基于多尺度分割注意力的無人機航拍圖像目標檢測算法
2023-04-19 04:35:20冒國韜鄧天民于楠晶
航空學報 2023年5期
冒國韜,鄧天民,2,*,于楠晶
1.重慶交通大學 交通運輸學院,重慶 400074
2.重慶大學 自動化學院,重慶 400044
3.重慶交通大學 航運與船舶工程學院,重慶 400074
隨著航空遙感技術的發展,無人機在軍事偵查、環境監測及交通規劃等領域引起了廣泛關注,無人機圖像目標檢測技術作為無人機圖像應用的關鍵技術之一,能夠拓寬無人機的場景理解能力,在軍事和民用領域具有重要的應用價值。然而,傳統目標檢測方法由于手工特征設計繁瑣、魯棒性差及計算冗余等原因,難以滿足無人機圖像目標檢測的需求。近年來,以卷積神經網絡(Convolutional Neural Network,CNN)為代表的深度學習方法在計算機視覺領域迎來了迅速發展[1],基于深度學習的目標檢測方法憑借其強大的自適應學習能力和特征提取能力,在檢測性能上遠超傳統的目標檢測方法,因此越來越多學者開始利用深度學習的方法進行無人機圖像目標檢測。當前基于深度學習的無人機圖像目標檢測方法可依據是否需要區域建議分為2 類:
1)基于區域建議的無人機圖像目標檢測算法,此類方法通過提取若干候選區域的特征信息來對預設的候選目標區域進行分類與回歸,進而獲取目標的類別與位置,其中較為典型的有Faster R-CNN[2]、Mask R-CNN[3]、Cascade RCNN[4]等。近年來,許多學者基于這類算法提出了針對無人機圖像目標的檢測方法。例如,Liu 等[5]針對無人機圖像小目標可獲取特征信息少的問題,基于Faster R-CNN 網絡設計了一種多分支并行特征金字塔網絡(Multi-branch Parallel Feature Pyramid Networks, MPFPN)以捕獲更豐富的小目標特征信息,此外,通過引入監督空間注意力模塊(Supervised Spatial Attention Module, SSAM)減弱背景噪聲的干擾,有效提升了對無人機圖像小目標的檢測性能,但對于訓練圖像中從未標注的物體存在誤檢的情況。Lin 等[6]在Cascade R-CNN 網絡的基礎上提出了多尺度特征提取骨干網絡Trident-FPN,同時引入注意力機制設計了一種注意力雙頭檢測器,有效改善了由于無人機圖像目標尺度差異大對目標檢測器帶來的不利影響,但區域建議網絡較大的計算開銷還有待改善。
2)基于回歸的無人機圖像目標檢測算法,該類方法在不進行區域建議的情況下完成端到端的目標檢測,直接通過初始錨點框對目標定位并預測類別,典型的有YOLO(You Only Look Once)系列算法[7]、單擊多盒檢測器(Single Shot MultiBox Detector,SSD)[8]及RetinaNet[9]等。為達到無人機圖像目標實時檢測的目的,已有研究人員將基于回歸的目標檢測算法應用于無人機 圖 像 領 域。例 如,Zhang 等[10]提 出 一 種 基 于YOLOv3 的深度可分離注意力引導網絡,通過引入注意力模塊并將部分標準卷積替換為深度可分離卷積,有效提升了對無人機圖像中小目標車輛的檢測效果。Wang 等[11]提出了一種高效的無人機圖像目標檢測器SPB-YOLO,首先利用設計的條形瓶頸(Strip Bottleneck, SPB)模塊來提高對不同尺度目標的檢測效果,其次,通過基于路徑聚合網絡(Path Aggregation Network, PANet)[12]提出的特征圖上采樣策略,提高了檢測器在無人機圖像密集檢測任務中的表現。裴偉等[13]提出了一種基于特征融合的無人機圖像目標檢測方法,通過引入不同分類層的特征融合機制以高效的結合網絡淺層和深層的特征信息,有效改善了SSD 目標檢測算法存在的漏檢和重復檢測問題,但由于更多的網絡層次和深度增加了較大的計算開銷,嚴重影響了目標檢測實時性。
由于大視場下的無人機航拍圖像目標往往呈現稀疏不均的分布,搜索目標將會花費更高的成本。此外,無人機航拍圖像的待檢目標具有小尺度、背景復雜、尺度差異大及排列密集等特征,通用場景的目標檢測方法很難取得理想的檢測效果。基于此,本文提出一種多尺度分割注意力單元(Multi-Scale Split Attention Unit,MSAU),分別從通道和空間2 個維度自適應的挖掘不同尺度特征空間的重要特征信息,抑制干擾特征信息,通過將其嵌入基礎骨干網絡,使網絡更具指向性的提取任務目標區域的關鍵信息;進一步的,本文結合加權特征融合思想提出一種自適應加權特征融合方法(Adaptive Weighted feature Fusion,AWF),通過動態調節各個特征層的重要性分布權重,實現淺層細節信息與深層語義信息的高效融合。最后,結合以上提出的MSAU 和AWF 兩種策略,本文設計了一種基于多尺度分割注意力的無人機航拍圖像目標檢測算法(Multi-scale Split Attention-You Only Look Once,MSA-YOLO)。
1 本文方法
MSA-YOLO 算法的核心思想是盡可能保證目標檢測器實時檢測性能的前提下,著重關注如何挖掘有益于無人機圖像目標檢測的關鍵特征信息,通過提出的多尺度分割注意力單元MSAU 和自適應加權特征融合AWF 來提升基準模型YOLOv5 在無人機圖像目標檢測任務中的表現。MSA-YOLO 算法的框架結構如圖1所示,嵌入在骨干網絡瓶頸層(Bottleneck Layer)中的多尺度分割注意力單元MSAU 主要包括多尺度特征提取模塊、通道注意力模塊及空間注意力模塊3 個部分,首先通過多尺度特征提取模塊提取出豐富的多尺度特征信息,隨后利用并行組合的混合域注意力為多尺度特征層的不同特征通道和區域賦予不同的注意力權重,從大量多尺度特征信息中篩選出對無人機圖像任務目標更重要的信息;自適應加權特征融合AWF利用可學習的權重系數對3 個特征尺度的特征層進行加權處理并實現自適應的特征融合,進而結合豐富的上下文信息強化目標檢測器的表征能力。
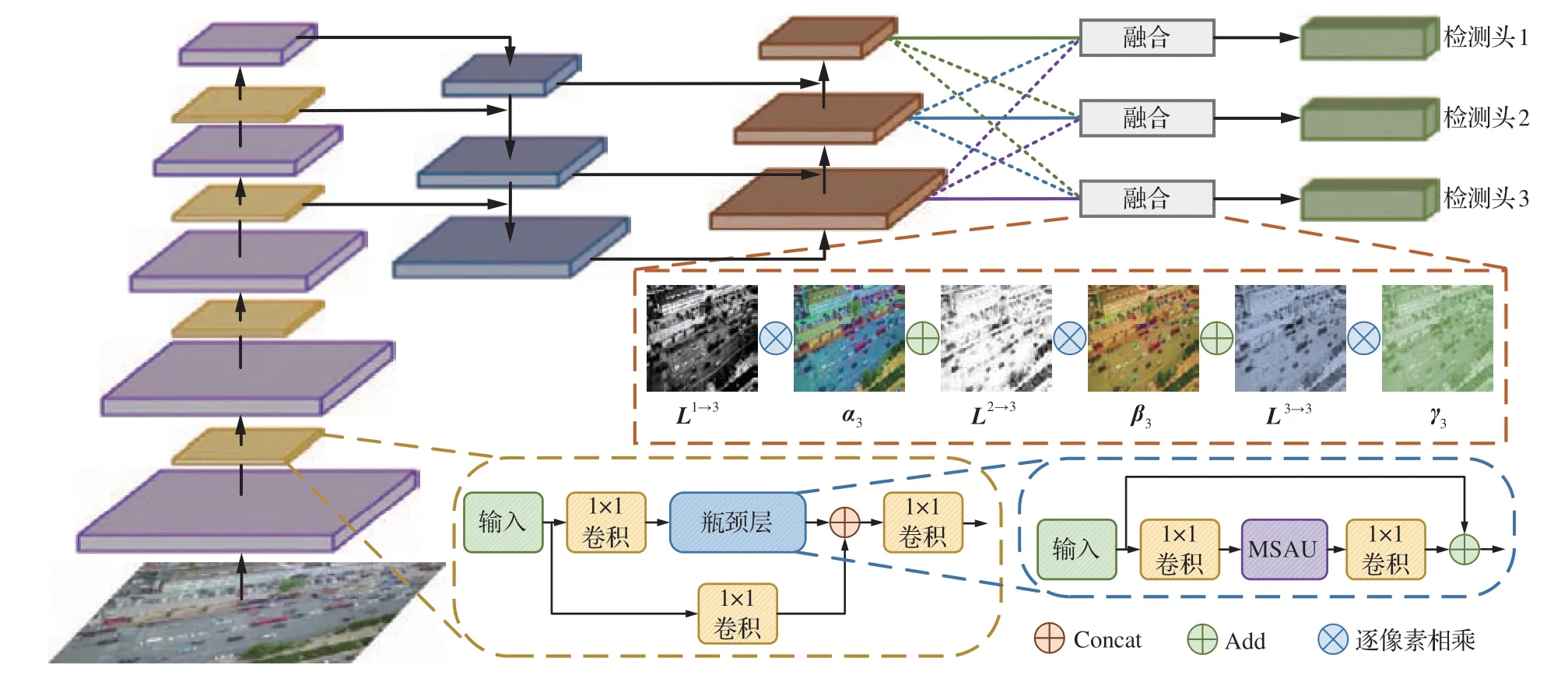
圖1 MSA-YOLO 算法框架結構圖Fig.1 Architecture of MSA-YOLO algorithm
1.1 多尺度分割注意力單元
在特征提取過程中,采用固定尺寸的卷積核只能提取到目標局部的特征信息,無法通過不同感受野挖掘豐富的上下文信息,為有效利用不同尺度的特征空間信息,本文設計了一種多尺度特征提取模 塊(Multi-scale Feature Extraction Module,MFEM),通過多尺度卷積的方式來獲取不同尺度的特征信息。MFEM 的多尺度特征提取過程如圖2 所示,假定多尺度特征提取模塊MFEM 的輸入特征空間為X=[X1,X2,…,Xc]∈RC×H×W,通過split 切片操作將輸入特征空間X的通道平均切分為n個部分,若C表示該輸入特征的通道數,則切片后各個部分Xi的通道數為C'=C/n,為了降低模塊的參數量,本文采用不同分組數量Gi且不同卷積核尺寸ki×ki的分組卷積提取多尺度的特征信息Fi∈RC'×H×W
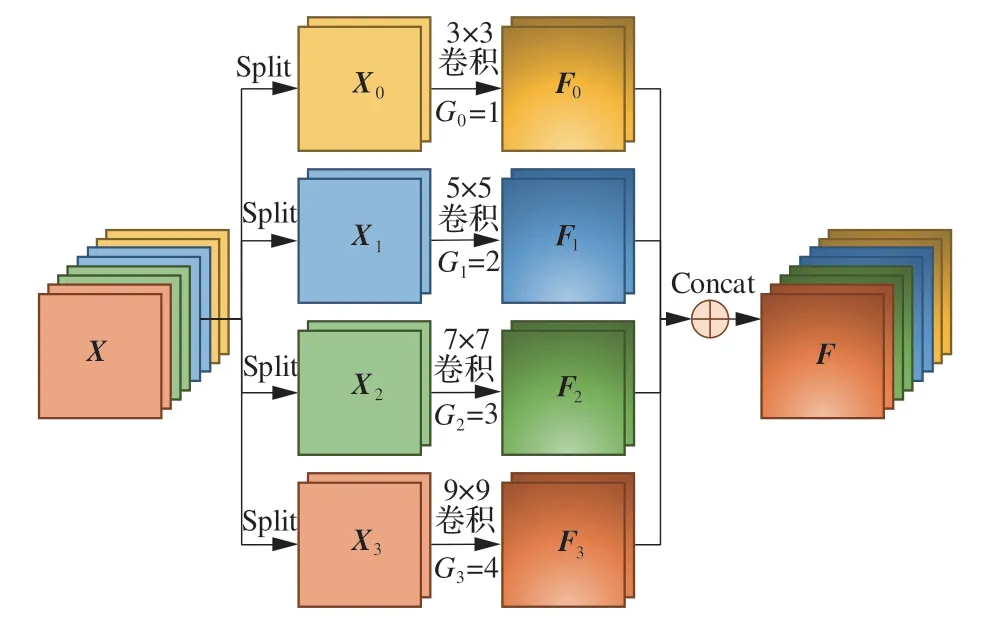
圖2 多尺度特征提取模塊流程圖Fig.2 Flow chart of multi-scale feature extraction module
式中:(Xi,Gi)表示對特征圖Xi進行分組數量為Gi且卷積核尺寸為ki×ki的卷積操作,為保證模型較小的計算開銷,本文將輸入特征空間切分為4 個部分,則設置n=4,分組卷積核尺寸ki分別為3、5、7、9,分組數量Gi分別為1、2、3、4。
各個部分的特征圖Xi在分別經過不同尺寸的卷積核后獲得了不同尺度的感受野,并提取出不同尺度的特征信息Fi,對Fi進行Concat 操作可以得到最終融合后的特征空間F∈RC×H×W
式中:Cat(·)表示對所有的特征圖進行Concat操作。
本文的多尺度特征提取模塊在一定程度上彌補了卷積核尺寸單一對網絡特征提取能力的不利影響,對輸入特征空間進行均勻分割,再分別利用4 種不同感受野的卷積核捕捉不同尺度的特征空間信息,最后將獲得的4 種不同尺度的特征信息進行融合,使得融合后的特征空間F具備豐富的多尺度上下文信息,有利于交錯復雜的無人機圖像檢測任務。
注意力機制中,所有特征信息會根據學到的注意力權重進行加權處理,相關性較低的特征信息被賦予較低的權重,反之則被賦予較高的權重,以此弱化不重要信息的干擾,并分離出重要信息。按照注意力域的不同,一般可將注意力機制分為通道域注意力機制、空間域注意力機制及混合域注意力機制。通道注意力機制關注特征圖通道之間的遠程依賴關系,空間域注意力機制聚焦于特征圖中對分類起決定作用的像素區域,混合域注意力機制則同時利用到空間域和通道域的信息,每個通道特征圖中的每個元素都對應一個注意力權重。這些即插即用的注意力模型可以無縫集成到各種深度學習網絡中用以指導目標檢測任務。
為更好地提取無人機圖像目標的特征信息,弱化無關背景信息的干擾,本文結合通道域注意力和空間域注意力,提出了一種并行組合的混合域注意力,一方面沿著通道維度獲取通道間的遠程相互依賴關系,另一方面通過強調空間維度感興趣的任務相關區域進一步挖掘特征圖的上下文信息。本文設計的混合域注意力由擠壓激勵模 塊(Squeeze-and-Excitation Module,SEM)[14]和空間注意力模塊(Spatial Attention Module,SAM)[15]并行連接組成。通道注意力旨在通過生成一種可以維持通道間相關性的注意力權重圖來挖掘輸入與輸出特征通道之間的遠距離依賴關系,SEM 和SAM 的網絡結構如圖3 所示。
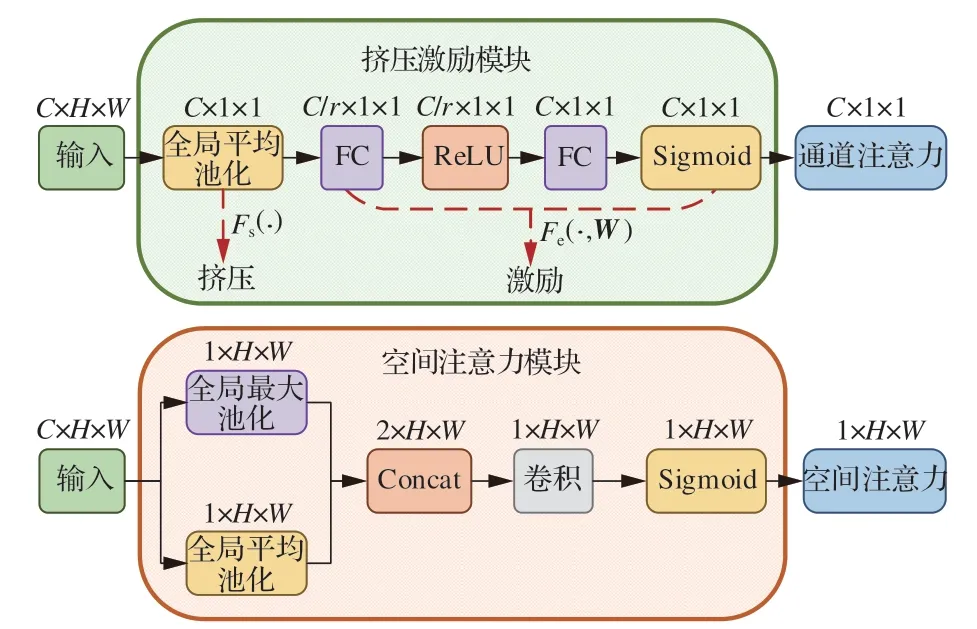
圖3 SEM 和SAM 的網絡結構圖Fig.3 Network structure of SEM and SAM
假設通道注意力模塊SEM 的輸入特征空間為X=[X1,X2,…,Xc]∈RC×H×W,C表示該輸入特征的通道數,H×W表示輸入特征的尺度大小,輸入特征空間的第c個通道用Xc∈RH×W表示。Fs(·)表示擠壓(Squeeze)映射,Fe(·,W)表示激勵(Excitation)映射,Fs(·)通常采用全局平均池化(Global Average Pooling,GAP)實現,對輸入空間特征X進行Fs(·)映射后獲得全局特征空間Z∈RC×H×W的第c個特征Zc:進一步的,利用Fe(·,W)激勵操作來降低計算開銷,獲得高效的自適應學習注意力圖。首先使用參數為W0,降維系數為r的全連接(Fully Connected,FC)層進行降維操作獲得維度為C/r×1×1 的特征,通過ReLU 函數對特征進行激勵操作δ,經過參數為W1的FC 層后恢復原始的維度C×1×1,最后利用sigmoid 激活函數進行歸一化后得到各個通道的注意力權重S,即
空間注意力模塊旨在利用輸入特征的空間信息生成空間注意力權重圖,并對輸入特征進行空間域注意力加權,進而增強重要區域的特征表達。空間注意力模塊的輸入特征空間與通道注意 力 模 塊 的 輸 入 特 征 空 間X=[X1,X2,…,Xc]∈RC×H×W相同,分別沿著通道維度采用全局最大池化(Global Max Pooling,GMP)和全局平均池化(Global Average Pooling,GAP)壓 縮 后 得 到Xavg∈R1×H×W和Xmax∈R1×H×W這2 個特征圖,對2 個特征圖進行concat操作后采用感受野較大7×7 卷積核進行卷積操作F7×7conv,最后通過sigmoid 激活函數σ進行歸一化后得到空間域注意力權重圖M∈R1×H×W:
空間注意力模塊SAM 將輸入特征的每個通道進行相同的空間加權處理,忽視了通道域的信息交互;而通道注意力模塊SEM 則忽視了空間域內部的信息交互,將一個通道內的信息進行全局加權處理。因此,本文將通道注意力模塊與空間注意力模塊通過并行的方式連接,旨在從全局特征信息出發,沿著通道與空間2 個維度深入挖掘輸入特征內部的關鍵信息,進而篩選出任務相關的重要信息,弱化不相關信息的干擾。相比于級聯連接的組合方式,這種并行組合的方法無需考慮通道注意力模塊與空間注意力模塊的先后順序,2 種注意力模塊都直接對初始輸入特征空間進行學習,不存在特征學習過程中互相干擾的情況,從而使混合域注意力的效果更穩定[16]。
混合域注意力同時考慮了空間注意力和通道注意力,在一定程度上豐富了特征信息,但無法有效地挖掘和利用不同尺度的特征空間信息。鑒于此,本文設計了一種能夠有效地建立多尺度注意力間長期依賴關系的多尺度分割注意力單元MSAU,如圖4 所示。MSAU 主要由多尺度特征提取模塊MFEM、通道注意力模塊SEM 及空間注意力模塊SAM 組成,輸入特征空間X通過多尺度特征提取模塊捕捉不同尺度的特征信息,得到多尺度特征空間F,隨后,不同尺度的特征圖分別通過通道注意力模塊和空間注意力模塊得到多尺度注意力權重,最后利用并行組合的通道與空間2 個維度的多尺度注意力進行注意力加權后得到最終輸出的特征空間Y。
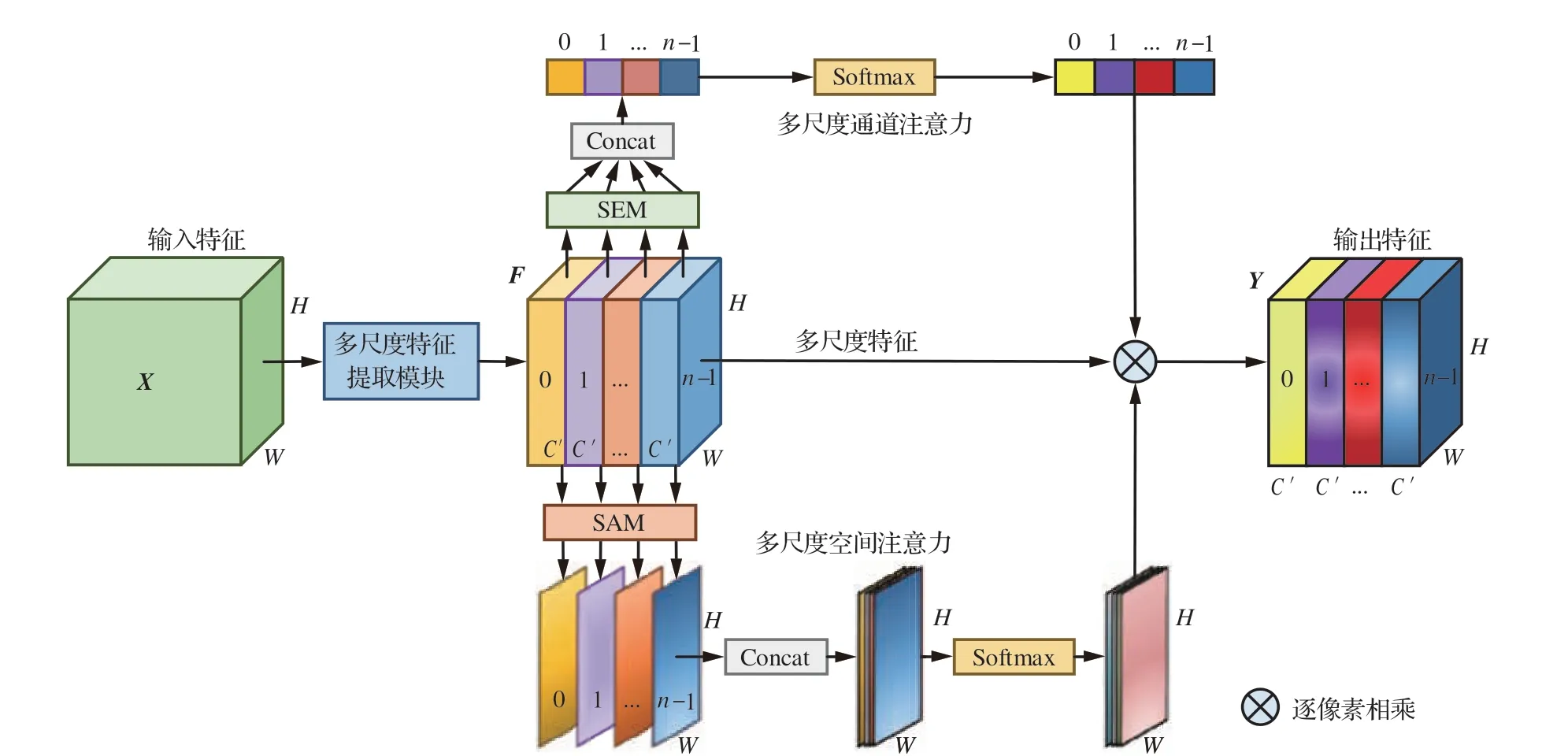
圖4 多尺度分割注意力單元結構圖Fig.4 Architecture of multi-scale split attention unit
假設多尺度分割注意力單元MSAU 的輸入特征空間為X=[X1,X2,…,Xc]∈RC×H×W,經過多尺度特征提取模塊提取特征后得到多尺度特征空間F∈RC×H×W,隨后不同尺度特征圖Fi利用通道注意力模塊來獲得多尺度通道注意力權重Si:
式中:SEM(·)代表利用通道注意力模塊SEM 挖掘特征圖的通道注意力;Si為Fi的通道注意力權重值,因此整個多尺度通道注意力S可以表示為
式中:⊕表示Concat 操作;S為多尺度通道注意力權重。
為建立通道間的遠程依賴關系,實現多尺度通道注意力之間的信息交互,進一步利用Softmax 函數對通道注意力Si進行重新標定得到最終的通道注意力權重Hi:
式中:Softmax(·)表示Softmax 操作,用于獲取多尺度通道的重標定權重Hi。
類似的,可以利用空間注意力模塊捕捉不同尺度特征圖Fi的多尺度空間注意力權重Mi:
式中:SAM(·)代表利用空間注意力模塊SAM 捕捉特征圖的空間注意力;Mi為Fi的空間注意力權重值,因此整個多尺度空間注意力M可表示為
式中:+表示add 操作;M為多尺度空間注意力權重。
隨后,利用Softmax 函數Softmax(·)對空間注意力Mi進行重新標定得到最終的空間注意力權重Pi:
最后,將SEM 和SAM 學習到的多尺度通道注意力權重向量Hi和多尺度空間注意力權重圖Pi與多尺度特征空間F∈RC×H×W進行注意力加權Fscale得到輸出的多尺度特征空間Yi:
式中:?表示特征加權乘法運算符號。Concat 操作能在不破壞原始特征圖信息的前提下,完整地維持特征表示,因此,最終得到的多尺度分割注意力單元MSAU 的輸出Y可表示為
MSAU 首先利用多尺度特征提取模塊有效提取了不同尺度特征空間的多維特征,隨后將其分別輸入并行組合的混合域注意力,為不同尺度特征空間賦予了不同的重要性權重。這種方法不僅能考慮到多尺度特征信息,同時使網絡能夠有選擇地處理關鍵信息,對目標區域投入更多注意力資源,以獲取更多待檢目標的細節信息。同時,不同尺度特征空間的多尺度注意力權重會在模型訓練過程中根據每輪輸入特征空間的重要性差異進行自適應的、精確的調整更新,通過將其嵌入骨干網絡,進而利用豐富的特征空間以指導無人機圖像目標檢測任務。
1.2 自適應加權特征融合
淺層網絡提取目標紋理邊緣特征,具有更多的細節內容描述;深層網絡則提取目標豐富的語義特征,但同時削弱了對小目標位置信息和細節信息的感知,以致丟失小目標在特征圖中的特征信息[17]。PANet 將不同深度特征信息以平等關系跨層融合,忽略了不同特征層之間的關系,直接使用3 個特征尺度的輸出特征進行目標預測,但不同深度特征層對任務目標的貢獻其實是不同的,淺層網絡特征在小目標檢測過程中占據著更重要的位置。針對以上問題,本節設計了一種自適應加權特征融合方法AWF,通過為各尺度特征層賦予不同比例權重,有效利用了3 個不同尺度特征層的淺層和深層特征,自適應的強化特征金字塔中對任務目標檢測更重要的特征信息,進而融合豐富的特征信息以指導無人機圖像小目標檢測任務。
AWF 在進行最終的特征融合時采用了加權再相加的方式,因此,需要確保參與融合的特征層分辨率相同,且通道數也應相同。對于特征金字塔的輸出特征Ln∈RCn×Hn×W n,其中n∈1,2,3,通過上采樣或下采樣將特征金字塔輸出特征Lm∈RCm×Hm×W m的特征圖分辨率和通道數都調整為與Ln相同,Lm→n∈RCn×Hn×W n表示調整后的特征。對于上采樣,首先使用1×1 卷積層來調整特征的通道數,然后通過雙線性插值來提高分辨率;對于下采樣,則使用步長為2 的最大池化層和3×3 卷積層同時改變特征的分辨率和通道數。將調整后的特征通過Concat 操作進行整合后可表示為整個特征金字塔的輸出特征L∈R3Cn×Hn×W n:
隨后,使用Softmax 函數Softmax(·)和1×1卷積層F1×1conv得到權重矩陣W∈R4×Hn×W n:
最后,沿著通道維度將權重矩陣W切割為再沿著通道維度進行擴展后得到特征金字塔調整后特征Lm→n對應的重要性權重參數αn,βn,γn∈RCn×Hn×W n,這些重要性權重參數來自前面特征層經過卷積后的輸出,并通過網絡的梯度反向傳播變為了可自適應學習的參數。將其與對應特征Lm→n加權融合后得到新的融合特征Fn:
由于加權特征融合的權重參數均源自前面3個尺度特征層的輸出,因此可學習的權重參數和特征是息息相關的,數據集實例樣本的特點則是影響貢獻衡量標準的主要因素,針對小目標實例居多的無人機航拍圖像,則認為淺層網絡中豐富的紋理和邊緣特征對無人機航拍目標檢測任務具有更大的貢獻,更有利于提取小目標的類別及位置信息,因此淺層網絡特征層則會被賦予更高的權重值,而這樣一個有效的權重系數可以經過不斷優化的訓練過程產生。在模型訓練過程中,AWF 根據各尺度特征層對當前任務目標的貢獻大小來動態的調節其權重值,充分挖掘了不同深度特征層的多維特征,可以更好地監督網絡的特征融合過程,使融合后的特征兼顧強大的語義信息和豐富的幾何細節信息。
值得一提的是,這種自適應加權的特征融合方法并不是能夠完全適用于任何目標檢測任務,在數據集整體實例的像素大小或各類目標實例的特征未呈現出一種較為顯著的趨勢時,可能很難達到較為理想的效果。
2 實驗結果與分析
2.1 實驗數據與參數設置
1)實驗平臺:本文實驗采用的硬件配置為Nvidia RTX3060 GPU 和Intel i5-10400 2.90 GHz CPU,軟件環境為Windows10 系統下的Pytorch 深度學習框架。
2)數據集:本文實驗所采用的數據來源于VisDrone無人機圖像目標檢測公開數據集[18]。該數據集包括行人(指具有行走或站立姿勢的人)、人(指具有其他姿勢的人)、汽車、貨車、公共汽車、卡車、摩托車、自行車、遮陽蓬三輪車及三輪車共10 個類別。VisDrone 數據集由288 個視頻剪輯而成,分為1 360×765 和960×540 像素2 種不同的圖像尺寸,總計提供了由不同高度的無人機捕獲的10 209 幅靜態圖像,其中包括6 471 幅訓練集圖像、548 幅驗證集圖像及3 190 幅測試集圖像,共計260 萬個目標實例樣本。
3)評價指標:為評估本文所提算法的有效性,選取模型規模、參數數量及每秒浮點運算次數(Floating Point Operations,FLOPs)來評價模型的復雜程度,選取平均均值精度(mean Average Precision,mAP)作為模型對多個目標類別綜合檢測性能的評價指標,采用平均精度(Average Precision,AP)來評價模型對單個目標類別的檢測性能。
2.2 消融實驗
為了驗證所提的多尺度分割注意力單元MSAU 和自適應加權特征融合AWF 在無人機圖像目標檢測任務中的有效性,本文在VisDrone測試集上進行了一系列的消融實驗,以YOLOv5為基線算法,mAP、模型規模、參數量及浮點運算次數為評價指標,最終結果如表1 所示。

表1 VisDrone 測試集上的消融實驗結果Table 1 Results of ablation experiment on VisDrone test set
消融實驗的結果表明,將提出的多尺度分割注意力單元MSAU 嵌入基線算法的骨干網絡后,算法的模型規模和參數量分別增加了15 MB 和7.53M(1M=106),同時浮點運算次數增加到140.9G(1G=109),取得了34.1%的mAP,檢測精度的提升也從側面反映出了MSAU 捕獲不同尺度特征信息的能力,正是由于其精準高效的挖掘了特征空間在多尺度上的特征信息,因此能在確保模型較小計算復雜度的同時有效提升對無人機航拍圖像目標的檢測效果;進一步的,在基線算法基礎上采用所提的自適應加權特征融合AWF 方法,相比基線算法僅增加了2.21M 的參數量和5.4G 的浮點運算次數,并取得了32.8%的mAP,AWF 在自適應地融合了網絡深層與淺層的豐富語義信息和幾何信息后,能夠較為充分的捕獲無人機圖像目標的特征信息。同時,由于AWF 添加了3 個特征融合層,且每個特征融合層都利用到前面各個特征尺度的輸出特征,給網絡帶來了一定的計算開銷,但相比于基線算法采用Concat 的特征融合操作,加權再相加的特征融合方式可使融合后的特征空間維持在更低的通道數,因此保持了良好的實時性能;與基線算法相比較,本文所提MSA-YOLO 算法的參數量和浮點運算次數分別增加了9.6 M 和31.7 G,模型規模由于參數量的增高而上升到108 MB,mAP 則比基線算法提高了2.8%,達到34.7%。綜上所述,MSA-YOLO 算法在維持較小計算開銷的前提下獲得了更好的檢測性能,可以有效地指導無人機圖像目標檢測任務。
2.3 各算法在VisDrone 測試集上的檢測性能
為證明MSA-YOLO 算法對無人機圖像各類目標檢測的有效性,本文在VisDrone 測試集上與各種先進的無人機圖像目標檢測算法進行對比 分 析,表2[19-24]為 各 算 法 對VisDrone 測 試 集10 類目標的AP 值與mAP 值。從表2 中可以看出,MSA-YOLO 算法與其他先進算法相比取得了最優的綜合性能,比次優的CDNet 高出0.5%的mAP。對于汽車、卡車及公共汽車等目標類別取得了最優的檢測性能,分別達到了76.8%、41.4%及60.9%的AP 值,對于行人、貨車、及摩托車等縱橫比較大且實例個數較少的目標類別則分別達到了33.4%、41.5%及31.0%的較優AP 值,在目標實例個數較少的情況下能夠較為充分的挖掘其特征信息,由此可見本文提出的MSA-YOLO 算法在處理無人機圖像目標檢測任務時具有較大優勢,其檢測效果是十分可觀的。
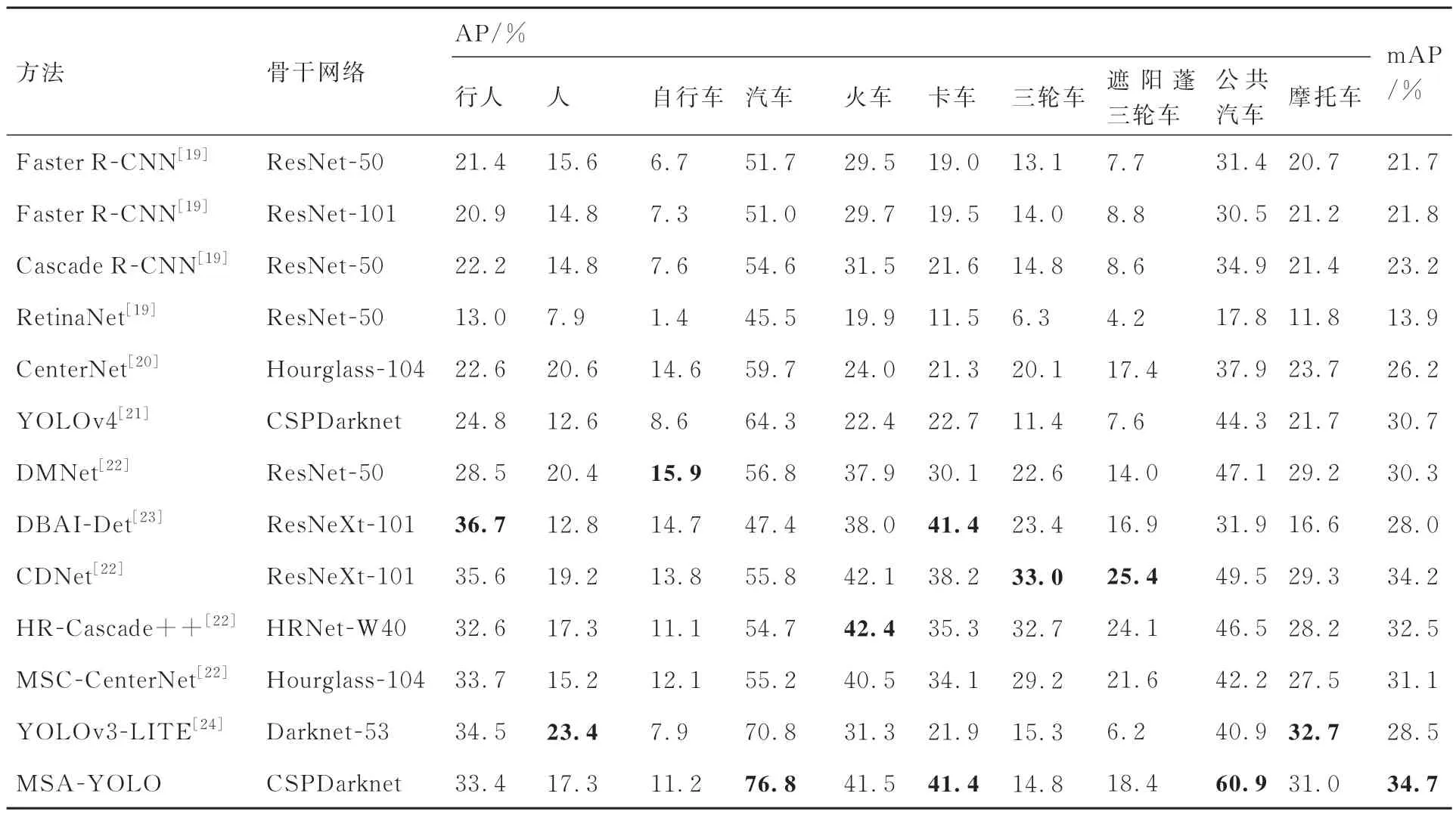
表2 不同算法在VisDrone 測試集上的AP 與mAP 對比Table 2 Comparison of AP and mAP of different algorithms on VisDrone test set
為了驗證MSA-YOLO 算法在實際場景中的檢測效果,選取VisDrone 測試集中實際檢測較為困難的圖像進行測試,部分檢測結果如圖5 所示,可以看出,本文方法對不同拍攝角度下背景復雜且分布密集的無人機圖像展現出了較為優異的檢測性能,能夠有效地抑制圖像背景噪聲信息的干擾,更具選擇性的挖掘有利于無人機圖像目標檢測任務的重要特征信息。為進一步評價基線算法和MSA-YOLO 算法在處理無人機圖像目標檢測任務時的性能差異,本文在VisDrone測試集中隨機選取了小目標樣例圖片進行測試,并可視化對比分析,如圖6 所示。

圖5 MSA-YOLO 在VisDrone 測試集上的部分檢測結果Fig.5 Partial detection results of MSA-YOLO on VisDrone test set
本文分別抽取了晴天和夜間的小目標樣例并對比了2 種算法的檢測結果,可以看出,MSAYOLO 算法有效提升了基線算法對小尺度目標的檢測效果。通過圖6(a)與圖6(b)的對比發現,基線算法錯將站立的行人檢測為人,且存在大量行人目標漏警的情況,而MSA-YOLO 算法則能夠精準的進行識別。對比圖6(c)和圖6(d)可以看出,在夜間低照度的情況下,基線算法受到背景噪聲信息的干擾出現了部分漏警,MSA-YOLO算法則通過弱化噪聲干擾、強化網絡感興趣的多尺度特征,從大量多尺度特征信息中分離出了有利于無人機圖像目標檢測的信息,在面對復雜的背景信息時表現出了較強的抗干擾能力,有效改善了夜間的漏警情況。總體而言,在處理無人機圖像目標檢測任務時,MSA-YOLO 算法相比于基線算法有更明顯的優勢,對于小尺度、背景復雜及排列密集的無人機圖像目標具備更強的辨識能力,有效避免了出現虛警、漏警等現象。

圖6 VisDrone 測試集上的小目標檢測效果對比Fig.6 Comparison of small object detection effect on VisDrone test set
3 結 論
本文提出一種基于多尺度分割注意力的無人機圖像目標檢測算法MSA-YOLO。針對無人機圖像背景復雜混亂的特點,提出了多尺度分割注意力單元MSAU,在多個尺度上沿著空間和通道維度提取無人機圖像目標的關鍵特征信息,同時弱化不相關的背景噪聲信息,有益于提高無人機圖像目標檢測性能。針對無人機圖像小尺度目標實例多,缺乏有效特征信息的問題,提出了自適應加權特征融合AWF 方法,通過自適應學習的方式動態調節各輸入特征層的權重,充分強調淺層細粒度特征信息在特征融合過程中的重要性,有效改善目標檢測器對小目標細節位置信息的感知能力。在VisDrone 數據集上的實驗結果表明,相比于現有的先進無人機圖像目標檢測方法,MSA-YOLO 算法在行人、貨車及摩托車類別上分別取得了第五、第三及第二的檢測效果,而在汽車、卡車及公共汽車這3 種目標類別則上取得了最優的檢測效果,能很好的應對無人機圖像目標檢測任務。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
