基于特征細化的多標簽學習無監督行人重識別
2023-03-15 14:27:18陳元妹王鳳隨錢亞萍王路遙
浙江理工大學學報 2023年12期
陳元妹 王鳳隨 錢亞萍 王路遙
摘 要: 針對無監督行人重識別中行人特征表達不充分以及訓練過程產生噪聲標簽等問題,提出了一種基于特征細化的多標簽學習無監督行人重識別方法。首先,為提高網絡對關鍵區域信息的利用能力,設計多尺度通道注意力模塊(Multi-scale channel attention module, MCAM),嵌入ResNet50網絡的不同層來構建特征細化網絡,并利用該網絡對輸入圖像通道維度上的關鍵信息進行強化和關注,以獲得更豐富的特征信息;其次,為降低訓練過程中產生的噪聲標簽對網絡的負面影響,設計多標簽學習模塊(Multi-label learning module, MLM),通過該模塊進行正標簽預測以生成可靠的偽標簽;最后,利用多標簽分類損失和對比損失進行無監督學習。在數據集Market-1501和DukeMTMC-reID上進行實驗,結果表明該方法在這兩個數據集上的平均精度均值分別達到82.8%和70.9%,首位命中率分別達到92.9%和83.9%。該方法使用注意力機制強化圖像的特征信息,并通過正標簽預測減少噪聲標簽,有效提升了無監督行人重識別的準確率,為無監督行人重識別領域提供了更魯棒的方法。
關鍵詞: 行人重識別;無監督;特征細化;多尺度通道注意力;多標簽學習
中圖分類號: TP391.4
文獻標志碼: A
文章編號: 1673-3851 (2023) 11-0755-09
引文格式:陳元妹,王鳳隨,錢亞萍,等.基于特征細化的多標簽學習無監督行人重識別[J]. 浙江理工大學學報(自然科學),2023,49(6):755-763.
Reference Format: CHEN Yuanmei, WANG Fengsui, QIAN Yaping, et al. Multi-label learning unsupervised person re-identification based on feature refinement[J]. Journal of Zhejiang Sci-Tech University,2023,49(6):755-763.
Multi-label learning unsupervised person re-identification based on feature refinement
CHEN Yuanmei, WANG Fengsui, QIAN Yaping, WANG Luyao
(a.School of Electrical Engineering; b.Key Laboratory of Advanced Perception and Intelligent Control of High-end Equipment, Ministry of Education, Anhui Polytechnic University, Wuhu 241000, China)
Abstract:? Aiming at the issue of inadequate expression of person features and noise labels generated in the training process in unsupervised person re-identification, we proposed a multi-label learning unsupervised person re-identification method based on feature refinement. Firstly, to improve the network′s ability to use key area information, a multi-scale channel attention module (MCAM) was designed. We embedded it into different layers of ResNet50 to construct a feature refinement network. This network was used to srengthen and focus the information on the channel dimension of the input image to obtain richer feature descriptions. Secondly, to reduce the detrimental effects of noise labels produced during network training, we designed a multi-label learning module (MLM). Positive label prediction was performed through this module to generate reliable pseudo-labels. Finally, unsupervised learning was carried out by using multi-label classification loss combined with contrast loss. We conducted experiments on Market-1501 and DukeMTMC-reID datasets. The results show that the Rank-1 hit rate is 92.9% and 83.9%, while the mean average precision reaches 82.8% and 70.9%, respectively. This method uses the attention mechanism to enhance the feature information of the image and reduces the noise label by positive label prediction. It effectively improves the accuracy of unsupervised person re-identification and provides a more robust method for unsupervised person re-identification fields.
Key words: person re-identification; unsupervised; features refinement; multi-scale channel attention; multi-label learning
0 引 言
行人重識別任務旨在不同的攝像機中識別出同一行人,這項任務在預防犯罪和維護公共安全方面具有重要意義[1-3]。目前在行人重識別方法中,有監督行人重識別的精準度相對較高,但該方法需要完整的真實標簽,成本高昂且標注耗時;無監督行人重識別可以彌補有監督行人重識別需要真實標簽的不足,能夠從未標記的數據集中學習行人身份的類間差異特征和類內相似特征,降低了標注成本,更適合實際應用。
基于深度學習的行人重識別方法通常利用卷積神經網絡(Convolutional neural network,CNN)來提取深層次的特征[4-5]。但由于圖像模糊、行人姿態、行人遮擋、光線等因素的影響,CNN無法從行人圖像中精確提取關鍵區域信息,導致行人重識別精度較低。因此,研究基于深度學習的行人重識別方法,首要任務是提升復雜場景下行人圖像的特征提取能力,以減少網絡訓練過程中的噪聲標簽,提高訓練速度和精度。
目前已有大量基于深度學習的行人重識別研究。劉紫燕等[6]提出了一種基于注意力機制的行人重識別方法,利用注意力機制緩解了環境因素的影響,有效提取了整個行人的特征。Cho等[7]提出了一種基于部件的偽標簽細化(Part-based pseudo label refinement,PPLR)框架,將交叉一致性分數作為特征相似性,并通過部分特征的預測信息來細化全局特征,以此減少全局特征聚類中的噪聲標簽。Ge等[8]提出了一種自步對比學習(Self-paced contrastive learning,SPCL)框架,結合源域和目標域信息進行聯合特征學習;與其他對比學習框架不同的是,SPCL可以為源域類級、目標域簇級和非簇實例級提供監督信號,并動態更新混合內存,充分挖掘了所有訓練數據的信息,提高了目標重識別準確率。為充分獲取行人信息,Lin等[9]提出了一種自下而上的聚類方法(Bottom up clustering,BUC),在聚類過程中使用多樣性正則項來平衡每個聚類中的樣本數量,實現了多樣性和相似性的有效平衡。孫義博等[10]提出了一種基于通道注意力機制的行人重識別方法,有效提取了更魯棒的行人特征,使設計的網絡模型達到了更高的識別精度。Yu等[11]提出了一種基于深度聚類的無監督非對稱距離度量學習方法,該方法有效降低了由于光線、遮擋等問題引起的圖像偏差,從而有利于無監督行人重識別網絡挖掘潛在的行人特征信息。Zhang等[12]為充分挖掘行人圖像中的判別性信息,并保持跨域標簽的一致性,提出了一種基于軟多標簽和復合注意力模塊的無監督行人重識別方法。Xuan等[13]提出了一種相機內和相機間的相似度計算(Intra-inter camera similarity, IICS)方法,相機內的相似度直接利用CNN提取每個相機內的特征,相機間的相似度利用每個樣本在不同相機上的分類分數計算;這種相似度計算方法有效緩解了相機間的樣本分布差異問題,使網絡生成更可靠的偽標簽。以上研究雖然取得了一定的成果,可以在復雜背景下提取行人的特征信息,但忽略了行人圖像中的細微特征。此外,如果無監督行人重識別網絡模型沒有充分提取樣本中的特征信息,易產生噪聲偽標簽,使得行人重識別準確率降低。
為充分提取行人圖像中的關鍵信息,減少訓練過程中產生的噪聲標簽,本文提出了一種基于特征細化的多標簽學習無監督行人重識別方法。首先設計了多尺度通道注意力模塊(Multi-scale channel attention module,MCAM),使得行人重識別模型對全局和局部通道上特征進行加權和強化;其次,設計了多標簽學習模塊(Multi-label learning module,MLM),利用MLM模塊進行正標簽預測,以減少噪聲標簽的影響;最后,利用多損失聯合監督網絡學習,提高行人重識別模型的訓練效率。本文提出的方法強化了行人圖像中全局和局部通道中的重要信息,在有效提取行人關鍵特征的基礎上通過MLM模塊提高了偽標簽的質量;無監督行人重識別網絡模型在訓練過程中無需額外的信息標注,在節約成本的同時提高了無監督行人重識別的準確率。
1 本文方法
1.1 整體網絡結構
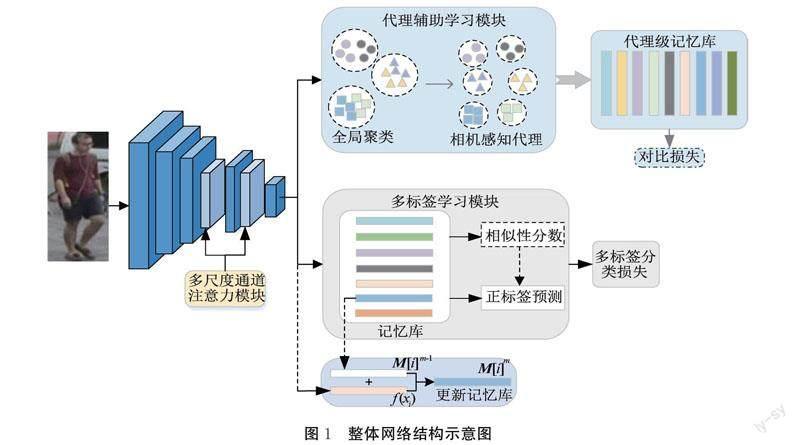
本文提出的基于特征細化的多標簽學習無監督行人重識別方法,采用ResNet50作為基礎網絡,并在基礎網絡的Layer3、Layer4之間和Layer4、Layer5之間添加MCAM模塊作為主干網絡,整體網絡結構示意圖如圖1所示。
整體網絡結構主要分為兩個模塊:代理輔助學習模塊和多標簽學習模塊。
在代理輔助學習模塊,首先對網絡提取的特征進行全局聚類;其次,將每個聚類作為多個相機感知代理,并生成一組新的偽標簽;最后,將代理特征存儲在代理級記憶庫中,并利用代理特征更新代理級記憶庫,同時計算對比損失。
在多標簽學習模塊中,將主干網絡提取的2048維特征存儲在記憶庫中,并計算輸入特征與其他特征之間的相似性分數。同時根據相似性分數進行正標簽預測,提高偽標簽質量。最后計算多標簽分類損失,多標簽分類損失在迭代訓練過程中不斷更新網絡。
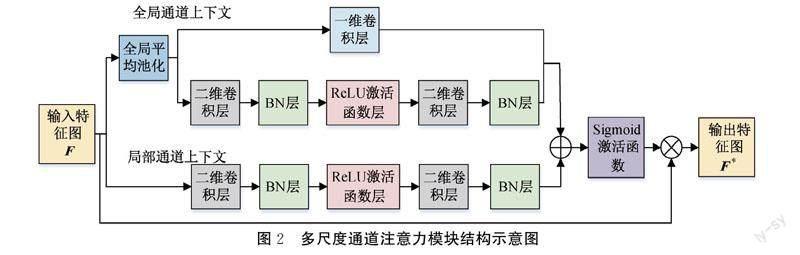
1.2 多尺度通道注意力模塊
MCAM模塊的核心思想是通過添加全局平均池化層來實現多個尺度上的通道注意。MCAM模塊由全局和局部通道上下文構成,其中全局通道又分為兩個分支。一個分支不改變通道維度,另一個分支先降維后升維,從而學習到不同維度的特征圖。多尺度通道注意力模塊結構示意圖如圖2所示。
將MCAM模塊的輸入特征圖記為F∈RH×W×C,輸出特征圖記為F*∈RH×W×C。
在全局通道上下文結構中,首先,將特征圖F輸入全局平均池化層(Global average pooling, GAP),得到1×1×C的特征描述。其次,將1×1×C的特征信息分別輸入兩個分支。其中一個分支僅經過一維卷積層,另一個分支依次經過二維卷積層、BN層、ReLU激活函數層、二維卷積層、BN層。最后,輸出全局通道上下文信息g,g可用式(1)計算:
其中:PmA表示mAP值;C表示類別數;PA,i表示第i個類別的平均精度;P(k)代表top-k檢索結果的精準率;Δr(k)=R(k)-R(k-1);R(k)為top-k結果的召回率,R(0)=0。每次實驗采用隨機測試集重復10次,計算平均性能。
2.2 實驗設置
本文實驗選用的GPU為NVIDIAGeForce RTX 2080Ti(11 GiB),操作系統為Ubuntu 16.04,處理器為英特爾Core i9-10900@3.7 GiHz,深度學習框架為Fytorch 1.2.0。本文采用ImageNet預訓練的ResNet50作基礎網絡。在每個epoch的開始,本文計算k倒數最鄰近的Jaccard距離,并使用Density-based spatial clustering of applications with noise (DBSCAN)進行全局聚類。模型的訓練批次由從8個代理中隨機抽取的32張圖像組成,每個代理有4張圖像。采用隨機翻轉、裁剪和擦除等數據增強方法。epoch大小設置為50,在前10個epoch采用預熱方案,初始學習率為0.00035,每20個epoch后除以10。正標簽預測中相似性閾值設置為0.6,超參數μ=α=0.5,τ=0.07,λ=0.5,ω=5。總損失函數采用對比損失和多標簽分類損失,前5個epoch僅使用相機內對比損失和多標簽分類損失,在剩余的epoch中,相機間對比損失與其共同作用,訓練過程中總損失曲線如圖3所示。
2.3 消融實驗
2.3.1 MCAM模塊嵌入層實驗
為分析MCAM模塊嵌入不同層的實驗效果,本文在Market-1501數據集進行實驗,實驗結果見表1。其中Layer2、Layer3、Layer4、Layer5分別表示在ResNet50的第2層、3層、4層、5層之后嵌入MCAM模塊。Layer3+Layer4表示在第3層和第4層之后同時嵌入MCAM模塊。
由表1可以看出,與分別在Layer2和Layer5之后嵌入MCAM模塊相比,在Layer3和Layer4之后分別嵌入MCAM模塊的實驗結果較好,并且在Layer3和Layer4之后分別嵌入MCAM模塊的實驗結果基本相同。因此本文在Layer3和Layer4之后同時嵌入MCAM模塊進行一次實驗,結果發現,該方式比分別在Layer3和Layer4之后嵌入MCAM模塊的效果更佳。由該實驗結果可知,將MCAM模塊同時嵌入基礎網絡的Layer3和Layer4之后,無監督行人重識別網絡挖掘行人關鍵特征的能力更優。因此本文在第3層和第4層之后都嵌入MCAM模塊,將此網絡作為本文的主干特征提取網絡。
2.3.2 MCAM模塊和MLM模塊有效性驗證實驗
為進一步驗證MCAM模塊和MLM模塊的有效性,在Market-1501數據集進行消融實驗。實驗結果見表2,其中:Baseline+MCAM表示在基線網絡基礎上僅添加MCAM模塊,Baseline+MLM表示僅添加MLM模塊,Baseline+MCAM+MLM為本文最終的模型。
實驗過程如下:首先,對基線網絡進行測試,基線網絡的PmA為78.0%,R1為90.5%;其次,在基線網絡ResNet50中嵌入MCAM模塊,由表2可以看出,PmA和R1分別提高了2.0%和1.4%;再次,在基線網絡中添加MLM模塊,其PmA和R1分別為81.0%和91.8%,相比基線網絡分別提高了3.0%和1.3%;最后,將MCAM模塊和MLM模塊同時添加至基礎網絡結構中,其PmA達到了82.8%,與原先網絡相比大幅提升了4.8%,R1達到了92.9%,在原先網絡基礎上提升了2.4%。
通過實驗結果可以看出,同時添加MCAM模塊和MLM模塊的評價指標最好,表明聯合使用MCAM模塊和MLM能夠有效提升無監督行人重識別的精確度,本文所提出的改進的方法有效。
2.3.3 參數β取值實驗
為探究本文總損失函數中參數β的取值對模型識別精度的影響,本文選取了β=0.4, 0.5, …, 0.8等5個不同的數值,在Market-1501和DuleMTMC-reID數據集上進行實驗,實驗結果見表3。
表3的實驗結果顯示,當選取不同β值時,Market-1501和DuleMTMC-reID數據集的PmA和R1均呈先升后降的趨勢。當β取0.6時,兩個數據集均呈現最佳效果,因此本文中β取0.6。
2.4 可視化結果分析
為比較本文方法與基線方法的行人重識別效果,本文在Market-1501數據集上進行實驗,其中行人a、行人b、行人c的識別結果如圖4所示。圖4中第1列為待識別行人;后10列為行人重識別準確率最高的前10張行人圖像,即R1至R10對應的行人重識別結果。每張識別圖像上方均標有數字,其中:未標方框的圖像表示行人識別正確;標有方框的圖像表示誤識別為其他行人,即行人識別錯誤。
由圖4可知,對于行人a,應用基線方法的行人重識別結果中有5張圖像識別錯誤,而應用本文方法的行人重識別結果僅出現1張圖像識別錯誤;對于行人b和c,應用基線方法分別出現2張和3張圖像識別錯誤,而本文方法未出現識別錯誤。上述實驗結果表明,本文方法可以充分提取行人圖像的細節特征,減少噪聲標簽,有效提升了無監督行人重識別的準確率;同時該結果表明,多尺度通道注意力模塊和多標簽學習模塊聯合使用的行人重識別方法具有較強的魯棒性。
為驗證MCAM模塊的有效性,本文利用梯度加權類激活熱力圖技術(Gradient-weighted class activation mapping,Grad-CAM)[17]對MCAM模塊輸出的區域注意力特征在Market-1501數據集上進行可視化分析,熱力圖如圖5所示。
圖5結果表明,MCAM模塊強化了行人圖像中多樣化的細節特征,如背包、手持物體、衣服圖案等,提高了無監督行人重識別網絡的特征提取能力。
2.5 與其他無監督行人重識別方法對比實驗
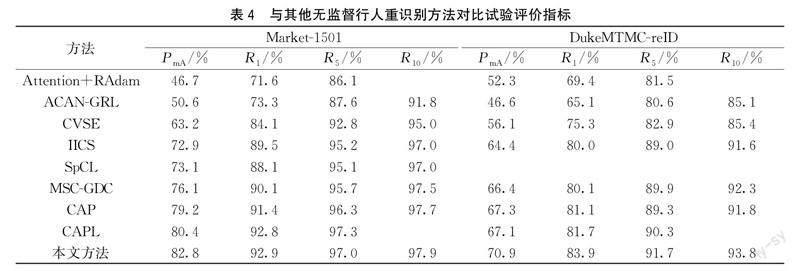
本文方法與其他典型無監督行人重識別方法在Market-1501和DukeMTMC-reID兩個大數據集上進行了對比,對比方法包括ACAN-GRL[18]、CVSE[19]、MSC-GDC[20]、CAP[21]、CAPL[22]等,對比結果見表4,表身中的空白表示文獻中沒有報告相關數據。
由表4可以看出,在同一評估指標下,本文方法相較于其他方法取得了更好的識別結果。將本文方法與Attention+RAdam方法相比,在Market-1501和DukeMTMC-reID數據集下,PmA與R1均大幅提升。Attention+RAdam方法與本文方法均使用注意力機制來輔助網絡關注行人圖像中的關鍵信息。Attention+RAdam方法僅對全局信息進行關注,而本文的MCAM模塊對全局和局部通道上的關鍵信息同時施加關注,獲得了更加豐富的行人特征信息。本文方法與IICS方法相比,PmA分別提高了9.9%和6.5%,R1分別增加了3.4%和3.9%。與CAP方法相比,PmA均提高了3.6%,R1分別增加了1.5%和2.8%。CAP方法與本文方法均采用相機感知代理學習策略,不同的是,本文將相機感知代理學習與多標簽學習模塊置于同一架構進行聯合學習,通過進行正標簽預測減少噪聲標簽,提高偽標簽質量。CVSE、MSC-GDC方法在兩個數據集上的識別準確率都遠低于本文方法,進一步驗證了本文所提方法的有效性和先進性。
3 結 語
本文提出了一種基于特征細化的多標簽學習無監督行人重識別方法。在特征提取過程中使用多尺度通道注意力模塊融合了全局和局部通道信息,更加關注行人重識別網絡所需要的信息;在多標簽學習中通過標簽預測生成了可靠偽標簽,有效提高了行人重識別的準確率。實驗結果顯示,Market-1501和DukeMTMC-reID數據集的平均精度均值分別達到了82.8%和70.9%,首位命中率分別達到92.9%和83.9%,表明本文方法能夠在充分提取行人特征的同時減少噪聲標簽,提升了無監督行人重識別模型的性能。
為進一步提升行人重識別網絡提取特征的能力,后續研究可考慮同時使用空間注意力和通道注意力,使行人重識別網絡模型分別從位置和通道上關注行人圖像中的關鍵信息,更加準確地定位到目標區域,從而獲得更豐富的特征信息。
參考文獻:
[1]黃新宇, 許嬌龍, 郭綱, 等. 基于增強聚合通道特征的實時行人重識別[J]. 激光與光電子學進展, 2017, 54(9): 119-127.
[2]羅浩, 姜偉, 范星, 等. 基于深度學習的行人重識別研究進展[J]. 自動化學報, 2019, 45(11): 2032-2049.
[3]Wang Y Y, Li X A, Jiang M X, et al. Cross-view pedestrian clustering via graph convolution network for unsupervised person re-identification[J]. Journal of Intelligent & Fuzzy Systems, 2020, 39(3): 4453-4462.
[4]Kim G, Shu D W, Kwon J. Robust person re-identification via graph convolution networks[J]. Multimedia Tools and Applications, 2021, 80(19): 29129-29138.
[5]潘海鵬, 郝慧, 蘇雯. 基于注意力機制與多尺度特征融合的人臉表情識別[J]. 浙江理工大學學報(自然科學版), 2022, 47(3): 382-388.
[6]劉紫燕, 萬培佩. 基于注意力機制的行人重識別特征提取方法[J]. 計算機應用, 2020, 40(3): 672-676.
[7]Cho Y, Kim W J, Hong S, et al. Part-based pseudo label refinement for unsupervised person re-identification[C]∥2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans, LA, USA. IEEE, 2022: 7308-7318.
[8]Ge Y X, Zhu F, Chen D P, et al. Self-paced contrastive learning with hybrid memory for domain adaptive object re-ID[C]∥Proceedings of the 34th International Conference on Neural Information Processing Systems. Vancouver, BC, Canada. New York: ACM, 2020: 11309-11321.
[9]Lin Y T, Dong X Y, Zheng L A, et al. A bottom-up clustering approach to unsupervised person re-identification[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 8738-8745.
[10]孫義博, 張文靖, 王蓉, 等. 基于通道注意力機制的行人重識別方法[J]. 北京航空航天大學學報, 2022, 48(5): 881-889.
[11]Yu H X, Wu A C, Zheng W S. Unsupervised person re-identification by deep asymmetric metric embedding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(4): 956-973.
[12]Zhang B H, Zhu S Y, Zhou Y F, et al. A novel unsupervised person re-identification algorithm based on soft multi-label and compound attention model[J]. Multimedia Tools and Applications, 2022, 81(17): 24081-24098.
[13]Xuan S Y, Zhang S L. Intra-inter camera similarity for unsupervised person re-identification[C]∥2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Nashville, TN, USA. IEEE, 2021: 11921-11930.
[14]Xie K, Wu Y, Xiao J, et al. Unsupervised person re-identifcation via K-reciprocal encoding and style transfer[J]. International Journal of Machine Learning and Cybernetics, 2021, 12(10): 2899-2916.
[15]Zheng L, Shen L Y, Tian L, et al. Scalable person re-identification:a benchmark [C]∥2015 IEEE International Conference on Computer Vision (ICCV). Santiago, Chile. IEEE, 2016:1116-1124.
[16]Zheng Z D, Zheng L, Yang Y. Unlabeled samples generated by GAN improve the person re-identification baseline in vitro[C]∥2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy. IEEE, 2017: 3774-3782.
[17]Selvaraju R R, Cogswell M, Das A, et al. Grad-cam: Visual explanations from deep networks via gradient-based localization[C]∥2017 IEEE International Conference on Computer Vision (ICCV). Venice, Italy. IEEE, 2017: 618-626.
[18]Qi L, Wang L, Huo J, et al. Adversarial camera alignment network for unsupervised cross-camera person re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(5): 2921-2936.
[19]Zhou S R, Wang Y, Zhang F, et al. Cross-view similarity exploration for unsupervised cross-domain person re-identification[J]. Neural Computing and Applications, 2021, 33(9): 4001-4011.
[20]Pang Z Q, Guo J F, Ma Z Q, et al. Median stable clustering and global distance classification for cross-domain person re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2022, 32(5): 3164-3177.
[21]Wang M L, Lai B S, Huang J Q, et al. Camera-aware proxies for unsupervised person re-identification[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(4): 2764-2772.
[22]Liu Y X, Ge H W, Sun L, et al. Camera-aware progressive learning for unsupervised person re-identification[J]. Neural Computing and Applications, 2023, 35(15): 11359-11371.
(責任編輯:康 鋒)
收稿日期: 2023-04-14網絡出版日期:2023-07-07
基金項目: 安徽省自然科學基金項目(2108085MF197);安徽高校省級自然科學研究重點項目(KJ2019A0162);安徽工程大學國家自然科學基金預研項目(Xjky2022040)
作者簡介: 陳元妹(1998- ),女,安徽宿州人,碩士研究生,主要從事智能信息處理方面的研究。
通信作者: 王鳳隨,E-mail:fswang@ahpu.edu.cn
