基于神經網絡的天然氣雙燃料發動機性能預測*
2023-04-10 06:40:32陳暉虞彪盧嘉專
汽車工程師 2023年4期
陳暉 虞彪 盧嘉專
(1.柳州職業技術學院,柳州 545005;2.柳州五菱柳機動力有限公司,柳州 545002)
1 前言
天然氣價格低、儲量大、存儲與運輸設施完善,是我國目前使用規模最大的燃料。柴油/天然氣雙燃料發動機不僅能實現高效燃燒,還能降低碳煙和NOx的排放體積分數,因此受到廣泛關注[1-3]。為了使雙燃料發動機在不同工況下獲得最佳性能,需要對發動機的運行參數進行標定,但標定試驗過程復雜、工作量大、成本高,相比于試驗標定方法,基于模型的發動機標定方法可以有效提高標定效率,降低標定成本[4-5]。
人工神經網絡(Artificial Neural Network,ANN)是一種類似于人腦的包含多個神經元結構和功能的信息處理系統,具有非線性映射能力、容錯能力、自學習能力等特點,在科學和工程領域被廣泛應用[6]。Syed 等[7]采用少量試驗數據訓練人工神經網絡,有效預測了氫氣/柴油雙燃料發動機的熱效率、油耗以及污染物排放量;Cay 等[8]采用人工神經網絡模型預測了甲醇/汽油雙燃料發動機的平均有效壓力、油耗、功率和排氣溫度,預測結果與樣本數據的平均誤差<3.8%,均方根(Root Mean Square,RMS)<0.0015;Ramalingam 等[9]采用人工神經網絡針對5 種不同比例的生物柴油/柴油混合燃料的性能和排放進行預測,預測結果的平均絕對百分比誤差(Mean Absolute Percentage Error,MAPE)范圍為0.98%~4.26%;Taghavi 等[10]利用遺傳算法優化的人工神經網絡預測了均質充量壓燃(Homogeneous Charge Compression Lgnition, HCCI)發動機燃燒始點;戴金池等[11]采用長短期記憶(Long Short-Term Memory,LSTM)神經網絡、逆向傳播(Back Propagation,BP)神經網絡和支持向量機3種不同模型對柴油機NOx排放量進行預測,結果表明LSTM 神經網絡預測性能最強。李昌慶等[12]利用BP 神 經網絡對大 型 客車的CO2、CO 和NOx排放 體積分數進行預測,預測結果的總體相關系數R2為0.9167,線性高度相關,該模型能較準確地預測大型客車尾氣排放量。
目前,對雙燃料發動機性能和排放的研究主要集中在試驗和模擬研究方面,基于模型預測的研究還較少,本文以發動機扭矩、轉速、過量空氣系數、噴油時刻、噴油壓力和天然氣替代率作為模型輸入參數,燃油消耗率、CO、NOx和總烴(Total Hydrocar?bons,THC)排放體積分數作為模型輸出參數,通過訓練試驗數據,建立基于人工神經網絡的天然氣雙燃料發動機機性能預測模型。
2 預測模型的建立
影響雙燃料發動機性能的參數很多,發動機性能和排放的預測屬于多變量、多目標的非線性問題,而且目標函數無法用數學解析式給出。BP神經網絡是一種多層前饋神經網絡,按照誤差逆向傳播算法進行訓練,具備處理參數之間復雜的非線性關系的能力,因此適用于多變量的變化函數建模,是目前應用最廣泛的人工神經網絡[13]。BP 神經網絡的結構包含輸入層、隱含層和輸出層,每層中有若干節點,每個節點稱為一個神經元,層與層之間的神經元全部相連,但同一層內的神經元不相連。BP神經網絡訓練包含了2 個過程,分別是輸入信號的正向傳播和計算誤差的反向傳播。在正向傳播過程中,輸入信號由輸入層經過隱含層到達輸出層,計算損失函數值:當損失函數值大于期望值時,訓練進入誤差反向傳播過程,通過求損失函數對權值和閾值的偏導數調整網絡的權值和閾值,使損失函數值不斷減小,神經網絡預測值不斷逼近期望值;當網絡輸出的誤差或學習次數達到設定值時,訓練過程結束。本文采用BP 神經網絡構建雙燃料發動機性能預測模型。
2.1 數據的選取與處理
將臺架試驗得到的260 組數據按80%、10%、10%的比例隨機分為訓練樣本、驗證樣本和測試樣本3 個部分。由于樣本中數據的量綱和數值量級差異性大,如轉速和過量空氣系數的數值量級可以相差1000 倍,因此需要通過對樣本數據進行歸一化處理,減小數據間的量綱和數值量級差異,提高求解速度和計算精度。常用的方法是按Min-Max標準化對數據進行線性變換,并映射到[0,1]區間,即
式中,x′為歸一化后的樣本數據;x為歸一化前的樣本數據;xmin為數據樣本中的最小值;xmax為數據樣本中的最大值。
2.2 輸入參數和輸出參數的選擇
模型輸入參數和輸出參數的選取是構建和訓練神經網絡的一個重要問題,對模型的預測精度有較大影響[14]。首先選擇過量空氣系數和天然氣替代率作為輸入參數,這2 個參數表示燃料與空氣的比例情況,其次,發動機扭矩、轉速、噴油時刻、噴油壓力是影響雙燃料發動機性能和排放的重要控制參數,也選作模型輸入參數,預測模型共選擇6個輸入參數。模型輸出參數為5 個,選擇燃油消耗率來表征發動機性能,CO、NOx、THC 排放體積分數和碳煙排放量來表征發動機排放情況。
2.3 神經網絡結構的確定
模型的輸入參數和輸出參數分別為6 個和5個,因此模型的輸入層和輸出層的神經元數量確定為4 個和2 個。BP 神經網絡采用單隱含層時即可高精度地逼近任意非線性函數,在實際應用中具有很好的預測能力,使用BP 神經網絡模型進行預測要考慮如何避免模型預測出現過擬合現象。在訓練數據樣本量較小時,采用多層隱含層容易出現過擬合,因此本文預測模型采用單層隱含層結構。隱含層中神經元的數量是影響神經網絡的預測性能的一個重要參數,可以采用試錯法確定,通過逐漸遞增神經元數量,對比不同神經元數量條件下計算得到的模型誤差,發現隱含層節點數量為18 個時模型預測的誤差最小,因此預測模型的結構最終確定為6-18-5,建立的BP 神經網絡模型拓撲結構如圖1 所示。模型隱含層選用Sigmoid為激活函數,輸出層選用Purelin 為激活函數。
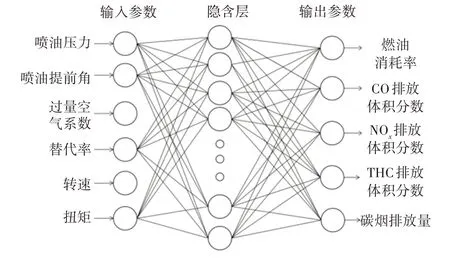
圖1 BP神經網絡拓撲結構
2.4 遺傳算法優化
BP神經網絡模型訓練過程中,初始權重和閾值一般為隨機賦值,對訓練結果有較大影響,容易造成在訓練過程中由于學習率過大或過小使得得到的結果不是全局最優解,預測結果誤差較大。遺傳算法是模仿生物遺傳學和生物進化原理人工構造的一種優化算法,通過使個體進行選擇、交叉、變異,進化出更優秀的個體,然后對個體的適應度進行比較,淘汰不適應環境的個體,從而在多個潛在解中找到最優解。為了解決BP 神經網絡初始權重和閾值隨機賦值導致預測性能魯棒性差的問題,通過遺傳算法對初始權值和閾值進行優化,將優化后的權重和閾值帶入BP 神經網絡進行訓練。基于遺傳算法優化的BP 神經網絡稱為GA-BP 神經網絡,圖2 所示為基于遺傳算法的BP 神經網絡模型優化流程。經過調試,在遺傳算法中,種群規模設置為20 個、進化次數為40 次、交叉概率為0.3、變異概率為0.1時,模型預測精度高且收斂速度較快。
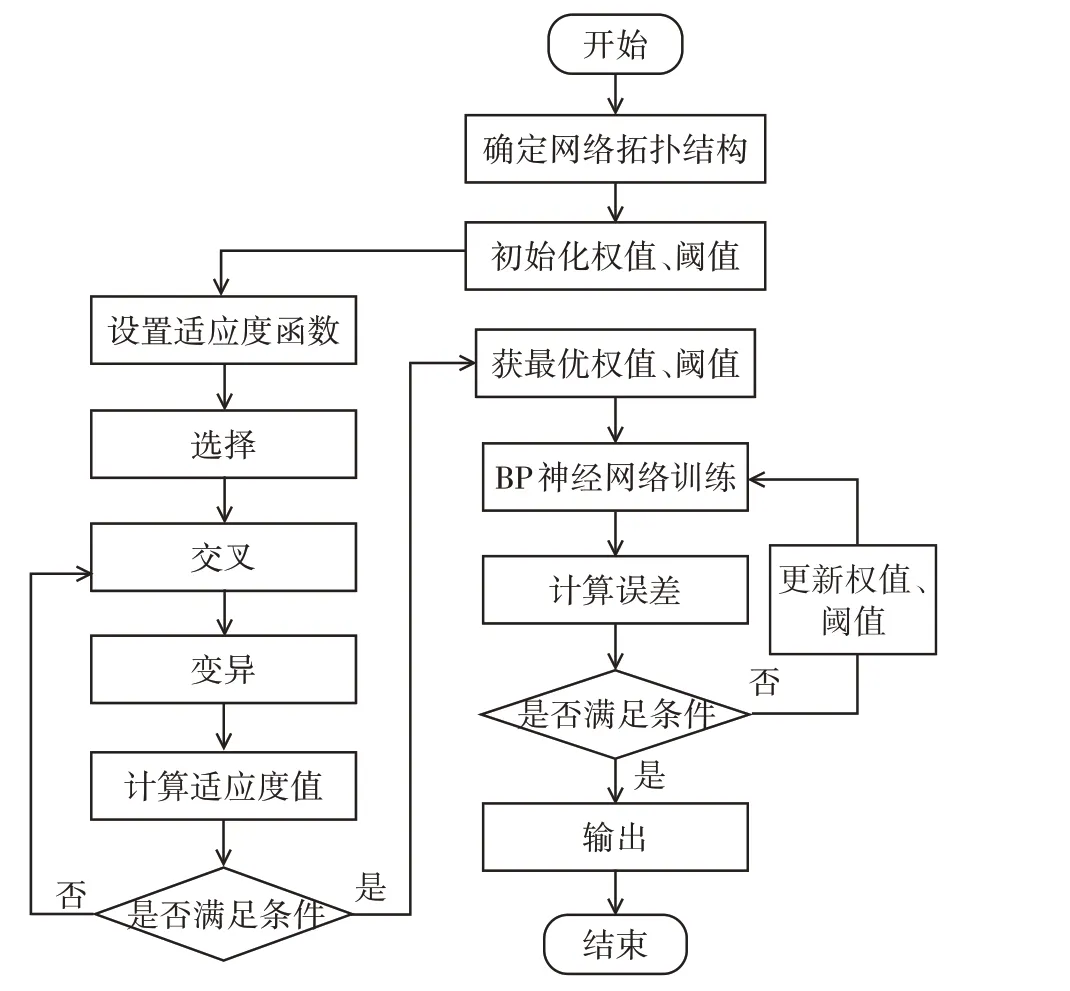
圖2 GA-BP神經網絡模型優化流程
3 結果分析
模型建立后,需對模型的預測結果進行評價,本文選用決定系數R2和平均絕對百分比誤差MAPE作為評價指標,決定系數R2越接近1,平均絕對百分比誤差MAPE越小,表明模型預測性能越好:
式中,ti為第i個測試集中的試驗值;oi為第i個模型預測值;tˉ為測試集試驗值平均值;n為測試集中的樣本數量。
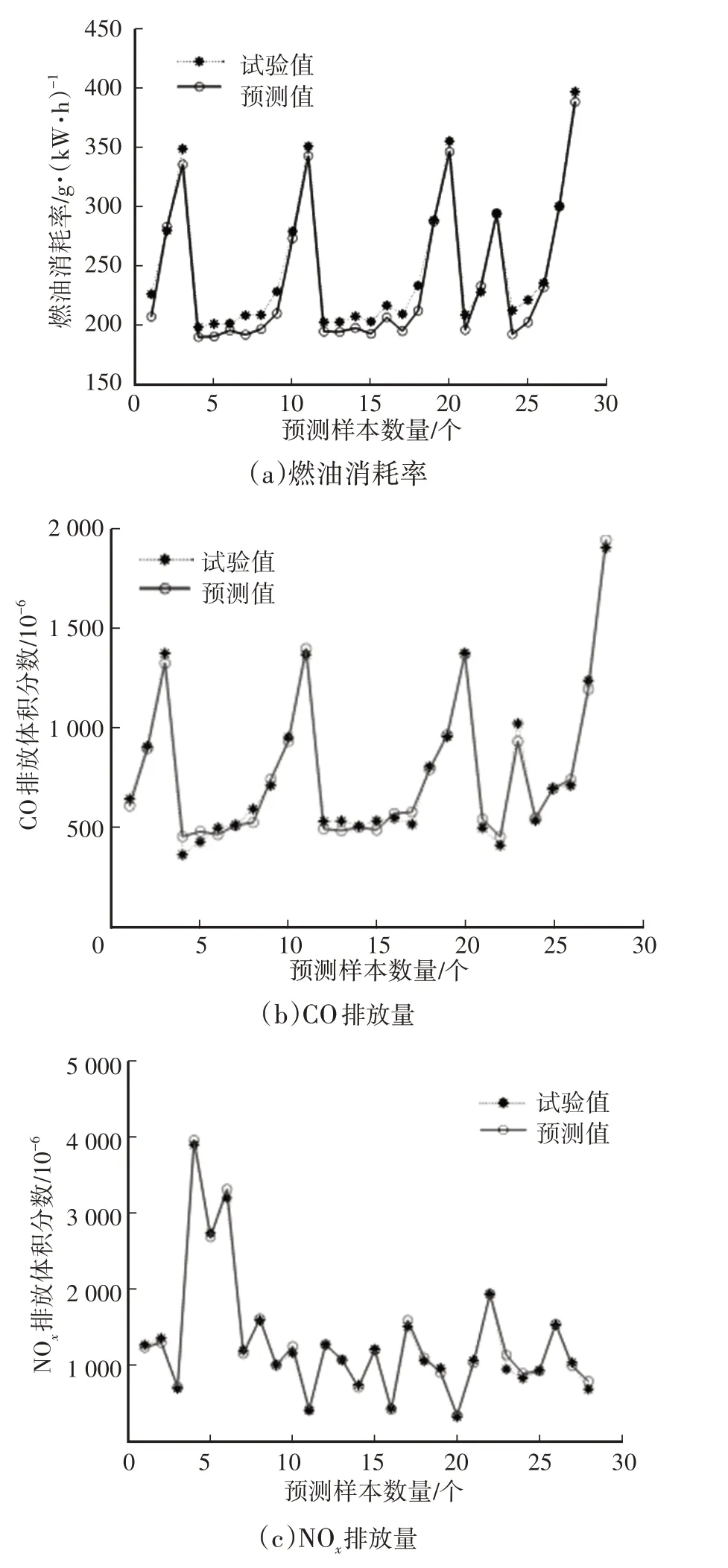
表1 和表2 所示分別為BP 神經網絡和GA-BP神經網絡的模型預測評價指標,對比表中數據可以看出,GA-BP 神經網絡的模型預測誤差較BP 神經網絡小,說明通過遺傳算法對BP神經網絡初始權重和閾值的優化可提高模型的預測精度。GA-BP 神經網絡對4個輸出參數預測的平均絕對百分比誤差MAPE均小于6%,并且決定系數R2均大于0.97,說明模型具有較高的預測精度和泛化能力。

表1 BP神經網絡的預測誤差
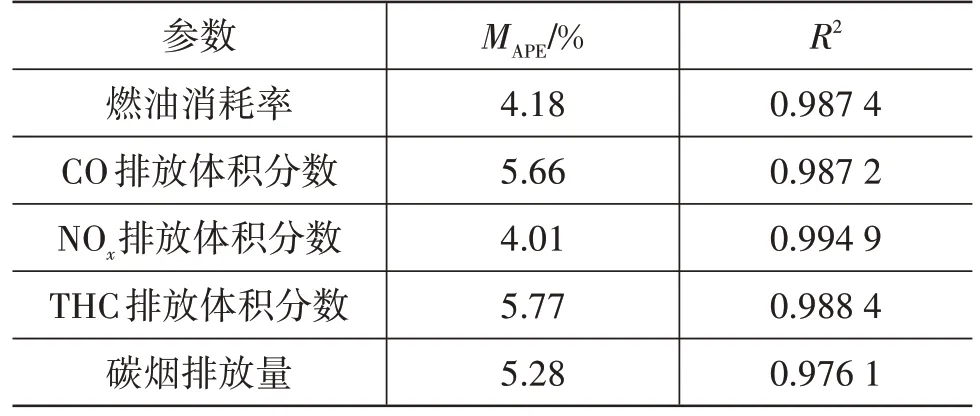
表2 GA-BP神經網絡的預測誤差
圖3 和圖4 所示分別為BP 神經網絡和GA-BP神經網絡模型預測結果與試驗結果的對比,BP神經網絡和GA-BP 神經網絡模型的預測值的變化趨勢與試驗值基本一致,較好地反映了輸出參數隨輸入參數的變化規律,GA-BP 神經網絡模型的預測值誤差更小,具有更好的預測性能。
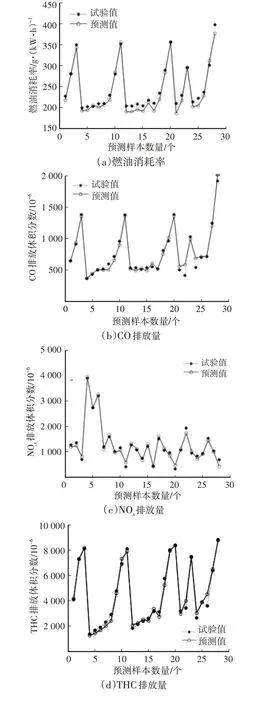
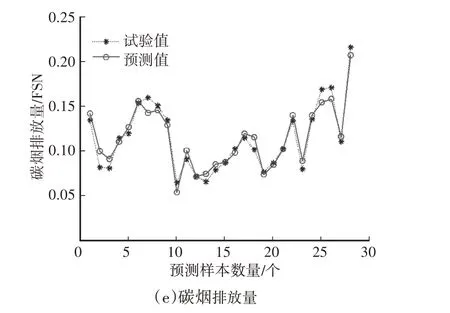
圖3 BP神經網絡模型預測值與試驗值對比
4 結束語
本文基于柴油/天然氣雙燃料發動機測試臺架試驗數據,以發動機扭矩、轉速、噴油時刻、噴油壓力和天然氣替代率、過量空氣系數為模型輸入參數,以發動機燃油消耗率和CO、NOx、THC 排放體積分數和碳煙排放量為模型輸出,構建了基于BP神經網絡和基于遺傳算法優化的GA-BP 神經網絡的預測模型。與BP 神經網絡模型相比,GA-BP 神經網絡模型的預測結果誤差更小,具有更好的預測性能。GA-BP神經網絡模型對5個輸出參數預測的平均絕對百分比誤差MAPE均小于6%,并且決定系數R2均大于0.97,模型具有較高的預測精度和泛化能力。GA-BP 神經網絡預測模型可為天然氣雙燃料發動機運行參數的標定及優化提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
汽車維修與保養(2021年8期)2021-02-16 00:28:30
汽車維修與保養(2021年8期)2021-02-16 00:28:18
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
汽車與新動力(2015年1期)2015-02-27 12:11:01
汽車與新動力(2014年2期)2014-02-27 12:10:15
汽車與新動力(2013年5期)2013-03-11 16:08:17
