓練效果對比如圖9 所示。由圖9 可以看出,在經過300 個Epochs的訓練迭代后,改進后的YOLOv7-Tiny 算法在6 類鋼材缺陷上的檢測精度均有提升,平均準確率mAP@0.5 相較于原始YOLOv7-Tiny 提高4.3%,同時模型大小壓縮了11.3%。
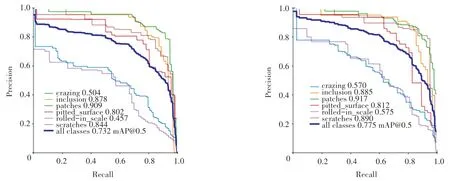
圖9 YOLOv7-Tiny 改進前后訓練效果對比圖Fig. 9 Comparison of YOLOv7-Tiny training effect before and after improvement
4 結束語
本文針對工業生產環境需要對鋼材表面缺陷進行高效檢測的應用背景,提出了一種基于改進YOLOv7-Tiny 的鋼材表面缺陷識別方法。 該方法以YOLOv7-Tiny 為基礎,改進特征提取層的ELAN結構,引入DCNv3 構建ELAN-DCNv3 模塊,在降低一定模型參數量的同時增強了網絡對多種類型、形狀缺陷的特征提取能力;增加CBAM 注意力機制,提升了網絡對鋼材表面缺陷的特征感知能力;采用基于內容感知的特征重組算子CARAFE 進行特征圖的上采樣,讓局部區域的相關點信息得到了更多的關注,更加豐富了輸出特征圖的語義信息;此外,針對IoU損失函數對小目標缺陷位置偏移敏感的問題,采取基于NWD 的損失函數,使得網絡有了更好的小目標檢測性能。 實驗結果表明,本文提出的方法對于鋼材表面缺陷有著很好的識別效果,識別準確率達到了77.5%,同時將模型壓縮了11.3%。 本文方法在不增加模型復雜度的前提下,識別準確率方面較YOLOv7-Tiny 有著較為明顯的提升,在實際應用中展示出了巨大的潛力。 未來將繼續優化算法,提升算法的準確率,對模型進行剪枝、知識蒸餾,進一步降低模型的推理復雜度,提升模型在邊緣計算端的性能,更適應實際生產應用。 同時考慮通過數據增強的方式擴充數據集,使得模型的泛化性能進一步提高。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
