個性化習題路徑推薦方法研究綜述
2023-04-07 01:47:10馮旭光張峰
軟件工程 2023年4期
馮旭光 張峰
關鍵詞:習題路徑推薦;個性化;全局最優路徑;局部迭代路徑;推薦算法
中圖分類號:TP391 文獻標識碼:A
1引言(Introduction)
在線題庫和在線判題系統[如“力扣”(leetcode),為全球程序員提供IT技術職業化提升的平臺]因學習資源多且用戶基數大,采用人工方式無法為每位平臺的學習者提供個性化指導。個性化習題路徑推薦旨在根據學習者的學習能力、知識背景等個性化特征,自動從題庫中選取適合該學習者的習題,并以合理的順序推薦習題。本文對近年來開展的個性化習題路徑研究工作進行了梳理,首先按照推薦形式的不同,將現有工作分為全局最優路徑推薦和局部迭代路徑推薦兩種類型,并對其實現方法和優點、缺點進行了介紹;然后對常用的五種個性化習題路徑推薦工作中常用的五種核心算法及使用這些算法的代表性工作進行了總結和歸納;最后從個性化特征的挖掘和習題路徑的合理性兩個角度闡述了當前該領域研究工作的難點及展望了未來的研究方向。
2個性化習題路徑推薦類型(Types of personalizedexercise path recommendation methods)
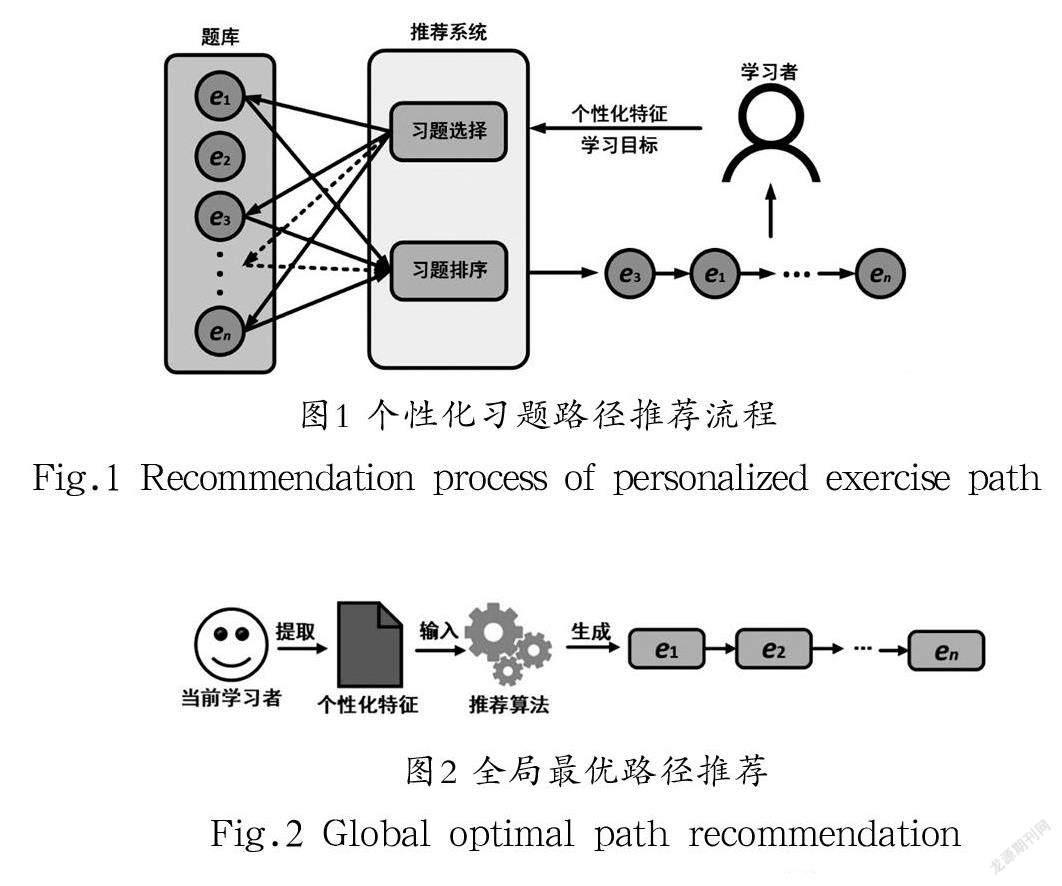
個性化習題路徑推薦的主要任務是根據學習者的知識水平、學習風格、學習習慣等個性化特征,從在線題庫中選擇適合學習者的題目,并按照習題特點和學習者的學習偏好對推薦的習題進行排序,最終以習題序列的形式推薦給學習者,個性化習題路徑推薦流程如圖1所示。
不同的個性化習題路徑推薦工作的實現方法和推薦目標各不相同。本文梳理了以往的個性化習題路徑推薦研究工作,借鑒云岳等[1]對個性化學習路徑推薦的研究思路,將現有的推薦方法按推薦形式分為注重完整推薦內容的全局最優路徑推薦和注重學習者學習過程的局部迭代路徑推薦兩種類型。本節將分別介紹兩類推薦方法及其優點和缺點。
2.1 全局最優路徑推薦
全局最優路徑推薦工作是從推薦內容的完整性出發,在一次推薦中為學習者呈現能夠滿足其學習目標的完整習題路徑,如圖2所示。該類方法能夠為學習者展示整個練習流程,方便學習者對將要練習的題目建立完整的認識和清晰的規劃。此外,全局最優路徑推薦中,每個推薦任務僅需運算一次,具有推薦速度快、運行效率高的特點。
在全局最優路徑推薦工作中,XIA等[2]首先將學習者答題結果劃分為六種類型,用于計算習題難度。然后將學習者已經完成的習題作為當前狀態,通過馬爾可夫模型計算出的轉移矩陣,得到后續每個習題的出現概率。最后根據轉移矩陣、習題難度和學習者需求,為學習者推薦流行路徑、挑戰路徑和漸進路徑。SEGAL等[3]提出了個性化習題難度排序算法(EduRank),用來為學習者生成個性化習題難度遞增序列。本研究根據相似學習者的已知難度排名,通過協同過濾投票機制,在不通過預測成績的情況下,直接為不同的學習者生成個性化的習題難度排序。XIA等[4]將習題路徑的練習范圍能夠覆蓋到所有指定的知識點作為推薦目標。本文首先定義了知識概念圖,用于表示知識點之間的關系;然后根據知識概念圖篩選出與目標知識點相關的所有題目;最后考慮習題難度,為學習者推薦符合知識點學習順序且難度適宜的習題路徑。
全局最優路徑推薦方法能夠為學習者提供完整習題路徑,但忽略了學習者在題目練習過程中知識水平等個性化特征的變化,導致路徑的后段推薦精度降低。
2.2 局部迭代路徑推薦
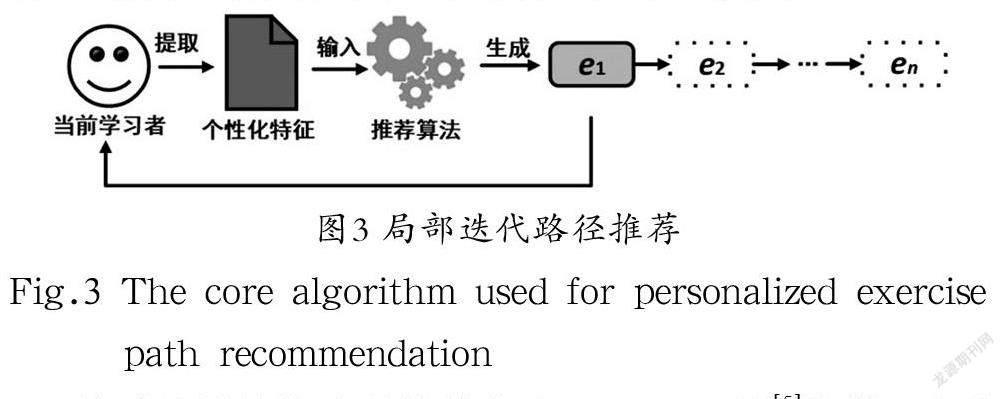
局部迭代路徑推薦方法考慮到學習者在學習過程中個性化特征的變化,在一個推薦任務當中,每次向學習者推薦部分習題,并收集學習者的練習得分、知識水平變化等信息,然后根據這些信息推薦后續習題,如此反復迭代,直到完成學習目標,如圖3所示。局部迭代路徑推薦以更細的粒度為學習者規劃習題路徑。通過追蹤學習者個性化特征的變化情況,局部迭代路徑推薦能夠實現更高的推薦精度。
針對局部迭代路徑推薦方法,SAI TO等[ 5 ]將學習者的當前能力和目標能力用圖表進行統計,并根據歷史學習者答題記錄使用長短期記憶神經網絡模型(Long Short-TermMemory,LSTM)推薦下一道適合學習者的習題。YERA等[6]使用協同過濾的方法,為學習者推薦下一道習題。本研究根據題庫中每道習題的回答狀態,將每位歷史學習者的學習記錄建模為學習者矩陣,對于每道沒有被當前學習者解決的習題,根據前k 個相似的用戶計算出推薦分數,并在每次推薦中推薦得分最高的習題。DIAO等[7]首先根據知識點的先決、包含和平行關系構造知識樹;然后將學習目標表示為知識點集合,根據知識樹表示的知識點之間的關系以及知識點掌握程度,為學習者逐步推薦未完全掌握知識點的相關習題。當學習者完成這些習題,則開始判斷學習者對知識點是否掌握,如果掌握,就推薦下一個知識點的習題,否則繼續推薦與該知識點相關的習題,直到學習者掌握最終目標知識點。
局部迭代路徑推薦方法考慮了學習者在練習過程中個性化特征發生的變化,但是由于習題路徑在學習過程中不斷生成,導致學習者難以把握學習任務的整體內容,也很難做到對學習進度的控制。此外,由于需要在一個任務中進行多次計算和推薦,所以增大了推薦系統的運行壓力。
3個性化習題路徑推薦所使用的核心算法(Themain algorithm used for personalized exercisepath recommendation)
推薦算法是一個推薦系統的核心,不同的推薦算法適用于不同的推薦目標和推薦場景。本節將介紹個性化習題路徑推薦工作使用最多的五類核心算法,即協同過濾、認知診斷、知識追蹤、深度學習和強化學習,并對使用各類算法的主要工作進行梳理和總結。
3.1基于協同過濾的方法
協同過濾根據其他用戶的偏好向目標用戶推薦,它首先找出一組與目標用戶偏好一致的鄰居用戶,然后分析該鄰居用戶,把鄰居用戶喜歡的項目推薦給目標用戶[8]。在基于協同過濾的習題路徑推薦工作中,LABAJ等[9]發現當學習者在沒有推薦的情況下自由選擇習題時,會選擇目前對他們來說比較容易和比較難的習題。為解決這個問題,本研究提出了一種基于相似學習者的難度反饋,為目標學習者推薦適當難度習題的推薦方法。TOLEDO等[10]將模糊技術應用于與協同過濾方法結合,根據其他用戶的歷史答題信息為當前用戶推薦習題路徑。本研究還提出了一種數據預處理方法,用于去除歷史信息中可能影響推薦的異常行為,進一步提高推薦精度。
3.2基于認知診斷的方法
認知診斷的目標是通過一批學習者在一批題目上的作答情況,分析每一位學習者對知識點的掌握程度。
在基于認知診斷的研究工作中,朱天宇等[11]首先使用認知診斷模型對學習者對知識點的掌握程度進行建模,然后結合概率矩陣分解方法預測學習者正確回答習題的概率pi,最后根據實際需求,設置推薦習題的難度范圍,即[β1,β2],并通過pi計算該習題對學習者的相對難度,篩選相對難度在推薦難度范圍內的試題,從而向每一位學習者進行個性化習題序列推薦。LI等[12]根據學習者選擇的知識點目標和期望的分數范圍,為學習者推薦與知識點目標高度契合的習題。首先,通過認知診斷判斷學習者對知識的掌握程度,并為每一位學習者對每個知識點的掌握程度標定等級。然后,通過歷史學習者的做題情況統計每道練習對它所包含的每個知識點的掌握程度的要求,并據此向學習者推薦習題。
3.3基于知識追蹤的方法
知識追蹤(Knowledge Tracing,KT)旨在建立學習者知識狀態隨時間變化的模型,以判斷學習者對知識的掌握程度。知識追蹤和認知診斷一樣,其目的都是為了獲得學習者對知識點的掌握度;它們區別在于認知診斷需要一批學習者的一批答題記錄,知識追蹤則只需要一個學習者對應的答題序列,并動態更新學習者的實時知識點掌握度[13]。
在基于知識追蹤的工作當中,WU等[ 1 4 ]從知識點覆蓋度、知識點掌握程度、習題多樣性三個角度為學習者規劃習題路徑。首先,本研究使用向量表示每道題目的知識點覆蓋情況。然后,基于RNN神經網絡,根據學習者從開始學習到現在所完成的練習,預測下一次出現的練習應該包括哪些知識點,并使用深度知識追蹤(Deep Knowledge Tracing,DKT)預測學習者對這些知識點掌握程度。最后,通過學習者對不同知識點的掌握程度,為學習者推薦練習范圍能夠覆蓋到掌握程度不足的所有知識點,且習題具有適當難度的習題路徑。為保證推薦的習題路徑具有新穎性和多樣性,本研究還加入了兩個過濾層用來過濾重復和相似的習題。DAVID等[15]考慮到單一的知識追蹤模型并不適合所有的學習場景,于是設計了一種多模型選擇算法,根據被推薦者過去的做題情況,從訓練好的多個模型中選擇最優模型,然后根據這個模型預測的知識點掌握程度和分數,為每一道待推薦的習題進行打分,每次向學習者推薦得分最高的習題。
3.4 基于深度學習的方法
近年來,深度學習被廣泛應用于教育推薦領域。各類深度學習算法的訓練本質上都是對自然界復雜映射關系進行抽象與擬合,而學習者與習題路徑之間正對應一種復雜的映射關系,其中的規律從理論上可由深度神經網絡進行表示和學習。
在基于深度學習方法的研究工作中,WANG等[16]首先使用深度學習訓練和生成學習者和練習習題的初始特征表示,然后使用因果推理干預算法對這些特征進行微調,最后再次使用深度學習預測學習者做習題的得分情況,并從中挑選難度適宜的習題推薦給相應的學習者。FANTOZZI等[17]基于自動編碼神經網絡(Auto-encoder Neural Network,ANN)構造了一種推薦方法,能夠逐步為學習者推薦難度遞增的習題序列。HUO等[18]認為目前的知識追蹤方法不足以對學習者的知識狀態進行個性化建模,并提出了一種個性化的建模方法,通過LSTM網絡為每一位學習者估計和維護一個獨立的知識狀態向量,并由此構造了一種新的個性化習題推薦模型,其具有個性化機制的長短期記憶神經網絡模型(LSTMCQP)。實驗證明,該模型推薦不同練習的能力優于現有方法。
3.5基于強化學習的方法
強化學習(Reinforcement Learning,RL)是一個用于目標導向學習和順序決策建模和自動化的計算框架。RL特別適用于涉及代理人需要學習在不同情況下做什么的策略——即如何將狀態映射到行動上,以使長期利益最大化的設置。
在基于強化學習方法的研究工作中,HUANG等[19]將學習者的做題過程抽象成一個馬爾科夫過程,并使用深度強化學習推薦下一步的最優習題。在該過程中,作者設計了三個獎勵函數用于同時優化三個推薦目標。CAI等[20]將學習者的習題練習過程表示為馬爾可夫決策過程,并使用深度知識追蹤技術從學習者練習習題的過程中動態檢索學習者的知識水平,并將其作為學習狀態,在此基礎上使用強化學習技術為學習者推薦最優的習題。
4研究難點與未來發展方向(Research difficultiesand future development direction)
根據對個性化習題路徑推薦領域的分析和研究,其研究難點及未來的發展方向主要體現在以下兩個方面。
(1)個性化特征的挖掘。在個性化習題路徑推薦方法中,一個關鍵步驟是根據學習者的個性化特征對其進行建模。然而,不同學習者進行習題練習的場景和目的各不相同,如何根據不同的推薦場景和學習目標挖掘具有代表性的個性化特征,成為能否成功推薦個性化習題路徑的關鍵,這也是個性化習題路徑推薦領域目前研究的難點之一。
(2)習題路徑的合理性。隨著信息技術與傳統教育方法的融合,許多優秀的教育理論被應用在電子學習之中。針對個性化習題路徑推薦領域,如何將更為科學的教育理論應用到推薦技術當中,使習題路徑在滿足學習者個性化要求的基礎上符合教育規律,是目前面臨的主要困難和未來重要研究方向。
6結論(Conclusion)
個性化習題路徑推薦作為在線學習的一個研究領域,有很多需要深入研究的問題。本文對近年來針對個性化習題路徑推薦的相關研究工作,從推薦形式和核心方法兩個角度對其進行了分類和整理,并對當前的研究難點和未來的研究方向進行了闡述。希望能夠為個性化習題路徑推薦研究領域構建一個較為完整的全景圖,為相關研究人員提供參考和借鑒。
作者簡介:
馮旭光(1997-),男,碩士生.研究領域:教育數據挖掘.張 峰(1981-),男,博士,副教授.研究領域:教育數據挖掘,軟件工程.本文通信作者.
