封閉域深度學習事件抽取方法研究綜述
2023-03-10 00:10:24焦磊云靜劉利民鄭博飛袁靜姝
計算機與生活 2023年3期
焦磊,云靜+,劉利民,鄭博飛,袁靜姝
1.內蒙古工業大學 數據科學與應用學院,呼和浩特010080
2.內蒙古自治區基于大數據的軟件服務工程技術研究中心,呼和浩特010080
“事件”是指在某個特定的時間片段和地域范圍內發生的,由一個或多個角色參與,由一個或多個動作組成的一件事情[1]。事件抽取作為自然語言處理(natural language processing,NLP)中的一項重要任務,在許多領域中都有著很高的應用價值,給人們帶來了很大的便利。例如,從事件中提取出結構化信息可以填充知識庫,為信息檢索提供有價值的信息,以便進一步進行邏輯推理[2-3]。并且事件抽取也能用于政府公共事務管理,使相關人員及時掌握社會熱點事件的爆發和演變,有助于當局迅速做出反應與決策[4-8]。在金融領域,事件抽取還可以幫助公司快速發現其產品的市場反應,并將推斷用于風險分析和交易建議[9-11]。在生物醫學領域,事件抽取可以用來識別科學文獻中描述的生物分子(例如基因和蛋白質)的狀態變化或多個生物分子之間的相互作用,以了解其性質和(或)發病機制[12]。簡而言之,許多領域都可以從事件抽取技術和系統的進步中受益。
傳統的事件抽取方法,需要進行特征設計,著重構建有效的特征來捕獲文本中不同組成成分之間的關系,來提高事件抽取的性能。而深度學習事件抽取方法不僅可以自動構建語義特征,節省人工成本,還能自動組合構建更高級的語義特征,獲得更加豐富的事件信息。近年來眾多研究者利用深度學習模型實現事件抽取,取得很多突破性的進展。
面對眾多的事件抽取方法,文獻[1]較早對事件抽取方法進行歸納整理,為后續的相關工作提供了極大的幫助。但該文獻更多是對事件抽取的任務進行定義,方法總結較少,對于發展趨勢的描述較為模糊,存在一定的局限性。而當前調研文獻的歸納方法較為簡單,只是根據神經網絡的不同而進行分類,并不能把握其背后的發展邏輯。本文通過大量調研,總結其方法思想,將深度學習事件抽取方法進行分類并詳細介紹,最后總結對于事件抽取方法的發展趨勢。
1 封閉域事件抽取任務定義
事件抽取作為自然語言處理中的一項重要技術,其目標是從新聞文本中提取出該新聞包含事件信息的元素,例如時間、人物、地點等。而封閉域事件抽取則是指事件抽取使用預定義的事件模式從文本中發現和提取所需的特定類型的事件并且進行實驗的數據已通過人為定義標注,提供了評測的標準。
ACE 2005 是一個多語言語料庫,新聞數據種類及來源較為廣泛,并且由于其任務定義明確,故其成為事件抽取任務中最具影響力的標桿。國內外的研究大部分都在該數據集上進行實驗,此后構建的事件抽取數據集也大多遵循其事件定義。綜上所述,本文沿用ACE[13]中的術語定義事件結構:
(1)事件提及:描述事件的短語或句子,包括一個觸發詞和幾個論元。
(2)事件觸發詞:能夠清楚地表達事件發生的主詞,通常是動詞或名詞。
(3)事件參數:在事件中充當參與者或具有特定角色的屬性的實體、時間表達式或值。
(4)參數角色:指事件參數與其參與的事件之間的關系。
文獻[14]首先提出將ACE 事件抽取任務分為四個子任務:觸發詞檢測、事件類型識別、事件參數檢測和參數角色識別。例如,在“5 月14 日,據《印度經濟時報》報道,IBM 將裁員300 人,主要集中在軟件服務部門。”這條新聞中存在“裁員”類型的事件。觸發詞識別器會首先識別句子中的事件提及并判斷事件類型;接著會提取出這條新聞中與“裁員”事件相關的事件參數(事件參數檢測)并根據預定義好的事件結構標注出它們各自的參數角色。如圖1 所示,圖中左邊是ACE 2005 中預先定義好的事件結構,右邊的事件抽取模型代表觸發詞檢測、事件類型識別、事件參數檢測和參數角色識別四個任務,事件抽取模型根據預定義事件類型表提取出文本中包含的事件結構。
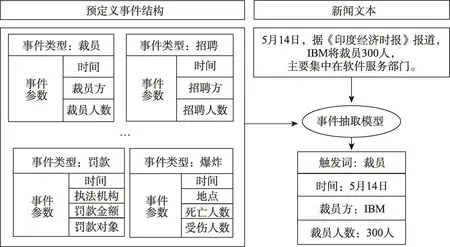
圖1 封閉域事件抽取示例Fig.1 Example of closed domain event extraction
2 基于深度學習的封閉域事件抽取模型
近年來,隨著深度學習的發展,神經網絡已經廣泛地應用于自然語言處理任務中,并且取得了良好的處理效果[15-24]。研究者同樣利用深度學習方法為事件抽取進行建模,并針對不同的應用場景,例如數據文本長度、數據量等,提出了不同的解決方案。本文根據不同的應用場景,將深度學習事件抽取方法分為句子級、篇章級、低資源事件抽取方法三大類,并對類別中的經典方法進行詳細介紹。
2.1 句子級事件抽取
在句子級事件抽取研究中,根據子任務之間的相關性,研究者將事件抽取模型分為以下兩個模塊:
(1)事件檢測模塊:識別句子中的觸發詞并判斷事件類型。事件檢測模塊一般包含特征提取層和分類層。特征提取層用來捕獲文本中包含的高級語義信息,分類層則對文本中的每個字/詞進行分類。最后根據分類結果識別觸發詞,完成事件檢測。
(2)事件參數提取模塊:識別句子中的實體并判斷參數角色類型。在網絡結構上,該模塊與事件檢測模塊類似。但在參數角色識別時,模塊要根據事件類型對事件參數進行分類。因此在構建事件參數提取模塊時,需要導入事件檢測模塊的信息。
通過以上內容,可以看出兩個模塊之間具有較強的依賴關系。構建模塊之間的關聯不僅是句子級事件抽取方法的主要挑戰,同時也是各個研究工作的不同之處。本文將按照不同的關聯方法,對這些句子級事件抽取方法進行分類,并介紹每種分類中的代表性工作。
2.1.1 基于管道方式的事件抽取方法
使用深度學習實現事件抽取的過程中,最初工作者們使用管道(Pipeline)方式的思想實現事件抽取。即將事件抽取任務分解為一個類似流水線任務,對這兩個模塊分別建模,先識別出事件的類型,然后根據事件類型對其進行事件參數提取。圖2 為管道模型的處理流程。
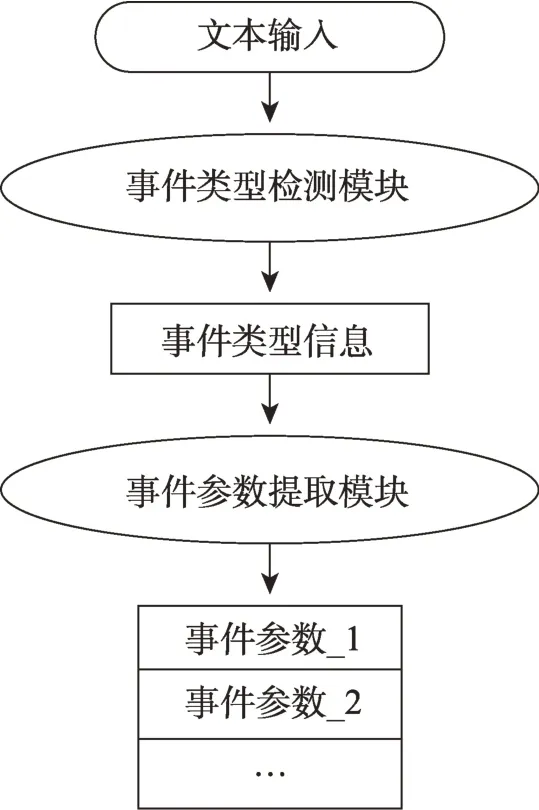
圖2 管道式事件抽取模型處理流程Fig.2 Pipeline event extraction model flow chart
而對于神經網絡的選擇上,研究者最先提出使用卷積神經網絡(convolutional neural networks,CNN)進行事件抽取。文獻[25]是最早地將神經網絡應用于事件抽取的研究工作之一,該方法基于CNN 進行建模。本文提出了一種動態多池卷積神經網絡(dynamic multi-pooling convolutional neural networks,DMCNN),該方法通過動態卷積層分別提取單詞和句子級別的文本特征,從而獲取句子的各個部分的有效信息。DMCNN 的輸入包含三部分:單詞嵌入、位置嵌入以及事件類型嵌入。在事件檢測時,使用DMCNN 對輸入進行卷積提取語義特征后,將單詞級別特征與句子級別特征分別池化獲取信息,最后使用Softmax 分類得到觸發詞,如果存在觸發詞,則進行事件參數提取。在事件參數提取過程中,本文同樣使用DMCNN進行事件參數提取。不同的是,在池化過程中,DMCNN 會對觸發詞以及候選的事件參數以及句子級別特征分別池化再進行分類。
此外也有一些工作者提出了基于CNN 改進的模型[26-29]。例如,文獻[27]設計了一個語義增強的模型Dual-CNN(dual-representation convolutional neural network),它在傳統的CNN 中增加了語義層來捕捉上下文信息。文獻[28]提出了一種改進的CNN 模型PMCNN(Parallel multi-pooling convolutional neural networks)用于生物醫學事件抽取。在獲取文本深層表達特征時,PMCNN 會并行執行不同大小的濾波器,在不同的細粒度上對文本特征進行卷積操作,因此它可以捕獲句子的組合語義特征。此外PMCNN 還利用基于依存關系的嵌入來表示單詞的語義和句法表示,并采用校正的線性單元作為非線性函數。文獻[29]使用自舉(bootstrapping)的方法構建了全局上下文的表示,并將這種表示集成到CNN 事件抽取模型中。
但對上述使用CNN 的模型來說,因為CNN 會對連續的單詞執行卷積操作,獲取當前單詞與其相鄰單詞的上下文關系,所以它們不能很好地捕捉到距離較遠的兩個單詞之間潛在的相互依賴關系。而深度學習中的另一種經典神經網絡——循環神經網絡(recurrent neural network,RNN)可以利用直接或間接連接的任何兩個單詞之間的潛在依賴關系,這使得它能夠廣泛應用于許多自然語言處理任務[30],因此一些研究人員使用RNN 或者CNN+RNN 來進行事件抽取。文獻[31]提出了一種方法,首先使用RNN 來獲取文本在時序上的句子特征,然后使用了一個卷積層對文本進行卷積操作以獲取短語級別的文本信息,最后將這兩種特征信息融合后進行事件抽取。表1 總結了上述方法的貢獻及其缺陷不足。
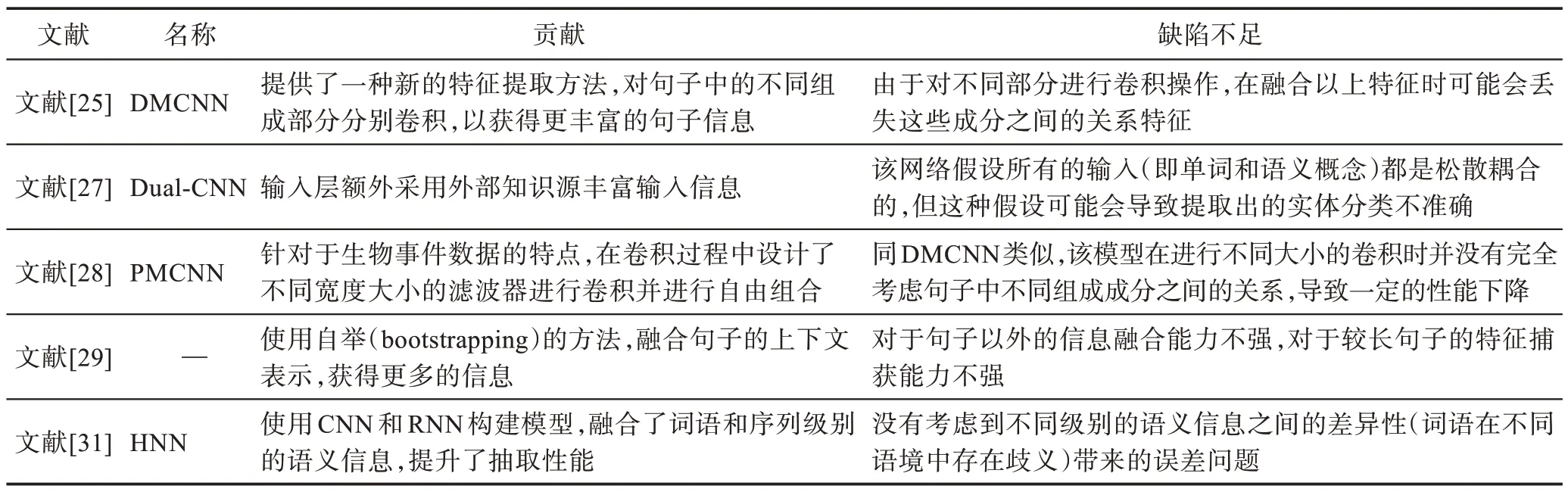
表1 基于管道模型的事件抽取方法總結Table 1 Summary of event extraction methods based on pipeline model
2.1.2 基于聯合方式的事件抽取方法
基于聯合方式的事件抽取方法就是利用觸發詞與事件參數之間的關系,為兩個模塊構建依賴關聯,使得兩個模塊可以進行信息交互,達到抽取性能的提升。如圖3 所示,聯合模型利用觸發詞與事件參數之間的關聯性為兩個子任務構建依賴關系。文獻[32]為事件抽取設計了一個雙向循環神經網絡體系結構(joint event extraction via recurrent neural networks,JRNN),該模型由雙向循環神經網絡組成,每個循環神經網絡都由門控神經單元(gated recurrent unit,GRU)[33]構成。同時,為了構建兩個模塊之間的依賴關系,文獻[32]利用記憶矩陣保存三種依賴信息:(1)觸發詞類型之間的依賴信息;(2)事件參數之間的依賴信息;(3)觸發詞和事件參數之間的依賴信息。該方法的聯合提取階段包括兩部分:編碼部分和預測部分。在編碼部分,利用JRNN 捕獲語義特征。在預測部分,在聯合抽取時,先進行事件類型檢測,然后將提取出的觸發詞也當作事件參數提取模塊輸入的一部分進行分類。最后對記憶矩陣進行更新,完成聯合抽取過程。除此之外,句子中單詞之間的關系也可以用來擴充基本的循環神經網絡結構。例如,文獻[34]通過將兩個神經元的句法依賴連接添加到模型中,設計了一個dbRNN(dependency-bridgeRNN)。除了使用依賴橋之外,句子的句法依賴樹也可以直接用來構建樹結構的循環神經網絡[35]。在經典的Bi-LSTM(bi-directional long short-term memory)的基礎上,文獻[36]通過轉換用于中文事件檢測的句法依賴分析器的原始依賴樹進一步構建了以目標詞為中心的依賴樹。文獻[37]提出用外部實體本體知識進一步擴充依賴樹,用于生物醫學事件抽取。文獻[38]通過引入抽象語義表示(abstract meaning representation)圖[39]來減少長依賴,同時使用了圖卷積網絡(graph convolutional network,GCN)[40-42]來對其建模。在輸入層使用Bi-LSTM 對文本序列、詞性嵌入、實體標簽以及位置信息進行編碼,然后使用圖卷積網絡進行句法信息特征提取。在聯合抽取中使用的方法大體與JRNN 類似,不同的是,在觸發詞識別模塊中使用自注意力機制來提升提取觸發詞的性能,然后將觸發詞和特征序列拼接作為事件參數提取模塊的輸入進行分類判斷,損失函數使用聯合負對數似然損失函數。雖然基于聯合模型的事件抽取方法將子任務之間的關系連接起來減少傳播誤差,但與此同時也產生了訓練困難、遷移性較差等問題。表2 總結了基于聯合方式的事件抽取方法的貢獻及不足。
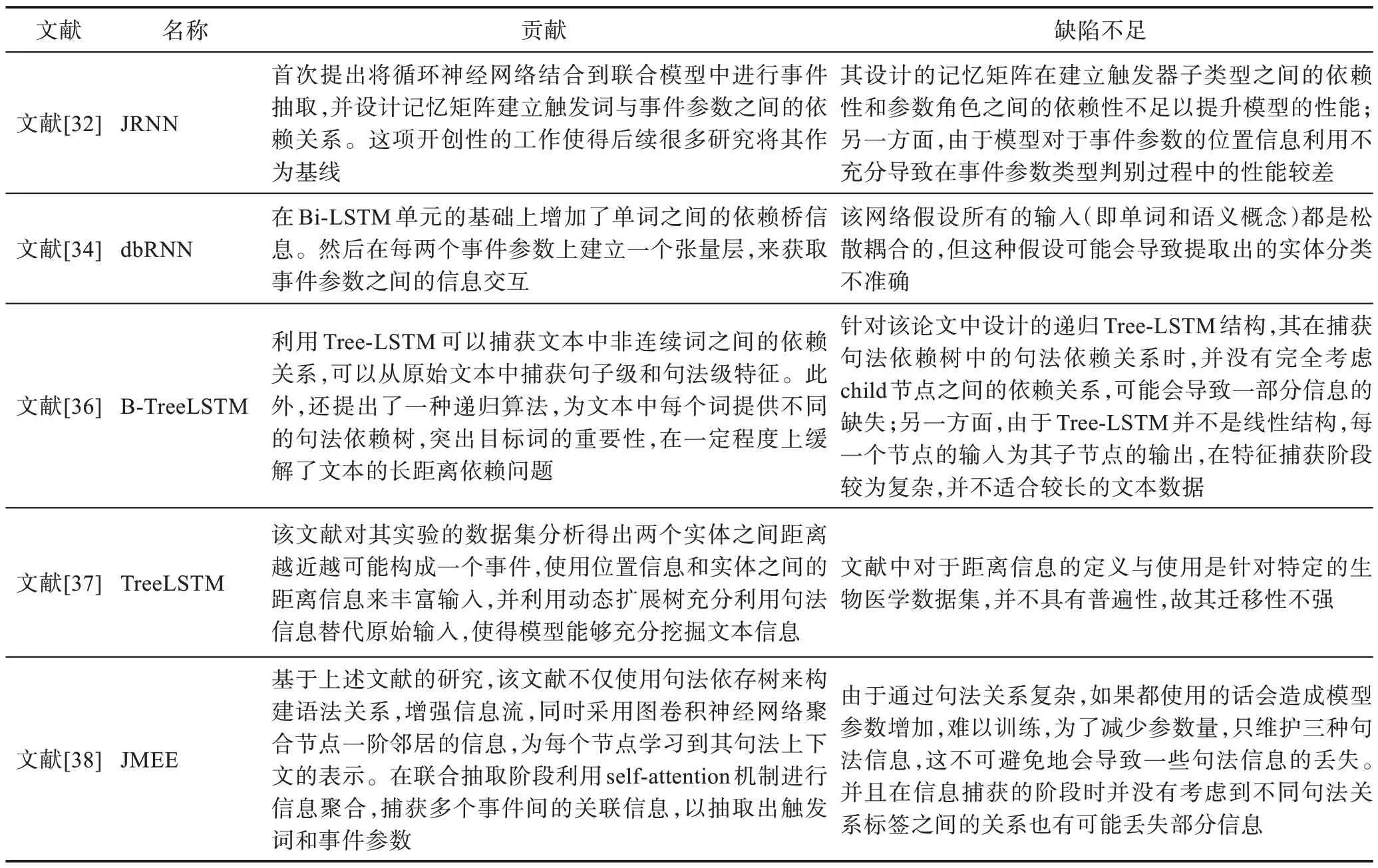
表2 基于聯合模型的事件抽取方法總結Table 2 Summary of event extraction methods based on joint model

圖3 聯合模型框架圖Fig.3 Framework diagram of joint model
2.1.3 基于端到端的事件抽取方法
采用端到端(end-to-end)的思想構建網絡模型,以純文本作為輸入,以事件結構作為輸出。相較于上述兩種事件抽取方法,端到端的事件抽取方法模型不再對某一任務單獨設計模塊,省去在每個任務執行前將數據重新標注輸入的過程,達到簡化模型和減少誤差傳播的效果。此外,得益于預訓練語言模型(ELMO[43]、BERT[44]等)強大的語言表征和特征提取能力,研究者可以從閱讀理解、文本生成等不同的角度重新審視事件抽取的任務結果,使得事件抽取的發展進入了一個新的階段。本文從以下三種類型介紹基于端到端的事件抽取方法。
(1)基于序列標注的事件抽取方法
序列標注(sequence labeling)方法就是利用模型對文本序列中的每個位置標注一個相應的標簽,在NER 中有著廣泛的應用[15]。而在事件抽取中,事件參數本質就是一個在特定類型事件下扮演相應角色的實體。如圖4 所示[45],當句子輸入模型后,BERT 捕獲句子中的語義特征并進行序列標注,然后使用CRF條件隨機場(conditional random field,CRF)層約束生成的標簽,最終得到每個實體的標注結果。這種方式簡化了事件抽取,并且取得了不錯的效果。但是面對事件抽取中角色重疊、同義消除等問題,還具有一定挑戰性。
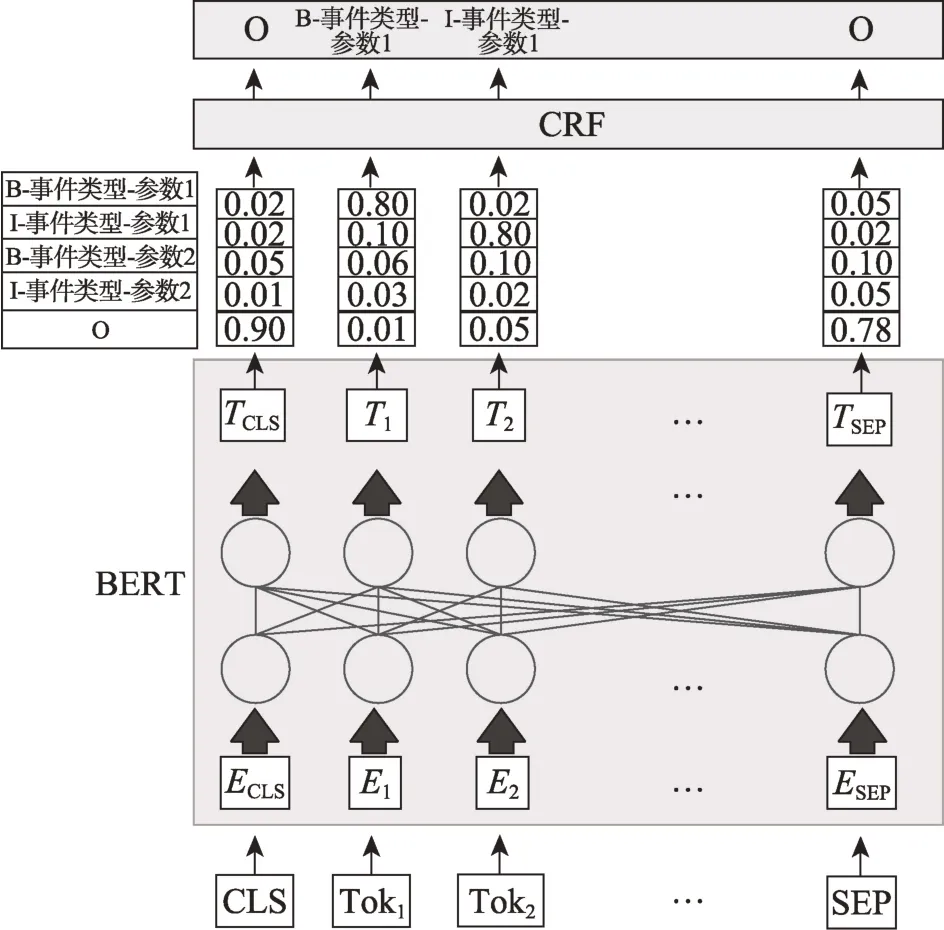
圖4 BERT+CRF 實現事件抽取Fig.4 BERT+CRF for event extraction
針對角色重疊問題,文獻[46]提出了一種基于預訓練語言模型的多層標簽指針網絡(pre-trained language model based multi-layer label pointer-net,BMPN)。BMPN 在進行序列標注時,每個事件參數的起始位置都由一個頭指針(start)和尾指針(end)組成的二分類網絡確定,同時疊加多則二分類網絡,便可以解決角色重疊問題。表3 總結了基于序列標注的事件抽取方法的貢獻及不足。

表3 基于序列標注的事件抽取方法總結Table 3 Summary of event extraction methods based on sequence labeling
(2)基于機器閱讀理解的事件抽取方法
基于機器閱讀理解(machine reading comprehension,MRC)的事件抽取方法通過定義問題引導模型在文中找到答案。相較于以往的工作,MRC 方法并不依賴實體識別。另外,在不同的事件中,事件參數可能含有相同的語義相似性。通過MRC 方式能使模型更好地學習到不同事件參數之間的語義相似性,從而提高模型的泛化能力。
文獻[47]是第一個基于MRC 的事件抽取方法。圖5 為文獻[47]的模型結構圖,整體模型分為觸發詞識別和事件參數抽取兩個階段,觸發詞抽取和論元抽取均設置了問題模板。第一階段,利用預先設定的觸發詞問題模板,識別文本中的觸發詞;第二階段,利用預先設定的參數模板識別事件參數。文中設計了三種抽取模板:針對觸發詞抽取階段的問題模板,作者直接將觸發詞設計為問題(question);對于事件參數抽取,根據事件參數的不同類型進行提問,例“who for person”“where for place”等;最后一個問題模板則是針對觸發詞與事件參數之間的關系進行設計,例如“[who for person] is the [argument] in[trigger]?”。三個模板逐層遞進,充分利用語義信息。而文獻[48]針對問題模板定義過于復雜的問題,提出了一種更加抽象的定義方法,將參數模板定義為“Person-based”“Normal”“Place-based”三類。表4為基于MRC 的事件抽取方法的貢獻及不足。
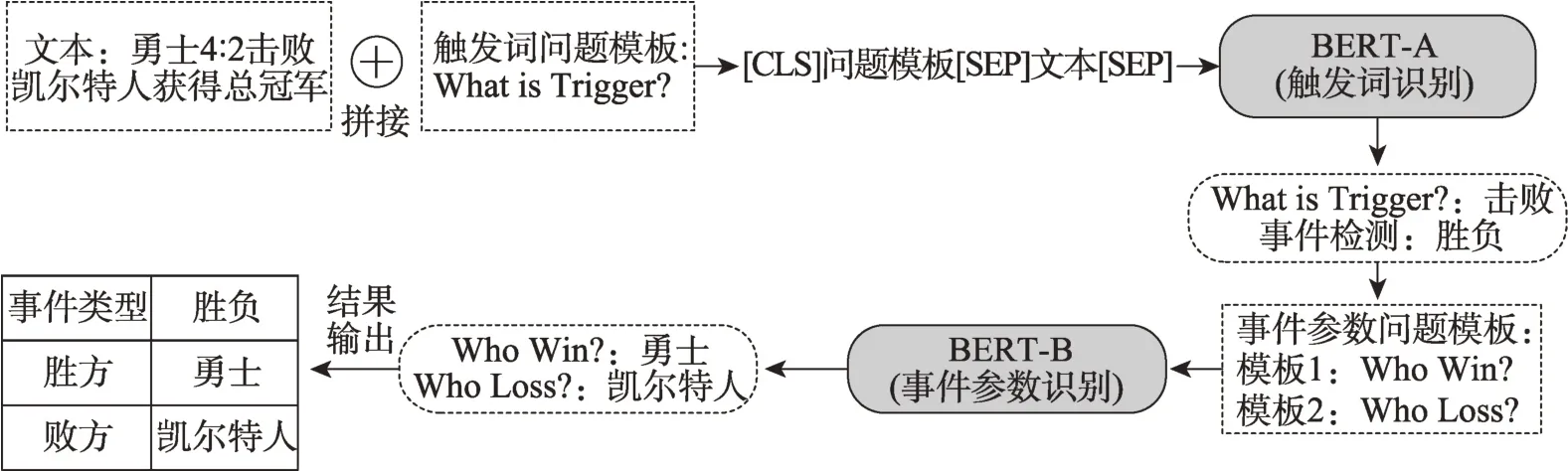
圖5 基于MRC 的事件抽取方法Fig.5 Event ExtractionbyMRC

表4 基于MRC 的事件抽取方法總結Table 4 Summary of event extraction methods based on MRC
(3)基于模板提示的事件抽取方法
采用基于模板提示的方法,就是在模板的指導下進行事件的識別和抽取,模型從文本里找到“答案”并填充到問題模板中,屬于序列生成任務。與MRC 的事件抽取方法類似,該方法并不依賴實體識別,同樣具有較強的遷移性。但不同之處在于,基于模板提示的方法直接針對不同的事件類型構建模板,不需要對觸發詞以及事件參數單獨構建,減少了額外的人工操作。
基于模板提示的事件抽取方法遵循序列生成任務中的Seq2Seq 方法,如圖6 所示,模型將給定輸入序列編碼為隱藏狀態,利用解碼器將該隱藏狀態解碼為另一個序列并輸出。文獻[49]提出了一個基于模板提示的事件參數識別模型。該模型架構使用了預訓練語言模型BART[50]、T5[51]。在進行事件參數抽取時,首先將模板和文本拼接輸入到BART 編碼器,然后編碼器對模板中各個參數占位符進行信息交互,同時生成文本編碼。最后BART 解碼器根據文本編碼中的詞匯輸出模板中的占位符生成對應的具體內容,完成事件抽取。文獻[52]利用不同粒度的模板信息,構建了一個通用信息抽取(universal information extraction,UIE)模型。該模型設計了一種結構化模板,能夠同時實現關系抽取、事件抽取等四種信息抽取任務。
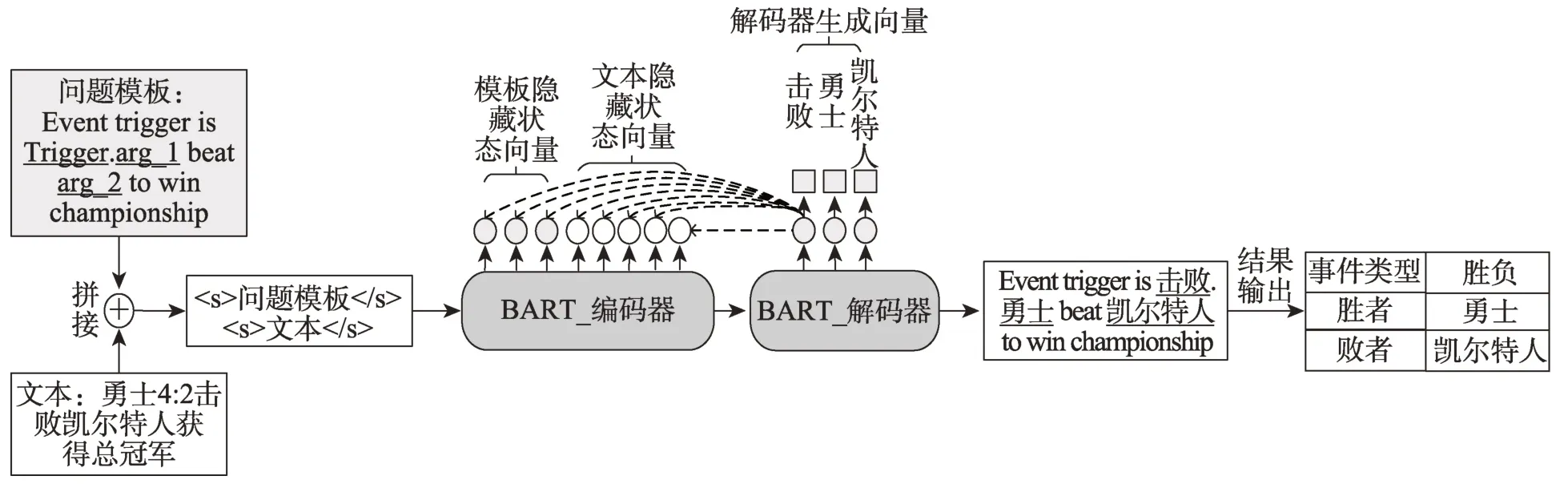
圖6 基于模板的事件抽取方法Fig.6 Event extraction method based on template
面對上述方法中人工構建的問題模板,文獻[53]認為,人工構建的模板不一定最優,并且在抽取時只考慮當前事件類型,忽略了其他事件之間的聯系。故文獻[53]利用Prefix-Tuning(在保持模型參數固定的情況下,只對特定任務向量優化)方法融合上下文及特定事件類型信息的動態前綴,解決上述存在的問題。文獻[54]研究了在抽取設置下的提示調優,并提出了一種新的方法實現論元抽取的參數交互。它擴展了基于問答的模型來處理多個參數抽取并利用了預訓練模型的優勢。該文獻提出了三種類型模板:人工模板、融合模板和軟提示模板。使得模型在句子和文檔層面都具有不錯的表現,并且簡化了模板提示式設計的要求。表5 總結了基于模板提示的事件抽取方法的貢獻及不足。
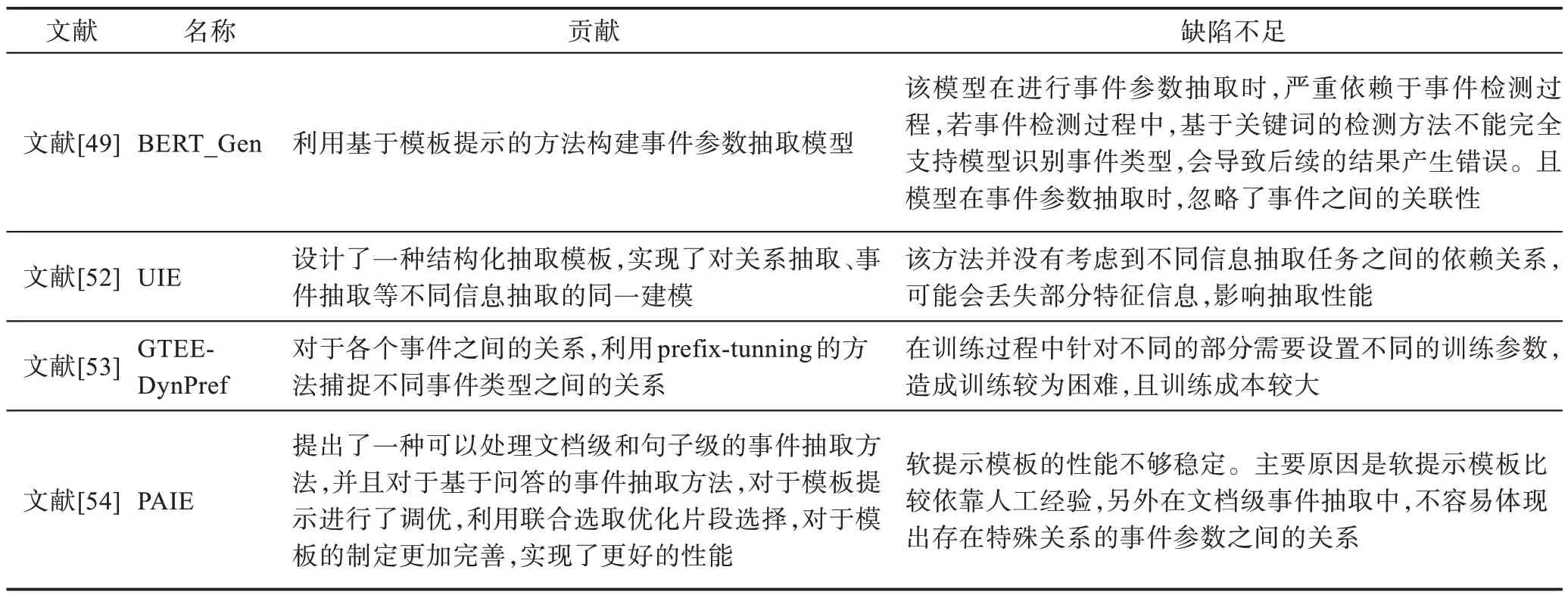
表5 基于模板提示的事件抽取方法總結Table 5 Summary of event extraction methods based on template
2.2 篇章級事件抽取方法
篇章級事件抽取方法是在文檔層面進行事件抽取,更加貼近現實世界中的實際需要。由于文檔由多條語句組成,包含更加復雜的全局語義特征。相較于句子級事件抽取方法,篇章級事件抽取方法不能單獨依靠觸發詞識別事件,還需考慮不同句子的語義信息。除此之外,文檔中待抽取的事件參數較為分散,如何讓篇章級事件抽取方法準確識別事件參數是一個亟需解決的問題。
傳統的句子級事件抽取一般分為觸發詞識別和事件參數提取兩個過程,而文獻[55]認為事件抽取的目標是識別事件類型并提取事件參數,而觸發詞只是這個任務的中間結果。并且在現實中,一類事件可能有多個觸發詞,若對數據進行觸發詞標注會消耗大量的人工成本。故基于無觸發詞的篇章級事件抽取方法成為主要的研究方法。
文獻[56]提出了一個基于無觸發詞設計的篇章級別事件抽取模型Doc2EDAG。該模型的核心思想是將文檔級別的事件表填充任務(document-level event table filling,DEE)轉化為基于實體的有向無環圖的路徑擴展任務(entity-based directed acyclic graph,EDAG)。Doc2EDAG 首先將文檔級別的文本信息編碼并進行命名實體識別,然后在事件檢測過程中設計了一種無觸發詞檢測,利用線性分類器對輸入中可能存在的事件進行事件觸發檢測;在事件參數提取過程中,首先識別出每個實體的參數角色并將相同實體進行融合,然后在事件表填充時,根據事件參數提取預定義的順序,使用有向無環圖的路徑擴展方法對其進行填充。另外在有向無環圖路徑擴展中還設計了一個記憶機制來對每個事件參數進行標記,以此解決同一事件參數屬于不同事件類型的問題。圖7為EDAG示意圖。
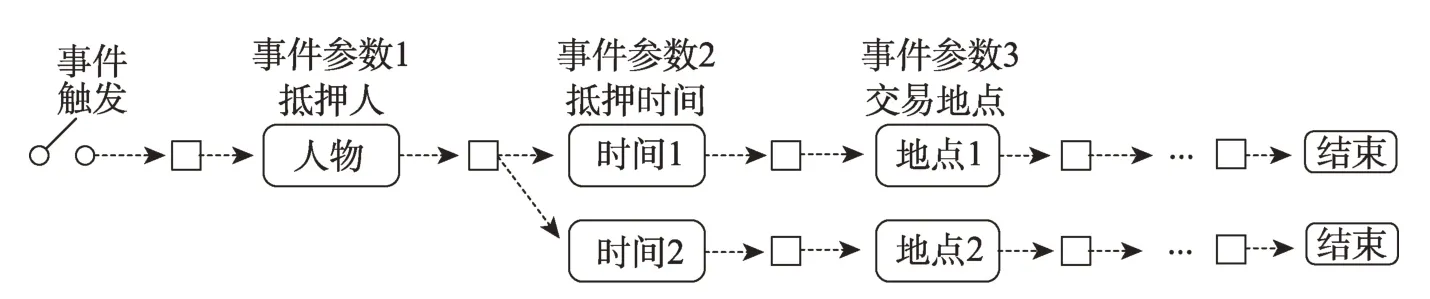
圖7 EDAG 示意圖Fig.7 Schematic diagram of EDAG
除此之外,研究人員也提出了其他的無觸發詞事件抽取方法[47-48]。針對單事件條件,文獻[47]提出了一個篇章級事件抽取模型ATTDEE(attention-based document-level event extraction),該模型的主要貢獻在于使用文檔中心句進行事件檢測。該方法認為當一篇文檔中包含一個事件時,總是存在一個提及事件發生且包含了最多關鍵參數的事件中心句,其他事件參數則有規律地分布在中心句的周圍。而對于關鍵參數的定義,文獻[57]采用了詞頻-逆文檔頻率(term frequency-inverse document frequency,TF-IDF)方法,用于判斷事件參數在文檔中的重要程度。在抽取階段,利用Transformer 根據事件參數的重要程度以及與中心句的距離進行抽取,簡化了單事件抽取過程。而在多事件條件下,文獻[58]利用Transformer 進行句子級編碼,同時使用圖神經網絡(graph neural network,GNN)將實體句子之間的關系連接起來,獲得更加豐富的文檔級語義信息。另外,受到文獻[56]的啟發,該模型設計了一個追蹤(Tracker)模塊用于多事件填充。Tracker 模塊按照預定義事件參數順序,利用約束擴展樹的方式進行路徑擴展,并持續跟蹤事件提取記錄,在進行事件抽取時查詢全局記憶,利用其他記錄的相互依賴信息,預測參數角色,從而提升模型的性能。表6 總結了基于無觸發詞的事件抽取方法的貢獻及不足。

表6 篇章級事件抽取方法總結Table 6 Summary of document-level event extraction methods
2.3 低資源事件抽取方法
由于深度學習方法需要調整神經網絡中的大量參數,通常數據集越大,標注質量越好,模型的效果就越好。然而,數據集的標注是一項巨大的工作量,需要消耗大量的成本,因此許多的數據集標注規模并不大,存在覆蓋領域小、標注質量差的問題。近年來,針對低資源下事件抽取效果差的問題,研究者提出利用小樣本學習[59-60]、引入外部知識[61-63]等方法,來提升事件抽取模型的性能。
2.3.1 小樣本事件抽取方法
小樣本學習(few-shot learning,FSL)與傳統監督學習不同,其思想是讓模型學習不同類別之間的差異性,從而獲得區分不同類別的能力。面對數據較少、樣本分布稀疏等問題,小樣本學習可以有效提高模型的識別性能和泛化能力。在事件抽取的研究中,研究者也提出了一些小樣本學習方法,它們的一般過程為:使用訓練集預訓練一個相似判斷網絡,讓其學習到不同事件類型之間的差異性。然后利用支持集提供的少量樣本對網絡進行微調,并為標簽信息生成特征向量。最后在預測階段,輸入一個查詢文本,模型生成對應的特征向量,將這個向量與標簽向量進行比較,得到最終的分類結果。
目前小樣本學習采用K-WayN-Shot(支持集中有K類,每類有N個樣本)的采樣方法。當N值較小時,模型可利用信息不充分,容易產生樣本偏差問題。文獻[59]提出了一種小樣本事件檢測方法,該方法利用動態神經網絡(dynamic memory networks,DMN)進行建模。使用DMN 多次從事件提及中提取上下文信息,從而讓模型學習更好的類型表示。面對同樣的問題,文獻[60]認為,此前的方法僅僅依賴查詢實例與支持集之間的相似信息,并沒有考慮支持集中的樣本類別信息。為此,文獻[60]在訓練函數中加入類間和類內損失,以此進一步增強模型的類型表示能力。
2.3.2 引入外部知識的事件抽取方法
目前研究使用的數據集大多存在數據規模小、類型分布不均的問題,這些問題會造成模型在稀疏的數據上訓練較差,而在密集的數據上過擬合。對此,研究者提出利用大型知識庫擴展訓練數據,從而提升模型識別性能[61-63]。
文獻[61]認為,FrameNet 知識庫包含大量的文本框架,每個文本框架由一個詞匯單元(lexical unit)和多個框架元素(frame elements)構成,該結構與ACE 2005數據集中定義的事件結構十分類似。因此,文獻[61]提出一種將FrameNet 的文本框架映射為ACE 事件結構的方法。首先,使用ACE 2005 數據集訓練一個神經網絡模型;然后,使用該模型對FrameNet 的句子進行類型識別,得到初始分類結果;最后,根據預先設計的假設對初始分類結果進行修正,得到擴展數據。
文獻[62]提出利用遠程監督[20]的方法對訓練語料進行自動標注。該方法首先利用Freebase 挑選出每個事件類型中的關鍵事件參數,再根據關鍵事件參數確定表達事件的觸發詞。獲得初始觸發詞集合后,通過詞嵌入技術將其映射到FrameNet 中,篩選出置信度高的觸發詞。最后使用一種軟遠程監督的方法重新篩選和標注句子,從而得到自動標注的數據。
針對標記數據的長尾問題(即某種事件類型僅有少量的標記數據),文獻[63]提出一種利用開放域觸發詞知識增強模型事件檢測的方法。具體而言,文獻[63]設計了一個師生(Teacher-Student)模型,首先使用WordNet 收集到的開放域觸發詞知識訓練Teacher模型,然后在Student 模型訓練時,使用沒有知識增強的數據來模仿Teacher模型的輸出,并利用KL 散度最小化概率分布之間的差異。最后,將Teacher 模型和Student模型進行聯合優化,完成整體模型訓練。
3 封閉域事件抽取數據集
本章介紹封閉域事件抽取任務的數據資源。隨著研究的發展,許多研究機構為事件抽取任務提供了數據支持,根據任務定義對數據進行人工標注,將其用于監督學習下的神經網絡訓練和測試中;數據標注一般由具有專業領域知識的人員完成,標注后的數據標簽可以認為是真實有效的。但是此種標注方法存在標注過程復雜、成本高昂的問題,導致許多公共數據集的規模以及覆蓋性不高。
由于數據的來源有多種方式,并且需要盡可能貼近現實,在原始數據收集時,在收集數據時會進行數據分析,對于獲取到的原始數據進行主題分類,得到這些數據的事件類型,例如人生、事故、組織行為等。然后針對以上每種事件類型的數據,會對其進行下一步的數據分析(關鍵詞分析等),得到事件子類型以及定義事件架構,最終對每條數據按照標準進行標注,得到可用的數據。
3.1 ACE 2005 數據集
ACE 2005 數據集[13]是語言數據聯盟(LDC)于2005 年發布的,ACE 2005 數據集定義了8 種事件類型和33 種子類型,為每一種子類型的事件構造了一種事件結構,其中的參數角色也不盡相同,所有事件子類型的事件參數角色總共有36 種。表7 羅列出了ACE 2005 數據集中的每種事件類型及其包含的子類型事件。ACE 2005 數據集是從新聞專線、廣播新聞、廣播對話、博客、新聞組、對話式電話語音6 種媒體收集而成,包括中文、英語、阿拉伯語3 種語言,共標注了599 個文檔和大約6 000 個事件。表8 提供了它們的數據來源統計。
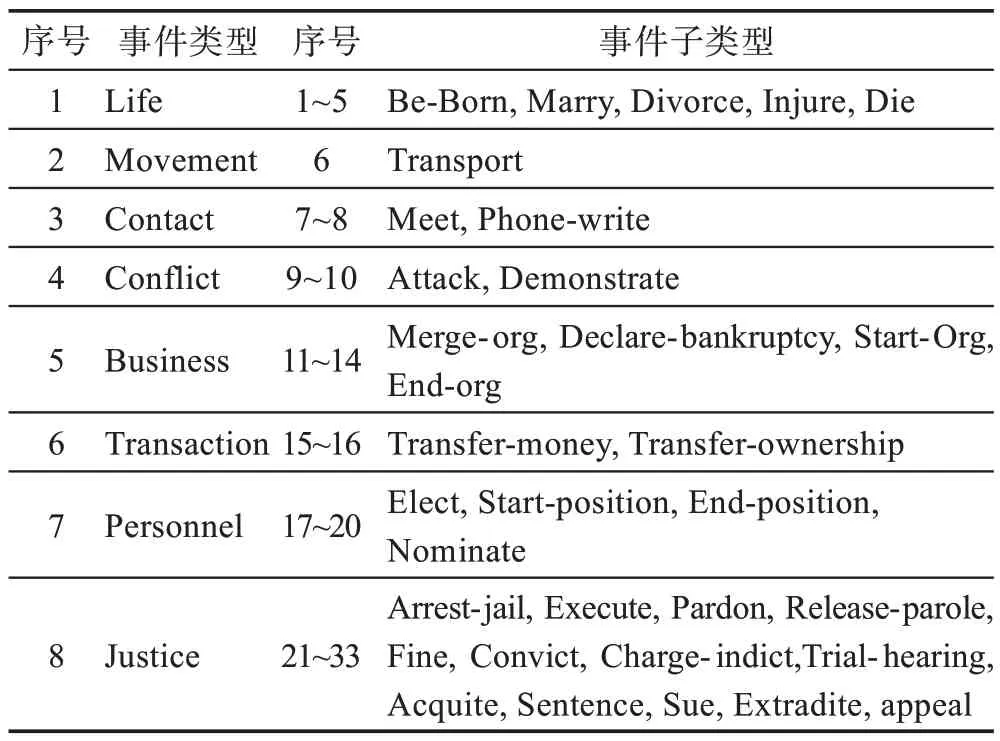
表7 ACE 2005 數據集的事件類型及其子類型Table 7 Event types and subtypes of ACE 2005 dataset
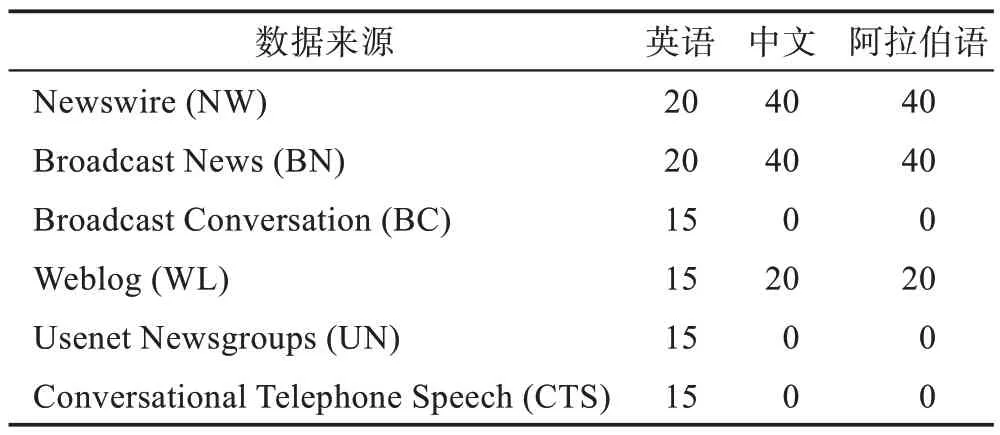
表8 ACE 2005 數據集的數據來源Table 8 Data source of ACE 2005 dataset 單位:%
3.2 TAC-KBP 數據集
TAC-KBP 2015 數據集[64]由LDC提供,用 于TAC-KBP 2015 事件跟蹤比賽,數據從新聞文章和論壇中收集而成,共有360 個標注文檔,其中158 個文檔作為先前訓練集,202 個文檔作為比賽正式評估的測試集。參考ACE 2005 數據集,TAC-KBP 2015 數據集定義了9 種事件類型和38 個子類型事件。在TAC-KBP 2015 數據集只有英文一種語言的數據,但在TAC-KBP 2016 比賽提供的數據集中增加了中文和西班牙語數據集。
3.3 DUEE1.0 數據集
DUEE1.0 數據集[45]由百度公司標注,用于2020語言與智能技術競賽事件抽取比賽當中。DUEE1.0數據集是目前公開的規模最大的句子級別的中文事件抽取數據集。DUEE1.0 數據集由19 640 個事件組成,包含65 個事件類型的1.7 萬個具有事件信息的句子。數據從百度信息流資訊中收集而成,相對于ACE 2005、TAC-KBP 數據集,DUEE1.0 中收集的中文事件包含很多新時代網絡用語,事件文本語法有著很高的自由度,事件抽取的難度也更大。該任務也接近于現實場景,例如,單個實例被允許包含多個事件,不同的事件被允許共享相同的參數角色,并且一個事件參數在不同的事件中被允許扮演不同的參數角色。
3.4 特定領域數據集
上述3 種數據集都是公共領域,包含不同的類型的新聞文本。而對于一些特定領域,因其含有大量專業名詞,所以需要對這些特殊領域進行單獨收集數據并標注,以提供更加可靠的數據支撐。
3.4.1 生物事件數據集
BioNLP(BioNLP-ST)生物文本挖掘比賽,其目的是為了從生物醫學領域的科學文獻中提取細粒度的生物分子事件。該比賽提供了多個由專業領域人員標注的生物事件數據集,例如Genia 數據集[65]、BioInfer數據集[66]。
3.4.2 金融領域事件數據集
針對金融領域事件,文獻[56]使用遠程監督算法[20]構建了一個大型的文檔級別金融領域事件抽取數據集ChFinAnn,共有32 040 個標注文檔,其中包含5 種金融事件類型。數據來源于2008—2018 年共10 年的中國金融事件新聞。表9 提供該數據集的事件類型及其事件參數類型。

表9 ChFinAnn 數據集的事件類型及事件參數類型Table 9 Event types and event parameters of ChFinAnn dataset
DUEE_fin 數據集[45]:由百度公司標注,用于2020語言與智能技術競賽事件抽取比賽當中。該數據集含有1.17 萬篇新聞,共標注了13 個事件類型及其對應的92 個論元角色類別。
4 事件抽取性能比較
上述這些神經網絡模型在不同的語料庫上進行了實驗,不太可能對它們進行公平的比較。本章主要將這些方法在不同數據集上的結果進行展示。
觸發詞識別(trigger detection,TD):識別出觸發詞在文本中的位置。
事件類型識別(trigger identification,TI):識別出觸發詞的事件類型與設定中的事件類型是否一致。
參數識別(argument detection,AD):事件參數是否被正確識別。
事件參數類型識別(argument identification,AI):事件參數類型被正確識別。
4.1 ACE 2005 數據集實驗結果
表10、表11 分別給出了在ACE 2005 數據集下中文和英文數據集中不同方法報告的事件提取結果,判斷指標為F1 分數。F1 分數是統計學中用來衡量二分類模型精確度的一種指標,兼顧召回率和精度。TP為真陽性(true positive),FN為假陰性(false negative),FP為假陽性(false positive)。
通過表10、表11 中結果可知,針對英文的事件抽取方法在數量方面要比中文多,同時性能也比中文好。造成該結果的原因在于:一方面,由于事件抽取任務提出與研究國外都比國內早,中文數據集的缺少以及標注質量不高,大多數研究者比較集中于英文事件抽取;另一方面,由于中文與英文語法存在巨大差別,英文的句法結構相對固定,在抽取過程中較中文更容易捕獲文本特征。雖然近年來例如中文分詞、句法分析等底層子任務的發展迅速,但中文沒有顯式分隔,在分詞時會產生一定的誤差,對觸發詞的判定造成影響。

表10 在ACE 2005 中文數據集上的事件抽取性能比較Table 10 Performance comparison of Chinese event extraction on ACE 2005 dataset
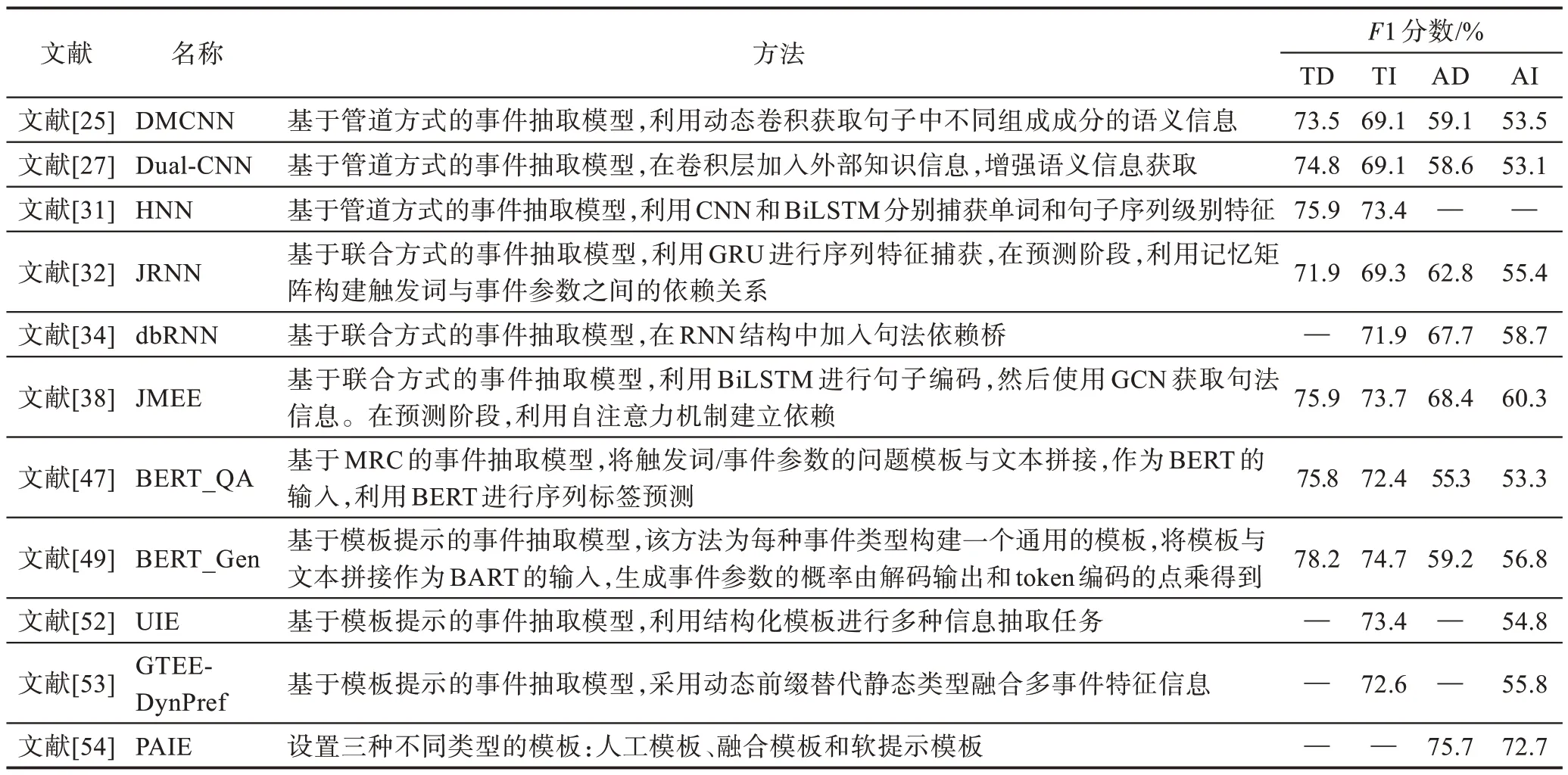
表11 在ACE 2005 英文數據集上的事件抽取性能比較Table 11 Performance comparison of English event extraction on ACE 2005 dataset
此外,通過實驗結果可以看到,基于MRC 和模板提示的事件抽取方法[51-58]的性能較之傳統的方法性能并沒有明顯提高,甚至某些方法的性能還有下降。主要原因在于這兩類方法都需要人工定義問題模板,模型的性能很大程度受到人工模板的影響。在后續的研究中,解決人工模板帶來的誤差問題,提升模板質量將是提升這兩類方法性能的關鍵所在。
4.2 其他數據集實驗結果
表12和表13分別展示了在ChFinAnn和DUEE1.0數據集下的不同方法的抽取結果[46-50]。根據結果可以看到,相較于ACE 2005 數據集,在ChFinAnn 和DUEE1.0 數據集實驗的方法整體性能要更好。原因在于,這兩個數據集的數據標注質量較好,且數據量大。另外ChFinAnn 數據集屬于金融領域數據集,事件類型少,文本語法結構化較為固定。

表12 在DUEE1.0 數據集上的事件抽取性能比較Table 12 Performance comparison of event extraction on DUEE1.0 dataset

表13 在ChFinAnn 數據集上的事件抽取性能比較Table 13 Performance comparison of event extraction on ChFinAnn dataset
通過上述分析,可以發現對于監督學習下的事件抽取模型,標注的數據越多,文本中包含的事件參數越完整,模型就能學習到更多的文本語義信息,模型的性能就會越好。
5 未來展望
事件抽取是自然語言處理中的一項重要任務,由于其廣泛的應用,事件抽取已經得到了廣泛的重視,近年來深度學習等許多新技術的快速發展,使得事件抽取這項任務得到了深入的研究。但目前封閉域事件抽取最大的困難和挑戰有以下方面:
(1)由于自然語言的靈活性強,復雜性高,文本轉換為詞嵌入時會造成一些信息的丟失,造成事件抽取方法性能下降。雖然有大量的研究人員利用各種方式對文本詞嵌入信息進行補充,但這些方法大多基于假設或特定場景,存在一定的局限性,故語義信息丟失問題仍需探究。
(2)數據集有待進一步完善。現有的數據集存在覆蓋領域小、包含的事件數量較少、事件信息較為簡單以及整體數據集的規模不大等問題。而基于深度學習的事件抽取方法非常依賴于大量的、貼近現實的標注數據進行訓練,因此導致事件抽取效果還不夠理想。
(3)現有方法大多集中于句子級別的事件抽取,由于這些方法對于捕獲文本上下文之間的信息能力不強,在面對角色共享以及共指消解(即同一實體的不同表達)等實際問題時,不能很好地解決上述問題,因此當前的事件抽取方法并不能滿足現實生活中對于長新聞文本分析的需要。除此之外,事件抽取對于實體識別、關系抽取等底層任務的依賴性很高,這些底層任務出現誤差時會給事件抽取帶來級聯錯誤,影響抽取性能。
雖然存在諸多挑戰,但隨著事件抽取受到更多的關注以及技術的發展,這些困難也會逐漸攻克,未來發展趨勢如下:
(1)隨著大規模預訓練語言模型的發展,利用海量數據進行預訓練得到的詞嵌入擁有更多的信息,將預訓練語言模型應用到事件抽取上也逐漸受到更多學者的關注。
(2)針對數據集缺少的情況,現有的大型知識庫例如FrameNet、Freebase、Wikipedia、WordNet 含有豐富的知識,在當前的研究中已經有學者使用遠程監督,利用知識庫構建了大型的數據集。故利用知識庫的豐富信息提升事件抽取的性能也將會成為研究的熱點。
(3)隨著研究的深入,利用閱讀理解、序列生成的方式可以避免對于實體識別等技術的依賴。這些方法將大大促進文檔級事件抽取的發展,吸引著更多學者的探索。
6 結束語
作為自然語言處理的重要任務之一,事件抽取為智慧問答、信息檢索等基于知識驅動的下游任務提供了重要支撐。本文首先對封閉域事件抽取的任務定義,然后分析、對比不同的深度學習事件抽取方法,列舉當前的數據支撐,最后總結出當前深度學習事件抽取方法存在的困難。在未來,使用大型數據庫補充數據,對于預訓練語言模型給予更多關注,提升特征獲取的方式,使其能夠處理更長的文本,將是事件抽取的重要研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
