基于數據挖掘的視頻評論識別分析
2023-05-30 10:48:04霍建光
電腦知識與技術 2023年2期
霍建光


關鍵詞:BERT 模型;推薦;文本情感分析;分類
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2023)02-0050-03
1 引言
互聯網技術的快速發展已經影響了人們工作、生活的方方面面。目前整個網絡的數據量越來越多,呈現出信息多樣化、信息化擴散快及類型多等特點[1]。整個數據的類型包括文本數據、視頻數據、文件數據等內容,這些數據有些是結構化的、有些是非結構化的。為了能夠獲取相關數據信息,文章可以通過爬蟲的方式來確定主題,以此獲取針對性的業務數據信息。
隨著技術的提升以及市場的完善,人們越來越多地使用網絡平臺進行購物、購票、出行等日常活動。另外,人們也增加了視頻平臺的使用時間。在這些活動之中,不論是日常活動還是娛樂活動,難以避免地會出現眾多來自用戶主觀性的、帶有情感色彩的評論[2]。這些評論并非活動中產生的贅余,而是一種寶貴的資源,它直觀表現出對某一事物的偏好,網絡平臺運營者如果能根據用戶的喜好進行推薦,則會大大促進用戶的消費意愿,增加客戶黏性。而若是能夠提前對用戶評論進行情感的分類,則能提升分析的效率。
對企業而言,各大社交平臺網站充滿了各種各樣的用戶評論,其中不乏過激的、惡意煽動的負面評論。敗壞社區風氣,而舉報惡意評論的功能需要用戶手動完成,不確定性高,而且效率低下。該系統可以幫助企業快速分辨出負面評論,再加以處理的效率隨之提高;對個人而言,想要得知一個視頻評論是正面評論還是負面評論居多并非一件容易的事,尤其是評論數量巨大的情況下,該系統可以分辨并展示出正面評論,中性評論和負面評論的數量,幫助用戶更全面客觀地了解人們對一個視頻的評價[3]。
目前在學術界,文本情感分析的方式主要有三種,這三種方法技術路線不同,分別采用深度學習、情感詞典與傳統機器學習的方式與方法進行處理[4]。傳統機器學習方法的優點在于方法容易實現且總體計算工作量小,但是缺點也很明顯,需要專業人員完成技術特征的分析與提取,總體算法的泛化能力弱;采用情感詞典的方式進行實現,主要優點在于方法實現簡單,但是總體需要耗費大量物力人力來完成整個情感詞典的構建。以此方式能夠看出傳統的機器學習方法與情感詞典都需要花費大的人力與物力完成分析與計算過程。而基于深度學習的方法能夠有效彌補這兩種方法的不足,對整個特征進行自動提取并加以分析與處理,有效提升整個本文情感分析的準確性。
2 關鍵技術
2.1 Python 爬蟲
目前常用的網絡爬蟲方式為聚焦爬蟲[5],第一步需要設置爬蟲的主題,在這個基礎之上與主題無關的信息不被抓取,而保留整個鏈接之中有用的信息,接著根據一定的搜索策略尋找下一個鏈接。和通用爬蟲相比,聚焦爬蟲極大地節省了硬件和網絡資源,并且增加鏈接評價模塊和內容評價模塊,評價的重要性不同,鏈接的訪問順序也不同。
2.2 BERT模型
1)BERT簡介
在整個語言特征模型的處理之中[6],目前常用的模型為BERT,這個模型的全稱為Bidirectional? Encod?er Representation from Transformers,此模型主要特點在于采用新的MLM 方法進行語言表征的分析與處理。這樣的處理方式與以往采用單一或者將兩個語言模型進行簡單的拼接有著本質的差異。
2)BERT優點
在整個訓練詞向量的處理之中,以往采用的方式主要是GloVe方法或者Word2Vec方法,這些方法是靜態編碼的處理方式,若是在不同的上下文環境處理之中,即使這個單詞是單一的,此時這個模型對于語義的處理也是不同,準確率有待提升。
對訓練詞向量采用BERT模型的時候,整個預訓練的處理采用MLM雙向Transformers模型進行,主要工作目標是生成雙向的語言表征。這個處理是深層的,采用預處理方式訓練之后,需要增加一個輸出層進行處理,能夠有效提升整個詞語的分類處理,整個過程之中并不需要對總體結構進行修改與處理。
3)BERT處理過程
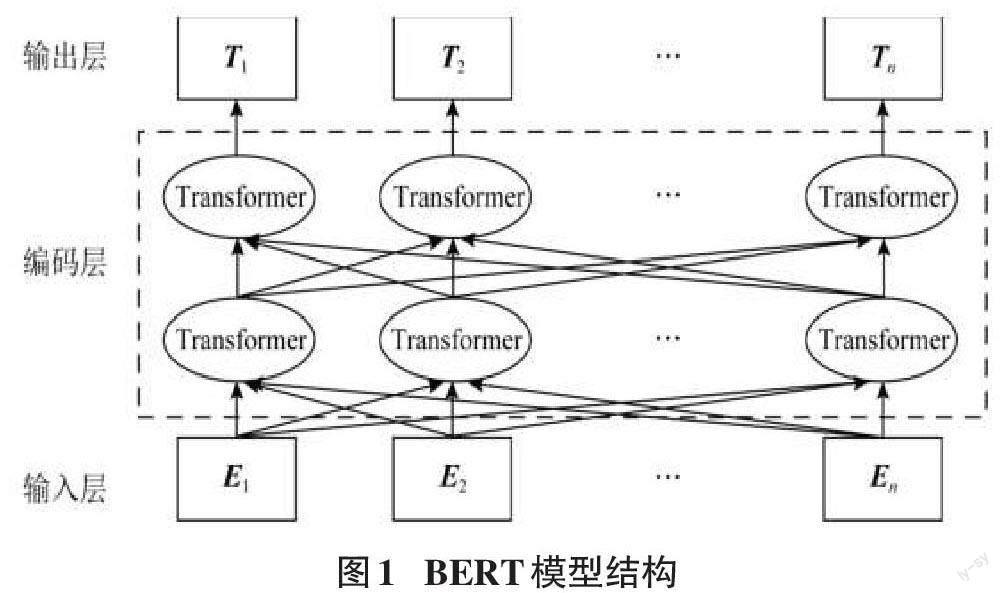
在整個BERT模型的分析與處理之中,其主要工作目標是完成語言模型的訓練與處理操作,其在以往傳統的方法之中進行了處理,其主要作用是確定句子語義之間的相互與處理,整個模型對應的處理結構如圖1所示。
在整個BERT的分析與處理之中,整個模型架構分為輸出層、編碼層與輸入層三層的方式進行處理,在這個模型之中,若是句子的意思相近,則其在空間之中的距離是相近的,整個對文字理解與句子之間的向量操作是類似的。
BERT模型的處理之中,整個輸入分為三個部分,第一部分是位置向量;第二部分是分段向量;第三部分是詞向量,這三種向量主要針對詞語的三個方面進行處理,位置向量主要的作用是確定詞語的位置,這個詞語的開頭與結尾使用CLS、SEP進行標記;對當前詞語的編碼主要通過詞向量進行標注,詞語在整個句子之中的位置通過分段向量來表示。在整個BERT模型的處理之中,關鍵核心的部分為雙向Transformer編碼層,這一部分主要的作用是對語言之中的特征進行提取與分析,這一個操作主要采用的是Encoder特征抽取器,特征抽取器主要的結構示意圖如圖2所示。
從圖2整個Encoder的結構示意圖中可以看出,其主要包括多個處理部分,如前饋神經網絡、求和與歸一化、自注意力處理機制等內容。整個特征抽取器處理的重要部分就是這個自注意力的管理機制,其能夠去除整個距離限制的影響因素,而主要考慮詞語之間的關系,整個處理機制效率高,針對上百個詞語也能夠快速完成詞語上下文、左右文等方面關系的分析挖掘與雙向標志。
3 業務需求分析
在整個模型的實驗與分析之中,第一步主要的任務是將模型的程序進行實現,主要通過程序框圖的方式進行展現,對整個系統實現流程進行闡述,以此來給出用戶登錄系統之后進行情感分析算法的運行與處理,并將最后的處理結果進行展現。詳細系統的處理流程如圖3所示。
程序框圖是進行程序設計的最基本依據。系統開始先對用戶是否已有賬號進行判斷,沒有賬號則進行注冊,再進行登陸,檢測到現有賬號則直接登錄,接著用戶輸入BV號,系統進行預測,向用戶返回結果。在整個程序的處理之中,從BERT模型的分析之中能夠看出,其關鍵處理部分是自身的注意力機制,具體此機制的示意圖如圖4所示。
在整個注意力機制的處理之中,其主要輸入的數據信息來源于BLSTM層,后者的輸出相當于注意力層的輸入,后續需要對這些不同的詞向量進行賦權操作,整個權值的大小與情感極性的分類息息相關,以此完成最終分類的確定,后續需要完成的處理為soft?max歸一化的操作。
4 模型實驗與分析
4.1 深度學習過程
1)實驗環境
對整個模型的程序流程處理過程闡述過后,后續需要對整個過程進行實現,第一步需要完成模型實驗環境的配置,具體配置信息如表1。
在整個環境的配置處理之中,主要采用的開發環境為IDEA,主要采用的開發語言為Java,以此完成整個模型的處理操作。
2)數據集
數據集為chnsenticorp中文情感分析評論語料。chnsenticorp分為四類:
ChnSentiCorp_htl_ba_2000:2000 條視頻評論re?view,label均衡。
ChnSentiCorp_htl_ba_4000:4000 條視頻評論re?view,label均衡。
ChnSentiCorp_htl_ba_6000:6000 條視頻評論re?view,label均衡。
ChnSentiCorp_htl_unba_10000:7000條,只有pos。
3)評價指標
本文實驗效果的評價指標為準確率Acc,在整個模型的處理過程之中,需要完成這些視頻評論的分析與處理,需要確定整個評論過程之中的積極評論、消極評論與中性評論的內容,并將這些評論數量在整個評論過程之中對應的比例進行闡述。
4)數據預處理
每一段評論都單獨在一個txt文件中,首先將其整合在一個txt文件中,每條評論占一行,再人工對每條評論進行標注,標簽-1表示負面文本,標簽0表示中性文本,標簽1表示正面文本,總共標注約2000條,將其中約200條提出作為驗證集,訓練集:驗證集=9:1,然后將訓練集和驗證集文件轉化成tsv格式。
5)BERT模型處理過程
BERT模型代碼分為幾個部分:classifier.py開始固定種子并進行微調訓練,configs.py確定了參數的設置,其中包括訓練集和驗證集的讀取路徑、隨機種子數,確定了batch_size=8,learning_rate=1e-05,epoch=5,dropout=0.3等超參數設置,model.py負責將BERT模型的輸出,一個768維的張量轉化為3維的輸出,代表了評論屬于正面評論、中性評論、負面評論的可能性,read_data.py負責讀取數據,test_code.py負責將測試用的數據代入模型運行得出結果,檢測模型的準確率。
4.2 模型訓練結果
1)處理結果模型訓練后會生成一個json 文件,記錄訓練結果。
{"micro/precision": 0.95, "micro/recall": 0.95, "mi?cro/f1": 0.9500000000000001, "macro/precision": 0.9340801538006507, "macro/recall": 0.8945502053004852,"macro/f1": 0.9121639784946236, "samples/precision":0.95, "samples/recall": 0.95, "samples/f1": 0.95, "accu?racy": 0.95, "labels/f1": {" -1": 0.96875, "0":0.7999999999999999, "1": 0.967741935483871}, "la?bels/precision": {" -1": 0.9489795918367347, "0":0.875, "1": 0.9782608695652174}, "labels/recall": {" -1": 0.9893617021276596, "0": 0.7368421052631579, "1": 0.9574468085106383}, "loss": 0.6011847257614136}
其中可以看到模型準確率為95%,判斷負面文本的概率是98.93%,正面文本的概率是95.74%,中性文本的概率為73.68%。
2)模型算法分析
在整個算法的分析過程之中,為了驗證整個處理模型的準確性,進行實驗的分析與對比,整個實驗分為兩種:第一個實驗需要完成不同云聯模型的對比實驗;第二個實驗需要將本系統采用的BERT實現的方法與其他方法進行分析與對比。
在第一個實驗的處理之中,由前文可以了解,目前語言的預訓練采用的方法有BERT、GloVe、Word2Vec,這些不同的訓練模型在針對同一個任務進行處理的時候,對這些實驗進行分析與對比,同時記錄每一個訓練模型的實驗結果,這些結果如表2所示。
從表2可以看出,將三者的處理結果進行對比,總體BERT模型在整個處理過程之中能夠對詞語的上下文進行提煉與管理,總體感情分類任務處理的效率與準確率會更高。為了確定整個BERT模型處理的準確性,需要對其文本情感分析有效性進行確認,核心的工作內容是完成準確率的計算,具體計算的結果如表3所示。
從中能夠看出本文采用的BERT方法相比機器學習與RNN等方法來說,總體準確率較高,具備良好的處理效果。
5 結論
雖然評論數據僅限制在了bilibili視頻平臺,但仍然有眾多的視頻分類包括音樂、舞蹈、游戲、知識、運動、生活等,這需要龐大的數據集進行訓練,而目前的數據集并沒有達到要求,也因此提供了管理員更新深度學習模型的功能,希望之后能收集到足夠多的數據進行訓練。
每個視頻平臺的前端頁面結構不同,爬取策略也會不同。為了方便起見,該系統目前僅限制在bilibili 視頻平臺進行爬取,希望之后可以針對不同的視頻平臺都可以進行視頻評論的獲取。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
