
基于機器學習的網上問政文本分類方法
2023-04-14 21:34:32於雯
電腦知識與技術 2023年6期
關鍵詞:機器學習
摘要:隨著信息技術的發展,政務服務的水平也得到了提升,各級政府部門都開通了網上問政服務,留下了大量的群眾留言,只通過后臺人工對留言進行分類,效率低下,費時費力。本文提出基于機器學習的方法,對網上問政的文本進行分類,利用自然語言處理的技術對文本進行合理的預處理操作,利用詞向量工具Word2vec將文本表示成向量的形式,通過機器學習算法支持向量機(SVM)的方法進行文本分類。實驗表明,在基于機器學習的文本分類中,經過預處理和詞向量模型表示后的文本,使用SVM分類方法對網上問政文本進行所屬機構類別取得了90%以上的準確率。
關鍵詞:自然語言處理;機器學習;網上問政;文本分類;SVM
中圖分類號:TP311? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)06-0022-03
開放科學(資源服務)標識碼(OSID)
0引言
智慧政府的建設為群眾提供了更多樣的政務服務途徑,開通網上問政方便群眾可以通過互聯網完成對相關問題和政策的咨詢,不受時間地點限制,方便群眾辦事,拓寬了政府服務渠道。對于網上問政的問題和留言,需要根據問題的類型分類以便歸口到對應的政府機構進行回復與處理,而有不少群眾對于自己所需要咨詢的問題并不能準確劃分歸口部門,導致問題不能及時得到有效處理[1]。通過自然語言處理對網上問政的留言文本進行分類可以更加高效地對留言進行分類,對群眾關切的問題進行及時回應,提高政務服務的水平。
自然語言處理就是將人類語言轉換成計算機可以理解和處理的語言,利用計算機技術實現更加智能的機器理解與后續處理。自然語言就是人類溝通交流所使用的語言,根據地域和種族的不同,不同國家和民族都會有自己的語言,主要有英語、漢語、俄語、法語等。不同的語言類型也有不同的語法結構,需要采用不同的處理才能達到理想的效果,針對中文的文本預處理,目前主要有中文分詞、去除停用詞、詞性標注、向量表示等,根據不同的文本特征進行預處理可以大大提高文本處理的準確率。支持向量機模型在多個自然語言處理問題中都取得了較好的實驗結果,本文利用SVM的算法對網上問政文本分類,采集網絡上公開的、實際的網上問政文本,通過文本預處理對網絡文本進行分詞,去除停用詞得到更加規整的文本形式,采用詞向量模型Word2vec將文本轉換成計算機更容易處理的向量形式,最后采用SVM分類方法對文本向量進行分類,并驗證分類的準確率,同時還驗證了采用不同的預處理操作,以及詞向量模型對于分類準確率的影響。
1 文本采集與預處理
1.1數據采集與清洗
從某市政府網上問政平臺公開的政務留言數據中,采集網上問政留言數據,并按群眾留言數量排序得到問政數量最多的前五個政府機構,分別為:人社、醫保、市場監管、公安、教育。由于采集到的網絡文本存在著網絡符號,重復文字,需要對采集后的原始網上留言數據進行清洗、規整、補錄和統計。第一,針對采集到的留言數據進行清洗,刪除針對研究沒有意義的符號、重復和缺失留言數據;第二,對采集到的部分半格式化的信息進行格式化,如將包含中文的留言數據字段規整為整型字段。數據清洗流程為之后的數據分析和分類提供優質的基礎數據。最終清洗后得到共計127000條留言數據,5個留言數量較高的機構數據數量如圖1所示。
1.2 中文分詞
中文句子的最小單位是字,而詞才是具有語義的最小單位,并且具有非常豐富的語義及結構特征。在對文本進行文本分類,對文本語句進行按詞的劃分具有決定性作用,因此分詞的準確性是保證分類結果準確的基礎。相比英文每個單詞都以空格結尾,對句子進行了天然的切分,所以中文文本不具有良好的切分標志,所以需要對句子按照詞語進行切分,只有正確地按照詞句進行切分才能對句子進行分析。對句子的正確切分就是自然語言處理領域的分詞,準確的中文分詞也是目前的研究難點。
目前針對中文的分詞工具有很多種,國內比較常用的分詞系統包括:jieba分詞、中科院的 NLPIR中文分詞系統,哈爾濱工業大學語言技術平臺(LTP)分詞系統等。jieba分詞是一種常用的開源分詞庫。它提供了一種非常適合文本細分的分析模式-精確模式[2]。主要是因為它能夠根據分割模型以最精確的方式分離句子。同時,jieba 還支持用戶自定義的詞庫,可以有效地提高準確率。本文采用比較常用的jieba分詞來進行分詞處理。
1.3 去除停用詞
停用詞(Stop Words)是指在自然語言處理中可以過濾掉的一些沒有實際意義的功能詞,這些詞在文本中出現的頻率較高,但對文本表達沒有實際意義,中文常用的停用詞有代詞“這”“那”,助詞“的”“了”,介詞“在”,語氣助詞“呢”“啊”等[3]。去除這些無實義的高頻停用詞可以降低特征向量的空間維度,提高分類的準確率,本文使用哈工大的停用詞表來對文本中的停用詞進行處理。
1.4 詞向量表示
網上留言屬于非結構化文本,不便于使用計算機處理和理解,需要將其按一定的規則把文本轉換成數值模型的詞向量,使計算機能理解并加以處理。這也是文本處理的一個重要問題,如果可以準確合理地將文本表示成數值類型,將會大大提高計算機的處理和分析難度。利用最簡單的想法,對每個詞語進行賦值,句子就是每個詞語數值的集合,但是這些散亂的數值便不能有效地表示出語義信息,因此采用一種神經網絡的語言模型,CBOW(Continuous Bag-of-Words)模型是一種經過改進的神經網絡語言模型,主要通過映射層替代隱層,實現了輸入層詞向量的相加,從而降低了模型的計算量。CBOW模型是由預知的上下文來得出單詞出現的概率。主要結構是由輸入層、投影層和輸出層三層結構組成,模型的學習目標是根據輸入層輸入的信息和輸出層輸出的條件概率最大化對數似然函數:
[L=w∈Cl))]? ? ? ? ? ? ? ? ? ? ? ? ? ? (1)
其中,[W]是從語料庫[C]輸入的詞語。 CBOW 模型的原理可以解釋為,假設已知上下文,通過上下文來預測中間最可能出現的詞。因此模型的輸入是上下文詞向量,經過投影層簡單求和,再輸入輸出層,輸出出現概率最大的詞[W]。
本文將使用 Word2vec訓練詞向量,Word2vec詞向量模型包含了 CBOW 模型,用高維向量表示詞語,并把相近意思的詞語放在相近的位置,并且使用實數向量(不局限于整數)只需要用大量的某種語言的語料,就可以用它來訓練模型,獲得詞向量。在本文的實驗中,對采用不同的預處理進行實驗對比,驗證預處理操作對文本分類結果的影響。
2 SVM 文本分類
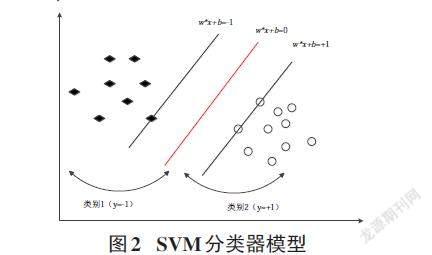
支持向量機是一種監督學習算法,是一種廣泛使用的機器學習方法,SVM算法具有泛化能力強,能夠很好地處理高維數據,無局部極小值問題。SVM算法利用核函數將詞向量映射到高維的空間中,使在低維空間中不可分的特征在高維空間中變得可分,從而完成分類的任務,利用 SVM 分類模型對詞向量提供的數據特征進行文本分類,根據訓練集數據將模型參數學習到最優,然后利用訓練好的模型對測試集數據中文本類型作出預測,最后根據預測結果判斷訓練模型的好壞[4]。針對文本二分類任務,SVM模型分類的原理是將通過預處理階段生成的文本詞向量經過核函數的映射作用,分布到更高維度的空間中,然后將問題轉化為在高維空間中的線性分類問題,找到可以分隔的最大區間超平面,并且兩個最大的超平面中的每一個超平面在每一側都有兩個其他超平面。兩個超平面彼此平行,并且最大化兩個超平面的間距就是最優的分隔超平面。支持向量機模型如圖 2所示。最大間隔超平面表示為:
[Wx+b=0]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(1)
兩個平行的超平面為:
[Wx+b=1]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(2)
[Wx+b=-1]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(3)
y表示數據的分類標簽,-1表示屬于機構1的數據,+1表示屬于機構2的數據。令:
[f(x)=Wx+b]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(4)
將兩個相互平行的超平面上的點稱為支持向量,滿足:
[|Wx+b|=1]? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? (5)
因此,從支持向量到最大間隔超平面的距離為:
[Wx+bW=1W]? ? ? ? ? ? ? ? ? ? ?(6)
設間隔的大小為[M],那么:
[M=1W]? ? ? ? ? ? ? ? ? ? ? ? ? ?(7)
最大化[M]等價于:
[max1W→minW2]? ? ? ? ? ? ? (8)
因此,滿足最大間隔超平面所需的條件是:
[minW2]? ? ? ? ? ? ? ? ? ? ? ? ? (9)
滿足于:
[yiWxi+b≥1;i=1,2,...,N]? ? ? ? ? ?(10)
轉化為拉格朗日優化問題,利用拉格朗日乘數法進行計算得到式(11):
[LW2,b,α=12W2-i=1NαiyiWTxi+b-1](11)
其中,[αi]是拉格朗日乘子。
SVM算法的特性對于二分類問題可以較好地處理,而對于多分類問題就要對SVM算法進行改進,目前針對多分類的問題,SVM算法的改進方法主要有兩種,第一種是對每兩個類別之間都構造一個SVM 二分類器,對每一個分類器判別出的所屬類別計數,最終計數最大的那個類別就是該文本所屬的類別;第二種是對于M個分類,對一個類別和剩余的M-1個類別之間構造一個二分類進行分類判別,如果不屬于第一個類別,就繼續在剩余的M-1個類別中繼續構造分類器進行判別。由于第二種方法中M-1個類別的數據量會明顯大于某個單一類別的數據量,造成數據失衡,導致一個樣本可能屬于多個類,因此本文中采用第一種方法構建多分類的SVM分類器。
本文對需要分類的五個樣本類別,每兩個分類之間構造一個SVM分類器模型,共需要訓練出10個SVM二分類器。在進行測試時,將測試樣例分別輸入每個分類器中,分別進行二分類,最終的分類類別取計數最大那個類別作為最終分類結果。機器學習工具包scikit-learn 包中已經集成了SVM算法模型,因此可以直接導入工具包來完成文本分類,本文的SVM算法中的核函數選用線性核函數來進行實驗。
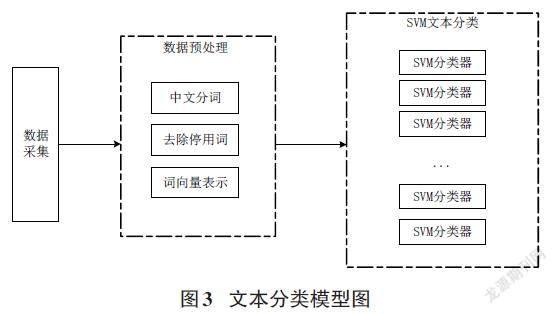
基于機器學習的SVM算法搭建網上問政文本分類模型如圖3所示。
3實驗分析
本文利用SVM算法對網上問政的留言文本分屬機構分類進行實驗,并對不同的預處理操作進行對比實驗。先對采集的網上問政留言文本數據使用jieba 分詞工具做中文分詞處理后,將數據隨機切分為測試集和訓練集,測試集和訓練集的占比為 2:8,訓練集用于訓練SVM 模型,測試集用于測試分類模型的分類效果。針對實驗結果的評價也是實驗中非常關鍵的一步。因此在本章的實驗中,采用統一的評價指標來描述分類模型的效果。主要有兩個評價指標,即準確率和召回率。
準確率(Precision)可以簡記為P。就是評價模型的準確率,對于分類算法模型來說,準確率是最直觀的評價標準,簡單明了地展示出模型的效果,計算標準就是分類正確的比例。計算公式如式(12)所示:
[準確率=判斷正確的類別數目該類別所有評論文本的數目]? ? ? ? (12)
召回率( Recall):簡記為 R,作為對模型準確率的補充,考查分類結果是否完備。可以指示出分類指標指定的效果,不能單從準確性就判斷模型的好壞,模型是否完善也是一個重要因素,召回率就是為人們在評價模型時提供一個更加完善的指標。可以通過式(13)計算得到:
[召回率=判斷正確的類別數目該類別實際應包含的評論文本數目] ? (13)
對于一個文本分類數據集D,屬于類別1且被正確分類到該類別的留言數量記為RR,分類為類別1但不屬于該類別的文本的數量被標記為 RN,并且屬于類別1但未被分類到該類別的文本的數量被標記為NR,其他不相關并且也沒有任何分類的文本數量標記為NN。此時,準確率和召回率可分別按照式(14)和式(15)計算:
[Precision=RRRR+RN]? ? ? ? ? ? ? ? ? ? (14)
[Recall=RRRR+NR]? ? ? ? ? ? ? ? ? ? ?(15)
相關研究表明,準確率和召回率兩項指標在某種程度上存在著相互制約的關系,兩者之間的相互制約使得在選擇模型時無法取舍。因此需要綜合度量兩項指標的變化情況。F-Measure就是可以同時關注準確性和召回率的一個指標, F-Measure均衡地制約著準確率和召回率,可以綜合這兩個指標的影響效果,其計算公式如式(16)所示:
[F-Measure=2*Recall*PrecisionRecall+Precision] ? (16)
F-Measure也稱為 F1 值,常作為評價指標用于衡量情感分類的整體效果,表明準確率和召回率對于模型的評價具有相同的參考價值。F1 的取值在 0 到 1 之間,最好的情況就是當F1值取1時表明準確率和召回率都為1,此時的模型才是最為理想的模型。
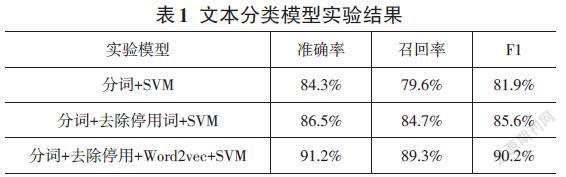
實驗一對分詞后的文本數據直接輸入SVM算法模型進行文本分類,實驗取得了84.3%準確率;實驗二將中文分詞后的文本數據利用停用詞表進行去除停用詞處理后輸入SVM算法模型,實驗取得了86.5% 的準確率;實驗三將經過分詞和去除停用詞處理的文
本數據,再通過Word2vec詞向量模型生成詞向量表達后,輸入SVM模型中,取得了91.2%的準確率。實驗結果如表1所示,實驗結果表明,SVM 算法可以較好地完成網上問政文本分類任務,采用合理的文本預處理操作比單純的使用SVM算法可以取得更高文本分類的準確率。本文采用的經過分詞及去除停用詞處理后的Word2vec+SVM算法文本分類模型取得了最高的準確率,由此可以說明,本文提出的方法可以較好地完成網上問政文本分類任務。
4結束語
本文提出了采用機器學習SVM算法模型對網上問政群眾留言的文本按機構部門分類,并采用了中文分詞和去除停用詞的文本預處理操作,同時利用了Word2vec詞向量表達模型取得了較高的分類準確率,相比于人工后臺分類更加高效省時,也解決了群眾在問題咨詢中不確定問題歸屬部門的問題。后續工作中可以加入更多的機器學習算法來進一步提高分類模型的各項指標[6]。
參考文獻:
[1] 朱文峰.基于支持向量機與神經網絡的文本分類算法研究[D].南京:南京郵電大學,2019.
[2] 胡玉蘭,趙青杉,陳莉,等.面向中文新聞文本分類的融合網絡模型[J].中文信息學報,2021,35(3):107-114.
[3] 何鎧,管有慶,龔銳.基于深度學習和支持向量機的文本分類模型[J].計算機技術與發展,2022,32(7):22-27.
[4] 於雯,周武能.基于LSTM的商品評論情感分析[J].計算機系統應用,2018,27(8):159-163.
[5] 趙延平,王芳,夏楊.基于支持向量機的短文本分類方法[J].計算機與現代化,2022(2):92-96.
[6] 劉婧,姜文波,邵野.基于機器學習的文本分類技術研究進展[J].電腦迷,2018(6):26.
【通聯編輯:唐一東】
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
