基于改進YOLOv5的安全帽檢測算法研究
2023-06-15 23:55:14胡曉棟王國明
計算機時代 2023年6期
關(guān)鍵詞:深度學(xué)習(xí)
胡曉棟 王國明
摘? 要: 針對現(xiàn)有的安全帽檢測算法參數(shù)量大,不利于嵌入式端部署,且密集目標(biāo)存在漏檢等情況,本文做出以下改進:對模型的主干特征網(wǎng)絡(luò)用更加輕量的MobileViTv2網(wǎng)絡(luò)進行替換并引入輕量級的無參卷積注意力模塊(SimAM),再結(jié)合大卷積核RepLKNet架構(gòu)對原有的超深小卷積核進行改進,在減少參數(shù)量的同時提升了精度。實驗結(jié)果表明,改進后的算法平均精度達到96%,提升了1.8%,模型大小降低了31%。同時能滿足實際場景對安全帽檢測精度和速度的要求。
關(guān)鍵詞: 深度學(xué)習(xí); YOLOv5; MobileViTv2; SimAM; RepLKNet; 安全帽
中圖分類號:TP389.1? ? ? ? ? 文獻標(biāo)識碼:A? ? ?文章編號:1006-8228(2023)06-76-05
Research on helmet detection algorithm based on improved YOLOv5
Hu Xiaodong, Wang Guoming
(College of Computer Science and Engineering, Anhui University of Science and Technology, Huainan, Anhuai 232000, China)
Abstract: In response to the existing helmet detection algorithm with large number of parameters, unfavorable for embedded end deployment, and dense targets with missed detection, the following improvements are made in this paper. The backbone feature network of the model is replaced by a more lightweight MobileViTv2 network and a lightweight non-parametric convolution attention module (SimAM) is introduced, and the original ultra-deep small convolution kernel is improved by combining with the large convolutional kernel RepLKNet architecture, which reduces the number of parameters and improves the accuracy. The experimental results show that the average accuracy of the improved algorithm reaches 96%, which increases by 1.8%, and the model size decreases by 31%. It can meet the requirements of accuracy and speed in the actual situation.
Key words: deep learning; YOLOv5; MobileViTv2; SimAM; RepLKNet; safety helmet
0 引言
在一些高危的現(xiàn)場施工環(huán)境中,未佩戴安全帽是違規(guī)操作。這種違規(guī)操作需要及時發(fā)現(xiàn)和被制止。近年來,基于深度學(xué)習(xí)的目標(biāo)檢測被廣泛應(yīng)用于人臉識別,行人識別,自動駕駛,工業(yè)檢測等領(lǐng)域。研究者從多層面對其作了許多研究,徐守坤等[1]在FasterR-CNN基礎(chǔ)上結(jié)合多尺度訓(xùn)練,增加錨點數(shù)量和在線困難樣本挖掘機制。賈峻蘇等[2]依托可變形部件模型,提出一種基于塊的局部二值模式直方圖,并增加合適的顏色特征與支持向量機(SVM)進行訓(xùn)練和檢測,得出一種適用性更廣,檢測準(zhǔn)確性更高的一種算法。張錦等[3]針對安全帽尺寸大小不一問題,提出用K-means++算法來重新設(shè)計相應(yīng)先驗框尺寸來匹配到特征層。肖體剛等[4]在YOLOv3的基礎(chǔ)上使用深度可分離卷積結(jié)構(gòu)來替換Darknet-53傳統(tǒng)卷積來縮減模型參數(shù)。算法往往參數(shù)量和計算量大,因此,本文對YOLOv5主干特征提取網(wǎng)絡(luò)進行輕量化網(wǎng)絡(luò)替換,并引入RepLKNet架構(gòu)對原有超深小卷積進一步改進,然后引入SimAM注意力機制加強對檢測對象的關(guān)注。算法改進后,能更好地滿足在低算力設(shè)備平臺上部署的需求。
1 YOLOv5s相關(guān)技術(shù)
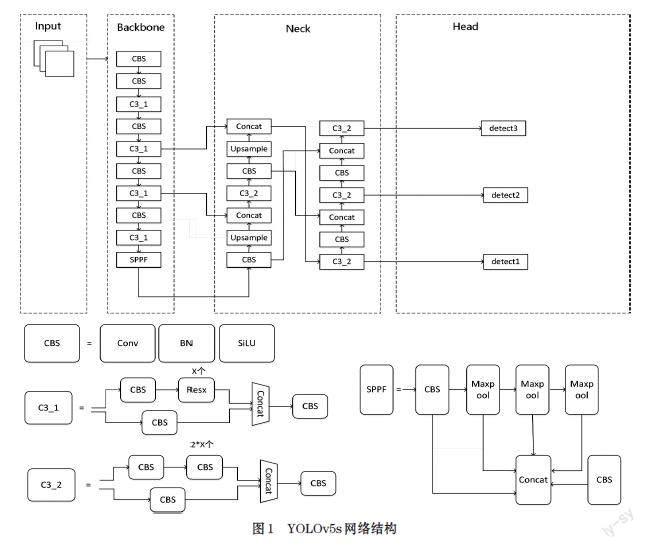
YOLOv5s分為輸入端(Input)、backbone、neck以及輸出端(Output)四部分。輸入部分包括馬賽克增強(Mosaic)、仿射變換(Random Affine)、Mixup增強、HSV色域空間增強等。Backbone部分核心包括CBS卷積模塊、C3結(jié)構(gòu)、SPPF模塊。CBS模塊由二維卷積Conv2d,批量歸一化處理(Batch Normalization)和SiLU激活函數(shù)串聯(lián)而成;C3模塊分為上下倆支路,上支路通過三個標(biāo)準(zhǔn)卷積層和多個Bottleneck模塊連接,下支路通過標(biāo)準(zhǔn)卷積處理和上支路進行拼接;SPPF采用多個小尺寸池化核并聯(lián)且級聯(lián)的方式融合不同感受野的特征圖,同時進一步提升運行速度。Neck部分采用FPN+PAN的自頂向下以及自底向上相結(jié)合的特征金字塔結(jié)構(gòu)進行多尺度融合后輸出到head部分,交由三個不同尺寸的檢測頭生成預(yù)測候選框和類別,使用CIoU_LOSS損失函數(shù)對目標(biāo)進行回歸修正,通過加權(quán)非極大值抑制來消除大量冗余框來進一步提高對目標(biāo)的識別準(zhǔn)確度。YOLOv5s結(jié)構(gòu)如圖1所示。
2 改進模型
2.1 主干網(wǎng)絡(luò)優(yōu)化
原有的YOLOv5s采用的C3結(jié)構(gòu)參數(shù)量大,檢測速度慢,應(yīng)用上受限,在移動端,嵌入式設(shè)備上使用不友好,容易面臨內(nèi)存不足問題的發(fā)生,從而將原有的C3結(jié)構(gòu)的主干特征提取網(wǎng)絡(luò)部分替換成更加輕量級的MobileViTv2,它結(jié)合卷積CNN和ViT的優(yōu)勢,來構(gòu)建移動視覺任務(wù)中的輕量級和低延遲網(wǎng)絡(luò),代替?zhèn)鹘y(tǒng)卷積用于神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)視覺表征,可有效將全局和局部信息進行編碼,更好的對安全帽進行全局學(xué)習(xí)表示,同時也不需要特別復(fù)雜的數(shù)據(jù)增強方法來對此訓(xùn)練,能夠一定幅度的降低參數(shù)計算量,加快檢測速度,減少顯存占用情況,對移動設(shè)備友好。
2.1.1 MobileViTv2模型
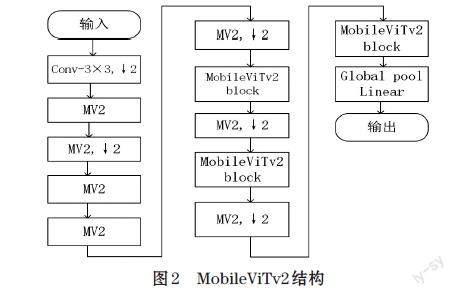
文獻[5]提出了MobileViTv2結(jié)構(gòu),如圖2所示,其中的MV2是MobileNetv2的縮寫,它是一種Inverted Residual倒殘差結(jié)構(gòu)。對于之前的殘差結(jié)構(gòu)ResNet[6]是倆頭寬,中間窄,但由于更高的維度經(jīng)過激活函數(shù)后,它損失的信息會少一些,從而采用MV2結(jié)構(gòu),通過1×1卷積進行升維,中間用3×3卷積進行DW(深度可分離卷積)操作,結(jié)束時再用1×1卷積進行降維保持倆頭窄,中間寬來減少信息的損失。對于MobileViT block,對輸入特征先進行3×3標(biāo)準(zhǔn)卷積層進行局部信息建模,然后通過1×1卷積核進行通道數(shù)調(diào)整,再采用Unfold->Transformer->Fold進行全局信息的建模,在v2版本中取消了v1版本的shortcut連接和融合模塊,接著再通過1×1卷積核調(diào)整為原來通道大小得到輸出。由于和所有像素點進行自注意力操作會帶來一定程度的信息冗余,為了減少參數(shù)量,只對相同位置的像素點進行點積操作。針對MobileViT中的效率瓶頸多頭自注意力(MHA),因為token數(shù)量需要的時間復(fù)雜度為O(k2),代價較大,所以提出了一種線性復(fù)雜度為O(k)的可分離自注意力方法。其成為資源受限設(shè)備上的較好選擇,如圖3所示。
2.1.2 MobileViTv2模型的優(yōu)化
由于非線性激活函數(shù)ReLU對低維特征信息會造成較大損失,高維信息損失不大,而倒殘差結(jié)構(gòu)最終輸出的低維特征信息,所以在最后一層卷積層用線性激活函數(shù)來避免損失。
swish函數(shù)是一種比ReLU更佳的激活函數(shù),它包含sigmoid函數(shù),相比之下計算開銷更大,而ReLU6函數(shù)相對來說比較簡單,所以選用h-swish函數(shù)來代替。
swish函數(shù)如式⑴所示:
[swishx=x*sigmoid(βx)]? ? ⑴
h-swish函數(shù)如式⑵所示:
[h-swishx=xReLU6(x+3)6]? ? ⑵
2.2 融合SimAM注意力模塊
SimAM[7]是一種對卷積神經(jīng)網(wǎng)絡(luò)簡單有效的無參數(shù)3D注意力模塊,在不增加原有網(wǎng)絡(luò)參數(shù)的情況下,為特征圖(feature map)推斷三維注意力權(quán)重。設(shè)計出一款能量函數(shù)來生成快速解析解來挖掘出每個神經(jīng)元的重要程度并分配權(quán)重。它可以隨意嵌入到現(xiàn)在的卷積神經(jīng)網(wǎng)絡(luò)中來,具有靈巧便捷性,可支持即插即用。模型如圖4所示。
在已有研究中,BAM和CBAM[8]分別采用并行和串行方式關(guān)注通道以及空間注意力。而人類神經(jīng)網(wǎng)絡(luò)需要同時協(xié)同處理這倆種注意力,因此SimAM能更好的把倆者統(tǒng)一起來。以下是SimAM的能量函數(shù),如式⑶所示。
[etwt,bt,y,xi=yt-t2+1M-1i=1M-1(y0-xi)2]? ⑶
其中[X∈RC×H×W],[t]和[xi]分別屬于X下通道的目標(biāo)神經(jīng)元和其他神經(jīng)元,[wt]和[bt]分別表示權(quán)重和偏置,M代表該通道上的神經(jīng)元個數(shù),i是空間上的索引值。進一步可得出最終能量函數(shù),如式⑷所示。
[etwt,bt,y,xi=1M-1i=1M-1-1-wtxi+bt2+1-wtt+bt2+λwt2] ⑷
當(dāng)能量(energy)越低,神經(jīng)元t與周圍神經(jīng)元的區(qū)別越大,重要程度也越高。每個神經(jīng)元其重要性可由最小能量的倒數(shù)表示。按照注意力機制,需對特征進行進一步增強處理。如式⑸所示。
[X=sigmoid1E☉]X? ?⑸
經(jīng)過多次實驗后,將SimAM注意力模塊加在backbone倒數(shù)第二層效果最好。
2.3 卷積核改進
以往卷積神經(jīng)網(wǎng)絡(luò)偏向于多個小卷積代替大卷級核,但在現(xiàn)有CNN技術(shù)加持下,使用一種更大的卷積核31×31的RepLKNet[9]的設(shè)計范例來代替超深小卷積核更具有優(yōu)勢。其中,深度的增加,會帶來訓(xùn)練問題,盡管ResNet通過殘差連接很好的解決了這個問題,但ResNet的有效感受野沒有得到很好的增加,根據(jù)有效感受野特性,與卷積核大小成線性關(guān)系,與深度成次線性關(guān)系,對此,RepLKNet憑借大卷積核的設(shè)計避免了過多的層就能有著更大的有效感受野和更高的形狀偏差。同時引入Identify shortcut和結(jié)構(gòu)重參數(shù)化的方法來解決大卷積核難以兼顧局部性的特征,容易出現(xiàn)過度平滑的現(xiàn)象問題。結(jié)構(gòu)如圖5所示。
RepLKNet結(jié)構(gòu)包括以下三個部分,Stem部分作為開始階段,使用帶有倆倍下采樣的3×3卷積,后接一個3×3的深度可分離卷積來捕獲低維特征,最后使用一個1×1卷積核和3×3的深度可分離卷積進行下采樣,該層對輸入圖像進行升維以及尺寸縮減。Stage階段作為核心層,包括RepLKBlock和ConvFFN倆部分堆疊而成,RepLKBlock由批量歸一層,1×1卷積,3×3深度可分離卷積以及最重要的殘差連接。FFN包括倆個全連接層,而ConvFFN用1×1卷積代替了原有的全連接層,同樣也具備層間殘差連接。Transition層放在Stage層之間,通過1×1卷積擴大特征維度,然后再由3×3深度可分離卷積進行倆倍下采樣。
RepLKNet和原模型YOLOv5s中超深小卷積相比,能減少一定參數(shù)量,并提高安全帽檢測模型精度。
3 實驗分析
3.1 實驗所需環(huán)境和參數(shù)
本次所有實驗都在Ubuntu操作系統(tǒng)下,使用的GPU是NVIDIA GeForce RTX 3080,顯存10GB,CPU為AMD EPYC 7601,深度學(xué)習(xí)框架采用的是Pytorch1.10.0,Cuda11.1.1,Python3.8。
所用數(shù)據(jù)集為公開的安全帽數(shù)據(jù)集,總共7581張圖片,按8:2比例進行劃分訓(xùn)練集和測試集,并以VOC形式標(biāo)記好,再將標(biāo)記標(biāo)簽XML格式轉(zhuǎn)化為YOLOv5所接受的txt格式,數(shù)據(jù)集標(biāo)簽分為倆大類,一類是戴了安全帽的人,標(biāo)簽為“hat”,另一類是未戴安全帽的人,標(biāo)簽為“person”。實驗所需超參數(shù)如表1所示。
3.2 消融實驗
為了進一步驗證改進的模塊對目標(biāo)模型檢測有效果,以下采取消融實驗進行比較,將MobileViTv2簡記為MVT2,改進1模型在原有網(wǎng)絡(luò)中單獨使用輕量級模型MobileViTv2進行特征提取;改進2模型在改進1基礎(chǔ)上融合注意力模塊SimAM;改進3模型在改進2模型的基礎(chǔ)上改進為大卷積核RepLKNet架構(gòu),得到最終目標(biāo)模型,記為YOLO-M。消融實驗結(jié)果見表2。
由表2數(shù)據(jù)可以看出,主干網(wǎng)絡(luò)替換成MobileViTv2后參數(shù)量下降了將近四分之一,平均精度降了0.7個百分點,融合SimAM注意力機制后與換成輕量級網(wǎng)絡(luò)相比,精度有所提升1.6個百分點。原有的YOLOv5s中Neck部分超深小卷積核替換為大卷積核RepLKNet后,精度提升了0.9個百分點。最終融合以上技術(shù)改進后的YOLOv5s模型在參數(shù)量得到了一定幅度減少的同時精度也提升了1.8個百分點,基本滿足現(xiàn)場環(huán)境對安全帽的實時檢測。
3.3 改進后的模型與其他算法對比
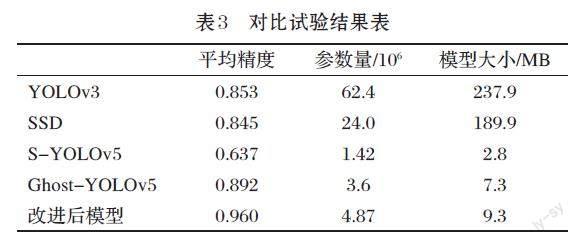
將改進后的模型與其他主流算法進行對比實驗,來對其性能進行分析,進一步驗證改進后的模型的可行性和優(yōu)越性,同時將ShuffleNetv2-YOLOv5簡記為S-YOLOv5,對比試驗結(jié)果如表3所示。
由實驗結(jié)果可知,改進后的模型跟ShuffleNetv2-YOLOv5和Ghost-YOLOv5相比,雖然模型大小稍顯大,但平均精度分別提升了32.3個百分點和6.8個百分點。與主流目標(biāo)檢測模型YOLOv3和SSD相比,不僅在精度上有所提升,同時模型大小也得到了大幅的減少。相較于當(dāng)前的基于輕量級檢測網(wǎng)絡(luò)和主流檢測算法,改進后的模型在速度和精度平衡上都有比較好的表現(xiàn)。
3.4 檢測結(jié)果分析
為了更直觀的表達檢測效果,選取了目標(biāo)不密集以及密集目標(biāo)情況下的檢測效果圖做對比觀察。在不密集情況下,改進后的輕量級模型檢測效果比原模型要好。在密集情況下,對于出現(xiàn)的遠處小目標(biāo)對象也能很好的檢測出來。結(jié)果如圖6所示。
4 結(jié)束語
對于現(xiàn)有的安全帽檢測所需參數(shù)量和計算量比較大,現(xiàn)提出一種對原模型進行輕量化改進,對主干網(wǎng)絡(luò)用MobileViTv2網(wǎng)絡(luò)模型進行替換,在主干特征提取網(wǎng)絡(luò)部分倒數(shù)第二層融合SimAM注意力模塊,參照大卷積核架構(gòu)對Neck部分超深小卷積進行替換。實驗表明,在保持較高精度的同時,計算量,參數(shù)量和模型大小都得到了大幅度下降,能滿足嵌入式設(shè)備上使用的要求。
參考文獻(References):
[1] 徐守坤,王雅如,顧玉宛,等.基于改進Faster RCNN的安全帽
佩戴檢測研究[J].計算機應(yīng)用研究,2020,37(3):901-905
[2] 賈峻蘇,鮑慶潔,唐慧明.基于可變形部件模型的安全頭盔佩
戴檢測[J].計算機應(yīng)用研究,2016,33(3):953-956
[3] 張錦,屈佩琪,孫程,等.基于改進YOLOv5的安全帽佩戴檢
測方法[J].計算機應(yīng)用:1-11[2022-10-27].http://kns.cnki.net/kcms/detail/51.1307.TP.20210908.1727.002.html
[4] 肖體剛,蔡樂才,高祥,等.改進YOLOv3的安全帽佩戴檢測
方法[J].計算機工程與應(yīng)用,2021,57(12):216-223
[5] Mehta S, Rastegari M. Separable Self-attention for Mobile
Vision Transformers[J].arXiv preprint arXiv:2206.02680,2022
[6] He K, Zhang X, Ren S, et al. Deep residual learning for
image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition,2016:770-778
[7] YANG L X,ZHANG R Y,LI L,et al.SimAM:a simple,
parameter-free attention module for convolutional neural networks[C]//Proceedings of the 38th International Conference on Machine Learning.New York: PMLR,2012:11863
[8] SH W,PARK J,LEE J Y,etal.CBAM:convolutional block
attention module[C]//Lecture Notes in Computer Science. Munich,GERMANY:IEEE,2018:3-19
[9] Ding X, Zhang X, Han J, et al. Scaling up your kernels to
31x31: Revisiting large kernel design in cnns[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition,2022:11963-1197
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
