基于LDA主題模型對電子商務專業(yè)崗位特征的挖掘
2023-06-25 23:37:59唐勇
電腦知識與技術 2023年13期
唐勇
摘要:文章使用Python語言基于LDA模型對電子商務專業(yè)的崗位特征進行挖掘。首先使用Selenium庫對人才招聘網站的求職信息進行采集,分析整理了電子商務專業(yè)崗位的主要職位名稱;然后對每個職位的崗位內容進行采集;使用skLearn機器學習庫對崗位內容進行LDA建模,分析出電子商務崗位的五大主題即:管理能力、服務能力、設計能力、直播能力和薪酬待遇,并計算了每個崗位主題下的主要特征詞匯,最后對這些主題進行了可視化處理,分析了各個主題的區(qū)別度和相關性。
關鍵詞:主題模型;LDA模型;電子商務崗位
中圖分類號:TP311.52? ? ? 文獻標識碼:A
文章編號:1009-3044(2023)13-0069-04
開放科學(資源服務)標識碼(OSID)
0 引言
人工智能、大數據及區(qū)塊鏈等新興技術正有力地推動著電子商務行業(yè)的新發(fā)展。例如網絡商品的展示已經從早期的圖片和文字轉變?yōu)橐远桃曨l和直播為主要形式;商品的網絡推廣也從關鍵詞推廣轉變?yōu)橐匀斯ぶ悄芎痛髷祿橹饕夹g手段的智能推薦;售前和售后的客戶服務環(huán)節(jié)則出現了智能客服機器人和智能語音應答等人工智能技術;在網店的運營數據分析方面人工智能算法和大數據處理技術也被應用起來。
電子商務行業(yè)的這些新變化引發(fā)了電子商務相關崗位技能的新變化,也對電子商務專業(yè)的人才培養(yǎng)提出了新的挑戰(zhàn)。然而,不同的電子商務企業(yè)對電子商務崗位技能的要求不盡相同,本文使用采用LDA主題模型對招聘網站中的電子商務專業(yè)崗位進行數據分析,發(fā)現電子商務專業(yè)崗位技能的主題和特征詞,從而為電子商務專業(yè)的人才培養(yǎng)提供借鑒。
1 LDA主題模型介紹
LDA(Latent Dirichlet Allocation) 是潛在迪利克雷分配的英文簡寫,屬于無監(jiān)督機器學習的一種算法,主要用于從大量文本數據中挖掘出潛在的主題信息。該算法認為每篇文檔是由主題的多項式分布表示,稱為文檔主題分布;而每個主題是由單詞的多項式分布表示,稱為主題單詞分布。文檔的生成過程是對文檔中每一個位置先由文檔主題分布隨機生成一個主題,然后由該主題單詞分布隨機生成該位置的單詞[1]。
盡管PLSA(概率潛在語義分析)模型也采用了文檔的主題分布和主題的單詞分布,但是與PLSA模型的不同之處在于:LDA模型假定文檔的主題分布和主題的單詞分布都具有先驗分布,并且這兩個分布的參數都服從迪利克雷分布,而PLSA模型并沒有使用先驗分布。使用迪利克雷分布作為先驗分布的好處是:一方面可以避免在參數學習過程中產生過擬合問題;另一方面是由于文檔主題分布和主題單詞分布都是多項式分布,而多項式分布的共軛分布是迪利克雷分布,因此可以直接推斷出其后驗分布也服從迪利克雷分布,從而方便了相關參數計算。
LDA模型算法中主題數K、文檔的主題分布概率參數α及主題的單詞分布概率參數β均為算法的超參數,需要預先設定。一般情況下,α和β的初始值可以設置為1/k,那么模型的主題數K就非常重要了。在自然語言處理中困惑度是評價語言模型的重要指標,效果越好的語言模型在測試數據集上的困惑度越小。通過計算不同主題數下困惑度的變化可以找出主題數K,當困惑度曲線出現拐點時的主題數K通常是較好的主題數。
2 LDA模型的語料庫
網經社電子商務研究中心2022年發(fā)布的電子商務人才狀況調查報告顯示,企業(yè)對于電子商務類人才的需求主要有:運營類、視頻直播類、客戶服務類及網絡營銷類[2]。劉亞寧、侯海濤等人基于招聘網站的人才需求將電子商務的崗位類型分為商務類、管理類和技術類[3];曾奕棠采用崗位群的視角將電子商務崗位分為技術類崗位群、商務類崗位群及綜合管理類崗位群,其中技術類崗位群包括了頁面設計、網店美工、信息編輯等崗位,商務類崗位群包括了網絡營銷、網絡策劃與推廣、客戶服務等崗位;綜合崗位類崗位群包括了客戶服務經理、網店運營管理等崗位[4]。程丹和詹增榮基于勝任力模型并結合企業(yè)和相關院校的調研數據,將電子商務專業(yè)的崗位分為技術型和營銷型,其中技術型人才核心崗位包括了網店美工、淘寶店長、網絡運維和頁面設計,營銷型人才核心崗位包括了運營專員、推廣專員和網絡客戶[5]。從上述企業(yè)和學者的研究結論可以看出:電子商務崗位主要集中于網店運營、網店美工、直播營銷、客戶服務等崗位。
招聘網站中匯集了大量的企業(yè)人才需求信息,能夠真實反映企業(yè)的崗位技能要求。本文選取前程無憂作為LDA主題模型的數據來源。前程無憂網站是國內較有影響的人才招聘網站,該網站中的求職信息能夠真實反映企業(yè)對電子商務專業(yè)的崗位技能要求。本文采用Python語言的Selenium工具包從前程無憂網站中獲取總計2 000余條電子商務專業(yè)的崗位招聘信息。
Selenium是Web應用程序的自動化測試工具包,可以用代替人來模擬Web瀏覽器訪問Web頁面。由于Selenium是間接地調用瀏覽器并通過瀏覽器向目標網站發(fā)送訪問指令,因此與真實用戶訪問Web頁面沒有本質的差異。通過對前程無憂網站的招聘列表頁面進行解析,成功采集到電子商務相關崗位的名稱及崗位對應的詳情頁網址,共計兩千條數據。
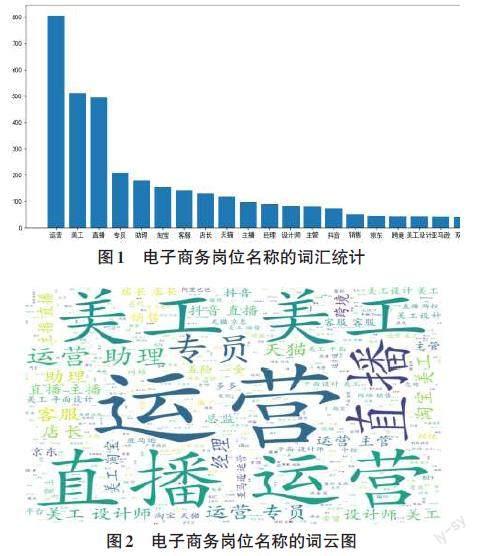
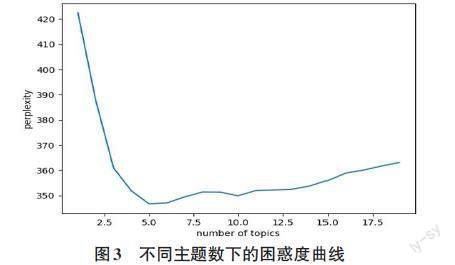
對于數據中的崗位名稱信息,本文使用Jieba分詞工具對齊進行中文分詞處理,接著基于百度停用詞表,過濾掉崗位名稱中的一些常規(guī)詞匯、停用詞和長度小于兩個字符的單字詞匯;然后使用Panadas數據分析工具和Matplotlib繪圖工具統(tǒng)計出崗位名稱中的高頻詞,如圖1所示;最后使用wordcloud工具包將上述詞匯統(tǒng)計數據轉換成詞云圖,如圖2所示。可以看出在電子商務專業(yè)的崗位名稱中運營、美工、直播等詞匯出現的頻率最高,其次是專員、助理、淘寶和店長等詞匯。通過對崗位名稱的詞匯統(tǒng)計可以發(fā)現目前企業(yè)招聘電子商務專業(yè)人才的主要需求。
3 LDA模型的構建
對崗位名稱的詞匯統(tǒng)計僅能淺層次的分析電子商務崗位的主要聚集方向,但是對于深層次的電子商務崗位特征信息還需要采集每個崗位的詳情頁內容,挖掘每個崗位的職責和任職要求。本文使用Selenium工具包分批次采集了上述崗位詳情頁列表。使用Jieba分詞工具對每個詳情頁文本進行了中文分詞處理、過濾了常用停用詞和長度小于兩個字符的單字詞匯,形成了電子商務崗位信息文檔共計2 000篇,構成了LDA主題模型的文檔集合。
LDA主題模型可以使用Python語言的gensim工具包或者sklearn庫來實現。LDA模型的主題數K需要人為選定,通常是依據計算不同主題數K值下困惑度P的變化情況來確定主題數。但是gensim工具包并沒有提供困惑度的計算,因此本文采用sklearn庫實現LDA模型。sklearn庫的decomposition模塊含有各種數據降維的算法接口,其中LatentDirichletAllocation接口就是LDA主題模型的線性變分算法實現接口。LatentDirichletAllocation接口要求輸入數據必須是特定格式的詞頻矩陣,矩陣中的每個元素表示為:(文檔序號,單詞編號,詞頻數),這里的文檔序號將文檔集合中的第1篇文檔編號為0,依次編號;文檔集合中的所有詞匯集合構成一個詞語列表,每個詞從1開始依次編號;例如:詞頻矩陣元素(1923,1217,3) 表示的是第1924篇文檔中編號為1217的詞匯在該文檔中總共出現了3次。使用sklearn的CountVectorizer類可以將之前使用Jieba分詞工具得到的文檔詞匯列表轉變文檔詞頻矩陣。具體代碼如下所示。
wordlist= [w for w in [" ".join(words) for words in wordlist]]
tf_vectorizer = CountVectorizer( max_features=1500, max_df =0.95, min_df =2)
tf = tf_vectorizer.fit_transform(wordlist)
上述代碼中wordlist就是文檔的詞匯列表;CountVectorizer類的參數max_features=1500表示選取詞匯表中詞頻數在前1500的詞放入詞頻矩陣;參數max_df=0.95表示當某個詞在所有文檔中出現頻率大于95%時該詞不放入詞頻矩陣;參數min_df=2表示當某個詞在所有文檔中出現的頻數小于2時,該詞匯不納入詞頻矩陣。max_df的設定實質上過濾了在所有文檔中都使用的常用詞,min_df則過濾了所有文檔都極少使用的詞匯。CountVectorizer類的fit_transform方法完成了將文檔詞匯列表轉換為詞頻矩陣的過程。如果使用print方法打印fit_transform方法的返回值tf,可以查看到詞頻矩陣的每個元素。
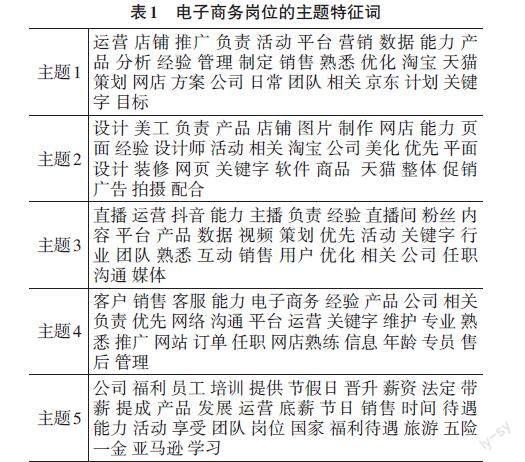
在計算出詞頻矩陣tf后就可以將其作為數據源,輸入到LatentDirichletAllocation接口中訓練LDA模型,但是LDA模型需要預設主題數K。根據前述電子商務崗位的名稱詞匯統(tǒng)計信息,本文將主題數K的范圍設定在1到20的范圍內,并計算不同主題數下模型困惑的數值,并使用matplotlib繪制出主題數與困惑度的曲線,如圖3所示。可以看出當主題數K的值為5時,困惑度曲線出現了明顯的拐點,因此,選擇LDA模型的主題數K的值為5較為合適。
在設定了主題數K的值之后就可以將LDA模型中的文檔的主題分布概率參數及主題的單詞分布概率參數的值設置為1/K。構建LDA主題模型的主要代碼如下所示。
lda = LatentDirichletAllocation(n_components=n_topics, max_iter=50, learning_method='batch', learning_offset=50, doc_topic_prior=1/ k,? topic_word_prior=1/k, random_state=666)
lda.fit(tf)
在上述代碼中,LatentDirichletAllocation方法的參數doc_topic_prior代表的是文檔的主題分布概率參數,而topic_word_prior代表的是主題的單詞分布概率參數,它們的初始值都被設置為1/K,max_iter表示算法的迭代次數,其值為50,表示模型將應用線性變分算法迭代50次后計算出模型參數和的值。最后使用fit方法對詞頻矩陣tf進行數據擬合,完成了LDA主題模型的訓練。
4 電子商務崗位的主題特征分析
經過訓練LDA主題模型中包含有詞匯表所有詞匯在各個主題下的評分信息,可以通過lda變量的_component屬性獲取各個主題及對應的特征詞匯評分。結合之前訓練得到的文檔詞匯矩陣tf_vectorizer變量就可以得到每個主題下評分最高的特征詞匯。計算每個主題下評分較高的特征詞匯程序代碼如下所示。
feature_names=tf_vectorizer. get_feature_names_out()
n_top_words=30
for topic_index, topic in enumerate(lda.components_):
topic_words= " ".join([feature_names[i] for i in topic.argsort()[:-n_top_words - 1:-1]])
pprint(topic_ words)
tf_vectorizer變量的get_feature_names_out方法可以獲取到語料庫中的所有詞匯。本文選擇n_top_words=30表示在每個主題下選取評分最高的前30個詞匯。獲取的主題特征詞匯見表1。
從獲取的主題特征詞匯表中可以看出,每個主題的特征詞匯有明顯的區(qū)別,部分詞匯是各個主題都包含的。主題1可以概括為管理能力,其崗位的特征包括店鋪的運營推廣、平臺的營銷、數據分析能力、計劃制定和管理能力及主流的電商平臺(淘寶、京東和天貓)的運營經驗;主題2可以概括為設計能力,其崗位特征包括產品和店鋪的圖片制作、美化和裝修能力,促銷、拍攝和配合能力等;主題3可以概括為直播能力,其崗位特征包括抖音的直播運營能力、有責任心和經驗,熟悉直播間、粉絲、內容、產品、視頻等直播元素,能夠與用戶互動、懂得溝通;主題4可以概括為服務能力,其崗位特征主要是客服能力、銷售能力和經驗、責任心和溝通能力,關鍵字維護和推廣,對網店的熟悉、訂單和售后的管理等;主題5是崗位的薪酬特征,包括崗位的福利待遇、職業(yè)發(fā)展空間、員工薪酬工資等方面。除了主題5之外其他主題都與電子商務專業(yè)的崗位技能要求有關,可以作為崗位的特征信息。
基于模型獲取的主題和主題的特征詞匯,本文使用pyLDAvis庫對LDA主題模型進一步展開可視化分析。pyLDAvis庫是可視化交互式的主題模型展示工具。pyLDAvis庫的lda_model類接收參數包括:已訓練完的lda模型、詞頻矩陣tf及文檔詞匯矩陣tf_ vectorizer,并調用show方法完成LDA模型的可視化展示。最終的LDA模型可視化效果如圖4所示。圖中左側的五個圓分別表示五個主題;選擇每個主題可以得出該主題下評分較高的前30個主題詞;圖中深色水平條塊表示該詞匯在此主題下的頻數,而淺色條塊表示該詞匯在全部文檔的頻數。
可視化分析的結果可以看出主題2(設計能力)和主題5(薪酬特征)與其他主題有明顯的區(qū)別度,這是由于設計能力和薪酬特征的相關詞匯較為專業(yè),與其他主題沒有太多的相關性;而主題1(管理能力)、主題3(直播能力)和主題4(服務能力)具有一定的重合度。尤其是主題1和主題4有較大的重合,這也表明了電子商務的運營、推廣和客戶服務、售后服務具有較大的相關性,而直播能力相對較為專業(yè)和獨立。
5 總結
本文通過LDA模型分析電子商務專業(yè)崗位的潛在特征,基于特征詞匯的評分概括為五個主題,即:管理能力、服務能力、直播能力、設計能力和薪酬特征,其中,管理能力和服務能力具有較多的重疊特征詞匯,而直播能力和管理能力具有較小的重疊特征詞匯,但是直播能力、服務能力和設計能力彼此具有相對對立的特征詞匯,這為電子商務專業(yè)的人才培養(yǎng)方向提供了一定的借鑒。在后續(xù)研究中需要擴大并優(yōu)化模型的數據源,以期進一步分析主題間的重疊特征詞匯,發(fā)現新的特征,另一方面對LDA模型自身的局限性要結合其他模型進行優(yōu)化,以期提升主題劃分的精確性。
參考文獻:
[1] 李航.統(tǒng)計學習方法[M].2版.北京:清華大學出版社,2019:391-393.
[2] 網經社中國電子商務研究中心.2021年度中國電子商務人才狀況調查報告[EB/OL].(2022-05-22)[2022-10-19].http://www.100ec.cn/detail--6611176.html.
[3] 劉亞寧,侯海濤,孫東陽,等.基于招聘網站的電子商務崗位能力要求研究[J].現代商業(yè),2022(10):65-67.
[4] 曾奕棠.基于崗位群的電子商務專業(yè)大學生就業(yè)能力研究[J].電子商務,2018(1):70-71.
[5] 程丹,詹增榮.基于勝任力模型下高職電子商務人才職業(yè)崗位能力及素質研究[J].電子商務,2018(6):67-69.
【通聯編輯:謝媛媛】
