基于深度學習的文本情感聊天機器人系統的設計與實現
2023-04-07 05:47:53上官鑫呂俊玉張桓宇劉力軍
軟件工程 2023年4期
關鍵詞:深度學習
上官鑫 呂俊玉 張桓宇 劉力軍

關鍵詞:情感監督;Seq2Seq;注意力機制;深度學習
中圖分類號:TP311.1 文獻標識碼:A
1引言(Introduction)
近年來,隨著人工智能技術的不斷發展,通過自然語言與人類進行對話的聊天機器人成為研究熱點,并因深度學習在自然語言處理、詞向量表示、情感分析等領域的廣泛應用,使其逐漸成為研究聊天機器人的關鍵技術[1]。目前,許多商業公司推出了應用深度學習技術的相關產品,如“蘋果”的Siri、“微軟”的小冰、“百度”的度秘等。雖然現有聊天機器人都可以與人類進行無差錯交流,普遍表現出“智商”很高,但是人們在日常交換信息的過程中,傳達的信息不僅包含信息語義本身,還包含著情感與情感狀態。為了使人機對話更加貼近現實,人們寄希望于聊天機器人具有“智商”的同時也具有“情商”。本文提出基于深度學習的文本情感聊天機器人系統,滿足人們進行日常文本聊天中對情感的需求,具有支持中英雙語對話、情感分類多元、適用多領域對話的功能,提升了用戶在日常閑聊時的使用體驗。
2研究現狀(Research status)
現有的文本聊天機器人按功能可劃分為任務型和非任務型。針對日常聊天應用場景,采用非任務型可以更好地提升用戶使用體驗,提高用戶滿意度。非任務型聊天機器人按對話的實現方式可以分為檢索式對話系統和生成式對話系統[2]。基于檢索式的聊天機器人的回復語句存有單一匹配關鍵字的問題,其利用信息檢索技術為用戶會話請求匹配已經事先存儲的對話語料作為回復[3]。基于生成式的聊天機器人,在現有的研究基礎上其回復語句多使用情感通用性回復語句,情感單一[4]。此類聊天機器人多采用Encoder-Decoder(編碼器-解碼器)框架中的Seq2Seq模型,其主要應用端到端框架[5],利用大量自然語言訓練集學習從問題到答案的關系,從而根據用戶輸入語句自動生成相應的回復,具備一定的自我學習能力。一些研究表明,基于Seq2Seq模型對于短句子有著較好的表現,但對于長句子則表現力有所下降。注意力機制可以選擇性地學習句子中的部分單詞或片段[6],從而更好地處理長句子。目前在情感對話領域,許多研究者將各種端到端的神經網絡模型作為情感對話生成模型的基礎,并通過情感分析、情感嵌入等技術對模型進行改進,實現了在對話生成中的情感表達[7]。周震卿等[8]提出了基于TextCNN(文本卷積神經網絡)情感預測器的情感監督聊天機器人,在Seq2Seq模型中引入更準確的情感特征,由問題直接獲取回復的情感表示,有效地提高了回復語句的質量,但存在不能區分情感類別和對長文本不敏感的問題。
3系統設計(System design)
本系統采用Seq2Seq+Attention(序列到序列+注意力機制)模型,解決現有文本聊天機器人存在的單一匹配問題。構建TextCNN-BiLSTM-SlefAttention(文本卷積神經網絡-雙向長短期記憶網絡-自注意力機制)情感分類器,獲得具備表示文本情感的情感向量和情感分類向量。為了讓聊天機器人具有更好的情感回復表達,將情感向量嵌入基于GRU的Seq2Seq+Attention對話模型中,同時將情感分類向量加入訓練模型的損失函數中,實現對話過程中的情感監督,避免產生通用性情感回復語句。運用豐富的數據集進行模型訓練,實現中英文對話,滿足了文本聊天中的多領域對話需求。使用微信小程序作為系統的前端,實現前后端分離,便于前端優化和功能更新。
3.1系統框架結構
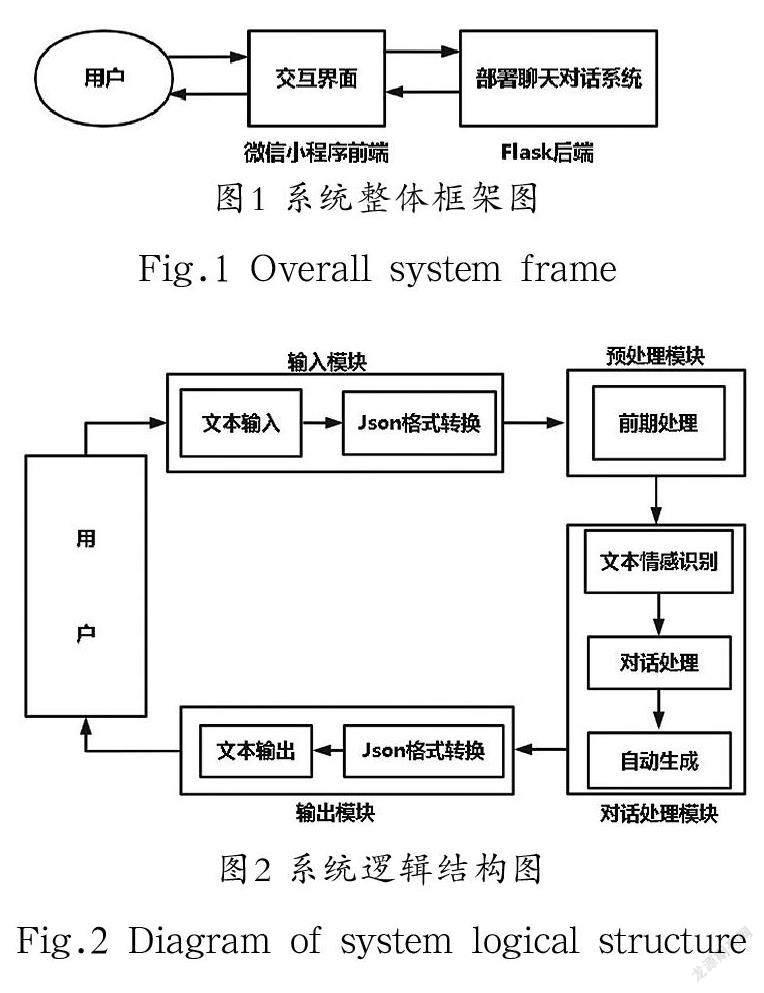
本系統采用分離式前后端部署的方式,前端部署在微信小程序中,與用戶進行交互;后端部署在Flask(Web應用程序框架)中,對用戶信息進行處理與反饋。系統的整體框架如圖1所示。
本系統邏輯結構分為輸入模塊、預處理模塊、對話處理模塊、輸出模塊,系統的邏輯結構如圖2所示。
系統邏輯結構流程如下:
①用戶在交互界面輸入文本;
②輸入文本經格式轉換后傳輸到后端服務器;
③后端服務器將接收到的文本進行格式化預處理;
④將預處理后的文本輸入對話處理模塊中自動生成回復文本;
⑤回復文本經格式轉換后返回給用戶。
3.2情感分類模型
關于文本情感分類的研究,一般是對情感類別(褒義、中性、貶義)進行情感分類;原福永等[9]提出將BiLSTM(雙向長短期記憶網絡)與CNN(卷積神經網絡)模型結合,與此同時引入Attention(注意力)機制實現對人們的情感進行分類;李輝等[10]提出將CNNGRU-Attention混合,實現二元(消極、積極)分類,并引入Attention機制構建混合神經網絡模型學習重要文本信息。
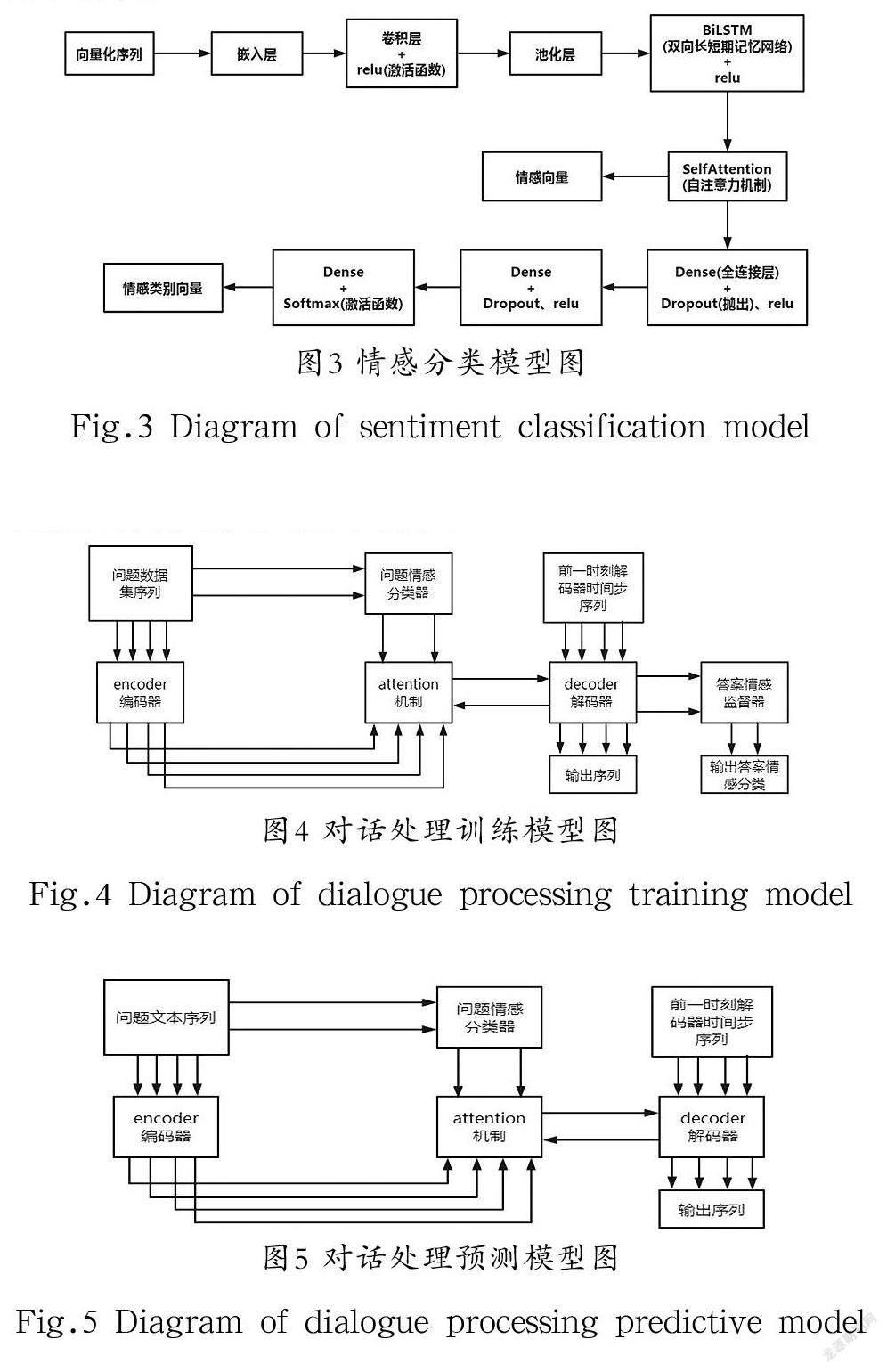
本系統通過構建TextCNN-BiLSTM-SelfAttention情感分類模型,應用于問題情感分類器和答案情感監督器。以憤怒、反感、害怕、內疚、快樂、難過、羞愧7類情感作為情感分類標簽,對輸入文本進行情感類別預測,其情感分類模型如圖3所示。
3.3 對話處理訓練模型
通過Seq2Seq+Attention模型與情感分類模型結合,構建對話處理訓練模型,如圖4所示。
對話處理的訓練流程如下:①將問題數據集序列分別輸入編碼器和問題情感分類器中,產生編碼向量和情感向量;②將上述產生的向量及decoder(解碼器)的hidden state(隱藏狀態)經過注意力機制產生context vector(上下文張量);③將答案數據集序列及context vector加入解碼器中,輸出回復向量及hidden state向量;④將hidden state向量輸入到答案情感監督器中,輸出情感分類向量;⑤將解碼器輸出的回復向量和答案情感監督器輸出的情感分類向量加入對話訓練模型的損失函數中,使對話訓練模型在訓練過程中實現情感監督。
3.4對話處理預測模型
本系統采用對話處理訓練模型去除答案情感監督器構成對話處理預測模型,從而進行對話處理預測,如圖5所示。
對話處理的預測流程如下:①將問題數據集序列分別輸入編碼器和問題情感分類器中,產生編碼向量和情感向量;②將上述產生的向量以及decoder的hidden state經過attention機制產生context vector;③將解碼時間步序列以及contextvector輸入解碼器中,輸出對話預測序列。
4系統實現(System implementation)
系統實現分為前端設計實現、數據預處理、對話處理和系統部署四個部分。
4.1實現環境
本系統實現環境詳見表1。
4.2前端設計實現
本系統的前端設計實現分為界面設計模塊,實現用戶交互界面;輸入模塊,實現對話文本更新。
4.2.1界面設計模塊
微信小程序框架系統分為邏輯層和視圖層。邏輯層使用JavaScript引擎,將數據進行處理后發送給視圖層,同時接收視圖層的事件反饋。視圖層由WXML(頁面文件)、WXSS(樣式文件)編寫,將邏輯層的數據反映到視圖層,同時將視圖層的事件發送給邏輯層。WXML用于描述頁面的結構,WXSS用于描述頁面的格式。
本系統實現的前端界面由對話框和輸入框構成,對話框實現用戶對話內容展示,輸入框接收用戶輸入文本,如圖6所示。
在對話框中實現聊天文本更新的流程,如圖7所示。
圖7中,msg為獲得的問題文本/答案文本;msglist為對話過程中產生的問題、答案文本集;wx:for(msglist)為頁面循環渲染msglist;scroll-into-view:bottom為將scroll-view窗口滾動到最低端(bottom為msglist的長度)。
該模塊流程如下:
①邏輯層在獲得輸入文本后,將輸入文本加入用戶對話列表中;
②視圖層進行頁面的重新渲染,將輸入文本信息展現在對話框中。
4.2.2輸入模塊
本模塊通過對用戶的輸入文本類別進行判斷,然后經過json格式轉換傳輸到后端服務器,從而進行相對應語言的對話預測處理,如圖8所示。
4.3數據預處理
為了完成本系統語言模型的構建、訓練以及生成對話,需要大量的數據集。基于目前已有數據集的基礎上,對其進行整理、預處理后加入對話生成模型中。整理數據集時發現,電影字幕文件的對話素材較為豐富,因此采用康奈爾大學電影對話語料作為對話處理訓練模型的訓練數據集。采用帶有情感標注的情感數據集作為問題情感分類器的訓練數據集;此外,收集了ai(人工智能)、food(食品)、history(歷史)、movies(電影)、literature(文學)等17 種話題領域的數據集實現中文多領域對話。
數據預處理流程如圖9所示。
(1)對數據集中的文本進行清洗分割(以電影對話語料庫為例)。使用Python的正則庫re,其中re.sub()函數對數據集中的問題和答案對進行清洗分割;給問題、答案字符串的前后加上‘\t(開始)、‘\n(結束)標志;得到Question_list,Answer_list;其中,問題格式如‘\t how are you ?\n,答案格式如‘\t i am fine ! \n。
(2)將切割分詞后的文本轉換為向量化數字序列。將得到的Question_list、Answer_list,經keras_preprocessing.Text.Tokenizer()處理得到Question_list_ids(問題向量化數字序列)、Question_vocab(問題字典)、Answer_list_ids(答案向量化數字序列)、Answer_vocab(答案字典)。keras_preprocessing.Text.Tokenizer:keras中的一個文本標記實用類,將每個文本轉化為一個整數序列,其每個整數都是詞典中標記的序列。
( 3 ) 將得到的向量化數字序列, 進行p a d d i ng填充。將得到的Question_list_ids、Answer_list_ids,經keras_preprocessing.sequence.pad_sequences()處理,獲得定長的問題、答案向量化數字序列。keras_preprocessing.sequence.pad_sequences:將序列轉化為經過填充后得到的一個長度相同的新序列。
4.4對話處理
將數據集樣本對放入系統構建的模型進行訓練,實現對話處理,完成對輸入文本的預測回復。系統模型訓練可分為問題情感分類器訓練和對話處理模型訓練。
4.4.1問題情感分類器訓練
問題情感分類器的嵌入層采用keras的自定義嵌入層(embedding layer),其embedding layer所有的words(單詞序列)被隨機初始化,將正整數(單詞序號)轉換為具有固定大小的向量。通過單層的卷積和池化進行特征提取,同時卷積層使用ReLU激活函數,對特征向量進行非線性處理,避免了梯度消失和爆炸的問題,并提高BiLSTM的訓練計算效率。BiLSTM獲取抽取后輸入特征向量間的相關性,同時關注“頭部”和“尾部”的信息,可以更好地學習長序列信息。SelfAttention針對BiLSTM輸出的特征向量,捕獲遠距離的特征,將SelfAttention輸出的特征序列作為輸入文本的情感向量。使用全連接層、Dropout機制防止過擬合,提升模型訓練效率。同時,使用Softmax激活函數對特征向量歸一化處理,輸出情感類別向量序列。
現有的情感分類一般是簡單的二元(消極、積極)或三元分類(消極、積極、中立),然而人的情感更加多元,因此本系統構建的情感分類模型為多分類模型。在實現上,采用分類交叉熵損失函數作為該模型的損失函數,將帶有情感標注的情感數據集輸入問題情感分類器中,實現模型的訓練。
4.4.2對話處理訓練模型
對話處理訓練模型分為情感分類器模塊、編碼器模塊、解碼器模塊。模型訓練回合數epochs設為50,batch size設為64。
(1)情感分類器模塊。加載已經訓練好的問題情感分類模型輸入問題向量化數字序列,得到情感向量和問題情感分類向量。
(2)編碼器模塊。將問題向量化數字序列輸入編碼器中,得到編碼輸出序列和最后的隱藏狀態序列。編碼器由嵌入層、GRU(門控循環單元)層構成,其中GRU設置為可返回隱藏狀態序列,如圖10所示。在選取編碼器輸入數據集時,首先對問題文本數據集進行抽取后,得到15,838 個規格化的問題文本集,抽取得到問題文本集的90%作為模型訓練集,10%作為模型驗證集。
(3)解碼器模塊。將編碼器輸出的向量序列和注意力機制對輸入文本選擇性學習得到的向量序列輸入到解碼器中。解碼器由嵌入層、GRU、全連接層組成,如圖11所示。在選取解碼器輸入數據集時,對答案文本數據集進行抽取后,得到15,838 個規格化的答案文本集,單個文本格式如‘\t i amfine !\n;抽取得到答案文本集的90%作為模型訓練集,10%作為模型驗證集。
4.5系統部署
微信小程序作為前端,實現微信小程序與用戶交互;Flask框架作為后端服務器,依載對話模型,并實現與微信小程序的通信。
4.5.1微信小程序
微信小程序的前端代碼存儲于微信服務器之中,在騰訊云端存放,無須加載,可以直接打開,響應速度較快。使用wx.request API(請求函數接口)與Flask后端服務器進行通信。
wx.request模板:
wx.request({
Url:,
Data:,
Method:'POST',
Header:{
'content-type':'application/x-www-form-urlencoded'
},
})
4.5.2 Flask后端
利用Python的Flask框架搭建后端服務器,可擴展性強,在開發過程中不需要HTTP請求的發送和接收。
app.run(host='127.0.0.1',port=5000,debug=True):設置服務端的IP地址和端口號;
@app.route():設置對話處理函數所綁定的URL;
Request.values:獲得Post表單的數據部分;
Return:將對話處理結果以json格式返回給前端。
5 系統展示(System display)
本系統的功能展示如圖12所示。
6結論(Conclusion)
本研究提出了一種基于深度學習的文本情感聊天機器人系統,該系統屬于生成式聊天機器人系統,解決了單一匹配知識庫問題且適用于多領域對話。同時,在對話過程中引入情感監督,實現了對話過程中的情感回復與響應,提高了生成回復語句的情感質量,有效拓展了文本聊天機器人的情感交互功能。此外,在系統部署上使用更加靈活的分離式框架搭建,便于前端優化和功能更新。從整體上看,本系統具有一定的創新性和較好的應用前景。
作者簡介:
上官鑫(2000-),男,本科生.研究領域:自然語言處理.
呂俊玉(2001-),女,本科生.研究領域:自然語言處理.
張桓宇(1999-),男,本科生.研究領域:自然語言處理.
劉力軍(1979-),男,碩士,講師.研究領域:網絡技術.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
