基于B/S 模式下的優化遺傳算法的自動組卷系統設計與實現
2023-04-13 02:02:38王旭吳志雄周子勛
電子制作 2023年4期
王旭,吳志雄,周子勛
(長江大學 計算機科學學院, 湖北荊州,434023)
0 引言
隨著信息化時代的發展,以及全國疫情的爆發,各種云會議、網絡授課等網絡技術的出現,同時教育行業的自動組卷模式也成為熱點。
本文采用具有較高的安全性、擴展性和兼容性等特點的B/S 模式架構[1],在普通遺傳算法的基礎之上對選擇算法的選擇策略進行優化將更好的篩選試題及交叉概率和變異概率的調整,將更好的防止“未熟就收斂,局部最優,生成的試題質量偏低”等問題,B/S 和優化的遺傳算法的相互融合很好的應用到自動組卷系統中[2]。
1 技術概述
1.1 B/S 模式
Browser/Server 模式,是指瀏覽器/服務器模式下的交互。B/S 相比于C/S 模式不需要安裝相應的軟件、占用內存小、與服務器交互時響應速度快的特點,而且可跨平臺操作、業務邏輯簡單方便、易于維護和較靈活結構等顯著優勢,使得自動組卷系統交互下展現其特性。
1.2 JMV 體系
JMV 體系是指Java+MySQL+Vue 技術的組合實現。采用具有多線程、安全性等特性的Java 的Spring Boot 架構編寫前后端服務器功能達到接收前端發送的增刪、修改、組卷操作請求命令和做出響應返還數據;數據庫服務器開發將使用MySQL 數據庫按照難度、知識點、區分度、時間等約束條件建立相應的表用以存儲試題庫;前端界面將采用具有視圖、數據、結構分離操作簡單化、組件化、速度快等特性的Vue 框架技術,用于用戶點擊界面的某一操作實現交互功能,JMV 體系將很好適用于自動組卷系統中。
2 系統設計
2.1 總體設計
自動組卷系統采用三層架構的思想,即表示層(Demonstrate)、服務層(Service)、數據層(Database)[3]。
基本設計流程:表示層是用戶登錄/注冊功能和用戶點擊增加或刪除、修改、查看試題等操作時將采用Ajax 異步請求服務,向服務器發送用戶的增刪改查試題等操作命令;服務層是對界面發送的增刪改查試題等操作命令進行邏輯處理,并且根據用戶選擇的難度系數、知識點、時間等約束條件通過優化的遺傳算法向試題庫進行抽選,然后返回數據到前端;數據層是每種試題按照難度系數、知識點、區分度、時間等約束條件進行存儲,接收服務器的查詢命令,返回數據[4]。如圖1 所示。

圖1 三層架構圖
2.2 系統功能設計模塊
本系統功能結構分為三大部分:用戶管理模塊;數據庫模塊;考試管理模塊。
(1)用戶管理模塊
用戶管理由管理員、教師、學生組成,登錄后的界面各不相同,其中管理員權限高于教師權限和學生權限。
①管理員:擁有創建或刪除用戶,修改密碼,用戶角色管理,系統菜單管理,考試管理以及試題庫的管理,維護系統數據等。
②教師:擁有密碼修改、試題管理、科目管理權限,例如增刪試題,自動組卷等。
③學生:擁有密碼修改、試題管理和試卷管理和自動組卷功能等。
(2)數據庫模塊
MySQL 數據庫是整個系統軟件的根基,是存儲數據和管理數據的庫[5]。
數據庫表的設計,數據以二維表格呈現的方式,用來記錄存儲數據對象的關系。本系統包括用戶表(user)、菜單表(menu)、角色表(role)、課程表(course)、試卷表(test)、試題表(paper)、成績表(score)等表,其中在試題表中字段列舉了每個題的難度(difficult)、區分度(distinction)、知識點(knowledge)、時間(time)等參數,有利于提高組卷系統的高效性。如表1 所示。

表1 數據表
(3)考試管理模塊
該模塊主要有試題管理、科目管理、試卷管理。用戶可對試題進行增加、刪除、修改,還可按照難度系數、知識點、區分度、答題時間進行自動組卷操作。
3 組卷策略設計
通過遺傳算法模擬自然界生物進化的思想,“物競天擇,適者生存”的生存法則[6],以種群為研究對象,對每個個體進行編碼,依據預先設定的目標函數對個體進行評估給出相應的適度值,通過逐代的選擇、交叉、變異,逐漸形成新的、適應度高的種群,最后進行解碼操作得到最大的適應度的個體并輸出。其執行流程如圖2 所示。
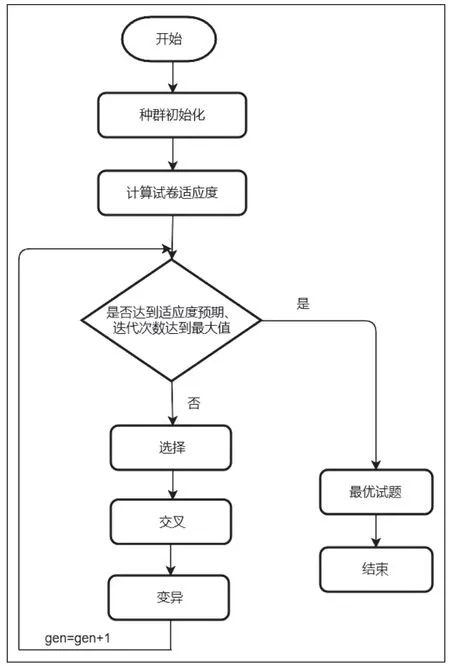
圖2 遺傳算法執行流程圖
本文將采用優化的遺傳算法在選擇策略上采用輪盤賭選擇法,保留當前種群中30%最優個體并記為oldmax,其不參與交叉變異,剩下的個體由輪盤賭法選擇出來。本文將傳統的只使用輪盤賭選擇算法改進為結合最優個體保存策略,改進后既可以保證遺傳算法能夠收斂,又能避免提前收斂陷入局部最優。
算法整體執行流程如下:
(1)種群初始化
系統將依據試題難度系數(difficult)、區分度(discrimination)、知識點(knowledge)、答題時間(time)4 個參數作為約束條件,假設有n 個試題則組成一個n×4的矩陣,如(1)式所示:
D 是目標矩陣的解,某一題 1iD=[1ia,2ia,3ia,4ia],其中0 ≤i ≤n,1ia代表難度系數,2ia代表區分度,3iD代表知識點,4iD代表答題時間,由上述約束條件生成試卷,構成“染色體”編碼。
根據用戶選定的考試類型和題量、難度系數、區分度、知識點、答題時間等條件,隨機從試題庫中抽取符合條件的題目,生成初代的n 套卷。
(2)適應度函數的建立
在遺傳算法中,適應度的大小是區分種群優劣的主要指標,將直接影響著算法的性能[7],本系統將采用4 個約束條件對適應度進行設計,模型如(2)式所示:
(3)遺傳操作算子
①選擇算子
選擇是指在種群中選擇好的個體,淘汰劣的個體,是生物進化學的“優勝劣汰”的應用,建立在適應度的基礎之上,適應度越高,被選擇的概率就越大。通過輪盤賭和最優適應度保存策略對其進行選擇操作。
假設種群由n 個個體組成,個體in的適應度用iF表示,則in個體被選擇的概率如(3)式所示:
式中,iF指第i 個個體的適應度值。
經過輪盤賭選擇后,保存30% 的最優個體記為oldmax,并且不參與個體的交叉變異操作,最后再替換掉適應度低于oldmax 的個體,較好的解決了“收斂快和局部收斂”的問題。
②交叉算子
交叉是指模擬生物進化的過程,從中獲取優良個體,產生新的下一代個體,交叉過程是按照一定的交叉概率在相應庫中兩兩隨機交叉,本系統采用兩點交叉方式,則交叉過程如圖3 所示。

圖3 交叉過程圖
隨機交叉方式,容易導致交叉后會出現重復的題目,使得算法早熟早收斂。為了防止重復事件的發生,通過控制交叉概率cP,一般選擇0.4-0.99,本系統使用0.5 的交叉概率,用以保證題目的不重復性。
③變異算子
變異是指生物模擬生物個體突變的過程,通過變異概率mP隨機的反轉某位二進制數值,則交叉過程如圖4 所示。

圖4 變異過程圖
變異過程是一種局部搜索,為了防止因選擇和交叉導致的信息丟失,保持種群的多樣性[8],變異概率一般選擇0.0001~0.1,本系統使用0.01 的變異概率,防止出現未熟就收斂的現象。
改進后的遺傳算法很大程度的保證了染色體中的優良個體,很大程度的防止早熟,局部最優等問題,最終通過不斷的選擇、交叉、變異達到預定的適應度或者迭代次數,滿足最高的適應度值的個體即為最優解。
4 系統實現
4.1 用戶管理實現
系統初始登錄界面,新用戶可選擇教師或學生來注冊系統,然后可登錄系統,已注冊用戶可直接登錄,成功后進入主界面,如圖5 所示。管理員擁有最高權限,可點擊用戶管理實現對教師和學生信息的查找和修改,另外還可以實現角色菜單管理功能。教師或學生點擊系統管理的密碼修改按鈕,可在輸入框中輸入舊密碼,再輸入新密碼,確認密碼,則可實現密碼修改。如圖6 所示。

圖5 登錄/注冊界面

圖6 教師界面
4.2 考試管理實現
考試管理包括了3 大部分,即試題管理、科目管理、試卷管理,教師和學生可在試題界面操作向服務器發送試題增刪修改操作命令,服務器響應并傳輸相應數據[9],本系統通過使用優化的遺傳算法進行組卷,教師或學生在試卷管理界面輸入難度系數(0-1,數字越大,難度越高),區分度(0-1,數字越大,難度越高),選擇知識點,再輸入答題時間,如圖7所示,即可組出一套試卷,并且可打印試卷,如圖8所示。

圖7 自動組卷界面圖

圖8 試卷生成界面圖
■4.3 試題庫管理實現
考試系統需要不斷的填充題目以完善題庫,保證測試的有效性,對試題進行必不可少的增添和修改功能。實現了試題按照題目、答案、難度、知識點、區分度、時間等參數添加相應試題,存儲到MySQL 數據庫中并且定期檢查和維護試題。
5 結束語
本文的自動組卷系統設計對傳統遺傳算法的選擇、交叉和變異策略進行改進,很大程度上防止“未熟就收斂,局部最優,生成的試題質量偏低”等問題,較好的根據用戶需求做到相應要求的試卷,實現組卷速度快且成卷質量高的優點,但還無法做到根據用戶動態的調整難度系數,還需一定改進,總體上大大減少了教師在出卷時消耗的時間和精力,為教師和學生提供了方便。
猜你喜歡
今日農業(2022年15期)2022-09-20 06:56:20
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
雜文月刊(2016年1期)2016-02-11 10:35:51
現代企業(2015年8期)2015-02-28 18:54:47
