基于特征圖像生成的Android惡意軟件檢測方法
2023-06-15 09:27:12曹曉梅王少輝
計算機技術與發展 2023年6期
陳 非,曹曉梅,王少輝
(南京郵電大學 計算機學院、軟件學院、網絡空間安全學院,江蘇 南京 210003)
0 引 言
近年來,Android操作系統在中國的市場份額不斷提高,其在2021年第四季度的市場份額已經達到78%[1]。然而,Android操作系統的飛速發展不僅帶來市場份額的提高,也帶來許多安全問題。360發布的《2021年度中國手機安全狀況報告》[2]顯示,360安全大腦在2021年共截獲移動端新增惡意軟件樣本約943.1萬個,平均每天截獲新增手機惡意軟件樣本約2.6萬個。不法分子利用Android應用植入廣告、竊取隱私,嚴重威脅用戶的財產和隱私安全,設計合理可行的Android惡意軟件檢測方法至關重要。
傳統的Android惡意軟件檢測方法包括三種:基于靜態分析、動態分析以及機器學習的檢測方法。基于靜態分析的方法[3-5]通過提取簽名、權限、組件等特征,生成特征匹配字典,將未知應用的特征與字典進行匹配,根據得到的相似度判定是否屬于惡意軟件。靜態分析方法操作簡單,但檢測類型單一、誤報率較高。基于動態分析的方法[6-9]是指在沙盒或虛擬機運行Android應用程序,通過監聽和分析應用程序在運行過程中行為和運行狀態的變化,如系統調用事件、潛在的劫持行為、數據流等,判斷是否屬于惡意軟件。動態分析方法準確率高于靜態分析方法,但動態分析方法需要運行應用程序,分析所需要的時間較長。基于機器學習的檢測方法通過對大量的樣本提取特征和訓練,生成分類模型,從而實現對惡意軟件的檢測。SVM、KNN、隨機森林、Stacking等傳統機器學習算法已經被應用到Android惡意軟件的檢測中[10-13],并且檢測準確率相較于基于靜態分析和動態分析的方法有了較大提高,但基于機器學習的檢測方法存在特征分布不平衡、難以挖掘特征之間深層聯系等問題,限制了其準確率的進一步提高。
相比于傳統機器學習,深度學習具有自適應提取特征和挖掘特征深層聯系的優勢,此優勢也是深度學習能夠在圖像分類、文本預測等方面成功實踐的原因所在。針對傳統機器學習檢測Android惡意軟件存在的問題,結合深度學習的優勢和成功實踐,深度學習應用到Android惡意軟件檢測可以取得較好的結果。目前,深度學習算法[14-19]在Android惡意軟件檢測中已有應用,且取得了一定成果,但仍存在不足:(1)用于分類模型訓練的數據表征能力偏弱,制約模型的收斂速度和檢測精度;(2)檢測不同類別相似度較高的樣本時,存在較大的漏報數和誤報數,導致算法最終的檢測準確率降低。
針對不足之處,該文提出一種基于特征圖像生成的Android惡意軟件檢測方法(Android Malware Detection Method Based on Feature Image Generation,FIG-AMD)。FIG-AMD方法針對訓練數據表征能力偏弱的問題,提取APK文件的權限、API、操作碼作為特征,挖掘各自的頻繁特征項集,使用降噪自編碼器(Denoising Autoencoder,DAE)抽取信息和轉換維度,將經過DAE處理的各特征進行融合,生成RGB特征圖像。該方法生成的特征圖像融合了多種特征,具有更好的表征能力。針對難以檢測相似度較高樣本的問題,該文設計了BaggingCNN分類算法,BaggingCNN使用 Bootstrap抽樣構造子訓練集,并訓練基于Bagging的多個CNN分類器用于檢測Android惡意軟件。實驗證明,FIG-AMD方法可以有效對Android惡意軟件進行檢測,且有著較低的誤報率。
1 相關工作
Imtiaz等人[14]提出DeepAMD惡意軟件檢測模型,該模型主要使用人工神經網絡(Artificial Neural Network,ANN)構建,選取權限、API、Intent Filter作為特征,盡管實驗表明該模型的檢測性能優于多數機器學習模型,但文中取得的二分類的準確率(93.40%)仍然偏低,主要原因是ANN存在梯度消失或梯度爆炸的問題,降低了檢測模型的擬合程度。超凡等人[15]提取APK文件應用組件、Intent Filter、權限等特征,并使用遺傳算法進行特征選擇以降低維度,最后使用深度神經網絡(Deep Neural Network,DNN)進行分類檢測,該方法提取的特征很充分,但提取的特征維度較高,增加了特征篩選的時間開銷。Elayan等人[16]使用API調用和權限作為特征,使用循環神經網絡(Recurrent Neural Network,RNN)中的門控循環單元(Gated Recurrent Unit,GRU)進行分類檢測,該方法雖然準確率等指標很高,但訓練模型使用的數據集數目較少,存在泛化能力弱的問題。孫志強等人[17]提出一種基于深度收縮降噪自編碼網絡的檢測方法,使用權限、API 等作為特征,使用貪婪算法自底向上訓練每個收縮降噪自編碼網絡,以抽取原始特征信息,最后使用反向傳播算法進行訓練和分類,該方法檢測效果優異,但缺少對重要特征的篩選,會增加分類模型的訓練時間。Xiao等人[18]針對現有檢測方法存在的數據模糊、代碼覆蓋范圍有限的問題,直接從Dalvik字節碼(classes.dex)中學習惡意軟件的特征,生成RGB圖片并使用卷積神經網絡(Convolutional Neural Network,CNN)進行分類檢測,該方法檢測時間遠低于其它方法,但缺少對敏感特征的關注,導致圖像的表征能力偏弱,進而影響了CNN 模型的收斂速度和檢測精度。Yen等人[19]提出基于代碼重要性和可視化深度學習的檢測方法,該方法根據TF-IDF計算APK文件源代碼每個單詞的重要值,經過分組和排序,使用Simhash和Djb2算法生成RGB圖片,并使用CNN進行訓練和分類,該方法特征單一且存在特征信息丟失,降低了CNN的分類性能 。
與同類工作相比,該文的主要貢獻和創新點體現在以下三點:(1)在特征預處理方面,對APK文件的多種特征進行提取,使用改進的FPGrowth算法對提取到的特征進行挖掘,有效過濾了低頻特征,提高了特征組合的合理性;(2)使用DAE抽取特征數據深層次信息和轉換特征向量維度,將經過DAE處理的權限、API、操作碼對應的特征向量合成為三維RGB圖片作為特征圖像。該方法生成的特征圖像具有較好的表征能力,分類算法可以很好地從中學習到不同類別Android應用的行為特征,進而有效的識別出惡意軟件;(3)分類算法對多個CNN分類器進行集成,并將Bagging算法的Bootstrap抽樣方法和多數投票機制遷移到該算法,設計出BaggingCNN分類算法。該算法通過多分類器集成提升了算法的分類能力,可以有效檢測出不同類別相似度較高的樣本,進而算法的檢測準確率、召回率、精準率均有提高。
2 FIG-AMD方法
FIG-AMD流程如圖1所示,包括特征預處理、特征圖像生成、BaggingCNN訓練和分類三個階段。
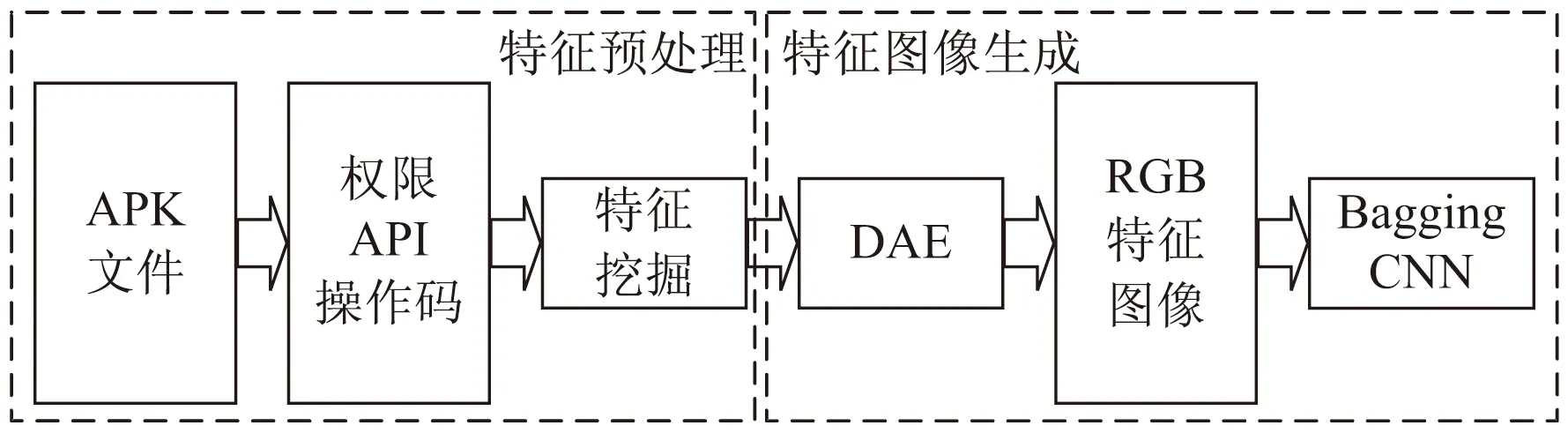
圖1 FIG-AMD流程
特征預處理階段提取APK文件的多種特征并對特征進行挖掘;特征圖像生成階段,生成RGB特征圖像用于訓練和分類;BaggingCNN訓練和分類階段,對生成的特征圖像進行訓練,調整優化算法參數,并對算法進行測試。
2.1 特征提取
該文使用特征匹配的方法對APK文件的權限、API、操作碼進行提取,其流程如圖2所示。使用Google提供的開源工具apktool反編譯APK文件得到兩種類型的文件,從Xml文件提取權限特征,從Smali文件提取API特征和操作碼特征,各特征提取步驟如下所述:
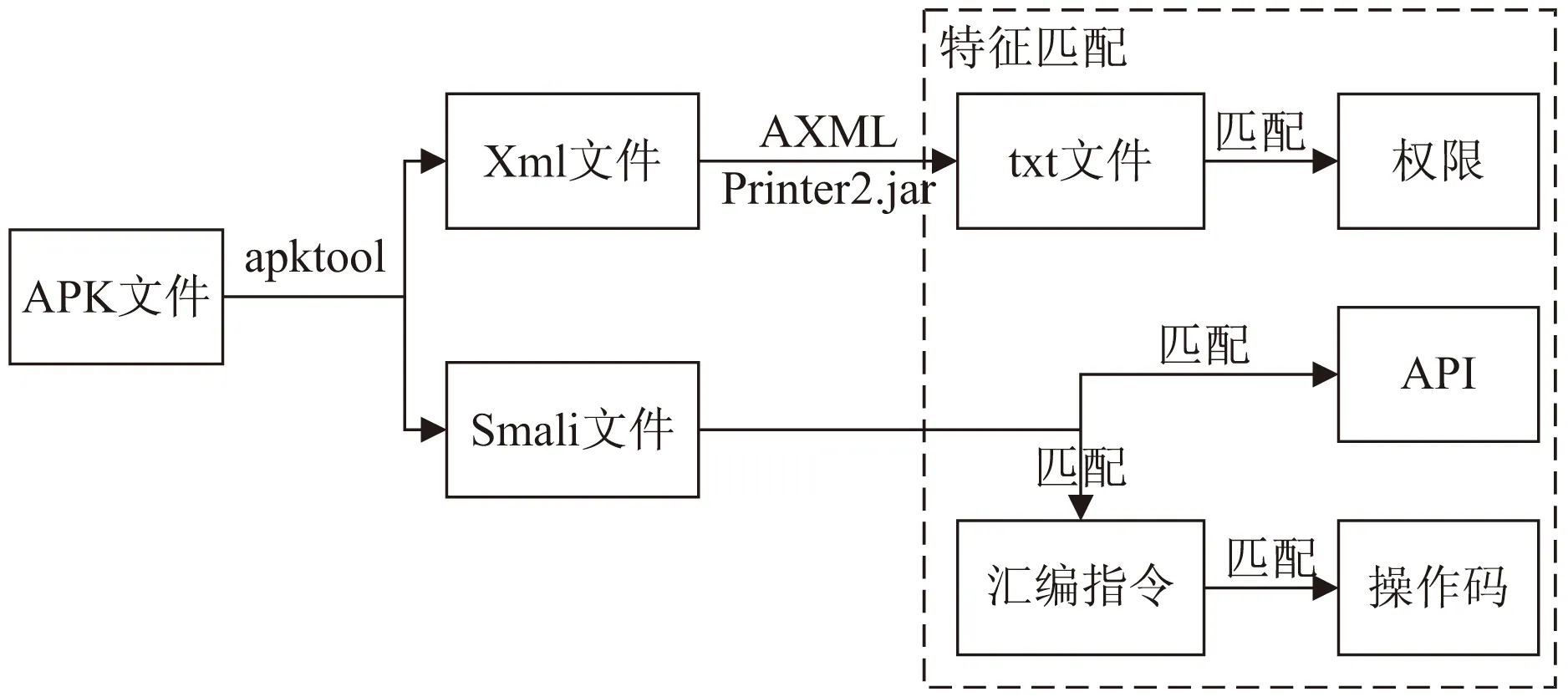
圖2 特征提取方法基本流程
(1)權限:首先將文獻[20]提供的權限列表構造成權限匹配字典;再利用AXMLPrinter2.jar靜態工具反編譯Xml文件得到txt文件;最后使用權限匹配字典對txt文件的內容進行匹配,得到相應的權限特征。
(2)API:首先將文獻[20]提供的API調用列表構造成API匹配字典;再使用API匹配字典對Smali文件對應的每行語句進行匹配,得到相應的API特征。
(3)操作碼:Dalvik定義了256個指令,這些指令包含move、return、invoke等基本操作碼,該文根據這些指令的功能進行分類(如:move/from16、move-object/16歸為M指令;goto/16、goto/32歸為G指令),得到指令匹配字典。由于指令之間存在序列關系,假設其遵循馬爾可夫性質并引入3-gram操作碼序列。針對反編譯得到的Smali文件,首先使用指令匹配字典對Smali文件的.method部分進行匹配,并將得到的指令轉為相應的M、G等指令名,加入到操作碼序列中;文件遍歷完成后,再以3作為滑動窗口的長度提取3-gram操作碼,如:{M,G,L,V}→{MGL,GLV},即得到操作碼特征。
2.2 特征挖掘
FPGrowth[21]算法挖掘相關性較高的特征組合,即頻繁特征項集。由于特征集合的樣本個數和維度均較大,而FPGrowth算法僅適合于小規模數據集,直接使用FPGrowth算法挖掘頻繁特征項集會較為耗時。因此,該文設計了基于FPGrowth算法的局部頻繁特征項集挖掘方法FPGrowth-r,其實現步驟如下:
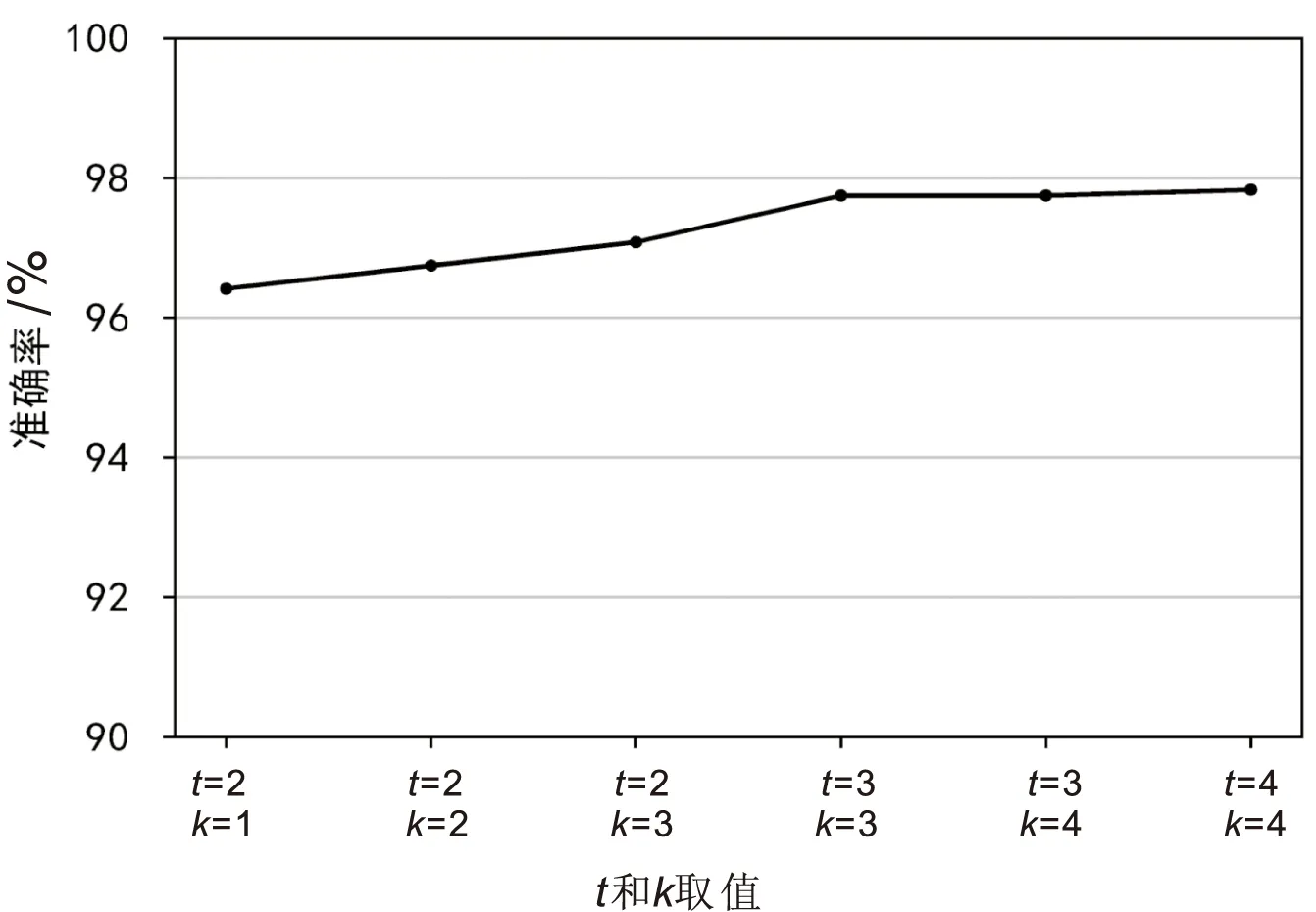
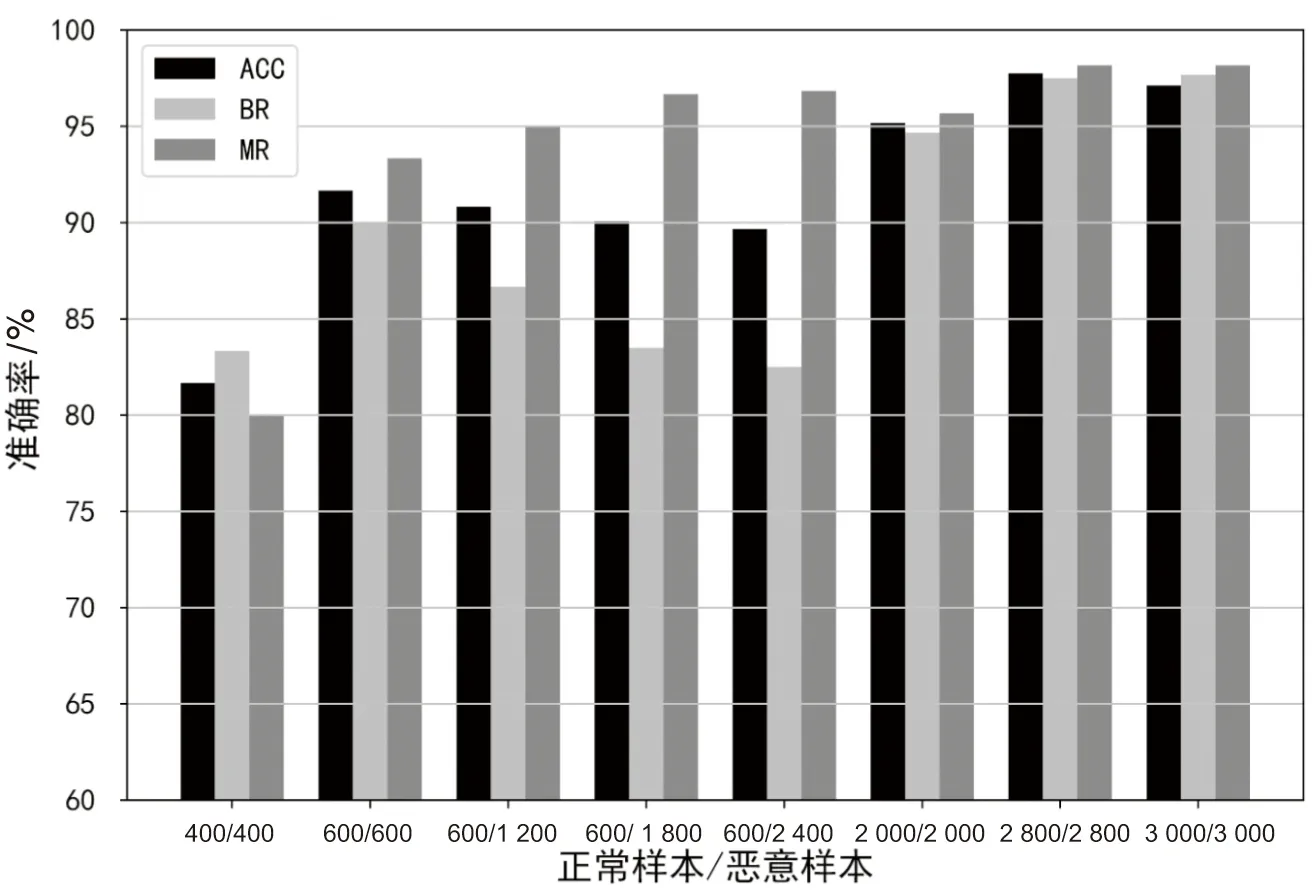
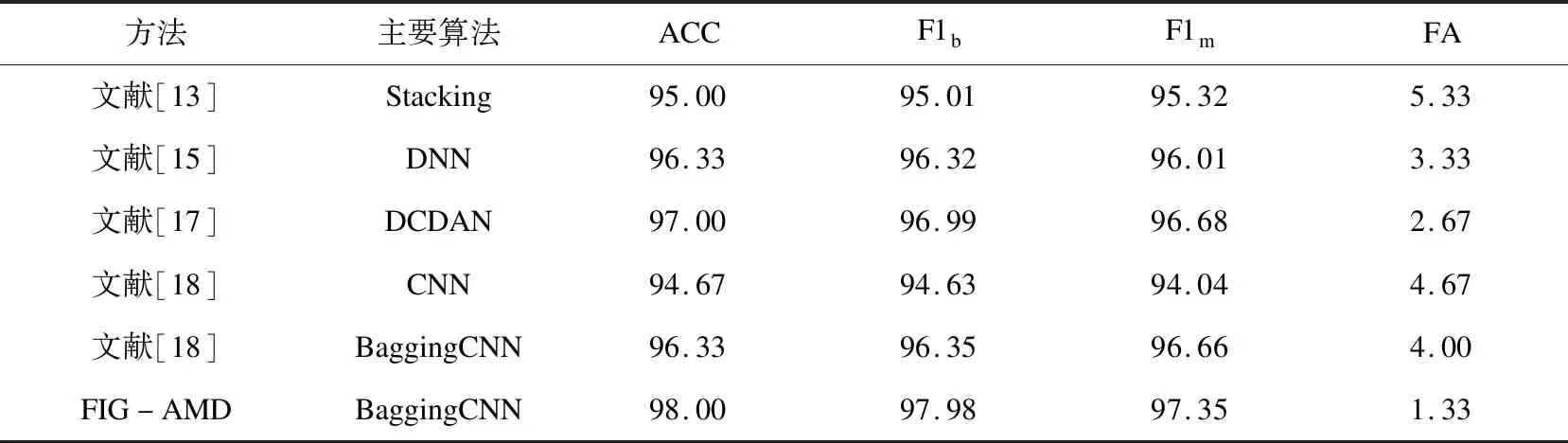
(1)將特征集合S分成k組,前k-1組每組n個特征,第k組num-n*(k-1)個特征,記第i組特征集合為Si,其中num為S的特征個數,且0 (2)使用FPGrowth算法挖掘Si的頻繁特征項集(FPGrowth算法的支持度大小設置為support),得到若干個不同的頻繁特征項集,取特征個數最多的項集作為Si的局部頻繁特征項集,記為Gi。 (3)對k組特征集合按步驟(1)(2)進行局部頻繁特征項集挖掘,得到G1,G2,…,Gk,計算Global=G1∪G2∪…∪Gk,即得到全局頻繁特征項集Global。 (4)對權限、API、操作碼按步驟(1)(2)(3)進行挖掘,得到各自的Global并進行過濾,最后將過濾完成的特征轉為01型特征向量(1表示包含某特征項,0表示不包含)。 降噪自編碼器[22]在輸入數據中加入了一定比例的噪聲數據,從而使得DAE網絡的反向傳播過程迫使隱藏層學習到的特征數據具有更強的魯棒性,進而增強了隱藏層輸出數據的表征能力。因此,該文使用DAE對特征信息進行抽取和轉換特征向量維度。 生成的特征圖像大小為[3,w,w],即經過DAE處理后的特征向量長度為w*w,則隱藏層最后一層神經元的個數應設置為w*w。為避免DAE處理后的特征向量過于稀疏化而影響特征圖像的表征能力,使用式(1)對最佳的w進行計算,即w取使得式(1)中value最小的正整數。分別對權限、API、操作碼的特征向量使用DAE進行處理,DAE經過訓練,損失函數值達到最小,使用式(2)計算DAE處理后的特征向量,即得到大小為w*w的特征向量。 value=|3w2-(npermission+napi+nopcode)| (1) (2) RGB特征圖像生成的流程如圖3所示。DAE對權限、API、操作碼對應的特征向量進行信息抽取和維度處理,對于同一個APK文件,其對應3個大小為w*w的線性特征向量。首先將線性特征向量轉換成大小為[w,w]二維特征向量,再對各二維特征向量增加一個通道,轉換成單通道圖像,維度變成[1,w,w],最后將3個二維特征向量在新增的維度進行拼接,即三個特征向量分別作為RGB圖片的R、G、B三個通道,其維度變成[3,w,w],得到最終的RGB特征圖像。 圖3 RGB特征圖像生成流程 針對單一分類算法魯棒性偏差、檢測不同類別相似度較高樣本誤差較大的問題,設計BaggingCNN分類算法,如圖4所示。BaggingCNN分類算法將不同的CNN算法根據特征圖像大小重新配置網絡參數和網絡深度,并將這些CNN算法作為子分類器進行集成,子分類器對不同的子訓練集進行訓練和分類,得到若干個分類結果,根據多數投票機制得到最終的分類結果。BaggingCNN分類算法的具體實現步驟如下所述: 圖4 BaggingCNN分類算法設計 (1)對于特征優化模塊生成的n個RGB特征圖像,該文按照一定比例將其劃分成a個訓練樣本和n-a個測試樣本,a個訓練樣本中包括a1個正常樣本,a-a1個惡意樣本。為防止隨機抽取出現樣本分布不平衡的問題,采用Bootstrap抽樣(有放回的均勻抽樣)方法,分別從正常樣本中隨機抽取a1/a*m個樣本,從惡意樣本中隨機抽取(a-a1)/a*m個樣本,共計m個樣本。抽取共進行k輪,得到k組子訓練集,每組子訓練集均使用t個不同的CNN算法進行訓練。 (2)t個CNN算法分別對k個子訓練集進行訓練,經過一定輪次的迭代更新算法參數,其分類性能達到最優,得到t*k個子CNN分類器。t*k個子CNN分類器分別對b個測試樣本進行預測,每個子分類器均得到b個關于測試樣本的預測結果和b個預測結果對應的概率大小。 (3)分別對t*k個CNN分類器得到的結果進行投票,1為惡意軟件,0為正常軟件。對于同一個測試樣本得到的t*k個分類結果,若sum(CNNi[j]) ≥ceil(t*k/2),則認為該樣本為惡意軟件,反之則認為是正常軟件。若出現票數相等的情況,則比較P1和P2的大小,P1大則認為是惡意樣本,反之則為正常樣本。其中,sum表示求和;CNNi[j]為第i個CNN分類器預測第j個樣本的結果;ceil(t*k/2)表示CNN子分類器個數k除以2并向上取整,P1表示預測為惡意樣本的平均概率,P2表示預測為正常樣本的平均概率。 實驗環境為:Windows10操作系統,8 GB運行內存,CPU為lntel i7-7500U,GPU為NVIDIA GeForce 940MX;深度學習框架為Pytorch1.6,編程語言為Python3.7。 FIG-AMD方法的數據集分為良性樣本和惡意樣本。惡意樣本共4 000個,其中426個來自CIC數據集、2 825個來自Drebin數據集、749個來自VirusShare數據集。良性樣本共4 000個,其中1 168個來自CIC數據集,另外2 832個為筆者使用爬蟲爬取的APK文件,其均經過病毒檢測網站VirusTotal檢測,均未發現存在風險,故標記為良性。該文將訓練集和測試集按照7∶3劃分,即訓練集5 600個,測試集2 400個。 針對FIG-AMD方法的評估,主要包括檢測能力、學習能力和泛化能力等方面。檢測能力的評估指標包括如下5個指標,其中TP、TN、FP、FN分別表示良性軟件分類成良性軟件、惡意軟件分類成惡意軟件、惡意軟件分類成良性軟件、良性軟件分類成惡意軟件的數目。 (1)準確率(Accuracy,ACC):正確檢測出來的正常軟件個數和惡意軟件個數總和占所有軟件個數的比例。 (3) (2)良性召回率(Benign Recall,BR):正確檢測出來的正常軟件個數占所有良性軟件個數的比例。 (4) (3)惡意召回率(Malicious Recall,MR):正確檢測出來的惡意軟件個數占所有惡意軟件個數的比例。 (5) (4)誤報率(False Alarm,FA):誤報為良性軟件的惡意軟件的個數占所有惡意軟件個數的比例。 (6) (5)綜合評價指標(F1):精確率(Precision)和召回率(Recall)的加權調和平均值。 良性軟件的精確率: (7) 良性軟件的F1值: (8) 惡意軟件的精確率: (9) 惡意軟件的F1值: (10) 將第2.2節中FPGrowth-r的n設置為10,support設置為10,表1展示了特征預處理階段各特征的數目和不同特征挖掘方法對應的耗時情況。 表1 特征數目及特征挖掘耗時 由表1可見,使用FPGrowth和FPGrowth-r挖掘后的特征數目較為接近,兩者均能對特征進行有效挖掘,但FPGrowth-r的耗時遠低于FPGrowth,因此該文設計的特征預處理方法是有效的。 根據式(1)和表1中FPGrowth-r挖掘的特征數目,經過計算,最佳的w為16,則DAE隱藏層最后一層的神經元個數設置為256。該文使用5層的DAE網絡對特征向量進行處理,最后生成大小為[3,16,16]的特征圖像用于BaggingCNN訓練和分類。 不同CNN算法對生成的特性圖像進行分類的結果如圖5所示,圖中算法均根據特征圖像大小調整了參數和深度,算法經過訓練達到最優。BaggingCNN抽取子訓練集樣本個數m設置為5 600(等于訓練集樣本個數),為確定BaggingCNN的最優參數t和k,使用圖5準確率前t的算法,在不同的抽樣次數k下進行實驗,結果如圖6所示。 圖5 不同CNN算法準確率對比 圖6 t和k在不同數值下的準確率變化情況 由圖6可以看到,隨著t和k的增大,算法的準確率也在提高,當t=3和k=3,算法的準確率趨于平穩。因此,選擇t=3和k=3作為BaggingCNN的最優參數,即子訓練集個數為3,選取準確率前3的GoogLeNet[23]、ResNet[24]、DenseNet[25]作為子分類器,其具體參數如表2所示。 表2 子分類器具體參數 在檢測能力、學習能力和泛化能力方面進行對比實驗,對FIG-AMD方法的有效性進行驗證: (1)檢測能力。 為了驗證FIG-AMD方法具備更好的檢測能力,利用GoogLeNet、ResNet、DenseNet和多種機器學習算法設計惡意軟件檢測方法,并與FIG-AMD方法進行對比。其中,GoogLeNet、ResNet、DenseNet的輸入為生成的特征圖像,機器學習算法的輸入為特征預處理階段多特征融合的線性特征向量,各算法均經過參數調整優化,算法分類性能達到最佳,實驗對比結果如表3所示。 表3 不同方法各項評估指標對比 % 從表3可以看到,GoogLeNet、ResNet、DenseNet的檢測效果優于傳統的機器學習方法,但檢測效果仍不及該文提出的FIG-AMD方法。因此,FIG-AMD方法相比較于其它方法,具備更好的檢測能力。 (2)學習能力。 為測試FIG-AMD方法的學習能力,改變FIG-AMD方法特征圖像生成階段生成的圖像數目以及正常樣本與惡意樣本的比例,并使用BaggingCNN分類算法對生成的特征圖像進行訓練和分類,實驗結果如圖7所示。 圖7 不同比例和數目樣本對FIG-AMD方法學習能力影響 從圖7中可以看到,在樣本分布不平衡或者樣本數目較少時,FIG-AMD方法可以保持較高的檢測準確率。當樣本比例保持在1∶1時,FIG-AMD方法的良性召回率和正常召回率較為接近,隨著樣本總數的增加,其各項檢測指標均在提高,說明FIG-AMD方法的學習能力在不斷提高。因此,提出的FIG-AMD方法具有較強的學習能力,其可以有效地從少量樣本或不平衡樣本中學習到不同類別樣本的特征。 (3)泛化能力。 在泛化能力測試方面,首先將文獻[13,15,17,18]提出的方法和該文提出的FIG-AMD方法使用相同的數據集進行訓練,再選用不同于該文訓練集和測試集的600個樣本(正常樣本300個,惡意樣本300個)進行測試。其中,文獻[13]為使用APK文件動態行為特征構造的特征向量經過Stacking訓練得到的分類結果;文獻[15]為組件、Intent Filter等特征經過遺傳算法篩選特征,使用DNN分類得到的結果;文獻[17]為使用深度收縮自編碼網絡對多特征融合的特征向量分類的結果;文獻[18]為dex文件轉換成RGB圖片,使用CNN分類的結果。此外,還將文獻[18]的分類算法替換成BaggingCNN進行了實驗,準確率得到了一定提升,說明BaggingCNN具有更好的分類性能,所有方法對比結果如表4所示,由表中對比結果可以看到:提出的FIG-AMD方法在準確率、誤報率等指標方面,均優于其它檢測方法,因此,可以認為FIG-AMD方法具備較強的泛化能力。 表4 不同方法檢測性能對比 % 設計了FIG-AMD方法對Android惡意軟件進行檢測,該方法側重于特征圖像的生成,提取APK文件多種特征并挖掘相關性高的特征組合,引入降噪自編碼器挖掘特征的深層信息和轉換特征維度,生成特征圖像用于訓練和分類,解決了訓練數據表征能力不足,影響分類算法收斂速度和檢測精度的問題。在分類算法方面,將多個CNN分類器調整后集成在一起,基于Bagging算法思想,設計BaggingCNN分類算法,該算法解決了單一分類算法魯棒性偏差的問題。經過實驗證明,提出的FIG-AMD方法可以對Android惡意軟件進行準確檢測,并在誤報率方面有著較大的降低,且該方法具有較好的學習能力和泛化能力。 在未來工作中,計劃在檢測方法中加入Android對抗樣本檢測機制,力求對設計的方法進行完善,從而可以準確檢測普通Android樣本以及Android對抗樣本。2.3 特征圖像生成
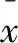

2.4 BaggingCNN分類算法

3 實驗結果與分析
3.1 實驗準備
3.2 評估指標
3.3 特征預處理

3.4 BaggingCNN參數
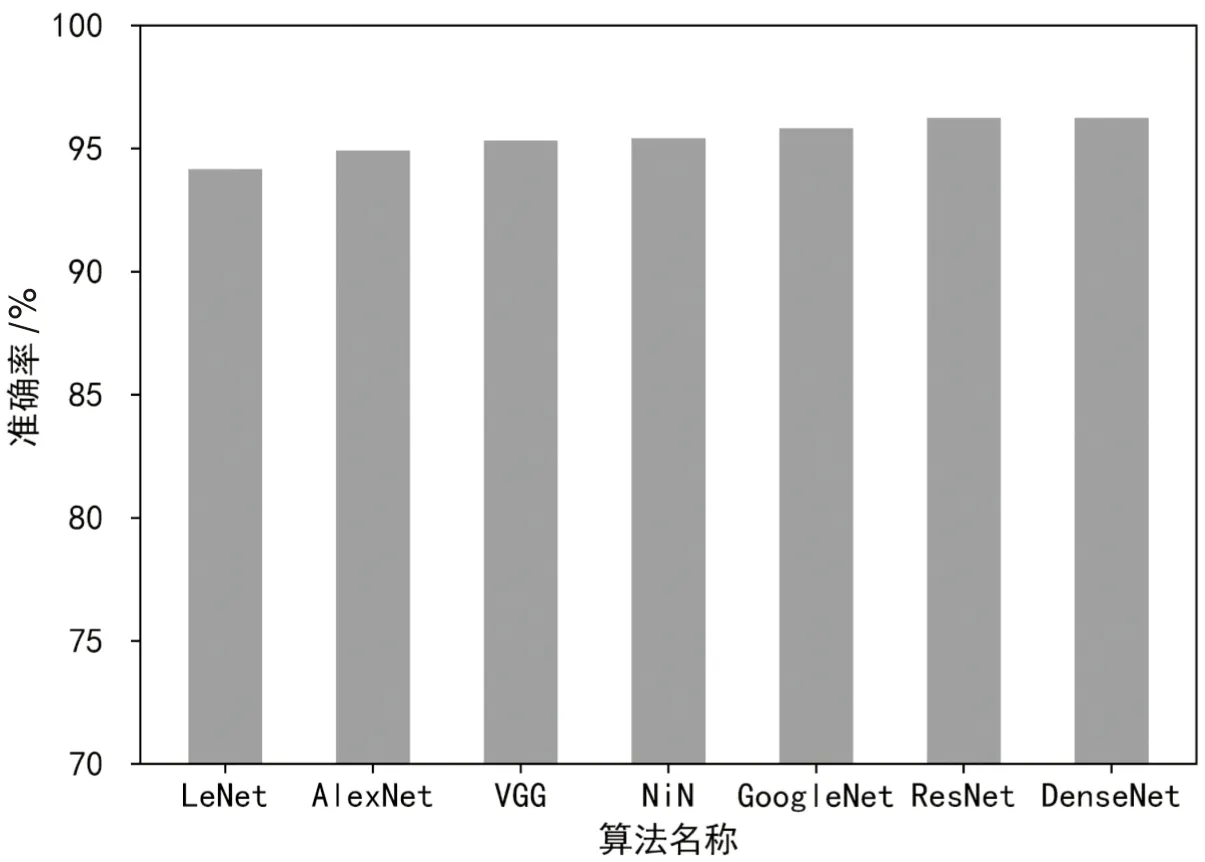

3.5 FIG-AMD方法有效性

4 結束語
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
