煤化工機器學習分類研究
2023-03-25 06:30:58*汪浩
當代化工研究 2023年4期
*汪 浩
(西安石油大學 化學化工學院 陜西 710065)
LIBS的原理屬于原子發射光譜法,在過去的20年里蓬勃發展。在鋼鐵、煙草、醫學和環境等各個領域,LIBS技術[1-2]已經被廣泛應用。目前,在對樣本進行更精確的分類、回歸、聚類等研究方面,越來越多的采用機器學習算法[3-4]與LIBS技術結合研究。Odhisea Gazeli等人[5-6]提出了將LIBS與機器學習算法相結合來檢測光譜信息方法,能夠實現對橄欖油高效、快速的分類方法;當使用線性判別分析算法(LDA)[7-8]構建模型時,該方法進行預測的預測結果準確率達到99.1%。DanielDiaz等人把主成分分析(PCA)算法和LIBS技術結合,搭建了應用于金礦石的分類模型。李曉慧等人提出了對脂肪、肌肉、皮膚等軟組織的判別方法,該方法采用了LIBS技術結合多元統計原理的方法,利用K最近鄰(KNN)算法和SVM算法搭建模型,最后驗證模型的魯棒性和準確性,采用交叉驗證法驗證的結果表明,在選擇KNN算法模型和SVM算法模型作為分類器時,模型的靈敏度達到了0.995,鑒別準確率超過99.84%。王平等人提出了一種用來對鐵礦石酸度進行分析的模型,采用LIBS技術與隨機森林(VIM-RF)算法結合搭建模型,由實驗結果可知,在模型的性能方面,采用的偏最小二乘法(PLS)模型次于VIM-RF模型的性能。趙云等人研發了一種用來檢測土壤Pb的污染程度,該模型原理基于LIBS技術和深度信念網絡(DBN)算法。驗證結果表明,LIBS數據能夠使用機器學習算法處理,模型預測的訓練集和測試集的準確率分別達到98.47%和90.62%。使用不同算法作為分類器,搭建模型實現不同煤礦標樣數據的高效、精確分類。首先利用一階導數、S-G平滑[9-10]、多元散射校正[11-12]、標準正態變量[13]、向量歸一化[14]五種預處理方法[15]對原始煤礦樣標光譜數據進行預處理,然后對光譜數據進行不同梯度比例劃分訓練集和測試集。再使用ELM[16]、SVM[17]和RF[18]算法作為分類器使用煤礦標樣數據進行分類。
1.實驗部分
(1)LIBS裝置。文中使用的Nd:YAG激光器是由法國Quantel公司生產,激光器的最大頻率10Hz,其最大脈沖能量為200mJ,激光波長為1064nm,脈沖持續時長為10ns;采用的光譜儀是產自荷蘭Avantes公司的七通道寬幅光譜儀,光譜的分辨率為0.1nm,光譜的范圍為190~950nm,有兩種方式來觸發外部設備,一種由采用外部TTL電平,另外一種是輸出電平。采用的可自由控制的XYZ軸的樣品臺,樣品臺的行程范圍為5cm,能夠實現微米級(<1μm)的定位高精度控制。
(2)數據集。本研究中使用數據集為28種煤標樣均以粉末狀購自濟南中標科技有限公司。將每個粉末樣品在28MPa的壓力下壓成顆粒5min。為了盡量減少樣品異質性的影響,在不同位置獲得了30個光譜,每個光譜是10個激光脈沖的平均值。
(3)建模環境。本文實驗平臺為Intel I5處理器,16GB RAM,Windows 11操作系統,編輯語言為Python3.7,IDE為PyCharm2022,框架為Pytorch10。
(4)數據預處理。為了實現光譜基線校正、消除背景的不同程度干擾、增強不同吸收特征的對比度和光譜特征值,對光譜進行一階導數處理;為了消除數據噪聲在提取光譜數據信息時產生的影響,采用S-G平滑進行預處理;為了消除樣品顆粒形狀大小對光譜產生的光譜誤差,增加光譜與數據間的關聯性,選擇多元散射校正(MSC)對光譜進行預處理;為了降低表面散射以及光程度變化所產生的光譜誤差影響,采用標準正態變量(SNV)對光譜進行預處理;在消除光程變化對光譜產生的影響時,通過光譜數據減去光譜的吸光度和平均值向量歸一化(VN)的方式來進行光譜與處理。
(5)建模原理。①極限學習機。在訓練單隱藏層前饋神經網絡(SLFN)時,采用傳統的SLFN訓練算法進行訓練與采用極限學習機(ELM)算法有區別,在輸入層權重和隱藏層偏置設置方面,極限學習機隨機選取參數,輸出層權重通過最小化根據訓練誤差項以及輸出層權重范數的正則項所組成的損失函數,按照Moore-Penrose(MP)廣義逆矩陣原理計算解析得出。我們假設給定訓練集(符號表達式,表示數據示例,表示數據示例對應的標記,集合代指所有訓練數據),極限學習機的隱藏節點數為L,與隱藏層前饋神經網絡的結構一樣,極限學習機的網絡結構如圖1所示。

圖1 極限學習機的網絡結構
對于一個神經網絡而言,我們完全可以把它看成一個“函數”,單從輸入輸出看就顯得簡單許多。很明顯圖1中,輸入部分為訓練樣本集X,隱藏層在中間,而從輸入層到隱藏層之間的部分是全連接層,記隱藏層的輸出為H(x),那么隱藏層輸出H(x)的公式如下:
隱藏層的輸入乘以對應權重參數再加上偏差,得到隱藏層的輸出,再通過非線性函數,將其全部節點結果求和得到。而隱藏層部分的節點的輸出函數并不固定為同一個函數,輸出函數的不同能夠應用在不同的隱藏層神經元。通常hi(x)在實際應用中如下表示:
②隨機森林。隨機森林(Random Forest,RF)算法屬于機器學習算法,作為分類算法比較高效。它由若干個子樹構成,而子樹又有子樹的子樹構成,每個子樹都是一個分類器,最終構成隨機森林分類器。所有子樹分類器統一采用自主抽樣法,隨機生成唯一的訓練集,根據自主抽樣技術的特點,能夠不間斷生成訓練集數據和測試集數據。森林由大量的樹木組成,隨機森林涉及處理許多決策樹。每棵樹預測目標變量的概率值,然后我們對產生最終輸出的概率進行平均,通過選擇有替換的數據點來創建數據集的第一個樣本。接下來,我們不使用所有輸入變量來創建決策樹,我們只使用可用的一個子集。每棵樹都被允許長到盡可能大的長度,并且不涉及修剪。
③支持向量機。支持向量機(Support Vector Machine,SVM)算法,是根據數學統計學理論而發展來的高效的機器學習算法。SVM算法設計的初衷是為了解決二進制的分類問題,為了提高數據類別的模型分類效果,引進了線性函數的假設平面到多維空間中運算。該算法利用變化的支持向量分類器,使其適用于評估非線性決策邊界。通過使用稱為kernels的特殊函數擴大特征變量空間。該算法考慮的決策邊界允許將特征變量標記為目標變量。它用于評估邊界的數學函數由下式給出,其中K代表核函數。
由于化學計量算法的特點,針對高維的LIBS光譜數據,不能有效處理高維特征向量數據。考慮到SVM算法的優秀全局收斂性的優勢,能夠定位高維特征空間中的邊界位置。SVM算法的步驟如下:A.針對不一樣的煤礦LIBS標樣數據,任意選取兩個樣本數據構造SVM模型,k類需建立K(K?1)/2個數量的分類器;B.利用分類器決策決定模型分類的結果。把LIBS特征數據集任意分為兩個部分,依次劃分為占總數據集的70%的訓練集以及占總數據集30%的測試集來驗證SVM模型的準確率。
2.結果與討論
為評估各個模型在不同規模訓練集中的表現,每個規模的訓練集按照訓練集和測試集的劃分比例隨機抽取10次進行實驗進行比較,把各模型在不同規模大小的訓練集上的每次運行時間、模型分類精確度以及模型預測標準偏差的平均值作為各個模型的最終性能評價參考指標值。
(1)分類準確率。分類的準確率是對RF、ELM、SVM模型分類結果是否可靠的衡量指標,模型的準確率越高,表示模型分類的可靠性越高。各個模型分別在不同大小規模的訓練集上的分類準確率情況如表1所示。

表1 各模型在不同規模的數據集上的分類精度(單位:%)
從表1可看出,不同比例的數據集中,各模型的性能隨著訓練集樣本的增加均逐漸增加,當訓練集和測試集規模比例達到588/252后,RF模型的分類精度達到99.05%以上。其中在各組數據集中,與ELM、SVM相比,訓練集規模大小RF的分類準確率均為最高,支持向量機的準確率稍次。由分析得出結論,集成學習可以把性能弱的分類器集成起來,進一步提高各個弱分類器模型的非線性分析能力;RF模型的分類準確率較高,分析認為RF算法能夠把樣品光譜數據之中的無效特征波長剔除出去,從而實現篩選最具樣品屬性特征的波長。ELM的分類準確率比SVM模型的低,代表核函數對ELM模型的鑒別能力幾乎沒有影響,然而其非線性建模性能比SVM算法差。
(2)運行時間。模型的運行時間是對分類模型工作效率的重要衡量參數,模型運行的時間越短表示煤礦分類模型的效率越高。如下表2展示了RF、ELM、SVM在不同規模大小的數據集上的模型運行時間。

表2 各模型在不同規模的數據集上的模型運行時間(單位:s)
由表2可看出,RF、ELM、SVM隨著訓練集規模大小的增加,模型運行時間均逐步增加,并且不論訓練集規模的大小,三個模型之中支持向量機模型的運行時間都最長,RF模型的運行時間第二,隨機森林模型的運行時間最短。研究分析可知,由于集成學習方式需要訓練多個弱分類器,從而完成最后網絡的訓練,導致RF模型只含有一個隱含層的網絡,并且不需要多次迭代尋優過程,從而減少了模型的運行時間。
(3)模型穩定性。為了驗證模型具有較強的應用穩定性,采用預測標準偏差(Standard deviation,STD)作為評估SVM、RF、ELM模型穩定性的評價指標。各個網絡模型在數據集按照不同比例劃分的訓練集上的STD參數如圖2所示。
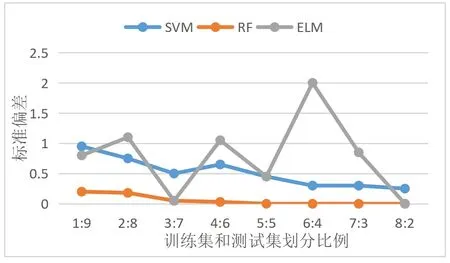
圖2 各模型在不同比例訓練集上的預測標準偏差
由圖2可看出,與極限學習機、支持向量機比較可知,按照不同比例大小劃分訓練集和測試集,隨機森林最低模型表現的STD值較低,支持向量機次之、極限學習機的STD值波動較大。結果顯示集成學習方法有助于提升隨機森林模型的穩定性。
3.結論
煤礦LIBS標樣數據分類模型,在效率和準確率以及穩定性方面能夠滿足分類需求。煤礦標樣LIBS光譜數據蘊含煤礦標樣的種類組成,以及元素含量等信息。文中對全光譜數據進行了數據預處理,建立極限學習機、隨機森林、支持向量機三種不同分類模型。極限學習機、隨機森林、支持向量機三種算法模型分類的準確率分別為83.1%、80.6%、90.4%,支持向量機的準確率最高。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
