
一種可解釋的自由文本擊鍵事件序列分類模型
2023-03-01 08:19:58韓繼紅張玉臣李福林
電子與信息學報 2023年2期
張 暢 韓繼紅 張玉臣 李福林
(信息工程大學 鄭州 450000)
1 引言
隨著人工智能技術的飛速發展,人臉等生物特征在身份認證和識別領域得到廣泛的應用。研究表明,人敲擊鍵盤的“節奏”可以作為身份認證和識別的行為特征[1]。通常把按鍵事件發生的時間間隔作為擊鍵行為特征,一般包括從前一按鍵釋放到后繼按鍵按下的時長UD time、從前一按鍵按下到后繼按鍵按下的時長DD time(或稱digraph)、從前一按鍵釋放到后繼按鍵釋放的時長UU time、按鍵從按下到釋放的時長Hold time、n(n≧2)個按鍵事件從第1個按鍵按下到第n個按鍵按下的時長n-graph等。擊鍵行為研究一般分為固定文本和自由文本兩大類,如果擊鍵事件序列對應文本內容和長度都相同,屬于固定文本研究;如果內容和長度不確定,則屬于自由文本研究。
人們研究擊鍵行為已有40多年。期間,固定文本研究文獻較多,取得了很好的分類效果,而自由文本研究的文獻偏少,且分類效果一直不佳[2]。近期,Acien等人[2]用孿生網絡模型大幅提升了自由文本擊鍵事件序列的分類效果。本文在Acien的工作的基礎上展開深入研究,探索分類效果好且具有可解釋性的模型。
自由文本擊鍵事件序列因為鍵值不確定、長度不一,所以無法得到像固定文本一樣“整齊”的特征向量。常見的自由文本擊鍵事件序列特征有:(1)以按鍵組合的n-graph均值為特征[3–6];(2)以基于n-graph均值的按鍵或按鍵組合的排序為特征[7,8];(3)以分組組合的用時均值為特征,例如把鍵盤劃分成左手區、右手區和空格3組[9,10],以這3組按鍵事件的時間間隔為特征,或者按元音、輔音、標點、功能鍵等劃分按鍵[11],以元、輔音等分組按鍵事件的時間間隔為特征。上述方法中,文獻[5]和文獻[6]在Clarkson II自由文本數據集獲得了15.3%和7.8%的等錯誤率(Equal Error Rate, EER),但得到這樣的結果需要至少200個digraph的測試樣本和10000個digraph 的訓練樣本,因此不適用于短自由文本擊鍵事件序列的分類。因為自由文本擊鍵事件序列的特征不“整齊”,很長一段時期,自由文本擊鍵事件序列的分類效果遠不及固定文本。
近期該問題有了轉機:生成模型POHMM[12]把擊鍵事件序列看作被試者受“積極”、“消極”兩種隱狀態的影響對鍵入文本的響應,如果有覆蓋全面的訓練集,理論上可以消除文本內容差異對分類的影響,但采集這樣全的樣本數據并不現實。蘆效峰等人[13]嘗試用卷積神經網絡+循環神經網絡結構的深度神經網絡模型做自由文本擊鍵事件序列的分類,在Buffalo 數據集中使用相同鍵盤的75個被試者的數據上,取得了3.04%的EER。作者聲稱其研究不足之處在于使用的數據量小。另外,這種方法解決的是閉集識別問題。Acien等人[2]用Aalto University自由文本數據集[14]的6萬多被試者的數據訓練基于長短時記憶網(Long-Short Term Memory,LSTM)的孿生神經網模型TypeNet,在剩余10多萬被試者的數據上測試,獲得了2.2%的EER,分類效果明顯優于POHMM。Morales等人[15]在Acien工作的基礎上,提出用SetMargin Loss訓練TypeNet模型。和Acien采用的Contrastive loss和Triplet loss不同,SetMargin Loss使得同類特征序列集圍成的面積小,而不同類特征序列的間距離大。該做法使TypeNet模型能夠更好地適應類內變化,取得了1.85%的EER。
2 研究思路
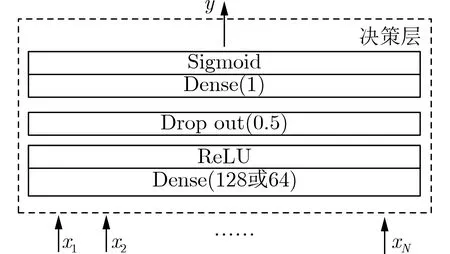
Acien和Morales的實驗結果驗證了TypeNet網絡結構的有效性,即用雙層LSTM將擊鍵事件序列對應的特征序列映射到表征空間(embedding space),基于孿生網絡結構采用對比學習方法,使得在表征空間上,屬于同一人的特征序列的歐氏距離小,不同人的特征序列的歐氏距離大。TypeNet的表征空間是128維,使用歐氏距離度量表征向量(embedding)的相似度,所以表征空間的維度缺乏可解釋性。本文用多層感知機替換TypeNet模型中的對比損失函數,來度量表征向量的相似度。具體做法是:把孿生網絡模型的分支輸出的表征向量差的絕對值作為多層感知機的輸入,多層感知機輸出作為孿生網絡模型輸入特征序列對的相似度量值,激活函數為sigmoid,采用交叉熵損失函數訓練模型。為了解釋表征向量,把多層感知機的輸入X(即表征向量)的元素xi作為自變量,輸出y作為因變量,用多元多項式模擬多層感知機的輸入X和輸出y之間的關系y=f(X)=f(x1,x2,...,xN)。根據多元多項式f分析X各維度與相似度量的關系。
3 孿生網絡模型
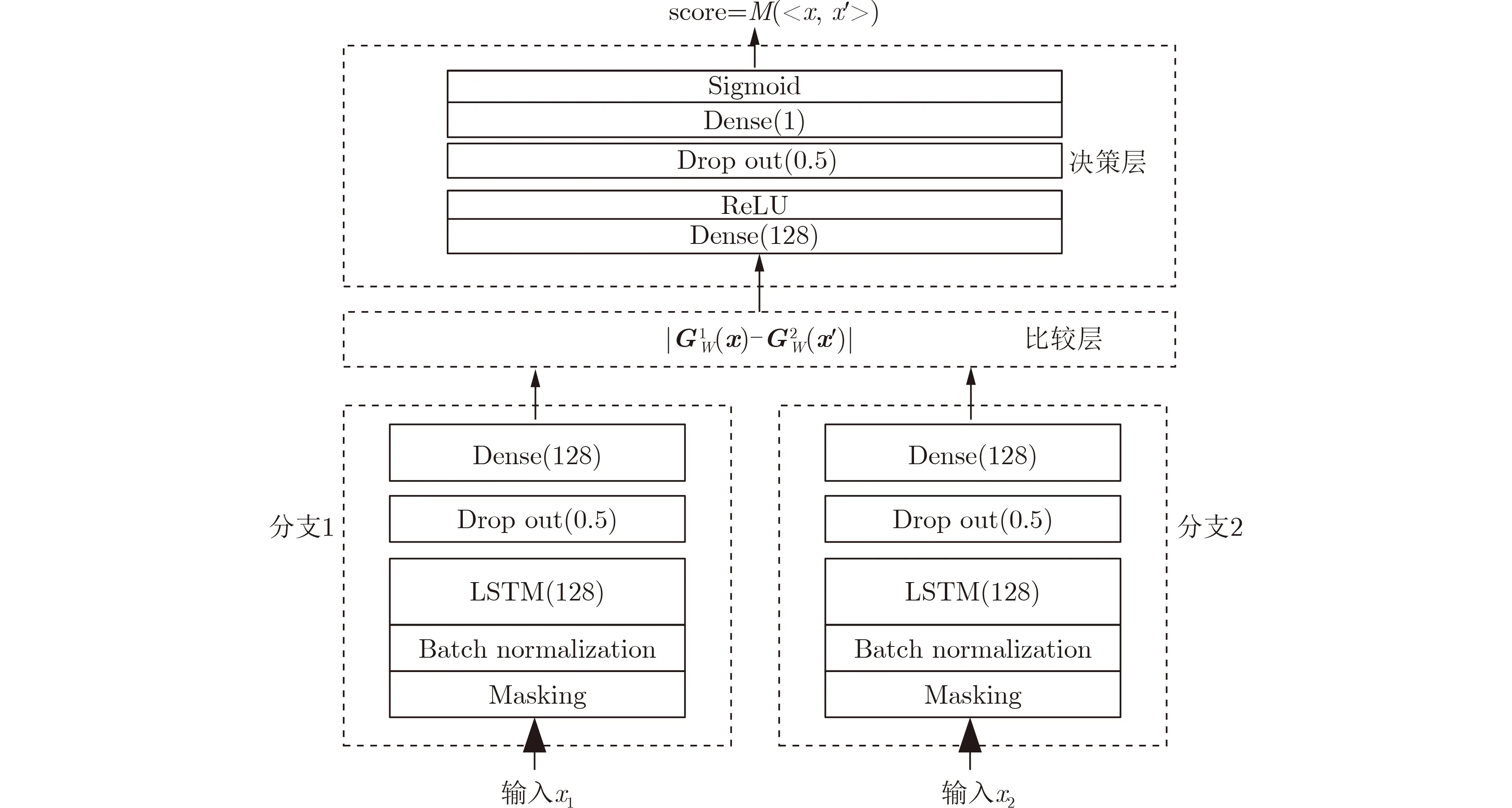
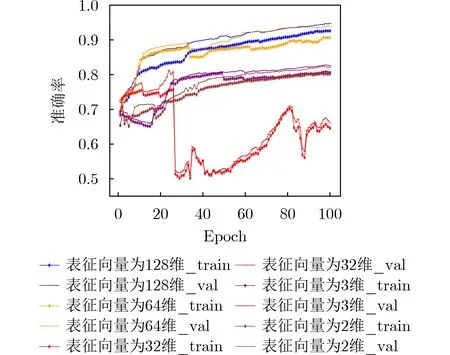
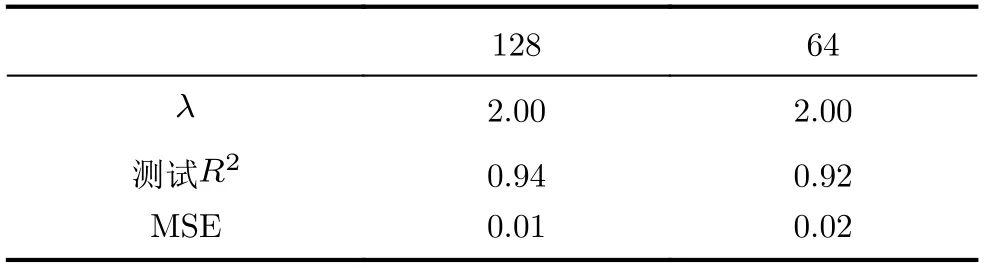
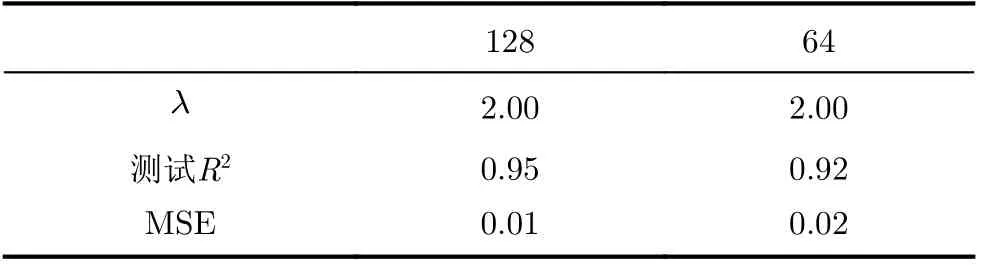
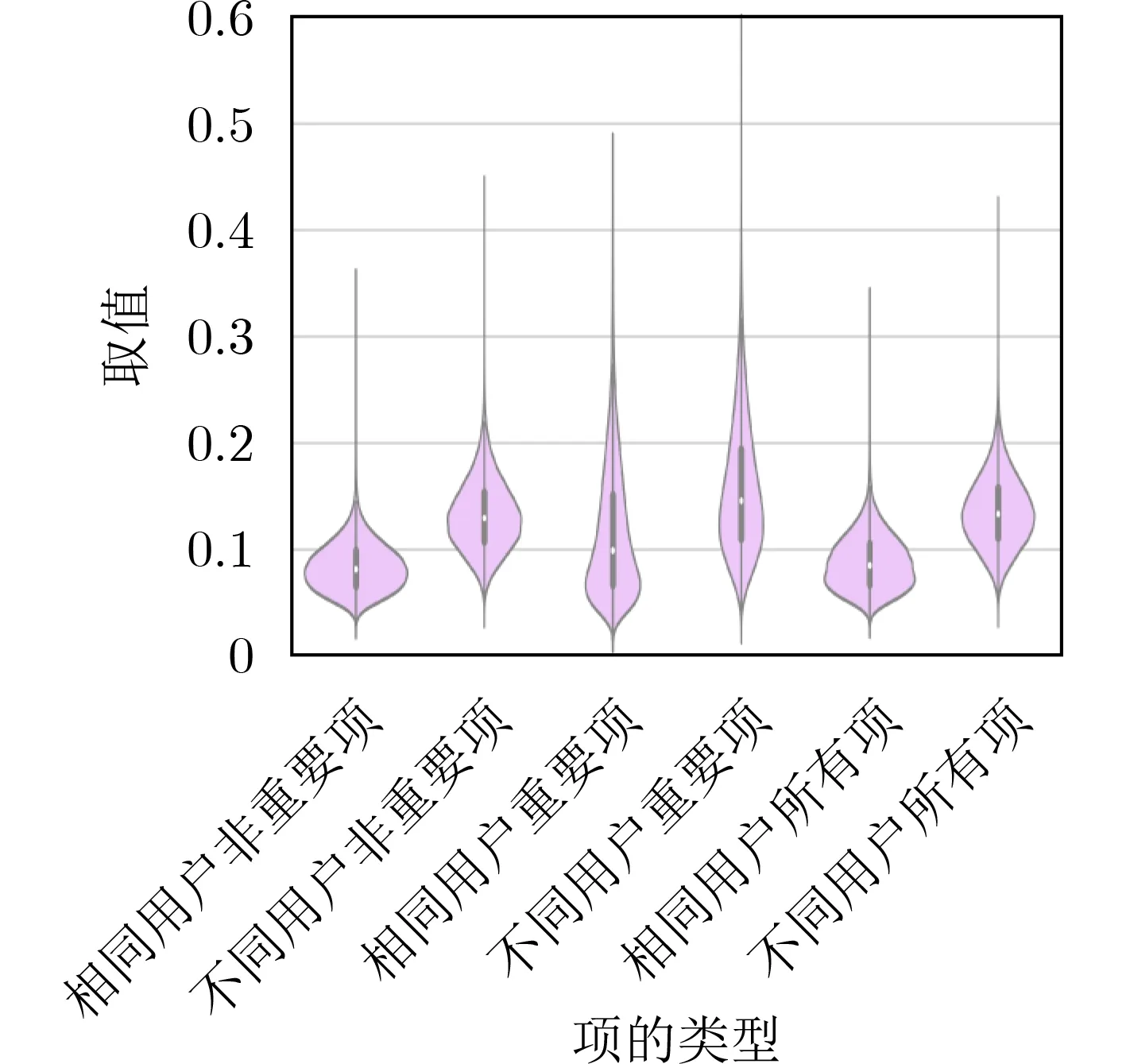
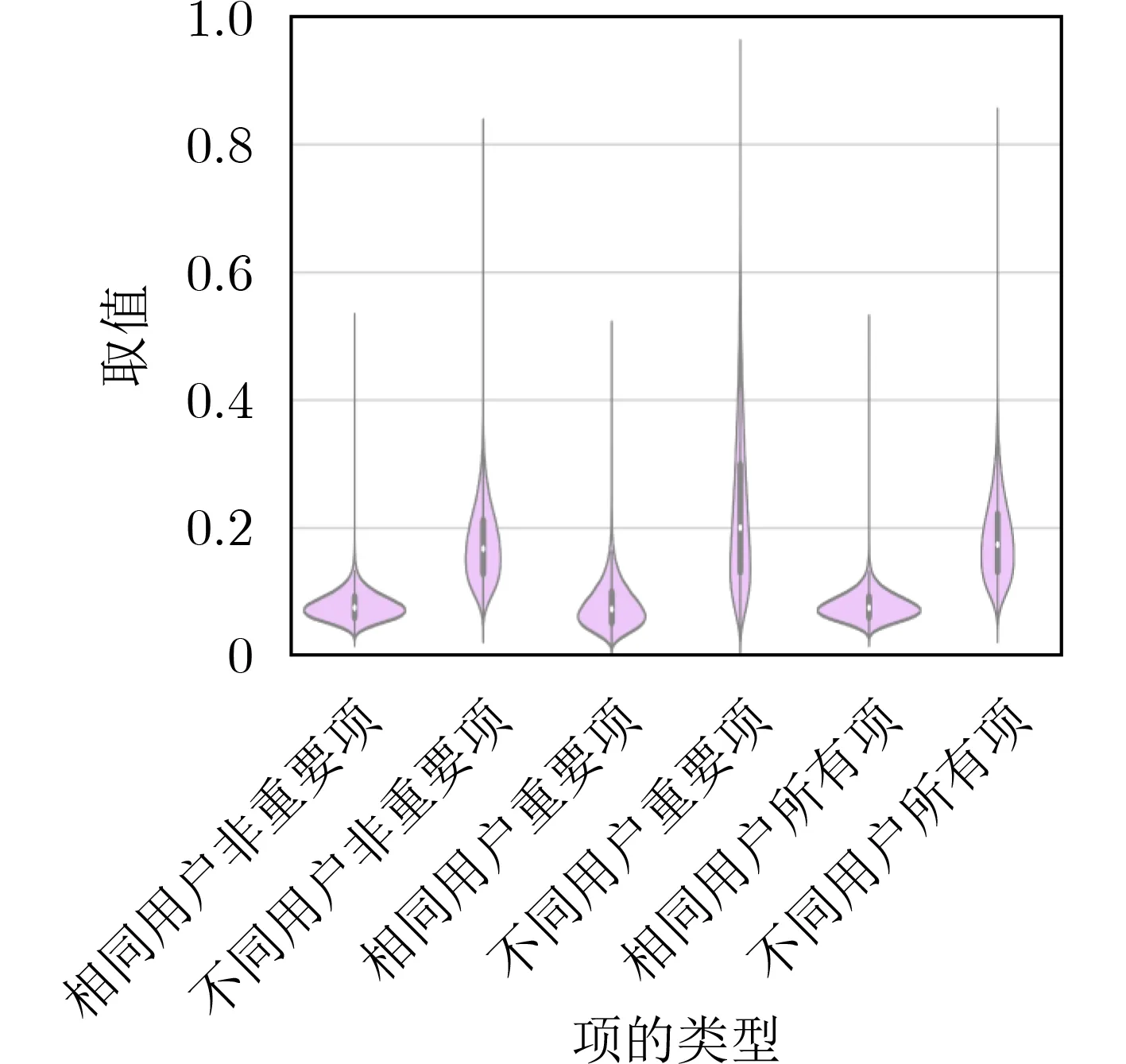
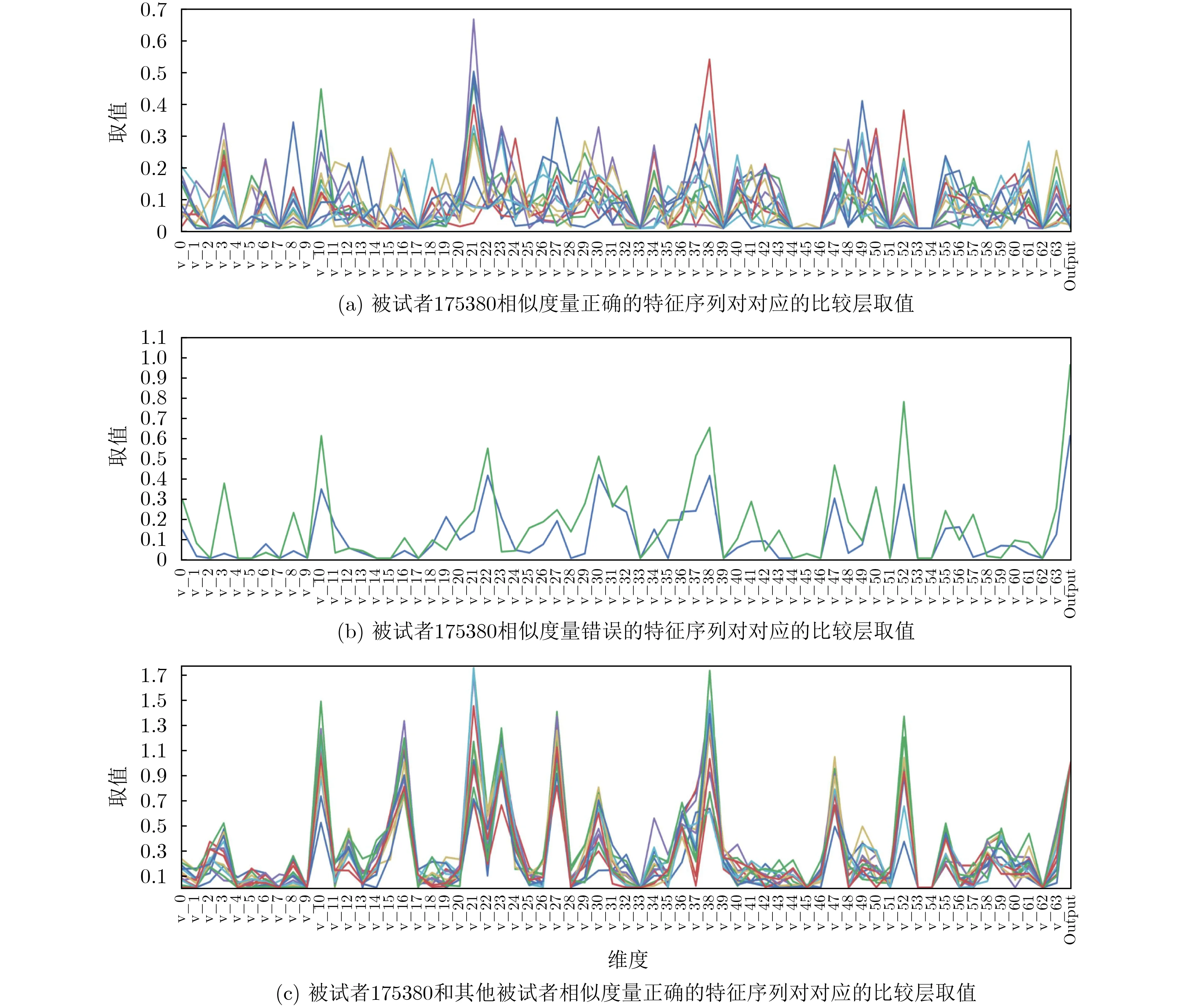
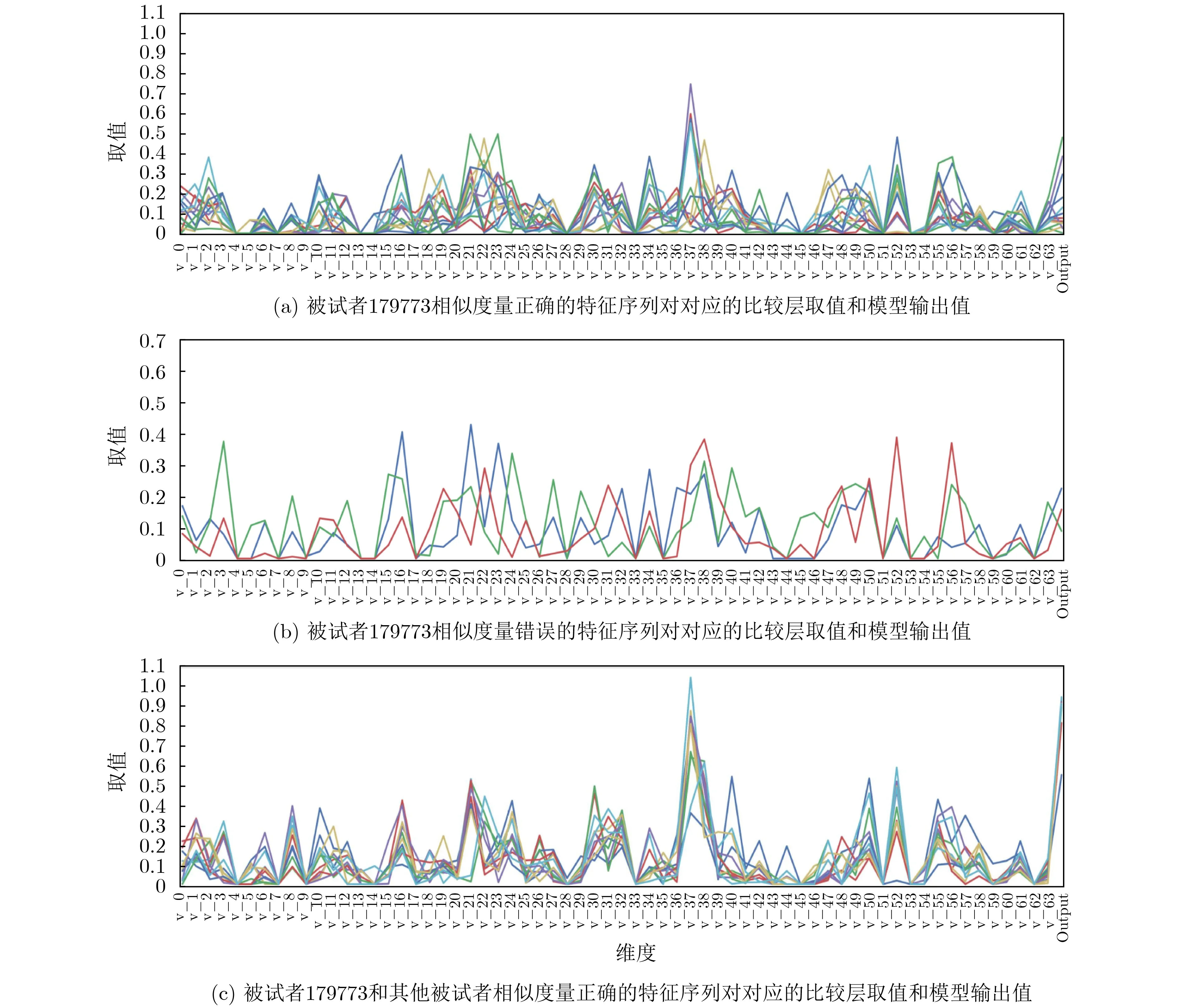
TypeNet模型[2]的分支的輸入為長度為M的特征序列。特征序列的元素是一個5元組:<按鍵值、按鍵的Hold time、本按鍵與后一按鍵的UD time、本按鍵與后一按鍵的DD time、本按鍵與后一按鍵按鍵的U U t i m e>。若特征序列長度N>M,則截斷丟棄超出長度M的部分;如果N 本文最初嘗試用和TypeNet模型一樣的分支結構,即兩層L S T M,得到的訓練效果遠不及TypeNet模型,之后轉而用單層LSTM網絡作分支結構,得到測試準確率超出了用contrastive loss訓練的TypeNet模型近5個點。下面介紹改進的模型TypeNet II。 單層LSTM的輸出是128維,若不降維處理,分支輸出的表征向量也是128維。為了降低模型的復雜度,在確保分類準確率的前提下,應盡量降低表征向量的維度(分支的Dense層的作用類似于bottleneck layer),所以本文也嘗試了一些比128小的維度。實驗中,表征向量維度取值范圍為{128, 64,32, 3, 2}。 為了弄清楚比較層各維度與相似度量的關系,本文用多元多項式模擬決策層(原理如圖2所示)。多元多項式的自變量對應于比較層的各維度,因變量是決策層的輸出,亦模型的輸出。將大量特征序列對輸入訓練好的模型產生因變量和自變量數據集,在此數據集上用嶺回歸學習多元多項式f(X)=f(x1,x2,...,xN),根據多項式分析比較層對決策層輸出的影響。 圖1 TypeNet II的結構 圖2 決策層的多元多項式回歸模型 和Morales一樣,本文用Aalto University自由文本數據集的68000個被試者的數據訓練TypeNet II,在剩余數據中選5000個被試者的數據測試分類效果。從Acien和Morales的文獻中無法得知這些數據來自哪些具體被試者。本文隨機抽取符合上述數量的數據作為訓練和測試數據。實驗分兩部分:實驗1訓練TypeNet II模型,并和Morales提出的模型的分類效果進行比較;實驗2用多元多項式模擬TypeNet II模型的決策層,用參與訓練TypeNet II模型的10000個被試者的數據學習得到多元多項式f1,用未參與模型訓練的10000個被試者的數據學習得到多元多項式f2, 比較f1和f2的系數以驗證多元多項式回歸的泛化性,最后結合多元多項式分析比較層與決策層輸出的關系。實驗代碼的地址為:https://github.com/zcmail/TypeNet_II。 圖3展示了TypeNet II模型訓練過程中的訓練(train)和驗證(val)準確率。模型輸出小于0.5判定輸入特征序列對屬于同一人,反之,不屬于同一人。圖4反映表征向量維度為128和64時模型的準確率高,維度為3和2時準確率低,維度為32時準確率最低。表2展示經過100個epoch的訓練,采用不同表征向量維度的模型取得的最佳驗證準確率。根據圖4,本文選擇測試了表征向量為128和64維的模型的分類效果。測試時,根據每個被試者的特征模板確定分類閾值(不一定是0.5)。表3展示TypeNet II模型和TypeNet模型的分類效果。可以看出,表征向量為128維時,TypeNet II的分類效果超過了目前已知最好的方法(即Morales的方法[1])。 表1 TypeNet II模型的主要超參數 表2 TypeNet II模型不同表征向量維度對應的最佳訓練驗證準確率 表3 模型的分類效果 圖3 TypeNet II模型的訓練和驗證準確率 圖4 分類效果隨負樣本類數量的變化情況 表4 兩個表征向量維度下P tr上 多元多項式f 不同自由度對應的R2 表5 兩個表征向量維度下P tr上多元2階項式嶺回歸結果 為了驗證在Ptr上 訓練得到的多元二項式f的泛化能力,本文在Str以外的10000個被試者的特征序列對數據集Pte上做了同樣的工作,得到的多元2階多項式回歸結果如表8—表10所示。綜合表6、表7、表9、表10可以得:在Pte上,表征向量為128維的模型的決策層的多元二項式回歸系數大于0.5的有16項(表9),這16項和Ptr上學習得到多元二項式(表6)基本一致。由于多元二項式的項多,逐個分析難度大,所以本文把比較層的維度分為兩類:把表6的16項對應的維度作主要維度,剩余的為其他維度。同樣地,表征向量為64維的模型的決策層的多元二項式回歸系數絕對值大于0.4的有7項,除了二次項v18×v19外,這6項和Ptr上學習得到回歸式(表7)基本一致,本文把這6項對應的維度作為主要維度。 表6 P tr上表征向量為128維,多元2階多項式系數絕對值超過0.5的項 表7 P tr上表征向量為64維,多元2階多項式系數絕對值超過0.4的項 表8 兩個表征向量維度下P te上多項式嶺回歸結果 表9 P te上表征向量為128維,多元2階多項式系數絕對值超過0.5的項 表10 P te上表征向量為64維,多元2階多項式系數絕對值超過0.4的項 這里比較分析比較層的主要維度和其他維度對決策層輸出的影響。圖5和圖6是將Str之外10000個被試者的特征序列對分別輸入表征向量維度為128和64的TypeNet II模型得到比較層的數值的小提琴圖。圖中第1、第3、第5列分別屬于同一人的特征序列對得到的其他維度、主要維度以及所有維度取值的均值,第2、4、6列分別對應不同人的特征序列對得到的均值。圖5和圖6表明:(1)屬于同一人的特征序列對得到的值要低于不同人的特征序列對得到的值;(2)主要維度取值的均值的分布相對分散。 圖5 表征向量維度為128的TypeNet II模型得到比較層的數值的小提琴圖 圖6 表征向量維度為64的TypeNet II模型得到比較層的數值的小提琴圖 為了進一步分析比較層各維度與決策層輸出(相似度量)的關系,下面選用表征向量維度為64的模型,分析從Str以外的數據中抽取2個被試者(175380, 179773)的樣本對應的特征序列。圖7(a)是相似度量正確的被試者175380的特征序列對對應的比較層取值,圖7(b)是相似度量錯誤的被試者175380的特征序列對對應的比較層取值,圖7(c)是相似度量正確的被試者175380和其他被試者的特征序列對應的比較層取值。被試者175380的第7和第8個特征序列對的 s core超過了0.96,第6和第7個特征序列對的 s core超過了0.6,這是兩個錯誤的相似度量。和圖7一樣,圖8是被試者179773的比較層取值情況。圖8(b)展示被試者179773的第5個特征序列和其他被試者的特征序列的s core為0.08,第14個特征序列和其他被試者的特征序列的s core為0.16,第1個特征序列和其他被試者的特征序列的s core為0.23,這是3個錯誤的相似度量。圖7和圖8的橫坐標的最后一個刻度是 s core。對比圖7(c)和圖8(c),除了取值變化的幅度稍大外,兩者的線型走勢沒有明顯相似之處,但它們對應的決策層的輸出都超過0.95。圖7(b)相對于圖7(a)取值的幅度變化稍大一些,和圖7(c)的線型走勢沒有相似之處,但圖7(b)和圖7(c)對應的決策層的輸出都超過0.6。圖8(b)相對于圖8(c)取值的幅度變化稍小,和圖8(a)沒有明顯相似之處,但圖8(b)對應的 s core都低于0.5。以上分析表明決策層的輸入和輸出之間是非線性關系。 另外,圖7和圖8中,比較層的一些維度取值始終是0,例如,v_33, v_53等,還有一些維度取值絕大多數為0,少許為較小的數(1e-2),例如v_9,v_62等。其原因是分支輸出的表征向量的這些維度取值為0或者絕大多數取值為0。 實驗1的結果表明,和TypeNet模型的分支不同,TypeNet II模型雖然只用了單層LSTM,但分類效果超過了Acien和Morales提出的方法。模型的表征向量維度是128和64維時,分類效果差別不大,當維度降到32或更小維度時,分類效果出現了明顯下降。圖7和圖8表明模型的表征向量是64維時,部分表征向量維度沒有提供對樣本分類有用的信息,表明模型的表征向量維度還可以繼續壓縮。 圖7 被試者175380的特征序列對應的比較層和模型輸出的可視化 圖8 被試者179773的特征序列對應的比較層和模型輸出的可視化 實驗2的結果表明TypeNet II模型中,特征序列的表征向量差的絕對值可以用來判斷特征序列是否屬于同一被試者。比較層和決策層的輸出呈非線性關系,用多元二項式模擬該關系可達到92%以上的準確率。整體上,多元二項式系數大的項對應的比較層的維度的取值大于其他維度,且分布較為分散。說明這些維度的值對決策層的輸出的影響較大。但要注意,多元二項式某項的系數大并不一定意味著該項對應的維度對決策層的影響大,因為有可能該維度值始終為0。 基于孿生網絡的TypeNet模型采用歐氏距離度量特征向量在表征空間的相似度。由于表征空間每個維度沒有明確含義而缺乏可解釋性。和TypeNet不同,TypeNet II的分支使用單層LSTM,用多層感知機度量兩個分支輸出表征向量差的絕對值體現出來的輸入特征序列的相似度,其分類效果超過了現有方法。用多元二項式模擬TypeNet II模型中的多層感知機,爾后基于多元二項式,可以分析多層感知機輸入和輸出之間的關系,對模型作出的分類判斷進行解釋。本文下一步可以做以下幾個方面的工作:(1)結合一些特殊的擊鍵事件序列樣本,解釋TypeNet II模型如何消除特征序列的鍵值和長度差異對分類的影響;(2)嘗試用在自然語言任務中取得很大成功的transformer處理特征序列;(3)擊鍵行為特征在一些安全級別較高的領域得到了應用[17],但一般不作為獨立的身份認證或識別因子[18],可以將其作為基于口令的認證密鑰交換協議[19,20]的安全增強,從而降低口令遭受猜測和字典攻擊的風險。3.1 TypeNet II模型




3.2 決策層的多元多項式回歸

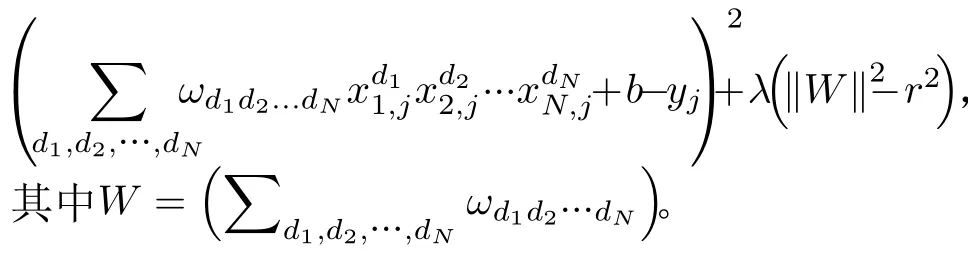
4 實驗及結果
4.1 實驗1







4.2 實驗2







4.3 結果分析
5 結束語
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
