基于鄰域聚合與CNN 的知識圖譜實體類型補(bǔ)全
2023-03-16 10:21:02鄒長龍安敬民李冠宇
計算機(jī)工程 2023年3期
關(guān)鍵詞:模型
鄒長龍,安敬民,李冠宇
(大連海事大學(xué) 信息科學(xué)技術(shù)學(xué)院,遼寧 大連 116026)
0 概述
知識圖譜通常以RDF 三元組的形式陳述一條事實[1],表示為(e1,r,e2),其 中e1和e2為知識圖譜的實體,r為e1和e2之間的關(guān)系,例如,(Jackie Chan,Isborn,Hong Kong)。在知識圖譜中除三元組之外,還有大量的實體類型實例(實體-實體類型元組)[2],記為(e,t)。例如,(Jackie Chan,Actor)表示實體“Jackie Chan”的類型為“Actor”。知識圖譜中的實體類型信息可以用于各種下游任務(wù),例如實體對齊[3]、實體鏈接[4]、知識圖譜補(bǔ)全[5-6]等。實體類型信息的缺失會影響這些算法的有效性與準(zhǔn)確性,但知識圖譜在實體類型信息方面經(jīng)常存在信息不完整問題。
知識圖譜實體類型信息不完整的問題可以通過實體類型補(bǔ)全(推斷實體e的類型t)來解決。知識圖譜實體類型補(bǔ)全是知識圖譜補(bǔ)全的子問題。早期的知識圖譜實體類型補(bǔ)全模型主要以概率分布為基礎(chǔ)[7]。表示學(xué)習(xí)現(xiàn)已成為知識圖譜相關(guān)研究的基礎(chǔ)。對于知識圖譜,表示學(xué)習(xí)[8]是通過機(jī)器學(xué)習(xí)等方法學(xué)習(xí)知識圖譜中對象的低維嵌入向量表示,學(xué)習(xí)到的嵌入向量不僅可以保留知識圖譜中對象蘊含的語義信息,而且用于各種基于知識圖譜的下游任務(wù),例如知識圖譜補(bǔ)全[6]、推薦系統(tǒng)[9-10]。因此,表示學(xué)習(xí)技術(shù)通常被用于知識圖譜實體類型補(bǔ)全。
大多數(shù)基于表示學(xué)習(xí)的實體類型補(bǔ)全模型傾向于對實體-實體類型元組(e,t)進(jìn)行建模和實體類型補(bǔ)全,而沒有有效地利用關(guān)系。例如RESCAL-ET[10]、HOLE-ET[10]、TransE-ET[10]、ETE[10]等模型使用異步的方式學(xué)習(xí)實體、關(guān)系和實體類型,并進(jìn)行嵌入表示。雖然這些模型學(xué)習(xí)了關(guān)系的嵌入表示,但是關(guān)系嵌入中包含的信息在進(jìn)行實體類型補(bǔ)全時并沒有被使用。ConnectE[11]模型使用三元組、實體-實體類型元組和實體類型三元組進(jìn)行訓(xùn)練和實體類型補(bǔ)全。盡管ConnectE 通過實體類型三元組利用了關(guān)系,但實體類型三元組造成了測試集數(shù)據(jù)的泄露。這些模型的建模方法無法有效地利用知識圖譜三元組,特別是實體之間關(guān)系包含的信息。然而,三元組中關(guān)系的信息有助于推斷一個實體的所屬類型。例如:對于三元組(Chicago,Islocation,Illinois)和(Chicago,Iswriter,Rob Marshall),關(guān) 系“Islocation”和“Iswriter”的信息有助于推斷出實體“Chicago”的類型可能包括“City”和“Film”。同時,這些模型屬于距離模型(使用向量的L1 或L2 范數(shù)衡量實體和實體類型的相似性)生成特征的數(shù)量有限,導(dǎo)致模型表達(dá)能力不足。卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)用于學(xué)習(xí)嵌入的深層表達(dá)特征,在不增加嵌入維度的基礎(chǔ)上增強(qiáng)模型的表達(dá)能力[12]。
本文提出一種基于鄰域聚合與CNN 的知識圖譜實體類型補(bǔ)全模型NACE2T,使用編碼器-解碼器的結(jié)構(gòu)。編碼器利用注意力機(jī)制為實體鄰域中的每個關(guān)系-實體對分配權(quán)重,以聚合實體鄰域中的實體和關(guān)系包含的信息,達(dá)到利用知識圖譜三元組或?qū)嶓w之間關(guān)系的目的。此外,考慮到現(xiàn)有實體類型補(bǔ)全模型的表達(dá)能力有限,基于CNN 提出一個知識圖譜實體類型補(bǔ)全模型CE2T 作為解碼器,衡量編碼器輸出的實體嵌入和實體類型嵌入之間的相似性。
1 相關(guān)工作
文獻(xiàn)[13]利用領(lǐng)域知識和知識圖譜外部的文本數(shù)據(jù)進(jìn)行知識圖譜實體類型補(bǔ)全,并提出一個基于張量分解的模型。文獻(xiàn)[14]利用文本數(shù)據(jù)進(jìn)行實體類型補(bǔ)全,并提出一種基于神經(jīng)網(wǎng)絡(luò)的實體類型補(bǔ)全模型。本文主要使用知識圖譜的內(nèi)部數(shù)據(jù)(三元組和實體類型實例)進(jìn)行實體類型補(bǔ)全。
對于知識圖譜,表示學(xué)習(xí)技術(shù)[1,15]主要集中在學(xué)習(xí)實體和關(guān)系的嵌入向量表示[16-18],對編碼實體-實體類型元組和三元組學(xué)習(xí)實體、關(guān)系和實體類型嵌入表示的較少。因此,本文主要介紹對三元組和實體-實體類型元組(e,t)進(jìn)行建模的實體類型補(bǔ)全模型。
文獻(xiàn)[10]提出的實體類型補(bǔ)全方法采用異步的方式學(xué)習(xí)實體、關(guān)系和實體類型的嵌入向量。首先,使用知識圖譜補(bǔ)全方法,如TransE[15]、RESCAL[16]、HOLE[17]和ContE[18]學(xué)習(xí)實體 的嵌入向 量e,目 的是讓實體在向量空間中根據(jù)它們的類型進(jìn)行聚類,在實體的周圍嵌入類型;其次,在訓(xùn)練時保持實體的嵌入向量e不變,通過最小化實體嵌入向量e與實體類型嵌入向量t之間的距離來更新實體類型的嵌入向量t,稱 為TransE-ET、RESCAL-ET、HOLE-ET 和ETE。它們的評分函數(shù)?(e,t)=||e-t||L1,其中||x||L1表示向量的L1 范數(shù)。雖然這些方法在訓(xùn)練過程中利用實體之間的關(guān)系,但是在進(jìn)行實體類型補(bǔ)全時未利用關(guān)系蘊含的信息。
文獻(xiàn)[11]構(gòu)建的最新實體類型補(bǔ)全模型是ConnectE,提出實體嵌入和實體類型嵌入應(yīng)處于不同的向量空間。同時,ConnectE 為利用實體之間的關(guān)系,根據(jù)知識圖譜三元組引進(jìn)實體類型三元組。然而,實體類型三元組的創(chuàng)建方式?jīng)]有考慮到實體與不同的關(guān)系組合會表現(xiàn)出不同的語義[19]。此外,實體類型三元組導(dǎo)致測試集數(shù)據(jù)出現(xiàn)了泄露。ConnectE 的評分函數(shù)?(e,t)=||M·e-t||L2,其 中||x||L2表示向量的L2 范 數(shù)。ConnectE 同樣采用異步的方式進(jìn)行訓(xùn)練,其訓(xùn)練過程分為三個階段:1)使用TransE[15]訓(xùn)練實體嵌入和關(guān)系嵌入;2)訓(xùn)練實體類型嵌入和將實體嵌入從實體空間投影到實體類型空間的投影矩陣M;3)使用TransE 訓(xùn)練實體類型三元組,并且只改變關(guān)系的嵌入,實體類型嵌入保持不變。
雖然上述模型在嘗試進(jìn)行知識圖譜實體類型補(bǔ)全時利用關(guān)系,但是它們利用關(guān)系的方式都是采用異步的方式去學(xué)習(xí)實體、關(guān)系和實體類型的嵌入表示,導(dǎo)致時間開銷增大。本文提出的NACE2T 模型采用同步的訓(xùn)練方式,即同時學(xué)習(xí)實體、關(guān)系和實體類型的嵌入表示。
2 NACE2T 模型
NACE2T 模型采用編碼器-解碼器的結(jié)構(gòu)。編碼器為基于注意力機(jī)制的鄰域聚合器,用于利用知識圖譜中實體之間的關(guān)系。解碼器為基于CNN 設(shè)計的知識圖譜實體類型補(bǔ)全模型CE2T。NACE2T模型架構(gòu)如圖1 所示。

圖1 NACE2T 模型架構(gòu)Fig.1 Framework of NACE2T model
2.1 編碼器
對于一個三元組(ei,rk,ej),其嵌入向量分別為ei∈Rd,ej∈Rd和rk∈Rd。當(dāng)使用聚合器聚合實體ei鄰域中的信息時,生成ei新的嵌入表示為:
其中:Agg 表示聚合器;N(ei)表示實體ei的一跳鄰域;W1∈Rd×d1和W2∈Rd×d1表示線性變換矩陣;σ(·)表示非線性激活函數(shù)。
在知識圖譜中的實體之間通常存在一條含有豐富語義信息的關(guān)系,然而,式(1)在聚合過程中忽略關(guān)系,因此并不適用于知識圖譜。為了在進(jìn)行實體類型補(bǔ)全時利用實體之間的關(guān)系,本文的編碼器需要在聚合實體鄰域信息的過程中聚合關(guān)系的信息,因此,在聚合信息的過程中利用消息傳播機(jī)制[20]對實體和關(guān)系的嵌入進(jìn)行組合運算,形式為Rd×Rd→Rd。在此情況下,ei新的嵌入表示為:
其中:Riu表示鏈接實體ei與N(ei)中包含的實體關(guān)系集合;φ(·,·)表示組合運算;φ(u,r)表示實體u通過關(guān)系r到實體ei的消息。
聚合器Agg 的選擇有很多種,最常用的是圖卷積網(wǎng)絡(luò)(Graph Convolutional Network,GCN)[21]聚合器。但是GCN 在聚合信息的過程中會平等對待實體之間的邊或關(guān)系,即無差別地聚合實體鄰域中的信息[22],而實體鄰域中的某些信息可能對推斷實體所屬的類型沒有作用。該問題可以通過注意力機(jī)制來解決。同時,GCN 屬于直推式的圖神經(jīng)網(wǎng)絡(luò),無法使用mini batch 的思想來訓(xùn)練。為了使用mini batch 的思想來訓(xùn)練模型,本文的編碼器在實體的一跳鄰域中利用抽樣方法隨機(jī)選取固定數(shù)量的關(guān)系-實體對來聚合信息。
一般的注意力計算方法都是對知識圖譜中的實體和實體計算注意力[23],但是這種計算方法同樣會忽略實體之間的關(guān)系。為了在計算注意力時利用關(guān)系的信息,本文的編碼器對實體和關(guān)系-實體對計算注意力,或?qū)嶓w和消息φ(u,r)計算注意力。
給定一個三元組(ei,rk,ej),實 體ei和關(guān)系-實體對(rk,ej)之間的注意力計算如式(3)所示:
其中:o∈Rd表示一個參數(shù)向量;?表示按元素乘。由于在實體ei的一跳鄰域中可能有多個關(guān)系-實體對,因此使用Softmax 計算式(3)得到的aijk進(jìn)行歸一化,如式(4)所示:
其中:Rin表示鏈接實體ei與N(ei)中包含實體的關(guān)系集合。隨后,對實體ei鄰域中的關(guān)系-實體對的嵌入向量進(jìn)行加權(quán),計算聚合之后的信息,如式(5)所示:
與式(1)的形式類似,通過對實體ei的嵌入向量ei與s進(jìn)行整合,以構(gòu)建實體ei的最終嵌入表示,如式(6)所示:
注意力的計算過程與聚合信息的過程如圖1所示,圖中使用實體與關(guān)系-實體對之間的注意力聚合實體ei一跳鄰域中的實體ej和關(guān)系rk的信息,其中,αijk表示注意力,φ表示向量的組合運算。同時,編碼器可能需要聚合實體ei鄰域中的多跳信息。因此,使用投影操作對關(guān)系的嵌入向量進(jìn)行線性變換,如式(7)所示:
其中:Wr∈Rd×d1為線性變換投影矩陣。投影之后的關(guān)系嵌入向量維度與式(6)中的hi相同。當(dāng)需要聚合實體鄰域中的多跳信息時,只需重復(fù)執(zhí)行式(3)~式(7)。
2.2 解碼器
受CNN 在知識圖譜補(bǔ)全上應(yīng)用[11-12]的啟發(fā)[24-25],本文使用CNN 對實體-實體類型元組(e,t)進(jìn)行建模,構(gòu)建知識圖譜實體類型補(bǔ)全模型CE2T 作為解碼器。該解碼器由卷積層、池化層、投影層和內(nèi)積層組成。CE2T 的評分函數(shù)定義為:
其中:e∈Rd1表示編碼器輸出的實體最終嵌入向量(式(6)中的hi),d1 表示編碼器輸出的最終實體嵌入向量的維度;t∈R?表示實體類型的嵌入向量,?表示實體類型嵌入向量的維度;Ω表示卷積核的集合;W表示投影矩陣;*表示卷積運算;pool(·)表示池化操作;vec(·)表示拼接成向量。
CE2T 模型的架構(gòu)如圖2 所示。從圖2 可以看出:在前向傳播過程中,e作為卷積層的輸入。假設(shè)卷積核Ω∈R|Ω|×1×f,步長為cs,其中|Ω|為卷積核的個數(shù),1×f為卷積核的大小。則卷積層的輸出F=σ(e*Ω)∈R|Ω|×a×b,其中a=1,b=(d1-f)/cs+1。卷積層的輸出F作為池化層的輸入。設(shè)池化的窗口大小為1×p,步長為ps。則池化層的輸出P=pool(F)∈R|Ω|×m×n,其中m=1,n=(b-p)/ps+1。之后,將P重新拼接成向量vec(P)∈R|Ω|·m·n作為投影層的輸入。
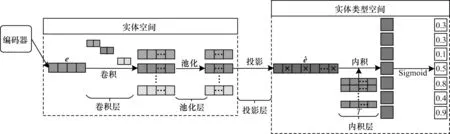
圖2 CE2T 模型架構(gòu)Fig.2 Framework of the CE2T model
由于實體和實體類型是知識圖譜中不同層次的對象[6],因此在解碼器CE2T中存在兩個不同的向量空間,分別記為實體空間和實體類型空間。投影層的作用是將卷積層和池化層提取的實體嵌入向量特征投影到實體類型空間。CE2T 模型與ConnectE[11]模型都采用了類似的投影策略,但ConnectE 模型投影的是實體的嵌入向量e,而CE2T 模型投影的是實體的特征向量(共|Ω|個,具體數(shù)量等于卷積核的個數(shù))。投影層的權(quán)重W∈R|Ω|·m·n×?。在實體類型空間中的實體投影向量=σ(vec(P)·W)∈R?。最后,實體的投影向量通過內(nèi)積與實體類型的嵌入向量t計算得到相似性評分。式(1)中的Ω和W是共享參數(shù),獨立于e和t。
2.3 NACE2T 模型的訓(xùn)練
為了快速訓(xùn)練NACE2T 模型,本文使用文獻(xiàn)[12]提出的1-N評分,即對一個實體的投影向量和所有實體類型的嵌入向量t進(jìn)行評分,如圖2 中的內(nèi)積層,其中T表示所有實體類型的嵌入向量組成的矩陣。同時,使用Sigmoid 函數(shù)將?(e,t)歸一化到0~1 之間,即p=Sigmoid(?(e,t)),并通過最小化二元交叉熵?fù)p失函數(shù)訓(xùn)練NACE2T 模型的參數(shù)。NACE2T 的損失函數(shù)定義如下:
其中:y∈R|T|表示二進(jìn)制的標(biāo)簽向量;T表示所有實體類型的集合;|T|表示實體類型的個數(shù)。如果(e,t)為真,則y的相應(yīng)位置為1,否則為0。優(yōu)化器選擇Adam。
2.4 問題定義與實現(xiàn)
知識圖譜實體類型補(bǔ)全的目標(biāo)是推斷給定實體e的類型t。對于在測試集中的每個實體e,NACE2T推斷的實體類型為:
NACE2T 模型推斷實體所屬類型的過程如下:首先,對于任意實體e,通過式(8)計算后得到|T|個評分,例如數(shù)據(jù)集FB15KET 含有3 854 個實體類型,則對于FB15K 中的任意實體,根據(jù)式(8)計算后得到3 854 個評分;然后,通過式(10)對這|T|個評分進(jìn)行排序,排序之后的最大值對應(yīng)的實體類型為NACE2T 模型推斷的實體類型。此外,對于NACE2T 模型,實體和實體類型之間的相似性評分是一個相對的指標(biāo)。NACE2T 模型使得正確實體類型和實體之間的相似性評分盡可能高,而錯誤實體類型和實體之間的相似性評分盡可能低。
3 實驗
本文實驗代碼使用Python 實現(xiàn),首先,使用CE2T 與NACE2T 進(jìn)行知識圖譜實體類型補(bǔ)全實驗,其次,對NACE2T 模型中向量的組合方式、關(guān)系-實體對的個數(shù)和卷積核的個數(shù)進(jìn)行分析。
3.1 數(shù)據(jù)集
在知識圖譜補(bǔ)全中經(jīng)常使用的兩個數(shù)據(jù)集是FB15K[15]和YAGO43K[10],分別是Freebase 和YAGO的子集。實體類型補(bǔ)全使用的實體-實體類型元組數(shù)據(jù)集(形式為實體、實體類型)稱為FB15KET[10]和YAGO43KET[10],分別將實體類型映射到FB15K 和YAGO43K 中的實體。FB15K 和FB15KET 與YAGO43K 和YAGO43KET 的統(tǒng)計數(shù)據(jù)如表1 所示。編碼器使用三元組數(shù)據(jù)集FB15K 和YAGO43K 來利用關(guān)系信息。CE2T 使用實體-實體類型元組數(shù)據(jù)集FB15KET 和YAGO43KET 學(xué)習(xí)實體類型的嵌入表示并進(jìn)行實體類型補(bǔ)全。

表1 數(shù)據(jù)集的統(tǒng)計數(shù)據(jù)Table 1 Statistics data of datasets
3.2 實驗設(shè)置
3.2.1 評價標(biāo)準(zhǔn)
本文采用知識圖譜補(bǔ)全任務(wù)中基于排名的標(biāo)準(zhǔn)對NACE2T 模型進(jìn)行評估[15]。首先,對于每個測試的實體-實體類型元組(e,t),移除類型;然后,根據(jù)式(10)進(jìn)行評分并排序;最后,根據(jù)正確實體類型獲得確切排名。本文采用兩個指標(biāo)進(jìn)行評估:平均倒數(shù)等級[15](MRR)和預(yù)測排名前k的正確實體類型比例[15](HITS@k)。MRR 與HITS@k的計算如式(11)和式(12)所示:
其中:|NET|表示測試集中實體-實體類型元組的數(shù)量;ranki表示第i個實體-實體類型元組的正確實體類型的位置;|Nk|(k取1、3、10)表示排名前k的正確實體類型個數(shù)。MRR 和HITS@k的值越大表示模型具有更優(yōu)的性能。
3.2.2 參數(shù)設(shè)置
本文使用網(wǎng)格搜索確定模型的最佳參數(shù)。在實體鄰域中關(guān)系-實體對的個數(shù)在[1,100]之間調(diào)整,實體和關(guān)系的嵌入維度在[50,200]之間調(diào)整,實體類型的嵌入維度在[100,300]之間調(diào)整,編碼器輸出的嵌入向量維度在[200,600]之間調(diào)整,批訓(xùn)練大小batch 在{128,256,512}中調(diào)整,學(xué)習(xí)率在[0.000 05,0.001]之間調(diào)整,CE2T 中卷積核的個數(shù)在{10,32,64,128}中調(diào)整,卷積核的大小在{1×2,1×4,1×8}中調(diào)整,卷積步長在[2,8]之間調(diào)整。池化選擇最大池化,窗口大小為1×2,步長為2。
3.3 實體類型補(bǔ)全結(jié)果分析
基線模型選擇RESCAL-ET[10]、HOLE-ET[10]、TransE-ET[10]、ConvKB[24]、CapsE[26]、ETE[10]和ConnectE[11]。不同模型的評價指標(biāo)對比如表2 所示,加粗表示最優(yōu)數(shù)據(jù)。

表2 不同模型的評價指標(biāo)對比Table 2 Evaluation indicators comparison among different models
從表2 可以看出,與最先進(jìn)的ETE 模型和ConnectE 模型相比,本文所提的NACE2T 模型具有較優(yōu)的結(jié)果。在不使用編碼器的情況下,CE2T 模型也取得較優(yōu)的效果,說明模型表達(dá)能力的提升可以提高實體類型補(bǔ)全的性能。相比RESCAL-ET、HOLE-ET、TransE-ET、ConvKB 和CapsE,NACE2T模型在實體類型補(bǔ)全性能上得到顯著提升。
在FB15KET 數(shù)據(jù)集上,CE2T 模型在所有評價指標(biāo)上相較于ETE 模型提高了約7%,與ConnectE 模型的各項指標(biāo)基本持平。NACE2T 模型相比ConnectE 模型的各項指標(biāo)提高約1.5%。
在YAGO43KET 數(shù)據(jù)集上,CE2T 模型相較于ETE模型和ConnectE 模型在MRR、HITS@1 和HITS@3 上分別提升約4%、6.5%和4.5%。同時,NACE2T 模型相比CE2T 模型在各項指標(biāo)上提升約2%,說明實體鄰域中實體和關(guān)系的信息有助于推斷實體所屬的實體類型。
此 外,RESCAL-ET、HOLE-ET 和TransE-ET 實體類型補(bǔ)全實驗的效果不佳,其原因是這些模型選用的知識圖譜補(bǔ)全方法使實體按類型聚類的效果一般。本文選擇FB15KET 中4 個實體類型且這4 個實體類型分別包含不同的實體。圖3 所示為使用RESCAL[16]、HOLE[17]和TransE[15]訓(xùn)練的實體嵌入向量經(jīng)過t-SNE 降維后的散點圖。

圖3 RESCAL、HOLE 和TransE 訓(xùn)練的實體嵌入向量可視化效果Fig.3 Visualization effect of entity embedding vectors trained by RESCAL,HOLE and TransE
從圖3 可以看出:4 個實體類型分別包含不同的實體,但都存在重疊的問題,說明聚類效果較差,特別是RESCAL。RESCAL-ET、HOLE-ET 和TransEET 在訓(xùn)練過程中不改變實體嵌入向量e,僅改變實體類型的嵌入向量t,使模型的性能極度依賴于RESCAL、HOLE 和 TransE 的聚類效果。而RESCAL、HOLE 和TransE 的聚類效果較差,間接導(dǎo)致RESCAL-ET、HOLE-ET 和TransE-ET 實體類型補(bǔ)全效果降低。ConnectE 同樣選擇使用TransE 對實體嵌入向量進(jìn)行訓(xùn)練,但是ConnectE 模型的實體類型補(bǔ)全性能相對于TransE-ET 模型有較大的提升。其主要原因是ConnectE 模型中包含一個可學(xué)習(xí)的投影矩陣M,雖然ConnectE 與TransE-ET 的訓(xùn)練方式大致相同,但是可學(xué)習(xí)投影矩陣M的存在使ConnectE的學(xué)習(xí)性能優(yōu)于TransE-ET。
在知識圖譜中一個實體通常會有多個實體類型,記為1-N,例如實體“Jackie Chan”的類型可以是“Actor”,也可以是“Person”。NACE2T 通過編碼器利用了實體鄰域中的信息,特別是關(guān)系的信息,因此,能夠有效地對1-N的情況進(jìn)行建模。
為檢驗NACE2T 對1-N情況(由于本文的目標(biāo)是推斷實體e的類型t,因此僅存在1-1 與1-N,不存在N-1和N-N等)進(jìn)行建模的效果,本文首先將FB15KET 和YAGO43KET 的測試集劃分為1-1 和1-N兩部分,然后在這兩部分測試集上分別使用ETE、ConnectE、CE2T和NACE2T 進(jìn)行實體類型補(bǔ)全實驗,實驗結(jié)果如表3和表4 所示。

表3 不同模型在1-1 實體類型補(bǔ)全實驗上的評價指標(biāo)對比Table 3 Evaluation indicators comparison among different models on 1-1 entity type completion experiment

表4 不同模型在1-N 實體類型補(bǔ)全實驗上的評價指標(biāo)對比Table 4 Evaluation indicators comparison among different models on 1-N entity type completion experiment
從表3 和表4 可以看出:NACE2T 在1-1 和1-N上的評價指標(biāo)均優(yōu)于ETE、ConnectE 和CE2T。其原因為NACE2T合理地利用了實體鄰域中實體和關(guān)系的信息,而這些信息有助于NACE2T 捕獲實體在對應(yīng)不同類型時的差異,能夠更有效地對1-N情況進(jìn)行建模。
3.4 向量組合方式對NACE2T 性能的影響
向量的組合方式φ(·,·)主要有:1)void:φ(u,v)=u;2)sub:φ(u,v)=u-v;3)corr:φ(u,v)=u★v。其中:★表示循環(huán)相關(guān)運算[17];void 表示聚合信息的過程中不聚合關(guān)系的信息。該實驗在FB15K 與FB15KET 上進(jìn)行,結(jié)果如表5 所示。

表5 NACE2T 利用不同向量組合方式的評價指標(biāo)對比Table 5 Evaluation indicators comparison of NACE2T using different vector combinations
從表5 可以看出:NACE2T(corr)和NACE2T(sub)的評價指標(biāo)優(yōu)于NACE2T(void),說明關(guān)系嵌入向量中包含的信息有助于推斷實體的所屬類型。同時,當(dāng)φ(u,v)=u-v時,NACE2T 模型具有較優(yōu)的效 果。除φ(u,v)=u以 外,對于不同的φ(u,v),NACE2T 模型在實體類型補(bǔ)全上的表現(xiàn)相差不明顯。
3.5 關(guān)系-實體對個數(shù)對NACE2T 性能的影響
在實體鄰域中關(guān)系-實體對的個數(shù)在[1,100]中調(diào)整,本文實驗在FB15KET 和YAGO43KET 數(shù)據(jù)集上進(jìn)行。關(guān)系-實體對個數(shù)對NACE2T 模型評價指標(biāo)的影響如圖4 所示。NACE2T 模型在FB15KET 數(shù)據(jù)集上的MRR 對應(yīng)于圖4 的左側(cè)坐標(biāo),在YAGO43KET數(shù)據(jù)集上的MRR 對應(yīng)于圖4 的右側(cè)坐標(biāo)。

圖4 關(guān)系-實體對個數(shù)對NACE2T 模型評價指標(biāo)的影響Fig.4 Influence of number of relationship-entity pairs on evaluation indexes of NACE2T model
從圖4 可以看出:當(dāng)關(guān)系-實體對的個數(shù)為1 時,NACE2T 在一定程度上會退化為CE2T 模型,此時NACE2T 的性能與CE2T 相似。隨著關(guān)系-實體對個數(shù)的增加,NACE2T 的性能不斷提高。在FB15KET數(shù)據(jù)集上,當(dāng)關(guān)系-實體對個數(shù)為20 時,NACE2T 具有較優(yōu)的評價指標(biāo)。當(dāng)關(guān)系-實體對個數(shù)大于60 時,NACE2T 的性能呈明顯的下降趨勢,這是因為在進(jìn)行實體類型補(bǔ)全時,實體鄰域中的某些關(guān)系-實體對的信息會成為噪聲,使NACE2T 不能充分地捕獲實體在對應(yīng)不同類型時的差異,導(dǎo)致性能降低。同時,側(cè)面反映出不是所有關(guān)系-實體對都對推斷一個實體的所屬類型有幫助。對于YAGO43KET 數(shù)據(jù)集,同樣存在這種下降的趨勢。
3.6 卷積核個數(shù)對NACE2T 性能的影響
為驗證卷積核個數(shù)對NACE2T 模型性能的影響,本文在實驗中僅改變卷積核的個數(shù),其他參數(shù)保持不變。卷積核的個數(shù)在[1,80]中調(diào)整。在不失一般性的情況下,在FB15KET 數(shù)據(jù)集上卷積核個數(shù)對NACE2T 模型評價指標(biāo)的影響如圖5 所示。

圖5 卷積核個數(shù)對NACE2T 模型評價指標(biāo)的影響Fig.5 Influence of the number of convolution kernels on evaluation indexes of NACE2T model
從圖5 可以看出:NACE2T 的性能隨著卷積核個數(shù)的增加而增加。當(dāng)卷積核的個數(shù)大于40 時,模型性能趨于平穩(wěn)。當(dāng)卷積核的個數(shù)為64 時,模型具有較優(yōu)的性能。因此,NACE2T 模型的性能不會隨著卷積核的改變出現(xiàn)較大的波動。
4 結(jié)束語
本文提出基于鄰域聚合與CNN 的知識圖譜實體類型補(bǔ)全模型。基于注意力機(jī)制設(shè)計用于利用關(guān)系信息的編碼器,通過對實體與其鄰域中的關(guān)系-實體對計算注意力,并將其用于聚合實體鄰域中實體和關(guān)系的信息。同時,針對現(xiàn)有知識圖譜實體類型補(bǔ)全模型表達(dá)能力不足,本文基于CNN 設(shè)計知識圖譜實體類型補(bǔ)全模型CE2T 作為解碼器,對編碼器輸出的實體最終嵌入向量和實體類型的嵌入向量進(jìn)行建模。實驗結(jié)果表明,與RESCAL、HOLE、TransE 等模型相比,本文所提的NACE2T 模型在MRR、HITS@1、HITS@3、HITS@10 評價指標(biāo)上得到顯著提升。后續(xù)將解糾纏表示學(xué)習(xí)應(yīng)用于NACE2T 模型,并進(jìn)行實體類型補(bǔ)全,以提高模型的表達(dá)能力和模型實體類型補(bǔ)全的準(zhǔn)確率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網(wǎng)絡(luò)安全與數(shù)據(jù)管理(2022年1期)2022-08-29 03:15:20
導(dǎo)航定位學(xué)報(2022年4期)2022-08-15 08:27:00
中學(xué)生數(shù)理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀(jì)智能(數(shù)學(xué)備考)(2021年9期)2021-11-24 01:14:36
成都醫(yī)學(xué)院學(xué)報(2021年2期)2021-07-19 08:35:14
新世紀(jì)智能(數(shù)學(xué)備考)(2020年9期)2021-01-04 00:25:14
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
