基于全球AIS的多源航跡關聯數據集
2023-03-01 08:20:46崔亞奇徐平亮余舟川張建廷于洪波
電子與信息學報 2023年2期
崔亞奇 徐平亮* 龔 誠 余舟川 張建廷 于洪波 董 凱
①(海軍航空大學信息融合研究所 煙臺 264001)
②(91001部隊 北京 100000)
③(91977部隊 北京 100000)
1 引言
多源航跡關聯問題在雷達數據處理領域中普遍存在,其中也包含中斷航跡接續關聯問題,并且有著較長的研究歷史,是目標跟蹤[1]、態勢感知[2]、信息融合[3]的前提和基礎。中斷航跡可以表述為:在對目標進行跟蹤的過程中,受目標機動、平臺機動、長采樣間隔、低探測概率等多種因素影響,存在大量的航跡中斷現象,即目標的當前航跡突然消失,一段時間后又在臨近區域重新起始跟蹤一條新的航跡。多源航跡可以表述為:在對目標進行跟蹤的過程中,經過不同傳感器的觀測,上報了對同一目標的多個航跡,各個航跡包含不同的系統誤差和隨機誤差。對于這兩種航跡關聯問題,傳統方法需要預先假定目標的運動模型,利用目標的先驗信息,采用統計估計理論對待關聯航跡進行復雜計算完成關聯任務[4–8],存在假設不合理、先驗信息難以獲取、門限無法確定等問題。
近年來,隨著人工智能和深度學習技術的快速發展,有學者提出采用基于深度學習的數據驅動方法完成航跡關聯任務,利用神經網絡提取航跡的運動特征、中斷特征、多源誤差特征等信息,通過損失函數對高維空間中的航跡特征進行約束,實現從航跡數據到關聯結果的映射[9–11]。與傳統方法相比,深度學習方法可以基于實測航跡數據,自動訓練航跡關聯模型,有效避免了人工對模型的選取、目標運動參數的設置、目標先驗信息的采集分析等大量調試操作,具有關聯速度快、關聯精度高、泛化能力強等優點。
然而,采用深度學習方法實現航跡關聯任務,其網絡訓練必須依賴大量的航跡數據。以上研究均基于仿真數據或采集到的少量真實數據,缺乏一個統一的、規范的、規模大的航跡關聯數據集。在深度學習發展較為成熟的領域,均有相關的高質量數據集作為支撐,例如圖像分類中的ImageNet數據集[12]、目標檢測和分割的PASCAL-VOC數據集[13]和COCO數據集[14]、遙感圖像分類的AID數據集[15]、遙感圖像檢索的RSICD數據集[16]、自動駕駛的KITTI數據集[17]、各類醫學影像數據集[18–20],等等。可以說,在深度學習領域,數據逐漸達到了與模型和算法同等重要的程度,必須有統一的、規范的、規模大的高質量數據集,才能為某一相關研究的發展提供基本保障。但是,航跡關聯數據集在國內外的構建還是一個空白,航跡關聯數據集的缺失成為制約基于數據驅動的航跡關聯研究的主要因素。因此,構建一個與航跡關聯任務相適應的數據集對相關研究的發展具有重要意義。
考慮到智能關聯算法研究的迫切需求和多雷達協同觀測航跡數據獲取困難,針對航跡關聯數據集缺失問題,該文公開了多源航跡關聯數據集(Multisource Track Association Dataset, MTAD),其由全球自動識別系統(Automatic Identification System, AIS)航跡數據經柵格劃分、自動中斷和噪聲添加處理步驟構建。該數據集包括訓練集和測試集兩大部分,共有航跡百萬余條,其中訓練集包含5000個場景樣本,測試集包含1000個場景樣本,每一個場景樣本由幾個到幾百個數量不等的航跡構成,涵蓋多種運動模式、多種目標類型和長度不等的持續時間。同時,進一步對構造的MTAD數據集進行可視化分析,詳細研究了各個柵格內航跡的特點,證明了該數據集的豐富性、合理性和有效性。最后,作為參考,給出了關聯評價指標和關聯基線結果。
2 數據集構建
船舶自動識別系統是一種廣播式的艦載應答系統,該系統能夠使船舶在公用無線信道上向附近的船舶和岸上的監測部門持續發送自身的身份、位置、航向、航速等數據[21]。AIS系統具有定位精度高、船舶編碼唯一、自控時分多址聯接(SOTDMA)、電子海圖等特點,為艦船目標識別[22,23]、艦船目標跟蹤[24,25]、加強海事管理[26,27]等應用提供了可靠技術保障,在軍用和民用領域均有廣泛應用。由于其廣播式的數據發送特點,與雷達航跡數據相比,AIS航跡數據具有分布廣泛、獲取難度低和時效性好的優點,因此這里采用全球AIS數據,構建多源航跡關聯數據集。
2.1 AIS數據特征信息
MTAD數據集采用的基礎AIS數據特征包括目標的用戶識別碼(MMSI碼)、時間(UNIX時間戳,單位:s)、緯度(l/10000°,±90°,北為+,南為–)、經度(1/10000°,±180°,東為+,西為–)、航速(單位:kn)、航向(單位:(°))。利用以上基礎特征通過添加中斷和多源誤差構造MTAD數據集。
2.2 全球AIS可視化分析
全球柵格是MTAD數據集構建的基礎,數據集中的所有場景均從全球柵格中抽取產生,因此柵格中的航跡質量對于MTAD數據集的質量至關重要。為了分析全球柵格航跡信息,在全球地圖中根據所有柵格中的MMSI數量繪制熱力圖,對MMSI數量進行可視化,結果如圖1所示。從圖1可以看出,在重要港口地帶,MMSI數量較多,在遠海區域,MMSI數量較少。各航跡在全球各個海域均廣泛分布,為數據集的構建提供了豐富的航跡資源。

圖1 MMSI數量熱力圖
之后,進一步分析MMSI數量的分布情況。以柵格內MMSI數量為橫軸,柵格所占比例為縱軸,繪制柱狀圖,如圖2所示。從圖2(a)可以看出,全球絕大多數柵格中的MMSI數量在300個以下,但也存在一些柵格中的MMSI數量達到了2000個以上。為了更細致地分析MMSI數量在0~300個的柵格比例,將MMSI數量在0-300個的柵格重新繪制其柱狀圖,如從圖2(b)所示。圖2(b)可以看出,在MMSI在0~300個的各個分段均有柵格分布,全面的AIS航跡庫為稀疏場景、普通場景、密集場景的構建提供了豐富的航跡資源。

圖2 MMSI數量分布柱狀圖
2.3 整體思路
航跡關聯數據集包括多個關聯場景樣本,每個關聯樣本包括信源航跡CSV文件和關聯映射表CSV文件,信源航跡CSV文件包括兩個信源的多條航跡,兩個信源可設置為艦載雷達、機載雷達或岸基雷達等不同類型。
關聯樣本生成流程如圖3所示,包括參數設置、基于空間柵格的真值航跡抽取和信源航跡生成等3個步驟。
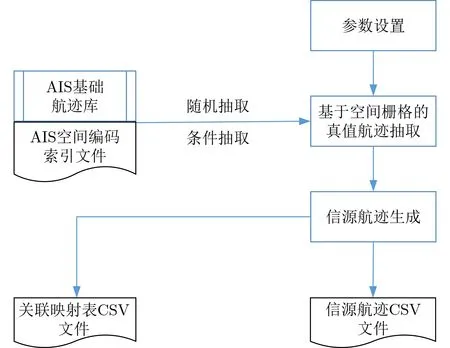
圖3 關聯樣本生成流程圖
2.4 參數設置
參數設置包括場景設置、目標設置和信源設置。
2.4.1 場景設置場景設置主要對柵格精度和場景中心經緯度進行設置。其中柵格精度α,用于全球柵格劃分,表示對全球經緯度劃分的最小間隔;場景中心經緯度W0,用于后續空間柵格的平移。
2.4.2 目標設置

2.4.3 信源設置
信源設置主要對信源1和信源2的探測特性進行設置。主要參數包括更新周期、目標發現概率、航跡開始時間范圍、航跡結束時間范圍、最小持續時間、中斷頻率、中斷時間范圍、位置系統偏差、航跡質量噪聲(高斯噪聲或瑞利噪聲)。
2.5 基于空間柵格的真值航跡抽取
基于空間柵格的真值航跡抽取包括AIS基礎航跡庫構建和真值航跡抽取兩個步驟。
2.5.1 AIS基礎航跡庫構建
AIS基礎航跡庫的構建步驟為:
(1)從AIS數據文件中,按照MMSI號對單個目標航跡進行抽取,存為CSV文件,文件名為MMSI號。
(2)對單個目標航跡進行預處理,包括拆分長時間未更新航跡,刪除靜止、速度過低航跡,刪除采樣點跳變航跡,刪除過短航跡。
(a)拆分長時間未更新航跡。航跡的更新時間每大于600 s就將航跡截斷一次,直至航跡結束。具體實施步驟為:
①設置初始索引I Ds=0 , 終止索引I De=0;
②遍歷航跡中的每個采樣點,計算后一采樣點與前一采樣點之間的時間差?T=Te?Ts, 并令IDe等于后一采樣點對應的索引;
③如果前后兩個采樣點的時間差 ?T>600 s,保存[ IDs,IDe] 之 間的航跡,并設置I Ds=IDe+1;
④重復①—③,直到航跡結束,并保存[IDs,IDe]之間的航跡。
(b)刪除靜止、速度過低航跡。對(a)中保存的航跡進行處理,若平均航速小于等于1,且經度最大值減經度最小值小于等于0.5,且緯度最大值減緯度最小值小于等于0.5,該航跡不保存。約束條件如式(3)所示。

(c)刪除采樣點跳變航跡。對(b)中保存的航跡進行處理,遍歷航跡中的每個采樣點,若前后兩點之間經度差的絕對值大于0.5,或緯度差的絕對值大于0.5,該航跡不保存。約束條件如式(4)所示。
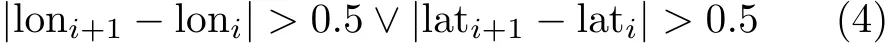
其中,∨表示或操作。
(d)刪除過短航跡。對(c)中保存的航跡進行處理,只保存航跡采樣點數大于30且持續時間大于300 s的航跡,分別命名為MMSI_0, MMSI_1, ···,約束條件如式(5)所示。


(4)統計每個柵格內的MMSI號、航跡數量、目標數量、航向方差均值、航速方差均值、目標密集程度、目標機動程度,并以CSV格式,存為AIS空間編碼索引文件,每個空間柵格一行,具體格式為{空間柵格緯度索引、空間柵格經度索引、航跡數量、目標數量、航向方差均值、航速方差均值、目標密集程度、目標機動程度、MMSI號序列}。
2.5.2 真值航跡抽取
真值航跡抽取包括兩種模式,一是隨機抽取,二是條件抽取。其中隨機抽取為對空間編碼進行隨機抽取,然后根據AIS空間編碼索引文件,得到柵格內所有的MMSI號,然后得到真值航跡。
條件抽取為根據設定的目標密集程度和目標機動程度,選取與設定密集程度和機動程度最相似的空間柵格,或者從多個相似的空間柵格中進行抽取。
2.6 信源航跡生成
(1)首先以抽取的柵格內AIS航跡Z0為真值,根據場景中心經緯度W0和信源參數,依次生成信源1和信源2兩個信源航跡,具體步驟如下:
(a)根據場景中心經緯度W0,對柵格內AIS航


(d)目標發現概率處理。根據設置的目標發現概率(可設置為0.8或0.9),對柵格內全部AIS航跡進行隨機抽取,得到信源的探測航跡索引I1。如果抽取后信源的航跡個數為0,則重新抽取。
(e)航跡插值處理。根據柵格內AIS真值航跡Z0和信源的探測航跡索引I1,對索引內的每條航跡,除第1個時間點和最后1個時間點外,將航跡的持續時間以信源的更新周期Ts為斷點進行分割,在每個時間點添加隨機誤差,然后進行插值(插值方法可以選擇最近鄰插值、階梯插值、線性插值、B樣條曲線插值等),得到信源的探測航跡Z1。

從而實現將航跡中斷為nB段 。
(g)設置批號。記錄信源航跡與真值航跡的對應關系,然后對信源的所有航跡進行隨機編號,得到其航跡批號。
(h)添加系統誤差。根據設置的系統偏差(es1~es2,單位為(°)),采用均勻分布的形式,對每個航跡的經度、緯度位置添加系統誤差。信源1不添加系統誤差,信源2的系統誤差以50%的概率服從U (?0.03,?0.01) 或U (0.01,0.03),單位為(°)。
(i)添加隨機誤差。根據設置的航跡質量(1~15),按照高斯分布(或瑞利分布),對每個航跡經度、緯度位置添加隨機誤差。其中,航跡質量表示航跡的隨機誤差,分為1~15個級別,級別越高,誤差越小,每個級別對應航跡隨機誤差的標準差,基于直角坐標系計算,單位為m。由于該數據集是基于經緯度添加誤差,而直角坐標系和地理坐標系之間的轉換是非線性的,因此需要對航跡質量進行變換,將原有的直角坐標系標準差變為場景中心附近的經緯度標準差,再添加到數據當中。
(j)根據每個航跡經度和緯度,計算得到航速和航向,進而得到每個航跡的信息Z3,包括{航跡批號、信源號(9001, 9002,隨機設置)、時間(一天內的絕對秒)、經度(°)、緯度(°)、航速(kn)、航向(°)}。
(k)同時生成關聯映射表,多個{開始時間-結束時間-真值批號-信源號-航跡批號}列構成的表。
(2)對兩信源的關聯映射表進行混合,按開始時間進行排序,設置新的航跡批號,重新編批,存為關聯映射表CSV文件。
(3)對兩信源的航跡信息進行混合,并按時間進行排序,根據關聯映射表中,重新編批,存為信源航跡CSV文件。
綜上,在生成信源航跡時所需的參數有信源1的更新周期Ts1、 信源2的更新周期Ts2、場景中心W0、 目標發現概率Pd、航跡質量Q,總結如表1所示。

表1 生成信源航跡時所需的參數表
3 數據集展示與分析
3.1 柵格可視化與分析
將AIS航跡劃分到全球柵格中,是后續生成中斷航跡和多信源航跡的前提和基礎。由于數據集中的航跡均由柵格航跡抽取得到,所以柵格中航跡質量的好壞程度將直接影響生成數據集的質量。本節對劃分到全球柵格的AIS數據進行可視化,包括MMSI數量可視化、目標數量可視化、密集程度可視化、機動程度可視化,分析柵格內航跡的全面性和有效性。
3.1.1 目標數量可視化
在2.5.1節中,由于對超過600 s的長時間未更新航跡進行了截斷處理,導致一條航跡分成了多個目標,因此目標數量與MMSI數量并不相同,故有必要對目標數量進行可視化分析。在全球地圖中根據所有柵格中的目標數量繪制熱力圖,對目標數量進行可視化,結果如圖4所示。從圖4可以看出,與MMSI數量可視化結果相似,在重要港口地帶,目標數量較多,在遠海區域,目標數量較少。各航跡在全球各個海域均廣泛分布,為數據集的構建提供了豐富的航跡資源。

圖4 目標數量熱力圖
之后,進一步分析目標數量的分布情況。以柵格內目標數量為橫軸,柵格所占比例為縱軸,繪制柱狀圖,如圖5所示。從圖5可以看出,全球絕大多數柵格中的目標數量在300個以下,但也存在一些柵格中的目標數量達到了2000個以上,全面的AIS航跡庫為稀疏場景、普通場景、密集場景的構建提供了豐富的航跡資源。

圖5 目標數量分布柱狀圖
3.1.2 密集程度可視化
如式(1)所示,柵格的目標密集程度反映了某一柵格內的目標數量的大小在總的柵格中的比重,其對數據集的構建具有較高的重要性。在全球地圖中根據所有柵格中的目標密集程度繪制熱力圖,對目標密集程度進行可視化,結果如圖6所示。從圖6可以看出,重要港口城市附近的目標密集程度較高,遠洋目標的密集程度較低,因此在對算法進行測試驗證時,可以根據對算法的使用場景需求,選擇密集柵格或稀疏柵格構建測試場景。
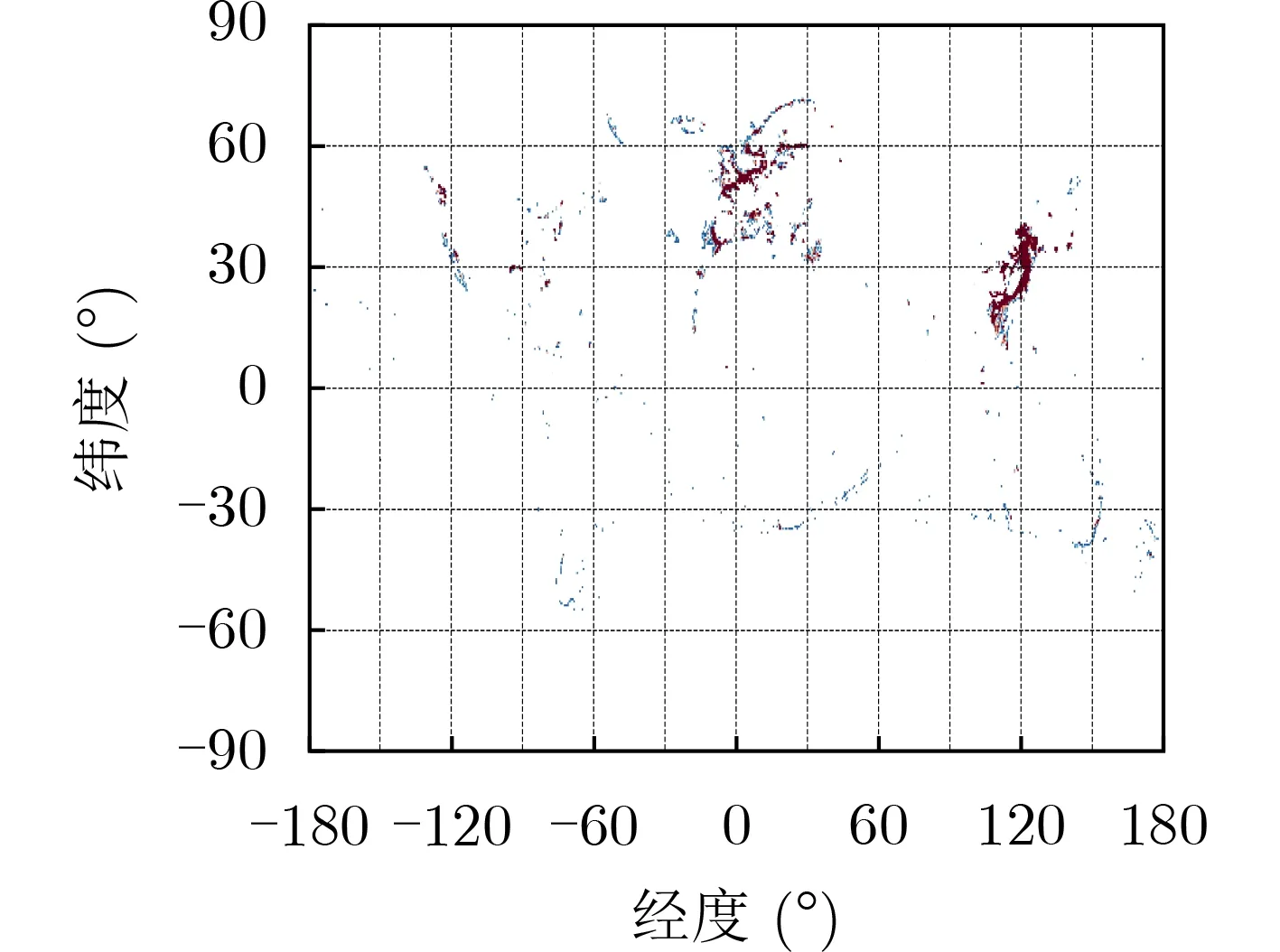
圖6 目標密集程度熱力圖
3.1.3 機動程度可視化
如式(2)所示,柵格的目標機動程度反映了某一柵格內的目標航速和航向標準差的大小在總的柵格中的比重,其對數據集的構建具有較高的重要性。在全球地圖中根據所有柵格中的目標機動程度繪制熱力圖,對目標機動程度進行可視化,結果如圖7所示。
從圖7可以看出,復雜航道和航道轉彎處的目標機動程度較大(例如圖中的重要港口城市附近),航道的直行區域目標機動程度較小(例如圖中的遠海區域),能夠滿足對于較大機動目標場景的構建需求。

圖7 目標機動程度熱力圖
之后,進一步分析目標機動程度的分布情況。以柵格內目標機動程度為橫軸,柵格所占比例為縱軸,繪制柱狀圖,如圖8所示。從圖8可以看出,有96%以上的目標其機動程度在0.5以下,表明大多數海面目標沒有進行特大機動運動。運動機動程度在0至0.7均有目標分布,為不同的場景構建提供了充足的數據保證。

圖8 目標機動程度分布柱狀圖
3.2 典型場景展示與分析
為了說明數據的豐富性、合理性、有效性,本節從數據集中抽取一組典型的航跡數據進行展示,給出其經緯度的可視化結果,同時還有其時間-緯度圖像和時間-經度圖像,用來說明“航跡共存時間處理”的有效性。典型場景如圖9所示,從上至下依次為航跡圖像、時間-緯度圖像、時間-經度圖像,其中紅色航跡為信源1觀測到的航跡,信源號為9001;藍色航跡為信源2觀測到的航跡,信源號為9002。
從圖9可以看出:
(1)整體上,航跡運動類型豐富,包括各種機動狀態以及各種密度場景,沒有靜止航跡、速度低航跡、過短航跡、跳變航跡。所有場景中心經緯度均為(20°, 30°),符合預期設置要求。比較時間-緯度圖像和時間-經度圖像可知,每個場景中均存在同時空航跡交叉現象,與實際情況相符,證明了“航跡共存時間處理”的有效性。
(2)中斷航跡方面,每個場景中均至少存在一條中斷的航跡,且兩個信源之間航跡的中斷位置、中斷時刻、中斷間隔、中斷目標數量不一致,證明了航跡中斷設置的合理性,符合實際要求。
(3)多源航跡方面,比較圖9中9001信源(紅色)和9002信源(藍色)的航跡,可以發現存在明顯的多源觀測現象。由于設置了目標發現概率,所以兩個信源觀測到的航跡數量不一致,符合實際要求。兩信源觀測得到的航跡起始點和終止點不一致證明了“航跡起始與終結時刻處理”的有效性。

圖9 典型場景展示
4 關聯評價指標和基線結果
為了明確關聯的評價標準并為研究人員提供對比參考的依據,本節提供一種關聯評價標準并在該標準下給出數據集訓練場景和測試場景的基線結果。
4.1 關聯評價指標
首先,對關聯指標中需要的重要變量進行定義。
定義1 實際應能關聯對AP
實際應能關聯對 AP 定義為根據關聯映射表,存在關聯關系,且滿足以下條件的關聯對:對于中斷關聯,兩條航跡的中斷時間間隔小于20 min,兩條航跡各自持續時間大于2 min;對于多源關聯,兩條航跡段的相交時間大于2 min。
定義2 實際應能關聯對集合TAP
實際應能關聯對集合TAP定義為由場景中所有實際應能關聯對 AP構成的集合。
定義3 關聯對輸出集合OAP
關聯對輸出集合OAP定義為由航跡關聯算法輸出的航跡關聯對構成的集合,包括中斷航跡關聯和多源航跡關聯對。
定義4 關聯對集合的模
關聯對集合的模定義為該關聯對集合中的關聯對的個數,用“|?|”表示。
關聯指標包括關聯正確率和關聯錯誤率,在計算過程中同時考慮中斷航跡關聯和多源航跡關聯,兩個指標可以根據定義的重要變量按照如下公式進行計算。
定義5 關聯正確率PCA
關聯正確率PCA定義為關聯對輸出集合OAP中屬于實際應能關聯對的個數與實際應能關聯對集合TAP中關聯對的個數之間的比值。
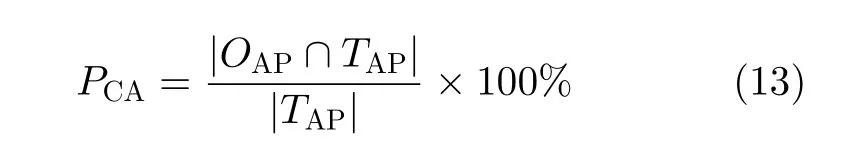
定義6 關聯錯誤率PFA

4.2 關聯基線結果
根據4.1節定義的關聯評價指標,本節給出了基于最近鄰距離的航跡關聯算法的關聯基線結果。
4.2.1 算法描述
基于最近鄰距離的航跡關聯算法通過計算并比較不同航跡之間的距離,選擇最近鄰(距離最小)的航跡對作為關聯結果,其關聯步驟如下:
(1)針對多源航跡關聯
步驟1:初始化距離矩陣D=(di,j)N1×N2和關

其中,L為參與計算的航跡點數,D為參考屬性個數,xdi(l)表 示信源1的第i個 航跡的第l個采樣點的第d維屬性,xdj(l)表 示信源2的第i個 航跡的第l個采樣點的第d維屬性。
步驟3:選擇距離矩陣D中的最小元素,將關聯矩陣A中對應位置元素設為1;
步驟4:將距離矩陣D中最小元素對應的行和列的所有元素設置為正無窮;
步驟5:重復步驟3和步驟4,直到距離矩陣D中的所有元素均為正無窮;
步驟6:根據關聯矩陣進行關聯判決,遍歷關聯矩陣中的所有元素,若該元素值為1,即ai,j=1,則信源1的第i個元素和信源2的第j個元素關聯,否則,不關聯。
(2)針對中斷航跡關聯
步驟1:初始化距離矩陣D=(di,j)N×N和關聯矩陣A=(ai,j)N×N,距離矩陣內元素為正無窮,關聯矩陣內元素為0,其中N表示待關聯信源觀測到的航跡個數;
步驟2:遍歷待關聯信源的所有航跡,設當前航跡索引為i,將其設為老航跡,再遍歷待關聯信源的所有航跡,設當前航跡索引為j,將其設為新航跡,若新航跡的開始時間大于老航跡的結束時間且新、老航跡索引不相同,則計算航跡i和 航跡j之間所有參考屬性的歐氏距離的平方,作為距離矩陣的第i行 第j列元素;

步驟3:選擇距離矩陣D中的最小元素,將關聯矩陣A中對應位置元素設為1;
步驟4:將距離矩陣D中最小元素對應的行和列的所有元素設置為正無窮;
步驟5:重復步驟3和步驟4,直到距離矩陣D中的所有元素均為正無窮;
步驟6:根據關聯矩陣進行關聯判決,遍歷關聯矩陣中的所有元素,若該元素值為1,即ai,j=1,則待關聯信源的第i個老航跡和第j個新航跡關聯,否則,不關聯。
根據基于最近鄰距離的航跡關聯算法可以看出,多源關聯和中斷關聯的核心都是比較航跡之間的距離,選出最近鄰航跡對作為關聯結果。其區別在于多源關聯的距離計算考慮的是不同源之間的航跡,而中斷關聯的距離計算考慮的是同源航跡。
4.2.2 關聯結果
為了便于研究人員的對比和參考,將多源關聯和中斷關聯的基線關聯結果分開表述,多源關聯基線結果如表2所示,中斷關聯基線結果如表3所示。表中的關聯正確率和關聯錯誤率均為各類數據集中所有場景的平均值。

表2 多源關聯基線結果(%)

表3 中斷關聯基線結果(%)
從表2和表3可以看出,采用基于最近鄰距離的航跡關聯方法,對于多源關聯任務可以取得較好的關聯結果,但對于中斷關聯任務,由于中斷前后新老航跡位置相差較大,且與周圍臨近航跡相互干擾,關聯效果急劇下降。并且,基于最近鄰距離的航跡關聯方法在兩種關聯任務中都具有較高的關聯錯誤率,表明其關聯結果可靠性較低,亟需對關聯算法進行進一步研究和改善。
5 結論
目前,在航跡關聯領域由于缺乏一個統一的、規范的、規模大的航跡關聯數據集,導致基于深度學習數據驅動的航跡關聯研究受到制約,難以滿足模型訓練和實驗對比的需求。考慮到智能關聯算法研究的迫切需求和多雷達協同觀測航跡數據獲取困難,針對航跡關聯數據集缺失問題,該文公開了多源航跡關聯數據集(MTAD),其由全球AIS航跡數據經柵格劃分、自動中斷和噪聲添加處理步驟構建。該數據集包括訓練集和測試集兩大部分,共有航跡百萬余條,其中訓練集包含5000個場景樣本,測試集包含1000個場景樣本,每一個場景樣本由幾個到幾百個數量不等的航跡構成,涵蓋多種運動模式、多種目標類型和長度不等的持續時間。同時,進一步對構造的MTAD數據集進行可視化分析,詳細研究了各個柵格內航跡的特點,證明了該數據集的豐富性、合理性和有效性。最后,作為參考,給出了關聯評價指標和關聯基線結果。
猜你喜歡
北京測繪(2022年6期)2022-08-01 09:19:06
師道·教研(2022年1期)2022-03-12 05:46:47
云南化工(2021年8期)2021-12-21 06:37:54
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
北京測繪(2021年7期)2021-07-28 07:01:18
海洋信息技術與應用(2020年1期)2020-06-11 12:43:56
當代陜西(2019年15期)2019-09-02 01:52:00
傳媒評論(2019年4期)2019-07-13 05:49:14
學苑創造·A版(2018年11期)2018-02-01 06:29:20
