基于生成對抗網絡的服裝圖像生成研究進展
2023-06-20 12:49:06施倩羅戎蕾
現代紡織技術 2023年2期
關鍵詞:深度學習
施倩 羅戎蕾


摘要:生成式人工智能正逐步運用在服裝零售、電子商務、趨勢預測、虛擬現實以及增強現實等服裝產業技術中,并廣泛覆蓋相關品類的服務與產品。深度學習領域,圖像生成模型主要包括深度信念網絡(DBN)、變分自編碼器(VAE)、生成對抗網絡(GAN)。文章圍繞GAN研究前沿對其變體發展進行分類梳理,將應用于服裝領域最為廣泛的條件生成對抗網絡(CGAN)在Text-to-Image、Image-to-Image、Image-to-Video中的相關研究成果加以介紹,并分析其優化歷程、優缺點以及適用類型;列舉GAN在服裝圖像生成中的具體應用,包括服裝橫幅廣告自動生成、個性化服裝推薦與生成、服裝與圖案設計、虛擬試衣;最后針對服裝圖像生成研究挑戰作出總結。研究認為,未來可在多模態生成模型研發、大規模時尚服裝數據集構建、服裝生成客觀評估指標的3個方向展開研究。
關鍵詞:深度學習;生成對抗網絡;服裝生成;智能廣告設計;虛擬試衣
中圖分類號:TN941.26
文獻標志碼:A
文章編號:1009-265X(2023)02-0036-11
圖像生成作為計算機視覺研究的熱門方向,是實施智能設計的重要手段。早期圖像生成主要通過機器提取有效數據特征并進行算法迭代達到目的,結果準確性較大程度上依賴人的專業知識背景,這種基于有限樣本統計學原理的“學習”無法取得較大進展。隨著深度神經網絡的發展,其高層次特征的表達能力使得傳統機器學習的缺陷得以彌補。深度學習領域中的生成模型一般可以分為兩類,一類是包含玻爾茲曼機及其變體、深度信念網絡[1]在內的使用能量函數定義聯合概率的模型,另一類是包含變分自動編碼器[2]、生成對抗網絡[3]在內的基于成本函數的模型[4]。該研究興起階段,生成圖像建立在模型統計以及物理原理上,生成結果僅限于紋理或諸如人臉這種結構性較強的特定圖案。隨著研究的深入,利用深度神經網絡進行表征學習在生成自然圖像方面頗有成效,研究朝著生成高分辨率且逼真、生成圖像多樣化的方向推進。
人工智能背景下,服裝圖像自動生成在推動行業數字化進程中發揮著重要作用。本文選取生成對抗網絡(GAN)為研究對象,以技術可實施性較強、應用服裝領域最為廣泛的變體——條件生成對抗網絡(CGAN)模型為例,綜述其在服裝生成中的文字、圖像、視頻多個模態之間的相互轉換進展,橫向列舉GAN賦能傳統服裝細分領域技術革新的相關案例,最后總結發展過程中所面臨的問題及挑戰。以期為時尚界AI研究的相關專家和學者提供理論參考和研究方向,同時予以服裝領域相關產業技術升級一定啟示。
1深度學習圖像生成模型
1.1深度信念網絡(Deep belief network,DBN)
DBN是由許多潛變量層構成的概率生成模型,通常是由多個限制玻爾茲曼機(RBM)組成[5]。研究證明DBN是手寫數字圖像等生成任務的良好模型[6],可在無監督學習下產生高質量圖像樣本,克服了以往梯度類學習算法易出現的梯度消失問題。Susskind等[7]通過人臉及相關高級描述符(包括面部動作編碼系統和身份標簽),訓練DBN生成顯示特定身份和面部動作的逼真人臉,證明了神經網絡在表示人臉,同時與高級描述相關聯是可能的。Osindero等[8]將橫向連接添加到DBN隱藏層,通過實驗對照驗證添加橫向連接能夠有效提高DBN數據建模能力,進而生成逼真自然圖像斑塊。Torralba等[9]利用機器學習技術將Gist圖像描述符轉換為緊湊二進制碼,減少內存占用同時保證圖像識別效果,達到使用高效的數據結構處理大量圖像進而生成彩色圖像。
1.2變分自編碼器(Variational auto-encoder,VAE)
VAE是一種無監督圖像生成學習框架,具有采樣速度快、處理方便、編碼網絡易接入等優勢。Vahdat等[10]提出了一種基于深度可分離卷積和批量歸一化生成圖像的深層次模型Nouveau VAE,成功應用于256×256像素的高質量圖像生成。Yan等[11]將圖像建模為前景與背景的組合,提出一種可進行端到端學習的分層VAE生成模型,對人臉和鳥類進行了實驗,證明模型能夠在屬性條件重建和合成中表現出良好的定量和視覺效果。Razavi等[12]擴展并增強了VQ-VAE中使用的自回歸先驗,并應用在大規模圖像中進而生成更具相關性和保真度的合成樣本。Cai等[13]提出從粗到細的多階段圖像生成方法,多級VAE將解碼器分成兩個模塊,第一個模塊生成草圖,第二個模塊在此基礎上對圖像進行細化,進而生成清晰的高質量圖像。
1.3生成對抗網絡(Generative adversarial networks,GAN)
生成對抗網絡自2014年于Goodfellow等[3]提出,隨后在圖像識別與生成、圖像修復、語義分割、風格轉換等多領域中的應用研究接連展開。圖像生成作為計算機視覺主流研究方向之一,圍繞低訓練難度、高分辨率、生成樣本多樣性等多種訴求衍生了豐富的GAN模型變體,使得GAN的發展脈絡不斷擴展和優化。按照GAN結構變體分類,模型涵蓋了深度卷積對抗生成網絡(Deep convolutional GAN)[14]、半監督學習生成對抗網絡(Semi-supervised learning GAN)[15]、條件式生成對抗網絡(Conditional GAN)[16]、拉普拉斯金字塔生成對抗網絡(Laplacian pyramid GAN)[17]、邊界均衡生成對抗網絡(Boundary equilibrium GAN)[18]等。按照GAN損失函數變體分類,主要代表模型有Wasserstein距離生成對抗網絡(Wasserstein GAN)[19]、WGAN-GP(Improved training of WGAN)[20]、F散度生成對抗網絡(F-divergence GAN)[21]、最小二乘生成對抗網絡(Least squares GAN)[22]。
1.4模型對比分析
DBN、VAE、GAN生成原理及優缺點如表1所示。服裝領域應用中,DBN在蠟染圖案識別[23]、人體部位及服裝識別[24]、面部生成[7]、服裝分類[25]等均有應用;VAE常應用在電商服裝推薦系統[26]、服裝設計[27]、風格分類[28]、服裝風格遷移[29]等領域;GAN在服裝領域中應用更為廣泛,例如電商廣告生成[30-31];服裝搭配推薦[32-33]、服裝設計[34-35];虛擬試衣等[36-37]。
深度生成模型將深度神經網絡強大的學習表征能力與數理統計、概率論的相關知識結合,近年來取得了顯著進步。2006年DBN被提出至2013年、2014年VAE、GAN模型的接連問世,三者之間隨著模型可處理的數據樣本集不斷擴增,其各自的生成能力也隨之遞進。DBN在擁有足量無標注樣本進行數據分布以及潛在特征的總結學習下,能夠在小樣本數據處理中展現優勢,但生成圖像的多樣性和清晰度較差。VAE更適用于學習具有良好結構的潛在空間,然而生成圖像清晰度欠佳。GAN沒有變分下界,相較于DBN而言,GAN產生的樣本可一次生成,無需重復利用馬爾科夫鏈來完成;相較于VAE,GAN訓練偏差小,鑒別器(Discriminator)的良好訓練則足以保證生成器(Generator)充分學習訓練樣本分布。GAN作為業內無監督學習中處理復雜分布問題最為看好的模型,理論上任意可微分函數均可用以構建判別器(D)和生成器(G),訓練時無需對隱變量做推斷,生成圖像多樣且分辨率高,可應用場景多,能夠帶來較高經濟價值。近幾年,基于GAN的服裝圖像生成研究熱度居高,不斷衍生的變體模型正逐步改善以往圖像生成所面臨的不足。因此,本文以GAN為研究對象,探尋其在服裝領域的發展脈絡和應用趨勢。
2基于多模態轉換的服裝圖像生成
原始GAN存在生成內容隨機、無法指定根據隨機噪聲生成的圖像類型等問題,CGAN通過在生成模型(G)和判別模型(D)的建模中引入conditional variabley,從而完成從無監督到有監督模型的改進,實現生成器生成數據類別的指定[16]。相較于醫療、建筑等領域,龐大易得的服裝數據集使得深度學習在該領域的發展更加廣泛深入,按照數據輸入類型和輸出類型分類,CGAN實現生成的形式主要有文本轉圖像、圖像轉圖像、圖像轉視頻。
2.1文本轉圖像(Text-to-Image)
文本合成圖像是指基于給定的文本描述生成所需圖像的過程。生成圖像分辨率越高,過程越具挑戰性,Zhang等[38]提出堆疊式生成對抗網絡StackGAN來生成基于文本描述的照片級真實感圖像,首次實現基于文本描述的256×256像素圖像生成。在此工作基礎上,Zhang等[39]隨后提出StackGAN++,將原有網絡結構擴展成樹狀,實現多個生成器和鑒別器的并行訓練,完成限定性生成到非限定性生成任務的跨越。提高生成圖像與輸入文本描述的細節關聯度是一大關鍵,Xu等[40]提出注意力生成對抗網絡(AttnGAN),在訓練生成器的過程中提出深度注意力多模態相似度模型,計算細粒度的圖像與文本匹配損失,對復雜場景的文本到圖像生成任務頗具參考意義。為減少文本生成服裝圖像產生的偽影和噪聲,解決在模特體形和姿勢不變的前提下生成服裝紋理與文本描述一致的問題,Zhu等[41]提出分兩階段完成生成任務的FashionGAN,實現穿著指定服裝的人物圖像的生成。類似生成任務中,Zhou等[42]基于自然語言描述引導人物姿勢、服裝屬性生成,Günel等[43]提出一種以文本為條件的特征線性調制生成對抗網絡(FiLMedGAN),能夠在保證人體身形姿勢不變的情況下,通過輸入不同的描述編輯圖像進而產生新的服裝。服裝在語義分類上具有多個屬性,如領型、袖長、圖案、顏色、款式等多個類別,Banerjee等[44]提出基于條件和注意力GAN框架(AC-GAN),通過在生成過程中提供文本屬性來對服裝類別及背景分類。
2.2圖像轉圖像(Image-to-Image)
生成對抗網絡在服裝設計中應用最廣泛的形式即為圖像到圖像的轉換。Pix2Pix作為CGAN的變體之一,是目前已知使用效能較好的圖像到圖像轉換GAN框架,通過引入U-Net架構減輕訓練負擔并生成細致圖像,能夠優化單一輸入圖像對應多個輸出問題,解決生成對抗網絡模式崩潰[45]。Zhao等[46]擴展Pix2Pix以適應AR中的服裝設計任務,提出的兩階段圖像生成神經網絡的補償方法降低了條件輸入的分布要求。Tango等[47]以Pix2Pix為基準模型,通過引入額外鑒別器和損失函數實現給定的動漫圖像到cosplay服裝圖像的生成。Kwon等[48]基于Pix2Pix模型提出由粗到細的生成對抗網絡Rough-to-Detail GAN以解決全局一致性問題,實現時裝模特著裝的精細生成。CycleGAN和DiscoGAN提出間隔較短,二者均摒棄對配對數據集的依賴性,通過雙GAN機制實現圖像到圖像之間的轉換。Fu[49]通過改進CycleGAN 網絡實現圖像的藝術風格轉移,而Kim等[50]提出的DiscoGAN能夠發現跨域關系,同樣能在保證鞋子和包袋屬性不變的情況下實現風格轉移。為解決在處理兩個以上的域面臨可擴展性和魯棒性限制問題,Choi等[51]提出StarGAN實現單個模型為多個域執行圖像到圖像之間的轉換,該模型在服裝設計中恰如其分,例如設計具有相同質感的不同類型服裝,然而卻存在生成圖像緩慢以及不能有效保留輸入圖像的紋理特征問題,為此Shen等[52]提出GD-StarGAN,將StarGAN生成器的原始殘差網絡替換為全卷積網絡U-net,提升損失函數的穩定性和收斂速度,使得輸入與輸出的服裝圖像紋理更為接近。在進一步增強服裝紋理合成細節工作中,Xian等[53]提出的TextGAN模型通過細粒度紋理控制實現用戶的精細需求。
2.3圖像轉視頻(Image-to-Video)
利用GAN實現圖像生成視頻通常應用于延時攝影、視頻幀預測以及視頻動畫的制作。面部表情視頻預測中,Shen等[54]提出AffienGAN,將每個面部圖像與表情強度相關聯,并利用潛在空間中的仿射變換,實現從單個靜止圖像中預測任意時間長度的面部表情視頻。為解決視頻生成中的人物隱私問題,Maximov等[55]提出一種圖像和視頻匿名化模型CIAGAN,在消除面部和身體的識別特征的前提下生成可用于任意計算機視覺任務的高質量圖像和視頻。GAN在服裝領域應用最廣泛之處便是虛擬試衣。Dong等[56]開發一種基于圖像的視頻虛擬試穿系統FW-GAN,通過引入流判別器提升時空平滑性,同時在語法一致性損失函數的保障下能夠合成任意姿勢下穿著所需服裝的人物視頻。相關工作中,Pumarola等[57]將服裝分割輸出與時間一致的GAN相結合,通過填充遮擋區域并適應新的光照條件和身體姿勢,逐步細化源紋理圖使其適應目標人,進而實現參考圖像中的服裝到目標視頻人物上的轉移。為解決視頻生成模型所需要的服裝形狀復雜非線性幾何表達能力的缺乏問題,Ma等[58]提出MeshVAE-
GAN模型,通過學習3D掃描各類姿勢的SMPL著裝,首次實現直接修飾3D人體網格并泛化到不同姿勢的服裝變形。最近的虛擬服裝試穿作品在量化所選的單獨視覺效果中缺乏細致說明,同時并未指定對實驗至關重要的超參數細節,針對此問題,Kuppa等[59]提出采用自下而上的試穿模型ShineOn,旨在闡明每個實驗的視覺和定量效果。
對于CGAN而言,通過向生成器(G)中分別輸入先驗分布中采樣出來的樣本Z和當前的條件C(條件C可以是有關目標生成的描述性文本或者是包含基本特征的輪廓圖),并將生成的對象X和條件C輸出到判別器(D),判別器(D)通過評估生成對象X是否真實同時與條件C是否匹配并進行打分,最終即可生成滿足目標條件的服裝圖像或視頻。總結發現,基于CGAN的文本、圖像、視頻之間的多模態轉換沿著生成數據精細化、清晰化同時具備高逼真度的方向改進,CGAN生成服裝圖像及視頻研究分類總結如表2所示。Text-to-Image圖像生成應用主要有給定模特換裝、服裝紋理渲染、人物姿勢及服裝屬性生成、服裝類別及背景分類;Image-to-Image圖像生成多應用在服裝設計、服裝圖像轉換、風格遷移、虛擬試衣、流行趨勢預測;Image-to-Video視頻生成應用有:面部表情視頻幀預測、匿名模特視頻生成、虛擬試衣。
3服裝圖像生成相關產業應用
3.1服裝橫幅廣告自動生成
智能生成技術在消費過程中產生的功能價值、社會價值、情感價值以及認知價值中均傳遞著積極影響[60]。服裝作為電商主要銷售產品,其橫幅廣告的大規模個性化生成在大型促銷活動中尤為重要,依托智能設計所具有的強大圖片生成能力不僅能有效提高服裝商家的工作效率,降低店鋪運營成本,同時也提升了數據利用率。另一方面,電商服裝產品
及其購買體驗需能夠有效滿足消費者的審美和享樂需求,在速度和新穎性方面也在不斷逐快逐新,借助生成式人工智能打通全渠道時代電商廣告的全鏈路營銷,進而抓住消費者至關重要。阿里巴巴鹿班作為多媒體內容制作的AI輔助工具,通過引入生成對抗網絡協助智能生成,其核心在于通過數據集的學習利用機器合成廣告并不斷調整優化。在其快速生成(一秒鐘生成8000張banner)背后,其智能設計中的數據資源調用能夠有效解決服裝圖片流量的問題,進而給商家帶來流量紅利。此外,大型電商活動中服裝產品價格頻繁更新,商家手動更改價格面臨數字準確性、更新實時性以及操作成本等問題。鹿班通過技術手段賦能系統自動更新價格、智能生成圖片并及時更新商品主圖,有效清除picasso域名的cdn緩存,解決了服裝大促活動中頻繁更換橫幅廣告帶來的商品緩存失效和cdn緩存圖片低命中率等問題,保障了服裝商家營銷鏈路環節運營流暢。
3.2個性化服裝推薦與生成
推薦系統是服裝電商縮小繁多種類、快速導航的有效工具。Amazon、eBay、淘寶等國內外電商正逐步掌握用戶興趣,基于消費者點擊、購買或者交互
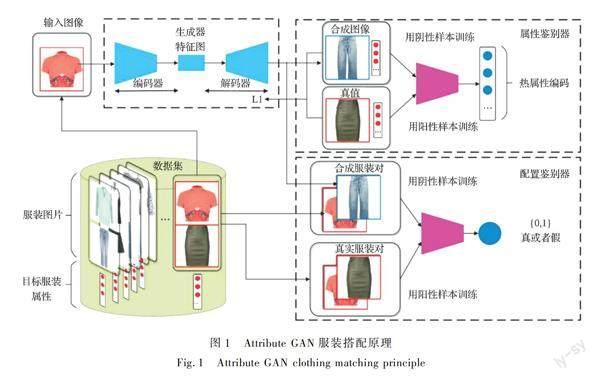
的歷史觀察使得其網站的服裝推薦系統正趨于多樣化、準確化。服裝領域構建有效的推薦系統主要挑戰在于該領域的高度主觀性以及服裝風格的語義復雜性[61]。研究中,服裝智能搭配推薦通常與服裝生成緊密結合在一起[62],將GAN添加到推薦系統中可以幫助在線零售商更好地獲取消費者需求,核心技術在于對成套服裝進行圖像分割處理并提取篩選服裝視覺、類別、文本特征后,利用生成對抗網絡和孿生卷積神經網絡(Siamese network)模型[63]自動生成服裝搭配結果。推薦系統重點應用于電子商務、服裝零售領域,例如適宜尺碼服裝推薦、日用產品推薦以及基于社交的流行服裝推薦[64]。基于電商的大規模服裝搭配數據集學習,采用CNN的“視覺感知”推薦器與GAN結合同樣可有效生成與用戶偏好相一致的多樣化服裝搭配[61]。研究表明,通過語義屬性的服裝匹配規則學習,生成對抗網絡變體AttributeGAN能夠在合成服裝的多樣性和匹配度上實現一定程度提升[65],其工作原理如圖1所示,通過輸入屬性相關的服裝圖像,經過對抗訓練的鑒別器會預測服裝對的匹配與否,最終生成符合消費者審美和穿著習慣的服裝搭配。
3.3服裝與圖案設計
因受眾廣泛性與數據公開性,與醫療等領域不同,服裝領域擁有諸如Deep Fashion、Instagram、Pinterest等龐大數據集,為深度生成提供便利。國內外代表
性電商網站中,Amazon利用深度學習在發現、反應并塑造最新時尚趨勢中占據優勢,阿里巴巴也相繼推出FashionAI項目實現服裝行業人工智能革新。智能服裝設計中GAN傳遞著積極作用,CGAN通過在生成器和判別器中添加參數向量y來生成特定條件下或者具備某些特征的圖像,通過將不同類目的服裝單品標簽作為輸入條件,目前已經實現了利用CGAN生成涵蓋上裝、褲裝、連衣裙、鞋靴等各種品類的服裝。如圖2所示,麻省理工學院的研究人員開發一種能夠生成時裝設計的GAN模型,其獨特大膽的生成(例如將普通袖子和喇叭袖設計在同一件服裝上、超長的帽子)使得設計結果別有韻味。服裝圖案生成中,Wu等[66]提出ClothGAN模型進而生成帶有敦煌元素的時尚服裝,Tirtawan等[67]提出的CGAN模型能夠生成蠟染圖案服裝,延續文化傳統的同時豐富了智能服裝設計中的圖案元素。
3.4走向視頻呈現的虛擬試衣
虛擬試衣在電影制作、視頻編輯以及線上購物上均具有較大應用價值[56],電商平臺中的虛擬試衣能夠促進在線零售并減少包裝和退貨產生的碳足跡。早期虛擬試衣系統主要依靠三維人體掃描和計算機,耗費成本的同時處理繁瑣,近年來研究人員利用深度神經網絡生成虛擬服裝,構建了例如CA-GAN、MG-VTON、FW-GAN等虛擬試衣模型,在自由變換服裝[68]、改善圖像欠擬合以實時適應人體姿勢變化[69]、細化虛擬試衣紋理褶皺細節并賦予其真實性[70]、解決試衣中人體與服裝之間干擾遮擋問題[71]的過程中優化遞進。購買服裝過程中試穿的實時性是一個有效加分項,Pix2surf模型[72]能夠將電商網站上的海量服裝圖像轉化為紋理貼圖進而映射到三維虛擬衣物模型的表面達到貼合覆蓋,進而實現實時虛擬試衣。虛擬試穿不僅在空間上實現2D到3D的躍升,同時實現了基于視頻呈現的試衣,能夠幫助消費者更加全面多角度地衡量試穿衣物的外觀效果。如圖3所示,Shineon模型[59]將模特與布料輸入到U-net網絡中,通過服裝變形和試穿雙模塊機制作用,最終生成用戶多角度試穿服裝的視頻。
4總結與展望
近年來的數字服裝研究可具體劃分為3個層次:低級服裝識別(服裝解析、地標檢測、姿勢估計)、中級服裝理解(風格分類、服裝檢測、屬性預測)以及高級服裝應用(服裝匹配檢索、服裝圖像生成、流行趨勢預測)。作為高級服裝應用之一,服裝圖像生成現已取得了顯著進展,在DBN、VAE、GAN 3種深度生成模型中,GAN因其低訓練難度、高訓練效率以及強大的生成能力成為目前圖像生成研究的主流方向。圍繞消費美學、心理學方面的生成訴求,GAN衍生的各種變體主要基于原模型的結構框架、損失函數予以改進,從而達到改進網絡結構、提高模型穩定性、解決訓練過程中梯度消失、難以收斂以及容易模式崩潰等問題,實現生成圖像清晰多樣化并兼具設計美感,有效迎合用戶流行趨勢和用戶喜好,取代設計人員低層次、重復性的勞動進而提高工作效率。然而行業仍面臨著諸如生成模型效用單一、服裝數據集適用面窄以及缺乏生成評估的客觀統一標準等問題,本文基于生成對抗網絡應用技術原理以及目前所面臨的人工智能技術挑戰,提出以下總結:
a) 綜合多模態生成的模型研發。深度生成技術在服裝領域的應用多在電子商務領域,作為綜合文字、圖像、語音以及視頻的多模態領域,相關研究已經朝著超大規模多模態預訓練模型的研發前進,比如2021年阿里巴巴聯合清華大學提出的中文多模態預訓練及超大規模預訓練模型“M6”,已經廣泛落地到搜索、推薦、服裝文案智能生成、服裝設計等多個電商場景中,能夠有效實現電商平臺中各種服裝的文本到圖像生成,以及基于服裝圖片的文本描述,視頻生成等。因此綜合多個模態之間轉換生成的大模型能夠有效增強生成效用。
b)大規模服裝數據集的集合。作為一種具有弱標簽、多領域、多模態的特殊數據,服裝數據集的良好表示對服裝生成來說至關重要。一般將服裝數據集分為單個任務基準數據集和多個任務基準數據集,目前存在著來源數據單一、作用任務局限、數據少以及跨越時間短的問題,缺乏包含多模態數據的統一大規模集合,因此這方面的努力具有廣闊前景。
c)進行服裝生成評估的客觀標準。基于人類偏好或者初始分數是當前服裝生成的主要評估指標,存在問題在于前者分數易受偏好個體的主觀情感和身處環境的影響,而后者關注點更多地在于圖像質量而不是美學因素。因此,建立一種服裝生成評估的客觀、穩健指標十分必要。
參考文獻:
[1]HINTON G E, OSINDERO S, TEH Y W. A fast learning algorithm for deep belief nets[J]. Neural computation, 2006, 18(7): 1527-1554.
[2]DIEDERIK P K, MAX W. Auto-encoding variational bayes[J/OL]. ArXiv,2013:1312.6114. https://arxiv.org/abs/1312.6114v10.
[3]GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al. Generative adversarial nets[C]//?Proceedings of the 27th International Conference on Neural Information Processing Systems. Montreal, Canada, 2014:2672-2680.
[4]PARK T, LIU M Y, WANG T C, et al. Semantic image synthesis with spatially-adaptive normalization[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Long Beach, CA, USA, 2019: 2337-2346.
[5]KAMADA S, ICHIMURA T, HARA A, et al. Adaptive structure learning method of deep belief network using neuron generation-annihilation and layer generation[J]. Neural Computing and Applications, 2019, 31(11): 8035-8049.
[6]HINTON G E, SALAKHUTDINOV R R. Reducing the dimensionality of data with neural networks[J]. Science, 2006, 313(5786): 504-507.
[7]SUSSKIND J M, HINTON G E, MOVELLAN J R, et al. Generating facial expressions with deep belief nets[J]. Affective Computing, Emotion Modelling, Synthesis and Recognition, 2008, 2008(5): 421-440.
[8]OSINDERO S, HINTON G E. Modeling image patches with a directed hierarchy of Markov random fields[C]//Proceedings of the Twenty-First Annual Conference on Neural Information Processing Systems, Vancouver, British Columbia, Canada, 2007: 1121-1128.
[9]TORRALBA A, FERGUS R, WEISS Y. Small codes and large image databases for recognition[C]//Conference on Computer Vision and Pattern Recognition. IEEE, 2008: 1-8.
[10]VAHDAT A, KAUTZ J. Nvae: A deep hierarchical variational autoencoder[J/OL]. ArXiv,2020:2007.03898. https://arxiv.org/abs/2007.03898.
[11]YAN X, YANG J, SOHN K, et al. Attribute2image: Conditional image generation from visual attributes[C]//European Conference on Computer Vision. Springer, Cham, 2016: 776-791.
[12]RAZAVI A, VAN DEN OORD A, VINYALS O. Generating diverse high-fidelity images with vq-vae-2[C]//NIPS'19: Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver Convention Center, Canada, 2019: 14 866-14 876.
[13]CAI L, GAO H, JI S. Multi-stage variational auto-encoders for coarse-to-fine image generation[C]//Proceedings of the 2019 SIAM International Conference on Data Mining. Society for Industrial and Applied Mathe-matics, 2019: 630-638.
[14]RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks[J/OL]. ArXiv, 2015:1511.06434. https://arxiv.org/abs/1511.06434v2.
[15]ODENA A. Semi-supervised learning with generative adversarial networks[J/OL]. ArXiv, 2016:1606.0158. https://arxiv.org/abs/1606.01583v1.
[16]MIRZA M, OSINDERO S. Conditional generative adversarial nets[J/OL]. ArXiv, 2014:1411.1784. https://arxiv.org/abs/1411.1784.
[17]DENTON E L, CHINTALA S, FERGUS R. Deep generative image models using a laplacian pyramid of adversarialnetworks[J]. Advances in neural information processing systems, 2015, 28(1): 1486-1494.
[18]BERTHELOT D, SCHUMM T, METZ L. Began: Boundary equilibrium generative adversarial networks[J/OL]. ArXiv, 2017:1703.10717. https://arxiv.org/abs/1703.10717v4.
[19]ADLER J, LUNZ S. Banach wasserstein gan[J]. Advances in Neural Information Processing Systems, 2018, 31(6): 6756-6764.
[20]GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wasserstein gans[J]. Advances in Neural Information Processing Systems, 2017, 30(12): 5769-5779.
[21]NOWOZIN S, CSEKE B, TOMIOKA R. F-gan: Training generative neural samplers using variational divergence minimization[J]. Advances in Neural Infor-mation Processing Systems, 2016, 29(12): 271-279.
[22]MAO X, LI Q, XIE H, et al. Least squares generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice, Italy, 2017: 2794-2802.
[23]HANDHAYANI T, HENDRYLI J, HIRYANTO L. Comparison of shallow and deep learning models for classificationof Lasem batik patterns[C]//?International Conference on Informatics and Computational Sciences. Semarang, Indonesia. 2017:11-16.
[24]CHEN Y, XUE Y. A deep learning approach to human activity recognition based on single accelerometer[C]//International Conference on Systems, Man, and Cybernetics. IEEE, 2015: 1488-1492.
[25]LIN X, PENG L, WEI G, et al. Clothes classification based on deep belief network[C]//3rd International Conferenceon Informative and Cybernetics for Compu-tational Social Systems (ICCSS). IEEE, 2016: 87-92.
[26]KIM J. Time-varying Item Feature Conditional Variational Autoencoder for Collaborative Filtering[C]//International Conference on Big Data. IEEE, 2019: 2309-2316.
[27]GU C, HUANG Z, LI S, et al. Apparel generation via cluster-indexed global and local feature representations[C]//9th Global Conference on Consumer Electronics (GCCE). IEEE, 2020: 218-219.
[28]PARK J. Improving fashion style classification perfor-mance using VAE in class imbalance situation [J]. Journal of the Korean Society for Information Technology, 2021, 19(2): 1-10.
[29]LU Z. Digital Image Art Style Transfer Algorithm and Simulation Based on Deep Learning Model[J]. Scientific Programming,2022, 2022(3): 1-9.
[30]LIU K L, LI W, YANG C Y, et al. Intelligent design of multimedia content in Alibaba[J]. Frontiers of Information Technology & Electronic Engineering, 2019,20(12): 1657-1664.
[31]陳偉.生成對抗網絡在廣告創意圖制作中的應用[D].北京:中國科學院大學,2020.
CHEN Wei. Application of Generative Confrontation Network in the Production of Advertising Creative Map[D]. Beijing: University of Chinese Academy of Sciences, 2020.
[32]楊怡然,吳巧英.智能化服裝搭配推薦研究進展[J].浙江理工大學學報(自然科學版),2021,45(1):1-12.
YANG Yiran, WU Qiaoying. Research progress of intelligent clothing matching recommendation[J]. Journal of Zhejiang Sci-Tech University (Natural Science Edition), 2021, 45(1): 1-12.
[33]楊爭妍,薛文良,張傳雄,等.基于生成式對抗網絡的用戶下裝搭配推薦[J].紡織學報,2021,42(7):164-168.
YANG Zhengyan, XUE Wenliang, ZHANG Chuanxiong, et al. Recommendation of users' down-loading collocation based on generative confrontation network[J]. Journal of Textile, 2021, 42 (7): 164-168.
[34]陳涵,沈雷,汪鳴明,等.基于生成對抗網絡的書法紡織圖案設計開發[J].絲綢,2021,58(2):137-141.
CHEN Han, SHEN Lei, WANG Mingming, et al. Design and development of calligraphy textile pattern based on generative confrontation network [J]. Journal of Silk, 2021, 58(02): 137-141.
[35]曹寶秀.用神經網絡自動設計服裝[J].中國纖檢,2019(4):120-121.
CAO Baoxiu. Automatic clothing design with neural network[J]. China Fiber Inspection, 2019 (4): 120-121.
[36]張穎,劉成霞.生成對抗網絡在虛擬試衣中的應用研究進展[J].絲綢,2021,58(12):63-72.
ZHANG Ying, LIU Chengxia. Research progress on the application of generating network in virtual fitting [J]. Journal of Silk, 2021, 58(12): 63-72.
[37]徐小春.深度學習算法在虛擬試衣中的應用[D].無錫:江南大學,2021.
XU Xiaochun. Application of Deep Learning Algorithm in Virtual Fitting[D]. Wuxi: Jiangnan University, 2021.
[38]ZHANG H, XU T, LI H, et al. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks[C]//Proceedings of the IEEE International Conference on Computer Vision. IEEE, 2017: 5907-5915.
[39]ZHANG H, XU T, LI H, et al. StackGAN++: Realistic image synthesis with stacked generative adver-sarial networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018, 41(8): 1947-1962.
[40]XU T, ZHANG P, HUANG Q, et al. Attngan: Fine-grained text to image generation with attentional generative adversarial networks[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 1316-1324.
[41]ZHU S, URTASUN R, FIDLER S, et al. Be your own prada: Fashion synthesis with structural coherence[C]//Proceedings of the IEEE International Conference on Computer Vision. IEEE, 2017: 1680-1688.
[42]ZHOU X, HUANG S, LI B, et al. Text guided person image synthesis[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2019: 3663-3672.
[43]GNEL M, ERDEM E, ERDEM A. Language guided fashion image manipulation with feature-wise transfor-mations[J/OL].ArXiv, 2018:1808.04000. https://arxiv.org/abs/1808.04000.
[44]BANERJEE R H, RAJAGOPAL A, JHA N, et al. Let AI clothe you: Diversified fashion generation[C]//Asian Conferenceon Computer Vision. Springer, Cham, 2018: 75-87.
[45]ZHU J Y, ZHANG R, PATHAK D, et al. Multimodal image-to-image translation by enforcing bi-cycle consistency[C]//?Advances in Neural Information Processing Systems. ACM Journals, 2017: 465-476.
[46]ZHAO Z, MA X. A compensation method of two-stage image generation for human-ai collaborated in-situ fashion designin augmented reality environment[C]//International Conference on Artificial Intelligence and Virtual Reality. IEEE, 2018: 76-83.
[47]TANGO K, KATSURAI M, MAKI H, et al. Anime-to-real clothing: Cosplay costume generation via image-to-image translation[J]. Multimedia Tools and Applications, 2022, 2022(4): 1-19.
[48]KWON Y, KIM S, YOO D, et al. Coarse-to-fine clothing image generation with progressively constructed conditional GAN[C]//14th International Conference on Computer Vision Theory and Applications. SCITEPRESS-Science and Technology Publications, 2019: 83-90.
[49]FU X. Digital image art style transfer algorithm based on cycleGAN[J]. Computational Intelligence and Neuroscience,2022, 2022(1): 1-10.
[50]KIM T, CHA M, KIM H, et al. Learning to discover cross-domain relations with generative adversarial networks[C]//International Conference on Machine Learning. PMLR, 2017: 1857-1865.
[51]CHOI Y, CHOI M, KIM M, et al. Stargan: Unified generative adversarial networks for multi-domain image-to-imagetranslation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 8789-8797.
[52]SHEN Y, HUANG R, HUANG W. GD-StarGAN: Multi-domain image-to-image translation in garment design[J]. PloSone,2020, 15(4): 1-15.
[53]XIAN W, SANGKLOY P, AGRAWAL V, et al. Texturegan: Controlling deep image synthesis with texture patches[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2018: 8456-8465.
[54]SHEN G, HUANG W, GAN C, et al. Facial image-to-video translation by a hidden affine transformation[C]//Proceedings of the 27th ACM International Conference on Multimedia. ACM Journals, 2019: 2505-2513.
[55]MAXIMOV M, ELEZI I, LEAL-TAIX L. Ciagan: Conditional identity anonymization generative adversarial networks[C]//?Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2020: 5447-5456.
[56]DONG H, LIANG X, SHEN X, et al. Fw-gan: Flow-navigated warping gan for video virtual try-on[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. IEEE, 2019: 1161-1170.
[57]PUMAROLA A, GOSWAMI V, VICENTE F, et al. Unsupervised image-to-video clothing transfer[C]//Proceedings of the IEEE/?CVF International Conference on Computer Vision Workshops. IEEE, 2019: 0-0.
[58]MA Q, YANG J, RANJAN A, et al. Learning to dress 3d people in generative clothing[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2020: 6469-6478.
[59]KUPPA G, JONG A, LIU X, et al. ShineOn: Illuminating design choices for practical video-based virtual clothing try-on[C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. IEEE, 2021: 191-200.
[60]SOHN K, SUNG C E, KOO G, et al. Artificial intelligence in the fashion industry: Consumer responses to generative adversarial network (GAN) technology[J]. International Journal of Retail & Distribution Manage-ment, 2020. 49(1): 61-80.
[61]KANG W C, FANG C, WANG Z, et al. Visually-aware fashion recommendation and design with generative image models[C]//International Conference on Data Mining. IEEE, 2017: 207-216.
[62]YU C, HU Y, CHEN Y, et al. Personalized fashion design[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. IEEE, 2019: 9046-9055.
[63]SUN G L, CHENG Z Q, WU X, et al. Personalized clothing recommendation combining user social circle and fashion styleconsistency[J]. Multimedia Tools and Applications, 2018, 77(14): 17731-17754.
[64]DOKOOHAKI, N. Fashion Recommender Systems[M]. Springer International Publishing, 2020.
[65]LIU L, ZHANG H, JI Y, et al. Toward AI fashion design: An attribute-GAN model for clothing match[J]. Neurocomputing,2019, 341(5): 156-167.
[66]WU Q, ZHU B, YONG B, et al. ClothGAN: Generation of fashionable Dunhuang clothes using generative adversarial networks[J]. Connection Science, 2021, 33(2): 341-358.
[67]TIRTAWAN T, SUSANTO E K, ZAMAN P L, et al. Batik clothes auto-fashion using conditional generative adversarial network and U-Net[C]//3rd East Indonesia Conference on Computer and Information Technology. IEEE, 2021: 145-150.
[68]JETCHEV N, BERGMANN U. The conditional analogy gan: Swapping fashion articles on people images[C]//Proceedings of the IEEE International Conference on Computer Vision Workshops. IEEE, 2017: 2287-2292.
[69]DONG H, LIANG X, SHEN X, et al. Towards multi-pose guided virtual try-on network[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. Seoul. 2019: 9026-9035.
[70]LAHNER Z, CREMERS D, TUNG T. Deepwrinkles: Accurate and realistic clothing modeling[C]//Proceedings of the European Conference on Computer Vision. Munich, 2018: 698-715.
[71]YU R, WANG X, XIE X. Vtnfp: An image-based virtual try-on network with body and clothing feature preservation[C]//Proceedings of the IEEE/CVF International Confe-rence on Computer Vision. IEEE, 2019: 10511-10520.
[72]MIR A, ALLDIECK T, PONS-MOLL G. Learning to transfer texture from clothing images to 3d humans[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. IEEE, 2020: 7023-7034.
Research progress of clothing image generation based onGenerative Adversarial Networks
SHI Qian, LUO Ronglei
(a.School of Fashion Design & Engineering; b.Zhejiang Provincial Engineering Laboratory of Fashion Digital Technology,
Zhejiang Sci-Tech University, Hangzhou 310018, China)
Abstract: The depth generation model mainly includes Deep Belief Network (DBN), Variational Self-Encoder (VAE) and Generative Adversarial Network (GAN). GAN, as a popular in-depth learning framework in recent years, constructs two networks G and D which are mutually antagonistic and game, so that they can achieve Nash equilibrium through continuous iterative training and then realize the automatic generation of images. GAN can be applied in many fields, including semi-supervised learning, sequence data generation, image processing, domain adaptation, etc. The image processing field can be subdivided into multiple scenes, such as image generation, image super-resolution, image style transformation, object transformation and object detection. The most widely used and successful part of GAN in image processing is image generation. Clothing image generation based on 5G, big data, depth learning and other technologies can effectively promote the digital development process of apparel e-commerce.
Conditional Generative Adversarial Network (CGAN) implements constraints on sample generation by adding constraint condition Y to GAN. CGAN can direct the generator to synthesize data in a directional way against expected samples. Therefore, CGAN is an effective model to realize automatic generation of clothing images that meet specific needs. During the training, the generator learns to generate realistic samples matching the labels of the training data set, and the discriminator learns to match the correct labels for the identified real samples. At present, the public clothing data sets that can be applied to clothing image generation mainly include Fashion-MNIST, Deep Fashion, Fashion AI, etc. According to the data morphology classification of the input model and the output model, the main forms of CGAN implementation in the clothing field are Text-to-Image, Image-to-Image and Image-to-Video. The three data synthesis forms respectively contain various derived GAN models, which correspond to different clothing generation application scenarios. Text-to-Image aims to generate the required clothing image based on the given description text, which can be specifically applied to a given model change, clothing texture rendering, character pose and clothing attribute generation, clothing category and background classification; Image-to-Image is mostly applied in clothing design, such as clothing pattern design, clothing image conversion (from sketch to cartoon clothing, model to dress), style transfer, virtual fitting, fashion trend forecast, etc.; Image-to-Video is usually applied to facial expression video frame prediction, anonymous model video generation, virtual fitting and other scenes.
In recent years, research on GAN-applied clothing image generation industry is mostly distributed in the field of e-commerce, including automatic generation of clothing banner advertisements, personalized clothing recommendation system, clothing and pattern design, virtual fitting towards video presentation, etc., which greatly enables the upgrading of related digital clothing industry. However, the industry is still facing the problems of single utility of generation model, narrow application of clothing data set and lack of objective and unified criteria for generation evaluation. The research in the future will focus on the research and development of integrated multi-modal generation model, the collection of large-scale clothing data sets, and the development of objective criteria for clothing image generation and evaluation.
Keywords: deep learning; GAN; clothing generation; intelligent ad design; virtual fitting.
收稿日期:20220324網絡出版日期:20220613
基金項目:浙江省一般軟科學研究計劃(2022C35099);浙江省絲綢與文化藝術研究中心培育項目(ZSFCRC20204PY)
作者簡介:施倩(1997—),女,河南信陽人,碩士研究生,主要從事數字服裝、計算機視覺方面的研究。
通信作者:羅戎蕾,E-mail:luoronglei@163.com
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
