長短時記憶脈沖神經網絡手語識別模型
2023-03-03 03:15:37馮一飛王青山
合肥工業大學學報(自然科學版) 2023年11期
馮一飛, 王青山
(合肥工業大學 數學學院,安徽 合肥 230601)
0 引 言
據世界衛生組織2017年的統計,全球大約有5.5%的人遭受聽力損失的困擾,合計人口達到4.66億,僅在中國就有2 780萬聽障人士。手語是聽障人士最重要的交流方式,然而對于沒有專門學習過手語的健全人來說,手語是一種難懂的語言,這使得聽障人士和健全人之間形成溝通障礙[1]。溝通障礙一方面影響了聽障人士的工作、學習、娛樂等生活狀態;另一方面可能使他們形成自卑心理,不利于形成健全的人格。為了讓聽障人士更好地融入社會,越來越多的研究者開始關注手語識別問題。
目前,已經存在許多手語識別的形式,從采集信號的種類上看,有基于視覺圖像的方法[2-4]、基于WIFI的方法[5]和基于傳感器的方法[6-7];從采用的識別方法來說,有機器學習方法[8-9]和深度學習方法[10-11]等。基于視覺圖像的方法可以采集到手和面部的特征,往往在多目標的手語識別任務中表現更出色,然而由于需要借助攝像機采集圖像數據采集,難以在現實生活中普及。基于WIFI的方法可以采集到除了手和手臂以外身體其他部分的運動,但是對于比較細粒度的運動,比如手指的運動,會損失采集的精確性。基于傳感器的方法通過佩戴手環來采集手勢的肌電流和運動的慣性信號,無需通過攝像頭采集,采集到的手勢信號也更為精確。
目前,脈沖神經網絡(spiking neural network,SNN)[12]已經應用在一些深度學習的任務中,如模式識別[13-15]、強化學習[16]。脈沖神經網絡中的神經元更接近生物神經元的組成,它利用稀疏的脈沖來表示信息,而不像傳統人工神經網絡的神經元使用連續的變量表示信息。由于這種仿生的機制,脈沖神經網絡有潛力在使用更少神經元的情況下達到和人工神經網絡相似的性能[9],使得脈沖神經網絡非常適合實際的場景。另外,脈沖神經網絡可以在線學習,對復雜信號處理的魯棒性高于人工神經網絡[17]。然而利用脈沖神經網絡對手勢進行識別[13,18]工作較少,文獻[13]設計了預訓練脈沖神經子網,使得脈沖神經網絡的隱藏層數更深,對8種手勢進行識別。文獻[18]提出了深度卷積脈沖神經網絡,縮短了處理信號所需的時間,在2個8分類的手勢數據集上驗證網絡性能。它們識別的手勢規模較小,本文研究脈沖編碼和訓練方法來設計輕量級的脈沖神經網絡,對101個常用手語手勢進行識別。
本文提出了基于表面肌電流(surface electromyography,sEMG)手語識別模型,該模型由輕量級長短時記憶脈沖神經網絡(long short-term memory-spiking neural network,LSTM-SNN)組成。在模型中設計自適應脈沖編碼對輸入的手語信號進行編碼,改進帶泄漏整合發放(leaky integrate-and-fire,LIF)神經元模型進行網絡訓練,最后通過實驗來比較該模型與其他深度學習和機器學習模型的準確率等方面的性能。
1 模型設計
手語識別系統框架如圖1所示,首先使用MYO手環采集數據得到原始手語sEMG信號,然后將sEMG信號經過自適應脈沖編碼后獲得脈沖信號,脈沖信號作為LSTM-SNN的輸入,通過時間驅動方式訓練神經元中的參數,由全連接層對特征向量進行識別分類,最后由LSTM-SNN中的softmax層輸出手語分類的結果。
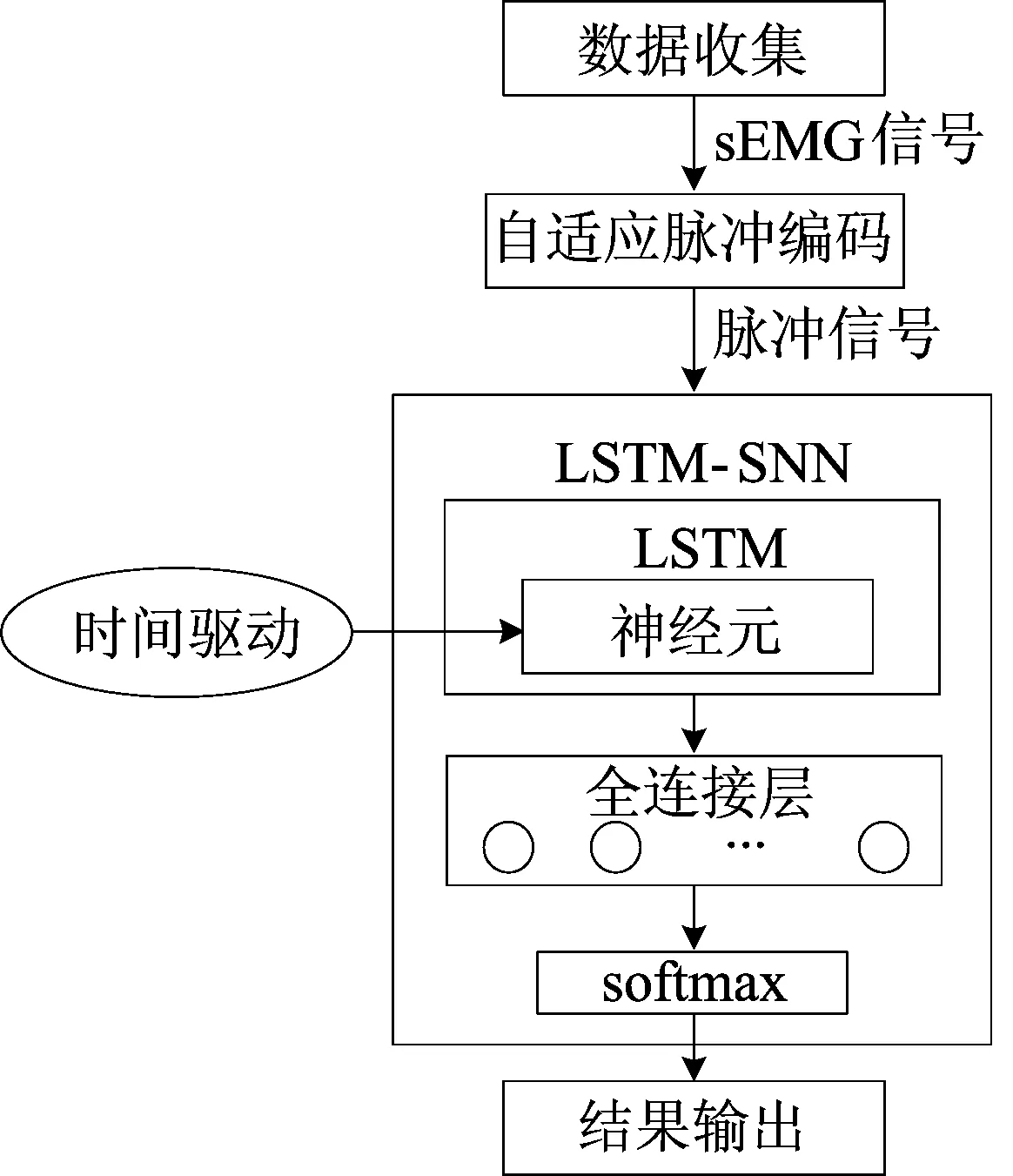
圖1 手語識別系統框架
1.1 脈沖編碼
脈沖編碼過程主要是將輸入信號轉化為脈沖信號,從而產生脈沖網絡的輸入。本文設計了一種自適應脈沖編碼來對手語信號編碼,其主要思想是通過計算當前時刻編碼手語信號前后變化信息進行自適應脈沖編碼。
對給定的手語信號X=(x1,x2,…,xT),其中,xt∈R,1≤t≤T,T為信號的幀數,經過脈沖編碼得到的序列為Y=(y1,y2,…,yL),其中,yl∈{0,1},1≤l≤L,L為脈沖序列長度,一般來說L=T。因為產生脈沖的原因是在膜電位形成了電位差,即該時刻產生的電壓變化較大,所以本文根據信號的變化程度進行脈沖編碼。當信號變化程度越大,發射脈沖的時間就越早。標準脈沖的發放時間表示為:
tf(zt)=(T-1)(1-xt)
(1)
其中:T為脈沖最大的發放時長;xt為當前時刻的輸入,且xt∈[0,1)。本文設計的自適應脈沖編碼思想,如圖2所示。
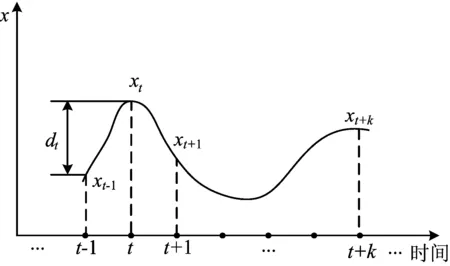
圖2 自適應脈沖編碼
1) 計算手語信號在當前時刻(2≤t≤T)與上一時刻t-1的差值dt=|xt-xt-1|。假設上述差值中最大值為dmax(2≤max≤T),通過dt/dmax將dt映射到[0,1]之間。


(2)
由式(2)可知,如果Rt≤RT,說明當前時刻t后k幀的信號變化較小,那么可以推遲脈沖發放的時間;反之,則盡早發放脈沖。
1.2 LIF神經元與時間驅動訓練方式
本文使用帶泄漏整合發放神經元模型來實現脈沖神經網絡中信息的傳遞。該模型主要模擬生物體內神經元突觸之間的信息傳遞方式,通過不斷地充電和放電來產生脈沖信號,這種方式被稱為時間驅動方式。
神經元的信息傳輸過程主要分為充電、放電和復位。充電和放電的具體過程分別用以下公式表達,具體計算公式如下:
Ht=Vt-1+Δvt
(3)
(4)
在充電的表達式(3)中;Ht為t時刻神經元未發放脈沖的瞬時電壓;Vt-1為上一個時刻t-1的電壓;Δvt為t時刻的電壓增量。在放電的表達式(4)中:θt表示是否產生了脈沖;如果Ht超過閾值Vthreshold,那么就會產生一個脈沖,隨后膜電位會立即回到一個靜息電位,此過程叫做復位;反之,不產生脈沖。
本文采用當前膜電位減去閾值Vthreshold的方式來復位,這樣膜電位在充電的過程中不需要從0開始增長,提高了脈沖放電的效率。具體的復位方式如下:
Vt=Ht-Vthresholdθt
(5)
其中,Vt為t時刻的電壓。
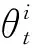
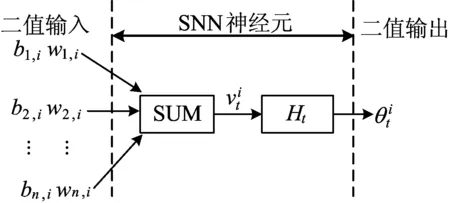
圖3 脈沖網絡的神經元
1.3 LSTM-SNN手語識別模型
長短時記憶網絡是一類特殊的循環神經網絡(recurrent neural networks,RNN),能夠為信號的時間依賴性建模,同時解決了循環神經網絡結構面臨的梯度消失問題[19]。因為肌電流信號是時間序列信號,所以本文選擇了長短時記憶網絡來捕捉脈沖神經網絡中信號的時間依賴性。長短時記憶脈沖神經元工作原理如圖4所示。
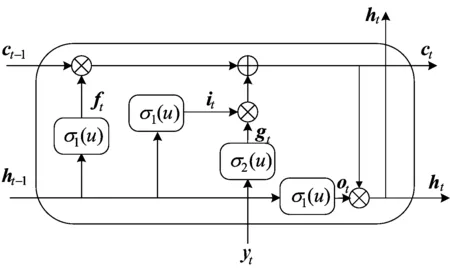
圖4 長短時記憶脈沖神經元工作原理
長短時記憶脈沖神經元與長短時記憶網絡神經元一樣,都使用了細胞狀態ct來管理神經元之間信息的傳遞。ft是遺忘門,決定了哪些信息會保存;it是輸入門,控制了輸入單元的信息和另一個輔助的輸入gt,gt由另一個脈沖激活函數來調節;ot是輸出門,形成下個神經元的輸入。具體來講,對于一組給定的脈沖序列(y1,y2,…,yL),長短時記憶脈沖神經網絡LSTM-SNN的門和狀態可以用如下方程描述:
(6)
其中:⊙代表Hadmard乘積;σ1、σ2為反應膜電位的脈沖激活函數,當函數值超過閾值時會產生脈沖。
2 實驗與結果
本文對所提的LSTM-SNN手語識別模型進行性能評價分析,具體包括實驗環境設置、LSTM-SNN性能、不同編碼方式對LSTM-SNN性能影響、LSTM-SNN與其他模型性能對比。
2.1 數據集
本文使用MYO手環采集肌電流數據,其包含8個表面肌電流傳感器,采樣頻率為200 Hz。將手環佩戴于前臂,可以采集到手部運動的信息,并通過藍牙設備傳輸到電腦,完成數據的收集。肌電流信號采集設備如圖5所示。
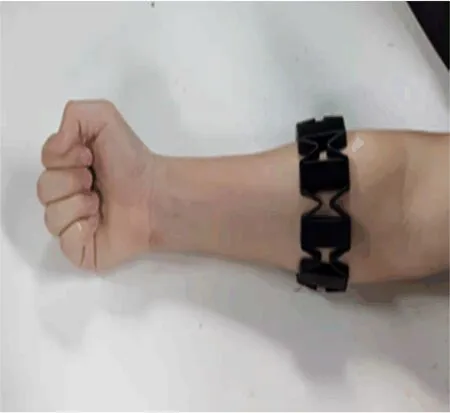
圖5 肌電流信號采集設備
本數據集包含101個日常生活中常見的手語手勢。該數據集由16位志愿者采集,包括8男8女,其中有4位手語老師和6位聽障學生,其余的志愿者也都經過了專業的手語訓練,可以熟練地使用手語。在本數據集中每個手語手勢有10個樣本,一共1 010個樣本,每種手勢中都包含了至少3位志愿者的手語樣本。
本文通過電腦端完成網絡的訓練,CPU是i7-9700F、32 GiB RAM,GPU采用NVIDIA RTX 2080Ti; 深度學習框架和訓練過程通過Pytorch完成。另外,本文應用深度學習框架驚蟄[20]搭建脈沖神經網絡。式(2)中的T設置為20。因為本文構建一個輕量級的網絡,所以網絡模型只設置了1層LSTM-SNN加1層全連接層,LSTM的隱藏層數量設置為128,訓練模型的epoch設置為800,batchsize為32,采用Adam作為優化器,優化器的學習率設置為0.001。
本文使用的評估指標包括準確率A(accuracy)、精確率P(precision)、召回率R(recall)和F1分數。準確率可以表現出模型對所有樣本的分類能力;精確率可以反映出模型對正樣本分類的能力;召回率反映模型對正樣本的誤判情況;F1為綜合考慮精確度和召回率的結果。這些指標經常被應用于分類任務中,作為評價模型性能的重要標準。
評估指標的計算公式如下:
(7)
(8)
(9)
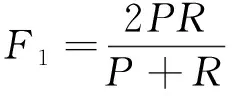
(10)
其中,Ntp、Nfp、Ntn、Nfn分別表示真陽性、假陽性、真陰性和假陰性樣本的個數。
2.2 LSTM-SNN性能分析
本實驗對101個手語手勢進行識別評價LSTM-SNN的性能,將數據集中的70%作為訓練集,30%作為驗證集,得到驗證集的準確率為95.37%、精確度為94.88%、召回率為94.53%、F1為94.70。這說明該模型可以正確分類大部分的樣本。進一步,本文對分類效果較差的16個手勢進行實驗分析其準確率,將模型輸出的維度調整為16,以16個手勢對應的160個樣本作為驗證集進行驗證,得到的混淆矩陣如圖6所示。
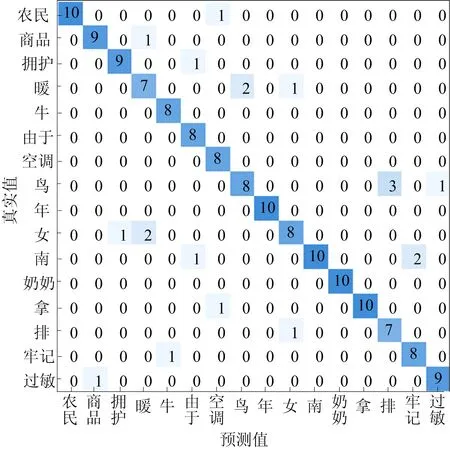
圖6 16個手語詞的混淆矩陣
由圖6可知,準確率為86.88%,說明模型在單獨分類這些樣本時效果并不差。從混淆矩陣的坐標軸中可以看出,這些手語在含義上并不相近,產生這種現象的原因可能是在這些手語手勢信號中有相似的肌電流信號,導致模型在分類時容易產生混淆。
2.3 編碼方式對LSTM-SNN性能的影響
本文將所提自適應脈沖編碼、常見的周期編碼和泊松編碼進行了性能比較,實驗結果見表1所列。從表1可以看出,采用自適應編碼在性能表現上都優于其他常見的編碼方式。
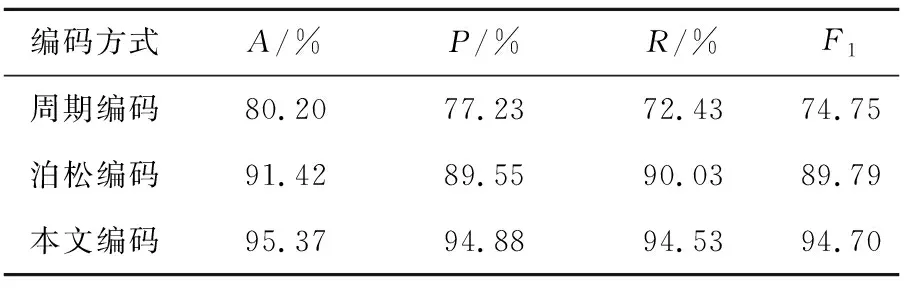
表1 不同編碼方式的性能比較
2.4 LSTM-SNN與其他模型性能對比
本文將所提模型LSTM-SNN同手語識別中現有的機器學習和深度學習模型進行性能比較,包括單層卷積神經網絡(convolutional neural networks,CNN)、單層長短時記憶網絡、單層全連接網絡(fully connected,FC)、多并行卷積神經網絡模型[21]、改進支持向量機(support vector machine,SVM)模型[22]和人工神經網絡模型[23]。另外,實驗還搭建并訓練了卷積脈沖神經網絡(CNN-SNN)和全連接脈沖網絡(FC-SNN),這些模型的搭建與長短時脈沖網絡的搭建類似,將其中的激活函數替換為LIF神經元,再使用自適應編碼和時間驅動方式進行訓練。這些模型的實驗結果見表2所列。
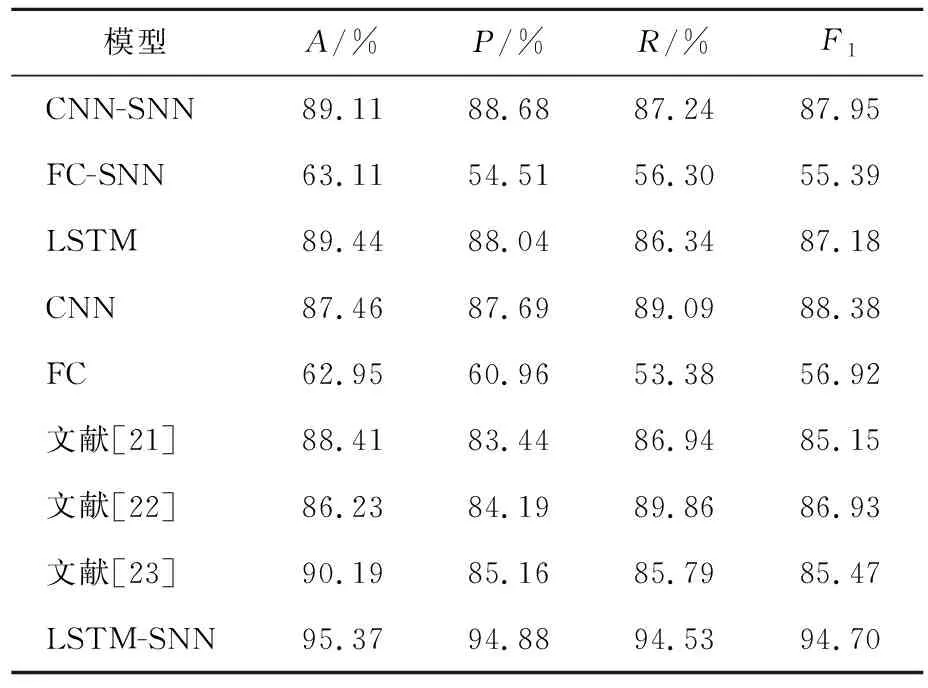
表2 不同模型的性能比較
從表2可以看出,所提模型LSTM-SNN在所有指標上性能最好。另外,傳統神經網絡LSTM、CNN和FC在采用脈沖神經元之后性能都有一定程度提升。
3 結 論
本文提出一種輕量級長短時記憶脈沖神經網絡模型,該模型對輸入信號設計了自適應脈沖編碼方法,改進了LIF模型進行網絡訓練,實現對101個手語手勢的識別。實驗結果表明,該模型在手語識別任務上較現有模型取得更高的準確率。本研究還有不足之處,例如,沒有探討手語識別實時性的問題,當手語數據集擴展后脈沖神經網絡系統的魯棒性問題,這些將在未來的工作中進行研究。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年3期)2019-02-01 06:12:26
光學精密工程(2016年6期)2016-11-07 09:07:19
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
海軍航空大學學報(2015年3期)2015-11-11 17:20:00
核科學與工程(2015年4期)2015-09-26 11:59:03
