基于BERT的長文本分類方法
2023-04-29 15:07:11劉博蒲亦非
四川大學學報(自然科學版) 2023年2期
劉博 蒲亦非


由于預訓練模型輸入分詞數(shù)量限制,基于 BERT 的長文本分類任務效果與長文本分割后的文本段集合的處理及特征融合密切相關(guān),現(xiàn)有的長文本分類研究在融合文本段特征時更關(guān)注文本段之間原始的順序關(guān)系,而本文提出了一種基于 BERT 和集合神經(jīng)網(wǎng)絡的長文本分類模型.該方法以 BERT 為基礎,可處理從同一文本樣本分割得到的任意數(shù)量文本段,經(jīng)過 BERT 后得到文本段特征,再將所有文本段特征輸入到具有置換不變性的集合神經(jīng)網(wǎng)絡層中,提取出集合級別特征來優(yōu)化長文本的特征表達.通過在三個數(shù)據(jù)上的實驗分析,論文在平均分詞長度較長的數(shù)據(jù)集上取得了90.82%的準確率,高出目前最優(yōu)方法4.37%.
文本分類; BERT; 集合神經(jīng)網(wǎng)絡; 長文本
TP391.4A2023.022003
收稿日期: 2022-05-12
基金項目: 國家自然科學基金面上項目(62171303); 中國兵器裝備集團(成都)火控技術(shù)中心項目(非密)(HK20-03); 國家重點研發(fā)項目(2018YFC0830300)
作者簡介: 劉博 (1998-), 女, 四川瀘州人, 碩士研究生, 主要研究領(lǐng)域為自然語言處理. E-mail: liu_bo@stu.scu.edu.cn
通訊作者: 蒲亦非.E-mail: puyifei@scu.edu.cn
BERT-based approach for long document classification
LIU Bo, PU Yi-Fei
(College of Computer Science, Sichuan University, Chengdu 610065, China)
Concerning the input limitation of pre-training model, a long document needs to be spit into a set of text segments. The performance of long document classification is closely related to the further processing of the segment set and feature fusion. Existing document classification models keep more attention on the sequential of segments in the text segment set. However, the athors consider that the sequential order of segments have a mild influence on drawing the feature of a long document. The authors propose a BERT based long document classification model, which utilizes deep sets to obtain the collection-level feature from the segment set. In the model, the authors obtain a set of text segment features after BERT, and this proposed network which is immune to permutation learns the identical feature of the set to represent the long document feature. The accuracy of our model on the 20 newsgroups dataset achieved 90.82%, which outperforms the state-of-the-art method by 4.37%.
Document classification; BERT; Deep Sets; Long Document
1 引 言
文本分類在自然語言處理中是一個經(jīng)典且重要的任務,要求模型能夠從各種文本信息中學習到句子或篇章級特征信息,從而對文本語義、情感和意圖等進行識別分類[1].網(wǎng)絡中存在海量的各類型文本數(shù)據(jù),包括新聞、論文、網(wǎng)頁、演講、對話等, 對文本進行快速識別和分類整理需要大量時間消耗,因此,借助計算機技術(shù)來完成文本快速分類成為了重要的研究方向.
近年來,深度學習的文本分類模型大量涌現(xiàn),比如基于卷積神經(jīng)網(wǎng)絡的 S2Net 模型[2],循環(huán)神經(jīng)網(wǎng)絡(RNN)的 TextCNN 模型[3],基于長短時記憶(LSTM)的 Bi-LSTM 模型[4]和 LT-LSTM 模型[5], 基于膠囊網(wǎng)絡的文本分類模型[6-8]等.上述模型在實現(xiàn)文本分類任務時,對文本長度都比較敏感,往往在處理較短文本時才能取得比較好的效果.RNN和LSTM 等模型著重考慮了句子的詞序信息,但網(wǎng)絡結(jié)構(gòu)決定了它們對內(nèi)存資源消耗極高.不僅如此,RNN 模型還存在梯度消失的問題.2018年谷歌提出了基于雙向Transformer[9]的BERT(Bidirectional Encoder Representations from Transformers)[10] 預訓練模型,由于其優(yōu)秀的基于詞向量的句級特征提取能力,在大量非生成式自然語言處理任務上都有突破性的貢獻.BERT 模型很好地克服了 RNN 和LSTM 模型無法并行計算的缺點,并且由于其內(nèi)部Transformer自注意力模塊的特性,在長距離依賴問題上表現(xiàn)出更好的“記憶”能力.但是 BERT 模型相對復雜,本身參數(shù)規(guī)模較大,模型對輸入句子中包含的分詞個數(shù)進行了限制,想要訓練超過輸入限制詞數(shù)的長文本時只能截取其中一部分內(nèi)容作為輸入.因此相比短句子分類問題,BERT 模型在長文本的分類問題上表現(xiàn)較差.
同時,除文本分類問題以外,自然語言處理的很多方向都有處理長文本的需求和困難[11].大量預處理模型和基于預處理模型改進的長文本分類模型也開始嘗試克服長文本處理的難題[12-15].受到BERT 預處理模型的啟發(fā),卡內(nèi)基梅隆大學聯(lián)合谷歌發(fā)布了 XLNET預處理模型[16],XLNET模型吸取BERT自編碼語言模型雙向信息提取的優(yōu)點, 并改進了需要設置 mask 從損壞的輸入中重建數(shù)據(jù)的缺點,同時將 Transfoermer-XL 的分割循環(huán)機制(Segment Recurrence Mechanism)和相對編碼范式(Relative Encoding)整合到模型中,從而解決超長序列的依賴問題,在處理長文本場景下有天然的優(yōu)勢.雖然 XLNET 模型在處理長文本甚至超長文本問題上,都有比較好的能力,但模型復雜度也遠超于 BERT 模型,模型訓練的硬件設備資源要求非常高,訓練難度較高.因此本文選擇基于 BERT-base 預訓練模型來完成長文本分類任務.
目前主要的基于BERT 的文本分類算法在處理數(shù)據(jù)集中長文本樣本時, 都將 BERT 模型無法處理的長文本分割成多個文本段后再分別輸入BERT,將經(jīng)過 BERT 提取到的所有特征以一定方式融合后投入下游的分類任務網(wǎng)絡中.這些長文本處理模型往往在下游網(wǎng)絡中使用 RNN、LSTM 和 Transformer 等結(jié)構(gòu),分析提取文本段順序中隱含的特征.
由于文字的特殊性,不同文本之間句子結(jié)構(gòu)和段落間關(guān)聯(lián)關(guān)系都不盡相同,例如有的文本中總結(jié)段落在文本開頭,有的文本總結(jié)段落在文本結(jié)尾.因此同一類別中,文本樣本中段落之間的順序關(guān)系對應的深層邏輯關(guān)系并不相同.因此本文認為可以讓模型學習文本段之間的深層邏輯特征.下游網(wǎng)絡輸入應該忽視文本段順序關(guān)系并能接收不同數(shù)量的文本段特征輸入,使模型學習文本段之間的真實邏輯特征.并且大部分長文本的主要信息都凝聚在局部的句子或段落,由文獻[1,10]的實驗結(jié)果可見,使用不超過 BERT 輸入限制的局部文本段學習到的特征信息在文本分類任務中已經(jīng)可以得到較好的結(jié)果.
受到集合神經(jīng)網(wǎng)絡模型[17]的啟發(fā),為學習文本段之間的真實邏輯特征、提取篇章級特征,我們認為可以將長文本的文本段特征集合,用具有置換不變性輸入的集合神經(jīng)網(wǎng)絡來進行處理.
綜上所述,使用預訓練模型完成長文本分類任務時,對分割后文本段的特征信息融合處理尤為重要,以往的算法為了達到較高的準確度犧牲了模型的復雜度,太過簡單的下游網(wǎng)絡又難以學習到較好的分類特征.過去基于 LSTM 和 RNN 等模型的下游處理網(wǎng)絡更關(guān)注與文本段之間的真實順序關(guān)系特征,但由于行文風格等差異,長文本之間順序關(guān)系特征可能不盡相同.同時我們注意到人腦是可以分析亂序文本段落之間的邏輯關(guān)系的,并且人腦在對文章進行分類時,段落之間的時序信息并不會帶來特別大的影響.因此我們猜測,長文本分類任務中,不需要著重對文本段時序信息進行提取.本文提出了一種基于 BERT的新穎且簡單的長文本分類算法,利用集合神經(jīng)網(wǎng)絡層來融合文本段集合的多尺度特征實現(xiàn)分類任務.本文的主要貢獻如下:(1) 提出了一種簡單高效的基于集合神經(jīng)網(wǎng)絡聚合多尺度特征信息進行長文本分類的方法;(2) 網(wǎng)絡可以處理同一文本樣本分割得到的任意多數(shù)量的文本段;(3) 在多個數(shù)據(jù)集中效果達到了 SOTA(State-Of-The-Art)水平,本文模型在參數(shù)量上有優(yōu)勢.
2 相關(guān)工作
長文本分類算法主要分為基于傳統(tǒng)機器學習的文本分類和基于深度學習的文本分類.基于深度學習的長文本分類算法是近年來的研究熱點,本節(jié)將分析領(lǐng)域內(nèi)主要的幾種深度學習模型.
2.1 基于LSTM 的長文本分類模型
LSTM 模型能夠有效對序列信息進行建模,并很好地解決長文本的遠距離依賴問題.大量基于LSTM 模型的變體在長文本分類任務中被提出.為了對樹結(jié)構(gòu)對語義進行建模,樹形結(jié)構(gòu)的 LSTM 模型被提出,不同于標準 LSTM 模型中節(jié)點只能從前一個節(jié)點獲取依賴信息,樹形 LSTM 可以選擇性地從子節(jié)點中獲取信息.Tai 等[18] 提出了兩種 Tree-LSTM 模型,其中依存句法分析樹適用于子節(jié)點個數(shù)不定或子節(jié)點亂序的樹結(jié)構(gòu),成分句法分析書僅適用于在子單元之間有序的情況下,且單元的子單元個數(shù)最多為N.Chen等[19]提出了能夠處理序列級別句子的 LSTM 模型,引入符號間關(guān)系的注意力機制,解決輸入的結(jié)構(gòu)化問題.除此以外,為了對非連續(xù)性短語結(jié)構(gòu)進行建模,Peng等[20]首次將圖卷積神經(jīng)網(wǎng)絡引入長文本分類任務中.
2.2 基于BERT的長文本分類模型
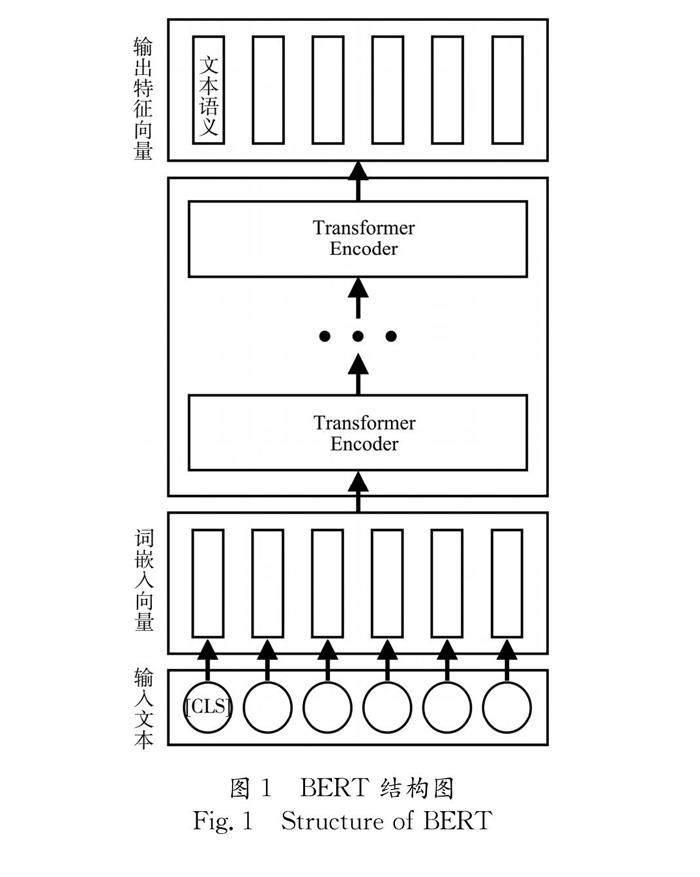
BERT是由Transformer 塊組成的雙向自編碼預訓練語言模型,相較于過去的 RNN、LSTM 語言處理模型,BERT不僅能夠同時利用上下文信息進行并發(fā)訓練,還能解決遠距離依賴問題.BERT 預訓練模型提取文本特征示意圖如圖 1,從目前相關(guān)研究中[1,12,21]我們可以發(fā)現(xiàn),在進行下游任務之前,使用預訓練好的 BERT 模型提取到的句子特征進行簡單的分類任務時就非常有效,即使只用一層全連接層實現(xiàn)分類,也在大部分數(shù)據(jù)集上取得了較好的結(jié)果.
但由于BERT 模型對輸入分詞數(shù)量的限制,在處理長文本分類問題時,必須對文本提前進行分割,再對分割后的文本進行處理.如何分割文本, 以及分割后經(jīng)過BERT得到的所有文本段特征如何融合都是需要認真考慮的問題.目前基于BERT的長文本分類算法對文本的處理方式主要可以被分為以下兩類.一類是直接將文本循環(huán)截斷成文本段,所有文本段通過 BERT 提取到其文本特征,再利用循環(huán)神經(jīng)網(wǎng)絡或長短時記憶網(wǎng)絡等結(jié)構(gòu)作為下游網(wǎng)絡,實現(xiàn)對文本特征按序結(jié)合生成新的總特征.另一類是從文中切割出單個且等于 BERT 輸入限制的文本段代表整篇文章,只對這一個文本段進行特征提取、分析.
2018年,相關(guān)研究者提出的 BERT 模型在文本分類等許多自然語言處理任務上展現(xiàn)出巨大潛力.在此之后基于 BERT 的模型也被大量提出,其中 Adhikari 等[10]提出的 DocBERT 模型通過微調(diào) BERT 以及知識蒸餾實現(xiàn)長文本分類任務.其他一些基于微調(diào) BERT 模型的長文本分類算法,通過將文本序列輸入預訓練好的 BERT 模型,輸出序列級別的文本特征,再在下游任務中進行分類.由于 BERT 模型限制了輸入文本長度,在長文本分類處理上有限制,Pappagari 等[22]提出了將長文本又重復地分割,經(jīng)過 BERT 模型后,下游任務中采用Transformer 來實現(xiàn)分類,Khandve等[23]采用LSTM 在 BERT 下游對文本段信息進行融合,這兩種層級訓練方法高效地將 BERT 擴展到了長文本分類任務上,并取得了比較好的效果.但下游參數(shù)量較多,難以對模型進行加速,同時將文本段原始順序特征作為主要特征進行提取.
2.3 基于集合神經(jīng)網(wǎng)絡的分類方法
Zaheer 等[17]提出了集合神經(jīng)網(wǎng)絡的編碼器-解碼器結(jié)構(gòu),編碼器部分先單獨作用于集合中所有元素,解碼器聚合編碼器輸出的所有元素特征,得到集合級別的特征,常使用池化結(jié)構(gòu)來聚合集合特征,在集合統(tǒng)計量估計和集合異常檢測實驗中取得了比較好的結(jié)果.Zaheer 等也給出了解碼器部分處理樣本為元素集合的函數(shù)規(guī)則,對集合級別特征的提取函數(shù)建模,需要遵循排列不變性,使集合級別特征與輸入樣本集合的排列順序無關(guān),只與輸入樣本集合數(shù)量和特征值有關(guān).為了同時學習到元素之間的交互信息,Lee 等[24]提出了 Set Transformer 模型,在編碼器部分設計了集合注意力模塊(Set attention Block),在集合元素之間執(zhí)行自注意力,輸出元素個數(shù)相同的集合.集合神經(jīng)網(wǎng)絡在集合統(tǒng)計量估計、點云分類、小樣本圖像分類和集合異常檢測等領(lǐng)域都取得了比較好的結(jié)果.因此本文也使用集合神經(jīng)網(wǎng)絡來對文本樣本的所有文本段集合進行處理,利用排列不變性函數(shù)提取出集合級別特征解決長文本分類任務.
3 方 法
3.1 基于 BERT 的長文本分類算法
對文本段的截取以及對各文本段特征的處理,是長文本分類處理任務中的重點.本文提出的算法中,BERT下游采用置換不變性的集合神經(jīng)網(wǎng)絡提取文本段集合級別特征,利用集合級別特征完成長文本分類,并引入ResNet 殘差網(wǎng)絡[25]解決退化問題.目前的算法大多都是對長文本的有序文本段特征進行分析處理,但是即使是同一類別的文本, 由于行文思路和寫作手法的不同,文本的邏輯結(jié)構(gòu)和敘事順序并不具備一致性,文章有序文本段之間的依賴關(guān)系也并不能在分類中其決定性作用.于是本文提出了一種基于 BERT 的長文本分類模型, 如圖2所示,我們將長文本按照BERT可處理的最大長度進行不重疊的分割,經(jīng)過BERT處理后得到文本段特征集合,再對該文本段特征集合進行無序的多尺度集合級別特征提取,最后完成文本分類.
我們將數(shù)據(jù)集中單個長文本X分割為N個文本段,表示為xi,i = 1,2,...,N,將經(jīng)過 BERT模型后得到的文本段特征表示為yi,i = 1,2,...,N,于是構(gòu)建出函數(shù)模型如下.
yi =B(xi)(1)
F(X)=S(R(y1),R(y2),...,R(yN))(2)
其中,B表示 BERT 網(wǎng)絡,輸入長文本樣本分割得到的文本段集合,得到對應的文本段特征集合;R()為殘差結(jié)構(gòu)的全連接網(wǎng)絡,用于獲取不同尺度特征并避免網(wǎng)絡退化;S()依據(jù)置換不變性原理,利用無序文本段特征集合得到集合級別特征.
3.2 殘差網(wǎng)絡提取多尺度特征
為處理任意多的文本段特征,我們采用所有文本段特征提取網(wǎng)絡之間參數(shù)共享的方案.為避免下游分類網(wǎng)絡退化,我們設計殘差網(wǎng)絡結(jié)構(gòu)來提取多尺度文本段特征.文本段特征提取網(wǎng)絡層函數(shù)R為
y=R(y)+W*y(3)
其中,W為轉(zhuǎn)換特征維度的參數(shù)矩陣.
3.3 集合神經(jīng)網(wǎng)絡提取元素集合級別特征
為設計提取集合級別特征的網(wǎng)絡結(jié)構(gòu),我們遵循置換不變性原則,使用最大池化層統(tǒng)計函數(shù),從數(shù)量不定的無序文本段特征集合中提取集合級別特征 ,集合特征提取函數(shù)可表示為
z=S(Y)=γmaxpool(yi|i=1,2,...,N)(4)
其中γ是最大歸一化的系數(shù);maxpool最大池化函數(shù)的提出是為了緩解卷積層對位置的過度敏感性,本質(zhì)是減少特征的同時并保持特征不變性.本文使集合級別特征,maxpool函數(shù)遵循置換不變性的原則,對文本段特征順序不敏感,提取的集合特征具有唯一性,并且可處理任意多數(shù)量多文本段特征.
4 實驗與結(jié)果
4.1 數(shù)據(jù)集
本論文使用三個文本數(shù)據(jù)集來評估我們的模型,分別是20 NG(20 newsgroups)數(shù)據(jù)集[26],IMDB數(shù)據(jù)集[27]以及R8數(shù)據(jù)集.
其中20 NG 數(shù)據(jù)集[26] 總共包含約 19 000 篇新聞,由20個不同類別的新聞文本組成,包括了一些相關(guān)主題,如“comp.sys.mac.hardware”和“comp.sys.ibm.pc. hardware”, 也包括一些完全無關(guān)的類別,如“sci.electronics”和“talk.politics.misc”等.其中文本的平均長度為 266 個詞,最長長度為10 334個詞.本文按照6∶4的比例將數(shù)據(jù)集分為訓練集和測試集.
IMDB數(shù)據(jù)集[27]包含50 000篇電影評論,分為正向和負向兩種情感傾向,平均長度為231個詞,最長長度.我們按照 1∶1 的比例將數(shù)據(jù)集分為訓練集和測試集.
R8 數(shù)據(jù)集包含了7 674 篇路透社的文章,分為8種不同的類別,平均長度為 64 個詞,我們按照7∶3的比例將數(shù)據(jù)集分為訓練集和測試集.
4.2 分組實驗
本文提出的長文本分類模型是在BERT 模型的基礎上,使用 BERT 模型輸出的文本段特征,在下游網(wǎng)絡中提取文本段集合級別特征并完成分類任務.由于數(shù)據(jù)集中存在大量樣本的文本長度比BERT-base 能夠處理的輸入單詞數(shù)量更長,于是進行無覆蓋的分割,得到長文本的文本段集合,再對經(jīng)過 BERT 輸出的文本段特征集合進行融合,完成分類任務.
本文所有實驗都使用單張NVIDIA GeForce RTX-3090,預訓練模型使用轉(zhuǎn)換到 Pytorch 框架下的 BERT-base 模型,該模型輸入限制為 512 個分詞,包含 12 層 Transformer 編碼器結(jié)構(gòu)塊,輸出文本段特征維度為 768.同時,在訓練過程中同時對 BERT 預訓練模型進行微調(diào),并使用了交叉熵損失函數(shù),具體參數(shù)取值見表1.
4.3 實驗結(jié)果與分析
本文方法與其他方法模型參數(shù)量對比如表2所示.本文提出算法是基于BERT-base模型,相較于其他一些基于BERT-base的算法,本文算法只增加了0.2 M的參數(shù)量.
本部分的其他算法模型準確率都來自于提出型的原論文中在同一數(shù)據(jù)集上的最好結(jié)果.我們將本文模型與其他表現(xiàn)SOTA水平的模型進行比較,BERT作為分類任務的基線,LongFormer是專為長文本處理提出的模型,SGC(Simple Graph Convolution)是簡單圖卷積神經(jīng)網(wǎng)絡模型.如表3所示,通過對比本模型與其他幾種不同模型在數(shù)據(jù)集上的準確率,我們可以看出,本文提出的算法模型在三個數(shù)據(jù)集上都表現(xiàn)出了SOTA水平,其中在20NG數(shù)據(jù)集上,遠遠超過了其他幾種模型的分類準確率,將準確率提升了.除此以外,在IMDB數(shù)據(jù)集上,效果也略好于其他四個模型,在R8數(shù)據(jù)集上,與其他模型效果相當.這些模型都著重提取了輸入順序帶來的時間順序特征,即原始長文本的文本段順序特征.而本文采用具有置換不變性的集合神經(jīng)網(wǎng)絡作為BERT下游網(wǎng)絡,來對長文本集合級別特征進行提取,并且取得的效果優(yōu)于目前主要的幾種長文本分類算法.因此在訓練時,不需要著重去提取文本段之間的順序特征,也可以在長文本分類任務中取得比較好的效果.
同時,為了驗證模型的有效性,我們在20NG數(shù)據(jù)集上對模型的收斂性進行測驗.如圖3 損失曲線圖,我們可以看出,在總共20 輪次的迭代輪次-損失的曲線圖中,模型訓練迭代輪次為 10 時, 模型損失已經(jīng)降低到較低水平,模型基本收斂.但是在第13 輪時突然產(chǎn)生損失小幅度增加的情況,同時在19 輪也有一定的損失小幅度增加,我們認為這是因為數(shù)據(jù)集比較小從而產(chǎn)生了一定的過擬合,但是整體的損失都維持在比較合理的變化范圍內(nèi).
4.4 消融實驗
為了更好地分析本文提出的模型中集合特征提取模塊的效果,我們設計了一組消融實驗,實驗采用 20NG 數(shù)據(jù)集,如表4所示.
表4中,前兩列對比了不同文本樣本的表示方法對準確率的影響,可以看出如果只從文本中提取單個512個分詞的文本段來代表這個樣本,效果比使用樣本的文本段集合要差很多.第三、四列比較了提取集合級別特征時,采用兩種不同的置換不變的池化函數(shù)產(chǎn)生的不同效果.由表4可見,在其他條件同等時,最大池化與平均池化效果相當.第五、六列比較了提取集合級別特征的區(qū)別,在不同網(wǎng)絡層提取多尺度的集合級別特征,比僅僅使用最后一層單尺度集合級別特征來進行分類任務效果更好.
由表4可見,沒有下游網(wǎng)絡處理的簡單BERT-base 模型在實現(xiàn)分類任務時,也能有一定的效果, 在 BERT模型下提取單尺度的集合級別特征用于分類,模型的準確度有一定提高,說明在長文本分類任務中,截斷的文本段之間的位置關(guān)系特征對集合級別特征提取并沒有那么重要,使用簡單的置換不變池化函數(shù)就可以得到比較有效的集合級別特征[30-32].不僅如此,在加入了多尺度集合級別特征提取模塊后,模型的分類準確度有了較大的提升,可以說明多尺度文本段集合級別特征信息有利于長文本分類.
5 結(jié) 論
本文提出了一種基于BERT 的長文本分類方法,通過將長文本分割后的所有文本段輸入 BERT 得到文本段特征集合,再使用置換不變的函數(shù)提取多尺度集合級別特征用于分類任務,減少了模型參數(shù)量.本方法可以對文本樣本分割得到的任意數(shù)量文本段進行特征融合.從實驗結(jié)果可見,本文模型在長文本數(shù)據(jù)集中取得了非常好的效果,表明引入集合神經(jīng)網(wǎng)絡結(jié)構(gòu)提取到的集合級別特征,極大地改善了長文本分類任務.下一階段,我們考慮拓展并檢驗本模型的分類能力,將本文模型應用到多標簽分類問題上.
參考文獻:
[1] Minaee S, Kalchbrenner N, Cambria E, et al. Deep learning-based text classification: a comprehensive review [J]. ACM Comput Surv, 2021, 54: 1.
[2] He H, Gimpel K, Lin J. Multi-perspective sentence similarity modeling with convolutional neural networks [C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: ACL, 2015.
[3] Chen Y. Convolutional neural network for sentence classification [D]. Waterloo: University of Waterloo, 2015.
[4] Liu P, Qiu X, Chen X, et al. Multi-timescale long short- term memory neural network for modelling sentences and documents[C]// Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Lisbon: ACL, 2015.
[5] ZhouP, Qi Z, Zheng S, et al. Text classification improved by integrating bidirectional lstm with two-dimensional maxpooling [C]//Proceedings of the 26th International Conference on Computational Linguistics.[S.l.]: Technical Papers, 2016.
[6] 朱海景, 余諒, 盛鐘松, 等. 基于靜態(tài)路由分組膠囊網(wǎng)絡的文本分類模型[J]. 四川大學學報: 自然科學版, 2021, 58: 062001.
[7] 高云龍, 吳川, 朱明. 基于改進卷積神經(jīng)網(wǎng)絡的短文本分類模型[J]. 吉林大學學報: 理學版, 2020, 58: 923.
[8] 王進, 徐巍, 丁一, 等. 基于圖嵌入和區(qū)域注意力的多標簽文本分類[J]. 江蘇大學學報:自然科學版, 2022, 43: 310.
[9] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [J]. Adv Neural Inf Process Syst, 2017, 30.
[10] Devlin J, Chang M, Lee K, et al. BERT: pretraining of deep bidirectional transformers for language understanding [EB/OL]. [2022-02-23].http://arxiv.org/abs/1810.04805.
[11] Kowsari K, Jafari K, Heidarysafa M, et al. Text classification algorithms: a survey [J]. Information, 2019, 10: 150.
[12] Adhikari A, Ram A,Tang R, et al. Docbert: bert for document classification [EB/OL]. [2022-02-23].http://arxiv.org/abs/1904.08398.
[13] Liu Y, Ott M, Goyal N, et al. Roberta:? a robustly optimized bert pretraining approach [EB/OL]. [2022-02-23].http://arxiv.org/abs/1907.11692.
[14] Beltagy I, Peters M E, Cohan A. Long-former: the long-document transformer [EB/OL].[2022-02-23].http://arxiv.org/abs/2004.05150.
[15] Ding S, Shang J, Wang S, et al. Ernie-doc: a retrospec-tive long-document modeling transformer[EB/OL].[2022-02-23]. http://arxiv.org/abs/2012.15.
[16] Yang Z, Dai Z, Yang Y, et al. XLNet: generalized autoregressive pretraining for language understanding [C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver: Neurlps, 2019.
[17] Zaheer M, Kottur S, Ravanbakhsh S, et al. Deep sets [J]. Adv Neural Inf Process Syst, 2017, 30: 3391.
[18] Tai K S, Socher R, Manning C D. Improved semantic representations from tree-structured long short-term memory networks[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. [S.l: S.n.], 2015.
[19] Cheng J, Dong L, Lapata M. Long short-term memory-networks for machine reading[C]// Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. [S.l]: EMNLP, 2016.
[20] Peng H, Li J, He Y, et al. Large-scale hierarchical text classification with recursively regularized deep graph-cnn[C]// Proceedings of the 2018 World Wide Web Conference. [S.l: S.n.], 2018.
[21] Adhikari A, Ram A,Tang R, et al. Exploring the limits of simple learners in knowledge distillation for document clas- sification with docbert [C]//Proceedings of the 5th Workshop on Representation Learning for NLP. Seattle: ACL, 2020.
[22] Pappagari R, Zelasko P, Villalba J, et al. Hi-erarchical transformers for long document classification[C]//Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). [S.l.]: IEEE, 2019.
[23] Khandve S,Wagh V, Wani A, et al. Hierarchical neural network approaches for long document classification [C]//Proceedings of the 2022 14th International Conference on Machine Learning and Computing (ICMLC). Guangzhou: ICML, 2022.
[24] Lee J, Lee Y, Kim J, et al. Set transformer: a framework for attention-based permutation-invariant neural networks[C]//Proceedings of the International Conference on Machine Learning. Edinburgh: Opnnipress, 2019.
[25] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. San Juan: IEEE, 2016.
[26] Pedregosa F, Varoquaux G, Gramfort A, et al.Scikit-learn: Machine learning in python[J]. J Mach Learn Resh, 2011, 12: 2825.
[27] Maas A, Daly R E, Pham P T, et al. Learning word vectors for sentiment analysis[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies. [S.l: S.n.], 2011.
[28] Sanh V, Debut L, Chaumond J, et al. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter [EB/OL]. [2022-02-23]. http://arxiv.org/abs/1910.01108.
[29] Wu F, Souza A, Zhang T, et al. Simplifying graph con-volutional networks [C]//Proceedings of the International Conference on Machine Learning. Long Beach: PMLR, 2019.
[30] Adhikari A, Ram A,Tang R, et al. Rethinking com-plex neural network architectures for document classification [C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers).? Minneapolis: ACL, 2019.
[31] Wagh V, Khandve S, Joshi I, et al. Comparative study of long document classification[C]//TENCON 2021-2021 IEEE Region 10 Conference (TENCON). Auckland: IEEE, 2021.
[32] Liu L, Liu K, Cong Z, et al. Long length document classification by local convolutional feature aggregation [J]. Algorithms, 2018, 11: 109.
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
