采用雙支路和Transformer的視杯視盤分割方法
2023-04-08 13:59:06王甜甜史衛亞張世強張紹文
科學技術與工程 2023年6期
王甜甜, 史衛亞, 張世強, 張紹文
(1.河南工業大學信息科學與工程學院, 鄭州 450001; 2.河南工業大學糧食信息處理與控制教育部重點實驗室, 鄭州 450001;3.河南工業大學人工智能與大數據學院, 鄭州 450001)
青光眼在早期階段沒有病癥,但可導致神經受損,進而導致視力下降[1]。視盤(optic disc,OD)是眼底圖像中較明亮的區域,近似橢圓形;視杯(optic cup,OC)是視盤區域上存在的可變尺度的中央凹陷[2]。隨著眼底圖像分割技術的發展,基于OC和OD比率(cup-to-disc ratio,CDR)的客觀評估方法成為可能[3]。以往的研究[4]表明,CDR的值越大,患青光眼的概率就越高。該評估方法要求能夠精確分割出視盤和視杯,因此得到一個精確的自動分割視杯和視盤的算法至關重要[5]。
病變區域會對分割結果產生影響,可以通過預處理操作裁剪感興趣區域(region of interest, ROI)來緩解該問題。因此,學者們將多種方法應用于視盤定位。李寧等[6]利用空洞空間金字塔模塊和金字塔池化模塊對視盤中心進行定位。Park等[7]使用重復閾值技術來檢測圖像中最亮的粒子,然后通過評估這些顆粒的圓度獲取視盤中心。Wang等[8]構建了一個提取網絡E對OD區域進行粗提取,從而確定OD的中心。通過定位的視盤中心,裁剪出指定的感興趣區域。
基于深度學習的OD和OC分割算法主要包括全卷積神經網絡(fully convolutional networks, FCN)[9]和U-Net[10]及其改進。由于卷積運算固有的局部性,基于CNN(convolutional neural networks)的網絡模型無法很好地學習全局和遠程語義信息交互。Transformer本身存在的自注意力機制利用了全局信息,能夠有效解決上述問題。隨著視覺Transformer(vision transformer, VIT)[11]的提出,Transformer首次應用于圖像分類任務。VIT的補丁嵌入過程忽視了語言和圖像之間的差距,導致了圖像的局部特征遭到破壞。此外,VIT冗余的注意力機制設計,導致VIT模型計算量大。Wang等[12]引入金字塔視覺Transformer,逐步縮小金字塔以減少大型特征圖的計算。同時,使用空間縮減注意力(SRA)層來進一步降低學習高分辨率表示的資源消耗,從而使得Transformer架構更適合密集預測任務。Wang等[13]在PVTv1的基礎上提出了PVTv2,將PVTv1的計算復雜度降低到線性。
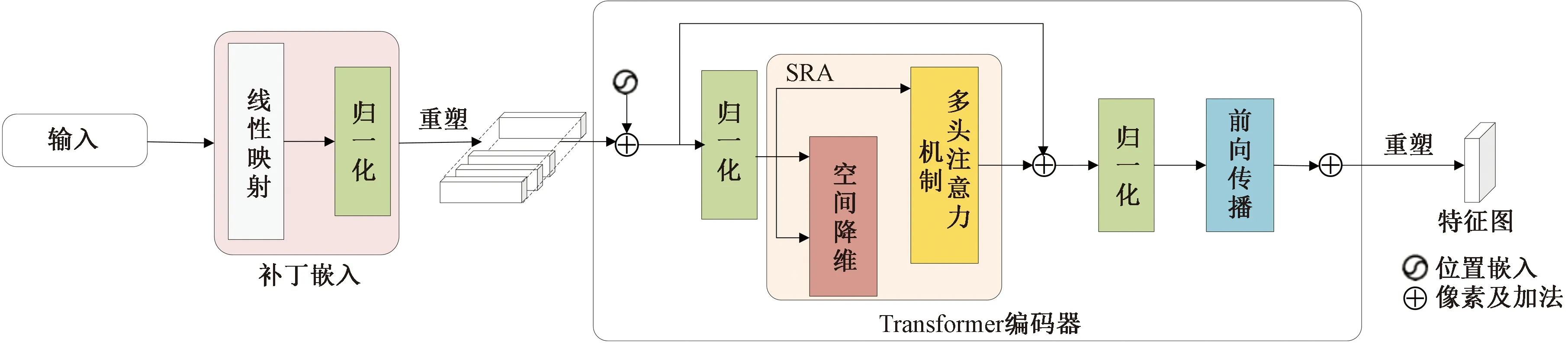
圖1 PVT模型的特征提取過程Fig.1 Feature extraction process for PVT model
模型提取的低層次特征感受野較大,幾何細節信息表征能力強,但是語義信息表征能力弱;高層次特征則相反[14]。為了更好地利用多尺度特征信息,研究人員通過不同的特征融合方法對多尺度特征進行融合。張文博等[15]提出了DeepLabV3+,該模型使用空洞金字塔池化結構來提取不同尺度的特征圖并結合。Yu等[16]提出了BiSeNet,使用雙分支結構,同時解決空間信息丟失和感受野過小的問題。傅雙杰等[17]同樣使用雙分支結構。在語義路徑嵌入上下文捕獲模塊和自適應特征融合模塊,捕獲多尺度的高語義上下文信息。
現提出一種采用雙支路和Transformer的視杯視盤分割方法,首先使用Transformer編碼器對圖像特征進行提取,解決卷積運算的局部性;尺度感知-特征融合模塊(scale-aware-feature fusion module,SCA-FFM)對高層次特征進行融合,使用注意力機制動態分配不同尺度特征的重要程度,收集高層次特征的語義特征;識別模塊(identification module,IM)使用注意力機制減少低層次特征中存在的噪聲;圖卷積域-特征融合模塊(graph convolution domain-feature fusion module,GCD-FFM)使特征圖同時具有不同尺度的信息。
1 相關方法
1.1 金字塔視覺Transformer(PVT)
最近的研究表明[18-19],視覺Transformer比CNN表現出更優的性能。受到PVTv2模型的啟發,本文研究使用PVTv2作為主干網絡提取視杯和視盤的特征信息。PVTv2包含4個階段,每個階段生成不同尺度的特征圖。每個階段的結構相似,都是由補丁嵌入層和Transformer編碼器組成,如圖1所示。
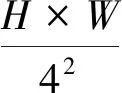
其中,X1顯示出視杯和視盤的外觀信息,X2、X3和X4提供了高級語義信息。由于PVTv2原本是用于分類任務,為了將其適用于視杯和視盤的分割任務,將最后一層的分類器移除,在4個多尺度特征圖之上設計一個視杯和視盤分割頭。
1.2 空間和通道注意力機制
通道注意力機制[20]Attc將長度為H′、寬度為W′、通道為C′的輸入特征圖x∈RH′×W′×C′分別進行自適應平均池化和最大池化,將輸入特征x變為1×1×C′大小,并得到兩個特征圖。然后分別將所得到的特征圖送入兩層的全連接神經網絡,得到兩個特征圖并相加。隨后,將相加得到的特征圖通過Softmax函數得到權重系數,將其與輸入的特征圖x相乘,得到最終的特征圖。
Attc(x)=σ{H1[Pmax(x)]+H2[Pavg(x)]}⊙x
(1)
式(1)中:x為輸入的特征圖;σ為Softmax函數;Pmax和Pavg分別為最大池化函數和自適應平均池化函數;H1(·)和H2(·)為共享參數,由1×1卷積核的卷積層組成,用于降低通道維數,然后是一個ReLu層和另一個1×1卷積層,恢復到原始通道數;⊙為哈達瑪積。
空間注意力機制Atts通過兩個池化操作分別獲得通道維度的最大值和平均值,并進行拼接。然后經過一個卷積層,生成一個新的特征圖。將得到的特征圖通過Softmax函數生成空間權重系數,然后再與輸入的特征圖相乘得到最終的特征圖x′∈RH′×W′×C′。
Atts(x)=σ(G{Concat[Rmax(x),Ravg(x)]})⊙x
(2)
式(2)中:Rmax和Ravg分別為最大值和平均值;G(·)為7×7的卷積層。
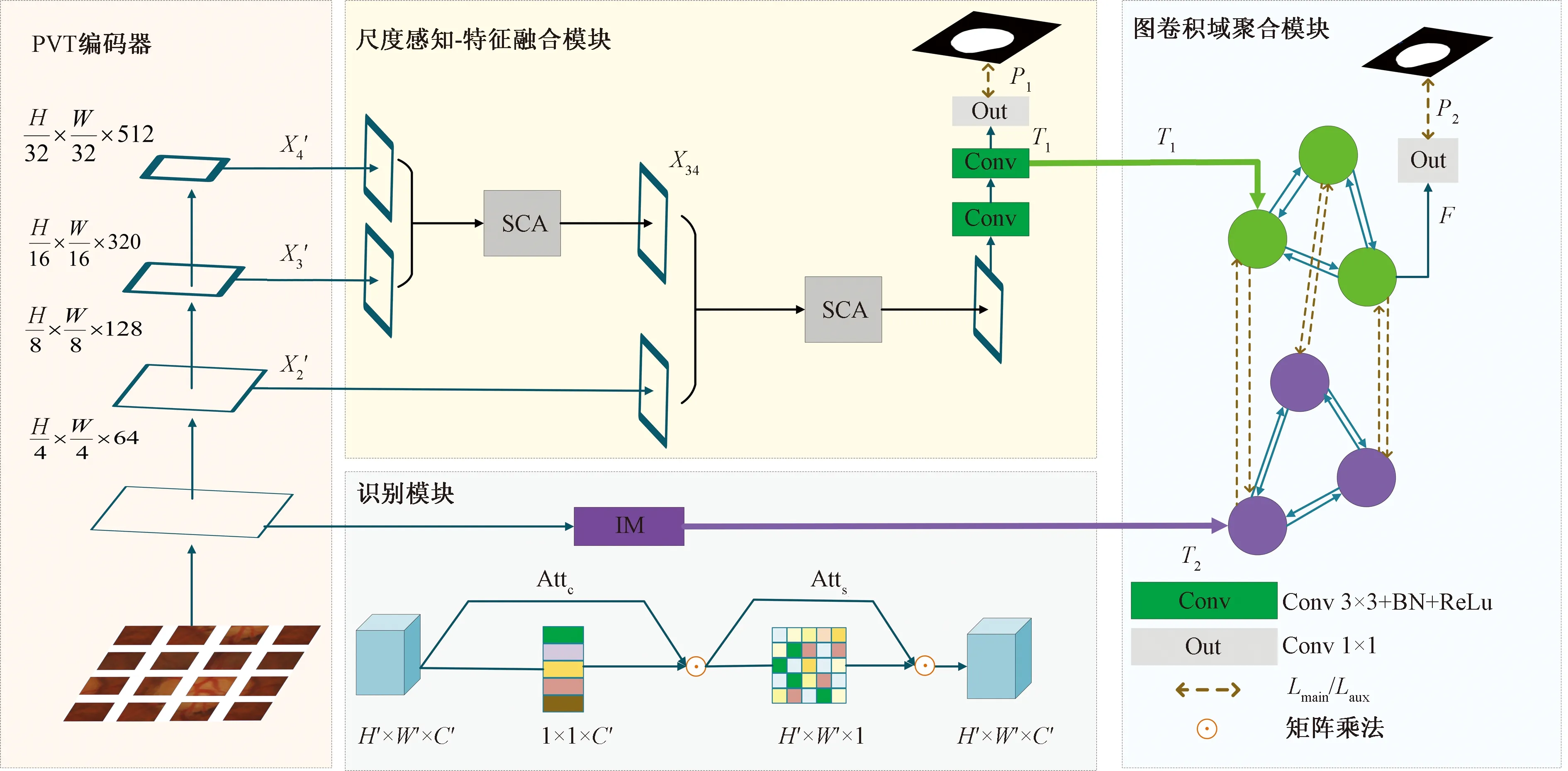
圖2 模型的總體結構圖Fig.2 Framework of the model
2 本文算法
2.1 整體框架
如圖2所示,本文模型分為兩個支路:①支路一使用識別模塊獲取空間語義信息,同時設計空間注意力機制和通道注意力機制來增強空間細節特征的提取;②支路二使用尺度感知模塊-特征融合模塊將多個階段具有強語義信息的多尺度特征表示相結合,從而提高圖像分割能力。
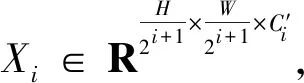
此外,為了提高分割精度,本文研究使用主損失函數Lmain和輔助損失函數Laux對模型進行優化。
2.2 雙分支結構
2.2.1 尺度感知-特征融合模塊
受采集設備和其他不可控因素的影響,圖像目標區域存在大小不同的問題,因此本文研究設計了SCA-FFM作為分支一。即不再采用簡單的解碼器以達到較高的預測速度,而是采用SCA-FFM來捕獲多尺度特征信息,從而平衡計算資源和分割精度。
SCA結構如圖3所示,它引入注意力機制,可以動態選擇合適的尺度特征并進行融合。輸入兩個不同尺度的特征Fa和Fb,將更高層次的特征圖Fb上采樣到與Fa相同的大小。接下來將它們進行拼接,經過一系列卷積操作后得到兩個特征圖A和B。然后經過Softmax運算生成像素級注意力特征A和B,將其分別與原始輸入特征Fa和Fb進行哈達瑪積運算得到對應的特征圖并相加,得到最后的融合特征:
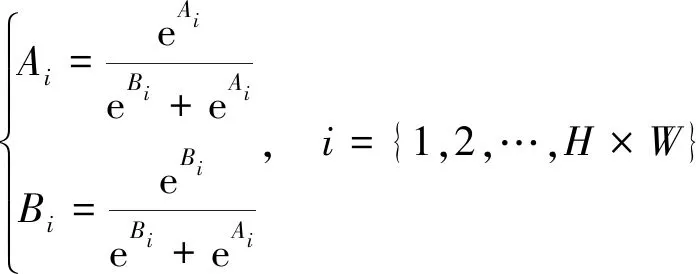
(3)
SCA(Fa,Fb)=A⊙Fa+B⊙Fb
(4)
式中:H為特征圖的高度;W為特征圖的寬度;eAi和eBi分別為將特征圖A和B的第i個像素轉化到指數函數上,用于保證概率的非負性。
SCA-FFM的最終輸出為
T1=SCA[X′2,SCA(X′4,X′3)]
(5)
2.2.2 識別模塊
低層次特征主要包含邊緣、顏色、紋理和形狀等信息,能夠定位目標的位置。由于眼底圖像的血管復雜,且背景與視杯和視盤相似。因此,本文研究中設計IM作為分支二來識別低層次特征中的視杯和視盤細節。
由圖4可知,IM由通道注意操作Attc和空間注意操作Atts組成。該模塊受到CBAM注意力機制模塊的啟發,能夠使得模型更關注目標物體。
IM的最終輸出為
T2=Atts[Attc(X1)]
(6)
2.3 圖卷積域聚合模塊
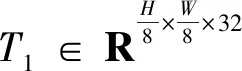
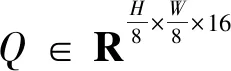
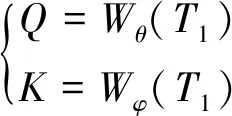
(7)
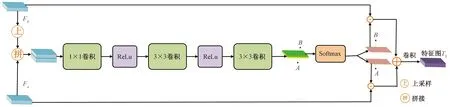
圖3 SCA-FFM結構圖Fig.3 Framework of SCA-FFM
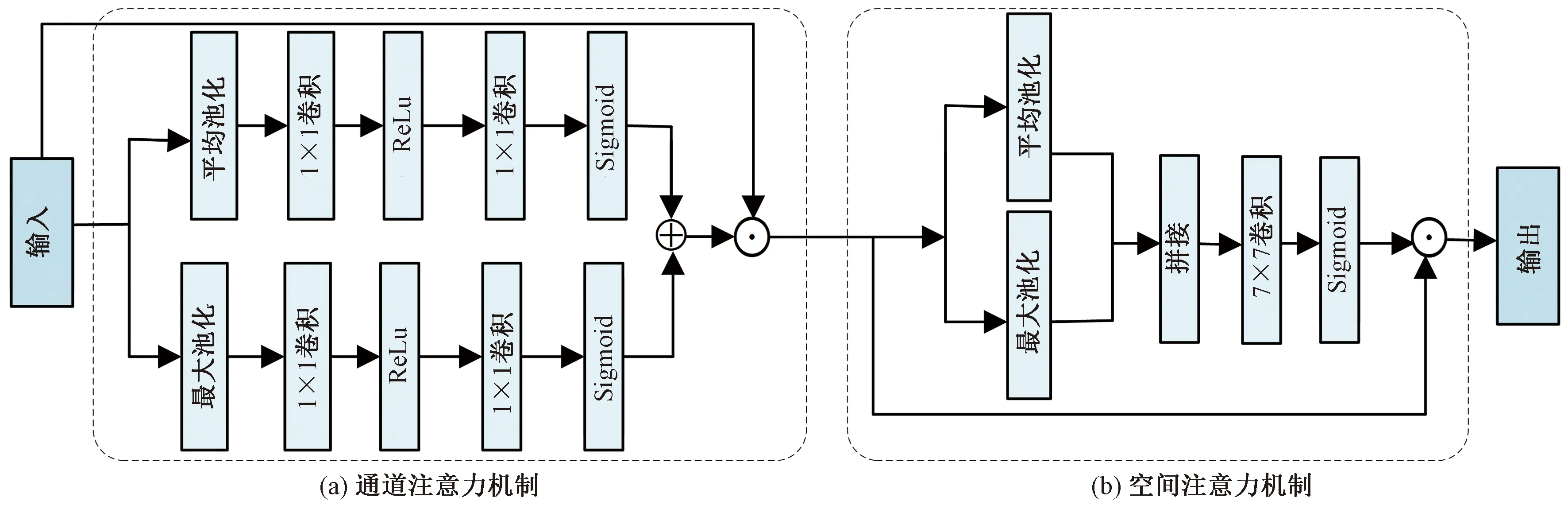
圖4 IM模塊Fig.4 IM model
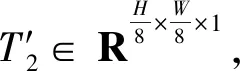
V=AP{K⊙F[Wg(T2)]}
(8)
式(8)中:Wg(·)為卷積單元;F(·)操作在通道維度上應用Softmax函數,并選擇第二個通道作為注意圖;AP(·)為池化和裁剪操作。
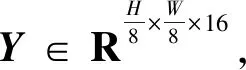
a=σ(V?KT)
(9)
Y=aT?GCN(a?Q)
(10)
式中:?為矩陣乘法;a為K和V的相關注意圖;GCN(·)為圖卷積層。
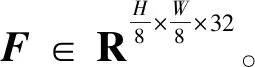
F=T1+Wz(Y)
(11)
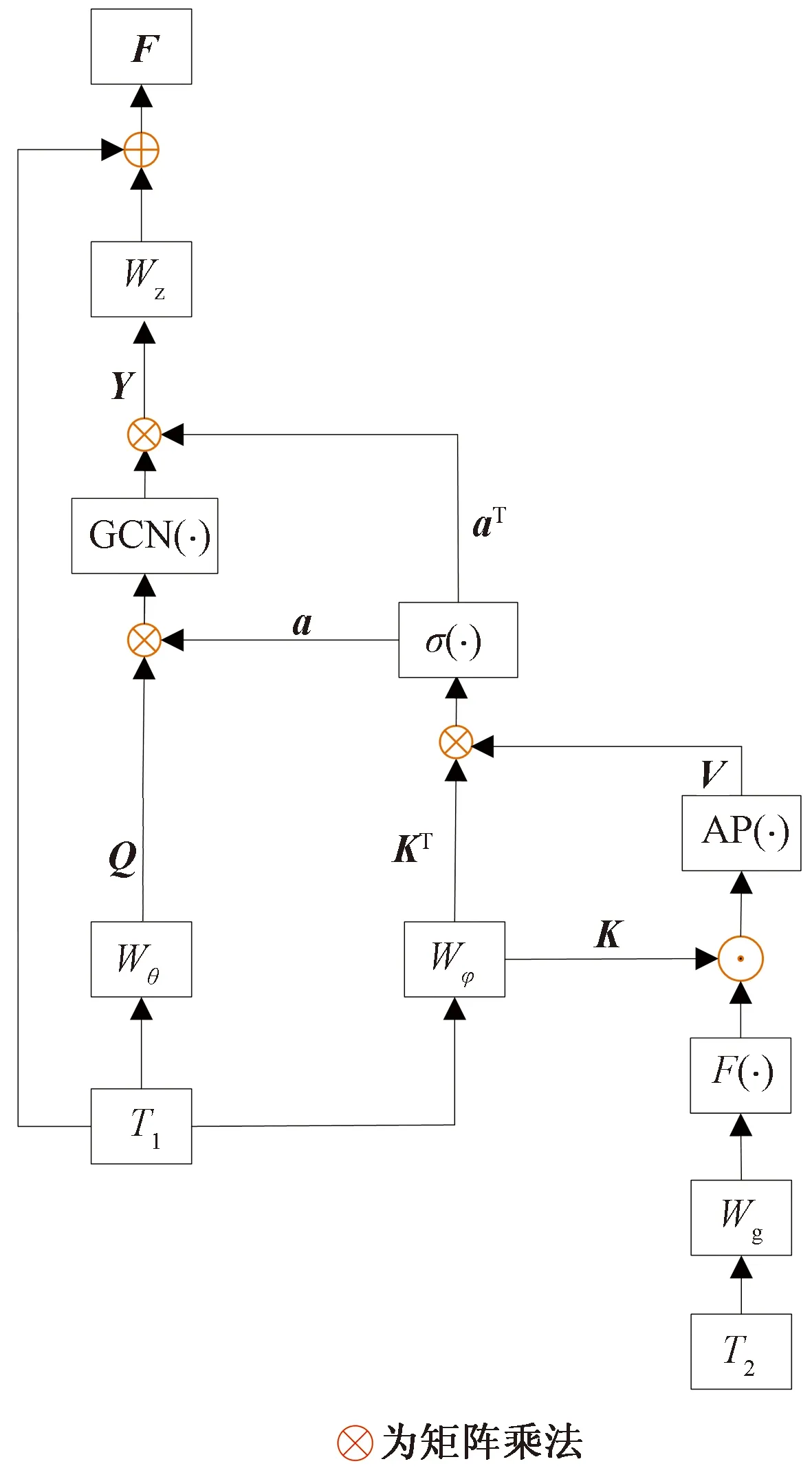
圖5 GCN-FFM細節圖Fig.5 Details of the GCN-FFM
2.4 損失函數
本文研究的損失函數包含兩部分,Lmain主要用于P2和手工標注真實值G之間計算。Laux用于監督SCA-FFM生成P1。計算公式為
L=Lmain+Laux
(12)
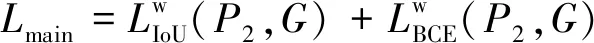
(13)
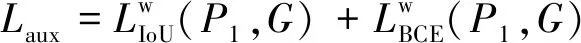
(14)
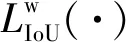
3 實驗
先將OD分割出來,而后通過OC處于OD內部這一先驗知識分割OC。分別在Drishti-GS1[25]、RIM-ONE-r3[26]和REFUGE[27]數據集上進行實驗。
本文提出的OD和OC分割算法步驟為:①使用E網絡,裁剪出512×512大小的圖片作為OD的ROI;②將ROI區域送到OD分割網絡,而后輸出分割圖;③將步驟②中得到的OD分割二值圖與步驟①中的ROI區域圖進行像素“與”操作,得到mask ROI(masked by optic disc)區域;④將步驟③中的mask ROI區域送到OC分割網絡,得到分割圖作為輸出;⑤將步驟②和步驟④中輸出的分割圖進行合并,得到合并的單張圖像,完成OD和OC的分割。
3.1 實驗細節
本文提出的模型基于預訓練的PVTv2。本文實現基于公共平臺PyTorch、GeForce RTX 2080Ti GPU和12 G內存。使用Adam優化器并將學習率和權重衰減均設置為1×10-4。Batch大小設置為8,epoch設置為100。
3.2 數據集與數據預處理
在Drishti-GS1[25]、RIM-ONE-r3[26]和REFUGE[27]三個公共數據集上進行實驗。每個數據集的相關信息如表1所示。
Drishti-GS1數據集中包含101張圖像,其中包含51張訓練集,25張驗證集和25張測試集,分辨率均為2 896×1 944。RIM-ONE-r3數據集包含159張圖像,其中包含99張訓練集,30張驗證集和30張測試集,分辨率均為2 144×1 424。REFUGE數據集包含1 200張圖像,其中包含400張訓練集,分辨率為2 124×2 056;400張測試集和400張驗證集,分辨率為1 634×1 634。
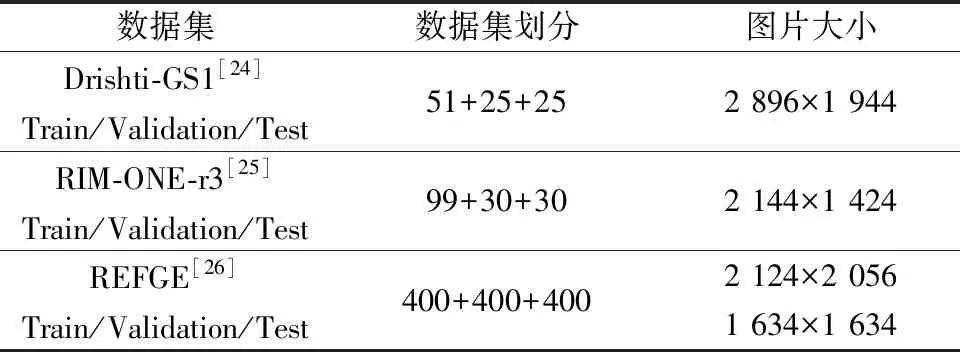
表1 數據集描述
為降低計算成本,同時降低病變區域對分割結果的影響。采用Wang等[8]提出的視盤定位方法裁剪出ROI。首先定位視盤的中心,然后以該中心點裁剪出512×512像素大小的視盤區域,該區域完整包含視杯和視盤,如圖6所示。
由于醫學圖像數據涉及病人的隱私,同時又需要專業人士對數據集進行標注處理,因此醫學圖像數據的獲取困難且數量有限。本文研究對所用數據集進行數據增強來增加眼底圖像的數量,所采用的數據增強方法包括眼底圖像的平移、旋轉、拉伸和縮放。
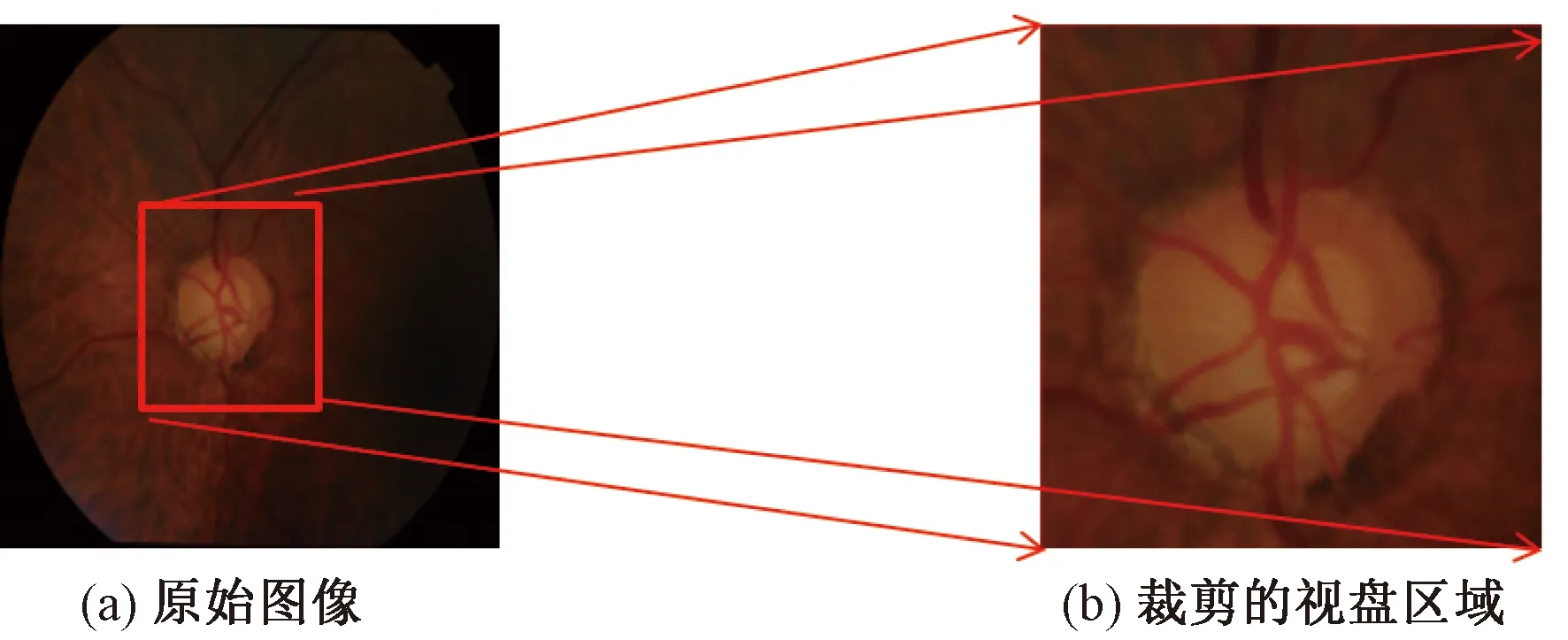
圖6 裁剪ROI區域Fig.6 Cropping the ROI area
3.3 評價指標
采用Dice[28]、IoU[29]和Fβ[30]對OD和OC分割模型進行評價。Dice和IoU都是用于衡量預測結果與mask之間的區域相似性。
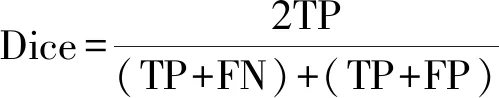
(15)
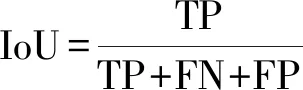
(16)
式中:TP、TN、FP、FN分別為真陽性、真陰性、假陽性、假陰性。
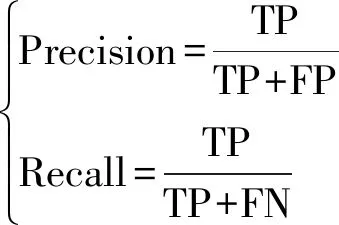
Fβ綜合考慮了精確率和召回率,為不同位置的不同誤差分配不同的權重。
(17)

(18)
文獻[30]表明β2=0.3,精確度更高。因此本文設β2=0.3。
3.4 學習能力的定量評估
本文研究添加了3個模塊提高模型的性能,但是造成了模型參數量的增加。原始的PVTv2模型的參數量為22.6 M,本文模型的參數量為28.11 M。為了進一步證明本文算法的學習能力,在Drishti-GS1、RIM-ONE-r3和REFUGE數據集上按照表1的數據劃分方式進行實驗。將本文算法與M-Net、U-Net、Robust[31]、CA-Net[32]、pOSAL、CE-NET[33]和CDED-Net[34]進行對比。在Drishti-GS1數據集上,本文OD和OC分割結果的Dice比CA-Net分別高0.45%和0.11%,如表2所示。在RIM-ONE-3數據集上,本文OD分割結果的Dice比CA-Net低0.76%;但是本文OC分割結果的Dice比其高2.65%,如表3所示。在REFUGE數據集上,本文OD分割結果的Dice比CDED-Net高2.39%;但是在OC分割任務中略遜于CDED-Net,如表4所示。
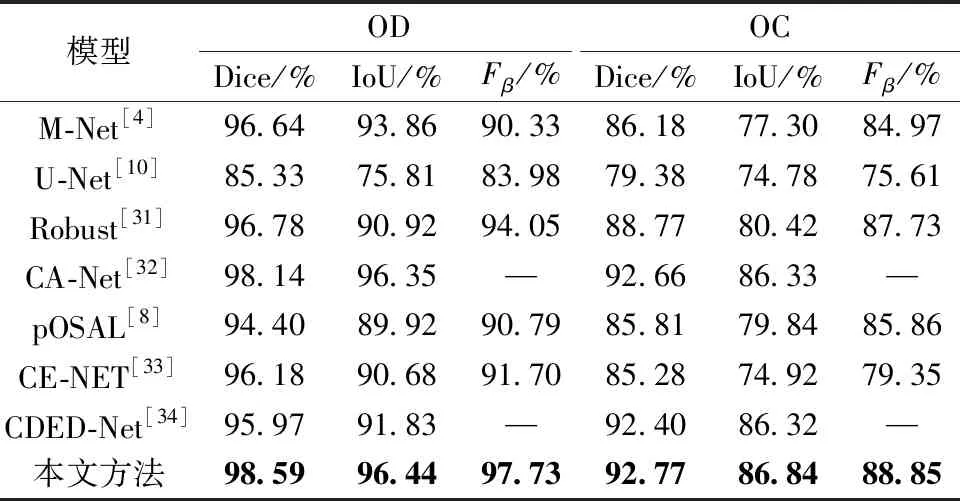
表2 不同方法在Drishti-GS1數據集上的分割結果對比
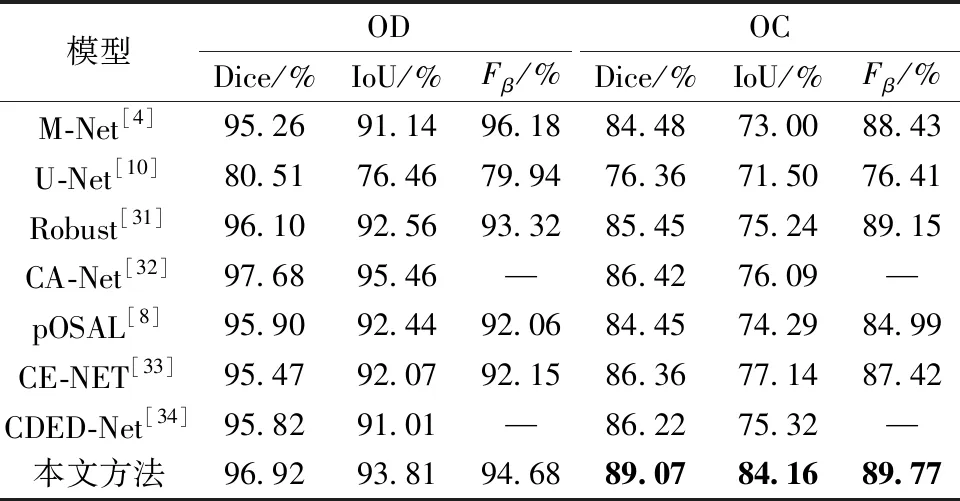
表3 不同方法在RIM-ONE-r3數據集上的分割結果對比
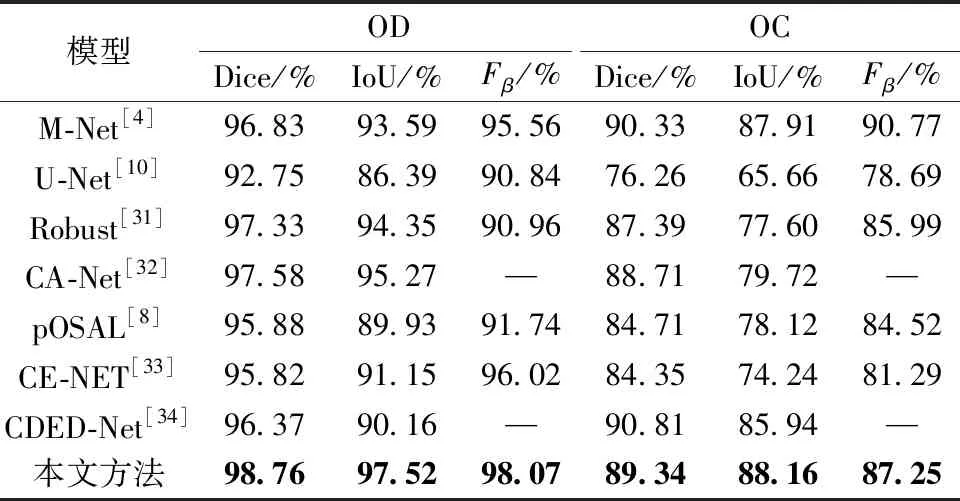
表4 不同方法在REFUGE數據集上的分割結果對比
分析可得,本文模型在視杯和視盤分割任務中能夠達到與其他算法持平或更優的效果。
對比實驗表明,本文算法具有更好的學習能力。這主要得益于Transformer架構強大的特征提取能力,從而獲得更強的特征表達能力。同時通過融合模塊對不同層次的特征進行融合,充分利用不同層次的特征。
3.5 泛化能力的定量分析
為進一步驗證模型的泛化能力,在Drishti-GS1、RIM-ONE-r3和REFUGE數據集上進行實驗。使用Drishti-GS1和RIM-ONE-r3數據集進行訓練,REFUGE數據集進行測試。值得注意的是,Drishti-GS1、RIM-ONE-r3和REFUGE的采集設備不同,因此,圖像的顏色和紋理均存在差異(圖7)。
圖7 不同數據集的圖像示例Fig.7 Examples of images from different datasets

綠色區域代表視盤區域;藍色區域代表視杯區域圖8 不同方法在DRISHTI-GS1數據集上的分割結果Fig.8 Segmentation results of different methods on the DRISHTI-GS1 dataset
從表5可得,本文方法分割視盤的Dice和IoU分別為0.959 8和0.922 5,分割視杯的Dice和IoU
分別為0.879 6和0.778 9。由于訓練集和測試集的圖片差異較大,不同的方法都存在一定程度的精度下降。但是,本文提出的方法包含IM模塊,能夠準確識別圖像的顏色、紋理等信息,因此在交叉實驗中仍然比其他算法的分割性能更優。綜合上述可得,本文提出的方法具有良好的泛化能力。
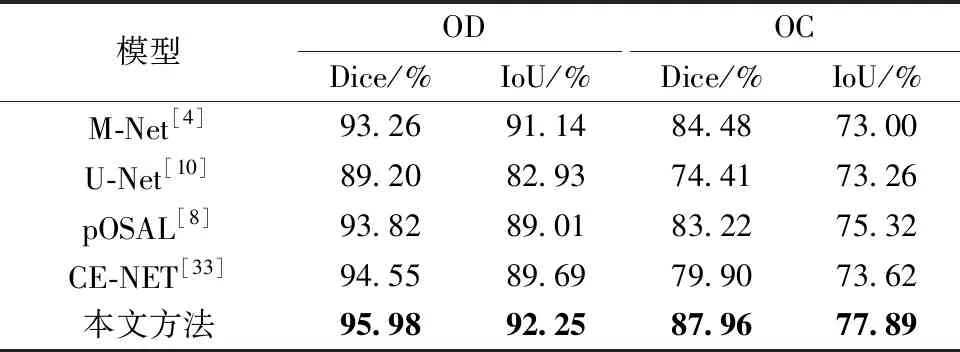
表5 在REFUGE數據集上進行泛化實驗

綠色區域代表視盤區域;藍色區域代表視杯區域圖9 不同方法在RIM-ONE-r3數據集上的分割結果Fig.9 Segmentation results of different methods on the RIM-ONE-r3 dataset

綠色區域代表視盤區域;藍色區域代表視杯區域圖10 不同方法在REFUGE數據集上的分割結果Fig.10 Segmentation results of different methods on the REFUGE dataset
3.6 定性分析
圖8、圖9和圖10分別為不同方法在3個數據集上的分割結果。
從圖8可得,M-Net和U-Net的視盤和視杯分割效果均略次于其他算法;Robust、pOSAL和CE-NET算法對視盤的分割效果較好,但是在視杯分割任務中表現欠佳。尤其是CE-NET方法中視盤和視杯的Dice相差最大,達到10.9%,這與圖5的可視化結果一致。在Drishti-GS1數據集中,本文算法的視盤和視杯分割效果均達到最優,展現了良好的分割效果。
由圖9可知,RIM-ONE-r3數據集中的圖像清晰度低于Drishti-GS1數據集,導致不同算法的分割效果均存在下降現象。U-Net和M-Net模型分割出的邊界不規則,且錯分嚴重。CE-NET網絡在Drishti-GS1和RIM-ONE-r3數據集的實驗結果相差不大,但對視杯和視盤的分割效果均次于Robust、pOSAL這兩種聯合分割網絡。此外,Robust、pOSAL和本文模型對視盤的分割效果持平,但是本文算法在視杯分割任務中體現出優越性。在REFUGE數據集上,本文模型分割邊界平滑,且分割效果良好。
綜上所述,本文方法可以適應不同的數據集,同時分割的邊緣更加接近真實標簽。
3.7 消融實驗
為了驗證ROI區域、SCA-FFM、IM和GCD-FFM的有效性,本文研究進行了一系列的實驗。如表6所示,使用PVTv2在DROSHTI-GS1數據集上進行實驗,分割視盤的Dice和IoU分別為97.05%和94.39%。在PVTv2基礎上添加的3個模塊,均對分割結果產生不同程度的提升。其中,SCA-FFM使得分割視盤的Dice和IoU分別提升0.73%和1.12%,同時使得分割視盤的Dice和IoU分別提升0.73%和1.06%,對分割性能的提升效果最佳。3個模塊均添加之后,效果達到最優,綜上所述,本文添加的3個模塊均有助于優化視盤和視杯的分割結果。
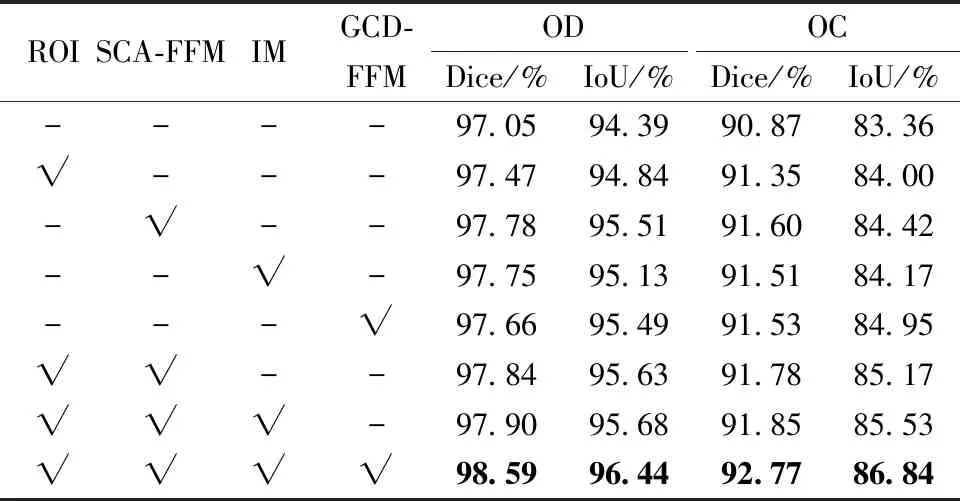
表6 DRISHTI-GS1數據集中的消融實驗
4 結論
提出了一種采用雙分支和Transformer的視杯和視盤分割模型。雙分支結構分別對低層次特征和高層次特征進行處理,使得提取的特征更加穩健,從而提高分割性能。本文算法在3個經典數據集上均體現出其優越性,但是引入的3個模塊增加了計算的工作量。此外,由于數據集樣本較少,影響了研究的結果。在未來的工作中,將從降低計算成本和小樣本分割方面入手,進一步完善實驗結果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
