基于多源環境變量的渭–庫綠洲土壤顆粒含量預測研究①
2023-05-26 02:50:48顧永昇丁建麗韓禮敬
土壤 2023年2期
關鍵詞:模型
顧永昇,丁建麗*,韓禮敬,李 科,周 倩
基于多源環境變量的渭–庫綠洲土壤顆粒含量預測研究①
顧永昇1,2,丁建麗1,2*,韓禮敬1,2,李 科1,2,周 倩1,2
(1 新疆大學地理與遙感科學學院智慧城市與環境建模自治區普通高校重點實驗室,烏魯木齊 830046;2 新疆大學綠洲生態重點實驗室,烏魯木齊 830046)
本文以渭干河–庫車河綠洲(簡稱渭–庫綠洲)土壤顆粒為研究對象,采集了綠洲內50個典型表層(0 ~ 10 cm)土壤樣本,通過相關軟件,提取到遙感指數變量、地形和氣候等環境變量,經過相關性分析確定環境變量和預測目標間的關系,使用R語言構建了預測土壤顆粒含量的隨機森林(random forest,RF)模型和極端梯度提升(extreme gradient boosting,XGBoost)模型。研究結果表明:XGBoost模型的預測結果整體好于RF模型,其中相關系數介于0.39 ~ 0.78;土壤pH、高程及衍生變量、光譜變換變量均是兩個模型預測土壤顆粒含量的重要因子;將模型預測結果、實測數據和世界土壤數據庫(HWSD)中的3種土壤顆粒數據作對比分析,結果表現出模型預測數據的誤差小于HWSD與實測數據的誤差。綜上所述,通過篩選環境變量建立的XGBoost模型,是預測渭–庫綠洲土壤顆粒含量的有效方法。
土壤顆粒;高光譜;環境變量;機器學習
土壤顆粒大小是劃分土壤質地的主要依據和重要特征。土壤質地受諸多因素影響,同時它也影響著溶質和養分等物質在土壤中的運移和分布,對提升土壤肥力和農業生產有重要的意義[1]。渭–庫綠洲是新疆主要農業生產區,實現該區域土壤顆粒的精準預測,對當地農業生產和土壤質量評價具有現實意義。
目前機器學習已成為預測土壤質地常用的方法,它具有可以控制模型過擬合、輸出變量重要性等優點[2]。劉亞東等[3]通過RF方法在青藏高原地區分析黏粒含量剖面分布的影響因素,其研究結果表明,氣候和地形是影響黏粒含量剖面分布的決定性因素。Liu等[4]利用MODIS數據的衍生變量,通過構建RF模型對江蘇省土壤顆粒、有機質、土壤pH等屬性進行了預測。Lie?等[5]在厄瓜多爾山區,用56個采樣點比較了回歸樹(RT)和隨機森林模型(RF)預測土壤顆粒的結果。Forkuor等[6]基于Landset遙感數據,建立了多元線性回歸(MLR)、隨機森林回歸(RFR)、支持向量機(SVM)模型預測土壤顆粒,研究結果表明機器學習預測性能優于MLR。da Silva Chagas等[7]在用 RF 模型和MLR方法預測巴西半干旱區土壤質地空間分布時,RF 模型取得更高的預測精度。高光譜數據和光譜變換數據是預測土壤屬性時常被選用的變量,通過光譜數據建立的模型能取得較高的預測精度[8]。喬天等[9]用篩選出的特征波段,建立土壤質地預測模型,研究結果比全波段建模預測結果更加精確。黃明祥等[10]對海涂砂粒光譜預處理后,構建了預測砂粒的線性和非線性模型,結果表明線性模型更加穩定可靠。
前人對土壤顆粒預測時,選擇的環境輔助變量多為高光譜數據、氣候數據和地形數據,結合環境變量和高光譜數據預測土壤顆粒含量的研究少有報道。本文將環境變量結合實測高光譜數據作為模型輸入變量,以室內實驗獲得的土壤砂粒、粉粒和黏粒含量為預測目標,建立RF和XGBoost預測模型。研究結果有望為該地區的土壤監測及管理提供數據基礎。
1 材料與方法
1.1 研究區概況
渭–庫綠洲位于塔里木盆地中北部,其北靠天山山脈,東臨塔克拉瑪干沙漠,地理位置(80°37′E ~ 83°59′E,41°06′N ~ 42°40′N),綠洲內地勢呈西北高東南低。成土母質以碳酸鈣巖和鹽巖為主,在風化、剝蝕等外力作用下其產物向平原區匯集。根據世界土壤數據庫(HWSD),按照FAO-90土壤分類系統,研究區內主要土壤類型有鹽漠泥砂土(屬于鹽化棕漠土亞類)、火黑土(屬于石灰性灰褐土亞類)、灰淤土(屬灌淤土亞類)。
1.2 土樣數據采集
土壤樣本采集在2017年7月2日至7月6日完成。根據以往采樣經驗和綠洲內土壤質地類別,在采樣區內(30 m × 30 m)用五點采樣法,共采集62個(0 ~ 10 cm)土壤樣品(圖1)。將采集的樣品混合均勻后裝入密封袋,經室內實驗,剔除異常值和誤差后,獲得50個有效土壤樣本。
1.2.1 土壤實驗及數據處理 根據土水比1∶5 (∶)配成土壤溶液,經沉淀過濾后測定土樣pH和土壤含鹽量(SSC)。土壤含水量(SMC)采用烘箱烘干后用稱重法測定。采用激光粒度儀(Mircotrace S3500)測定土壤粒徑,將測量數據按美國制分為:黏粒(< 0.002 mm)、粉粒(0.002 ~ 0.05 mm)、砂粒(0.05 ~ 2 mm)[11]。

圖1 采樣點示意圖
1.2.2 光譜測量及數據處理 在暗室環境下采用FieldSpec3型光譜儀,對每個樣本測量10次后取均值,即為該樣本的光譜數據。去除邊緣噪聲較大的350 ~ 400 nm和2 401 ~ 2 500 nm的光譜曲線,用一階微分(FD)和Savitzky-Golay (SG )平滑方法對其余波段進行預處理。通過SPSS軟件對3種光譜數據進行主成分(PCA)分析,原始光譜選擇前3個主成分(YPC1、YPC2、YPC3),一階微分選擇前5個主成分(FDPC1、FDPC2、FDPC3、FDPC4、FDPC5),SG平滑選擇前2個主成分(SGPC1、SGPC2),作為模型輸入變量。
1.3 遙感影像獲取及預處理
在Google Earth Engine(GEE)平臺,獲取2017年7月4日L1T級的Landsat8 OLI 影像,其空間分辨率為30 m,波段運算后得到歸一化植被指數(NDVI)和增強型植被指數(EVI)。土壤容重(BD)數據來源于HWSD,空間分辨率為1 km,下載地址http://data. tpdc.ac.cn;土壤有機碳(SOC)、陽離子交換量(CEC)數據來源于https://soilgrids.org/,空間分辨率250 m,通過ArcMap處理后得到研究區土壤BD、SOC和CEC數據。
1.4 地形和氣候變量
在土壤的形成和發育過程中,受母質、時間、人類活動諸多環境因素影響[12]。因時間和人類活動沒有定量數據表達,選擇地形和氣候作為環境變量。地形(DEM)變量及衍生變量用SAGA GIS軟件計算,數據來源https://www.gscloud.cn,空間分辨率30 m。下載2017年CRU TS氣候數據集作為氣候數據,數據來源https://crudata.uea.ac.uk/cru/data/hrg/,分辨率為覆蓋陸地表面0.5°。經ArcMap重采樣(30m空間分辨率),得到7月的月均溫(TEM)和月均降水量(PRE)。以上環境變量見表1。

表1 環境變量信息
1.5 模型構建和評價
隨機森林(RF)是多棵決策樹的組合,其中樹彼此間相互獨立,在多棵樹中完成對樣本的訓練和預測[2]。RF不同于線性回歸要假設目標預測變量的概率分布,并能夠防止過擬合問題[6]。在R語言中用caret包把樣本數據60% 劃為訓練集,40% 劃為測試集,可取得較好的預測效果。模型參數ntree為 500和1 000,mtry為2、3和5。
極端梯度提升(XGBoost)算法具有正則化、并行處理運算、內置交叉驗證和高度的算法靈活性等優勢[13]。其模型結構相對簡單,避免過擬合且準確率較高。模型參數eta=0.1,gamma默認,max-depth=6,nrounds=500。
2用來表示模型預測精度,RMSE 和 MAE用于計算模型預測數據的誤差。其計算公式如下:

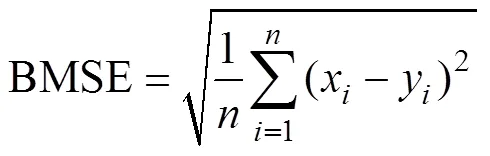

2 結果與分析
2.1 土壤粒徑描述性統計特征
50個采樣點的土壤粒徑統計結果如表2所示。研究區內土壤顆粒含量砂粒最多,粉粒其次,黏粒最少。3種土壤顆粒的變異系數隨著顆粒粒徑的減小而升高,說明研究區內土壤顆粒含量的異質性較強。
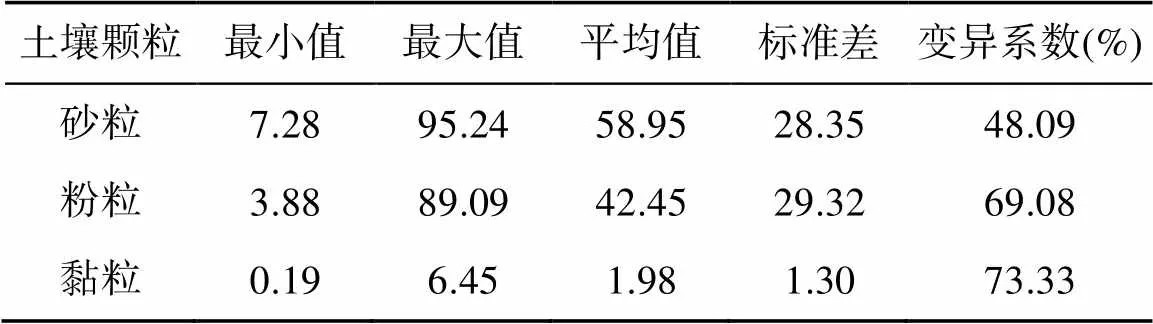
表2 土壤粒徑描述性統計(%)
采用SigmaPlot繪制土壤質地三重圖(圖2)。根據美國制土壤質地分類標準,渭–庫綠洲的土壤質地主要為砂壤質。

圖2 土壤質地三重圖
2.2 土壤理化屬性及環境條件
研究區內土壤采樣點的基本理化屬性和環境條件如表3所示。可以看出采樣點土壤呈微堿性;SOC含量和NDVI值因綠洲內土壤類別和植被覆蓋度的差異而變化較大;CEC是土壤保肥指標,綠洲內的土壤保肥能力處于中等水平。由于綠洲內降水少蒸發量大,加之肥力較好的成土母質,形成了發達的綠洲滴灌農業。

表3 土壤屬性和環境描述
2.3 土壤顆粒的影響因素分析
將預處理的環境變量和實測土壤顆粒數據進行Pearson分析。由表4可知,pH與砂粒呈負相關,由于砂粒孔隙度大,在強烈的蒸發下,土壤水和致酸離子解離后,導致土壤呈酸性。pH與粉粒呈正相關,隨著土壤粒徑的減小,土壤顆粒的保水性能會提升,土壤顆粒間的OH–和H+彼此交換中改變土壤酸堿性。土壤光譜反射率受顆粒粒徑影響,粒徑大的顆粒之間能保持更多的空氣和水,使得光譜吸收率增加;粒徑小的土壤顆粒,因孔隙度的變小使顆粒間結合更為緊密,光譜反射率變大[14]。相關研究表明,光譜數據在通過微分變換后,土壤光譜反射率與土壤粒徑呈負相關[15]。由于綠洲內高程起伏較小,減小了地形對土壤顆粒再次分配的影響,因此地形變量和土壤顆粒有較強的相關性[16]。
2.4 環境變量重要性分析
在R語言中對環境變量進行重要性排序(圖3)。兩個預測模型中,pH、光譜變換變量和地形變量是預測砂粒和粉粒含量的重要因子。pH受生物、氣候及人類作用等因素影響,土壤中游離的酸堿離子在土壤溶液交換過程中改變土壤酸堿性[17]。相關研究表明,變換后的高光譜數據,在參與建模時綜合預測能力好于原始光譜[18]。李愛迪[19]的研究結果表明:Elevation、TWI等地形因子是預測土壤質地的重要變量。在預測黏粒含量的變量重要性排序中,兩個模型的排序出現較大差異,是因為RF模型中是用均方誤差作為變量重要性的評價指標,XGBoost模型是以變量劃分后對樣本的覆蓋度為變量重要性衡量指標。
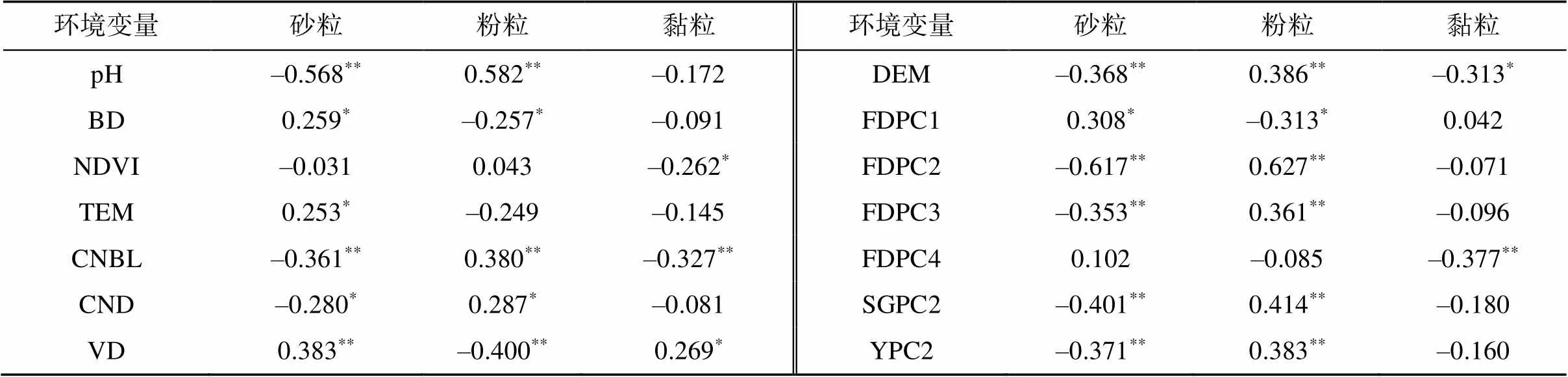
表4 土壤顆粒與環境變量的相關性
注:*、**表示相關性達<0.05和<0.01顯著水平(雙尾)。
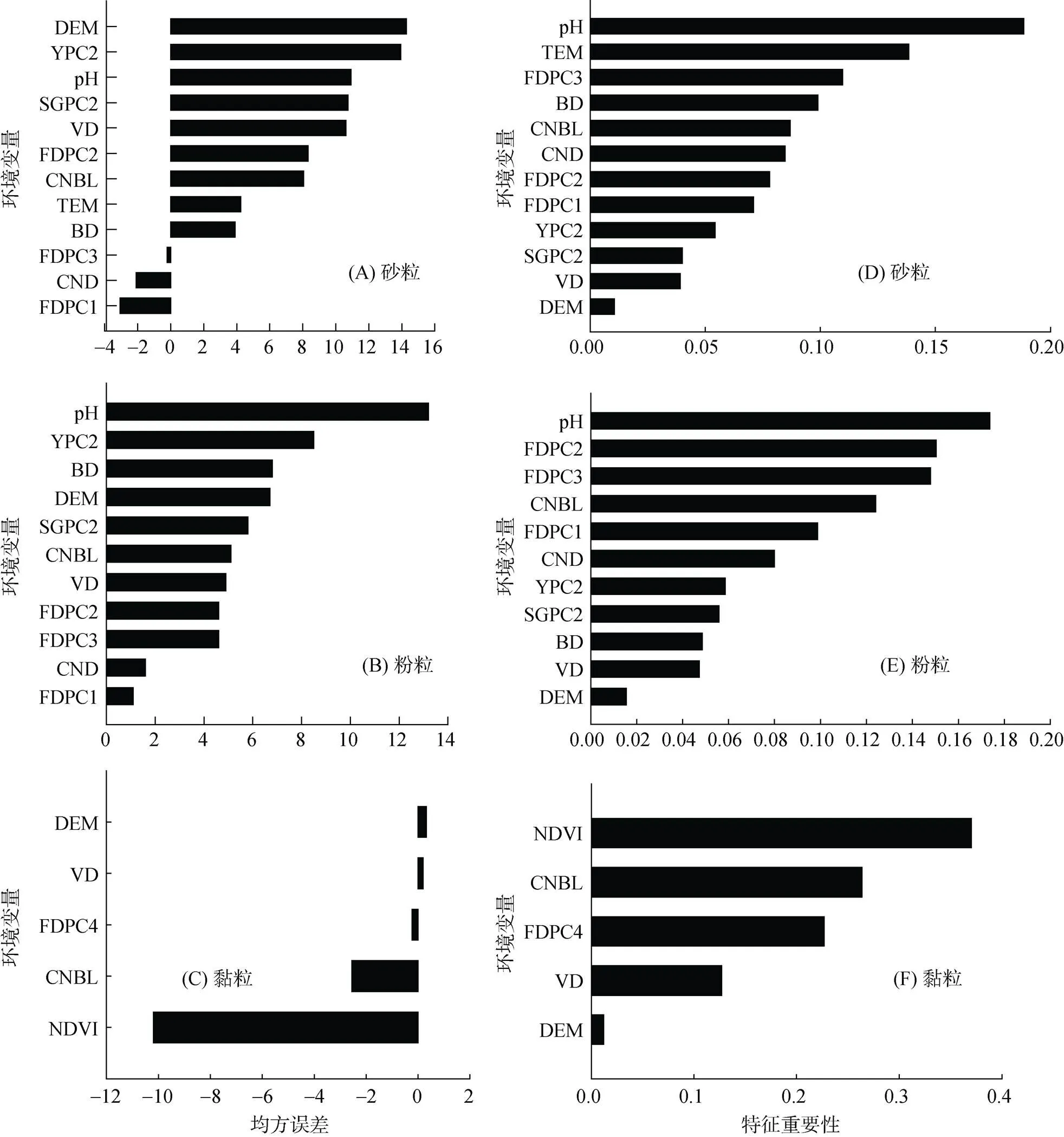
(A、B、C為RF模型中變量重要性排序;D、E、F為XGBoost模型中變量重要性排序)
2.5 預測結果分析和對比
模型預測結果如表5所示。RF模型對粉粒的預測效果最好,砂粒次之,黏粒的預測效果最差。對比RF模型,XGBoost模型的預測效果,砂粒最好,粉粒次之,黏粒有所提升。預測單個土壤顆粒時,XGBoost模型對砂粒的預測效果最好;RF模型對粉粒預測有優勢,誤差也相應減小;XGBoost對黏粒的預測結果好于RF模型。從整體預測結果來看,XGBoost模型好于RF模型。
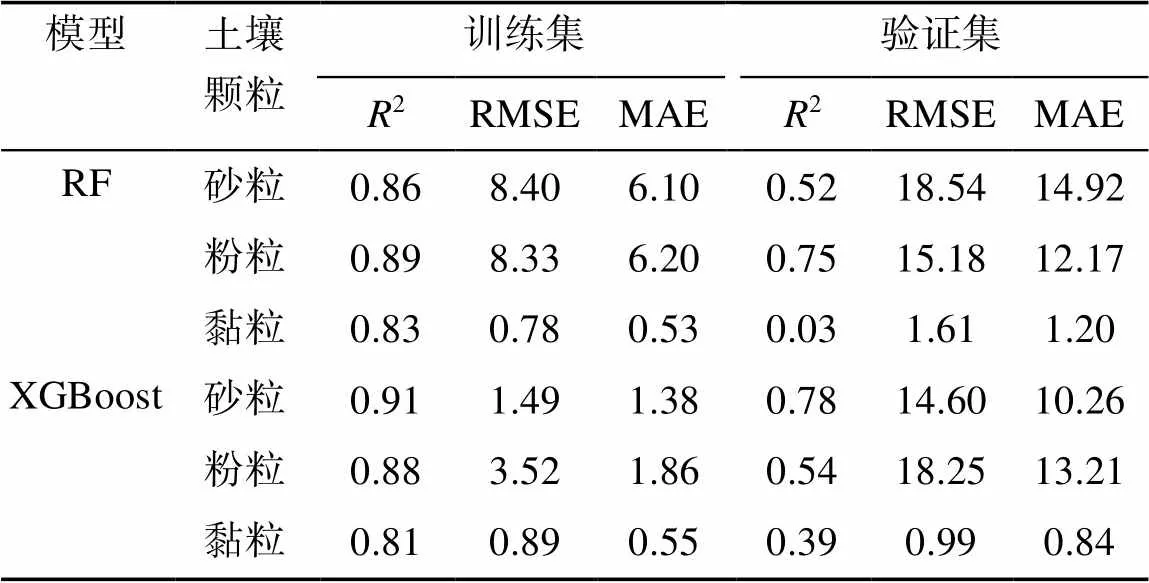
表5 土壤顆粒含量預測精度驗證
通過ArcMap提取HWSD中研究區內的土壤顆粒數據。對模型預測數據、實測土壤顆粒數據和HWSD中的3種土壤顆粒數據的誤差(RMSE、MAE)進行對比分析。從圖4中可以看出,本研究中兩個模型的預測誤差整體上均小于HWSD和實測數據的誤差。

圖4 數據誤差對比
3 討論
選擇土壤屬性變量、環境變量和光譜變量等,構建了RF和XGBoost預測土壤顆粒含量模型。從預測結果來看(表5和圖4),本文兩種模型的預測結果比馬重陽等[20]預測土壤屬性的結果有所提升;與da Silva Chagas等[7]預測干旱區土壤顆粒的研究結果相似。模型輸入變量對預測結果也有較大影響,在相關研究中,通過高光譜數據建立的預測模型,相較于只有土壤屬性變量、環境變量和地形變量建立的預測模型,能取得更高的預測精度[21–22]。同時,本研究與前人研究也存在差異之處,魏宇宸等[23]和其他學者[5,7]在預測土壤顆粒含量時,RF模型預測效果最好。本研究中,RF模型在預測黏粒時精度較低,可能是因為RF模型將FDPC4、CNBL、NDVI環境變量重要性計算為負數。
徐佳等[24]利用機器學習方法從土壤屬性角度出發,推測關鍵成土的環境要素研究中發現,各土壤屬性中pH對地表溫度、年降水量和年均溫環境變量的貢獻性較高。在本文中,pH也是環境變量中重要的土壤屬性因子,其對砂粒和粉粒的預測結果影響較大。DEM及相關衍生變量是影響土壤顆粒組成的重要因素,在以往的研究中常被選為預測土壤顆粒含量的關鍵因子[25]。在本研究中DEM、CNBL、CND等地形因子,在模型預測的環境變量中均占據較高的重要性。光譜信息是反映土壤屬性的有效數據,用光譜數據建立機器學習評估粒徑含量和分布模型,達到較高的預測精度[26]。在本研究中,預測砂粒和粉粒含量時,有較多的光譜變量參與建模,預測精度也較高;預測黏粒含量時,只有較少的光譜變量參與建模,是導致模型預測精度較低的一部分原因。
實測土壤顆粒含量數據的離散程度,會對模型預測結果產生不確定性的影響[18]。研究區實測土壤顆粒數據中砂粒和粉粒的分布比較集中,兩種模型預測精度整體較高;而黏粒數據的分布較離散,使RF模型沒有發揮本有的預測性能。由于建模樣本量過小,致使本文中出現了驗證集對比建模集精度下降的問題。在以后的研究中,應采用更加科學合理的采樣方法以及增加樣本數量,利用更優的環境變量篩選方法和多種變量組合方案,以降低模型預測的不確定性,提高預測精度。
4 結論
1)通過Pearson相關性分析得出的環境變量,構建了RF和XGBoost模型預測土壤砂粒、粉粒、黏粒含量,并取得較好的建模效果。XGBoost模型的預測精度整體較高,尤其是預測黏粒含量。
2)數字高程模型、原始光譜主成分2、土壤pH和月均溫是預測砂粒含量的重要環境變量;土壤pH、一階微分主成分2、土壤容重和數字高程模型等是預測粉粒含量的重要環境變量;歸一化植被指數,河網基準面,一階微分主成分4和谷深是預測黏粒含量的重要環境變量。
3)對模型得到的預測數據、實測數據和世界土壤數據庫(HWSD)中的土壤顆粒數據進行對比分析,模型預測數據比HWSD中土壤顆粒數據更接近實測數據的范圍。
[1] 張世文, 王勝濤, 劉娜, 等. 土壤質地空間預測方法比較[J]. 農業工程學報, 2011, 27(1): 332–339.
[2] Breiman L. Random forests[J]. Machine Learning, 2001, 45(1): 5–32.
[3] 劉亞東, 李旺平, 趙林, 等. 青藏高原溫泉地區土壤黏粒含量剖面分布模式及其影響因素[J]. 土壤, 2021, 53(3): 637–645.
[4] Liu F, Rossiter D G, Song X D, et al. An approach for broad-scale predictive soil properties mapping in low-relief areas based on responses to solar radiation[J]. Soil Science Society of America Journal, 2020, 84(1): 144–162.
[5] Mareike Lie?, Bruno Glaser, Bernd Huwe. Uncertainty in the spatial prediction of soil texture: comparison of regression tree and Random Forest models[J]. Geoderma, 2012, 170: 70–79.
[6] Forkuor G, Hounkpatin O K L, Welp G, et al. High resolution mapping of soil properties using remote sensing variables in south-western Burkina Faso: A comparison of machine learning and multiple linear regression models[J]. PLoS One, 2017, 12(1): e0170478.
[7] da Silva Chagas C, de Carvalho W Jr, Bhering S B, et al. Spatial prediction of soil surface texture in a semiarid region using random forest and multiple linear regressions[J]. CATENA, 2016, 139: 232–240.
[8] 趙明松, 謝毅, 陸龍妹, 等. 基于高光譜特征指數的土壤有機質含量建模[J]. 土壤學報, 2021, 58(1): 42–54.
[9] 喬天, 呂成文, 肖文憑, 等. 基于遺傳算法的土壤質地高光譜預測模型研究[J]. 土壤通報, 2018, 49(4): 773–778.
[10] 黃明祥, 程街亮, 王珂, 等. 海涂土壤高光譜特性及其砂粒含量預測研究[J]. 土壤學報, 2009, 46(5): 932–937.
[11] 吳克寧, 趙瑞. 土壤質地分類及其在我國應用探討[J]. 土壤學報, 2019, 56(1): 227–241.
[12] 丁建麗, 王飛. 干旱區大尺度土壤鹽度信息環境建模——以新疆天山南北中低海拔沖積平原為例[J]. 地理學報, 2017, 72(1): 64–78.
[13] Chen T Q, Guestrin C. XGBoost: A scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA. New York: ACM, 2016: 785–794.
[14] 楊雪紅. 土壤粒徑對土壤光譜特征的影響[J]. 科技信息, 2010(25): 390–391, 154.
[15] 馬創, 申廣榮, 王紫君, 等. 不同粒徑土壤的光譜特征差異分析[J]. 土壤通報, 2015, 46(2): 292–298.
[16] 張世文, 黃元仿, 苑小勇, 等. 縣域尺度表層土壤質地空間變異與因素分析[J]. 中國農業科學, 2011, 44(6): 1154–1164.
[17] 耿增超, 戴偉. 土壤學[M]. 北京: 科學出版社, 2011.
[18] 張雅梅, 施夢月, 王德彩, 等. 基于高光譜的土壤不同顆粒含量預測分析[J]. 土壤通報, 2021, 52(4): 777–784.
[19] 李愛迪. 地形因素影響下重慶市主要土壤的質地類型空間分布預測研究[D]. 重慶: 西南大學, 2019.
[20] 馬重陽, 孫越琦, 巫振富, 等. 基于不同模型的區域尺度耕地表層土壤有機質空間分布預測[J]. 土壤通報, 2021, 52(6): 1261–1272.
[21] 李春蕾, 許端陽, 陳蜀江. 基于高光譜遙感的新疆北疆地區土壤砂粒含量反演研究[J]. 干旱區地理, 2012, 35(3): 473–478.
[22] 盧宏亮, 趙明松, 劉斌寅, 等. 基于隨機森林模型的安徽省土壤屬性空間分布預測[J]. 土壤, 2019, 51(3): 602–608.
[23] 魏宇宸, 趙美芳, 朱昌達, 等. 基于景觀及微地形特征的丘陵區土壤屬性預測[J]. 應用生態學報, 2022, 33(2): 467–476.
[24] 徐佳, 劉峰, 吳華勇, 等. 基于人工神經網絡和隨機森林學習模型從土壤屬性推測關鍵成土環境要素的研究[J]. 土壤通報, 2021, 52(2): 269–278.
[25] Laborczi A, Szatmári G, Takács K, et al. Mapping of topsoil texture in Hungary using classification trees[J]. Journal of Maps, 2016, 12(5): 999–1009.
[26] Parent E J, Parent S é, Parent L E. Determining soil particle-size distribution from infrared spectra using machine learning predictions: Methodology and modeling[J]. PLoS One, 2021, 16(7): e0233242.
Prediction of Soil Particle Content in Wei-Ku Oasis Based on Multi-source Environmental Variables
GU Yongsheng1, 2, DING Jianli1, 2*, HAN Lijing1, 2, LI Ke1, 2, ZHOU Qian1, 2
(1 Key Laboratory of Smart City and Environment Modelling of Higher Education Institute, College of Geography and Remote Sensing Sciences, Xinjiang University, Urumqi 830046, China; 2 Key Laboratory of Oasis Ecology, Xinjiang University, Urumqi 830046, China)
In this paper, soil particles in the Weigan River-Kuche River Oasis (referred to as the Wei-Ku oasis) were used as the research object, fifty typical surface (0 – 10 cm) soil samples were collected from the oasis, and environmental variables such as remote sensing index variables, topography and climate were extracted through relevant software. After correlation analysis to determine the relationship between environmental variables and prediction targets, a random forest (RF) model and an extreme gradient boosting (XGBoost) model for predicting soil particle contents were constructed using R language. The results show that the prediction results of the XGBoost model are better than those of the RF model, with the correlation coefficients ranging from 0.39 to 0.78. Soil pH, elevation and derivative variables, and spectral transformation variables are all important factors in the prediction of soil particle contents in both models. The errors of model prediction data are smaller than those of HWSD and measured data. In conclusion, the XGBoost model established by screening environmental variables is an effective method for predicting soil particle content in the Wei-Ku oasis.
Soil particles; Hyperspectra; Environmental variables; Machine learning
S152.3
A
10.13758/j.cnki.tr.2023.02.024
顧永昇, 丁建麗, 韓禮敬, 等. 基于多源環境變量的渭–庫綠洲土壤顆粒含量預測研究. 土壤, 2023, 55(2): 426–432.
新疆維吾爾自治區自然科學基金重點項目(2021D01D06)和國家自然科學基金項目(41961059)資助。
(watarid@xju.edu.cn)
顧永昇(1995—),男,甘肅武威人,碩士研究生,主要從事干旱區綠洲水鹽運移研究。E-mail:1774600807@qq.com
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
