基于Transformer 與BiLSTM 的網絡流量入侵檢測
2023-03-16 10:20:44張吉濤高宇飛陶永才
計算機工程 2023年3期
石 磊,張吉濤,高宇飛,衛 琳,陶永才,2
(1.鄭州大學 網絡空間安全學院,鄭州 450002;2.鄭州大學 信息工程學院,鄭州 450001)
0 概述
隨著計算機互聯網技術的快速發展,網絡入侵、攻擊以及病毒等網絡安全問題日益嚴重,對互聯網用戶的正常使用造成了極大影響。網絡入侵檢測技術通過對網絡流量進行識別分類,及時發現惡意入侵流量并報告給用戶,提醒用戶采取進一步措施,從而防止重大安全事故發生。然而,由于互聯網規模的不斷擴大,網絡流量呈現爆炸式增長,結構也愈發復雜,如何提高惡意流量的檢測準確率及高效分辨不同惡意流量的類別成為亟待解決的問題。同時,在入侵檢測領域中,正常流量數據數量遠大于異常數據,若對不平衡數據處理不當,則將導致高假陰性率和低召回率。
目前,入侵檢測系統主要分為傳統方法和基于機器學習[1]、深度學習[2]的方法兩類。傳統方法具有一定的局限性,無法適應日益復雜的網絡環境和攻擊方式。隨著機器學習算法在其他領域的成功應用,網絡安全領域開始利用機器學習模型實現智能化檢測來提高效率[3]。傳統計算機網絡安全防御方法主要包括防火墻、殺毒軟件、網絡安全硬件產品等,即通過模式匹配對入侵流量或病毒程序進行識別,這類方法對已有的入侵行為檢測效果較好,但對于新型的攻擊行為防御效果較差。為此,業界引入機器學習算法,通過學習入侵流量特征進而提高對未知攻擊的檢出率。文獻[4-5]結合隨機森林算法進行入侵檢測研究,提高了入侵檢測的自適應性,在不平衡數據的多分類問題上具有一定優勢。文獻[6]和文獻[7]采用主成分分析(Principal Component Analysis,PCA)對入侵檢測數據進行降維:前者使用PCA 方法對KDD 99 數據集進行篩選降維,通過支持向量機(Support Vector Machine,SVM)進行訓練;后者首先使用信息增益進行屬性特征選取,然后使用PCA 進行數據降維,最后使用樸素貝葉斯(Naive Bayes,NB)進行分類檢測。上述方法具有一定優勢,但并沒有提高對各類攻擊的檢測率。文獻[8]考慮到數據具有時間、空間和內容3 個維度的特點,提出一種多維特征融合和疊加集成機制,從原始數據提取基本特征數據,結合基本特征數據形成綜合特征數據,并將決策樹作為基本學習算法、隨機森林作為元學習算法,通過集成多種決策樹,有效提高分類精度。基于機器學習的方法能夠分析數據的表層特征,并通過對特征的學習達到自主檢測的目的。基于深度學習的方法能夠挖掘數據更深層次的特征,提高檢測效率、降低誤報率,有助于發現潛在安全威脅[9]。文獻[10]使用降維技術與特征工程結合的預處理方法產生有意義的特征,并提出兩種基于深度學習的檢測方法。文獻[11]基于數據的維度特征和時間序列特征,使用PCA 簡化數據特征,并利用基于遷移學習的堆疊GRU 檢測模型對簡化后的特征進行入侵檢測。文獻[12]提出一種遺傳卷積神經網絡模型,首先使用結合了KNN 適應度函數和模糊C 均值聚類的遺傳算法進行特征選擇,獲取改進的特征子集,然后采用五倍交叉驗證選擇效果最好的卷積神經網絡模型,在NSL_KDD 數據集上進行了模型驗證。文獻[13-15]采用卷積神經網絡和雙向長短時記憶(Bidirectional Long Short-Term Memory,BiLSTM)網絡相結合的方式進行入侵檢測。文獻[16-17]借鑒極限學習機(Extreme Learning Machine,ELM)泛化性強的優勢,取得了良好的實驗效果。
以上方法雖得到了較高的檢測率,但沒有注意數據集不平衡對模型訓練的影響[18]。針對不平衡類分布的問題,學者們進行了大量研究并取得了一定的成果。文獻[19]提出一種基于類平衡動態加權損失函數的類再平衡策略,該策略能夠有效地處理類的不平衡問題,同時提高了校準性能,但并未分析數據本身的分布特點,無法產生少數類數據。文獻[20]提出一種新的困難集采樣算法來解決類不平衡問題,該方法首先使用最近鄰算法將訓練集劃分為困難集和容易集,然后通過K-Means 算法壓縮困難集中的多數類樣本,放大少數類樣本。文獻[21]結合過采樣和欠采樣技術來解決不平衡數據的分類問題,使用SMOTE 算法進行過采樣,利用互補神經網絡進行欠采樣,但該方法未考慮SMOTE 算法生成少數類的邊緣分布問題。
為了在解決數據不平衡問題的同時提高入侵檢測的準確率,建立一種融合單邊選擇(One-Sided Selection,OSS)、SMOTE 算法以及Wasserstein 生成對抗網絡(Wasserstein Generative Adversarial Network,WGAN)[22]的上下采樣模型OSW,該模型能夠學習到少數類數據的分布,避免生成數據的邊緣分布問題。為了使模型在關注重要特征的同時不丟失局部特征間的聯系,構建一種結合Transformer和神經網絡的入侵檢測模型TBD。TBD 模型通過引入多頭注意力機制,增加了對不同特征之間以及局部特征與全局特征之間的關注,從而挖掘特征之間的內在聯系。同時,使用雙向長短時記憶網絡保留時序特征,利用深度神經網絡(Deep Neural Network,DNN)提取深層次的特征,采用Softmax 分類器對輸出進行分類。
1 TBD 模型
首先,對初始數據進行預處理,通過單邊選擇和SMOTE 算法對原始數據進行上采樣和下采樣,為避免SMOTE 算法生成數據的邊緣分布問題,只生成少量數據。其次,使用WGAN[22]學習少數類數據的分布,并通過生成器進行少數類數據的上采樣以構建平衡數據集,將預處理后的數據輸入Transformer模塊,建立不同特征之間的聯系,并且通過多頭注意力提取更加豐富的特征信息。然后,將數據輸入BiLSTM 神經網絡獲取前后特征之間的聯系以保留時序信息。最后,通過DNN 進一步提取特征并使用Softmax 分類器對特征進行分類識別得到最終結果。TBD 模型借鑒各模型的優點,同時考慮不同特征之間的聯系以及特征的時序信息,整體結構如圖1 所示。
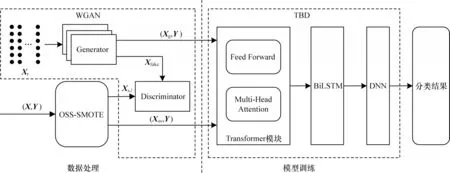
圖1 TBD 模型整體結構Fig.1 Overall structure of the TBD model
1.1 數據預處理
數據預處理過程如圖1 中數據處理部分所示。首先,原始數據(X,Y)經過OSS-SMOTE 模塊對多數類數據進行下采樣,對少數類數據進行初步上采樣生成數據(Xos,Y),其中Xs,l表示經過SMOTE 初步上采樣后生成的標簽為l的真實訓練數據。然后,隨機噪聲數據Xr經過生成器后生成偽造數據Xfake,使用Xs,l和Xfake分別對每個少數類迭代訓練判別器和生成器。最后,使用訓練好的生成器生成少數類數據(Xg,Y)。
1.1.1 OSW 模型
OSS 算法是一種經典的欠采樣算法,結合了Tomek links 和KNN,能夠在對多數類數據進行采樣的同時去除噪聲。不同于隨機移除樣本,它在評估每個樣本所含信息量大小的基礎上決定移除哪些樣本。Tomek links 指(xi,xj)樣本對,存在以下關系:
其中:d(xi,xj)表示xi和xj之間的歐氏距離;xi表示少數類;xj表示多數類;xk表示任意其他樣本。
由Tomek links 的定義可知,被標記為Tomek links 的樣本是邊界樣本或噪聲樣本。OSS 算法以最近鄰原則篩選出分類錯誤的樣本,并在這些樣本中找到Tomek links 樣本對,移除多數類樣本并保留少數類樣本,達到下采樣的目的。
SMOTE 算法的基本思想是隨機在少數類樣本中選擇一個樣本中心Xo,通過KNN 算法找到Xo的k個鄰近同類樣本并從中隨機選擇一個樣本Xs。通過Xo和Xs合成新樣本,如式(3)所示:
其中:rand(0,1)表示一個0~1 的隨機數;Xnew表示新生成的樣本。
SMOTE 算法通過在少數類樣本間生成新的少數類樣本來達到數據平衡,但該算法無法克服非平衡數據集的數據分布邊緣化問題,容易模糊多數類與少數類的邊界,從而增加分類難度。如果初始數據量過少,則WGAN 也無法充分學習少數類數據的分布。為解決上述問題,本文提出OSW 模型,在SMOTE 生成數據的基礎上使用生成對抗網絡(Generative Adversarial Network,GAN)來充分學習少數類數據的分布,從而使生成數據的質量更佳。由于GAN 存在梯度不穩定且生成器梯度容易消失的問題,因此使用WGAN 代替GAN。相較于原始GAN,WGAN 去除了判別器最后一層的Sigmoid 并采用Earth-Mover 距離作為Loss,其Loss 函數計算如式(4)、式(5)所示:
其中:Loss(c)和Loss(g)表示WGAN 中判別器和生成器的損失函數;gθ表示WGAN 中的生成器;fw表示WGAN 中的判別器;x表示真實數據;z表示隨機噪聲數據;m表示一個batch 的大小。
在對WGAN 網絡進行訓練時,Adam 會導致模型訓練不穩定的問題,因此采用RMSProp 作為WGAN 網絡訓練的優化器。
1.1.2 MLP 編碼
實驗使用NSL_KDD 數據集[23]對模型進行訓練驗證。在該數據集中有9 個數據是離散型數據,使用one-hot 對其進行編碼處理,并將其插入初始特征,作為整體的一部分進行訓練。
類似于自然語言處理中的詞嵌入層,使用一個多層感知機(Multilayer Perceptron,MLP)對每個特征數據進行數據編碼,將特征放大映射到不同的子空間,提取更豐富的特征并達到模型要求的輸入維度,同時在訓練時動態調整MLP 的參數。MLP 結構如表1 所示。

表1 MLP 結構Table 1 Structure of MLP
在二分類和五分類實驗中,原始數據標簽具有38 種攻擊類型,因此需要對原始數據中的標簽進行預處理。在執行二分類任務時,將標簽分為正常(Normal)和非正常(Abnormal)2 類,在執行五分類任務時將標簽分為正常以及端口掃描攻擊(Probing)、遠程未授權訪問攻擊(R2L)、拒絕服務攻擊(DOS)、本地提權攻擊(U2R)等5 類。
1.2 Transformer 模塊
Transformer 原始模型結構包含編碼和解碼兩部分,由于入侵檢測任務的具體需要以及數據集中每條數據定長的特點,TBD 模型只使用Transformer 中的編碼部分,并對其中某些參數進行微調。編碼部分包括一個多頭注意力機制和一個前饋神經網絡。注意力機制使用點積注意力,包含query、key 和value 等3 個輸入,使用query 和key 計算出分配給每個值的權重分數,之后將該權重與value 計算加權和得到輸出,使用點積注意力進行并行運算,減少訓練時間。注意力計算如式(6)所示:
其中:Q、K、V分別代表Query、Key、Value 矩陣;dk為Key 的維度。
由于實驗輸入數據的特點,省去原模型中的Mask 部分。為了使提取的特征更加豐富,使用多頭注意力結構。多頭注意力計算如式(7)所示:
其中:i=1,2,…,n,n為注意力頭的個數;WO表示一個可以學習的矩陣,其作用是與多個注意力頭拼接后的結果進行線性變換。
前饋神經網絡部分只有一個隱藏層的感知機,輸入輸出維度相同,由于單隱藏層網絡非線性映射能力較弱,考慮到計算復雜度以及映射能力之間的平衡,因此設置隱藏層神經單元個數為輸入層的2 倍。使用高斯誤差線性單元激活函數GeLU 作為激活函數,其相比于ReLU 增加了隨機性,計算公式如式(8)所示:
整個Transformer-Encoder 模塊結構如圖2 所示,使用殘差連接防止出現梯度消失問題。
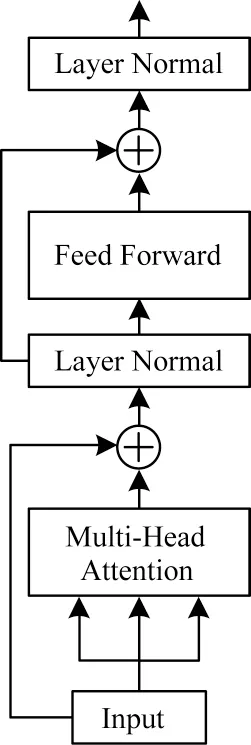
圖2 Transformer-Encoder 模塊結構Fig.2 Structure of Transformer-Encoder module
1.3 BiLSTM-DNN 結構
長短時記憶(Long Short-Term Memory,LSTM)[24]網絡是一種解決了長序列遠距離信息丟失的循環神經網絡(Recurrent Neural Network,RNN),用來處理時序信息并解決了RNN 結構中存在的梯度爆炸和梯度消失問題,可記憶有價值的信息。BiLSTM 網絡由一個前向LSTM 和一個反向LSTM 組成,包含了前向和反向的所有信息,結構如圖3 所示。
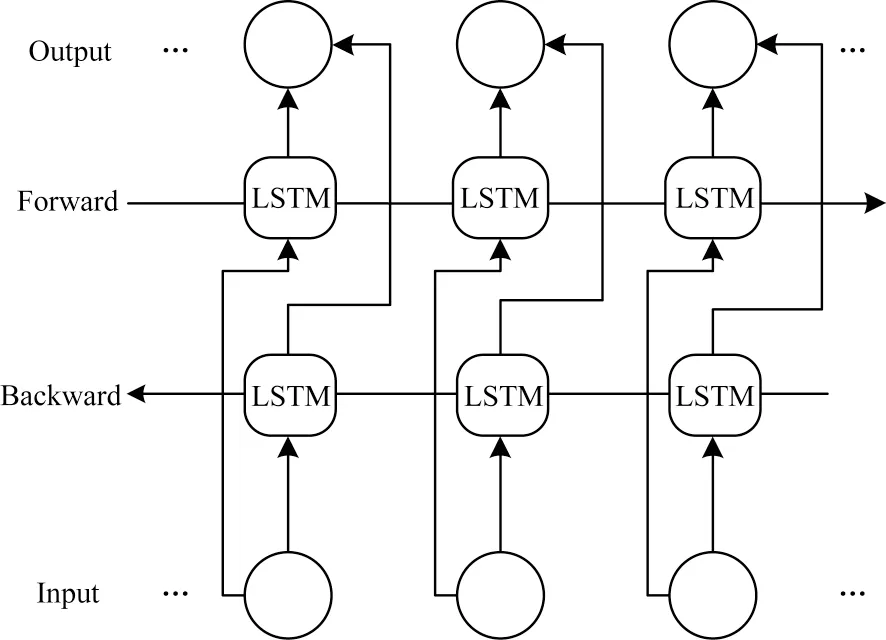
圖3 BiLSTM 網絡結構Fig.3 Structure of BiLSTM network
輸入層(Input)將輸入數據分別輸入前向網絡(Forward)和反向網絡(Backward)中,對網絡的輸出(Output)進行拼接處理,輸出如式(9)所示。使用前向和反向的最后一個輸出進行拼接,作為下一層的輸入,并且設置輸出維度為2 倍的輸入維度以盡可能降低模型的復雜度。
其中:hj表示第j條輸入數據經前向輸出和反向輸出拼接后的最終輸出結果,j=1,2,…,n1,n1表示輸入數據的總數。
深度神經網絡通常也被稱為多層感知機,是深度學習的一種框架,TBD 模型中DNN 具有兩個隱藏層。使用ReLU 作為激活函數,隨機失活率(Dropout)設置為0.5。DNN 結構如表2 所示,其中*表示根據實際需求進行設置,如果進行N分類任務,則設置為N。DNN 計算通式如式(10)所示:
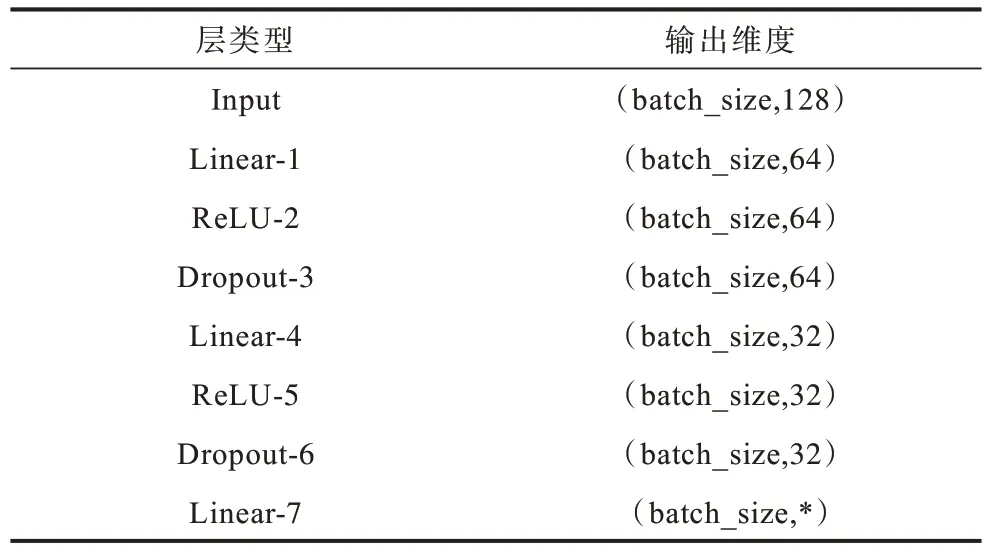
表2 DNN 結構Table 2 Structure of DNN
2 實驗與結果分析
2.1 實驗環境
實驗操作系統為Ubuntu20.04 服務器版,處理器為Intel Xeon Silver 4210,內存為64.0 GB,GPU 為NVIDIA Tesla T4 16 GB,編程語言為Python 3.8,學習框架為PyTorch 1.8.1。
2.2 實驗數據集
實驗數據使用NSL_KDD 數據集。該數據集是TAVALLAEE 等[23]針對KDD CUP 99 數據集存在大量冗余記錄、各類數據分布不均勻等問題進行改進生成的新數據集,包含KDDTrain+、KDDTest+、KDDTest-21、KDDTrain+_20Percent 等4 個子數據集,其中,KDDTrain+包含125 973 條記錄,KDDTest+包含22 544 條記錄,KDDTrain+_20Percent包含KDDTrain+中的前25 192條記錄。實驗使用KDDTrain+_20Percent作為訓練集,使用KDDTest+作為測試集。在數據集中的類標簽表示正常和攻擊類型,其中有1個正常類型和4個攻擊類型,分別為Normal、Probing、R2L、U2R、DOS。各類型數據在訓練集和測試集上的數量及所占比率如表3 所示。
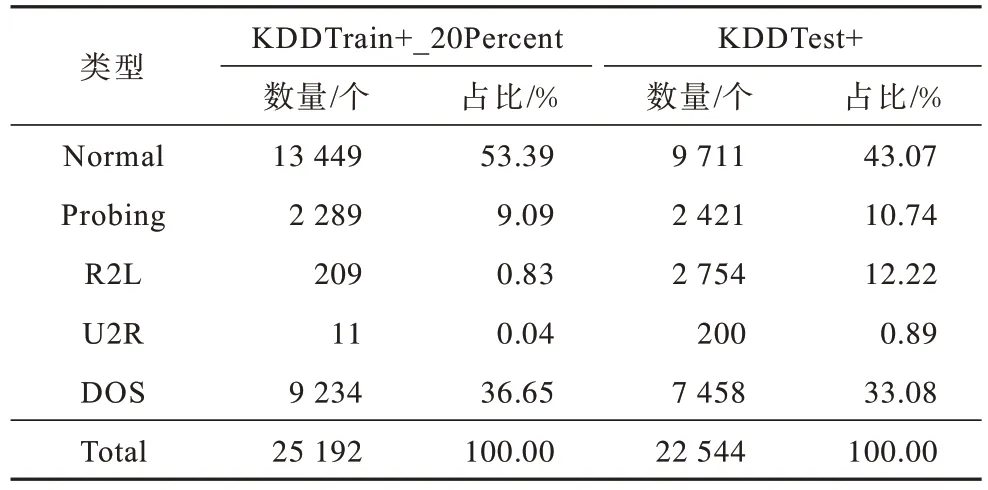
表3 初始數據集詳情Table 3 Details of initial dataset
訓練集經過OSW 數據預處理后的數據集詳情如表4 所示。
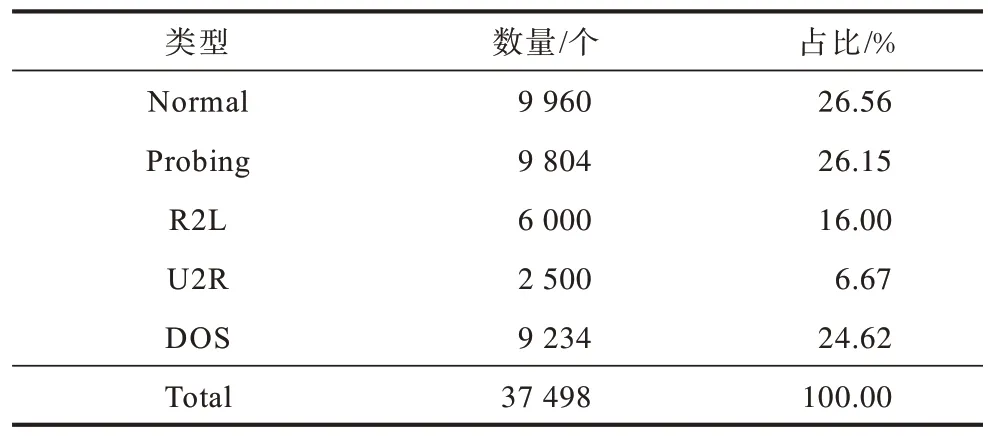
表4 預處理后的訓練集詳情Table 4 Details of pre-processed training set
2.3 評價標準
實驗指標由表5 中的混淆矩陣計算得到,其中,真正例(True Positive,TP)是將正常樣本預測為正常的數量,真反例(True Negative,TN)是將異常樣本預測為異常的數量,假反例(False Negative,FN)是將正常樣本預測為異常的數量,假正例(False Positive,FP)是將異常樣本預測為正常的數量。
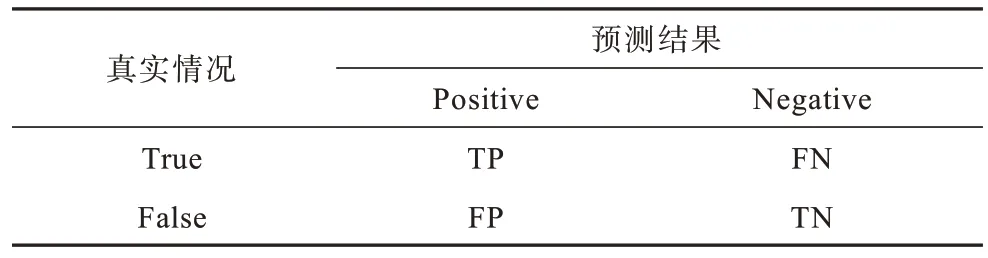
表5 混淆矩陣Table 5 Confusion matrix
實驗使用的評價指標主要有準確率(A)、查準率(P)、召回率(R)和F1-score,其中,準確率表示模型能夠正確分類的樣本數占總樣本數的比率,查準率表示被正確分類的樣本數與被檢索到的樣本數的比率,召回率表示被正確分類的樣本數與應當被正確分類的樣本數的比率,F1-score 表示基于查準率和召回率的調和平均數,計算公式分別如式(11)~式(14)所示:
在多分類任務中,將所有分類正確的數據個數除以總的數據個數得到多分類的準確率,如式(15)所示:
分別計算每一個分類類型的查準率、召回率和F1-score,之后對這些數值求和并求平均得到多分類任務的評價標準。以查準率為例的計算公式如式(16)所示:
其中:m表示分類類型個數。
2.4 參數設置
不同的超參數設置會影響模型收斂速度和實驗結果,本文實驗超參數配置情況如表6 所示。

表6 超參數配置Table 6 Configuration of hyperparameters
在訓練過程中,TBD 模型實驗采用Adam 優化器來優化模型參數,能夠自動調整學習率(Learning Rate),但初始學習率仍需要通過實驗來確定,否則可能直接收斂到很差的局部最優點。
2.4.1 學習率參數調優實驗
圖4 給出了在不同學習率下訓練集和測試集上的損失值變化情況。由圖4 可以看出:當學習率設置為0.000 01 時,TBD 模型在訓練集和測試集上均無法擬合;當學習率設置為0.000 1 或0.001 時,TBD模型在訓練集上能很好地進行擬合,但在測試集上學習率為0.000 1 時的擬合效果優于學習率為0.001時的擬合效果。因此,選擇0.000 1 作為TBD 模型的訓練學習率。
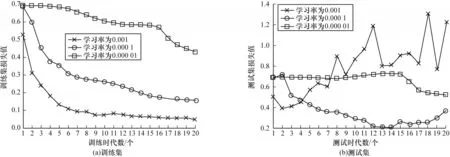
圖4 不同學習率下的實驗結果對比Fig.4 Comparison of experimental results with different learning rates
2.4.2 Dropout 參數調優實驗
圖5 給出了在不同Dropout 下訓練集和測試集上的損失值變化情況。由圖5 可以看出:當Dropout為0.7 時,由于TBD 模型訓練時丟棄網絡單元過多導致無法充分學習數據特征,損失值下降,擬合效果不佳;當Dropout 為0.3 或0.5 時,TBD 模型在一定的訓練時代之后均出現了不同程度的過擬合現象;當Dropout 為0.5 時,TBD 模型在測試集上的擬合效果優于將Dropout 設置為0.3 時的擬合效果。此外,還可以采取提前終止訓練的方法避免TBD 模型過擬合問題。綜上,TBD 模型選擇0.5 作為Dropout的值。
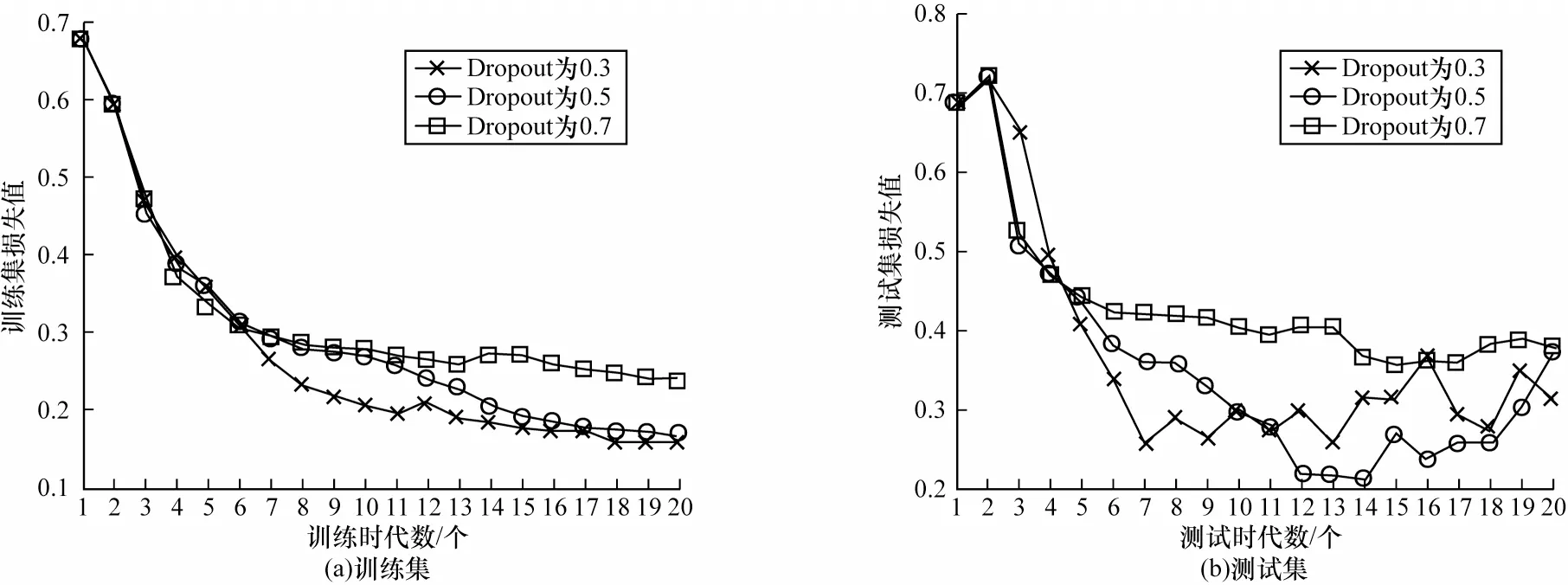
圖5 不同Dropout 下的實驗結果對比Fig.5 Comparison of experimental results with different Dropouts
2.5 結果分析
使用常用的SVM、決策樹(Decision Tree,DT)、隨機森林(Random Forest,RF)等機器學習算法以及以下4 個深度神經網絡模型作為實驗對比方法:
1)BiLSTM-DNN(BD)。該模型在TBD 模型的基礎上略去了Transformer 模塊,將其作為實驗對比模型以探究Transformer 模塊在本文模型中的重要作用。
2)MultiAttention-BiLSTM-DNN(MABD)。該模型是在TBD 模型的基礎上將Transformer 模塊替換為多頭注意力模塊,用于探究Transformer 模塊中的前饋神經網絡以及殘差連接對訓練準確度提升的作用。
3)Transformer-DNN(TD)。該模型在TBD 模型的基礎上略去了BiLSTM 模塊,用于探究BiLSTM模塊在保留數據時序特征和長距離依賴信息的作用上是否對分類結果產生影響。
4)Position-Transformer-DNN(PTD)。該模型在Transformer 的本體結構中,使用位置向量來保留數據中的時序信息,通過在TBD 模型中添加位置向量信息并略去BiLSTM 模塊來探究BiLSTM 模塊相對于位置向量的優越性。
在進行和未進行訓練集數據平衡處理的情況下對各個模型和算法進行訓練驗證,并且設置無下采樣、聚類中心(ClusterCentroids)和隨機下采樣(RandomUnder)等3 種算法來取代數據預處理中的下采樣算法以驗證OSS 的有效性。實驗結果如表7所示,其中SW 表示SMOTE+WGAN。
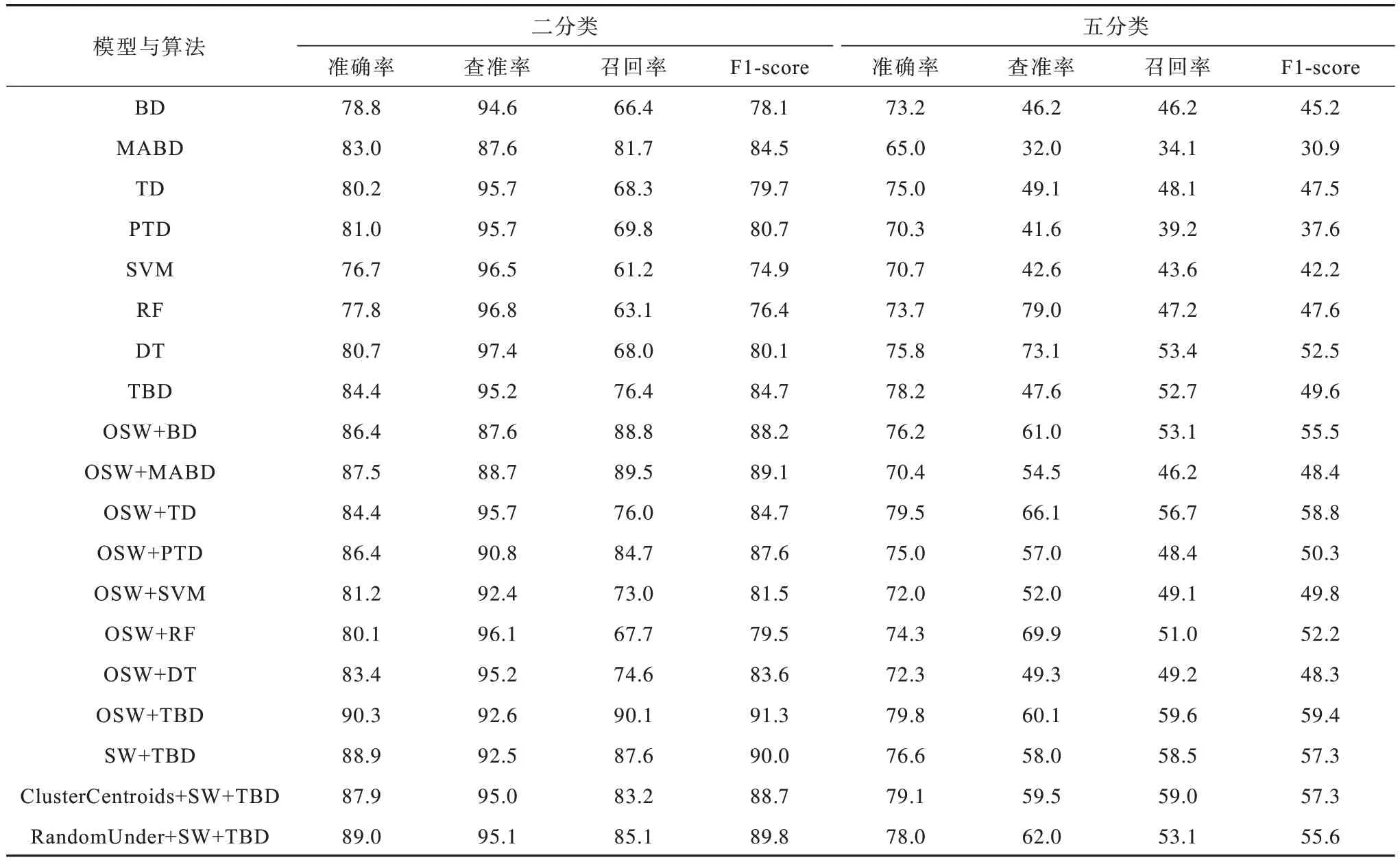
表7 不同深度神經網絡模型及機器學習算法的實驗結果對比Table 7 Comparison of experimental results of different deep learning network models and machine learning algorithms %
由表7 可以看出:
1)對于二分類而言:本文提出的OSW+TBD 模型準確率達到90.3%,高于經過數據平衡處理的其他對比模型和算法;省去了前饋神經網絡以及殘差連接的OSW+MABD 模型的準確率為87.5%,位居第二,表明Transformer 模塊相對于單純的多頭注意力模塊具有一定的優越性;其他模型和算法的準確率都在87.0%以下;TBD 模型的F1-score 較高。由此可以看出,經過數據平衡處理后,各個模型的實驗指標均得到較大提升,同時OSS 算法相對于其他下采樣算法在實驗中具有微弱優勢,這證明了數據平衡處理的必要性以及OSW 數據平衡處理模型的有效性。綜上所述,TBD 模型相對于只學習淺層特征的SVM、RF、DT 等傳統機器學習算法更具優越性,通過與BD、MABD、TD、PTD 等模型的比較也驗證了TBD 模型中每個模塊都具有重要的作用。
2)對于五分類而言:本文提出的OSW+TBD 模型準確率達到了79.8%,高于其他對比模型;OSW+TD 模型的準確率達到79.5%,位居第二;在二分類實驗中表現較好的OSW+MABD 模型的準確率只有70.4%,但文獻[25]指出準確率這一指標在不平衡數據中具有欺騙性,業界通常使用其他評估指標對不平衡學習進行評估,例如F1-score。由此可以看出,在經過OSW 訓練集數據平衡處理后,TBD 模型的F1-score 達到59.4%,優于其他模型。
綜上所述,在多分類實驗中,數據平衡處理具有重要的意義。相較于其他模型和算法,本文提出的OSW+TBD 模型在各類指標對比中均具有優越性。
3 結束語
本文構建針對不平衡數據處理的OSW 模型以及TBD 入侵檢測模型。OSW 模型充分發揮了SMOTE 算法和Wasserstein GAN 的優勢,能夠學習少數類數據的分布特征。在TBD 模型中:Transformer 模塊通過多頭注意力機制關注不同屬性特征之間的聯系,提取更加豐富的特征;BiLSTMDNN 模塊進一步提取深層次特征,并保留了特征的時序信息。實驗設置BD、MABD、TD、PTD 等4 種對比模型,驗證了TBD 模型中Transformer 模塊以及Transformer 模塊中前饋神經網絡和殘差連接的重要作用,也驗證了BiLSTM 獲取長距離依賴和保留時序信息的能力對結果具有重要影響。此外,通過對比進行和未進行訓練集數據平衡處理的模型實驗結果,證明了數據平衡處理的重要性和OSW 數據平衡處理模型的有效性。下一步將利用OSW 模型減少不平衡數據的影響,融合網絡流量包數據以及人工提取特征,以解決模型普適性[26]問題,并利用深度學習技術在特征提取方面的優勢,進一步提高檢測準確率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
