司法智能裁量系統:問題、措施及趨勢
2023-04-29 21:14:22張妮蒲亦非
四川大學學報(自然科學版) 2023年2期
張妮 蒲亦非
法學與智能技術的深度結合應用于司法審判領域,可輔助司法糾錯、優化決策、預警法律風險等,能夠讓司法實踐提質增效,但在技術中立偽裝下也可能帶來司法偏見、失控與誤導.本文首先論述了司法信息提取中的問題,提出通過增加法律文書說理部分和規范法律文本結構等提高司法信息有效性的具體措施.其次,提出司法裁量模型中應加入價值觀念,并討論了建立價值審核和監督機制與促進算法可解釋性的具體路徑,通過建立內外部監督機制,讓司法智能裁量模型使用的背景、整體的價值觀以及采用的規則可被法律人理解,才能讓其真正服務于司法實踐.最后,針對當前司法智能裁量系統建立的難點即類案推薦,分析了類案判定的困境,并在比較法律專家系統與基于當前智能技術的計算模型利弊的基礎上,指出人機協作建立具有綜合分析能力的認知系統是司法智能裁量系統的發展方向.
人工智能; 認知計算; 法律專家系統; 計算法學; 司法歧視
D90A2023.027002
收稿日期: 2022-11-21
基金項目: 國家社會科學基金(21BFX031)
作者簡介: 張妮(1977- ), 女, 博士, 副研究館員, 研究方向為人工智能與法律的交叉.E-mail: zhang_ni@scu.edu.cn
通訊作者: 蒲亦非.E-mail: puyifei@scu.edu.cn
Judicial intelligent system: problems, measures and tendency
ZHANG Ni1, PU Yi-Fei 2
(1.Library of Sichuan University, Chengdu 610065, China; 2.Colledge of Computer Science(College of Software), Sichuan University, Chengdu 610065, China)
Legal system is a complex adaptive system, the deeply combination of law and intelligent technology can be applied in judicial justice, which can assist judicial error correction, make optimal decision, trigger erarly legal risks warning, etc., and can improve the quality and efficiency of judicial practice. But we also should pay more attention on the bias, loss of control and misdirection brought by technology to the legal field under the guise of technology neutrality. This paper firstly discusses the problems in the extraction of judicial information and puts forward some concrete measures to improve the effectiveness of semantic processing by adding the legal document reasoning part and standardizing the structure of legal text. Secondly, it proposes to add values into the judicial discretion model, and discusses the specific paths to establish a value review and supervision mechanism by expert group and promotes the interpretability of the algorithm. By establishing an internal and external supervision mechanism, only when the background, overall values and adopted rules of judicial intelligent system are understood by legal people, it can be truly served the legal system. Finally, as for the similarity case recommendation, the most tackling challenge in establishing judicial intelligent system, it analyzes the difficulties in the judgment of similarity cases. By comparing the advantages and disadvantages of legal experts and the data-centric computing systems based on present artificial intelligent technology, it then points out that the man-machine cooperative cognitive system with comprehensive analysis ability will be the development tendency of the judicial intelligent system.
Artificial intelligence;? Cognitive computing; Legal expert systems; Computational law; Judicial discrimination
1 引 言
人工智能模擬、延伸和擴展了人類的智力,通過專業領域大數據學習,建立司法裁判智能系統可為司法決策和行動提供支撐.實時、在線、網絡化的計算社會科學研究發展的同時,以數據為中心的新技術高速發展為分析與解決法律問題打開了大門,法學與信息科學的深入融合,促使了新興交叉學科——計算法學[1,2]的產生.法學是一門社會科學[3],具有高度反饋性,法律制度的產生、變遷看似是包含很多偶然因素的主觀選擇,但法律制度背后的東西卻很難改變.從系統論的觀點[4],法律系統可被看成是一個復雜體系,該系統由法官、檢察官、律師和立法人員等組成,在法律法規和規章制度的指導下通過立法、裁判以及調解等方式運行該系統.在此過程中通過諸如上訴、再審、立法評估等一系列司法反饋活動,使得系統不斷調試并趨于穩定.人工智能應用于法學領域加速了法律信息的公開與反饋[5],有助于發現好的司法策略、預測司法判決和預警法律風險,幫助法官糾正司法實踐中的錯誤.通過探究智能系統運行過程和揭示異象原因,反過來將促進立法的科學性,完善法學理論,發現法律成長的規律.
智能技術應用司法審判領域,正深刻地影響和改變著司法審判[6].法律翻譯軟件、法律文書自動生成系統、在線糾紛處理系統等提高了司法效率,以庭審為中心的智慧法院建設在法庭語音轉錄、光學字符識別、文書糾錯、文書生成等方面取得了長足進步.最高人民法院2018年推出了“類案智能推送系統”, 2019年上海推出了公檢法司四機構統一辦案平臺——“206智能刑事辦案”系統,北京推出了“睿法官”,法信、北大法寶、無訟、聚法案例等法律科技公司也在推出了一系列類案推送系統[7],然而,關鍵字和貼標簽的方法在實際運行中成效并不顯著.當前我國尚未形成統一的司法數據標準,各檢索平臺使用的數據庫、算法和分析技術存在差異,案例相似性判定標準也不確定 [8],案例推送精準度有待提高[9].同時存在過度依賴人工干預、識別準確率低、算法非可視化、顆粒度悖論等客觀技術瓶頸[10],法官不得不花費大量的時間和精力進行相似案例的閱讀和甄別.簡言之,目前仍處于“人工有余而智能不足”階段.建立具有綜合分析和預測能力的復雜系統司法智能系統是未來的發展方向.
人們探討法律與科學、技術的深度融合,也要意識到計算模型的脆弱性和難以檢測性,更要關注技術對法律領域帶來的偏見、失控與誤導,應當從司法信息的獲取到司法智能裁量模型運行使用的全過程,構建風險防范措施和運行保障制度.首先,法律信息如何轉換為可計算的法律信息,怎樣提高司法信息的有效性;其次,智能技術在法律信息處理中扮演怎樣的角色,如何在司法裁量模型中融入價值判斷;如何對司法智能裁量系統進行合理的監督與審核;最后,類案的判定是司法智能裁量模型建立的難點,如何確定案例的相似性.
2 讓數據說話:可計算的法律信息
大數據分析將數學算法應用在海量數據上,從而洞察并預測事件的發生.司法智能模型通過編碼、解碼的過程,考察法律人對法律法規和司法案例的解釋過程,讓審判規則有跡可循,從龐大的司法語料庫中發現其主張的社會價值,找到更好的司法智慧.
2.1 計算思維在法學的應用
計算思維是進行問題求解、系統設計等一系列思維活動,利用啟發式的推理來尋求解答,采用各種搜索策略來解決實際問題[11].計算思維與人們的工作和生活息息相關,已經成為人們必備的一種生存能力,計算思維奠定了法律知識計算的思想基礎.
計算思維采用抽象和分解來設計龐大復雜的系統,通過分解、模式識別、抽象化和算法等4個步驟進行知識計算,解決各種背景和學科中真實和重要問題.受技術因素影響,律師的工作由量身定制、標準化服務轉到知識模塊化外包服務,各項法律任務被拆解,譬如訴訟律師的工作分解為文件審閱、法律研究、項目管理、訴訟支持、電子披露、策略、戰術、談判和法庭辯論等.這類以抽象、算法和規模為特征解決問題的思維方式使得法律事務代碼化成為可能[12],智能合約以計算的方式呈現法律關系,司法智能裁量模型通過對某類案例特征的提取,基于法律規則和過往案例的邏輯推理,繼而計算獲取相似案例及其排序,實現司法預測.
2.2 司法信息提取中的問題
司法信息是與法有關的信息和知識的總和,不僅包括法律法規、司法案例、司法程序、規范性文件、法律學者研究著作等靜態規范性文件,也包括了法庭辯論、庭審記錄、案件評論等動態信息.司法數據可對案件的數量、分布、審理情況、息訴服判情況、當事人特征等基本情況進行實時分析,還可為類案多元糾紛化解機制的構建提供決策依據.當前司法信息提取存在的主要問題集中在以下幾方面.
(1) 司法信息包含大量多源異構的半結構化、非結構化數據.司法信息包含來自司法機關網站、人民法院和人民檢察院公報、司法工作年度報告、新聞發布會、報刊、廣播 、電視等新聞媒體資源,涵蓋法律法規等規范性法律文件和過往案例相關的信息.這類信息來源廣泛、效力不一、結構不規范,不易提取.加之,信息以圖片、文字、視頻等多種表現形式,文字、圖片、音視頻轉換也可能造成數據丟失.
(2) 人工智能輔助裁量系統的司法案例信息來源不充分,多集中于案卷信息,無法全面真實地再現案例的全貌.不少司法審判書即便讓具有豐富經驗的法官也很難從中直接獲取其他法官的審理思路,更別說讓機器通過學習而獲得.法官裁量過程圍繞客觀事實與法律事實、規范語義內涵、法規背后利益等爭議和沖突展開.裁判是包含了價值選擇的博弈過程,而司法裁判文書僅僅是文字表現的最終審理結果.裁判文書數據特征隱藏較深,對司法裁判論證過程描述不清,直接影響法律模型結果的實用性[13].
(3) 司法案例結構不清、分級不明確、缺乏必要的清理,法官需要花大量的時間來甄別案件是否具有可參照性.以中國裁判文書網為基礎數據庫,而裁判文書網上的案例看似龐大,但案件信息質量堪憂.因隱私、保密等原因,公布的案例有限,且地域化信息較強,東部地區公布的案例明顯多于西部地區的相關案例,甚至公布案例中還包含部分信息錯誤或不規范.人工智能推薦案例軟件大多并未區分案例的等級.僅北大法寶規定了案例的“參照級別”,分成指導性案例、經典案例、一般案例等.一般來說裁判者多傾向于檢索本院及所屬上級法院的生效判決[14].有些案件信息隨時間推移、國家政策、價值觀等變化而失去參考意義,也有案例包含種族和性別歧視信息、政策信息等.這些信息無法與時俱進,適應新形式的需求.以此為基礎將造成新的判決的不公,需要法官對信息進行甄別和排除.
2.3 對提高司法信息有效性的思考
司法信息是建立司法裁量系統的基礎.司法信息來源的全面性、真實性和客觀性決定司法裁量系統的優劣.為了提高系統的可靠性和精確度,需要提高司法信息的有效性.
首先,司法數據的結構化.機器學習對于輸入的數據有著較高格式化的要求,統一判決書的輸入結構對于智能系統的處理結果具有至關重要的作用.案件信息結構化應秉持準確描述案件事實和過程、涵蓋案件事實的復雜性與完整性的原則.從裁判文書來看,雖然文書包括案由、原告訴稱、被告辯稱、本院查明、本院認為等格式化的詞語,但很難從司法文書中發現法官的判案思路.建議根據類案的特點,對司法裁判文書的爭議焦點、事實認定以及法律適用等進行結構化的處理.目前法院以及各法律信息檢索公司的結構化法院判決書的做法可以分為幾類:(1)? 增加案件概述:專業人員用簡短的話概括案件的基本情況,對案件內容和內在的主題的精簡;(2) 增加案件爭議焦點:專業人員對控辯雙方的主要分歧進行人工梳理;(3) 案件進行要素化處理:將某類案件的信息轉化為要素填充;(4) 類案特征的總結:分為支持控方的因素和支持辯方的因素.與指導案例類似,增加案例概述有利于提煉出案例的啟示,便于其他案例的引用.司法判決書的“法院認定”事實部分是法官認定后的結論,但法庭辯論更能尋求事實的真相.案例爭議焦點可對案件的庭審過程進行還原.司法判決書的結構化處理有利于案件信息的提取,建議增加案例概述、案例爭議焦點、要素提取(法律關系與處理結果較明確的案件)、根據類案特征進行案例重述.只有增加裁判文書的說理部分,完善案件事實認定、爭議焦點提取和法律推理論證[15],裁判文書案件事實描述應當詳實,法條適用應當明確,要將判決的理由說清說透,實現“說得出的正義”[16].
其次,建立完善的司法程序,嚴格管理司法信息的存儲、傳遞、清洗等全過程,采用數字加密、區塊鏈技術等保障司法信息流轉中的可靠性與全面性,避免信息被篡改.根據2018年司法部的《“數字法治、智慧司法”信息化體系建設指導意見》[17],分別建網承載涉密和非涉密業務信息,按照安全自主可控要求,構建高標準的安全防護體系, 筑牢平臺建設和網絡安全防線,確保網絡和數據安全.值得注意,司法信息公開應注意保護訴訟參與人的隱私權和個人信息,平衡公眾知情權和隱私權、個人信息權益[18].如果即將公開的司法信息將促進公共利益,則需要在隱私權與公益促進法益之間進行利益衡量,從而決定司法信息公開的時間、方式、程度和內容[19].
最后,拓寬司法信息來源.我國司法判決形成過程中的部分關鍵信息并未在裁判文書中完全獲取,如事實確定過程、法官判決后所撰寫的審判報告、以及一些酌定情節及其理由.建議將更多的案件信息如起訴書、庭審過程、法律論辯、證據確定等案件材料作為類案檢索的基礎數據來源,便于更好地尋找法官司法裁判的邏輯思路與判案技巧.
通過類案裁判文書的規范化,增加說理部分,并將歷史案件的裁判邏輯進行圖譜化歸納,法官根據裁判要點,才能真正快速發現所需解決疑難案件的解題思路,提高智能裁判系統的精準檢索率,找到其期望的“類案”.
3 核心:司法裁量模型中的價值判斷
法律具有特定的價值:正義、強力、安全、均衡,主體的平等權利尤為重要[20],司法本質是通過價值判斷的裁判權,法律推理過程通過法律論證實現依法裁判追求個案正義[21].當前許多智能系統往往無法應對法律推理中的價值評判與利益衡量問題,忽視了法律推理的多元化、立體化形態.
3.1 司法裁量模型應加入價值觀念
龐德認為法律秩序的實際過程,是用經驗(反復試驗和司法上的取舍)和理性(法學家指定的各種假設)去發現有助于調整各種沖突或重疊利益的東西[22].法官并不是在形式數學意義上適用法律的“自動售貨機”,其適用和解釋法律規范的過程需要價值判斷[23].法律事實的認定過程、法規的選擇、裁量的輕重等都與法官密切相關,法官的價值、觀念和態度對于他們在法庭上的推理和判決有著重要的決定性作用[22].法官根據社會經驗以及道德、正義等觀念的理解,有比較明確的價值觀念.譬如,明代官員海瑞在出現疑難訴訟時確定了“與其屈兄,寧屈其弟;與其屈叔伯,寧屈其侄……”的辦案原則[24].
司法裁量系統是數據驅動的系統,通過輸入→特定任務的學習→自動決策的方式,進行司法預測.建立司法裁量模型,系統開發人員對數據的選擇、數據分析和數據呈現等決定了系統如何運行.以技術外殼,看起來價值無涉,但價值優先權的內置,作為技術應用的副產品,能夠強化社會某些價值觀念.如果“喂入”系統的數據本身就帶有歧視信息,這類信息的輸入反過來又會進一步加劇歧視與不公平.目前美國的一些人工智能輔助司法的系統諸如Hunch Lab、COMPAS等飽受質疑,黑人成為警察監控的重點,被錯誤判斷為“有罪”的概率明顯高于白人[25].
司法案例或法律文本中隱含了立法者或法官的價值,反映了相互沖突的價值和因素之間的偏好規則.司法裁量模型有利于發現法官群體價值走向,更好地保障公民的人權,彰顯公平正義.人工智能與法律研究者早就意識到這個問題.Ashley等[24]具體分析了考慮價值的司法裁判模型中價值如何影響司法事實的認定.HYPO知識產權預測模型中,隱藏的價值是應制定和實施明確的保密協議以及允許某人使用合法手段開發產品,其價值排序:保密協議優于合法手段,合法手段優于合法努力[26].價值選擇貫穿了整個司法裁量模型的始終,事實上價值對事實認定和裁量結果起到了決定性的作用,智能系統中加入司法的價值考量是發展的必然趨勢.
首先,司法論證本質上是圍繞法律事實和價值展開,如何將傳統法學研究的價值觀念融入司法裁量模型是司法裁量模型構建的核心問題.大多司法情形可事先假定,人類有一套價值觀和可接受的價值排序,基于價值的論證方案,讓智能主體能夠基于價值偏好進行選擇[27].一些現行探索者提出建立司法裁量模型中強調了系統預測依賴于背景、價值和規則[28].簡言之,構建司法裁量模型時將智能主體置于具體推理場景中,通過控辯雙方的論證確定法律事實,依據法律法規以及人們的價值觀進行事先預設.
其次,構建司法裁量系統時應將價值選擇權交由使用者,防止技術人員越廚代庖,事先進行價值植入.算法殺熟、信息繭房[29]是以技術為外包裝的對主體平等權利的侵害,建立司法智能裁量模型加入價值預設時應防止技術人員或智能輔助系統提供人員的價值強制植入.司法智能裁量模型設計過程中的決策與價值偏好密切相關.表面上看技術人員采用價值中立的立場,實際上技術人員的價值觀在使用技術時已悄悄植入.技術設計的選擇提升特定價值,促進社會潛規則,更為重要的這種價值植入并非有意,而是以技術、效率或功能為名的設計方案的副產品[30].因此,技術人員算法編寫不應只考慮技術最優,而應更多關注司法適用對人的尊重[31],更多地盡到告知義務,將價值選擇權交由系統的使用者決定.
最后,司法裁量模型的價值觀念也許并非單個主體而是多個主體觀念的綜合.司法裁判與醫生的診斷類似,當判決結果不確定時,可以讓更多的法官和利益相關人“會診”,通過論證博弈的方式,找尋雙方都能接受的裁判方式.(1) 司法裁判是多種價值交織在一起,做出價值排序是一件艱難的事.不同法官對同一案例,因為法官在追求準確地認定事實和適用法律之外,也追求其他諸多目標.例如社會效果、領導或公眾的認可、晉升調薪、及時結案等[32].價值選擇沖突最為突出的是自動駕駛汽車的事故引發的道德和法律困境.自動駕駛過程中若無法避免撞到行人,那么自動駕駛車是撞向一個人還是一群人,是撞老人還是孩子?(2) 價值的判斷主體并非個人,而是多個主體在不同階段做出的價值判斷的綜合.無人駕駛車將犧牲誰的利益這個選擇權的設定尤其關鍵.如果價值預設是生產者,則生產者富有不可推卸的“殺人”責任.如果將這倫理難題交給使用者或乘客,由他們的價值倫理觀念決定了自動汽車危及時的處置方法[33],可以幫助他們選擇更有利的處置方式.(3) 建立司法裁量模型時將價值觀念融入司法案例的法律推理的實際場景中.價值觀念并不是指抽象的價值排序,而是在具體的事實場景中分析司法結果對價值觀念的影響.例如,彭宇做好事被誣陷案中,雖然法官按照法律的推理沒錯,但其產生的后果會對傳統的價值觀念產生巨大的沖擊.法律推理并非是一一對應的單調推理,而是依賴語境,具有容錯性和不確定性的非單調推理[34].Bench-Capon構建了法律事實與法律價值相互影響的理論模型,價值優先性決定了可廢止規則的優先性[35].
3.2 智能系統的價值審核和監督機制
大數據殺熟、算法歧視讓人們更清醒地認識到數據的偽裝性,更關注結論的正義性與可用性,迫切地需要建立包括數據傳導、偏離預警、系統自控、系統有效性評估、專業人員監管等機制,讓法官、律師和法律學者可以評估模型的合理性.將智能系統用到司法領域,則應尤其慎重,其傷害的是人們對法治的信仰.法律人需要對司法裁量模型使用的背景、整體的價值觀以及采用的規則進行審核.注重通過持續的審查與檢驗確保其有效更新,使算法決策減少偏見和無意識歧視的影響,以保障其符合司法價值的內涵[36].
首先,司法智能裁量系統應引入監管與評估機制,建立事前審核和事后監督機制.《中華人民共和國電子商務法》和《中華人民共和國網絡安全法》中規定了與算法相關的條款,應從事前規制、事中監測、事后救濟和追責三個方面將智能算法納入到監管之中.有些司法數據來源本身不合規范,且侵犯了個人的隱私權或信息有誤.2022年5月18日我國第一家數據資源法庭溫州市甌海區人民法院正式掛牌成立[37],用于解決數據生產、儲存、使用、交易等各環節中的違法行為.數據資源使用前需要明確數據來源、使用規則、排除標準、司法裁量要素選擇原則、權重系數的選取方式、價值沖突處理原則等,便于法律人理性地審視司法裁量模型的公平性與合理性.司法裁量系統事前審核程序是其獲得實際應用的前提,必須經過審核、整改才能投入使用,同時在智能系統使用過程中進行監督.
其次,司法智能裁量模型的應用,應由相關審核部門引入算法影響評估和告知義務,對其內容進行全方位的評估[38].當智能系統運行與法官的判斷有較大偏差時,審核人員要叫停系統,并讓系統設計者對其進行修正和重新評估.法律人作為社會公平運行的監督員,應當做好“守門員”角色.當法官發現有歧視行為時,應對相關案例進行標注和說明,對以后的引用產生影響,且要由審核人員進行甄別和修正.審核和監督的程序可以嵌入司法智能系統中.與車輛提示駕駛員除非先通過自帶的吹氣酒精測試,否則車輛不打火的程序相類似[12],沒有經過審核和消歧的系統不能自動給出預測結果.簡言之,通過算法審核抑制代碼歧視風險,并建立非歧視準則規范人工智能開發、利用行為[39].
第三,建立外部算法問責制度,明確算法設計者、算法使用平臺和算法審核或監督人的法律責任.司法智能裁量系統涉及軟件開發者、設計者、使用者、監督機構等幾方主體.他們在智能系統設計和使用的不同階段應當進行責任分擔,明確界定追責與免責之邊界[40].2021年4月21日歐洲委員會通過了“人工智能法案”,該法案指出人工智能系統提供者負有使用前的評估和投入市場之后的監控責任[41].在系統的開發階段,智能系統的責任主體在企業,企業設置內部監督機制,同時需要監督人員的嵌入或事前評估.運營階段用戶是責任主體,仍需要開發企業的回訪與監督機構的事后評價,通過多維度對智能系統內部構成和外在關聯進行系統性審視[42].2022年12月最高人民法院《關于規范和加強人工智能司法應用的意見》“透明可信原則”強調:保障人工智能系統可解釋、可測試、可驗證的方式接受相關責任主體的審查、評估和備案[43].通過合理分配人工智能軟件的技術人員、軟件的開發商、軟件的最終用戶等的責任,讓智能系統的運行更透明,責任分擔更明確.
第四,司法信息的審核和消歧程序.司法信息中可能存在種族和性別歧視信息,技術人員將法律規則轉化為代碼的過程中也帶有人類文化中固有的偏見,則司法裁量模型的輸出結果也不可避免地存在歧視和偏向,需要對裁判文書中的歧視、價值選擇錯誤等不當趨向進行標注、提示、清理,警惕數字“喂養”中風險.大數據應用于司法領域對一些基本權利和法律價值構成挑戰,應遵循合法性原則、比例原則,加強外部監督和司法監督[44].20世紀70年代由法學和計算機科學的學者與行政官員一道組成的“斯坦利屋工作組”(Stanley House)認為算法設計應注入“人化”的價值,即保持透明、公平、不作惡、可問責與隱私原則.GitHub公布了三個算法治理開源工具Deon、Model Cards與AI Fairness 360,用于審計個人信息保護、數據安全、數據集偏見、算法公平、可解釋性等問題[45].
最后,需要有專業審核人員對司法智能裁量系統的運行進行全程監督與評估.知識和數據融合復雜推理技術不足(如過度擬合、信息來源不充分、案例部分細節過度放大以及智能技術不收斂等)或模型的價值偏差(如種族歧視、偏見等)都可能造成司法裁量系統偏離法官期望,所以需要專業人員進行監督、審核與糾偏.審核的人員可由技術專家、法學專家、社會公眾代表等相關人員的參與組成,可以是類似于審計公司的第三方獨立機構,也可以是法院或政府機構的專業審核人員.審核人員從系統規劃、設計、運營全過程參與,剔除和減少倫理不合規的系統設計,保障設計的系統符合司法建設的要求.
3.3 促進算法公開和可解釋性
算法黑箱是人們恐懼智能技術的根源,它是由算法的技術性特征造成的[46],開發人員的個人價值選擇因素以技術為包裹變得更為隱蔽.司法裁量模型的輸入部分是案例的信息和訴訟事由,輸出是法官的裁判結論,連接輸入與輸出的往往是復雜和不透明的人工智能技術基于相似案例統計得出的一組近似結論.計算參數的輕微變化能夠極大地改變計算結果,計算缺乏約束且代碼無法理解,程序易演變成“黑箱”.
首先,解開算法黑箱的第一步是算法公開.電氣和電子工程師協會(IEEE)倡導AI程序源代碼公開、對源代碼進行解釋等措施使開放資源和促進代碼透明化,減少信息不公開和程序包含的錯誤.法律技術公司應采用使用者喜好的方式,運用機器學習、語義處理和行為實驗等技術向用戶進行有針對性的信息披露[47].
其次,算法可解釋性的關鍵是讓法律專業人員理解系統的運行.算法是經過訓練數據集而不斷進行調整優化產生的.運行結果具有一定的隱蔽性和不確定性,難以發現技術人員的價值選擇和傾向.即便輸入相同的數據,由于算法編程邏輯和學習方式不一致,運行結果也會產生較大的偏差.算法的可解釋性強調算法必須為數據主體或終端用戶所理解[48],通過人機互動、知識圖譜等方式增加數據的可解釋性,進而對數據的可用性、合規性和合法性進行判斷.技術代碼代表的司法意義、運行潛在的危害、價值沖突時程序的選擇等應有數據工程師類專業人員進行判斷.2019年6月,我國科技部頒布的《新一代人工智能治理原則——發展負責任的人工智能》提出“安全可控”的原則,即要求人工智能技術“可審核、可監督、可追溯、可信賴”.歐盟明確提出了算法“解釋權”概念,即“數據主體有權獲得人工干預,表達其觀點,獲得針對自動化決策的解釋并提出異議的權利”[36].技術人員價值植入將造成新的歧視與不公平,算法的公開和可解釋能在一定程度上減少司法信息的歧視和被人為操縱的可能性.由于復雜模型的參數量大、工作機制復雜、透明性低,使得其難以得到較好的解釋[49,50].只有當司法論證過程、結論和法律行為的動機都能夠用法律人能夠理解的方式進行解釋[51],并能驗證其行為合法性,才能確保不諳熟統計學的法官、律師、學者對司法裁判模型的合理性進行評判.
最后,算法的可解釋性在于法律推理過程的公開.譬如司法論證用于法庭信息,支持與反對的信息進行可廢止論證博弈,充分展示系統做出判決的論證過程.司法實踐中研究人員為讓系統具有可解釋性做了積極地探索.總體來說有三種方式:第一類人工標注司法解釋,即讓法律人對司法文書進行大規模的標注,之后再進行相關性的排序,查詢相關案例[52];第二類基于注意網絡的案例查詢和半監督案例注釋,采用注意網絡預測或注意權重突出相關性較強的案例,避免了對全法律信息的標注[53];第三類基于論證的法律解釋,即模擬法官或律師做出司法決策的過程通過一方列舉相似類比案件,應訴方引用反例,提出假設來強化或弱化論證的方式討論案件的相關性,從而對司法智能裁量模型的運行進行有益的解釋[54].
4 難點:類案的推薦
德國哲學家考夫曼指出:“同案同判”表現了法律適用上的平等,是正義的核心[55].類案是法官尋求判決確信和解決疑難案件的一種方式.類案類判是人們追求司法公正和司法穩定的基本要求.我國司法實踐也要求制作關聯案件和類案檢索報告.如何用機器學習融合案例的各種特征幫助人類找到相似案例是建立司法智能裁量模型進行法律推理的關鍵問題.
4.1 類案判定的困境
案例具有引領社會導向以及塑造法治未來的功能,新的判決賦予了案例新時代內涵并緩解法律規范滯后性的難題.人們對智能裁判最大的期盼在通過查詢類案,對“疑難案件”給予指引.然而,當前司法實踐中人工智能類案檢索系統不同程度地存在“湊數”和“過量”的情況[56].
首先,何為“類案”一直存在爭議,建立司法智能裁量系統采用的標準不一.有人將案例相似性判定的依據歸結為三種:案例引用、案例內容和案例的概要[57].也有人認為,案例相似是案件事實、法律關系和案件爭議焦點的相似.我國最高人民法院2020年《最高人民法院關于統一法律適用加強類案檢索的指導意見(試行)》進行了界定:類案是指與待決案件在基本事實、爭議焦點、法律適用問題等方面具有相似性,且已經人民法院裁判生效的案件.案件關鍵事實是法律相似性判斷的基本出發點,案情、爭議焦點與法律適用相結合,更為全面的描述案件的特征.
其次,司法智能裁量系統的法律邏輯推理較為欠缺.人工智能可以幫助人類進行事實拆解和標簽化,從而提取法律信息語義特征、獲取特征權重和通過反饋學習提高系統性能[6].當前的智能系統大多通過對輸入的案件進行解構,抽取出案件中最小要素,再進行要素選擇及組合,從而進行類案推薦[58].司法裁量模型中案件被拆分為:案件名稱、案由、當事人名稱、原告訴稱、被告辯稱、審理經過、爭議焦點、本院查明、本院認為、法律依據、裁判文書等基本信息.為提高相似案例的精度,有些公司采用人工對案例進行人工標準,將每個司法案例由法律人進行識別和加標簽,用戶搜索時再用關鍵詞與系統中的標簽進行對比,最終推送標簽最為類似或相近的案例.司法裁量模型輸入是案件事實,輸出是法官的裁量,而運行的過程是復雜和不可控的.如果僅通過大規模的法律標簽比對而法律人無法對比對過程中的核心法律技術細節和過程進行評判,司法裁判系統判定的相似案例的參考價值將大大削弱.
第三,類案的判定與個案所處的情境密切相關.司法裁量系統忽略價值與個案背景的輸入,司法論證過程表現不充分,則獲得的類案不準確.讓機器進行相似案例的判定尤其需要提前設定相似案例判定的原則、標準,不能將輸出結果的無因性完全歸結于技術原因.案例相似性評判的基礎是案件的事實,其相似性判定有賴于與案件論證相關的事實背景的詳細輸入.以經典HYPO海波系統為例,輸入是當前事實情境,輸出包括:(1) 將當前實時情境與支持原告案例進行類比論證;(2) 從當前事實情境中區分被引案例的論證,論證支持被告的反例;(3) 對反證案例進行反駁,在可能的情況下強化原告在當前事實情境中的論證[6].
最后,人工智能難以對法官的裁判思維進行清晰刻畫.法官期望的“類案”并非案件的案由相似或是案情的完全一致,只是希望某些案例事實認定或是法律適用能夠參照其他法官的裁判思路與技巧,如何搜索出法官所需案件的判決規則和判決思路.司法裁判文書是人工智能模型建立主要來源.判決書本身經過了法律語言的二次處理,各種隱性知識或是法官的個人考慮因素無法在判決書中盡述.判決書中法律參與人在法庭上的論證過程往往一筆帶過,對司裁判辯論過程描述不清晰,裁判理由說明不充分.這些過程信息、隱性信息的缺失導致了法官裁判規則無法清晰刻畫,法律人尚不能透過文字發現法官的審判規則.將專業人士無法回答的問題交給機器,自然難以獲得滿意的答案.
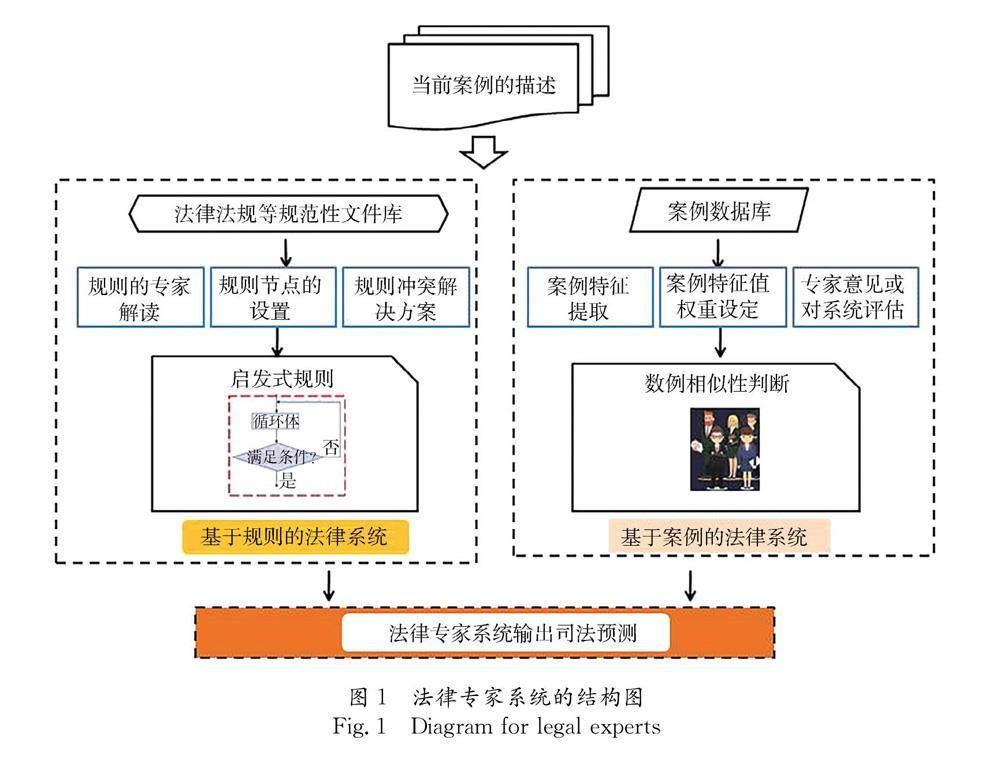
4.2 法律專家系統描述
人工智能技術推薦相似案例大體有兩類思路:(1)建立案例引用網絡來發現案例相似性.這類方法僅對有案例援引習慣的國家有效,且案例援引的不平衡,帶有一定局限性.(2)采用神經網絡等機器學習的方法對比分析案例的相似性.這是建立司法智能裁量模型的主要方法.司法智能裁量系統通過模擬法官法律推理的過程,進行支持和反對法律結論的論證,從而進行司法預測與類案推薦,專家系統、基于當前智能技術的計算模型以及認知計算系統都是該方法的具體應用.
法律專家系統是人工智能與法律相結合的最經典的解決方案,既讓法官、律師從繁蕪的事務中解放出來,又讓專家系統的運行符合法律人的期望.專家系統將人工判斷、層次分析法、模擬和模糊系統相結合[59],類似于“簡單案件——法律適用量刑系統”,沒有對證成階段的證據推理和法律適用階段的法律解釋進行模擬[60].早期人工智能與法律研究多集中于法律專家系統的建構,人們輸入當前遇到的法律問題,通過法律語義識別系統,獲取到相關法律要點,再搜尋相關類似案例從過去的司法案例中類推出當前案例的可能解決策略,或是手動詢問人類專家,了解專家分析此類問題所采用的規則,完善推理過程.以HYPO模型為代表法律智能學習模型,首先案件事實被分解為各種因素或特征,這些特征矢量可被看成高維空間中的點,尋找與目標案例相匹配的點,反饋給用戶超過相似度閾值的案例.這些因素被分為“支持”和“反對”兩個陣營,通過建立基于論證的模型,更容易識別案例的相似性與不同[51].
圖1 法律專家系統的結構圖
Fig.1 Diagram for legal experts
但是法律專家系統帶有較強的專家的個人色彩,法律專家系統的缺點也比較明顯.(1) 專家系統的建立需要專家的參與較多,提前設定的啟發式規則節點與設定的案例特征庫都打上了專家的印記,受專家的個人因素影響較大.基于案例的專家系統,利用人工智能技術比較案例相似性,生成基于這些相似性評估的論證,獲得類案推薦;基于規則的專家系統,從已知事實開始,應用啟發式推理規則設計了前向鏈接循環使用規則,一旦“觸發”規則,則得出推論結論.不論基于規則還是基于案例還是二則兼有,專家對于規則節點的選擇、案例相似性的判斷等都起到了關鍵作用.(2) 專家系統針對審判要素確定的案例,其運行效果較好;但如處理信息不完整的數據,其效果堪憂.(3) 如果大量的案件都建立專家系統,耗時耗力,且成效不顯著[6].(4) 文本解析技術可以提取某些類型法律語義信息,但目前尚無法通過學習獲知專家系統的規則.(5) 司法案例的語義解析,往往忽視了專家系統中法官的價值選擇、數據歧視等因素.(6) 司法裁判在法律信息代碼化的過程中,剔除了裁判細節,使得裁量因素簡化,但有的細節恰好對法官的判斷具有較大的意義.
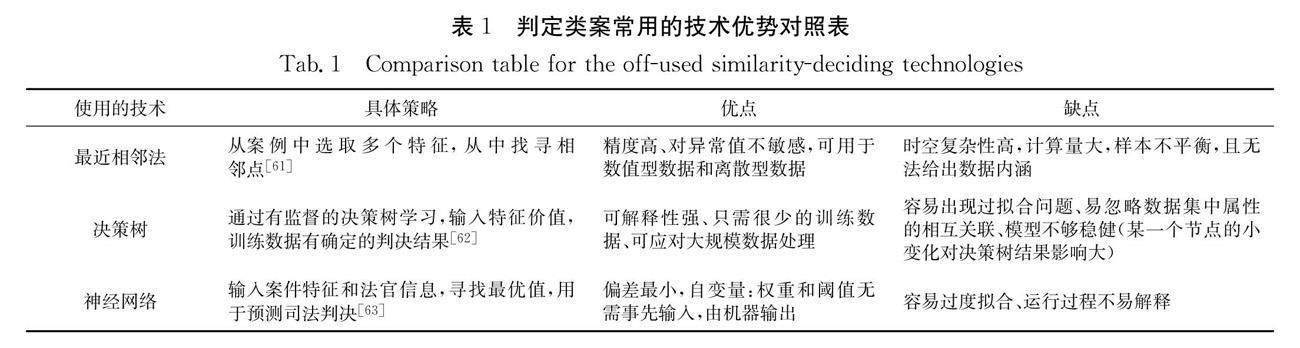
基于當前智能技術的計算模型將法律推理過程交由人工智能系統,不管有監督學習還是無監督學習,能夠最大限度上擺脫人對智能系統運行的干預.專家系統與當基于大數據分析的智能模型的區別表現在:(1) 法律專家系統預設了案件的各種可能情節,專家幫助解決用戶的問題,而基于大數據分析的智能模型通過模擬用戶的處境,獲取相關法律信息,幫助用戶構建解決方案[6].(2) 法律專家系統中專家譬如啟發式規則節點選取、案例特性值、特征的權重系數等均由專家根據經驗手動獲取,而基于當前智能技術的計算模型的識別、判斷和排序均從特定領域的數據集合中提取獲得.目前最常用的獲取相似案例的人工智能技術:最近相鄰法、決策樹和神經網絡.最近相鄰法又稱K最鄰近法找尋特征空間中最鄰近的值.決策樹是用概率分析的一種圖解法,每個葉節點代表一種類別.神經網絡是一種模仿動物神經網絡行為特征進行分布式并行信息處理的數學模型.
以下幾點值得注意:(1) 案例相似性不是看特征維度的數量而是看事先設置的維度集以及子集關注案例特征的相關重疊因素.(2) 案例特征的權重,不宜事先指定,因素的權重與背景高度相關,法官可能不是根據權重進行推理.(3) 機器學習的統計相關性并不能夠代表因果關聯,機器學習采用分類方法所得到的準確率和召回率不一定就真正反映了案例的相關性[64].基于機器學習案例相關性判斷是通過建立數據集,查詢和排序相關案例,而基于論證的相關性判斷旨在論證隱匿在法律文本中的相似關系,Ashley等提出將這兩種思路相結合,建立基于論證的法律推理模型,此方法對司法過程的描述較為詳細.這也是當前司法智能預測建模的主流方法.
司法裁量過程是尋找各方都接收且公平的解決策略.法官處理案件往往依據個人經驗或是直覺對案件的判決有一個初步的認定[65],利用各種技術手段和證據推理認定案件事實,往返于案件事實與法律規范之間,再運用法律推理尋找控辯雙方“可以接收”解決方式.法官的裁判過程是基于論證的復雜活動,其判決結果并非基于法律法規大前提和案件事實小前提的三段式法律邏輯的閉合適用,其結果與法官個人學習和生活經歷有關,與道德、倫理乃至判決的實用性相關[66].法官需要在不斷地反饋、調試中形成新的司法裁判,尋找“更優”解決方案來彌補法律的漏洞和不周延性.法律語言模糊、司法解釋具有多樣性、司法裁判需要感性與常識.各種隱性知識、過程知識、模糊知識等難以用計算機符號體系表達.基于當前智能技術的計算模型在沒有獲知法官裁判真實思維的基礎上,對案件情況較簡單、法律關系相對簡單明了的事務,通過要素輸入在稅法、交通法等領域取得了較好的效果;而對案件事實較復雜、法律關系相對復雜、法律判決結果差異較大的復雜案例,智能系統的司法預測效果尚待提高.
目前人工智能技術在計算能力和感知能力方面取得重大突破,然而智能機器不具有常識、邏輯推理和思考與應變能力,使用當前語義處理技術和機器學習技術無法揭示法律關系的復雜本質,在模擬法律行為人思維上效果欠佳.人類擁有專業知識、判斷、直覺、同情心、道德和創造力,對不同模態的知識具有一鍵搜索能力.認知智能以模仿人類認知理解記憶思維等能力為基礎,是人工智能技術發展的高級階段,強調知識、推理等技能,試圖獲得類似于人腦的多模感知能力[67].當前人工智能系統的基本做法是通過強大的算力將所有可能結果一一嘗試,而人類依靠直覺得出初步結論,再進行邏輯思維和綜合研判.因此,用認知計算進行類案相關性的判定將提高智能系統對法律數據理解、知識表達、邏輯推理和自我學習能力.2020年阿里達摩院的科技趨勢報告指出:未來人工智能將在認知智能與機器間大規模協作上取得突破,其能力將從“聽說看”拓展到邏輯推理、思考決策[68].認知智能的研究尚處于起步階段,建立完全脫離了法律人的認知裁量系統并不現實,將機器“百科全書式的記憶與巨大的計算能力”和人類“專業知識、判斷、直覺、同情心、道德和創造力”[6]相結合建立的認知計算模型,將是司法裁量模型發展的新模式.認知法學是人工智能與法律研究者將新的問題、信息提取和論證挖掘技術用于法律領域問題的解決過程,從計量法學、計算法學發展到認知法學是人工智能技術發展的必然趨勢.人機協作的認知模型將是司法智能裁量系統未來發展的方向[69].
5 結 語
司法裁量模型輔助法官進行司法裁判,毋庸置疑將減少法官重復勞動,提高司法效率,有利于發現法官裁判規則和司法共識、輔助司法糾錯和優化決策、進行法律風險預警等.司法裁判是復雜論證過程,并非簡單因果邏輯,需要理性與感性結合來作出判斷[36].要警惕“直覺的判斷被迫讓位于精準的數據分析”[70,71].法官具有直覺、同情心、價值觀以及人文關懷,若習慣于大數據“喂養”和“推薦”將淪為馬克斯·韋伯口中的“訴訟機器”.司法裁量模型的目標并非要代替法官行使司法權,而是輔助法官,減少法官相似案件的機械、重復勞動,同時抑制司法人員的恣意,增加法律適用的統一性以及減少偏見.司法智能輔助模型的重點是促進算法的可解釋性發展,提高智能系統對法律數據理解,發展其法律邏輯推理能力,邁向認知法學.智慧司法不僅需要技術人員與法律人的深度配合,更需要建立相應的風險防范措施和運行保障制度,避免司法裁量模型侵蝕法官的裁量權.只有當法律人的直覺、判斷與人工智能的強大算力相結合,縮小智能系統的預測結果與法律人的實際判斷的差距,才能讓人工智能系統落地生根,真正被法律人所接受.司法智能裁量系統將整個司法過程作為一個整體,提供了立體觀察司法體系運行的機制,從而保障智慧司法的健康發展.
每一個案件的法律細節都不同,司法智能裁量模型的建立實際上是舍棄了案例細微差異性而尋求共同性.但這些細微差異性或許對于某些案例的判決至關重要,因此,法官的判決與智能系統的司法建議不一致可能經常發生,需要建立適當的程序,保障法官盡可能避免因決策風險而遭受責難,堅持自己的判斷.當法官的判決偏離了智能系統的預測,需要法官對判決不一致的地方進行較為詳細的理由陳述,類似于“指導案例”的裁判規則的總結,為之后的類案裁判提供依據.陳述理由需要明確:(1) 待決案件與類案的不同點具有實質不同;(2) 社會及經濟情況發生變化;(3) 類案存在錯誤、過時、理由不充分等缺陷.當然這種說明程序不能過多增加法官的工作量,防止法官因怕麻煩而選擇“順從”.法官對不一致案例的處理應是法官工作考評的加分項,鼓勵法官對裁量模型的運行進行反饋與實時更新.
參考文獻:
[1] ?張妮, 蒲亦非. 計算法學導論[M]. 成都: 四川大學出版社,? 2015.
[2] 申衛星, 劉云. 法學研究新范式:計算法學的內涵、范疇與方法[J].法學研究, 2020(5): 3.
[3] 魯道夫·馮·耶林. 法學是一門科學嗎?[M].奧科·貝倫茨, 編注. 李君韜,譯. 北京: 法律出版社, 2010.
[4] Ruhl J B,Katz D M,? Bommarito M J. Harnessing legal complexity [J]. Science, 2017,? 355: 1377.
[5] 張妮, 蒲亦非.計算法學: 一門新興學科交叉分支[J].四川大學學報: 自然科學版, 2019, 56: 1187.
[6] 凱文·D阿什利.人工智能與法律解析——數字時代法律實踐的新工具[M].邱昭繼,譯.? 北京: 商務印書館, 2020.
[7] 劉雯靜.類案智能推送系統改進建議——基于法官用戶體驗及類案檢索系統的比對研究[EB/OL]. [2022-04-23]. http: //maszy.chinacourt.gov.cn/article/detail/2019/12/id/4739358.shtml.
[8] 李世宇.司法大數據在類案裁判中的應用探索[J].鄭州大學學報: 哲學社會科學版, 2018(1): 24.
[9] 左衛民.如何通過人工智能實現類案類判[J].中國法律評論, 2018(2): 26.
[10] 王祿生.司法大數據與人工智能開發的技術障礙[J].中國法律評論, 2018(2): 46.
[11] Wing J M. Computing thinking[J]. Commun ACM,? 2006,? 49: 33.
[12] 理查德·薩斯坎德.法律人的明天會怎樣?[M].何廣越, 譯.北京: 北京大學出版社, 2015.
[13] 高尚.司法類案的判斷標準及其運用[J].法律科學, 2020(1): 24.
[14] 馬超, 于曉虹, 何海波. 大數據分析: 中國司法裁判文書上網公開報告[J].中國法律評論,? 2016(4): 195.
[15] 曹磊.類案檢索對裁判文書寫作的期待[J].揚州大學學報: 人文社會科學版, 2021(6): 28.
[16] 剛青卓瑪.刑事裁判文書釋法說理的現狀及優化路徑[J].貴州警察學院學報, 2021, 33: 64.
[17] 司法部.“數字法治、智慧司法”信息化體系建設指導意見[J].中國司法, 2018, 11: 108.
[18] 張新寶, 魏艷偉.司法信息公開的隱私權和個人信息保護研究[J].比較法研究, 2022(2): 104.
[19] 范姜真微.政府資訊公開與個人隱私之保護[J].法令月刊, 2001(5): 2.
[20] 高鴻鈞.德沃金法律理論評析[J].清華法學, 2015(2): 96.
[21] Coons J E. Consistency [J]. California Law Rev, 1987, 75: 60.
[22] 羅· 龐德.? 通過法律的社會控制、法律的任務[M]. 沈宗靈, 譯.北京: 商務印書館, 1984.
[23] 托馬斯·威施邁耶.人工智能與法律的對話[M].韓旭至, 譯.上海: 上海人民出版社, 2020.
[24] 黃仁宇.萬歷十五年[M]. 北京: 生活·讀書·新知三聯書店,? 2006.
[25] 陳邦達.人工智能在美國司法實踐中的運用[N].中國社會科學報,? 2018-04-11(7).
[26] Grabmair M,Ashley K. Argumentation with value judgments-an example of hypothetical reasoning[C]//Proceedings of the 23rd Annual International Conference on Legal Knowledge and Information Systems (JURIX). Netherlands:? IOS press,? 2010.
[27] 凱文·D·阿什利.人工智能與法律解析——數字時代法律實踐的新工具[M].邱昭繼, 譯.北京: 商務印書館,? 2020.
[27] Bench-Capon T,? Modgil S. Norms and value based reasoning:? justifying compliance and violation [J]. Artif Intell Law,? 2017,? 25:? 29.
[28] Berman D H,? Hafner C L. Incorporating procedural context into a model of case-based legal reasoning[C]//Proceedings of the third international conference on artificial intelligence and law.New York: ACM Press, 1991.
[29] 凱斯·桑斯坦.信息烏托邦—眾人如何生產知識[J].畢竟悅, 譯. 北京: 法律出版社, 2008.
[30] Surden H. Values embedded in legal artificial intelligence [J].IEEE Technol Soc Mag,? 2022,? 41: 66.
[31] 山本龍彥.AI と個人の尊重、プライバシー[M].東京: 日本經濟新聞出版社, 2018.
[32] 韓振文.裁判思維的整合性認知[M]. 北京: 清華大學出版社, 2019.
[33] Francesca L,? Giovanni S,? Giuseppe C. The Ethical Knob:? ethically-customisable automated vehicles and the law [J]. Artif Intell Law,? 2017,? 25:? 365.
[34] 熊明輝.論法律邏輯中的推論規則[J]. 中國社會科學, 2008(4): 26.
[35] Bench-Capon T,? Sartor G. A model of legal reasoning with cases incorporating theories and values [J]. Artif Intell,? 2003, 150: 97.
[36] 馬靖云.智慧司法的難題及其破解[J].華東政法大學學報, 2019(4): 110.
[37] 溫州市中級人民法院. 全國第一家數據資源法庭揭牌設立![EB/OL]. [2022-05-23].https: //www.sohu.com/a/548420713_121123759.
[38] 劉云.論可解釋的人工智能之制度構建[J].江漢論壇, 2020, 12: 113.
[39] 李成.人工智能歧視的法律治理[J].中國法學, 2021, 2: 127.
[40] 王東方.人工智能嵌入司法審判的邏輯[J].研究生法學, 2020(2): 90.
[41] Ebers M. Standardizing AI-the case of the european commission′s proposal for an artificial intelligence act [EB/OL]. The Cambridge Handbook of Artificial Intelligence:? Global Perspectives on Law and Ethics,? 2021Available at SSRN:? https: //ssrn.com/abstract=3900378 or http: //dx.doi.org/10.2139/ssrn.3900378.
[42] 段偉文.算法的客觀性預設與運作策略之弊[N].社會科學報,? 2022-10-27(6).
[43] 最高人民法院. 最高人民法院關于規范和加強人工智能司法應用的意見 [EB/OL]. [2022-10-12]. https: //www.court.gov.cn/fabu-xiangqing-382461.html.
[44] 程雷.大數據偵查的法律控制[J].中國社會科學, 2019(3): 189.
[45] 許可.馴服算法.算法治理的歷史展開與當代體系[J].華東政法大學學報,? 2022(1):? 99.
[46] 沈偉偉.算法透明原則的迷思——算法規制理論的批判[J].環球法律評論, 2019(6): 20.
[47] Porto F D. Algorithmic disclosure rules [J]. Artif Intell Law,? 2021,? 29: 1.
[48] 丁曉東.論算法的法律規制[J].中國社會科學, 2020(12): 138.
[49] 劉定一, 沈陽陽, 詹天明, 等. 融合微博熱點分析和LSTM模型的網絡輿情預測方法[J]. 江蘇大學學報: 自然科學版, 2021, 42: 546.
[50] 紀守領, 李進鋒, 杜天宇, 等.機器學習模型可解釋性方法、應用與安全研究綜述[J].計算機研究與發展, 2019(10): 2071.
[51] Bibal A, Lognoul M,? Streel A,? et al. Legal requirements on explainability in machine learning [J]. Artif Intell Law, 2021,? 29:? 149.
[52] 王竹.司法人工智能推理輔助的“準三段論”實現路徑[J]. 政法論壇,? 2022,? 40:? 28.
[53] Branting L K,Pfeifer C,? Brown B,? et al. Scalable and explainable legal prediction [J]. Artif Intell Law, 2021,? 29:? 213.
[54] Prakken H,? Ratsma R. A top-level model of case-based argumentation for explanation:? Formalisation and experiments [J]. Argum Comput,? 2022,? 13: 159.
[55] 考夫曼.法律哲學[M].劉幸義, 譯.北京:? 法律出版社,? 2004:? 24.
[56] 孫躍.類案檢索的司法適用及其完善[J].法律方法, 2022, 39: 268.
[57] Bhattacharya P,? Ghosh K,? Pal A,? et al. Methods for computing legal document similarity:? A comparative study [EB/OL].[2022-11-02]. https: //doi.org/10.48550/arXiv.2004.12307.
[58] 王燃.以審判為中心的訴訟制度改革——大數據司法路徑[J].暨南學報: 哲學社會科學版,? 2018(7): 61.
[59] Li S L,? Li J Z.Hybridising human judgment,AHP,simulation and a fuzzy expert system for strategy formulation under uncertainty [J]. Expert Syst Appl, 2009,? 36: 5557.
[60] 張寶生.人工智能法律系統.兩個難題和一個悖論[J].上海師范大學學報: 哲學社會科學版, 2018(6): 25.
[61] Zhang N,? Pu Y F,? Yang S Q, et al. A Chinese legal intelligent auxiliary discretionary adviser based on GA-BP NNs[J]. Electron Libr,? 2018, 36: 1135.
[62] Mohri M,? Rostamizadeh A,? Talwalkar A.Foundations of machine learning[M].Cambridge,? MA:? MIT, 2012.
[63] Katz D M,? Bommarito M J. Measuring the complexity of the law:? the United States Code [J]. Artific Int Law,? 2014,? 22: 337.
[64] 魏斌.智慧司法的法理反思與應對[J].政治與法律, 2021(8): 111.
[65] 郭春鎮, 王凌皞.認知神經科學在法學中的應用研究[M].北京: 法律出版社, 2018.
[66] 羅伯特·阿列克西.哈貝馬斯的法律商談理論[M].雷磊, 譯, 北京: 法律出版社, 2013.
[67] 張燕.人工智能未來已來.由感知智能向認知智能演變將催生新業態[J].中國經濟周刊,? 2020(1): 92.
[68] 達摩院.達摩院2020十大科技趨勢[EB/OL].(2022-04-21)[2022-10-27].https: //damo.alibaba.com/events/57.
[69] 張妮, 蒲亦非.計量法學、計算法學到認知法學的演進[J].四川大學學報: 自然科學版, 2021, 58:? 020001.
[70] 陸汝鈐. 從大數據到大知識[J]. 重慶郵電大學學報: 自然科學版, 2022, 34: 921.
[71] 維克托·邁爾·舍恩伯格, 肯尼斯·庫克耶.大數據時代——生活、工作與思維的大變革[M].盛楊燕, 譯.? 杭州: 浙江人民出版社,? 2013.
猜你喜歡
少先隊活動(2021年2期)2021-03-29 05:40:48
法律方法(2021年3期)2021-03-16 05:57:02
中學生數理化(高中版.高二數學)(2019年6期)2019-06-24 03:37:50
商界(2019年12期)2019-01-03 06:59:05
IT經理世界(2018年20期)2018-10-24 02:38:24
中國公路(2017年7期)2017-07-24 13:56:38
小康(2017年16期)2017-06-07 09:00:59
南風窗(2016年19期)2016-09-21 16:51:29
山東青年(2016年1期)2016-02-28 14:25:30
中國衛生(2015年1期)2015-11-16 01:05:56
