消費者異質性對推薦系統的影響研究與仿真
2023-06-25 23:37:59陳運昌趙軍
電腦知識與技術 2023年13期
陳運昌 趙軍

摘要:現有商品推薦系統的研究大多通過改進推薦算法以提升推薦效果。很少有研究從消費者視角,探究當面對同一推薦系統,消費者異質性對推薦效果的影響。基于深度強化學習算法,構建細粒度感知消費者行為的推薦系統;從消費者屬性和行為模型兩個角度刻畫消費者異質性;基于多Agent技術組合推薦系統Agent與消費者Agent,構建商品推薦仿真模型。仿真結果表明,消費者異質性對企業利潤、消費者滿意度、點擊率均能產生較大影響。
關鍵詞:推薦系統; 消費者異質性; 多Agent技術; 建模與仿真; 深度強化學習
中圖分類號:TP391.9? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)13-0058-05
開放科學(資源服務)標識碼(OSID)
0 引言
商品推薦系統會根據消費者的瀏覽歷史、交互行為、個人信息等數據,結合商品信息,為異質消費者提供不同的商品推薦[1]。基于深度強化學習(DRL)的推薦系統可以建模用戶行為序列、捕捉動態偏好、最大化長期反饋,在商品推薦領域得到廣泛研究。現有研究大多探究如何改進DRL算法,使推薦系統可以達到更好的推薦效果。然而,很少有研究明確討論消費者異質性對推薦效果的影響。本文從消費者屬性和行為模型兩個角度刻畫消費者異質性,并基于DRL建立推薦系統與消費者交互,從企業利潤、消費者滿意度、點擊率三個方面,深入探討消費者異質性對推薦效果的影響。
目前,國內外對推薦系統研究較多。在提升基于DRL的推薦系統性能方面,潘華麗等人[2]引入預訓練模型和注意力機制實現多模態特征融合,結合DRL算法有效提升了個性化推薦效果;華勇等人[3]將多輪對話推薦系統與DRL相結合,考慮消費者對商品的多粒度信息反饋,有效提升了推薦成功率。在消費者異質性研究方面,程永生等人[4]針對消費者異質社交能力展開研究,基于效用理論分析消費者的購買和推薦行為,探討消費者社交能力對企業利潤的影響;楊敏等人[5]通過偏好特性與敏感特性兩個方面構建旅客異質性,將異質性畫像與DRL算法相結合,有效提升了推薦算法性能。動態的實驗環境非常重要,多Agent建模與仿真方法已廣泛應用于商品推薦的研究[6-7],通過對異質且獨立的消費者Agent及推薦系統Agent建模,可以在抽象層面上合理反映消費者和企業行為,并可以降低模型訓練與測試的成本。綜上,本文從消費者屬性和行為模型兩個角度刻畫消費者異質性,基于DRL構建推薦系統,基于多Agent建模與仿真方法實現動態環境,探討消費者異質性對推薦效果的影響,具有很大的理論與應用價值。
2 基于深度強化學習的推薦系統設計
消費者行為是消費者異質性的表現方式,為了更好地探究消費者異質性對推薦效果的影響,本文基于DRL建立可以細粒度感知消費者行為的推薦系統,將消費者對商品i產生的跳過、點擊、加購行為映射為消費者滿意度和企業利潤,并作為商品i產生的環境獎勵,根據環境獎勵優化推薦系統。
2.1 消費者行為映射
首先介紹消費者行為映射為消費者滿意度和企業利潤的方式。消費者與推薦列表中的商品i交互產生滿意度[sati],滿意度的計算如公式(1) 所示:
[sati=0, x=跳過α·Ii+(1-α)·quality+noise,? ?x=點擊、加購] (1)
其中,x表示消費者對商品i采取的行為,包括跳過、點擊、加購。當消費者跳過商品i時,不產生滿意度;當消費者點擊或加購商品i時,根據公式映射為滿意度sati,其中α表示異質性中的消費者感性,體現了異質性對滿意度的影響。公式計算與文獻[8]相同,在此不再贅述。本文將sati看作環境獎勵ri1。
消費者跳過、點擊和加購行為,需要經過行為轉化過程,才能映射為企業利潤。消費者跳過、點擊或加購推薦列表中的商品i,不會產生利潤,只有購買商品才能產生利潤。考慮到購買行為的稀疏性,推薦系統很難單純依靠購買產生的利潤來優化推薦策略[9],故本文引入消費者行為轉化率,建立跳過、點擊、加購這些相對頻繁的行為與購買行為之間的聯系,以更好地計算商品i的利潤Vi,企業利潤Vi的計算公式如公式(2) 所示:
[Vi(x,i)=0, ? ? ? ? ? ? ?x=跳過150price(i)·1λ,? ?x=點擊120price(i)·1λ,? ?x=加購]? ?(2)
其中,price(i)表示商品i的價格。根據電商用戶行為分析[10],消費者的點擊轉化率在2%左右,加購轉化率在5%左右,因此[150]和[120]分別表示點擊、加購的行為轉化率;[1λ]為歸一化參數,這里λ的取值為[120max(price(i))]。本文將Vi看作環境獎勵ri2。
綜上,消費者與商品i交互,產生的環境獎勵包括消費者行為映射的滿意度ri1和映射的企業利潤ri2,則消費者對商品i的行為映射的環境獎勵ri如公式(3) 所示:
[ri=0.5·ri1+0.5·ri2]? ?(3)
其中,0.5為是歸一化處理的參數。ri、ri1、ri2∈(0,1)。
2.2 構建基于深度強化學習的推薦系統
本文根據Slate-Q[8]算法構建推薦系統。Slate-Q是Ie E等人設計的用于列表推薦的DRL算法,其最大特點是可以計算列表中單個商品i的Q值Qi,并根據Qi計算商品分數以構建推薦列表,如公式(4) :
[Scorei=Ii·Qi]? ? ? ? ? ? (4)
及計算整個推薦列表的Q值,如公式(5):
[Q(s,A)=i∈AP(i | s,A)Qi]? ? ? ? ? (5)
借助于Slate-Q的這種特性,再考慮到Qi取決于商品產生的環境獎勵ri,可以推斷出:結合2.1提出的商品i環境獎勵ri的計算公式,Slate-Q可以細粒度掌握消費者行為,根據具體的消費者行為優化推薦系統,提升推薦效果。
在此基礎上,本文修改了Slate-Q的推薦動作A的環境獎勵R及Q值計算公式。推薦動作A中包含多個商品i,則動作獎勵R如公式⑹所示:
[R=i∈Ari]? ? ? ? ? ? (6)
推薦動作A的Q值[Q(s,A)]的計算公式如公式(7)所示:
[Q(s,A)=i∈AQi]? ?(7)
Slate算法結合公式(4) 與top-k算法構建推薦動作A,結合公式(6) 和(7) 與下文的商品推薦仿真模型,評價推薦動作A。
3 消費者異質性設計
3.1 消費者異質性設計
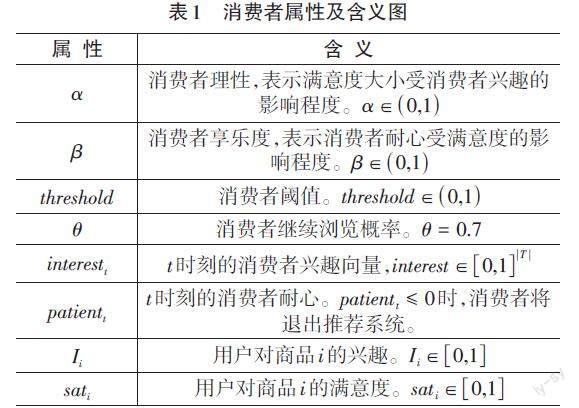
本文根據RecSim[11]中的用戶模型設計消費者異質性,從消費者屬性與消費者行為模型兩個方面,細粒度刻畫消費者異質性。消費者屬性及含義如表1所示:
消費者屬性包括靜態屬性和動態屬性。靜態屬性包括ɑ、β、threshold、θ,構建了消費者的異質性,其中threshold又分為消費者點擊閾值thresholdI和加購閾值thresholdsat,兩個閾值及θ的作用在下文消費者行為模型介紹。動態屬性包括interestt、patientt,Ii、sati,其中interestt、patientt表示消費者的實時狀態,Ii、sati用于下文的消費者行為模型,影響行為和狀態轉換。4個動態屬性計算公式與文獻[10]相同,在此不再給出。
消費者行為模型決定了當消費者面對推薦列表中的商品時,做出跳過、點擊、加購中的哪一個行為。文獻[8]中提出使用MNL和CL作為消費者行為模型。根據消費者行為理論,推薦系統中消費者行為具有位置偏向性和吸引偏向性,這兩種模型均忽略了這種情況,且消費者只能點擊一次與事實不符。本文將Ii、sati兩個動態屬性與DBN(動態貝葉斯網絡)結合,建立消費者行為模型,模型結構如圖1所示:
我們將[Ii?thresholdI]看作消費者被商品i吸引,將[sati?thresholdsat]看作消費者很滿意商品i,將上圖分解為消費者行為規則如表2所示:
3.2 基于多Agent的商品推薦仿真模型
本文利用RecSim[11]推薦系統仿真平臺,基于多Agent技術建立商品推薦仿真模型,模型包含異質性消費者Agent、推薦系統Agent和商品,在仿真環境下探究消費者異質性對推薦效果的影響。其中,消費者Agent為3.1建立的異質性消費者,推薦系統Agent為2.2構建的推薦系統。消費者Agent需要與商品列表交互,才能體現出消費者異質性。因此商品仿真模型的設計同樣重要。本文根據RecSim中的文檔模型建立商品仿真模型,本模型可以生成任意數量的商品,商品具體參數與含義如表3所示:
T為商品主題集,[topic∈T],[T=5],即本文設置五種商品主題,每個商品只屬于一種主題。price為商品價格,服從分布U(a,b),主題不同價格也不同:topic0的商品價格在[10,50]之間,topic1在[50,100]之間;topic2在[100,150]之間;topic3在[150,200]之間;topic4在[200,250]之間。
綜上,本文基于改進Slate-Q算法構建可細粒度感知消費者行為的推薦系統,從消費者屬性與消費者行為模型兩個方面構建消費者異質性,基于多Agent技術建立商品推薦仿真模型。接下來進行仿真實驗,探討消費者異質性對推薦效果的影響。
4 仿真實驗
4.1 仿真過程描述
本文將消費者開始瀏覽至退出推薦系統的整個過程稱為一個交互回合。在一次推薦過程中,推薦系統會產生推薦列表,消費者會與列表中的商品進行交互,產生企業利潤及消費者滿意度、點擊率,并改變自身狀態。一個交互回合會重復上述推薦過程,直到消費者退出推薦系統。消費者異質性會導致消費者狀態及動作不同,進而導致產生的企業利潤等推薦效果不同。因此,對一個交互回合進行仿真,可以探究消費者異質性對推薦效果的影響。
4.2 仿真實驗設置
4.2.1實驗指標設置
本文設置三個實驗指標以展示推薦效果,(8)(9)(10)為計算公式。E表示一個交互回合中涉及的商品集合。
利潤V:
[V=i∈EVi]? ? ?(8)
該指標表示消費者在一個交互回合中產生的總利潤。其中,Vi表示消費者與商品i交互產生的利潤。
消費者滿意度Sat:
[Sat=i∈Esati]? ?(9)
該指標表示消費者在一個交互回合中產生的總滿意度。其中,sati表示消費者與商品i交互產生的滿意度。
消費者點擊率Click_rate:
[Click_rate=i∈EclickiE]? (10)
該指標表示消費者在一個交互回合中產生的點擊率。其中,clicki表示消費者是否點擊了商品i,是為1,不是為0;|E|表示一個交互回合中總的商品個數。
4.2.2 輸入參數設置
消費者Agent模型需設置7個參數。五個靜態屬性默認參數值:α=0.5,β=0.1,thresholdI=0.5,thresholdsat=0.7,θ=0.7;兩個動態屬性初始參數值:t=0時,interestt=[1, 0.8, 0.5, 0.2, 0],patient=10。
企業Agent模型需設置3個參數。候選商品集D的大小|D|=20;推薦列表長度slate_size=4;折扣因子γ=1。
總之,在設置了實驗指標和輸入參數后,進行了40 000個時間步的模擬,其中包含了大約3 000~4 000個交互回合,以訓練本文的基于DRL的推薦系統,并進行100個交互回合的測試,以探討消費者異質性對推薦效果的影響。
4.3 消費者異質性實驗
探究消費者異質性對推薦效果的影響,主要是探究消費者理性α、消費者享樂度β、興趣閾值 interest_threshold、滿意度閾值sat_threshold這些靜態屬性對推薦效果的影響。在接下來的實驗中,本文先按照默認值運行一次實驗作為對照組,之后修改某一種靜態屬性的取值,其余屬性取默認值,運行試驗記錄指標變化,以探討消費者異質性對推薦效果的影響。
4.3.1 消費者理性α
消費者理性表示決定消費者對商品的滿意度是更看重對商品的興趣還是商品本身質量。參數越高,表示滿意度更看重商品質量;參數越低,表示滿意度更看重對商品的興趣。α依次取值0.5/0.2/0.8,其余屬性取默認值,其中0.5為對照組實驗,三次實驗結果如表4所示。
橙、藍、紅線分別代表三個取值的實驗結果。利潤V和滿意度Sat指標下,紅線表現最差,橙和藍線較接近;點擊率Click_rate指標下,藍線表現最差,橙線略優于紅線。可見,更理性的消費者(α=0.8) ,其在一個交互回合中雖然有較高的點擊率,但僅能產生較少的企業利潤和自身滿意度;不理性的消費者(α=0.2) ,其在一個交互回合中雖然點擊率不高,但能產生的企業利潤和自身滿意度較高。
4.3.2 消費者享樂度β
消費者享樂度表示消費者耐心受滿意度的影響程度,當β取值較大時,滿意度對耐心的影響較大,顯著增加消費者的交互回合長度。β依次取0.5/0.2/0.8,其余屬性取默認值,其中0.5為對照組實驗,三次實驗結果如表5所示。
橙、藍、紅線分別代表三個取值的實驗結果。三幅圖整體來看,藍、橙、紅線的長度依次增加,可見享樂度β越高,消費者的回合長度越長。利潤V和滿意度Sat指標下,藍線表現最差,橙和紅線較接近;點擊率Click_rate指標下,藍線和紅線表現均差與橙線。可見,享樂度更高的消費者(β=0.8) ,在一個交互回合中能產生較高的企業利潤和自身滿意度,但點擊率較低;享樂度更低的消費者(β=0.2) ,企業利潤、自身滿意度及點擊率均較差。
4.3.3 興趣閾值 interest_threshold
興趣閾值表示消費者被商品吸引點擊的閾值,滿意度閾值越高,消費者應該越難點擊。interest_threshold依次取值0.5/0.2/0.8,其余屬性取默認值,其中0.5為對照組實驗,三次實驗結果如表6所示。
橙、藍、紅線分別代表三個取值的實驗結果。可見,消費者興趣閾值參數在很大程度上影響推薦效果。興趣閾值越低,一個交互回合內產生的企業利潤、消費者自身滿意度、點擊率以及回合長度越高。
4.3.4 滿意度閾值sat_threshold
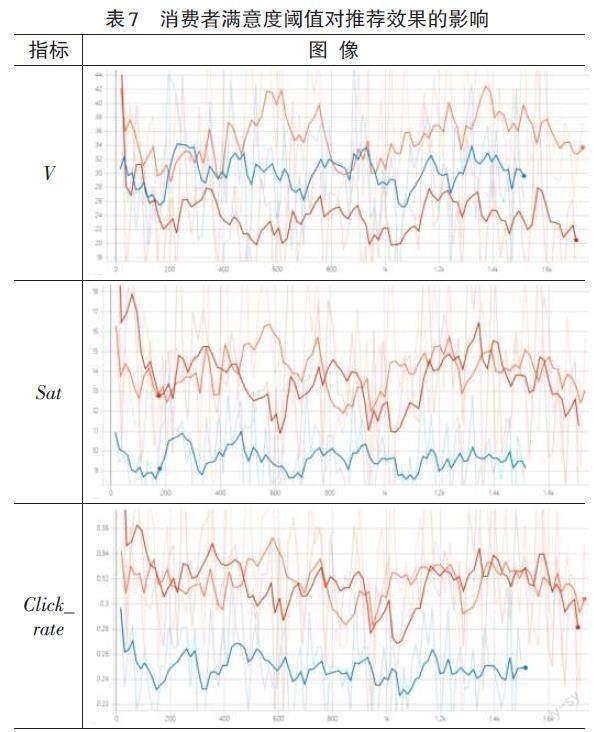
滿意度閾值表示消費者將商品加入購物車的閾值,滿意度閾值越高,消費者應該越難加購。sat_threshold依次取值0.7/0.5/0.9,其余屬性取默認值,其中0.7為對照組實驗,三次實驗結果如表7所示。
橙、藍、紅線分別代表三個取值的實驗結果。利潤V指標下,紅線表現最差,藍線略低于橙線;滿意度Sat和點擊率Click_rate指標下,藍色線表現最差,藍線與橙線表現相近。可見,滿意度閾值偏高的消費者(sat_threshold=0.9),其在一個交互回合中產生的自身滿意度和點擊率較高,但僅能產生較少的企業利潤;滿意度閾值偏低的消費者(sat_threshold=0.5),其在一個交互回合中產生的企業利潤較高,但其產生的自身滿意度和點擊率均很低。
5 總結與展望
本文研究了消費者異質性對推薦系統推薦效果的影響。基于改進Slate-Q算法構建可細粒度感知消費者行為的推薦系統,從消費者屬性與行為模型兩方面構建消費者異質性,基于多Agent建模與仿真方法建立商品推薦仿真環境。仿真實驗表明,消費者理性、享樂度、興趣閾值、滿意度閾值等異質屬性,均能對一個交互回合中的企業利潤、消費者自身滿意度、點擊率產生重要影響。
參考文獻:
[1] 宋倩.基于關聯規則算法的電子商務商品推薦系統設計與實現[J].微型電腦應用,2021,37(10):205-208.
[2] 潘華莉,謝珺,高婧,等.融合多模態特征的深度強化學習推薦模型[J/OL].數據分析與知識發現:1-18[2023-02-10].http://kns.cnki.net/kcms/detail/10.1478.G2.20220907.1507.008.html.
[3] 姚華勇,葉東毅,陳昭炯.考慮多粒度反饋的多輪對話強化學習推薦算法[J].計算機應用,2023,43(1):15-21.
[4] 程永生.基于消費者異質性社交能力的推薦獎勵策略[J].運籌與管理,2020,29(12):231-239.
[5] 楊敏,李宏偉,任怡鳳,等.基于旅客異質性畫像的公鐵聯程出行方案推薦方法[J].清華大學學報(自然科學版),2022,62(7):1220-1227.
[6] Ghanem Nada..Balancing consumer and business value of recommender systems:a simulation-based analysis[J].Electronic Commerce Research and Applications,2022(55):101195.
[7] Zhou M, Zhang J, Adomavicius G. Longitudinal Impact of Preference Biases on Recommender Systems' Performance[J]. Kelley School of Business Research Paper, 2021(10).
[8] Ie, Eugene et al. SlateQ - A Tractable Decomposition for Reinforcement Learning with Recommendation Sets[C]. International Joint Conference on Artificial Intelligence.(2019): 2592-2599.
[9] Pei C H,Yang X R,Cui Q,et al.Value-aware recommendation based on reinforcement profit maximization[C]//WWW '19:The World Wide Web Conference.May 13 - 17,2019,San Francisco,CA,USA.New York:ACM,2019:3123-3129.
[10] 郝浩宇,任杰成.電商平臺用戶行為分析系統研究[J].信息與電腦,2021,33(21):80-82.
[11] Ie E,Hsu C W,Mladenov M,et al.RecSim:a configurable simulation platform for recommender systems[EB/OL].2019:arXiv:1909.04847.https://arxiv.org/abs/1909.04847.
【通聯編輯:李雅琪】
