基于深度學習的視覺慣性里程計技術綜述
2023-03-10 00:10:26王文森黃鳳榮王旭劉慶璘羿博珩
計算機與生活 2023年3期
王文森,黃鳳榮+,王旭,劉慶璘,羿博珩
1.河北工業大學 機械工程學院,天津300401
2.中國人民解放軍93756 部隊
視覺慣性里程計(visual inertial odometry,VIO)[1-3],又稱為視覺慣性導航系統,是由視覺和慣性傳感器構成的組合導航系統。VIO 擁有自主性、實時性等特點,傳感器的優勢互補使VIO 的導航精度明顯高于由單一傳感器組成的慣性導航系統或視覺里程計(visual odometry,VO),低成本、體積小的消費級微機電慣性測量單元(micro electro mechanical systems inertial measurement unit,MEMS-IMU)和相機的使用更促進其發展。VIO 研究的主要目的,就是充分利用視覺慣性的優勢,實現系統的高精度6 自由度(degree of freedom,DoF)位置與姿態估計。
傳統的VIO 系統的基本框架如圖1 所示。其中,前端包括基于運動學模型的慣性預處理模塊和基于幾何學模型的視覺里程計,后端為基于濾波器或優化器的狀態估計模塊。此外,為了進一步提高導航精度,還可能會添加回環檢測等功能。傳統方法已經展示了不錯的性能[4-5],但受到建模的局限和真實環境的復雜性使其仍然難以投入實際應用中。近年來,深度學習[6-7]為VIO 的方法研究提供了新的思路。深度學習的方法相比傳統方法表現出了更強的魯棒性。基于深度學習的VIO 相比傳統方法展現出的優勢可以體現在以下方面:
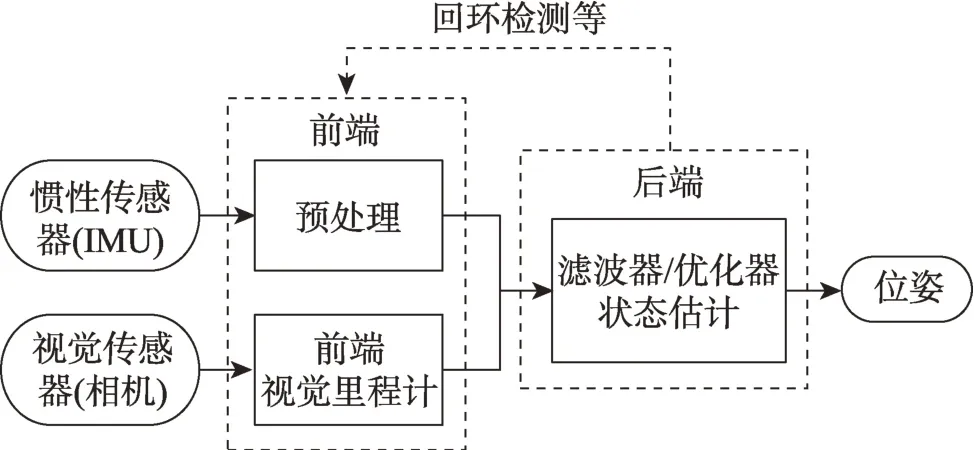
圖1 基于幾何學與運動學模型VIO 的基本框架Fig.1 Framework of VIO based on geometric and kinematic model
(1)傳統方法基于復雜的幾何與運動學模型,而且現實中很難建立與真實應用嚴格相符的數學模型,深度學習模型基于神經網絡,可以通過自適應訓練實現高精度導航。
(2)由于受到IMU 的噪聲和偏差的影響,傳統方法一般僅對慣性數據進行簡單的預處理[8],基于深度學習的方法使慣性特征也具有了量測的能力,可以使系統不再局限于來自單模態的量測特征。
(3)傳統方法提取圖像特征局限于特征點、線和平面等低級特征的提取方法[9],深度學習可以學習潛在的高級特征,有利于實現復雜環境中的導航。
由此,隨著越來越多基于深度學習的VIO 的研究方法的出現,本文在對基于深度學習的視覺慣性里程計的發展歷史、研究現狀以及方法梳理的基礎上,從融合策略的角度分別對深度學習與傳統模型結合的方法和端到端的深度學習方法進行了綜述,并分別從監督學習和無監督/自監督學習方面介紹了網絡模型,同時分析并闡述了常用數據集、評價指標和方法對比。最后,總結了當前研究中亟待突破的問題并對未來的研究方向進行了展望。
1 基于深度學習的VIO 系統融合策略
根據后端是否是以深度學習的方式實現融合,可以將VIO 系統按融合策略分為深度學習與傳統模型結合的融合和基于深度學習的端到端融合。同時,VIO 系統無疑是多模態的融合[10-11],可分為數據級融合、特征級融合和決策級融合。特征級融合和決策級融合的方法都已經實現,在VIO 中一般稱之為緊耦合和松耦合。以下將從融合策略概述現有的研究方法。
1.1 深度學習與傳統模型結合的融合
在傳統方法中,慣性狀態計算基于運動學模型,視覺狀態和特征點特征計算基于視覺幾何模型,最后采用濾波器或優化器實現二者的特征融合。深度學習與傳統模型結合的方法完整保留了傳統模型的后端,但是在前端則基于深度學習設計了學習狀態的新模型。
早期的深度學習模型主要用于替換原有的前端傳統模型。Rambach等[12]設計了首個基于深度學習的監督學習VIO 模型,模型結構如圖2 所示。其慣性前端基于長短時記憶網絡(long short-term memory,LSTM)[6]學習位置和姿態,同時加入誤差檢測器可以實現慣性網絡和視覺前端的互相監督,最后以卡爾曼濾波(Kalman filter,KF)作為后端實現了VIO 的松耦合。Li等[13]將基于卷積神經網絡(convolutional neural networks,CNN)[6]的VO模型DeepVO[14]作 為VIO 的視覺前端輸出相對位姿,再利用擴展卡爾曼濾波器(extended Kalman filter,EKF)將視覺位姿預處理的慣性狀態進行融合。余洪山等[15]基于改進SuperPoint 網絡[16]檢測和描述特征點,有效抑制了異常特征點,加強了視覺前端的魯棒性,在后端則使用了VINS-Mono[17]的緊耦合融合框架進行融合,實現了高精度導航。
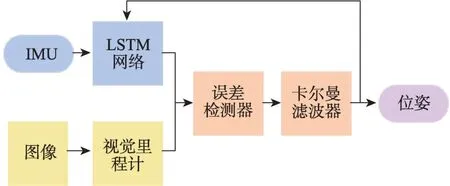
圖2 文獻[12]的模型結構Fig.2 Structure of Ref.[12]
其他方法則會利用深度學習在特征學習中的多樣性,在前端建立新的子模塊,擴展了后端的特征向量,如行人導航方法RNIN-VIO[18]使用EKF 作為融合后端,在慣性前端的深度學習網絡中,利用人體運動的規律性,使用IMU 原始數據和濾波器中的姿態學習相對位移和其不確定度。最終,視覺特征、慣性狀態和網絡輸出的慣性特征通過濾波器實現了緊耦合。該方法增強了對慣性特征的利用,提高了系統魯棒性。系統也可以僅依靠慣性數據進行較高精度的導航。Wang等[19]同樣以EKF 作為后端,其視覺前端建立了地標識別模型,通過識別已知位置的地標信息計算比例關系進而實現位姿優化,以緩解位置誤差累積的問題。Shan等[20]和Zuo等[21]基于MSCKF(multi-state constraint Kalman filter)[22]的融合框架,前者在前端建模了目標物體的語義特征的網絡,系統在幾何和語義級別上理解周圍環境,以目標物體產生的殘差約束視覺慣性的狀態,可以實現高精度定位和生成全局地圖;后者建模了深度估計網絡,將圖像深度作為特征向量以實現視覺慣性更緊密的耦合,系統在輸出位姿的同時還可以實時地提供密集稠密深度圖。以上方法通過建立額外的量測約束,使VIO 在一些特定應用場景中擁有更強的魯棒性。
1.2 基于深度學習的端到端的融合
Clark等[23]提出了首個使用深度學習框架實現的端到端的監督學習VIO 方法VINet,整體可微的CNN-LSTM 架構使其可以實現端到端的訓練,其中CNN-LSTM 架構是由CNN、LSTM 網絡結合的網絡模型架構。系統前端將視覺慣性特征轉化為高維特征表達,在后端將視覺特征、慣性特征和上時刻位姿拼接,最后基于LSTM 網絡和全連接層進行特征融合并估計位姿。VINet 在應對時間不同步、數據外參標定不準確和校準誤差導致的發散時,相比傳統方法都表現出更強的魯棒性。但是其后端沒有明確特征選擇的建模,隱式的處理方法很難對靜態和動態的特征實現有效和靈活的識別,在提取不同表示、不同分布的數據特征時并不穩定。后續的研究為建模特征選擇過程,分別采用基于加法交互作用的方法[10,24-25]和基于乘法交互作用的方法[26-28]。對特征選擇進行建模進一步提高了系統的魯棒性,具體可以體現在應對傳感器數據丟失、損壞,視覺慣性傳感器數據不同步等方面。不同于利用LSTM 網絡建模特征融合后端的方法,Aslan等[28]基于高斯過程回歸[29]實現了特征融合。這些方法的原理框圖如圖3 所示。
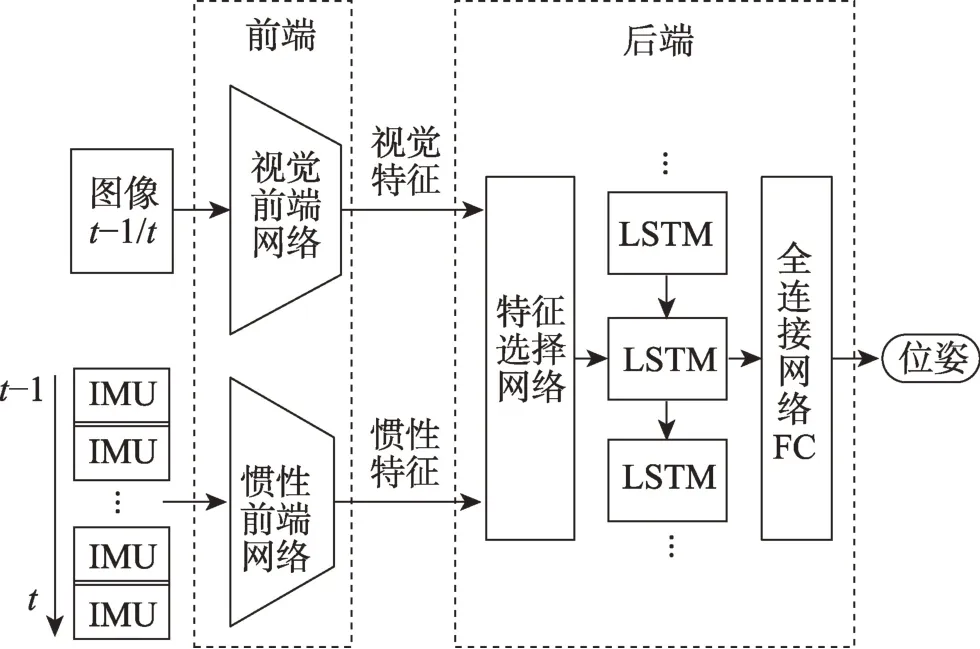
圖3 監督學習VIO 的基本框架Fig.3 Basic framework for supervised VIO
為減少對數據集真值的依賴,無監督和自監督的方法[25,30-35]也被提出,其系統框架如圖4 所示。無監督與自監督學習的VIO 不直接使用數據集真值建立損失函數,而是基于重建的源圖像和目標圖像的幾何約束[36],建立無監督損失項。無監督VIO 中用于建立無監督項的深度圖由外部提供,自監督方法的重建圖像信息來自相機圖像序列,Almalioglu等[25]使用生成式對抗網絡(generative adversarial networks,GAN)和無監督學習方法聯合實現姿態估計和生成深度圖,實現在未知陌生環境中的定位和建圖。Han等[34]利用立雙目圖像序列估計深度得到密集的三維點云,進而得到三維光流和6 自由度姿態等三維幾何約束作為自監督項。無監督VIO 可以對有尺度軌跡做在線矯正,在面對新環境和惡劣環境時具有更強的適應和泛化能力,同時受錯誤校準、數據不同步等因素影響相比傳統方法要低,有些方法[25,31-32]還可以在沒有已知傳感器外參和視覺慣性數據松散同步的情況下給出載體位姿信息。
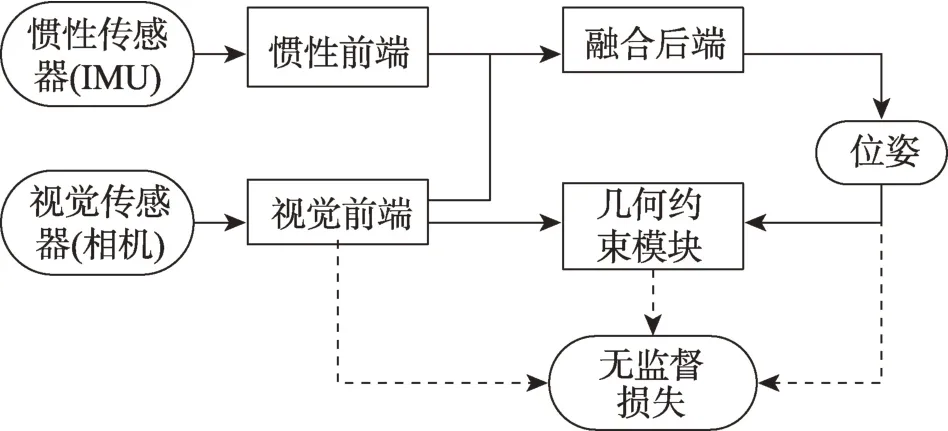
圖4 無監督VIO 的基本框架Fig.4 Basic framework of unsupervised VIO
2 深度學習VIO 系統的神經網絡模型
深度學習VIO 的網絡模型需依據是否在訓練中使用了數據集提供的真值,可以分為監督學習模型和無監督/自監督學習模型。
2.1 監督學習模型
慣性前端網絡能夠利用低精度的IMU 信息提高整個系統的魯棒性和精度。Rambach等[12]建模的慣性網絡包括1 層LSTM 網絡和3 層全連接層,雖然網絡可以利用有限的數據得到不錯的結果,卻存在比較嚴重的漂移。RNIN-VIO[18]建模的魯棒慣性網絡由ResNet18、3 層LSTM 網絡和兩個并行的全連接層組成。ResNet18 用于學習人體運動隱藏變量,LSTM 網絡將當前的隱藏狀態與之前的隱藏狀態進行融合,以估計運動的最佳當前隱藏狀態。同時RNIN-VIO設計了兩種不同的損失函數用于保證每個窗口以及長序列的訓練精度。視覺前端的網絡可以提高系統在快速運動和無紋理場景等特殊環境中的魯棒性。Li等[13]的視覺網絡使用CNN 網絡提取視覺特征,將特征排列為時間序列,然后通過雙層LSTM 網絡輸出相機位姿和不確定度。
VINet[23]是首個基于深度學習的端到端方法,其模型框架如圖5 所示,其中慣性前端基于LSTM 網絡進行建模,網絡每次將圖像兩幀之間的所有原始數據輸入,這樣保證了慣性特征的學習和前端視覺慣性特征的同步輸出。光流網絡可以利用圖像序列中像素在時間域上的變化以及相鄰幀之間的相關性來找到圖像的對應關系,進而獲得載體的運動信息。因此,視覺前端使用預訓練的FlowNetCorr光流網絡[37-38]的前端卷積部分網絡以兩張連續的圖像作為輸入,經過光流網絡內CNN 網絡的多次特征提取后輸出高維的特征表達。VINet 的后端使用兩層的LSTM 網絡建模以實現特征融合。
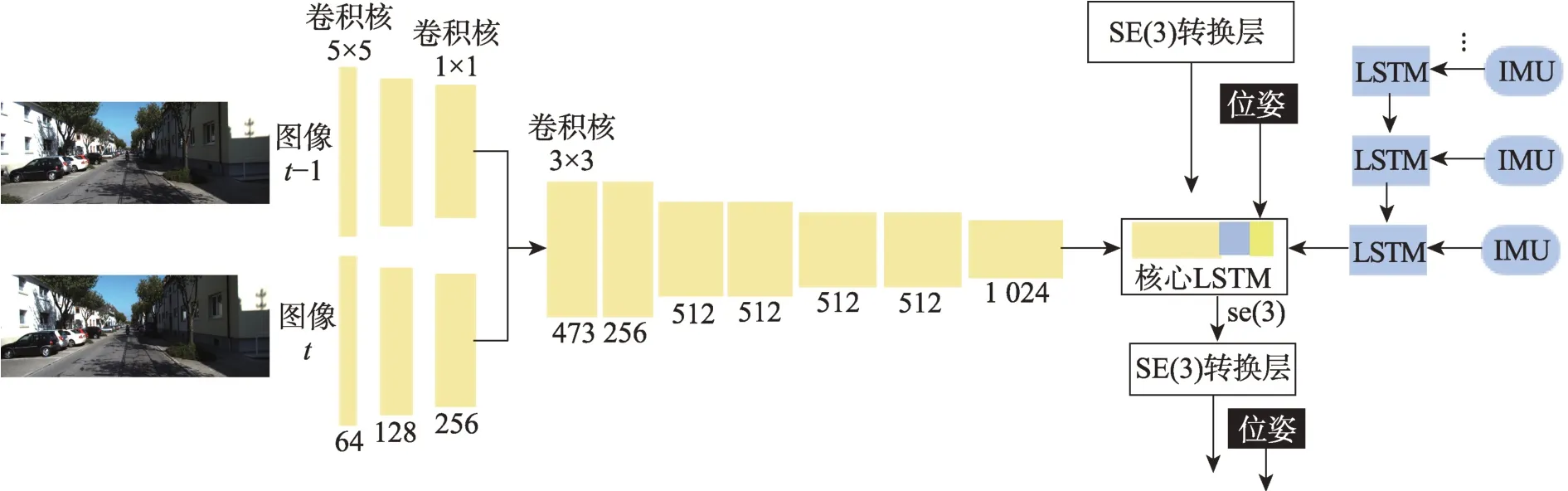
圖5 VINet的模型結構Fig.5 Model structure of VINet
在特征融合后端,為了進一步提高特征融合網絡模型的可解釋性和提高系統魯棒性,Chen等[24]提出在視覺慣性特征向量拼接后分別使用具有確定性的軟融合和具有隨機性的強融合兩種具有可解釋性的融合模式,以加法交互作用的方式實現特征選擇的顯示建模。同時,這種方法還采用了輕量級的FlowNetSimple 網絡[37-38]以加快運行速度。但是這種融合方式依然缺少視覺慣性特征之間的顯式聯系。為了進一步提高模型的可解釋性和可學習性,Shinde等[26]基于多頭自注意力機制[39]建模了后端融合模型,以乘法交互作用的方式實現顯式融合。ATVIO[27]在特征選擇過程中根據SENet 網絡[40]構建了注意力生成模塊,顯式地建模了特征之間的相關性,減少了異常數據對后端特征融合造成的影響。
在特征提取前端也需要準確、高效的模型。早期的慣性網絡一般基于LSTM 網絡建模,然而LSTM網絡內參數較多,訓練時間較長。CNN 網絡相比LSTM 網絡雖然不能補償傳感器間的時間偏差,但是其建模計算速度更快,網絡更穩定和容易收斂[41]。隨著傳感器同步校準精度的提高,基于CNN 的慣性前端網絡模型也可以發揮優勢。ATVIO[27]使用了兩個并行的3 層CNN 網絡層分別學習IMU 中加速度和角速度中的特征。Aslan等[28]將平滑和去噪的IMU 數據使用預訓練的Inception V3 網絡[42]學習慣性特征。在視覺前端,CNN 網絡無法記憶先前的圖像信息,為此ATVIO[27]使用ConvLSTM 網絡建模視覺前端,ConvLSTM 網絡是可以同時提取圖像時空相關特征的網絡,使視覺前端得以學習來自先前圖像特征的約束。此外,經過合理初始化的視覺前端網絡相比未經過訓練的網絡模型具有更快的收斂速度,訓練過程也更穩定,因此特征級融合的方法一般會對前端視覺網絡進行預訓練。
端到端的監督學習模型的損失函數θ可以使k時刻的真實位姿(pk,φk)與其估計的地面位姿之間的歐氏距離最小化以實現最優結果[14,43-44],一般以均方誤差(mean square error,MSE)計算,稱為MSE損失函數。部分數據集的姿態真值以四元數的形式保存,但直接使用四元數計算損失會因其冗余的維數導致訓練難度增加,同時浪費了計算資源,因此一般會將四元數轉化為歐拉角使用。網絡模型復雜的深層結構使MSE 損失函數在訓練中仍受到諸多限制,模型子網絡的平均性能較差。于是Liu等[27]將自適應損失函數[45]應用于訓練過程中,模型在訓練過程中自適應地調整參數,加快了網絡收斂,同時強化了對子網絡的訓練,提升了網絡整體性能。監督學習VIO 的損失函數定義為:
其中,β是用于平衡位置和姿態的比例因子。
2.2 無監督/自監督學習模型
無監督和自監督學習的VIO 需要通過在訓練過程中建立約束模型以擺脫對數據集真值的依賴或應對沒有真值的情況。在深度學習與傳統模型結合的方法中,由于難以提供真實的視覺特征,利用深度學習對特征點或其他特征進行跟蹤匹配,或者實現深度預測等,往往需要用無監督或自監督學習解決。余洪山等[15]的改進SuperPoint 網絡由輕量級的編碼層、特征點檢測層和描述符解碼層構成,采用稀疏描述符損失函數進行訓練,但是網絡在訓練前還需經過預訓練獲取合適的初始化參數,以保證后續網絡的正常收斂。CodeVIO[21]用于深度預測的網絡分為兩部分:一部分是修改過的編碼網絡,通過原始圖像和級聯稀疏深度圖預測稠密的深度圖及其不確定度;另一部分是變分自編碼器,通過對深度信息進行編碼得到用于VIO 優化的深度向量。
Shamwell等[31-32]提出了首個端到端的無監督方法VIOLearner,模型結構如圖6 所示。在IMU 固有參數和外部校準參數未知的情況下,網絡首先學習IMU 狀態并生成原始軌跡,然后通過多尺度縮放圖像的投影誤差的修正,實現原始軌跡的在線校正。多尺度的縮放不僅有助于克服訓練期間的梯度局部性,而且有助于在運行時進行在線誤差校正。Lindgren等[33]提出了Boom-VIO,系統包括一個學習相對位移的傳統模型、一個深度網絡和一個無監督學習模型,無監督學習模型基于VIOLearner。其在網絡訓練過程中加入傳統模型的引導,并得到最終的訓練軌跡。DeepVIO[34]通過直接結合二維光流特征和IMU 原始數據來提供絕對軌跡估計。系統包括一個學習視覺特征的CNN 光流網絡,一個學習慣性特征的LSTM網絡,一個用于融合的全連接網絡。此外,還有一個用于建立自監督約束的模塊,能夠分別對視覺網絡、IMU 網絡和整體的網絡進行訓練,其模型結構如圖7所示。SelfVIO[25]前端包括基于CNN 的慣性網絡、視覺網絡和深度學習網絡,后端由基于多頭自注意力機制的融合網絡和LSTM 網絡組成。其中,深度網絡學習輸出的單目深度圖,與網絡估計的位姿、源圖像共同實現圖像重建。UnVIO[35]同樣通過預測圖像深度建立無監督約束。此外,UnVIO 在訓練過程中采用了滑動窗口優化的策略,以克服長期運行中誤差累積和尺度模糊的問題。窗口內部通過判斷光度一致性建立幾何約束,窗口之間利用三維幾何一致性和軌跡一致性建立約束,這有效緩解了誤差累積的問題。
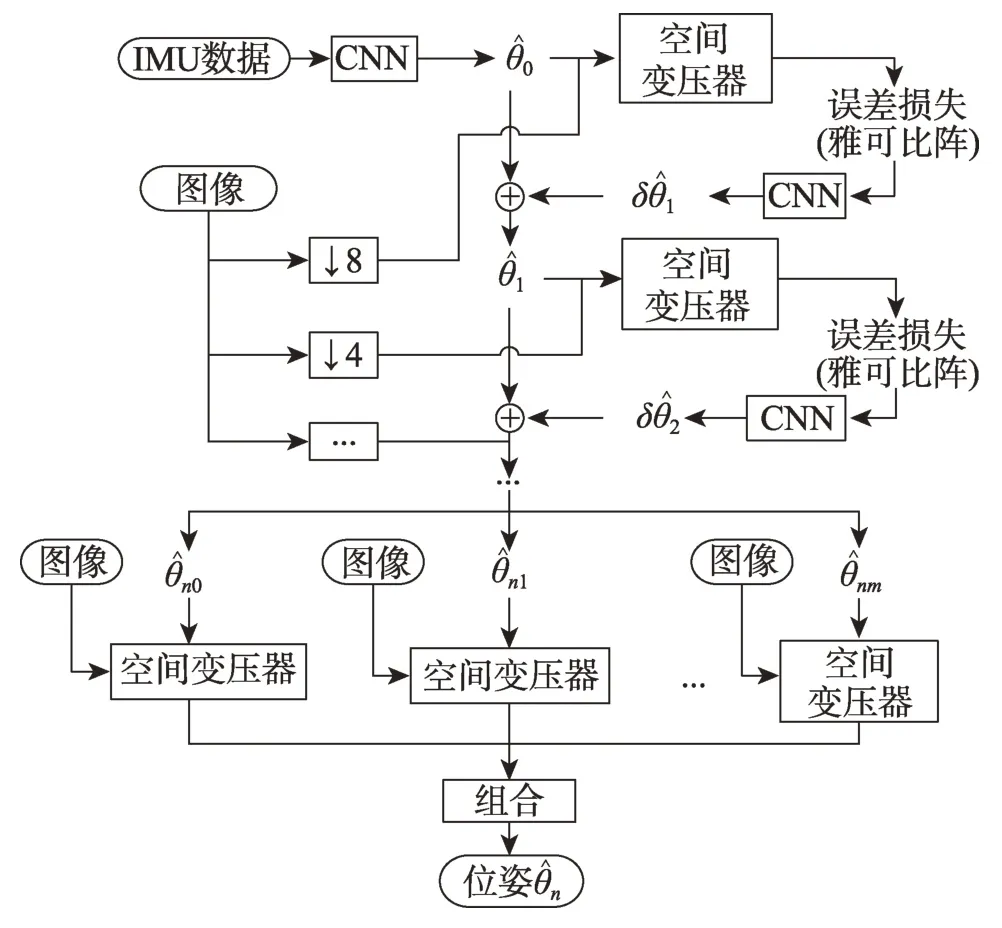
圖6 VIOLearner的模型結構Fig.6 Model structure of VIOLearner
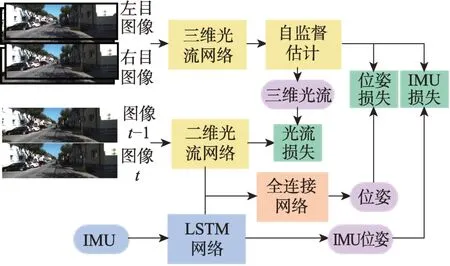
圖7 DeepVIO 的模型結構Fig.7 Model structure of DeepVIO
無監督和自監督損失可以利用圖像的時間或空間性質構造[31-32],以表示一個訓練的圖像序列,其中的某一幀It為目標圖像,其余的作為源圖像,根據兩幀圖像間的光度差異可定義損失函數為:
其中,p是像素點坐標值,是基于源圖像Is重建后的源圖像。
3 深度學習VIO 的數據優化與評估
以上方法從學習方式、融合方式、方法特性、方法局限等方面匯總并整理至表1。除建立網絡模型外,模型的訓練、優化與評估方法也至關重要。深度學習VIO 模型的訓練和測試需要使用數據集。模型優化的最終要求是模型輸出的損失達到目標值,這需要選擇合適的優化器,并針對不同的融合策略和學習方式建立與之匹配的損失函數等,這里只展開介紹損失函數。評估方法可以用于對比系統因模型的改變,或面對不同的環境,或與不同方法的橫向對比中時,表現出這些模型、方法的優秀性能和存在的問題。因此,本章將對VIO 現有的公開數據集與評估方法進行總結,同時比較部分方法的性能。
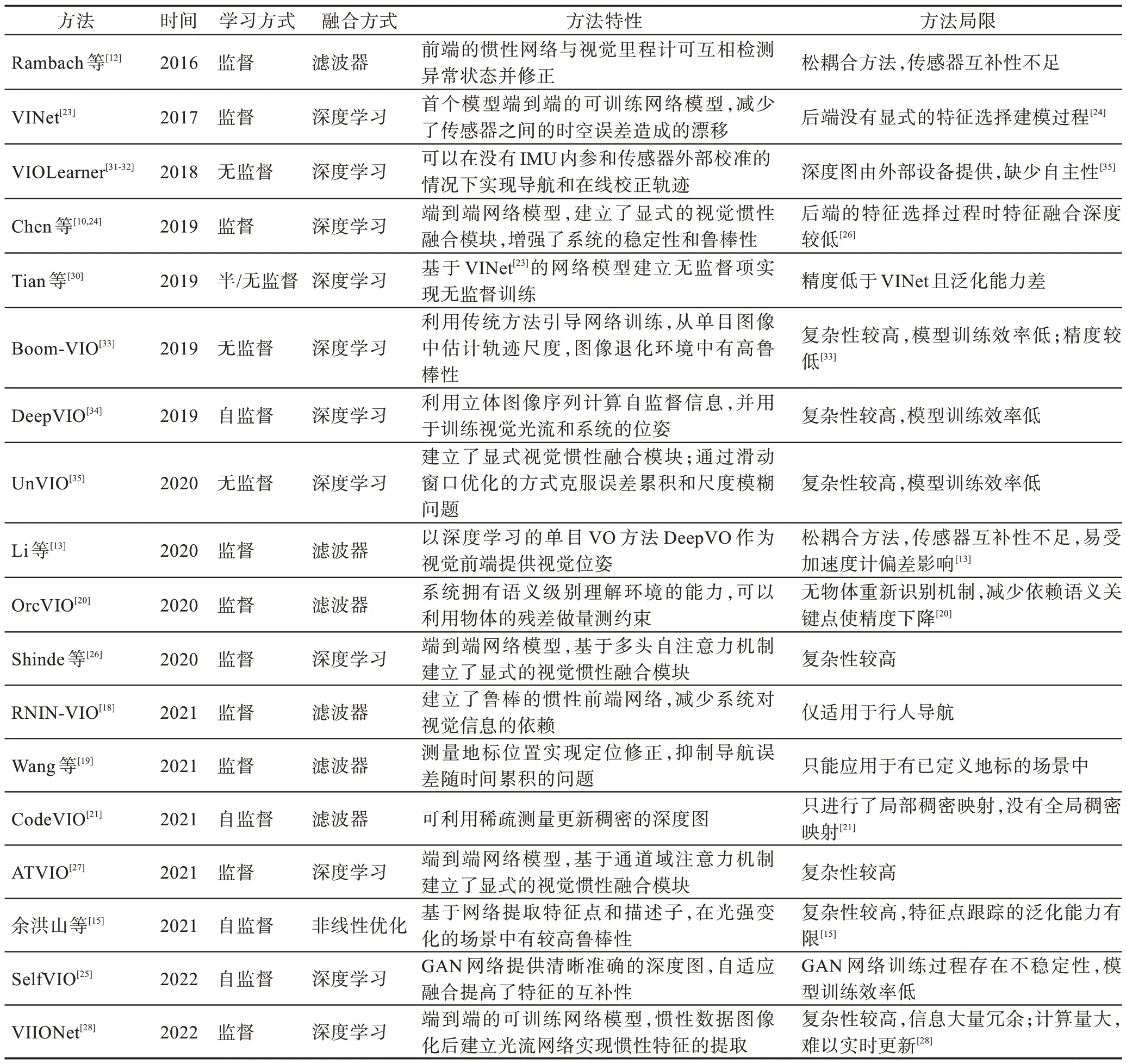
表1 基于深度學習的VIO 方法概覽Table 1 Overview of deep learning-based VIO methods
3.1 數據集
基于深度學習的VIO 網絡模型需要使用大量數據進行訓練以提高泛化能力和提高導航精度。網絡模型在訓練測試過程中一般使用公共的數據集。公共數據集按采集數據的載體平臺分類可分為:駕駛類數據集KITTI(Odometry 序列)[46]、Malaga Urban[47]、UMich NCLT[48]、Zurich Urban[49]、Canoe[50]、CUHK-AHU[51]等;手持設備數據集TUM-VI[52]、PennCOSYVIO[53]、ADVIO[54]、CVG ZJU[55]、NEAR[56]、UMA-VI[57]、HAUD[58]等;微型飛行器(micro air vehicle,MAV)/無人駕駛飛機(unmanned aerial vehicle,UAV)等小型機器人數據集EuRoC MAV[59]、AQUALOC[60]、Blackbird UAV[61]等;虛擬系統采集的數據集WHU-RSVI[62]、VIODE[63]等。以上數據集的基本屬性可見表2。其中,KITTI、EuRoC MAV 是常用的公開數據集。
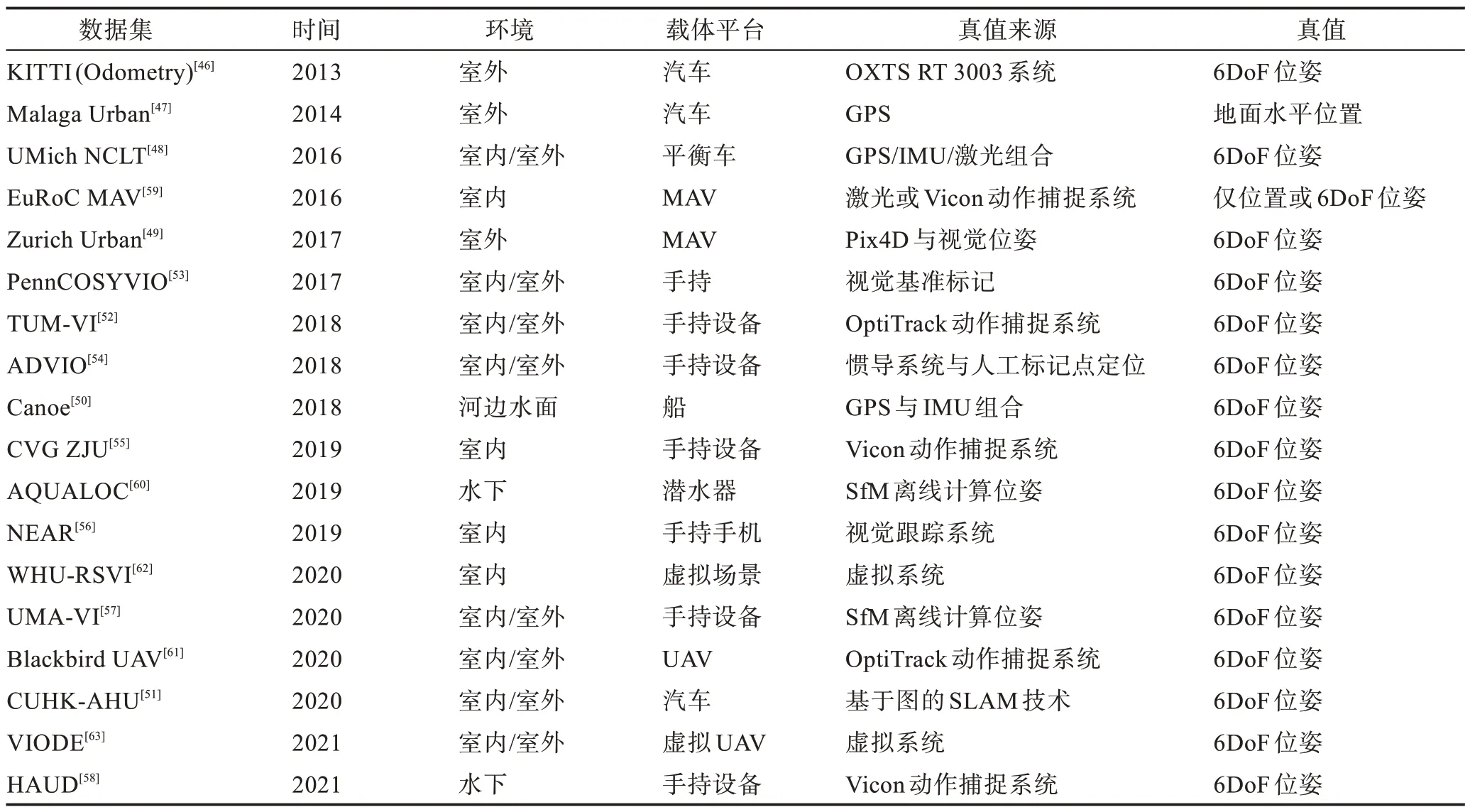
表2 VIO 數據集Table 2 VIO datasets
KITTI 數據集[46]由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合制作,是目前最大的自動駕駛場景中的公開數據集。KITTI 包含市區、鄉村和高速公路等室外場景采集的22 個序列,其中11 個有真值。圖像采集自2 個灰度相機(FL2-14S3M-C)、2個彩色相機(FL2-14S3C-C),采集頻率為10 Hz,IMU采集頻率為100 Hz,真值來自高精度全球定位和慣性導航組成的組合系統OXTS RT 3003。
EuRoC MAV 數據集[59]是由蘇黎世聯邦理工學院制作的微型飛行器數據集,數據采集于一個工廠場景和兩個室內場景。整個數據集包含從良好視覺條件下的緩慢飛行到運動模糊和光照差的動態飛行共11 個序列。圖像采集使用雙目相機MT9V034,采集頻率為20 Hz,IMU使用ADIS16448,采集頻率 為200 Hz,真值來自激光跟蹤系統或Vicon 動捕系統。
3.2 評估方法與指標
深度學習網絡通常是模塊化設計,可以使用消融實驗[64],即通過刪除、修改或替換某些模塊以判斷網絡行為和驗證一些提出的方法的有效性。
評估VIO 最重要的指標就是導航精度。在VIO方法的評估實驗中,常用的度量標準包括:
(1)絕對軌跡誤差(absolute trajectory error,ATE)直接計算VIO 位姿的估計值與真實值之間的差值,可以直觀地反映算法的精度。首先將真實值與估計值的時間戳對齊,然后計算每對位姿之間的差值。一般使用均方根誤差(root mean square error,RMSE)統計ATE。
(2)相對位姿誤差(relative pose error,RPE)用于衡量運動軌跡中固定長度或時間內的局部準確度。通過位姿真實值與估計值的實時比較,可以估計系統的漂移情況,一般使用RMSE 統計RPE。
(3)CPU/GPU 的負載、內存的占用、計算速度等參數也是VIO 的評價指標,VIO 不僅要實現高精度,也要綜合考慮應用環境的成本和實現條件。
表3 比較了一些重要方法在公開數據集中的性能。評估指標為KITTI 的09、10 兩個序列在長度為100~800 m 的平均位移和角度的均方根誤差漂移trel(%)和rrel((°)/hm)以及EuRoC 中Vicon 動捕房間中的前5 個數據集的絕對軌跡誤差。此外表中還添加了經典的傳統方法進行對比,包括基于濾波的方法MSCKF[22]、S-MSCKF[65]和基于優化的方法OKVIS[66]、VINS-Mono[17]。其中可以看到,在大部分的測試中深度學習方法具有更高的精度。同時,數據集不同可能會影響深度學習方法的結果,比如Li等[13]的方法在KITTI中具有很高的精度,然而在IMU 數據的偏差噪聲更大的EuRoC 精度較差。此外,在遇到光照改變、圖像模糊、相機運動過快、圖像和IMU 數據丟失等情況時,深度學習的方法表現出更強的魯棒性。
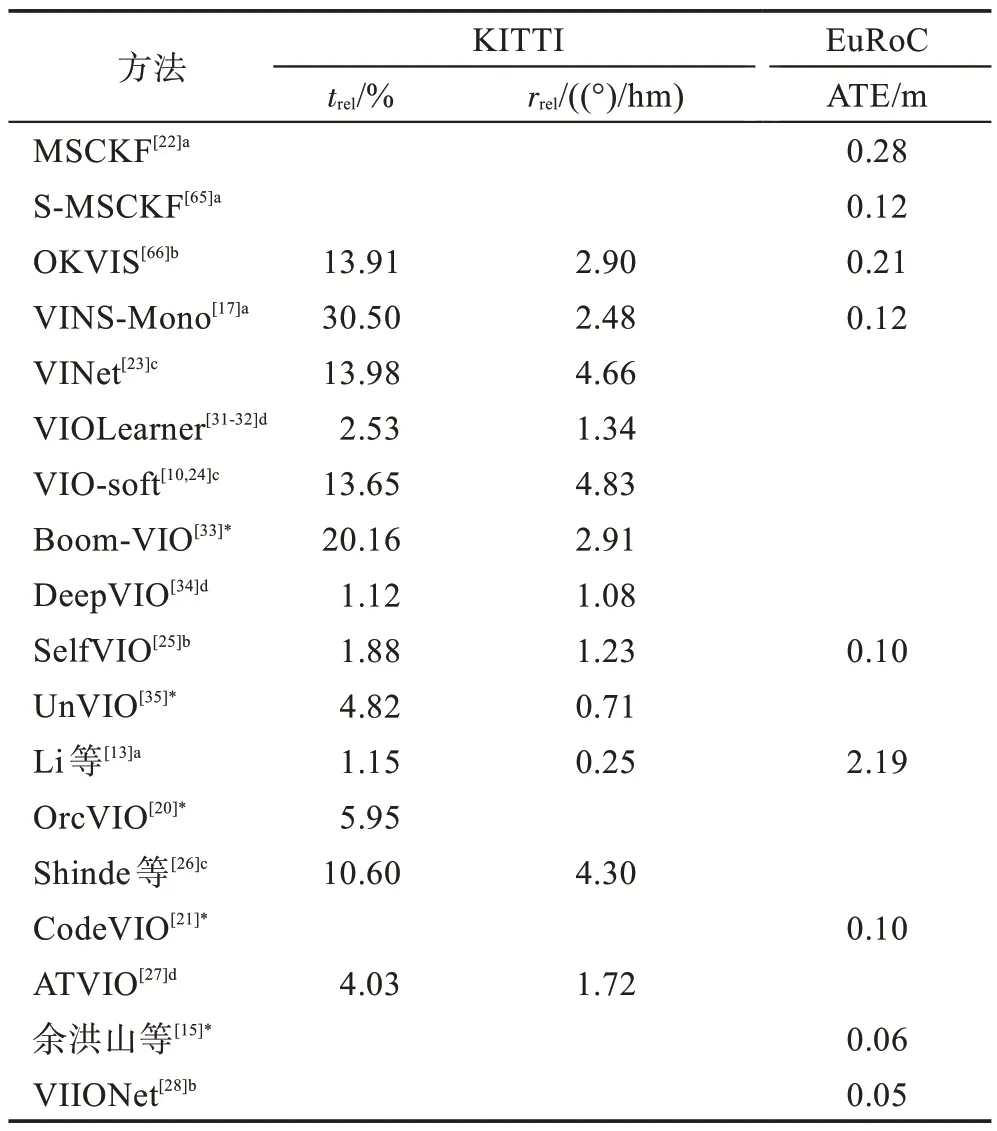
表3 基于深度學習的VIO 方法比較Table 3 Comparison of deep learning-based VIO methods
4 總結與展望
本文簡述了深度學習VIO 的研究現狀,對研究方法進行了梳理和概括,總結了基于深度學習的系統融合策略,分析了深度學習VIO 的模型結構,并對可用于其數據集、損失函數以及評估模型的方法與指標等進行了介紹,以期望能對現有的方法進行總結,以及對未來的發展方向提供一些參考。目前可以從兩方面總結現有方法的性能。
(1)從融合策略的方面來說。深度學習與傳統模型結合的方法利用網絡可以針對性地優化子模型的性能,進而提高系統的魯棒性;同時,系統內部有明確意義的特征可以與其他系統進行一定程度的相互融合。這類方法的局限是其限制了隱藏特征的表達,而且狀態量的增多會提高模型的復雜度,使計算量增加。端到端的方法對潛在特征挖掘的能力要高于與傳統模型結合的方法,但是復雜網絡的訓練首先需要高性能的計算機;其次,網絡模型內部的不可解釋性使得端到端的模型內部的高維特征表達也使其內部的特征難以利用,使系統功能僅局限于輸出位姿。
(2)從網絡模型的學習方式來說。監督學習與無監督學習的模型都具有很強的魯棒性,在有挑戰性的視覺環境中相比傳統方法可以保持更高的導航精度。然而,這些模型需要大量數據進行訓練,同時它們都難以在與訓練環境不同的場景中繼續保持高精度。監督學習模型結構更簡單,訓練更容易;無監督因無監督項的構建使模型更為復雜,同時訓練也相對困難。
深度學習與VIO 結合的研究正在快速發展,基于深度學習的VIO 的方法研究正不斷地有新的研究成果出現。同樣的,依然存在很多可以優化和尚未解決的問題,需要繼續深入研究。基于以上存在的問題,未來開展基于深度學習的VIO 方法研究時可以從初始對準、復雜環境導航、深度融合和多系統融合等方面著手,具體如下:
(1)初始對準。初始對準極大地影響后續位姿估計,初始化的不準確將使后續位姿的回歸快速發散,初始化是VIO 運行過程中非常重要的一步。VIO的初始對準因系統初始位置的隨機性使其難以通過真實數據集進行訓練,可以使用無監督學習的方式實現,在保證對準精度和時間的情況下省略傳感器標定、IMU 與相機校準等的人工校準行為。
(2)復雜環境導航。基于深度學習的方法需要根據數據集進行訓練,在面對與訓練數據不同的場景中,導航的精度會快速下降。因此,可以建立多場景的大型數據集,通過包含更多場景、更多運動模式的數據集提高模型的魯棒性,或者使用遷移學習等方法提高模型的泛化性。此外,在深度學習與傳統模型結合的方法中可以學習一些高級特征,比如利用語義信息實現語義層面的定位約束,提高系統的魯棒性和環境適應性。
(3)深度融合。目前的端到端網絡模型對多模態特征的冗余性和差異性的理解依然有限。特征融合過程中引入新的深度學習方法可以進一步提高融合深度。在基于濾波和優化的VIO 方法中,深度學習使多模態特征的融合不再局限于后端的濾波器或優化器,前端的融合可以增加系統的融合深度,提高系統的精度和魯棒性。
(4)多系統融合。系統間的協作與融合是一個趨勢,VIO 可以與其他導航傳感器結合以適應某些特殊環境或運動行為。比如與藍牙、WiFi定位相結合實現行人或機器人的室內導航,與全球定位系統(global positioning system,GPS)結合以提高遠距離無人機導航的精度和自主性。也可以投入實際應用中,以輸出位姿、深度地圖等作為輔助信號,實現系統的路徑規劃和自動導航等研究。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
人大建設(2020年4期)2020-09-21 03:39:12
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
人大建設(2017年2期)2017-07-21 10:59:25
人大建設(2017年9期)2017-02-03 02:53:31
