小樣本圖像分類研究綜述
2023-03-10 00:10:20安勝彪郭昱岐白宇王騰博
計算機與生活 2023年3期
安勝彪,郭昱岐,白宇,王騰博
河北科技大學 信息科學與工程學院,石家莊050018
大規模標注數據集是深度學習成功的必要條件之一[1-4]。在現實世界的真實場景中,許多領域并不具有獲得大規模數據集的條件,這對于工作開展十分不便。也有一些領域,涉及到隱私、成本、道德等問題,也很難獲得高質量數據。例如,在醫療診斷領域,醫學圖像的來源是病例,而病例會因為隱私等問題獲取難度較大;在半導體芯片缺陷檢測領域,會面臨半導體芯片的型號不同和缺陷數據較少等問題。
為了解決諸多領域中數據有限和獲取難度較大的問題,小樣本學習(few-shot learning,FSL)[5-8]方法被提出。小樣本學習是指在訓練類別樣本較少的情況下,進行相關的學習任務。機器通過學習大量的基類(base class)后,僅僅需要少量樣本就能快速學習到新類(new class)。通常情況下,小樣本學習能夠利用類別中的少量樣本,即一個或者幾個樣本進行學習。例如,一個小朋友去動物園并沒有見過“黃鶯”這個動物,但是閱讀過有關動物書籍,書籍上有“黃鶯”的信息,通過學習書上的內容,小朋友就知道動物園中哪個動物是“黃鶯”。這是因為人們可以高效地利用以往的先驗知識,對現在的任務快速理解。人們這種快速理解新事物的能力,也是當前深度學習難以具備的。本文針對小樣本圖像分類問題介紹小樣本學習的相關技術,主要是介紹小樣本圖像分類。小樣本圖像分類的最終目的是達到人類的水平[9]。
小樣本圖像分類問題建模如圖1 所示。圖中將任務劃分為兩部分,訓練集(training set)也叫作支持集(support set),其中分為N個數據類別,每N個數據類別包括K個樣本,簡稱為N-wayK-shot 問題。測試集(test set)也叫作查詢集(query set),查詢集的類別屬于支持集中的類別。解決N-wayK-shot小樣本圖像分類問題,首先從輔助的數據集學習先驗知識[10],再在標注有限的目標數據集上利用已經學習的先驗知識進行圖像分類和預測。
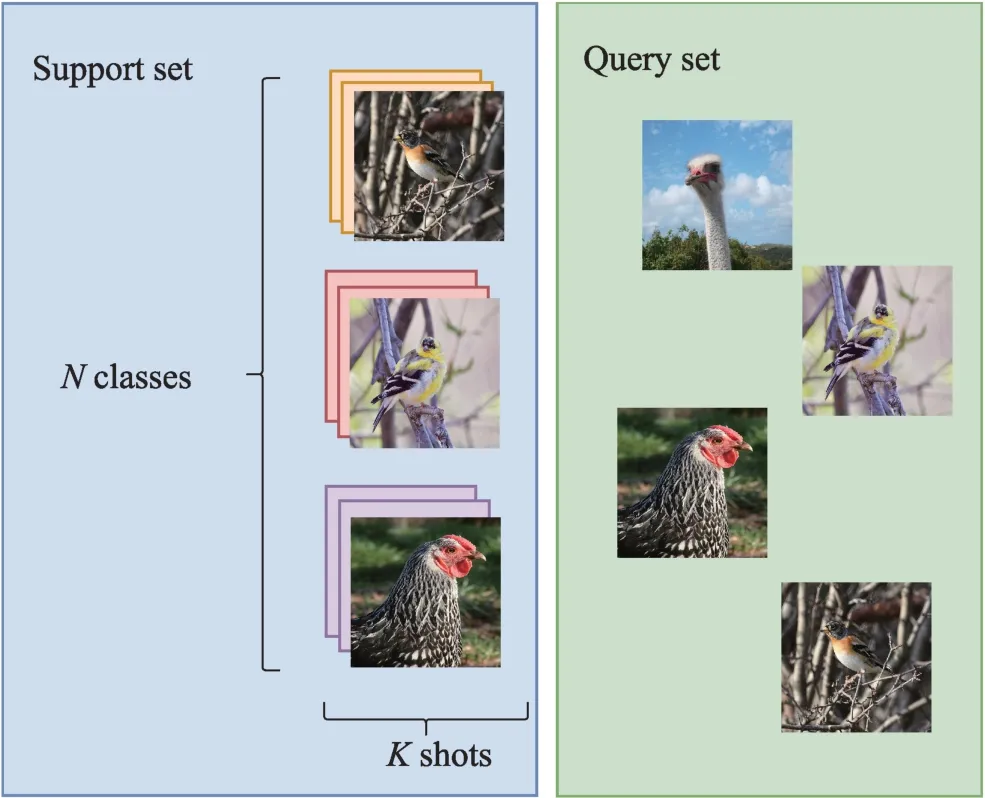
圖1 小樣本圖像分類示例Fig.1 Few-shot image classification example
目前已經有一些關于小樣本學習各方面的綜述。趙凱琳等人[11]從基于模型微調、數據增強和遷移學習的三個方向來介紹小樣本學習的方法,并且進行了歸納總結;劉春磊等人[12]將小樣本學習方法歸納為基于遷移學習的范式和基于元學習的范式,再按照改進策略的不同進行小樣本目標檢測綜述介紹;張振偉等人[13]從基于度量學習、數據增強、模型結構、元學習等六方面對小樣本目標檢測方法進行了總結分析。綜合近些年小樣本學習發展,元學習、度量學習和數據增強等深度學習方法已經逐漸成為解決小樣本圖像處理的主流方法。隨著無監督學習[14]、半監督學習[15]和主動學習[16]的興起和發展,很多研究者也將其應用到小樣本圖像分類問題中。與這些綜述[11-13]不同,本文首先將這些方法分為有監督、半監督和無監督三種范式,如圖2 所示,再按照各種情況的不同方法,從度量學習、元學習、偽標注、對比學習等角度進行歸納總結,對比分析了這些方法的性能表現,并總結了各自的核心思想以及使用領域。
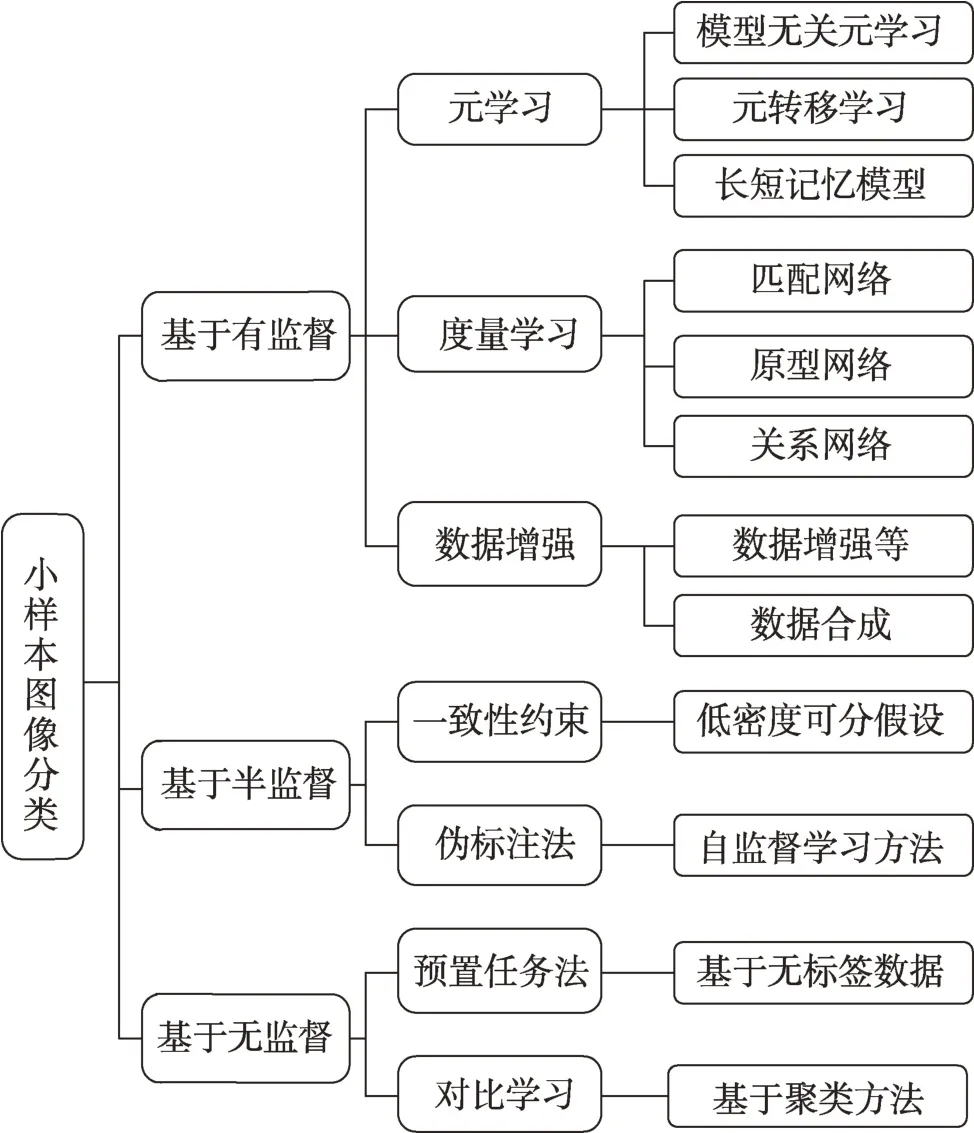
圖2 小樣本圖像分類方法Fig.2 Few-shot image classification methods
1 小樣本圖像分類框架及其數據集介紹
1.1 符號和定義
在標準FSL 場景中,一般需要建立兩個數據集:一個帶有Cbase類的基集和一個帶有Cnovel類的新集,其中Cbase∩Cnovel=?。Cbase是一個輔助數據集,目的是通過遷移學習來訓練分類器。Cnovel是執行任務分類的數據集。訓練通常在Cbase類上進行,其目標是將學到的知識遷移到基于Cnovel構建的新任務中。在測試期間,需要為每個任務都建立一個支持集S和一個查詢集Q。支持集S包含N個類,每個類有K個圖像。查詢集Q包括N×Q個未標記的圖像。在大多數文獻中,N設置為5,K設置為1 或5。
1.2 小樣本圖像分類方法
針對小樣本圖像分類任務,現有的基于小樣本圖像分類方法可以總結以下三類:(1)元學習[17];(2)度量學習[18];(3)數據增強[19-25]。
1.2.1 元學習
元學習也稱為learn to learn,利用以往的知識經驗指導新任務的學習,被廣泛應用在小樣本學習中。元學習通過既有數據集和元學習器跨任務提取的元知識來解決新任務。具體來說,元學習器逐步學習跨任務的通用信息(元知識),并且學習器使用特定于任務的信息將元學習器概括為新任務。
如圖3 所示,在小樣本學習中元學習將數據集劃分為訓練任務和測試任務。在訓練階段,通過對已有的數據進行隨機采樣,區分出支持集和查詢集,從而構造出多個不同的元任務。其中支持集用于訓練,查詢集用于驗證訓練階段的分類是否正確。之后,在測試階段,對訓練階段未見過的小樣本數據集也做相同數據劃分,便可以在訓練好的模型上直接對小樣本查詢集進行判別。圖3 中,對于各種鳥類的小樣本分類問題,可以利用已有的各種鳥類數據,通過采樣構造支持集和查詢集,訓練小樣本模型。測試階段,對于黃雀和海鷗等未知鳥類,用同樣的采樣方法區分出支持集和查詢集,之后提取圖像特征,并計算支持集和查詢集特征的距離或相似度。對于一個小樣本分類任務,元學習不會直接學習如何做到這件事情,它要做的是去學習一些相似的任務,在這些任務中有足夠的知識或樣本來學習,當學習了很多這樣的任務之后,元學習模型便學會了舉一反三,之后用這個分類任務來測試元學習模型,只要模型在之前的訓練中已經具備了足夠好的舉一反三的能力,那么模型就可以完成任務。
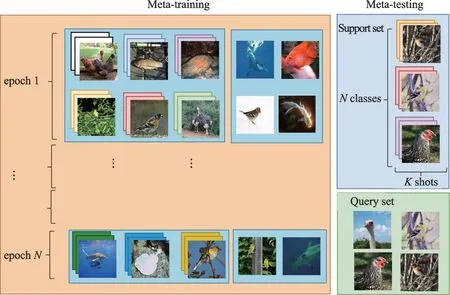
圖3 通過元學習解決少鏡頭圖像分類問題Fig.3 Solving few-shot image classification via meta-learning
1.2.2 度量學習
度量學習是解決小樣本圖像分類最常用也是很有效的方法之一。度量學習可以解釋為是一種空間映射的方法,能夠學習到某種特征空間。在小樣本圖像分類中,可以理解為將數據轉換成特征向量。度量學習也指相似度學習,衡量在嵌入空間中兩個目標特征或者多個相似度或者距離,相同的類特征距離較近,反之不同的類特征距離較遠。
度量學習的小樣本圖像分類方法,如圖4 所示。度量學習網絡主要由嵌入模塊f(特征提取器)和度量模塊g(分類器)兩部分組成。首先將樣本分為支持集和測試集,將圖像輸入嵌入模塊f獲得特征,并且以一定的規則計算得到支持集圖像中每類的中心特征,以這些中心特征作為支持集中各類圖像的代表,再使用度量模塊g求得與查詢集中樣本最近的中心特征,將這個中心特征所屬的類別標簽作為該查詢集樣本的預測標簽。最終根據相似度得分獲得分類結果。
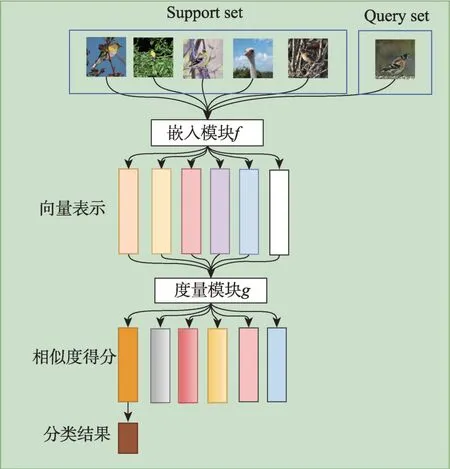
圖4 度量學習算法流程圖Fig.4 Metric learning algorithm flowchart
通過卷積神經網絡和循環神經網絡等方法來實現特征的提取。度量分類器可以使用基于布雷格曼散度的歐氏距離、馬氏距離和余弦距離的固定度量方法或者基于深度神經網絡的可學習度量方式[26]。基于度量學習的小樣本圖像分類方法的性能取決于兩方面:一方面是特征提取器和分類器的性能;另一方面是特征與分類器的匹配程度。因此,如何設計一個小樣本條件下表達能力強的特征提取器,并使提取的特征與分類器的要求相匹配,對于提升網絡的分類性能十分重要。
1.2.3 數據增強
數據增強又稱為數據擴充,通過增加既有數據的多樣性,而不是實際收集新數據來緩解數據稀缺問題。基于增廣數據集,可以明顯降低過度擬合[27]的風險,有效地增強模型的泛化能力。數據增強方法可以分為基于數據扭曲的數據擴充和基于深度生成模型的數據擴充。
基于數據扭曲的數據擴充:數據扭曲是一種通過基于現有數據執行基本圖像操作來生成新樣本的方法。常用的變換技術包括裁剪、翻轉、過濾、旋轉和去噪。這些轉換較容易實現,以增加數據規模。然而,這些方法均無法生成新的語義信息來增加數據的多樣性,并且數據增強方法對提高模型性能的效果有限。因此,這種方法不能完全解決樣本限制問題,通常被用作數據預處理的輔助技術。
基于深度生成模型的數據擴充:深度生成模型可用于學習目標圖像上豐富的概率分布,并生成具有變化的新樣本。生成對抗網絡(generative adversarial network,GAN)28]是生成模型中較有代表性的一類,是由Goodfellow 等人于2014 年提出來的一種新穎的生成模型框架。GAN包含生成器(generator,G)和判別器(discriminator,D)兩個神經網絡。訓練G和D的過程可以看作是造假團隊G與警察團隊D之間的一種相互博弈。造假團隊G的目標是生成以假亂真的圖片,而警察團隊D的目標是判別圖片的真假。兩者通過不斷地對抗來提高自己的水平[29]。直到警察團隊D無法判別圖像真假時,說造假團隊G能夠生成騙過警察團隊D的圖像。
生成對抗網絡的基本模型如圖5 所示。

圖5 生成式對抗網絡Fig.5 Generative adversarial network
生成式對抗網絡巧妙地利用了博弈的思想,將圖像生成任務轉化為最大最小化目標函數的優化問題。進一步地,又轉化為兩個神經網絡采取梯度下降方法交替訓練的問題。
無論是基于數據扭曲還是基于深度生成模型,數據增強的手段都是來增加小樣本數據,緩解小樣本分類中因為缺乏數據導致分類率低的問題。采用數據增強的思路來解決小樣本學習問題是人們最常用、最簡單的一種方式,并且這種方式相對來說方式較為靈活,選擇也很多。基于數據增強的小樣本圖像分類研究具有普遍通用性,是不可或缺的。
1.3 小樣本圖像分類數據集
本節介紹了用于小樣本圖像分類的公共數據集,如圖6 所示。下面列出了數據集的統計數據和常用實驗設置。

圖6 小樣本學習通用數據集Fig.6 Few-shot learning general dataset
Mini-ImageNet[30]:Mini-ImageNet數據集是另一個廣泛使用的數據集。它由ImageNet 中選擇的100個類組成,每個類有600 張圖像。該數據集最初由Vinyals 等人提出,但最近的研究遵循Ravi 和Larochelle 提供的實驗設置,將100 個類分為64 個基類、16 個驗證類和20 個測試類。
Tiered-ImageNet[31]:與Mini-ImageNet 一樣,它是ILSVRC-12的子集,但Tiered-ImageNet代表了ILSVRC-12 的更大子集(608 個類,而Mini-ImageNet 則為100個類)。類似于將字符分組為字母的Omniglot,Tiered-ImageNet 將類別分為與ImageNet 層次結構中較高級別的節點相對應的更廣泛的類別,共有34 個大類別,每個類別包含10 到30 個小類別。數據集分為20 個基類、6 個驗證類和8 個測試類。
CIFAR-FS[32]:CIFAR-Fewshot數據集建立在CIFAR-100 之上,包含100 個類,每個類600 張圖像。數據集劃分為64個基類、16個驗證類和20個測試類。
CUB-200[33]:CUB-200數據集全稱為Caltech-UCSD Birds-200-2011 數據集。CUB 數據集是一個細粒度的鳥類分類數據集,共包含200 個類別和11 788 張圖像。數據集通常分為100 個基類、50 個驗證類和50 個測試類。
Omniglot[34]:Omniglot數據集包含50個不同字母(語言的1 623 個不同手寫字符)。每一個字符都是由20 個不同的人通過亞馬遜的Mechanical Turk在線繪制的。每個字符產生了20 幅圖像,相當于1 623 個類,每類20 個樣本。在實驗時,取1 200 個字符進行訓練,其余423 個字符進行測試。此外,將每個圖像的大小調整為28×28 像素,并旋轉90°作為數據增強。
2 有監督小樣本圖像分類
2.1 基于元學習的有監督小樣本學習
元學習在處理小樣本問題時包括元訓練(metatraining)和元測試(meta-testing)兩個階段。在元訓練階段,如圖7 所示,基礎學習器將面對元學習器提供的許多個獨立的監督任務T,任務之間所包含樣本的類別不完全相同。在每一個任務內,從已有的基礎類別集Cbase中隨機抽取N個類別,從每類樣本中抽取K個樣本(共N×K個樣本)組成支持集S作為基礎學習器的輸入,再從這N類的剩余樣本中隨機抽取一批作為查詢集用于測試。
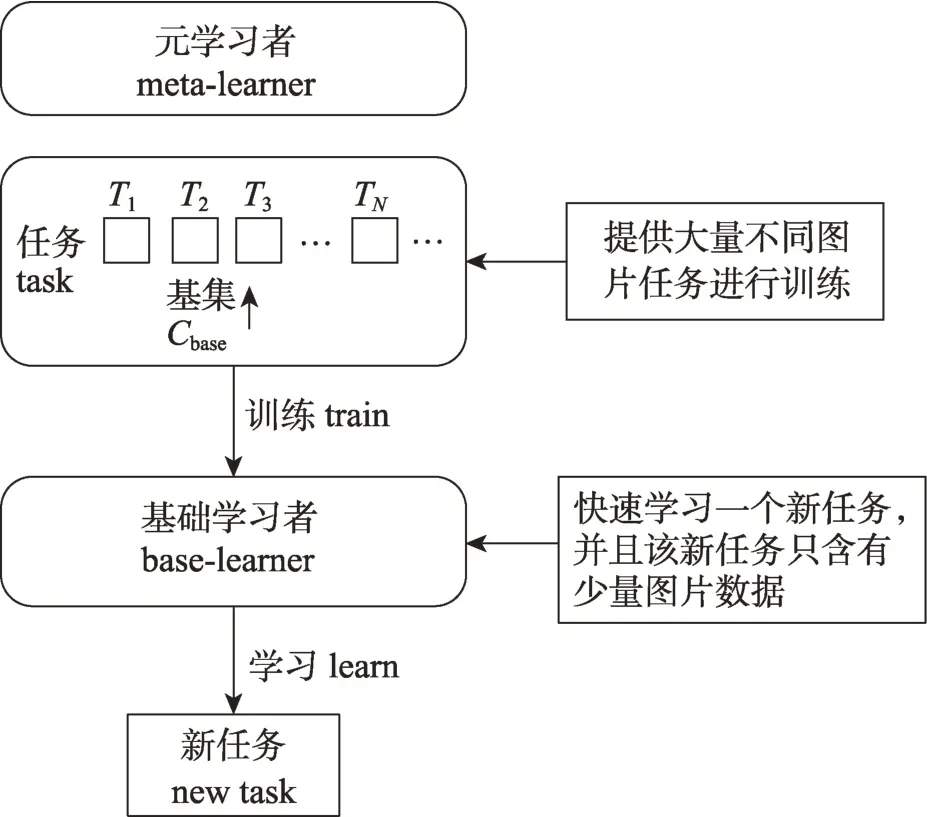
圖7 元學習訓練思想Fig.7 Meta-learning training ideas
本節回顧了近年來用于小樣本圖像分類的代表性有監督元學習方法。調查研究發現,小樣本元學習的一個主流方法是梯度迭代,通過迭代,獲得合適的模型,因此眾多研究基于迭代的研究思路展開。
MAML(multi-agent modeling language)由Finn等人[35]提出,將元學習應用到小樣本圖像分類。MAML的核心思想是梯度迭代。首先需要在源數據上將目標設定好,每一個任務當中的訓練集只含有很少的標注樣本信息,然后利用這些標注樣本所訓練的模型參數在測試集上面評估得到的監督信息參數θ,并用監督信息θ來訓練原網絡,使得模型學習到適配特征。整個過程通過梯度迭代優化,前一步迭代優化訓練得到的模型,將會作為當前迭代優化的初始模型。訓練完成后的模型具有對新訓練的學習域分布最敏感的參數。正是通過這種優化方式,可以從多次迭代優化任務中獲得最貼合新任務的模型參數,達到比較好的準確率,并且對于學習相似任務的信息可以快速地泛化。Nichol 等人[36]提出的Reptile 模型基于MAML 模型,但Reptile 取消了內層優化僅更新一次的限制,梯度更新從二階轉化為一階,因此Reptile 有效節約了計算成本。針對MAML 的不足,Antoniou 等人[37]在2019 年提出MAML++模型。對于訓練不穩定問題,Antoniou 等人提出多步損失優化法,通過改善梯度傳播的方式緩解MAML 優化過程中的不穩定性。
Meta-Learner LSTM 是一種基于LSTM(long shortterm memory)的元學習模型,用于學習作用于另一個學習的最優化算法。LSTM 的作者Larochelle 等人[38]發現了更新規則與一般的梯度下降算法更新規則非常類似,因此將LSTM 更新規則的輸入替換為其他的一系列參數,用于更新Learner 的值。算法的主要貢獻是首次將序列優化問題進行了規范化。使用LSTM 這樣的序列優化模型,模型按照順序在不同的任務中交替訓練,使得模型能夠通過少量樣例,從一個分類任務快速遷移到另一個分類任務中。但由于訓練數據較少,LSTM 模型所需參數規模較大,算法實際在小樣本任務上的分類效果并不是很好。
基于梯度的元學習技術在解決小樣本學習時具有廣泛的應用性。然而,當在極低數據狀態下對高維參數空間進行操作時存在實際困難。潛在嵌入優化將基于梯度的自適應過程與模型參數的底層高維空間分離。因此,Rusu等人[39]在2019年提出了具有潛在嵌入優化的元學習(latent embedding optimization,LEO)。LEO 通過學習模型參數的數據相關潛在生成表示,并在這個低維潛在空間中執行基于梯度的元學習,可以繞過這些限制。
將元學習與遷移學習相結合來解決小樣本問題也是眾多研究者思考的問題,并且嘗試替換神經網絡的深淺和長度,用一些新的模型來替代卷積神經網絡,也能取得不錯的效果。
由于深度神經網絡(deep neural networks,DNN)傾向于僅使用少數樣本進行過擬合,因此元學習通常使用淺層神經網絡(shallow neural networks,SNN),而限制了有效性。2019 年國內Sun 等人[40]提出了一種新的元遷移學習(meta-transfer learning,MTL)進行小樣本學習。MTL 使深度神經網絡適應小樣本學習任務,通過學習每個任務的DNN 權重的縮放和移位函數來實現遷移。
許多小樣本學習方法通過從已見類中學習實例嵌入函數,并將該函數應用于來自有限標簽的未見類。Ye 等人[41]于2020 年提出了使用Set-to-Set 函數嵌入自適應的小樣本學習(few-shot embedding adaptation transformer,FEAT)。通過Set-to-Set 函數使實例嵌入適應目標分類任務,從而產生特定于任務且具有區分性的嵌入。Ye等人憑經驗研究了這種集合到集合函數的各種實例,并觀察到Transformer是有效的。
許多用于小樣本學習的元學習方法依賴于簡單的基礎學習器,例如最近鄰分類器。但在小樣本情況下,經過判別訓練的線性預測器也可以提供更好的泛化能力。Lee 等人[42]在2019 年提出了具有可微凸優化的元學習(MetaOptNet)。MetaOptNet 使用預測器作為基礎學習器來學習小樣本學習的表示,并表明在一系列小樣本分類基準中提供了特征大小和性能之間的更好權衡。
受自動化機器學習(AutoML)取得成功的啟發,Zhang 等人[43]在2021 年提出為小樣本學習尋找一個好的適應策略,稱為Meta Navigator。Meta Navigator通過尋求更高級別的策略并提供自動化選擇來解決小樣本學習限制的問題,搜索系統建立在離散元學習策略的連續放松之上,其中每個候選策略都與一個可學習的策略選擇指標相關聯。目標是尋找適用于網絡不同階段的良好參數適應策略,以進行小樣本分類。Zhang 等人還提出了一個搜索空間,涵蓋了許多流行的小樣本學習算法,并開發了一種基于元學習的可微搜索和解碼算法,支持基于梯度的優化。
通過對整個分類進行訓練,即對整個標簽集進行分類,可以獲得與許多元學習算法相當甚至更好的嵌入。Chen等人[44]因此在2021年提出了元基線(Meta-Baseline),探索簡單元學習的小樣本學習方法。Meta-Baseline 的所有單個組件都已在先前的工作中提出,但沒有一個工作將它們作為一個整體進行研究。
2.2 基于度量學習的有監督小樣本學習
Snell 等人[45]在2017 年提出了原型網絡(prototypical network)。原型網絡的思想為每個類別在向量空間中都存在一個原型(prototype),也稱為類別中心點。原型網絡使用深度神經網絡將圖像映射成特征向量,對于同屬一個類別的樣本,求得這一類樣本向量的平均值作為該類別的原型。通過不斷訓練模型和最小化損失函數,使同一類別的樣本距離更加接近,不同類別的樣本更加遠離,從而更新嵌入函數的參數。原型網絡思路架構如圖8 所示,在原型網絡中f和g是參數共享的嵌入網絡,這種思路框架也是許多后續基于度量的小樣本學習方法的基石。
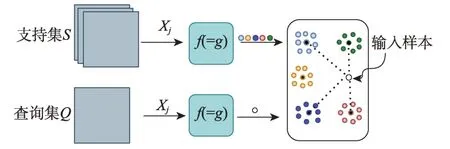
圖8 原型網絡樣例Fig.8 Prototypical network example
早期的小樣本度量學習方法,如孿生網絡(Siamese network)和匹配網絡(matching network),通過測量和比較查詢樣本與支持樣本的距離來對查詢樣本進行分類。孿生卷積神經網絡(Siamese convolutional neural network)[46]是首個用于一次性圖像分類的深度度量學習方法。孿生網絡首先在文獻[47]中引入,由兩個具有相同架構和共享權重的子網絡組成。孿生神經網絡可以提取兩個輸入圖片在同一分布域的特征,從而判斷兩個輸入圖片的相似性。匹配網絡[48]在整個支持集的上下文中使用不同的網絡對支持和查詢圖像進行編碼,并且將情景訓練引入小樣本分類,支持圖像通過雙向LSTM 網絡嵌入。該網絡不僅考慮圖像本身,還考慮集合中的其他圖像;查詢圖像通過具有注意機制的LSTM 嵌入,以啟用對支持集的依賴。早期度量學習方法特征學習能力有限,魯棒性較差,無法達到理想的效果。這些方法為度量學習建立了理論基礎,近幾年度量學習方法在此基礎上取得了較好的效果。
很多研究者將度量學習下小樣本學習目光放在了特征問題上,通過有效提取特征之間的關聯性,來提高小樣本圖像分類的準確率。
子空間是度量學習經常用到的一種方法。Simon等人[49]在2020 年提出了深度子空間網絡(deep subspace networks,DSN)。引入小樣本構建的動態分類器,為小樣本學習提供了一個框架。通過使用子空間來擴展現有的動態分類器。子空間方法被用作動態分類器的中心塊,這種建模會導致對擾動異常值的魯棒性。還引入了一個判別公式,在訓練期間鼓勵子空間之間的最大區分,并在監督和半監督的小樣本分類任務上產生較有競爭力的結果。
Hou 等人[50]在2019 年提出了一種新穎的交叉注意網絡(cross attention network,CAN)來解決小樣本分類問題,CAN 引入交叉注意力模塊來處理看不見類的問題。該模塊為每一對類特征和查詢樣本特征生成交叉注意力圖,以突出目標對象區域,使提取的特征更具判別力。其次提出了一種轉導推理算法來緩解低數據問題,該算法迭代地利用未標記的查詢集來擴充支持集,從而使類特征更具代表性。
國內Zhang 等人[51]也在2020 年提出了具有可微推土機距離和結構化分類器(deep earth mover’s distance,DeepEMD)的小樣本圖像分類。地球移動距(earth mover’s distance,EMD)可以作為度量來計算密集圖像表示之間的結構距離,以確定圖像相關性。EMD 生成具有最小匹配成本的結構元素之間的最佳匹配流,用于表示分類的圖像距離。EMD中的最佳匹配流參數和特征嵌入中的參數以端到端的方式進行訓練。為了生成EMD 公式中元素的重要權重,Zhang 等人設計了一種交叉引用機制,可以有效地減少由雜亂的背景和較大的類內外觀變化造成的影響。
通過設計歸納偏差提出一種新穎的特征學習方法。Rizve 等人[52]在2021 年提出了小樣本學習不變和等變表示的互補優勢,實現了輸入變換所需的特征,可以提供更好的區分。專注于轉換判別的特征對于類判別不是最優的,而是有助于學習數據結構的等變屬性,從而獲得更好的可遷移性。
CAN、DSN、DeepEMD 和互補優勢等方法從度量學習的特征角度入手,通過設計有效的特征學習方法,使得小樣本學習性能得以提升。也有眾多研究者從度量學習其他角度來解決小樣本圖像分類問題,如質心、類空間等方法,并同樣使得性能得到提升。
基于質心的方法通過最近鄰規則實現了較好分類性能。Liu 等人[53]認為這些方法本質上忽略了每類分布,由于類內方差的多樣性,決策邊界是有偏差的。Liu 等人在2021 年提出了用于改進小樣本分類的類度量尺度機制(class-wise metric scaling,CMS)。CMS 使得度量標量在訓練階段被設置為可學習的參數,有助于學習更具區分性和可轉移性的特征表示。CMS 構建了一個凸優化問題來生成一個最優標量向量,以優化最近鄰決策。CMS 可以應用于訓練和測試階段,充分利用每類分布之間的信息來解決小樣本問題。
從基集類空間的角度來看,研究者要么側重于通過常規預訓練來利用全局視圖下的所有類,要么更注重采用情節式的方法在局部視圖中對少數類內的元任務進行訓練。Zhou 等人[54]在2021 年提出小樣本分類的雙目互學習(binocular mutual learning,BML)。BML 通過視圖內和交叉視圖建模來實現全局視圖和局部視圖的兼容。全局視圖在整個類空間中學習以捕捉豐富的類間關系。同時,局部視圖在每一集的局部類空間中學習,專注于正確匹配正對。此外,跨視圖交互進一步促進了協作學習和對有用知識的隱性探索。由于這兩個視圖捕獲了互補的信息,大大提高了分類的準確性。
選擇一個距離度量來直接計算查詢和支持圖像之間的距離以進行分類,然而這些方法中的大多數使用圖像級池表示進行分類,可能會失去相當大的判別性局部線索,這些線索在類之間享有良好的可轉移性。Wu 等人[55]在2021 年通過將自動零件挖掘過程集成到FSL 的基于度量的模型中,提出了一個端到端的任務感知零件挖掘網絡(task-aware part mining network,TPMN)。TPMN 設計了一個元過濾器學習器,以元學習方式基于任務嵌入生成任務感知部分過濾器。任務感知部分過濾器可以適應任何單個任務,并自動挖掘與任務相關的本地部分,即使是看不見的任務。其次,提出了一種自適應重要性生成器來識別關鍵的局部部分,并將自適應重要性權重分配給不同的部分。
Singh 等人[56]在概率深度學習的啟發下,提出了一種新型的變異推理網絡TRIDENT,將圖像的表示解耦為語義和標簽的潛在變量,同時以交織的方式推斷它們。為了誘導任務意識,作為TRIDENT 推理機制的一部分,使用一個新的內置的基于注意力的反導特征提取模塊,以TRIDENT能夠全面看到一個任務中的所有圖像,在標簽信息的推斷中誘發任務認知。
He 等人[57]提出一種新的分層級聯變換器(hierarchically cascaded transformers,HCTransformers),通過光譜標記池利用內在的圖像結構,并通過潛在的屬性代理優化可學習參數。設計了一個由三個連續級聯的變換器組成的元特征提取器,每個變換器都在不同的語義層面對圖像區域的依賴性進行建模。相同聚類中標記的特征被平均化,以生成新的標記描述符,用于后續的轉化器。譜系標記集合背后的動機是將圖像分割層次帶入變換器。
表1 選取了Mini-ImageNet(test)、Tiered-Image-Net(test)和CIFAR-FS 數據集的實驗結果作為對比參考,因為其他幾個數據集使用較少,所以不做討論。由表1 可以看出,在每個數據集上面,5-shot準確率均比1-shot 準確率高10 個百分點左右,表明小樣本學習和常規的訓練學習一樣,訓練數據越多,學到的信息和特征越多,分類的性能也越好。在Mini-Image-Net(test)上,最初在1-shot 與5-shot 上43.44%和60.60%的準確率已經提升到了74%和89%左右,不同模型方法通過不同的側重點改進,均取得了較好的性能提升,但在此數據集上還有較大的提升空間。因為Tiered-ImageNet(test)與Mini-ImageNet(test)都出自ImageNet 數據集,所以準確率的提升和Mini-ImageNet(test)同樣明顯。但因為Tiered-Image-Net(test)數據集中包含層次結構較高級別的節點對應更廣泛的類別,所以最高準確率在1-shot 和5-shot 上已經達到79%和91%,但同樣有提升的空間,距離人的識別準確率還有較大差距。CIFAR-FS 數據集與以上兩個數據集有一個顯著的區別在于,早期的有監督小樣本學習更注重在Mini-ImageNet(test)和Tiered-ImageNet(test)上的性能表現,但在近幾年,研究者們開始關注在CIFAR-FS 上的性能表現,并在1-shto 和5-shot 下達到了78%和90%的準確率,較之前都有了35 個百分點的性能提升。同時通過調查發現,基于元學習和度量學習的小樣本學習準確率均達到了較高的數值,且兩種方法通過相互結合,能夠進一步提高實驗結果。如表2 所示,通過對有監督下小樣本圖像分類方法的對比分析,發現各方法均有優勢,但元學習器設計較為困難,而度量學習容易引入其他噪音參數。
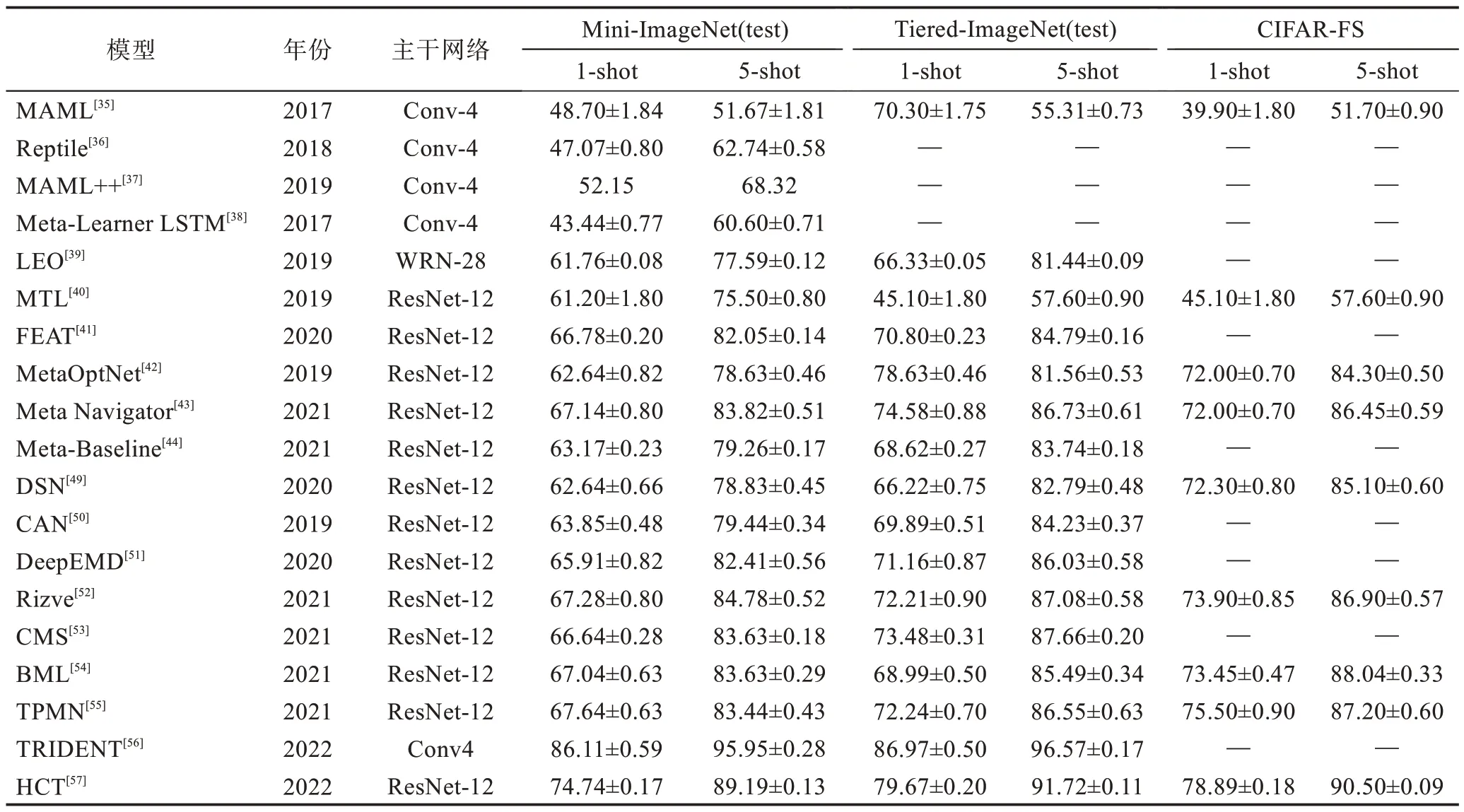
表1 有監督下小樣本圖像分類方法準確率對比Table 1 Accuracy comparison of supervised few-shot image classification methods 單位:%

表2 有監督下小樣本圖像分類方法對比分析Table 2 Comparative analysis of supervised few-shot image classification methods
3 基于半監督小樣本圖像分類
3.1 半監督概念
獲取大量的有標注數據集需要耗費大量的人力物力,但是隨著深度學習的快速發展和手機、攝像機等收集圖像設備的迭代更新,每時每刻都有人將自己拍攝的圖片傳輸到社交網絡當中。另一方面,隨著智慧城市概念的提出,為了城市的安全和管理考慮,監控系統已經普及到全國各地所有的城市當中,通過監控每天都能獲得許多無標記的圖片。雖然無標注數據集沒有具體的類別標簽等人為標注信息,但是無標注信息本身就含有大量的有用的特征信息和語義結構信息,因此一個很自然的想法就隨之誕生,如果同時依靠有限的標注數據,同時能夠有效提取無標注數據中自身含有的有用信息進行學習,則可以大大促進圖像分類相關研究的發展。而關于小樣本學習下的半監督學習,前期絕大多數都是在基于元學習的理論框架下發展的,近些年相關新的技術也被提出。下面根據半監督的相關方法展開討論。
3.2 基于半監督的小樣本學習
如果只用少量的有標注圖像進行深度學習模型的訓練,則會造成深度模型的過擬合,無法學到泛化能力強的分類模型,而充分利用無標注樣本的結構和語義信息可以幫助獲得更好的模型,如圖9 所示,相比于有監督的圖像分類任務,半監督圖像分類將會充分利用無標注數據。因此本節研究的關鍵是如何依靠有限的標注數據,同時利用大量的無標注數據進行圖像識別模型的學習,即基于半監督學習的圖像分類。
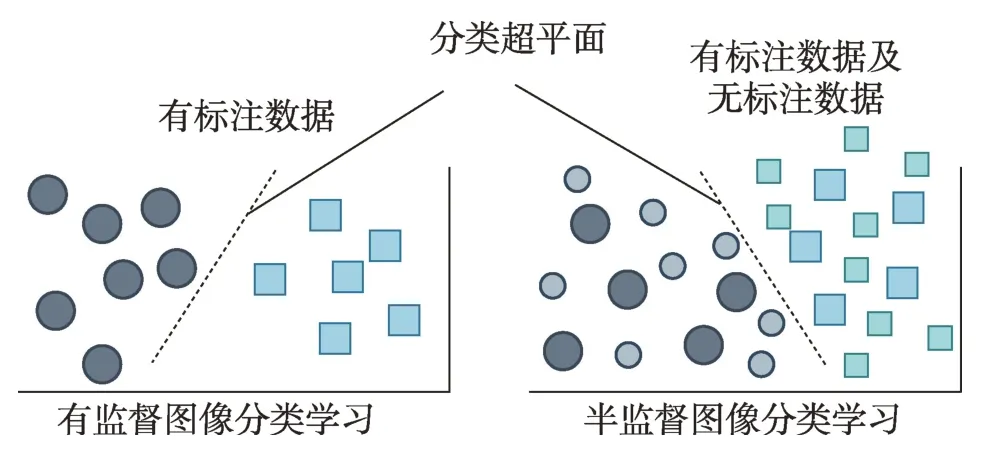
圖9 有監督學習與半監督學習的對比Fig.9 Supervised learning vs semi-supervised learning
半監督學習的關鍵是如何挖掘和利用無標注樣本中包含的信息。為了利用無標注樣本,現有的半監督學習方法基本都遵循一個基于密度的聚類假設:位于高密度區域的樣本可能屬于同一個類簇。該假設還有一個等價的描述:分類超平面不應該越過高密度區域,而應該位于低密度區域,即低密度可分假設,如圖10 所示。基于低密度可分假設,研究者提出了兩類半監督學習方法:第一類是基于一致性正則的方法,主要約束模型對無標注樣本經過隨機擾動后的分類預測與對原始樣本的分類預測具有一致性;第二類是基于偽標注的方法,該類方法主要通過模型的分類預測或鄰近的有標注樣本為無標注樣本產生偽標簽。
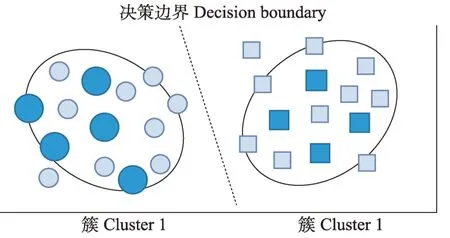
圖10 低密度可分示意圖Fig.10 Low density separable schematic
3.2.1 一致性約束的方法
半監督下基于一致性約束的方法主要基于低密度可分假設。分類超平面應該位于數據的低密度區域,而不應穿過高密度區域;因為相同類別的樣本更可能形成高密度,所以分類超平面如果位于高密度區,則會將相同類別的樣本劃分為不同的類別。當前基于半監督學習的圖像識別算法基本都遵循該假設。為確保分類超平面低密度可分,研究者提出了一致性約束的方法,其核心思想為約束每個訓練樣本經過數據擾動之后,網絡的輸出與原始訓練樣本對應的輸出一致。
基于密度圖的半監督學習算法。通過構建密度圖,每個樣本可以很容易獲得其鄰居信息。更重要的是,特征學習和標簽傳播可以一起進行端到端的訓練,并且為了更好地利用密度信息,顯式地將密度信息有機地引入到特征學習和標簽傳播的過程中。具體來說,首先給定有標注樣本和無標注樣本來構建密度圖,并且為圖中每個節點定義密度信息。基于密度圖進行特征學習,提出聚合鄰居信息去增強目標節點的特征。
Laine 等人[58]提出兩種使用一致性約束的半監督圖像識別方法,即PI 模型(productivity index)和時序集成模型(temporal ensemble)。PI 模型將原始訓練樣本和對應的經過數據擾動的樣本一同輸入模型,然后約束模型對這兩種輸入的輸出具有一致性。不同于PI 模型需要將兩種訓練樣本輸入模型,時序集成模型則提出保存每個訓練樣本對應的模型輸出的歷史均值,然后約束樣本對應的當前模型的輸出與歷史平均值具有一致性。PI 模型的特點是不需要保存每個樣本的歷史平均值,但模型需要前向計算兩次;時序集成模型不需要對每個樣本前向計算兩次,但需要保存所有訓練樣本的歷史類別預測均值,故具有較大的存儲開銷。
Rodriguez 等人[59]提出密度峰假設,強調高密度的樣本更可能是類簇的中心,同時高密度的樣本更能表征所屬類簇的信息。相比于低密度的樣本,高密度的樣本具有更高的特征性,這對半監督學習來說是一個非常有價值的信息。但是當前的半監督學習方法并沒有像這樣顯式地利用密度信息或者深入地挖掘密度信息。對于一個半監督學習算法來說,特征學習和無標注的偽標注生成是其核心的兩部分。在進行特征學習時,當前的方法只利用了單個樣本自身的信息,而忽略了可以利用的鄰居信息,這些鄰居信息包含的類簇和結構信息可以幫助學習到更好的特征。
MeanTeacher[60]對時序集成模型進行了改進。不同于時序集成模型要求原始樣本的輸出與經過隨機擾動的樣本的輸出具有一致約束性,Mean Teacher 提出在訓練過程中對模型的參數做歷史滑動均勻,并維護對應的模型,然后約束同一訓練樣本,經過當前模型與歷史平均模型后的輸出具有一致性。
Liu 等人[61]在2018 年提出一種基于半監督的元學習框架,通過情景訓練的元學習,可以學習標簽傳播網絡。從訓練集中采樣的查詢示例可以用來模擬真實的測試集進行跨導推理,稱為跨導傳播網絡(transductive propagation network,TPN)。為解決圖像分類數據低的問題,TPN 用于對整個測試集進行一次分類,以緩解低數據問題。通過學習利用數據中流形結構的圖構造模塊,以端到端的方式聯合學習嵌入圖形構造的參數。
Yu 等人[62]的思考角度發生了轉變,將預訓練模型遷移到小樣本學習。Yu 等人在2020 年提出了一種新的半監督小樣本學習轉移學習框架Trans Match。TransMatch 充分利用標記基類數據和未標記新類數據中的輔助信息,顯著提高小樣本學習任務的準確性。TransMatch 的最大創新點在于,以往的半監督學習方法都基于元學習,而Yu 等人將目光放在基于遷移學習,并且取得成功。
大多數基于圖網絡的元學習方法對示例的實例級關系進行建模。Yang 等人[63]進一步擴展這一想法,提出了分布傳播圖網絡(distribution propagation graph network,DPGN)。DPGN 傳達了每個小樣本學習任務中的分布級關系和實例級關系,為了結合所有示例的分布級關系和實例級關系,Yang 等人構建了一個由點圖和分布圖組成的對偶完全圖網絡,每個節點代表一個示例來進行實驗,并取得了不錯的效果。
3.2.2 基于偽標注的方法
基于偽標注的方法的核心思想是為無標注樣本賦予“偽標簽”,之后結合原始有標注數據共同進行有監督的小樣本訓練,因此該類方法又被稱為自監督學習方法。該類方法的關鍵是為無標注樣本生成準確的類別標簽,而不同的產生類別標簽的方法代表了不同的半監督學習方式。
Li 等人[64]在2019 年提出一種基于半監督的帶硬偽標簽和軟偽標簽的自我訓練方法,利用稀缺的標記數據和豐富的未標記數據來學習,稱為自學習訓練(learning to self-train,LST)。LST 利用未標記的數據,特別是元學習,來挑選和標記此類無監督數據,以進一步提高性能。在每個任務中,訓練幾個鏡頭模型來預測未標記數據的偽標簽,在每個步驟中對標記和偽標記數據迭代自訓練步驟,最后在下游任務中進行微調。此外,此模型還提出軟加權網絡來優化偽標簽的自訓練權重,以便網絡能夠更好地為梯度下降優化做出更大的貢獻。
Huang 等人[65]在2020 年提出了一種用于半監督小樣本學習的任務統一置信度估計方法PLCM(pseudoloss confidence metric)。PLCM 通過偽損失模型將不同任務的偽標記數據映射到一個統一的度量空間,從而可以了解之前的偽損失分布。PLCM根據偽標記數據偽丟失的分布分量置信度估計偽標記數據的置信度。
以往利用元學習范式或數據增強中的新原理來緩解極度缺乏數據的問題。Wang 等人[66]提出了一種簡單的統計方法,稱為實例可信度推斷(instance credibility inference,ICI),以利用未標記實例的分布支持進行小樣本學習。首先用標記的少數樣本訓練一個線性分類器,并推斷未標記數據的偽標簽。為了衡量每個偽標記實例的可信度,通過增加附帶參數的稀疏度來解決另一個線性回歸假設,并根據它們的稀疏度對偽標記實例進行排名,選擇最值得信賴的偽標記實例與標記實例一起重新訓練線性分類器。
Li 等人[67]在2021 年引入一種新的基線方法,通過迭代偽標簽細化來減少噪聲,從而實現半監督小樣本學習。半監督小樣本學習基線方法是修改一個帶有偽標簽細化(pseudo label refinement,PLAIN)的遷移學習框架。Li等人使用去噪網絡改進了PLAIN,通過適應新類的知識來減少偽標簽噪聲,并使用高斯混合模型(Gaussian mixture model,GMM)來學習干凈和有噪聲偽標簽的分布,以獲得可靠的偽標簽實例,產生了一種稱為PLAIN++的高級小樣本學習方法。與PLAIN 相比,PLAIN++需要使用高置信度的偽標記實例來訓練去噪網絡。使用這個去噪網絡來評估GMM 偽標簽的置信值,GMM 對干凈和有噪聲的偽標簽樣本的分布進行建模,以便可以選擇偽標簽的η百分比來更新小樣本分類器。此過程交替執行,直到達到預定義的迭代次數。
表3 選取了Mini-ImageNet(test)、Tiered-Image-Net(test)和CIFAR-FS 數據集的實驗結果作為對比參考。由表3 可以看出,半監督小樣本的研究對比于有監督相對較少,但是同樣取得了不錯的效果。同樣在每個數據集上面,5-shot 準確率均比1-shot 準確率高。在Mini-ImageNet(test)上,最 初 在1-shot 與5-shot 上的準確率已經提升到了74%和82%左右,在此數據集上還有較大的提升空間。在Tiered-ImageNet(test)上同樣取得不錯的效果,1-shot 和5-shot 上分別達到82%和88%的準確率,相比較最初的TPN 有了將近20~30 個百分點的性能提升。CIFAR-FS 數據集在1-shto 和5-shot下達到了85%和88%的準確率。如表4 所示,通過對半監督下小樣本圖像分類方法對比分析,發現它們都各有優勢,但一致性約束方法局限性各不相同,而偽標注的方法優勢在于充分利用偽標簽,同時帶來偽標簽不準確的問題。
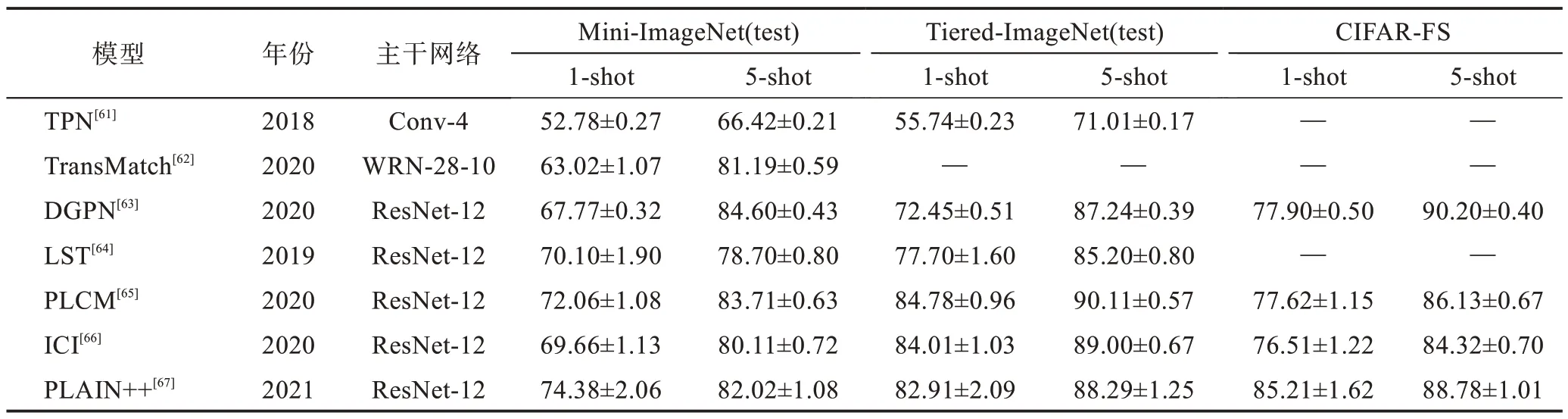
表3 半監督下小樣本圖像分類方法準確率對比Table 3 Accuracy comparison of semi-supervised few-shot image classification methods 單位:%

表4 半監督下小樣本圖像分類方法對比分析Table 4 Comparative analysis of semi-supervised few-shot image classification methods
4 基于無監督學習的圖像分類
4.1 無監督概念
監督學習依賴于人類標注信息,但是對于標注信息的過度依賴具有局限性。例如,人工標注的數據遠遠不如數據本身的內部結構豐富,在這種情況下進行大量樣本的訓練,得到的模型會比較脆弱;而且標注的信息通常適用于特定的任務,并不具有泛化性能。
以自監督為代表的無監督學習成為解決這一難題的辦法,因為圖像自身就可以為模型提供監督信息。無監督學習方法的一個核心用例是通過在無監督表征的基礎上進行訓練[68-69]或對所學模型進行微調[70],使下游任務的學習變得更好或更有效。小樣本下的圖像分類問題,通過利用無監督學習的方法,結合元學習算法的框架,使用未標記數據來生成少量任務,最終在目標任務中生成需要的標簽并進行訓練。
4.2 基于無監督的小樣本學習
在下游任務中使用無監督的表征與元學習密切相關,需要找到一種比從頭開始學習更有效的學習程序。然而,與無監督學習方法不同,元學習方法需要大量的、有標簽的數據集和手工指定的任務分布。這些依賴性是廣泛使用這些方法進行小樣本圖像分類的主要障礙。
4.2.1 數據增強的方法
在只有原始的、無標簽的觀察結果的情況下,模型的目標是學習一個有用的先驗。這樣,在元訓練之后,當遇到一個適度大小的指定任務的數據集時,模型可以轉移先前的經驗,有效地學習執行新任務。許多無監督學習工作基于重建、解纏結、預測和其他指標開發代理目標。2018 年Hsu 等人[71]也提出了一種自動構建無監督元學習任務的方法CACTUS(clustering to automatically construct tasks for unsupervised meta-learning)。利用無監督嵌入為元學習算法提出任務,從而產生一種無監督元學習算法,該算法對于指定的下游任務進行預訓練。使用基于嵌入的簡單機制生成的任務的元學習,提高了這些表示在學習下游指定任務中的效果。針對數據集來說,Hsu 等人實驗的數據集的分布較均勻,但現實世界中的數據集分布無法這么均勻,因此聚類的效果可能并不會很好,遷移性差。
分類器的小樣本或一個樣本學習需要對學習的任務類型有顯著的歸納偏差。獲得這一點的一種方法是對類似于目標任務的任務進行元學習。Khodadadeh 等人[72]在2019 年提出了UMTRA(unsupervised meta-lear-ning for few-shot image classification),一種對分類任務執行無監督、模型不可知元學習的算法。UMTRA 原理如圖11 所示,UMTRA 的元學習步驟是在未標記圖像的平面集合上執行的。雖然假設這些圖像可以分為一組不同的類并且與目標任務相關,但不需要關于類或任何標簽的明確信息。UMTRA使用隨機抽樣和增強來為元學習階段創建合成訓練任務。只有在最終的目標任務學習步驟中才需要標簽,并且每個類可以少至一個樣本。
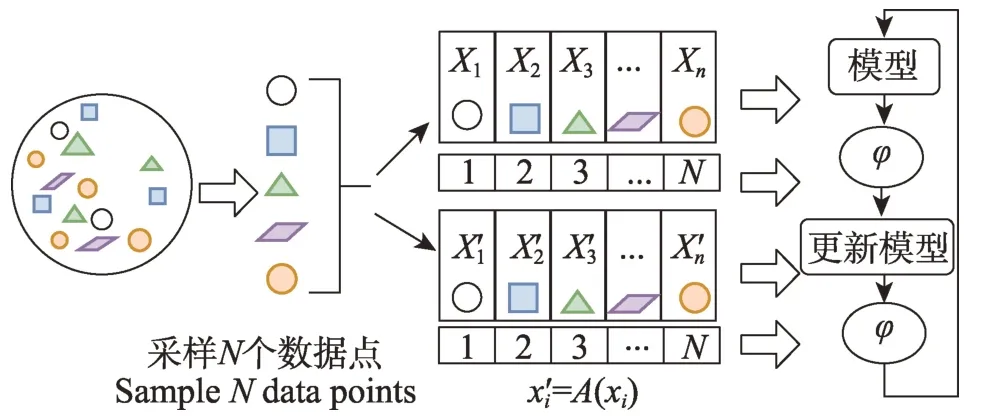
圖11 UMTRA:基于數據增強的無監督小樣本學習Fig.11 UMTRA:unsupervised few-shot learning based on data augmentation
Antoniou 等人[73]在2019 年提出了一種使用未標記數據生成少量快照任務的方法,稱為假設、增強和學習(assume,augment and learn,AAL)。AAL 假設給定支持集的聚類來訓練模型,擴充支持集生成目標集,并使用MAML 框架訓練模型,以便模型能夠快速獲得支持集的知識,并在目標集上很好地推廣。AAL 從未標記的數據集中隨機標記圖像的一個子集,以生成支持集,通過對支持集的圖像進行數據擴充,并重用支持集的標簽,獲得了一個目標集。由此產生的少量快照任務可用于訓練任何標準元學習框架。
2019 年Ji 等人[74]提出了一種整合漸進聚類和情景訓練的無監督小樣本學習方法UFLST。UFLST 由兩個交替過程組成:漸進聚類和情景訓練。前者生成用于構建情景任務的偽標記訓練樣本;而后者使用生成的情景任務訓練小樣本學習者,進一步優化數據的特征表示。這兩個過程相互促進,最終產生一個高質量的小樣本學習器。與以往的無監督學習方法不同,UFLST 將無監督學習和情景訓練集成到一個統一的框架中,便于特征提取和模型迭代訓練。
大多數以前的小樣本學習算法都是基于元學習,以假的小樣本任務作為訓練樣本,其中需要大量的標記基類。訓練后的模型也受到任務類型的限制。2020 年Li 等人[75]提出一種通過對比自我監督學習進行小樣本圖像分類的方法CSSL-FSL(contrastive self-supervised learning)。CSSL-FSL 提出了一種新的無監督小樣本學習范式來修復缺陷,分兩個階段解決小樣本任務:通過對比自監督學習對可遷移特征提取器進行元訓練,并使用圖形聚合、自蒸餾和流形增強訓練分類器。在第一階段,使用比較自監督學習方法,對未標記的圖像獲得具有良好泛化能力的特征提取器。在第二階段,元訓練特征提取器用于從當前任務的所有圖像中提取特征,并基于當前任務定義的特定圖進行特征聚合,以便查詢集的信息與查詢集的信息交互支持集。
Qin 等人[76]也在2020 年提出通過基于分布轉移的數據增強進行無監督的小樣本學習,開發了一個新的框架ULDA。ULDA 在使用數據增強時會關注每個小樣本任務內部的分布多樣性。Qin 等人強調了分布多樣性在基于增強的小樣本任務中的價值和重要性,這可以有效緩解過度擬合問題,并使小樣本模型學習到更魯棒的特征表示。在ULDA 中,系統地研究了不同增強技術的效果,并建議通過多樣化地增強這兩個集合來增強每個小樣本任務中查詢集和支持集之間的分布多樣性。
Xu 等人[77]在2021 年使用聚類嵌入方法和數據增強函數構建任務,以滿足兩個關鍵的類別區分要求,提出了一種使用聚類和增強構建無監督元學習任務的算法CUMCA。為了減輕增強數據引入的偏差和弱多樣性問題,CUMCA 提供了一個理論分析來解釋為什么外循環比內循環對增強數據更敏感。其次,提出了一種新的數據增強方法Prior-Mixup,而不是像UMTRA 中那樣僅使用旋轉、水平翻轉和剪切等規范進行圖像數據增強。Prior-Mixup 專為無監督元學習而設計,以滿足良好元學習任務分布的多樣性要求。
Zhang 等人[78]在2021 年提出了一種用于無監督小樣本學習和聚類的自監督深度學習框架UFLAC。UFLAC 可以被解釋為從學習的嵌入中反復發現新的類別,并用自我監督的信號訓練一個新的嵌入函數來區分發現的類別線索。在UFLAC 框架中,首先從未標記的數據中發現類別,再對之前的分區結果進行后處理,以去除異常值并導出每個類別的原型。然后使用先前選擇的數據和增強的虛擬數據構建小樣本學習任務。最后,通過前面的步驟迭代訓練網絡以學習最終表示。
Hiller 等人[79]將輸入樣本分割成斑塊,并通過視覺變換器的幫助對這些斑塊進行編碼,能夠在整個圖像的局部區域之間建立語義上的對應關系,并與它們各自的類別無關,稱為FewTURE。然后,通過推理時的在線優化,為手頭的任務確定信息量最大的補丁嵌入,另外還提供圖像中“最重要的東西”的視覺可解釋性。該方法建立在通過遮蔽圖像建模對網絡進行無監督訓練的最新進展上,以克服缺乏細粒度標簽的問題,并學習數據的更一般的統計結構,同時避免圖像級別的負面注釋影響。
該類方法的主要思想是將每個無標注的圖像當作獨立的類別,然后針對每個樣本通過數據增強的方法生成對應樣本的多個增強樣本,將原始樣本和增強生成的樣本作為同一類,這樣就可以轉化為有監督小樣本學習進行求解。
4.2.2 對比學習的方法
對比學習是自監督學習方法的一種,不依靠標注的數據,從無標注圖像中自己學習知識。自監督學習本身已經在圖像領域里被探索了很久。對比學習則是典型的判別式自監督學習,相對生成式自監督學習,對比學習的任務難度要低一些。對比學習方法已有很多,有效地將對比學習與小樣本圖像分類相互結合,也能取得不俗的效果。
由于訓練圖像的數量有限,當直接應用于小樣本學習時,隨機圖像變換可能會效果較差,具有更多的噪聲和更少的概念相關信息,會導致無法學習細粒度結構。為了有效改善小樣本學習環境下細粒度結構學習,Luo 等人[80]在2021 年提出了用于基于度量元學習的視圖可學習對比學習方法(view-learnable contrastive learning,VLCL),將對比學習的隨機圖像變換替換為空間變換網絡(spatial transformation network,STN),這是一個允許對圖像進行靈活空間操作的學習模塊,并開發了一種學習到學習的算法來自適應地生成同一圖像的不同視圖。
2021 年Liu 等人[81]提出通過對比學習來嵌入模型學習的方法Infopatch,并被擴展用于小樣本學習的任務。InfoPatch 利用源類信息構建正負對的算法,對于每個查詢實例,可以使用所有支持實例構造正例和負例。為了找到更多信息對來訓練良好的嵌入,Liu 等人提出了生成困難實例的策略。直觀地說,人類只能依靠圖像的一部分來識別物體,即使是圖像的其他部分是不可觀察的。強制執行這種直覺以幫助在FSL 中構建對比學習算法。
對比學習提出通過帶有標簽信息的自監督表示學習來代替交叉熵損失。Lee 等人[82]也使用監督對比學習來增強小樣本學習,稱為SPTA。Lee 研究發現,在第一個訓練階段,監督對比損失而不是簡單的交叉熵損失,大大提高了最終分類的準確性,尤其是在數據集不大的情況下。在小樣本學習的第一階段,將監督對比學習應用于預訓練。特征提取器使用監督對比損失進行訓練,然后進行微調,而分類器使用TIM 損失進行適應。
Lu 等人[83]認為小樣本學習方法依賴于用大量的標記數據集進行訓練,使得無法利用豐富的無標記數據。從信息論的角度來看,提出了一種有效的無監督FSL 方法UniSiam,通過自我監督來學習表征。在低維的學習表征中保留更多關于高維原始數據的信息。與有監督的預訓練相比,自監督的預訓練著重于捕捉數據的內在結構。它學習全面的表征,而不是關于基本類別的最有鑒別力的表征。有監督的預訓練和自我監督的預訓練實際上是在最大化不同的相互信息目標。自監督預訓練最大化了同一實例的增強視圖的表征之間的相互信息。
表5 選取了Mini-ImageNet(test)、Tiered-ImageNet(test)和Omniglot 數據集的實驗結果作為對比參考。由表5 可以看出,無監督小樣本的研究相比有監督和半監督發展較為緩慢,但對比學習下的SPTA 和InfoPatch 表現了較好的性能。同樣在每個數據集上,5-shot 準確率均比1-shot 準確率高。在Mini-ImageNet(test)和Tiered-ImageNet(test)數據集上,在1-shot 與5-shot 上的準確率已經提升到了70%和80%左右,無監督的小樣本學習在此數據集上還有較大的提升空間。Omniglot數據集在1-shot和5-shot上分別達到了94%和98%的準確率,可提升空間較小。如表6 所示,通過無監督下小樣本圖像分類方法對比分析,發現其核心在于充分利用數據增強的方法,實現方法各不相同,均取得了較好的實驗結果。隨之而來的是數據增強手段帶來了缺陷,如引入噪聲等。
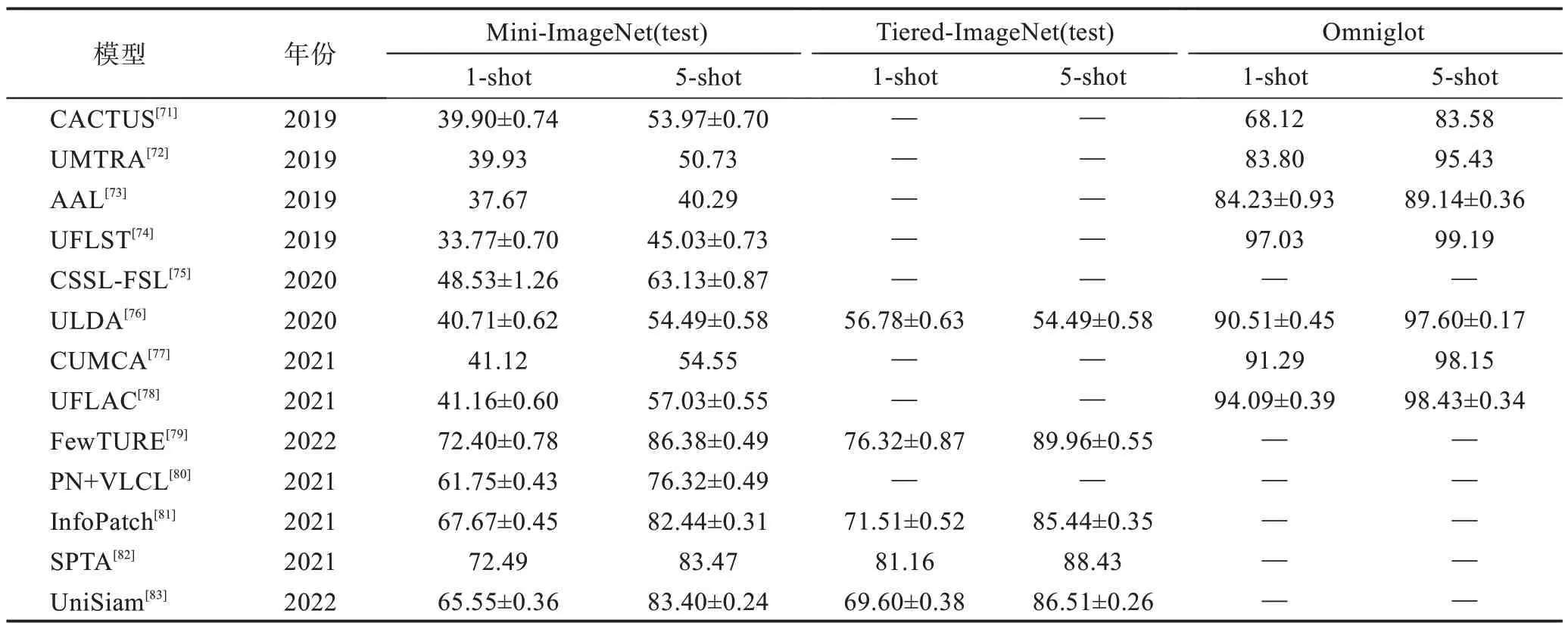
表5 無監督下小樣本圖像分類方法準確率對比Table 5 Accuracy comparison of unsupervised few-shot image classification methods 單位:%
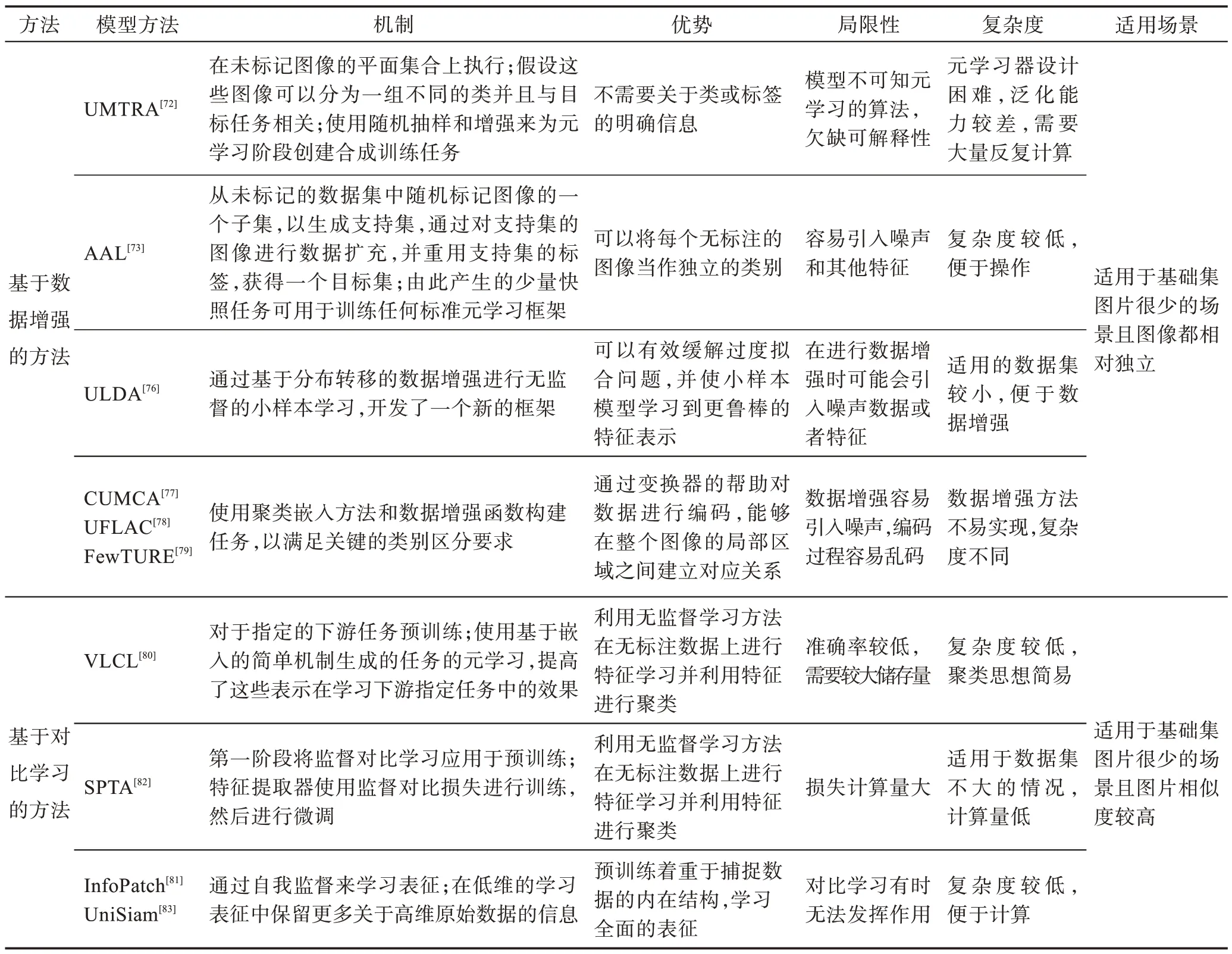
表6 無監督下小樣本圖像分類方法對比分析Table 6 Comparative analysis of unsupervised few-shot image classification methods
5 小樣本圖像分類挑戰與未來方向
隨著計算機硬件以及深度學習算法的發展,基于深度學習的人工智能算法在各行各業起到至關重要的作用,但是在許多領域中樣本量很少或者標記樣本很少,并且樣本的標注耗費大量的人力物力。近年來小樣本圖像分類已經得到越來越深入的研究和發展,且產生較好的效果,但是與人類的準確率相比仍然有不小的差距。下面列舉了一些當下小樣本圖像分類面臨的困難。
5.1 小樣本圖像分類方法總結
小樣本圖像分類各方法的機制以及優缺點對比如表7 所示。有監督下小樣本圖像分類技術主要有度量學習方法、元學習方法和數據增強方法。度量學習模擬樣本間距離分布,采用非參估計方法進行分類,優勢是便于理解并且直觀,便于計算和公式化,但采用較為簡單的距離來衡量相似度的方法準確率會有所降低。元學習方法通過優化模型的參數或學習算法來加速網絡學習,使模型具有學習能力,能夠學習到一些訓練過程之外的知識,但元學習器設計困難,復雜度較高,泛化性也不理想。數據增強方法為小樣本圖像分類數據集生成新數據,不需要對模型進行調整,只需利用輔助數據或者輔助信息擴充數據或增強特征,但在進行數據增強時可能會引入噪聲數據或者特征,對分類效果產生負面影響。半監督下小樣本圖像分類技術主要有一致性約束方法和偽標注方法。一致性約束方法基于低密度可分假設,相同類別的樣本形成高密度,分類超平面如果位于高密度區,會約束每個訓練樣本經過數據擾動之后,網絡的輸出與原始訓練樣本對應的輸出一致,需要保持所有訓練樣本的歷史類別預測值,故具有較大的存儲開銷。偽標注方法為無標注樣本賦予“偽標簽”,然后結合原始有標注數據一起進行有監督訓練,但會涉及到高計算復雜度的矩陣計算,同時不能與特征學習部分一起進行端到端的訓練。無監督下小樣本圖像分類技術主要分為基于預置任務的無監督和對比學習。預置任務下多數方法均為基于聚類的思想,利用得到的特征進行聚類,轉化成有監督小樣本問題來解決,目標樣本在特征空間里展示出很好的聚類結果,只利用少量的標注樣本即可獲得不錯的分類模型。普通的無監督預訓練獲得的特征的表達能力不夠好,無法形成更好的類簇。對比學習方法通過自我監督來學習表征,在低維的學習表征中保留更多關于高維原始數據的信息。預訓練著重于捕捉數據的內在結構,學習全面的表征,是較為新型且有效的方法,但有待進一步研究擴展。
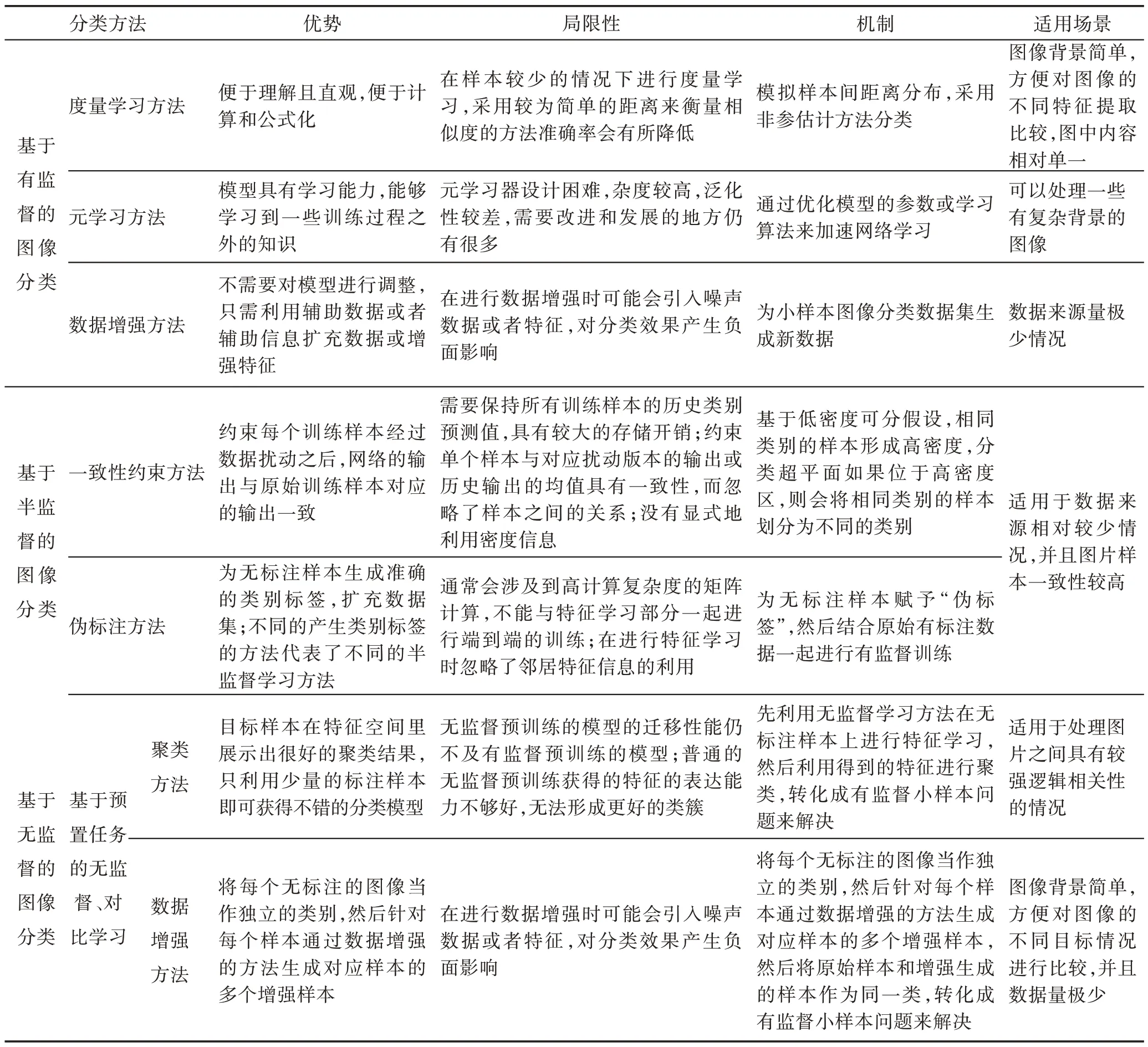
表7 小樣本圖像分類各方法機制及優缺點對比Table 7 Comparison of mechanisms and advantages and disadvantages of few-shot image classification methods
5.2 小樣本圖像分類挑戰
(1)深度學習的可解釋性
神經網絡模型被廣泛地應用到小樣本學習等領域,隨著大量研究者參與,特征提取等卷積神經網絡模型日漸復雜。深度學習模型本身是一個黑盒模型,有許多結構和特點:第一個特點就是神經元多并且參數眾多;第二個特點是結構分層,且隱含層眾多;第三個特點是神經網絡的參數對應的特征不是人工設計的,是神經網絡在學習過程中自己進行選擇的。研究者無法得知神經網絡模型到底學習了什么,也不知道每一個參數的具體含義是什么,因此無法解釋整個模型的運作機制,無法得出明確而有針對性的優化方案來解決問題,只能通過大量實驗不斷地嘗試提高性能的方法。因此一個好的可解釋性工作對小樣本甚至任何研究方向都有指導作用。
(2)數據集的挑戰
現有的小樣本學習模型都需要在大規模數據上預訓練。圖像分類任務中目前僅有ImageNet 作為預訓練數據集,而文本分類中缺少類似的預訓練數據集,導致很多小樣本圖像分類方法缺少普適性,只適合在特定的數據集上發揮好的結果。在小樣本圖像分類任務中Mini-ImageNet 和Omniglot 是兩個被廣泛使用的標準數據集,最近的斯坦福犬[84]和CUB 細粒度分類等數據集也開始被人們用于測試,但并沒有ImageNet數據集使用廣泛。
(3)模型預訓練的挑戰
在已有的小樣本學習方法中,不管是基于模型微調的方法還是基于遷移學習的方法,都需要在大量的非目標數據集上對模型進行預訓練,致使小樣本學習一定程度上變成偽命題。因為模型的預訓練依舊需要大量標注數據,從本質上來看與小樣本學習的定義背道而馳。從根本上解決小樣本問題,就要做到不依賴預訓練模型,需研究利用其他先驗知識而非模型預訓練的方法。
(4)其他挑戰
在小樣本圖像分類中,將各種基于深度學習的算法技術有效地結合起來,以產生更好的效果。例如,將元學習與度量學習相結合,在進行特征提取之前,通過元學習預處理數據,設置更加合理的支持集和查詢集。雖然已經有研究者開始嘗試,但是想實現這樣的效果卻十分困難,幾個學習算法的相互結合,有時候反而會導致小樣本學習的性能下降。
5.3 小樣本圖像分類未來發展方向
通過對當前小樣本圖像分類研究進展進行總結,以展望未來小樣本學習的發展方向。
(1)在數據層面訓練模型時嘗試利用其他先驗知識,或更好地利用無標注數據。探索和發現不依賴模型預訓練,使用先驗知識就能取得較好結果的方法。雖然在諸多領域中標注樣本數量較少,但在真實世界中存在大量無標注數據,并蘊含著大量信息,利用無標注數據的信息訓練模型值得更加深入研究。
(2)對度量學習提出更有效的神經網絡度量方法。度量學習在小樣本學習中的應用已經相對成熟,但是基于距離函數的靜態度量方法改進空間較少,使用神經網絡來進行樣本相似度計算可能成為度量方法的主流。因此研究如何設計性能更好的神經網絡度量算法,以提高實驗的準確率。在網絡上提取圖像特征時進行更有針對性的處理,例如使得特征向量之間相互垂直,采用掩碼恢復等方式,以便于后面的相似度區分。
(3)元學習作為小樣本學習的熱點研究方向之一,元學習模型還繼續有待提升。如何設計元學習器使其學習到更多有用的信息或更有效的元知識,也將是今后一個重要的研究方向。
(4)對比學習通過自動構造相似實例和不相似實例,習得一個表示學習模型,通過此模型,使得相似的實例在投影空間中比較接近,而不相似的實例在投影空間中距離比較遠。將對比學習與小樣本學習有效地結合來達到更好的性能,是值得研究發展的方向。
(5)隨著主動學習和強化學習框架的興起,可以考慮將這些先進框架應用到小樣本學習。主動學習是機器學習中的一種主要研究范式,它專注于為未標記的實例請求標簽,從而最大限度地提高性能。主動學習旨在使數據標記成為學習過程的一部分,以便模型選擇樣本進行標記。
(6)通過注意力機制來提高小樣本圖像分類準確率。注意力機制的提出,實際上就是讓神經網絡能夠模仿人類,關注圖像中更加重要的特征信息,與小樣本學習的思想十分貼合。這種做法將神經網絡原有的為圖像平均分配資源的方式,改為根據圖像的重要程度分配資源的方式。重要的信息權重高,不重要的信息權重低,從而能夠更快、更準確地對圖像進行分類。
(7)嘗試更多小樣本學習方法的結合。現有小樣本學習大多數基于某個方法的研究,今后可以嘗試將各個方法進行結合,例如度量學習與元學習的結合、度量學習與注意力機制的結合或者元學習與對比學習等方法的結合,以達到更好的效果。
6 總結
本文首先介紹了小樣本學習的研究背景和問題定義;然后介紹了用于小樣本學習的常用算法,以及小樣本圖像分類在有監督、半監督和無監督下的技術發展;最后總結了小樣本圖像分類的挑戰和未來發展方向。小樣本學習領域目前仍然具有很多值得研究者們去突破的方向。小樣本學習在與常規學習相比較時,性能仍然存在一定的差距,因此還需要研究者們繼續探索。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
人大建設(2020年4期)2020-09-21 03:39:12
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
