多學習行為協同的知識追蹤模型
2023-05-24 03:18:34覃正楚秦心怡
計算機應用 2023年5期
張 凱,覃正楚,劉 月,秦心怡
(長江大學 計算機科學學院,湖北 荊州 434023)
0 引言
智能導學系統(Intelligent Tutoring System,ITS)和大規模在線開放課程(Massive Open Online Course,MOOC)等智慧教育平臺逐漸被大眾接受,然而智慧教育的初始內稟屬性并未包括判斷學生的知識狀態、預測學生未來的學習表現等功能。
基于上述原因,知識追蹤(Knowledge Tracing,KT)成了智慧教育領域的重要研究內容,它通過分析平臺收集的學習行為數據判斷學生的知識狀態,并根據知識狀態預測學生未來作答的表現。知識追蹤目前被廣泛應用于各類在線教育平臺,如國家高等教育智慧教育平臺、學堂在線、愛學習以及國外的Khan Academy、edX、Coursera 等。當前知識追蹤的主要意義和作用在于通過把握學生的知識狀態和未來的答題表現,為智慧教育平臺提供細粒度的教育策略,為每個學生提供個性化的教育服務。
學習序列由學生的學習記錄組成,主要包括學生的學習行為數據。學習行為數據一般可分為學習過程、學習結束和學習間隔數據三類[1]。學習過程數據主要包括學生嘗試作答次數和請求提示次數等;學習結束數據主要包括學生作答的習題及作答的結果等;學習間隔數據主要包括學生相鄰兩次學習的時間間隔和學習某概念的次數等。圖1 展示了學習過程行為、學習結束行為和學習間隔行為及其先后關系。

圖1 學習行為及其先后關系Fig.1 Learning behaviors and their sequential relationship
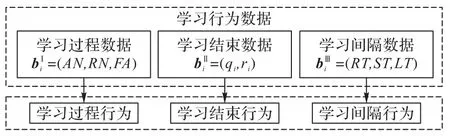
圖2 學習行為及其數據的對應關系Fig.2 Correspondence between learning behaviors and their data
經典的知識追蹤模型[2-4]僅使用學習結束數據。這類模型一般通過分析學生的學習結束行為判斷學生的基本知識狀態,但學習結束數據只包含了學生答對或答錯某道習題的信息,無法更加準確地追蹤學生的知識狀態。例如,學生A、B 的學習結束數據相同,但學習過程數據不同,在經典知識追蹤模型中無法表示學生A、B 不同的知識狀態。
學生的學習記錄中還包括學習過程行為和學習間隔行為,這些行為也是學生知識狀態發生變化的映射。有研究者利用學習過程和學習結束數據追蹤學生的知識狀態[5],用學習間隔數據建模學生的遺忘行為[6-7],但都沒有考慮學習行為的多類協同性,即學習序列中多種類型學習行為的相互作用。
為了更加準確地追蹤學生的知識狀態,本文的主要工作有:
1)描述學習行為的同類約束性。首先,選取三類學習行為數據的集合作為輸入;然后用多頭注意力機制獲取輸入數據的注意力權重,表示單一類型學習行為在時間序列上的約束關系,用來描述學習行為的同類約束性。
2)描述學習行為的多類協同性。首先,拼接三類學習行為數據的集合作為輸入;接著用通道注意力機制獲取三類學習行為的全局信息;最后將全局信息映射為學習行為之間的注意力權重,表示多種類型學習行為的相互作用,用來描述學習行為的多類協同性。
3)提出多學習行為協同的知識追蹤(Multi-Learning Behavior collaborated Knowledge Tracing,MLB-KT)模型。首先,使用編碼器融合學習行為的同類約束性和學習行為的多類協同性;然后使用解碼器通過輸入不同的查詢向量來獲取學生的學習向量和遺忘向量;最終達到更準確地追蹤學生知識狀態的目的。
1 相關工作
1.1 知識追蹤
1.1.1 基于學習結束行為的知識追蹤模型
貝葉斯知識追蹤(Bayesian Knowledge Tracing,BKT)[2]首先提出知識追蹤的概念,并用概率計算解決知識追蹤的任務。BKT 以學習結束數據為輸入,定義初始學會某概念的概率P(L0)、未學會狀態到學會狀態的轉移概率P(T)、未掌握概念但猜對的概率P(G)、掌握概念但答錯的概率P(S)等,并使用隱馬爾可夫模型(Hidden Markov Model,HMM)[8]建模上述四個概率的關系,從而預測學生的未來學習表現。
深度知識追蹤(Deep Knowledge Tracing,DKT)[3]首次使用深度序列模型來解決知識追蹤的任務。類似于BKT,DKT仍使用學習結束數據作為輸入,以循環神經網絡(Recurrent Neural Network,RNN)[9]或長短 期記憶(Long Short-Term Memory,LSTM)網絡[10]的隱藏狀態來表示學生的知識狀態,最終以全連接層預測學生的未來學習表現。
動態鍵值記憶網絡(Dynamic Key-Value Memory Network,DKVMN)[4]受標準記憶增強網絡的啟發[11],提出用記憶矩陣的方法解決知識追蹤的任務。DKVMN 仍使用學習結束數據作為輸入,用一個鍵(key)矩陣存儲概念,一個值(value)矩陣存儲學生對概念的掌握狀態;模型通過兩個矩陣判斷學生每次學習時對各個概念的掌握狀態,最終以全連接層輸出學生未來學習表現的概率。
在后續的研究中,研究者仍僅用學習結束數據作為模型的輸入建模學生的知識狀態:K?ser 等[12]在BKT 的基礎上提出了動態貝葉斯知識追蹤模型,建模不同概念之間的依賴關系;Su 等[13]在DKT 的基礎上為模型的輸入添加了習題信息;Abdelrahman 等[14]在DKVMN 的 基礎上使用了Hop-LSTM 網絡結構,使模型能夠捕獲學生學習記錄中的長期約束性。這類模型的變種還有:TLS-BKT(Three Learning States Bayesian Knowledge Tracing)[15-16]、PDKT-C(Prerequisite-driven Deep Knowledge Tracing with Constraint modeling)[17]、HMN(Hierarchical Memory Network for knowledge tracing)[18]等。
BKT、DKT 和DKVMN 是經典的知識追蹤模型,這些模型為后續的研究奠定了堅實的基礎;但它們在追蹤學生的知識狀態時僅用學習結束數據建模學習行為的同類約束性,沒有使用學習過程數據和學習間隔數據建模學習行為的多類協同性,所以無法為表示學生的知識狀態提供更加充分的支撐。
1.1.2 基于學習間隔行為的知識追蹤模型
部分研究用到了學習間隔數據:Nagatani 等[6]受艾賓浩斯遺忘曲線[19]的啟發,在DKT 模型的基礎上增加了學習間隔數據作為輸入,他們認為學習間隔數據是影響遺忘行為的因素,通過向模型增加學習間隔數據作為輸入能夠建模遺忘行為,提出了DKT-F(DKT+Forgetting)模型;李曉光等[7]受艾賓浩斯遺忘曲線和記憶痕跡衰退說[19-20]的啟發,提出了學習與遺忘融合的深度知識追蹤模型,該模型不僅考慮了上述學習間隔數據,還考慮了學生概念掌握狀態對遺忘的影響。
雖然上述兩個模型在使用學習結束數據的基礎上增加了學習間隔數據并取得了較好的效果,但仍僅建模學習行為的同類約束性,忽略了建模學習行為的多類協同性。
1.1.3 基于學習過程行為的知識追蹤模型
部分研究用到了學習過程數據:Cheung 等[5]用學習過程數據輸入分類和回歸樹模型預測學生能否正確作答習題,然后將預測結果與真實結果組合,最后將組合的數據與學習結束數據輸入DKT 模型預測未來答題情況,提出了DKT-DT(Deep Knowledge Tracing with Decision Trees)模型。該方法將學習過程數據作為學習結束數據的一種補充,改進建模學習行為同類約束性的方法,但尚未建模學習行為的多類協同性。
總的來說,大部分研究在追蹤學生的知識狀態時僅用學習結束數據作為輸入,或引入兩種類型的學習行為數據作為輸入,也有引入全部三種類型學習行為數據作為輸入[21],但均未建模學習行為的多類協同性。針對上述問題,本文提出了多學習行為協同的知識追蹤模型,在建模學習行為同類約束性的同時,對學習行為的多類協同性也進行建模,為表示學生的知識狀態提供更充分的支撐。
1.2 注意力機制
從生物學的角度看待注意力機制,它的原理是人類基于非自主性提示(Nonvolitional cue)和自主性提示(Volitional cue)有選擇地引導注意力的焦點[22]。非自主性提示指的是人沒有認知和意識的驅動來獲取信息;自主性提示指的是人有認知和意識的驅動來獲取信息,其中,查詢是自主性提示,鍵和值是非自主性提示。添加自主性提示的好處是使注意力機制的輸出偏向于某些輸入數據,而不是對輸入數據全盤接收。
例如在判斷學生的知識狀態時,學生S 在某次學習中答對了有關概念C 的習題。如果沒有認知和意識的驅動,僅以學習結束數據為標準,教師的注意力由非自主性提示引導并判斷學生S 對概念C 的掌握狀態;但如果有了認知和意識的驅動,在學習結束數據的基礎上,教師還會注意到學生的學習過程數據和學習間隔數據,注意力由自主性提示引導并判斷學生S 對概念C 的掌握狀態。
Ghosh 等[23]提出了 AKT(context-aware Attentive Knowledge Tracing)模型,用注意力機制構建習題qt和結果rt的上下文感知表示,總結學生過去的表現來解決知識追蹤任務。邵小萌等[24]提出融合注意力機制的時間卷積知識追蹤(Temporal Convolutional Knowledge Tracing with Attention mechanism,ATCKT)模型,用注意力機制建模學生學習的習題對各時刻知識狀態不同程度的影響。注意力機制的輸入是查詢(query)、鍵(key)以及值(value),輸出是值的加權和,注意力權重通過計算查詢和鍵的相似度獲得。自注意力機制是注意力機制的變體,它的輸入來自同一數據,由于沒有外部數據的輸入,所以更擅長捕捉數據內部的相似性,減少了對外 部數據 的依賴。Pandey 等[25]提出了SAKT(Self-Attentive model for Knowledge Tracing)模 型,首次將Transformer 模型[26]應用到知識追蹤領域,通過描述輸入在時序上的約束關系來完成知識追蹤任務。Transformer 模型的主要結構是多頭注意力機制,由多個注意力機制或自注意力機制并行組成,其中的全連接層將輸入數據映射到不同的子空間,能夠基于相同的機制學習到不同的權重,用來描述學習行為的同類約束性。
多頭注意力機制使用學習過程、學習結束以及學習間隔數據作為自主性提示,它的缺點在于不同的學習行為在追蹤知識狀態時被視作具有相同的權重。通道注意力機制能解決這一問題[27-30],將三類學習行為數據作為通道注意力機制的輸入,“擠壓”操作收集三類學習行為數據的全局信息,“激勵”操作將全局信息轉化為注意力權重,表示多種類型學習行為的相互作用,用來描述學習行為的多類協同性。
2 多學習行為協同的知識追蹤模型
2.1 模型提出的思想
學習序列包括不同類型的學習行為,如學習過程、學習結束、學習間隔等行為。本文使用學習過程數據bI、學習結束數據bII、學習間隔數據bIII分別描述上述三類學習行為,其中:bI主要包括學生的嘗試作答次數和請求提示次數等數據;bII主要包括學生作答的習題及作答的結果等數據;bIII主要包括學生相鄰兩次學習的時間間隔和學習某概念的次數等數據。我們發現,學習行為具備同類約束性和多類協同性的特征。具體說明如下:
根據文獻[31],學生知識狀態的變化受其已有知識狀態的約束,表現為學習行為的同類約束性,即知識狀態的變化在某一學習行為上的反應是平緩的。具體地,學習過程數據bI的同類約束性可能表現在,針對某一習題學生的嘗試作答次數在相鄰時間步的變化是平緩的;學習結束數據bII的同類約束性可能表現在,針對某一習題學生的作答結果的變化也是平緩的;學習間隔數據bIII的同類約束性可能表現在,若干次相鄰的學習時間間隔的變化同樣是平緩的。從模型角度上來說,對三類學習行為數據的表征應考慮其各自的同類約束性,以此來反映學生知識狀態的客觀變化,這是當前研究所忽略的。
根據文獻[32],學習序列中多種類型學習行為存在相互作用,表現為學習行為的多類協同性。具體地,學習過程數據bI和學習結束數據bII的多類協同性可能表現在,針對某一習題學生嘗試作答次數較多時作答結果正確的概率較低,嘗試作答次數較少時作答結果正確的概率較高;學習間隔數據bIII和學習結束數據bII的多類協同性可能表現在,針對某一習題學生學習時間間隔較長時作答結果正確的概率較低,學習時間間隔較短時作答結果正確的概率較高。從模型角度上來說,對三類學習行為數據的表征應考慮其多類協同性,以此來反映學生知識狀態的客觀變化,這是當前研究所忽略的。
BKT 使用學習結束數據bII追蹤學生的知識狀態。但bII只包含了學生答對或答錯某道習題的信息,且沒有表示出學習結束行為在時間序列上的約束關系,即學習結束行為的約束性。雖然后續的研究[12-15]仍舊僅使用學習結束數據bII,但多使用深度模型,所以在建模學習結束行為的約束性方面有一定的進展。隨后,部分研究者向模型的輸入增加學習過程數據bI[5]和學習間隔數據bIII[6-7],提高了模型的性能。雖然這些研究驗證了學習過程和學習間隔行為的有效性,但是沒有建模出學習序列中多種類型學習行為的相互作用,即學習行為的多類協同性。
綜上所述,在追蹤學生的知識狀態時,綜合考慮多類學習行為數據是有利的,這能使知識追蹤模型更準確地預測學生的未來表現。然而在建模學習行為時,應綜合考慮學習行為的同類約束性和多類協同性。
本文使用多頭注意力機制自適應地分配每類學習行為數據自身的權重,以此建模學習行為的同類約束性;使用通道注意力機制自適應地分配不同類型學習行為數據之間的權重,以此建模學習行為的多類協同性。
2.2 學習行為數據定義
2.3 多學習行為協同的知識追蹤模型架構
本文提出了多學習行為協同的知識追蹤(MLB-KT)模型,整體流程如圖3 所示。MLB-KT 模型由輸入模塊、編碼器、解碼器以及預測模塊組成:輸入模塊嵌入表示若干連續的學習行為數據;編碼器建模學習行為的同類約束性和多類協同性;解碼器生成學生的學習和遺忘向量,并更新狀態矩陣圖3 中的虛線表示預測模塊根據前一時刻的狀態矩陣、概念矩陣以及當前時刻作答的習題qt預測學生的答題情況;Mk表示概念,Mv表示學生的概念掌握狀態,這兩個矩陣隨著學習序列而動態更新。
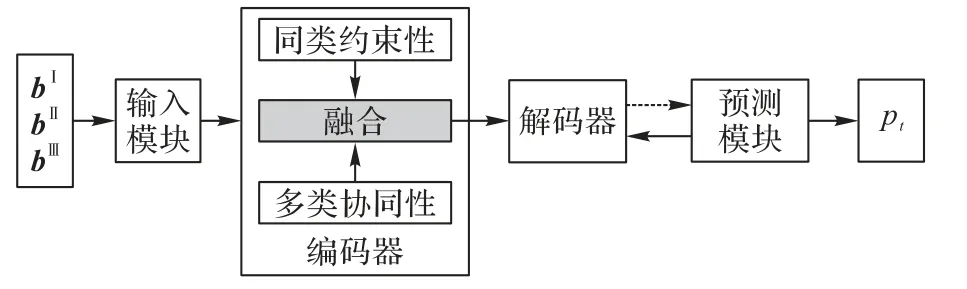
圖3 MLB-KT模型的整體流程Fig.3 Overall flowchart of MLB-KT model
2.3.1 輸入模塊
取連續n條嵌入表示的學習行為數據,再根據學習行為類型分別組合得到3 個大小為n×dv的矩陣BI、BII、BIII作為多頭注意力機制的輸入;將這3 個矩陣拼接成一個大小為3 ×n×dv的三維數組Xt作為通道注意力機制的輸入,其中3表示數組Xt包含三類學習行為;n表示數組Xt包含連續n條學習行為;dv是學習行為數據向量表示的維度。圖4 展示了輸入模塊的設計細節。
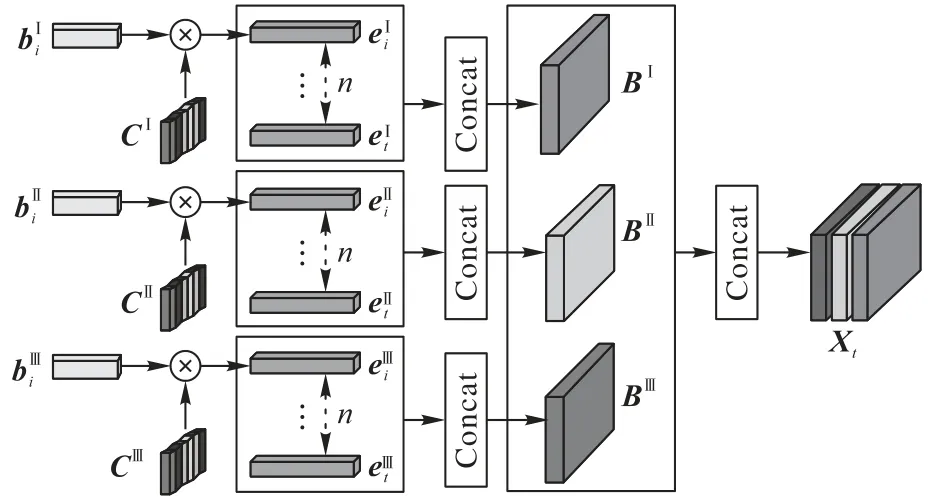
圖4 輸入模塊Fig.4 Input module
2.3.2 編碼器
數組Xt由矩陣BI、BII、BIII拼接組成,這三個矩陣各自均包括了n條連續的學習行為數據,這些學習行為數據分別表示三類不同的學習行為:學習過程、學習結束和學習間隔等行為。
1)建模同類約束性。每一類學習行為在學習序列上均存在對后續同類行為的約束性,即學習序列中相同類型學習行為在時間序列上的約束關系。因為多頭注意力機制能夠定位學習序列上的相似信息,并轉化為序列中學習記錄的相對權重,所以使用多頭注意力機制來建模上述同類約束性,具體流程如圖5 所示,其中h表示多頭注意力機制的層數。
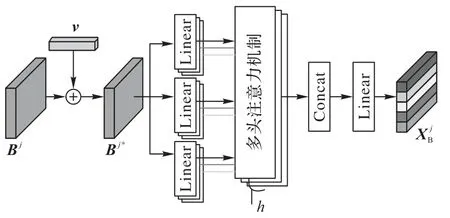
圖5 建模同類約束性Fig.5 Modeling homo-type constraint
首先使用參數v∈R1×n作為位置編碼,表示連續n條學習行為數據在時序上的相對位置,加入到輸入矩陣BI、BII、BIII中,形成含有時序上相對位置信息的學習行為矩陣:
其次將學習行為矩陣BI*、BII*和BIII*分別輸入多頭注意力機制,通過計算各學習行為間的相似性獲得注意力權重,用于建模學習行為的同類約束性,注意力權重的大小表示學習行為約束關系的強弱。輸出矩陣和分別表示學習過程行為、學習結束行為以及學習間隔行為的同類約束性:
2)建模多類協同性。多類學習行為之間存在相互的協同性,即學習序列中多種類型學習行為的相互作用。因為通道注意力機制能夠捕獲多種類型學習行為的全局信息,并轉化為各個學習行為的相對權重,所以使用通道注意力機制建模學習行為的多類協同性,具體流程如圖6 所示。
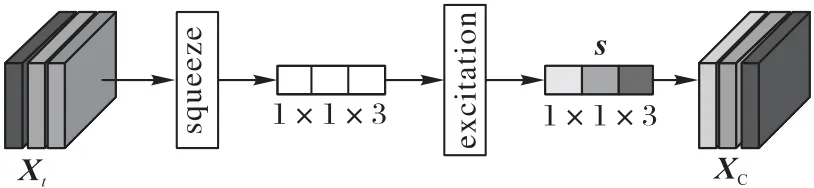
圖6 建模多類協同性Fig.6 Modeling multi-type collaboration
將數組Xt作為通道注意力機制的輸入,通過收集三類學習行為的全局信息進而獲得注意力權重,用于建模學習行為的多類協同性,注意力權重的大小表示學習行為協同的程度。擠壓(squeeze)操作收集學習行為的全局信息,激勵(excitation)操作通過全連接層將上述全局信息轉化為不同學習行為間的注意力權重s:
其中:Sigmoid(xi)=1/(1+);全連接層的權重矩陣為W;RC(·)表示逐行卷積;Cov(·)表示計算協方差矩陣,協方差矩陣用來表征三類學習行為的相關程度。
輸出的注意力權重s表示學習行為的多類協同性,將其與數組Xt進行通道乘法,改變數組Xt特征值的表達,得到數組XC:
將表示學習行為同類約束性的數組XB和表示學習行為多類協同性的數組XC相加得到數組X',通過全局平均池化獲得學習行為同類約束性和多類協同性的全局信息:
將全局信息向量g∈R1×3用線性整流函數(Rectified Linear Unit,ReLU)激活,得到特征向量z∈
其中:ReLU(x)=max(0,x);Wz∈。向量z用于生成同類約束性數組XB和多類協同性數組XC的融合權重:
其中:αB∈R1×3、αC∈R1×3是同類約束性數組XB和多類協同性數組XC的融合權重;R∈、Q∈表示數組XB和數組XC的軟注意力矩陣。
加權融合同類約束性數組XB和多類協同性數組XC,并用3 × 1 ×dv的卷積核對融合數組進行逐行卷積,得到編碼器的輸出XE∈表示學習行為的同類約束性和多類協同性:
2.3.3 解碼器
解碼器由兩個h層的多頭注意力機制組成,通過矩陣XE分別生成學習向量和遺忘向量,結構如圖7 所示。首先,以第t次學習結束數據作為查詢輸入,從h個空間維度表示學習向量lt;其次,以第t次學習間隔數據作為查詢輸入,從h個空間維度表示遺忘向量ft;最后,根據向量lt和ft更新概念掌握狀態矩陣Mv。
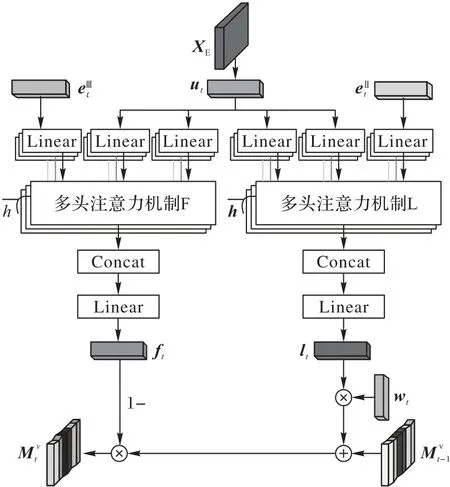
圖7 解碼器Fig.7 Decoder
將矩陣XE輸入Tanh 函數激活的全連接層獲得解碼向量ut∈,是矩陣XE的降維表達:
其中:Tanh(xi)=Wu、bu分別是全連接層的權重矩陣和偏置項。解碼向量ut含有學習行為的同類約束性和多類協同性,將其作為圖6 中多頭注意力機制L、F 中鍵和值的輸入。
在多頭注意力機制L 中,以向量作為查詢輸入,獲得學習向量lt:
在多頭注意力機制F 中,以向量作為查詢輸入,獲得遺忘向量ft:
其中:WF、bF分別是全連接層的權重矩陣和偏置項。向量是經過處理后的學習間隔數據,該向量描述的是學生相鄰兩次學習的時間間隔和學習某概念的次數等學習行為,用它做解碼過程的查詢輸入可以得到學生因遺忘而引起的概念掌握狀態的變化情況。
學習向量lt和遺忘向量ft以及關聯權重wt用于更新當前時刻的概念狀態矩陣
關聯權重wt將在預測模塊中描述。
2.3.4 預測模塊
預測模塊用于預測學生未來的答題情況,結構如圖8所示。
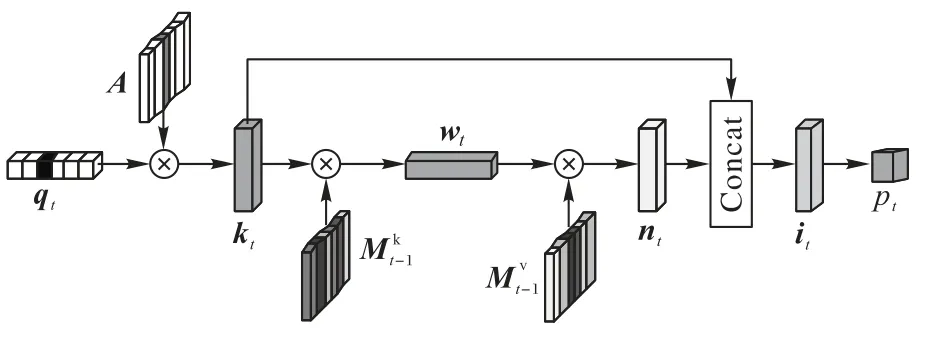
圖8 預測模塊Fig.8 Prediction module
首先,將習題qt轉換為one-hot 編碼,與嵌入矩陣A∈相乘,得到維度為dk的習題嵌入向量kt,描述習題qt的相關信息。
其次,將kt與存儲概念的矩陣Mk∈相乘,并通過Softmax 函數轉化為關聯權重wt,用來描述習題qt所包含的概念。
然后,將關聯權重wt與矩陣相乘,得到向量nt,表示學生對習題qt所包含概念的掌握狀態:
考慮到習題間存在一定的差異,如難度系數不同,將向量nt與向量kt進行拼接,并輸入至帶Tanh 激活函數的全連接層,得到向量it。向量it既包含了學生對概念的掌握狀態又包含了習題信息:
最后,利用一個帶有Sigmoid 激活函數的輸出層,將it作為輸入,用來預測學生對習題qt的表現情況:
2.4 損失函數
本文選擇交叉熵損失函數來最小化預測值pt和真實標簽rt之間的差異性。
3 實驗與結果分析
3.1 數據集和實驗環境
本文相關實驗在3 個真實數據集ASSISTments2012(簡記 為Assist12),ASSISTments2017(簡記為Assist17)和JunyiAcademy(簡記為Junyi)上進行,其中,每個數據集70%的數據作為訓練集,30%的數據作為測試集。上述數據集的基本信息如表1 所示,包括學生數、學習記錄數以及概念數。本文實驗具體軟硬件配置如表2 所示。
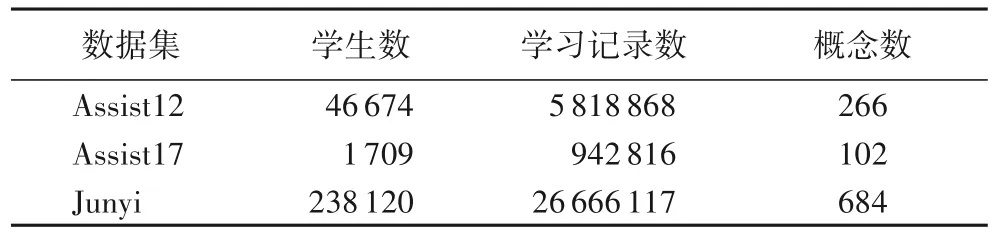
表1 數據集的基本信息Tab.1 Basic information of datasets

表2 實驗環境Tab.2 Experimental environment
3.2 模型性能對比
使用曲線下面積(Area Under Curve,AUC)分析和評價MLB-KT 模型的性能。AUC 是受試者工作特征曲線(Receiver Operating Characteristic curve,ROC 曲線)與橫坐標軸圍成圖形的面積,該面積的取值為[0.5,1],若AUC 的值為0.5,說明模型是隨機預測模型;AUC 的值越大,說明模型預測性能越好。
MLB-KT 模型的核心是以三類學習行為作為輸入,使用多頭和通道注意力機制分別建模上述學習行為的同類約束性和多類協同性。基于上述情況,在選擇對比模型時本文主要考慮如下三個條件:一是被廣泛接受且性能表現屬同類最好的模型;二是輸入各類學習行為數據的模型;三是建模同類約束性或多類協同性的模型。
根據上述三個條件,本文選用的對比模型為:僅使用學習結束數據作為輸入的單學習行為模型DKT[3]、DKVMN[4]、ATCKT[24]、SAKT[25]以及CL4KT(Contrastive Learning framework for KT)[33];在使用學習結束數據作為輸入的基礎上,引入其他學習行為數據的多學習行為模型DKT-DT[5]、DKT-F[6]。主要原因在于,這些模型均以部分或全部學習行為數據為輸入,并建模了同類約束性或多類協同性。具體地,DKT、DKVMN 和CL4KT 使用學習結束數據作為輸入,使用序列模型建模同類約束性;SAKT 和ATCKT 同樣使用學習結束數據作為輸入,還使用注意力機制建模同類約束性;DKT-F 和DKT-DT 在使用學習結束數據的基礎上,分別增加了學習間隔和學習過程數據作為輸入,使用序列模型建模同類約束性,未建模多類協同性。性能對比實驗的結果如表3所示。
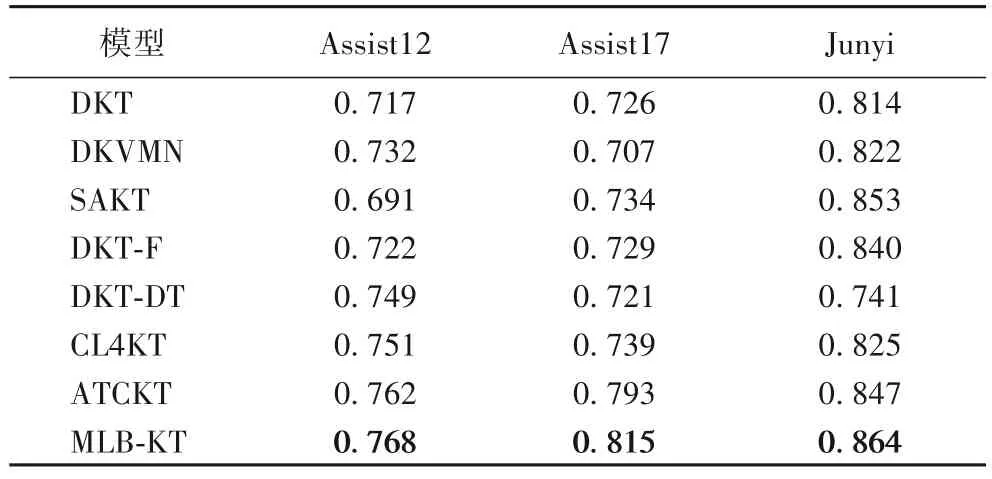
表3 不同模型的AUC對比Tab.3 AUC comparison of different models
單學習行為模型中的ATCKT 在三個真實數據集上的AUC 值分別到達了0.762、0.793 和0.847,屬同類最高,整體表現良好,5 個單學習行為模型雖均使用學習結束數據作為輸入,但由于建模學習行為同類約束性的方法不同,模型性能存在差異。
多學習行為模型中的DKT-F、DKT-DT 引入其他學習行為數據作為輸入,雖未改進建模學習行為同類約束性的方法,但改進了模型的輸入,與單學習行為模型相比均有更好的表現。與DKT 和ATCKT 模型相比,MLB-KT 在Assist17 數據集上的AUC 值分別提升了12.26%、2.77%,且MLB-KT 的AUC 值在3 個真實數據集上均優于其他模型,分別達到了0.768、0.815 和0.864,說明了在建模學習行為同類約束性的基礎上建模多類協同性的有效性。
3.3 學習行為對比
模型性能對比結果表明引入其他學習行為數據作為輸入能夠帶來模型性能的提升。為了進一步對比分析三類學習行為在模型中的重要程度,本文調整缺省MLB-KT 模型的輸入:MLB-e 表示模型僅以學習結束數據bII作為輸入;MLB-pe 表示模型以學習過程數據bI和學習結束數據bII作為輸入;MLB-ei 表示模型以學習結束數據bII和學習間隔數據bIII作為輸入。表4 給出了上述模型以及它們在3 個數據集上的AUC 值。
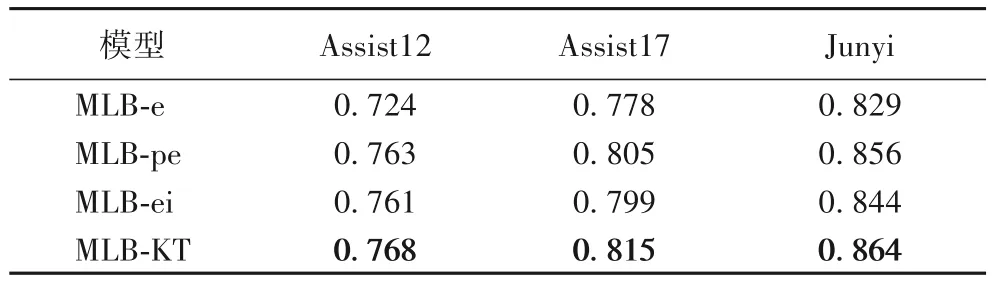
表4 不同輸入數據對模型AUC的影響Tab.4 Influence of different input data on AUC of model
由表4 可以看出,在3 個真實數據集上,MLB-e 模型的AUC 最低,說明僅分析學習結束行為及其同類約束性能夠基本判斷學生的知識狀態,但由于bII僅包含學生答對或答錯的學習結束數據,包含的信息有限,無法更準確地建模同類約束性;MLB-pe 和MLB-ei 模型的AUC 值高于MLB-e,說明在將學習結束數據作為輸入的基礎上,還引入其他學習行為數據作為輸入,并同時建模學習行為的同類約束性和多類協同性能夠提高模型的性能;但這兩個模型的AUC 值低于MLB-KT,說明在建模學習行為同類約束性和多類協同性的基礎上,模型分析的學習行為越全面則模型的性能越高。
3.4 編碼器消融
為了分析學習行為的同類約束性和多類協同性,本文分別熔斷編碼器中建模同類約束性和多類協同性的注意力機制:MLB-B 表示模型僅建模了學習行為的同類約束性;MLB-C 表示模型僅建模了學習行為的多類協同性。表5 給出了上述模型以及它們在3 個數據集上的AUC 值。由表5可以看出,MLB-KT 模型在3 個數據集上的AUC 值均優于其他兩個模型,說明在綜合考慮三類學習行為時分析其同類約束性和多類協同性是有效的;MLB-C 模型在三個數據集上的AUC 值要低于MLB-B 模型,說明僅建模學習行為的多類協同性而忽略同類約束性,會導致模型丟失學習行為在時間序列上的約束關系,無法提高模型的性能;而MLB-B 模型在三個真實數據集上的AUC 值要低于MLB-KT 模型,說明僅建模學習行為的同類約束性而忽略多類協同性,會導致模型丟失多種類型學習行為的相互作用,同樣也無法提升模型的性能。
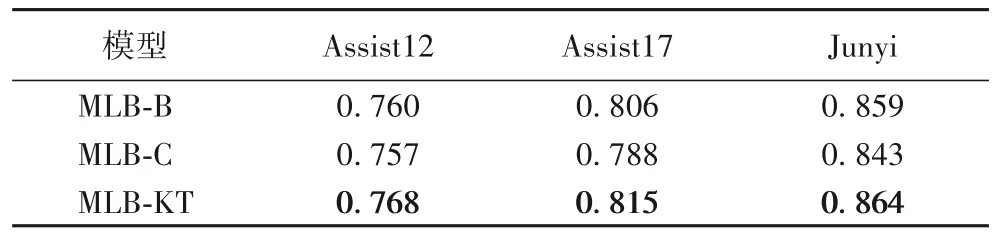
表5 編碼器的消融實驗結果Tab.5 Ablation experiment result of encoder
3.5 模型表示質量對比
模型的表示質量指模型在實際應用中預測結果與實際結果的總體差異情況。例如,知識追蹤模型KT 由某個真實數據集訓練且具有良好的預測性能。現將KT 應用于實際教學環境中,若KT 預測有40%的學生答錯有關概念C 的習題,但實際結果顯示只有10%的學生答錯有關概念C 的習題,這表明KT 在實際應用中的預測結果與實際結果總體差異較大,表示質量有待提高。
上述示例中KT 雖然有良好的預測性能,但實際應用的表現情況較差,無法在實際教學環境中應用,這表明模型既需要較高的預測性能,同時其表示的質量也至關重要。一般使用校準曲線[33]測量預測概率和觀測概率之間的一致性,使用基準對齊線x=y衡量各個模型的表示質量,校準曲線更貼近基準對齊線則說明模型預測概率更加接近觀測概率,即模型的表示質量較好。
為了更好地展示模型與基準對齊線的距離,本文取模型的校準曲線與基準對齊線的差值,得到差值對齊線y=0(Baseline),模型的校準曲線與差值對齊線越接近則表示模型的表示質量越好。圖9 是各個模型的校準曲線與差值對齊線的位置關系(以Assist12 為例)。
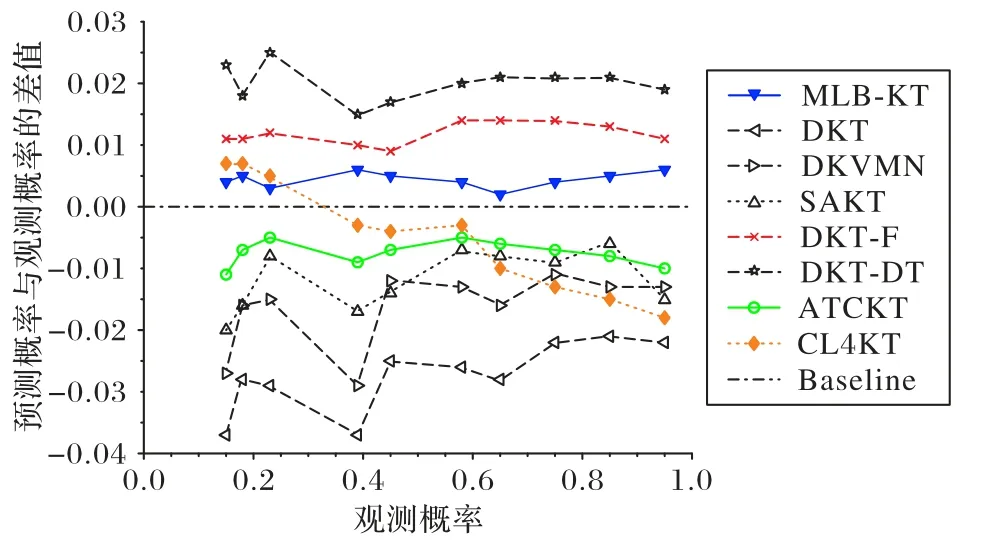
圖9 各個模型的校準曲線與差值對齊線的位置關系(以Assist12為例)Fig.9 Position relation between calibration curve of each model and difference alignment line(taking Assist12 as an example)
如圖9 所示,首先,無論在觀測概率較低還是觀測概率較高時,MLB-KT 模型差值線都更接近基準線,說明在與對比模型的比較中,MLB-KT 模型的表示質量更優。其次,SAKT、ATCKT 以及CL4KT 模型的差值線雖也接近基準線,但這些模型的差值線相較于MLB-KT 的差值線表現出更為劇烈的起伏,即整體上看,MLB-KT 模型的表示質量較為穩定。圖9 的結果表明,MLB-KT 考慮多種學習行為并建模學習行為的同類約束性和多類協同性是有效的,這使模型不會顯示嚴重的偏差,并獲得更好的表示。
4 結語
本文提出了一個多學習行為協同的知識追蹤模型MLBKT,用于解決現存知識追蹤模型無法準確地描述單一類型學習行為在時間序列上的約束關系,或無法準確地描述多種類型學習行為相互作用的問題。MLB-KT 模型使用多頭注意力機制表示學習行為的同類約束性;使用通道注意力機制表示學習行為的多類協同性;融合同類約束性和多類協同性,完成對不同類型學習行為的協同表示。MLB-KT 模型與7 個對比模型在3 個真實數據集上的實驗結果顯示,MLB-KT 模型性能較為突出,同時驗證了同類約束性和多類協同性的有效性,而且本文的模型在表示質量方面也優于對比模型。未來將繼續深入研究學習行為的同類約束性和多類協同性對知識追蹤模型帶來的影響。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
作文大王·笑話大王(2021年4期)2021-04-26 19:00:35
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電影(2018年9期)2018-11-14 06:57:21
作文世界(小學版)(2018年4期)2018-10-16 17:13:34
快樂作文·低年級(2016年12期)2017-01-03 20:52:44
光學精密工程(2016年6期)2016-11-07 09:07:19
快樂作文·低年級(2016年6期)2016-06-24 18:58:40
核科學與工程(2015年4期)2015-09-26 11:59:03
