
基于校園一卡通數據的高校貧困生認定應用研究
2023-05-30 10:48:04王新雷史瑞剛
計算機應用文摘 2023年1期
王新雷 史瑞剛
關鍵詞:貧困生;校園一卡通;貧困認定;貧困識別
1引言
大學生貧困認定是當前社會關注的焦點之一。它不僅是一個簡單的貧困生問題[1],更是一個關系到家庭和社會的問題。為了促進教育公平,國家、高校、社會各界共同努力,建立了較為完善的學生資助政策體系,從多方面保證各學生能夠順利入學和完成學業。貧困生的認定一直是大學生資助管理的難題,貧困生的正確認定直接影響大學生資助管理的效果。但是,根據目前對我國高校學生資助管理中貧困生認定情況的調查,所有高校學生資助管理人員都承認貧困生認定的重要性,但同時也表示,在具體認定過程中,很難保證貧困生認定的合理性和正確性。
目前,一些研究人員已經利用學生的三餐消費、學校超市購物、上網消費等日常生活數據來識別和分析貧困學生。陳曉等[2]使用基于加權約束的決策樹方法構造了加權約束的決策樹來識別貧困生,提高了貧困生的識別效率。劉亮等[3]采用K-Means聚類方法來構造貧困生聚類指數,由此確定貧困大學生的貧困程度。王文娟等[4]使用校園一卡通數據進行描述性統計和非參數檢驗分析,得到了大學生在校園內的消費行為特征以及不同學生的消費差異,為貧困大學生的認定提供主要依據。趙丙賀[5]采用機器學習中的K-Means算法對校園一卡通的學生消費數據進行聚類分析,根據聚類結果將學生消費等級分為三個層次,并結合學生成績等數據得到貧困生認定標準。伍智鑫[6]利用聚類方法分析了學生校園一卡通消費特征數據,并對聚類的結果進行分類,實現了貧困生的高效精準認定。
本文通過采集學生三餐消費、學校超市購物、網絡消費等日常生活數據,將校園一卡通數據接人大數據平臺,結合學校大數據分析平臺,對貧困生的家庭情況和消費水平,以及學生的日常行為數據進行相關性分析和研究,建立科學合理的貧困生精準認定模型,精準確定貧困生資助對象,實現對貧困大學生的識別和監控,為差異化精準資助貧困生提供決策基礎,進一步提高學生資助部門的大學生資助工作的準確性和實效性。
2高校貧困生認定存在的問題
2.1認定模式單一
目前,高校認定貧困生的流程一般是通過學生提交的本年度貧困證明或相關困難證明(如《低保證》《建檔立卡證》)根據貧困程度進行認定。同時,建立班級貧困生鑒定工作組,經過鑒定組成員的民主鑒定,最終建立班級貧困生數據庫。
這種認定模式主要是班級評議小組根據材料和學生在校表現進行民主評議,過于依賴學生在校表現來評價學生。在沒有實地調查或有效取證的情況下,僅憑這兩項工作很難客觀了解學生家庭的真實情況。
2.2貧困認定標準不統一
由于不同地區居民收入水平存在較大差異,各地區貧困家庭的認定標準也必然不統一。學生在當地出具的貧困證明只表明該學生家庭在當地貧困,并不表明該學生在學校與其他同學相比貧困。因此,貧困是一個相對的概念,由于缺乏統一的標準,貧困生認定工作在實際操作中存在較大的難度。
2.3貧困證明材料不真實,貧困生身份難以分辨
由于相關部門對發放貧困證明不夠嚴謹,出現不審查家庭情況直接蓋章、找關系開證明、求人偽造貧困證明等情況,導致貧困生人數激增。另一方面,一些真正貧困的大學生為了自身的自尊心,會多填寫人均家庭年收入,這樣一來就會影響貧困生認定模型的正確構建,并且學校也沒有能力逐一分辨這些數據的真偽,最終將貧困資助指標下發給“假貧困生”,占了貧困生資助名額,致使真正貧困的大學生未能得到實際資助,給學校的貧困資助工作帶來潛在影響。
3基于校園卡平臺的貧困生數據倉庫建設
3.1貧困生數據倉庫建設
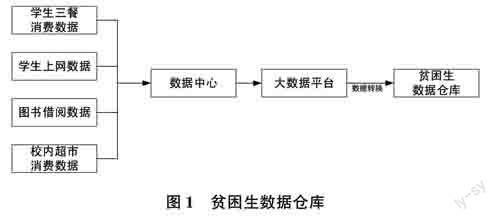
基于校園一卡通平臺和大數據應用開發平臺,收集學生三餐、學校超市購物、網絡消費等日常生活數據,使用大數據平臺分布式存儲系統,完成貧困生大數據的存儲,將貧困生數據與學生日常消費行為數據深度整合,建立學校貧困生大數據的數據倉庫,如圖1所示。
3.2基于人工干預的高效數據降維
在現有線性相關降維方法的基礎上,結合校園卡數據特點,引人人工干預方法,有助于直接提取、標記、篩選學生就餐消費信息和網絡消費等數據。然后,可以應用機器學習算法,對學生的飲食和網絡消費等數據建立一組強有力的關聯變量,為貧困生的評定分析做準備。
3.3貧困生數據倉庫的更新
由于每年都會有新生人校、畢業生離校,這就使得貧困人員信息處在動態變化中,為了更加精確地評定貧困生,我們需要對貧困生數據樣本開展數據治理,主要采用數據統計和大數據分析算法,過濾已經畢業的學生以及不能反映學生真實貧困情況的數據,及時完成貧困生數據倉庫的更新,確保貧困生數據的真實性和有效性。
3.4構建貧困生主題域
貧困生主題庫建設決定了對貧困生認定業務的支撐,須建立相關主題庫對校內學生消費信息進行統一整理與規范,還原校園一卡通學生消費的業務場景,將每個環節拆解后分析,圍繞一卡通消費的對象、消費行為、一卡通業務辦理展開,針對各類群體、各類消費類型、消費時間等維度,分析消費金額、消費次數、消費時間等,同時可以根據消費行為,分析低消費人群,作為貧困生資格的參考。貧困生主題庫的建設須結合校園卡平臺和學生實踐活動,了解數據產生與發展的狀況,充分理解數據內容,并在此前提下遵循以下兩大原則進行建立。
第一原則:遵循既定的校級數據標準規范。需要在建立相關主題表單的過程中嚴格遵循既定的校標數據項標準與規范,確保貧困生數據主題庫中數據項的唯一性與規范性。
第二原則:建立校內統一且認可的貧困生數據分類規則與方式。通過與大數據平臺對接,整理出貧困生主題域。
4基于校園卡數據的貧困生認定框架構建
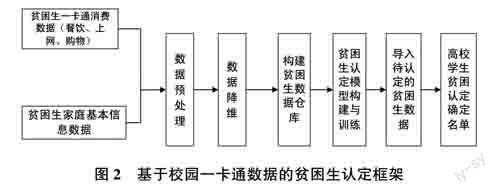
隨著高校信息化建設的不斷完善,各種信息系統積累了大量的學生日常校園生活數據,如學生食堂消費、家庭經濟狀況、移動賬單、一卡通、圖書借閱、網上消費等數據。這些數據可以對學生在校行為給出更準確的畫像,并結合同學和教師的民主評議結果,將這些數據采集到大數據平臺,通過構建貧困生識別模型,實現對高校貧困生的準確認定,其認定過程如圖2所示。
4.1貧困生數據庫采集
通過貧困生數據倉庫收集學生日常生活、學習、消費記錄,這些流水記錄包括學生身份信息、校園卡號碼、使用場所、消費金額等信息。
4.2數據預處理
學生一卡通數據來自不同數據庫,信息量大,數據類型多樣,導致實驗數據不完整、不一致、異常等問題。為了解決低質量數據的問題,需要對原始數據進行轉換,本文使用Python語言工具,首先對學生食堂消費、家庭經濟狀況、移動賬單、一卡通、圖書借閱、網上消費等數據進行挖掘,深度分析學生食堂消費、家庭經濟狀況、一卡通、圖書借閱、網上消費等學生個人信息。其次,結構化學生校園卡平臺數據,完成貧困生歷史數據、學生日常消費數據的融合。然后,針對貧困生數據庫中數據項有缺失的字段,進行缺失值填充,將貧困生樣本數據集中的缺失值評估填充為貧困生數據樣本屬性均值。最后,完成貧困生樣本數據離群數據挖掘,并對離群數據進行標注,完成貧困生大數據預處理工作。
4.3數據降維階段
通過采集學生的消費數據、上網數據、圖書借閱數據、家庭基本情況等數據,發現數據特征異常復雜,但是有一些字段的數據對于結果沒有影響,或者影響極小,我們需要根據實際情況,采用主成分分析方法對所采集的數據進行降維,盡量減少原指標包含信息的損失,以達到對所收集數據進行全面分析的目的。
4.4貧困生識別模型構建
將校園一卡通中學生的三餐消費、上網數據、圖書借閱等數據采集到大數據平臺后,采用機器學習算法中的Logistic方法,使用貧困生的基本消費數據和家庭情況數據構建貧困生認定模型。然后,利用往年的貧困生數據對貧困生識別模型進行訓練,得到最佳的模型參數,使得貧困生預測模型的結果更加精確。最后,使用優化后的貧困生識別模型對新貧困生進行識別和分析。由此可見,關于高校貧困生認定模型的建立是一個不斷優化的過程,隨著時間的推移和貧困生數據庫中數據的增加,貧困生識別模型將更加準確和有效。
4.5貧困生認定
將待識別的貧困學生數據導人大數據處理平臺,通過Python工具來計算學生近一個月的三餐消費、超市消費金額、上網消費等數據,形成貧困生特征向量。基于這些特征向量,形成貧困生數據集。同時,使用貧困生識別模型對形成的貧困生數據集進行識別,找出真實的貧困生,生成初步的貧困生名單。然后,由負責學生資助工作的老師對模型輸出的貧困生和貧困等級進行審核,最終確定貧困生名單。最后,將識別出的貧困生數據輸入貧困生數據庫,更新貧困大學生數據倉庫的數據,為貧困生認定模型的優化提供數據支撐。
5結束語
本文利用校園一卡通采集學生三餐消費、超市購物、上網消費等日常生活數據,建立貧困生數據倉庫,提出基于一卡通數據的貧困生認定流程,實現高校貧困生的識別和監控,為實施精準資助提供決策依據,從而建立科學合理的資助管理體系,提高學校貧困生資助工作的準確性。
