數據和知識驅動的空戰目標集群類型綜合識別
2023-06-27 04:58:08張會霞梁彥馬超雄汪冕喬殿峰
航空學報 2023年8期
張會霞,梁彥,*,馬超雄,汪冕,喬殿峰
1.西北工業大學 自動化學院 信息融合技術教育部重點實驗室,西安 710129
2.中國電子科技集團第二十研究所,西安 710068
在信息化條件下,空戰戰場環境日漸復雜,多平臺協同作戰正在逐步成為空戰的主流[1-2]。集群通過實時動態編組,在線任務分配、集群協同突防的方式,實現了以量取勝、動態聚能、精準釋能的飽和攻擊,整體效能大于單個效能的累加和,即作戰效能涌現“1+1>2”的系統增效[3-4]。因此,如何根據空戰戰場態勢信息進行實時、準確的集群場景分析和威脅評估是提高我方作戰成功率和生存率的關鍵。亟需綜合利用數據和知識對集群進行由粗到細的精細化分析,輔助指揮員快速準確全面理解戰場態勢。
聚類不需要對數據的標簽有初步的認識,它處理未知區域的數據結構劃分,也是進一步研究集群精細化識別的基礎[5]。集群分析中聚類的主要任務是基于正確的相似性度量將數據點劃分為適當的類。聚類算法一般分為以下幾種: 劃分方法、層次方法、基于密度方法和基于網格方法。K-means 算法高度依賴一組給定的初始聚類中心,聚類結果容易受到離群值的影響[6]。相比之下,分層方法以聚集或分裂的方式對數據集進行多級分區。基于密度的聚類是一種非參數方法,將聚類視為高密度數據點,由低密度數據點組成的連續區域相互分離,可以檢測任意形狀的聚類[7]。但是,適當的閾值設置因數據集的不同而不同,仍然沒有有效的方法來預先確定這些閾值。作為一種流行的基于密度的聚類算法,快速搜索和發現密度峰值聚類(Density Peaks Clustering,DPC)算法也可以處理非球形數據,不需要手動指定類別的數量[8]。DPC 算法的參數選擇比DBSCAN 算法更容易。因此,出現了許多關于DPC 的有價值的工作。HaloDPC 算法不僅提出了合理的Halo 處理方法,而且改進了聚類結果[9]。DPC-KNN 算法將k最近鄰的思想融入到距離計算和分配過程中,使分配過程更加合理[10]。然而,這些DPC 算法的變體對于分布不平衡的聚類的劃分并不是很有效,因為它們只使用一個指標(近鄰點的距離)來同時處理內部點和邊界點。因此,將上述2 個指標結合起來,增強尋找邊界點的能力,使集群聚類準確分離是有價值的研究。
集群識別是態勢推理的重要組成部分,且此識別過程主要依據基于D-S 證據、專家系統、模板匹配、貝葉斯網絡等方法。針對稀疏信息環境下的數據融合問題,基于D-S 證據推理設計了判斷戰場事件可靠性的框架[11]。一種基于知識的海戰場態勢評估輔助決策系統利用知識發現技術對戰場數據進行分析,綜合利用數據、知識和模型實現態勢評估[12]。基于模板匹配的計劃識別與態勢評估系統通過識別模型以多假設的形式描述個體的當前和未來的活動[13]。然而模板庫的構成用到大量的軍事規則和領域專家知識,實現難度大、維護更新難;采用分層貝葉斯網絡(Bayesian Network, BN)對作戰計劃分級建模表示,通過提取實時的戰場事件及當下的作戰單元動作,實現分層BN 結構構建[14]。BN 利用網絡參數的實時調整能夠動態地適應復雜多變的戰場環境,實現對敵方群類型/意圖的準確推理[15-16]然而在日益復雜的戰場環境中,傳統給定參數的貝葉斯網絡不能滿足日益復雜的集群作戰中集群推理分析,僅僅依靠專家經驗確定或數據學習2 種方式均存在弊端。因此,需要充分利用數據和知識雙重優勢,還需考慮數據在時間上相關性,實現復雜戰場環境下集群類型推理優化和提升。
軍事強國均在加緊研究適用于集群的分析與應用,美國多個研究機構紛紛圍繞無人機“蜂群”作戰展開關鍵技術試驗,“小精靈”“郊狼”“低成本無人機集群技術”等項目不斷出現新的研究突破[17],面對緊張的國際形勢,中國在作戰集群方面研究的緊迫性日益凸顯。集群作戰要在聯合部隊內建立靈活以及具有適應性的編隊,改變部隊部署態勢能夠加強對敵威懾。隨著數據的收集和專家經驗的總結,典型作戰樣式被充分挖掘,分析出其主要包括:“忠誠僚機”戰術騙擾、有人/無人智能協同、“蜂群”智能協同等典型樣式[18]。有學者對目標估計和群狀態(群大小、形狀等)進行估計,提出了群體目標的動態模型和觀察函數,并構建估計狀態集的鄰接矩陣,實現戰斗機編隊跟蹤和群形狀估計[19];還有將集群整體作為一個擴展目標,通過建立更符合實際的量測模型,提升了對集群的跟蹤精度[20]。群意圖分析方面,在綜合群目標的基本組成、公開活動、作戰條例等各類信息構建的知識圖譜基礎上,提出一種多實體分層貝葉斯網絡來推理目標意圖[21];利用集群情景分析法對系統內外相關問題進行系統分析,設計出多種可能的未來前景,對系統發展態勢做出自始至終的情景與畫面描述,有效描繪未來變化的進程[22]。群任務分派方面,集群在執行任務過程中,不同飛機各司其職,在有限資源下進行資源分派,一方面保護自身安全,一方面協同完成指定作戰任務[23-25]。隨著未來作戰節奏與進程加快,如果能夠預判出集群編隊類型,就可輔助指揮員分析出敵方下一步或幾步行動,提前做出部署,建立作戰優勢。目前,集群相關研究更多停留在目標的幾何隊形識別、集群內部資源的任務分派,但是集群類型作為集群任務、意圖等緊密相關的重要因素缺乏深入研究。綜上,敵方集群類型精細化識別不僅是國家在應對國防安全所面臨的重要難題,也是學術研究中值得探究的內容。
基于上述學術研究和應用需求討論,本文提出分層精細化推理的目標集群識別框架,預識別層檢測目標運動過程中的集群的分群/合群,得到群的初步識別結果;在再識別層綜合分析集群執行任務、運動、電磁等多種特性,在此基礎上構建了集群類型推理網絡結構,進一步又設計了基于專家經驗及少量數據樣本的推理網絡參數學習方法,得到完整的推理網絡,實現在集群內部進行精細化推理。該研究的特點主要包括:提出集群類型推理的新問題,構建了分層精細化推理的集群場景識別框架;所構建的集群推理網絡發揮了知識和數據雙重優勢,具備從粗到精的集群目標識別能力,實現集群的精細化識別與判讀。
1 問題描述
不同于傳統的作戰樣式,集群作戰要在聯合部隊內建立靈活以及具有適應性的編隊,通過改變部隊部署完成對應的執行任務。不能僅從組成單元的行為推斷,只分析局部不可能得出集群/整體性推理結果(集群類型、意圖等)。空中作戰不斷演變的特點使態勢要素間的關系更加復雜多變,如圖1 所示,單元之間組合表現出不同的飛行速度、高度、飛行目的地等特點,這些特點本質上反應的是集群編隊類型,準確綜合分析出集群編隊的類型會輔助指揮員對作戰態勢全面理解,亟需對集群編隊類型進行精細化識別。
根據圖1 反應的戰場中集群協作執行任務,其隱含的集群類型推理識別正是戰場態勢分析的關鍵要素,如何在復雜戰場環境下對集群類型有效識別主要面臨兩大問題。
問題1如何適應復雜多變的集群作戰場景綜合分析,優化問題如下:
最優:分層推理框架。
問題2如何對集群精細化分析,主要是從推理網絡的結構確立和參數獲得兩方面,優化問題具體如下:
其中,θ為推理網絡參數;γ為推理網絡結構。
綜上,亟需對整個集群進行快速的劃分,通過借助多元知識和多特征綜合,動態推理出集群類型,輸出集群編隊推理結果的概率度量。
2 基于數據和知識的推理識別網絡構建
復雜戰場環境下集群在執行任務中隨著靠近任務區域,集群開始緊湊,協同執行任務,如圖2 所示。然而如何在集群有效聚類分群之后對集群類型進行精細化仍是開放性話題。
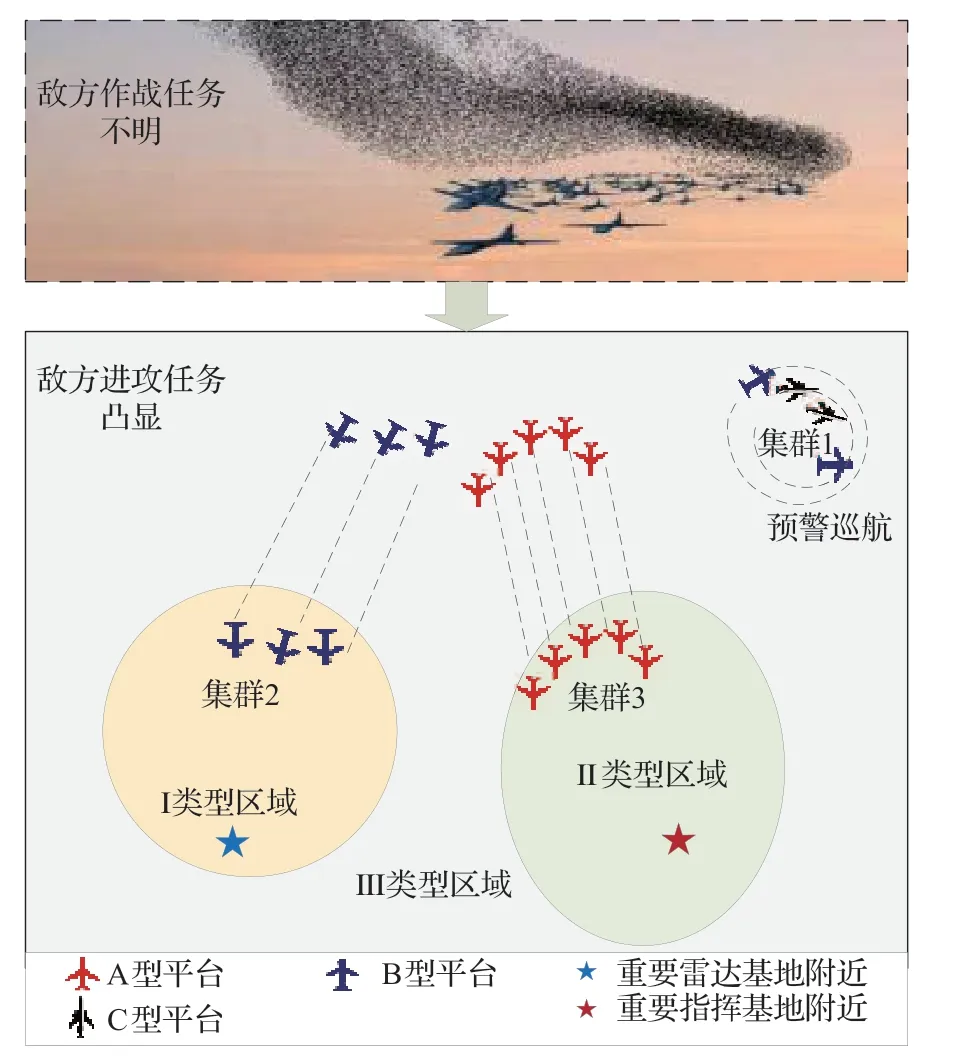
圖2 目標集群態勢變化Fig.2 Change for target cluster situation
本文擬綜合數據和知識的優勢使設計框架具備空間要素聚合,時間動態推理的能力,達到漸次提升集群識別精度目的,給出框架設計圖如圖3 所示。對專家知識、領域知識、作戰規則等多元充分分析,即知識收集,用于抽取推理識別網絡構建時用的約束條件和規則,在此基礎上設計分層精細化推理的集群類型識別來提高集群編隊識別的精度。首先依據典型場景(轉場、掃蕩等)利用基于相鄰點距離和數據點非對稱度量的有效局部密度計算方法進行初步的集群空間劃分;然后從功能性的角度出發,在多元知識里提取了關鍵約束條件和因素之間的相關性,綜合多方面因素,設計了集群類型推理網絡結構;最后基于所設計的一種基于專家經驗及少量時間序列樣本參數學習方法,通過有限數據的充分利用得到推理識別網絡的參數修正,進而在集群內部進行精細化推理,識別出集群類型。
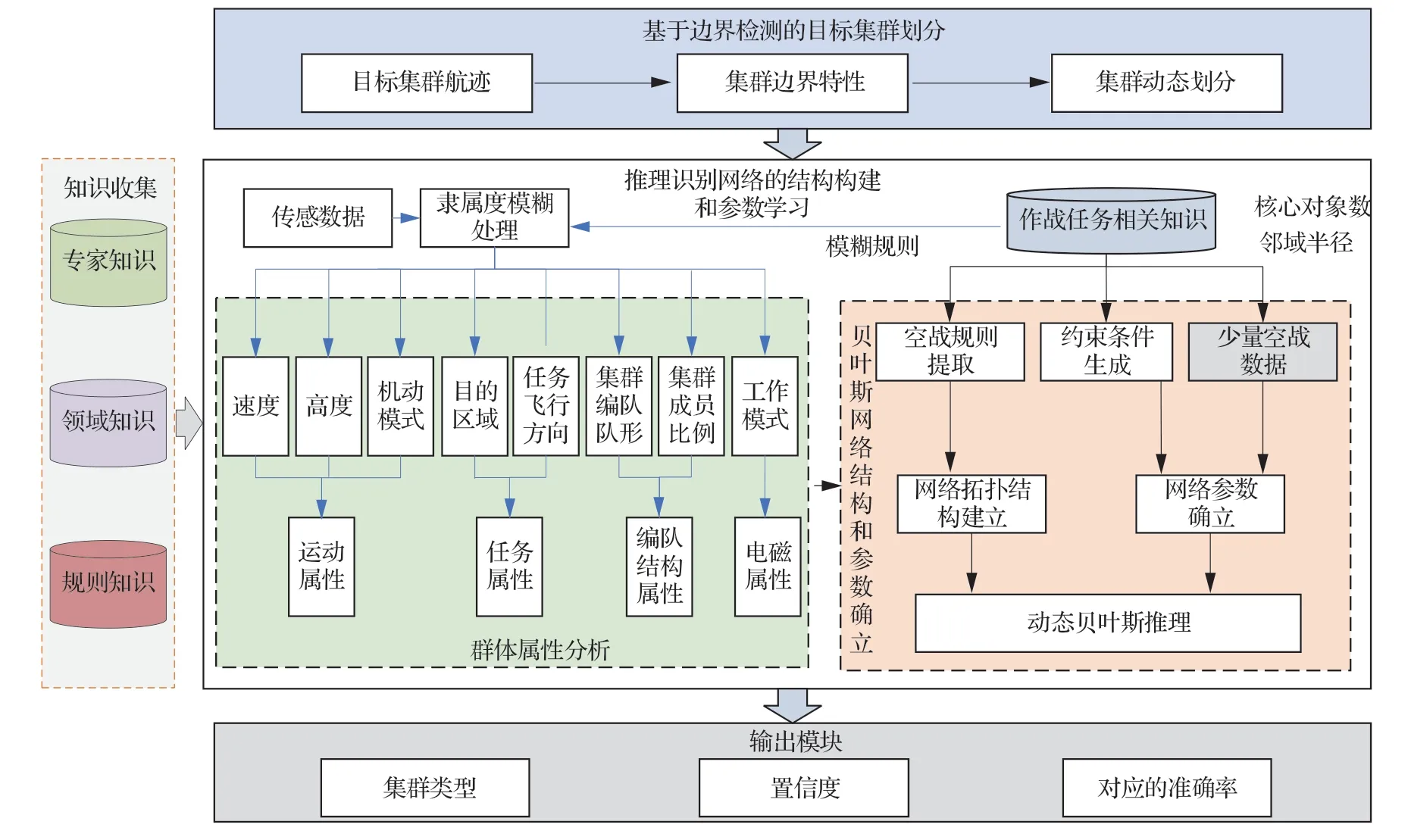
圖3 數據和知識驅動下的目標集群綜合推理識別Fig.3 Comprehensive reasoning and recognition of target clusters driven by data and knowledge
為讓本文所設計框架和算法更加明了,給出算法流程框架圖如圖4 所示。在圖4 中給出算法流程架構圖,為更清晰的了解本文算法,給出本文偽代碼如算法1 所示。
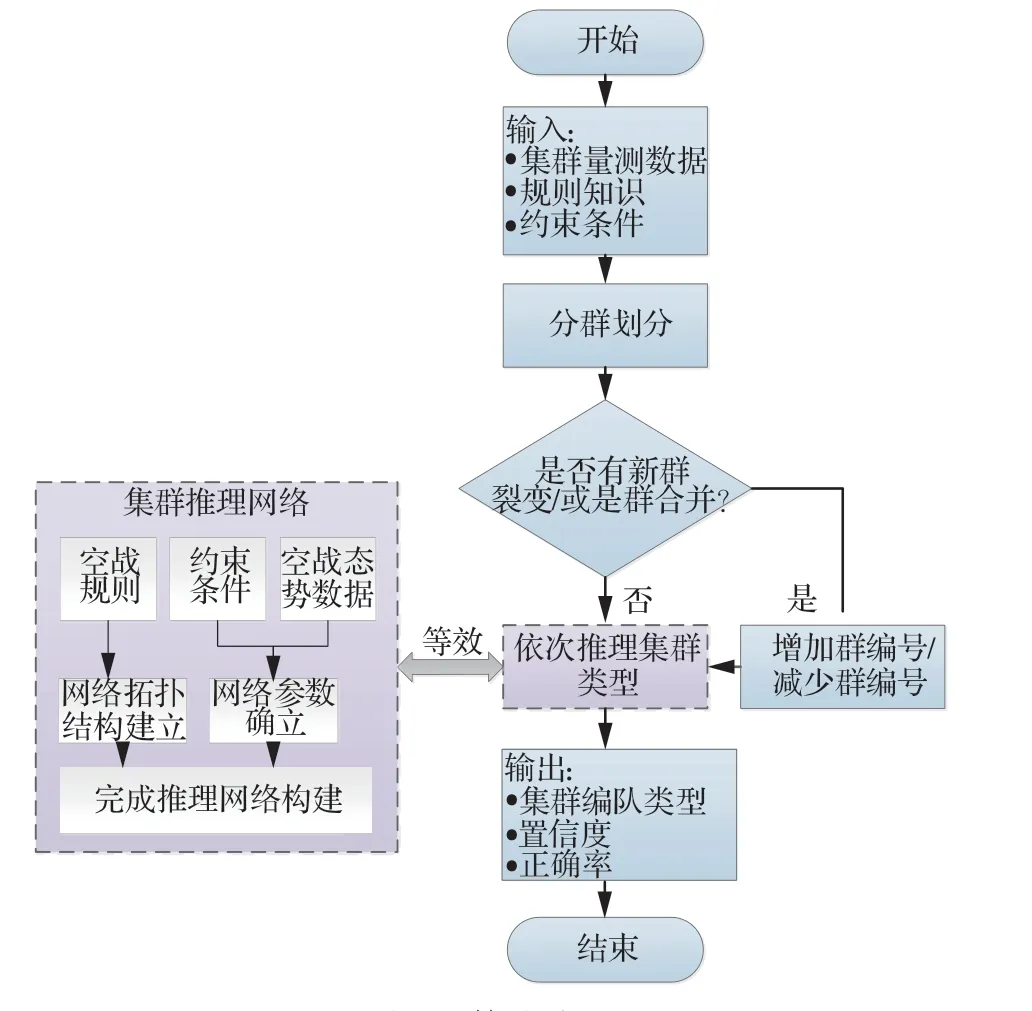
圖4 算法流程Fig.4 Algorithm flow
針對圖3 所示的研究框架圖,研究內容可以分成3 部分:基于邊界檢測的目標集群劃分情況、推理識別網絡中的結構構建和參數學習,具體模塊依次詳細展開如2.1~2.3 節所示。
2.1 基于邊界檢測的目標集群劃分
對于給定的一維數值屬性數據集X=[x1,x2,…,xm]T,不對稱的比例αxc定義為
式中:Small(X,xc) 表示小于xc的元素個數;Large(X,xc) 表示大于xc的元素個數。對于均勻分布的數據集中靠近中心的點,其αxc的值將會很小。式(1)可以通過數據集中元素的不對稱性來判斷矩陣的位置。

算法1 數據和知識驅動的集群類型識別1.輸入:知識收集模塊,提取規則和約束條件,以及實時的傳感數據;2.for 當前時刻所有目標位置量測;3. 檢測目標集群劃分情況:if 出現分群合群順序執行4;else 沒出現分群合群跳轉5;4.增減集群編號情況;5. for 對當前目標集群數量,讀入每個集群其他信源;6. 經推理網絡識別每個目標集群的所屬類型;7. end;8.end;9.輸出:集群類型、置信度及正確率。
對于數據集Xm×n中一個給定的點xc=[xc1,xc2,…,xcn],如果它位于數據集的邊界,則它在數據集中具有很強的不對稱性,否則就是內部核心點。
k最近鄰采樣總是將由k個數據點組成的局部空間提取為動態采樣空間,因此能更好地反映局部空間的分布特征。內點的k最近鄰點在其周圍均勻分布,即內點的k最近鄰點的非對稱性較弱。相反,如果邊界點的k最近鄰點非均勻分布,則邊界點的最近鄰點的非對稱性是較強的。定義非對稱度量AM 如下:
式中:k是Xc m×n中第d列Xd的最近鄰個數,k的值應根據數據集的大小來確定,它主要用于控制最近鄰點的個數來計算非對稱度量。由式(2)可以看出,簇內點的非對稱性較弱,而邊界點的非對稱性較強。AM 的值通常在簇內區域相對較大,而在簇邊界區域相對較小。因此,非對稱度量可以用來檢測邊界點。
本文聚類方法的決策圖包含了每個點的2 個量:局部密度?(xc)和距離δxc。本文算法充分利用局部密度?(xc)和非對稱度量AM2 個指標的互補性,構造了xc的一個新的局部密度,?(xc)和δxc的計算過程。
式中:0 ≤α≤1,0 ≤β≤1;dc為可調參數,dc=v·m,v為唯一的參數,局部密度由dc的高斯核估計,它為集群分配點提供了較為嚴格的標準。xd=[xd1,xd2,…,xdn],d(xc,xd)是xc和xd之間的歐式距離。在本文算法中決策圖的另一個量,距離δxc為
上述過程中關鍵步驟是結合2 個指標計算局部密度,可以更好地識別邊界點,從而使不同集群聚類,最終達到提高聚類效果的目的。本文設計了適用動態復雜戰場的計算方法,如算法2所示。

算法2 基于邊界檢測的集群聚類1.輸入:樣本點Xm×n、距離參數dc 和最近鄰個數k;2.使用歐式距離計算任意2 個樣本點之間的距離;3.根據式(3) 計算點xi 的?(xi)( i=c,d);4.根據式(4) 計算點xi 的δxi;5.繪制決策圖,選擇聚類中心;6.將每個剩余的點分配到最近的具有更高局部密度的點上;7.輸出聚類結果。
面對作戰情況復雜多變的情況,集群的分布往往是不平衡的,該方法能有效解決這類問題。
2.2 推理識別網絡結構模型構建
推理識別網絡結構包括可以觀測到的證據節點和需要推理其后驗概率的隱節點。在基于動態貝葉斯網絡的場景識別過程中,實質上是對目標的集群編隊進行推理。在戰場中集群編隊類型主要通過集群組成、任務特性、運動特性3 方面體現,模型結構中的證據節點主要包括集群編隊類型相關的要素[23]。最后在專家知識、領域知識、作戰規則等多元的可以提供目標集群的運動學特征、結構特征、電磁特性多方面的規則約束和條件約束,在此基礎上依據任務等要求的不同對集群編隊類型要素進行提取,選取最為重要的以及對集群編隊類型影響程度較大的因素[17,22],通常用于集群編隊類型推理的要素主要包括4類。
1) 運動特性
飛機運動模式是什么類型是判斷集群編隊樣式的重要因素。主要影響因素有集群速度、高度、機動模式。根據參考文獻[21],速度通過模糊劃分可以分成小、中、大3 類; 高度也是同樣的處理方式,通過模糊劃分可以分成低、中、高3 類,因為集群類型會對應不同的飛行高度;機動模式是在飛行過程中產生的具有特定模式的狀態[24],包含:盤旋機動、S 形機動、爬升/俯沖機動、無明顯機動幾種典型的機動樣式。
2) 任務特性
飛機集群編隊的執行任務確定,是編隊樣式劃分的另一重要因素。打擊任務為例:候選的打擊點和打擊方向成為關鍵,即任務特性反應在與我方不同目標的接近速率和執行任務飛行方向。因此,任務特性的主要影響因素有集群接近打擊點距離變化率和任務飛行方向。根據參考文獻[21],接近打擊點距離變化率是接近幾個重要價值目標的距離變化率,通過模糊劃分可以分成3 類:靠近、無明顯變化、遠離;任務飛行方向是指接近重要價值目標[24],設定的高價值目標包括:高價值目標、通信目標、無明顯目標。
3) 集群結構特性
由集群編隊內單個飛機的機型識別結果計算出的集群結構,也是推理飛行編隊樣式的重要因素。可通過單架飛機的機型種類置信度算出集群成員機型比例來確立集群結構特性,此外,隊形也是集群結構特性的重要因素,主要考慮集群機型占比和集群編隊隊形2 個影響因素[23]。集群機型占比通過關鍵機型數量的占比可以分成3類:戰斗機、干擾機、預警機。
4) 電磁信號特性
敵方飛行器雷達工作時釋放的電磁信號與自身功能性密切相關,從捕獲的電磁信號可以發現敵方飛行器雷達的工作模式,進而為兵力構成分析提供依據支撐,根據參考文獻[21,25-26],主要考慮因素為工作模式和電磁開關機,同時電磁信號特性可以通過工作波段來進行類型劃分,主要包括:UHF 波段、L 波段、S 波段、X 波段、Ku波段,其代表了所處的工作模式。
由上述分析,不僅可以確定貝葉斯網絡模型的節點,還可以得到初始網絡的構建,在初始網絡中加入時間因素,確定基于動態貝葉斯網絡的集群類型推理模型結構如圖5 所示。
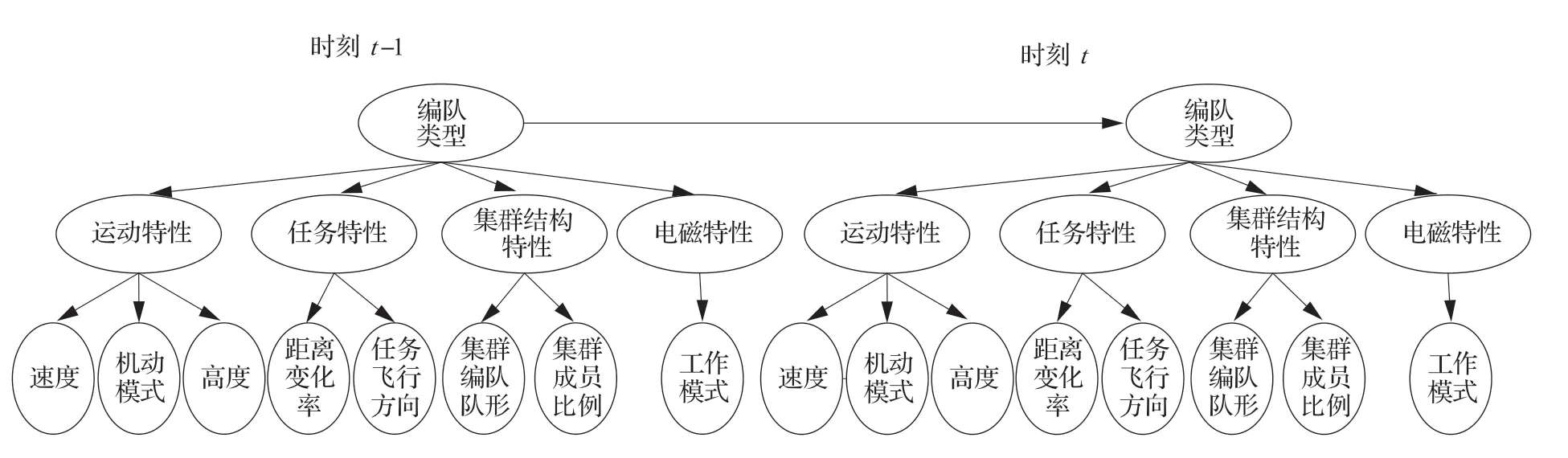
圖5 空戰動態貝葉斯網絡推理模型Fig.5 Dynamic Bayesian network inference model in air combat
圖5 中各節點狀態空間具體如表1 所示。表1中在仿真的標簽為目標速度={1,2,3}={小,中,大};目標高度={1,2,3}={低,中,高};機動模式={1,2,3,4}={盤旋機動,S 形機動,爬升/俯沖機動,無明顯機動};任務飛行方向={1,2,3}={高價值目標,通信目標,無明顯目標};距離變化率={1,2,3}={靠近,無明顯變化,遠離};集群成員比例={1,2,3}={戰斗機,干擾機,預警機};集群隊形={1,2,3}={“8”字型,菱形,一字型};雷達工作模式={1,2,3,4,5}={ UHF 波段,L 波段,S 波段,X 波段,Ku 波段};運動特性={1,2,3}={高空盤旋,低空搜索,定高巡航};任務特性={1,2,3}={指揮控制,快速打擊,釋放干擾};集群結構特性={1,2,3}={預警編隊結構,戰斗編隊結構,干擾編隊結構};電磁特性={1,2,3}={高頻段,低頻段,中頻段};集群編隊類型={1,2,3}={預警編隊,掃蕩編隊,壓制編隊}。

表1 貝葉斯網絡節點狀態空間Table 1 Bayesian network node state space
2.3 基于參數學習的集群編隊類型推理模型
完成聚類分群劃分之后,需要對集群的內部進行精細化分析,設計了基于參數學習的動態推理網絡具體如2.3.1 節所示。
2.3.1 推理網絡的參數學習算法設計
在現有的小數據集下的貝葉斯網絡參數學習方法中,估計方法是學習效果較好的參數學習方法之一,相比文獻[27]的靜態推理,未考慮數據在時間上的相關性,考慮使用具有時序關系的樣本數據,達到對推理網絡的轉移概率的參數學習的目的,即為動態定性最大后驗概率(Dynamic Qualitatively Maximum A Posterior,DQMAP)該方法得到網絡參數后驗概率如下:
式中:θ代表網絡參數;G為網絡結構;ψ為參數約束;C=log10P(D|ψ,G)通過如下形式得到
式中:Nijl表示訓練樣本數據中節點i的父節點處于第j組合狀態條件下節點i取第l狀態的數據統計量;n、q、r均是常數值。
網絡參數先驗分布的定義為
給定ψ和G,這組先驗參θijl定義了一類先驗網絡,如果在一個先驗網絡中采樣A次,即等價樣本量,則樣本中滿足(Xi=l,pa(Xi)=j)的數目等于Mijl=A×P(Xi=l,pa(Xi)=j|ψ),Mijl定義為虛擬樣本量,P(Xi=l,pa(Xi)=j|ψ)滿足全部已知參數約束。通過定性最大后驗概率估計得到參數的具體形式:
式中:W是采樣參數的數量;Pw(Xi=l,pa(Xi)=j|ψ)滿足所有已知參數約束。定性最大后驗概率估計得參數的對數形式:
基于定性先驗知識ψ的先驗網絡集合增加了數據樣本中的統計量,并定義一類后驗概率。通過將樣本統計信息投影到由先驗知識定義的先驗參數空間上,獲得參數的后驗概率集。對上述函數求解得貝葉斯網絡參數的定性最大后驗估計:
對于推理網絡來說,其參數由條件概率和轉移概率組成,在式(10)基礎上考慮使用具有時序關系的樣本數據,實現對動態推理網絡的轉移概率的參數學習。本節設計的推理網絡參數方法,具體如算法3 所示。

算法3 D-QMAP 參數估計1.輸入:M 具有時間關系的序列樣本數據 D={ D1,D2,…,DM},參數約束ψ,網絡結構G,節點集E={ X t1,X t2,…,X tN } (t=1,2 );2.對于t=2 時間片中每個節點X 2i (i=1,2,…,N ), N 為常量;3.計算條件概率:對于M 時間序列樣本數據,統計同一時間片內的節點狀態統計量Nij 和Nijl,父節點屬于當前時間片即pa(X 2i)∈X 2i (i=1,2,…,N );4.判斷此時節點是否與前一時間片里的節點有時間轉移關聯,若沒有,轉至6,若有轉至5;5.計算相應的轉移概率:對所有時間序列樣本數據,統計相鄰時間片間M-1 個節點轉移狀態統計量Nij 和Nijl,父節點屬于前一時間片即pa(X 2i)∈X 1i (i=1,2,…,N );6.通過式(8)滿足參數約束的采樣條件概率和轉移概率分別對其平均后得到滿足推理網絡參數約束的整體參數P(Xi=l,pa(Xi)=j|ψ);7.通過交叉驗證方法劃分樣本數量A;8.利用式(10)得到條件概率和轉移概率對應的估計值;9.輸出:最優推理網絡參數θ*。
上述方法達到了場景樣本數據小的情況下,也能滿足多元知識的推理網絡參數學習的目的。
2.3.2 參數學習
本節利用D-QMAP 方法為2.3.1 節提出的推理網絡參數進行學習。首先需要獲取訓練樣本以及專家經驗提供的參數約束信息。對于訓練樣本方面,根據不同類型目標在不同集群類型下執行作戰任務時的運動狀態,從而得到目標高度、速度、距離、執行任務飛行方向、機動類型等信息,再綜合不同任務想定下雷達狀態等其他要素信息,將其進行預處理后共同作為參數學習的數據樣本。表2 給出了3 種典型的編隊樣式的特性,隨機包含10 個時刻的訓練數據具體樣式如表3 所示。

表2 集群編隊類型特征Table 2 Characteristics of cluster formation
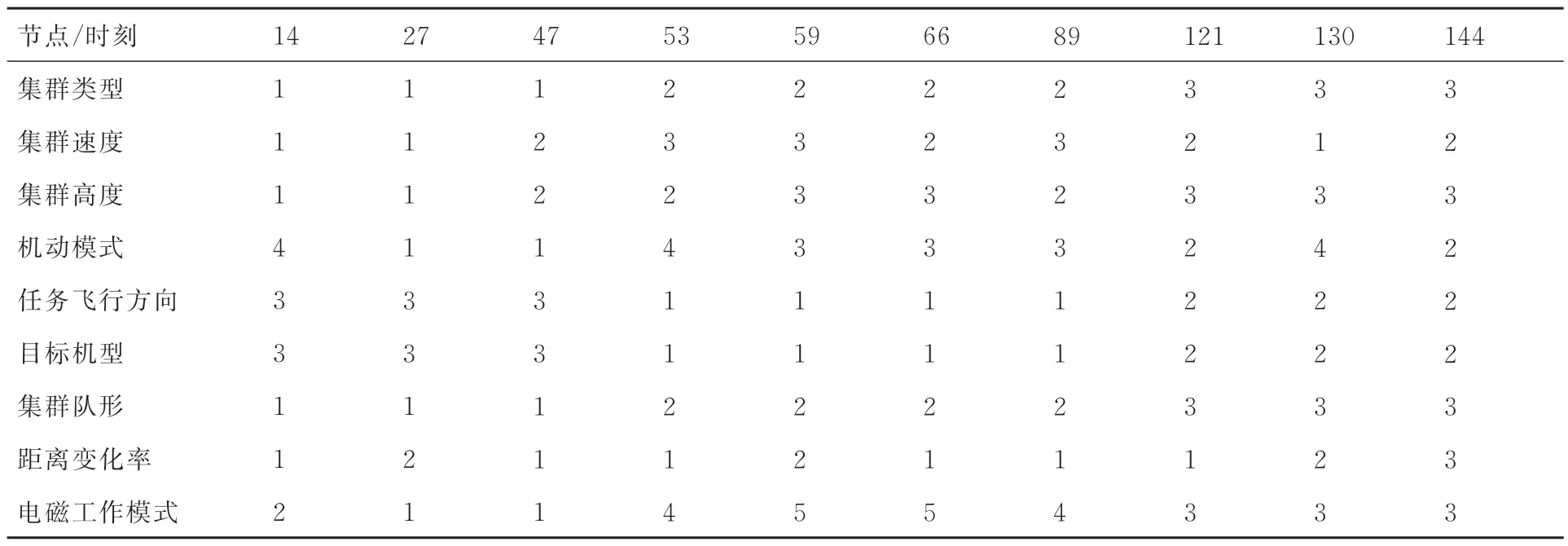
表3 訓練數據具體樣式Table 3 Specific style of training data
一條包含10 個時刻的訓練數據總共生成每條10 個時刻的時序樣本共100 條。數據樣本來源于研究所給定數據特性,考慮到數據有一些偏離點或是異常值,還需要加入專家經驗作為參數約束條件對模型參數進行學習,以彌補訓練數據的不足。在參數約束方面,主要采集5 種類型的專家經驗作為參數約束條件,主要包括:規范約束、先驗約束、區間約束、同分布參數約束、0 概率參數約束。依據這5 類約束得到了的參數約束信息,以及時間序列訓練樣本。對圖5 所示的集群編隊類型的推理模型進行參數學習。
本節考慮由于模型參數較多,這里僅展示部分主要參數學習結果,分別為推理模型的集群速度條件概率表、集群高度條件概率表、集群距離變化率條件概率表等,具體如表4~表7 所示。
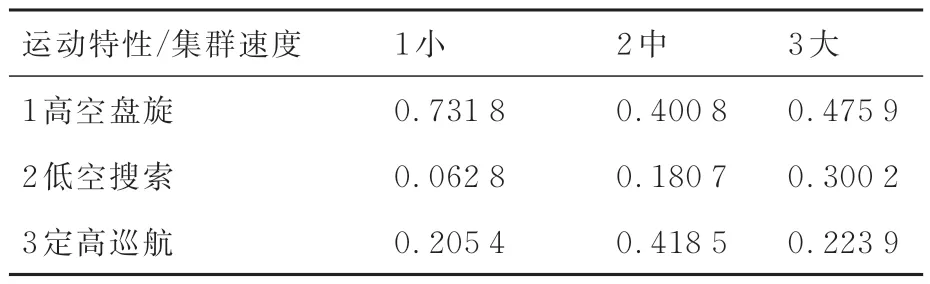
表4 集群速度條件概率Table 4 Conditional probability of cluster velocity
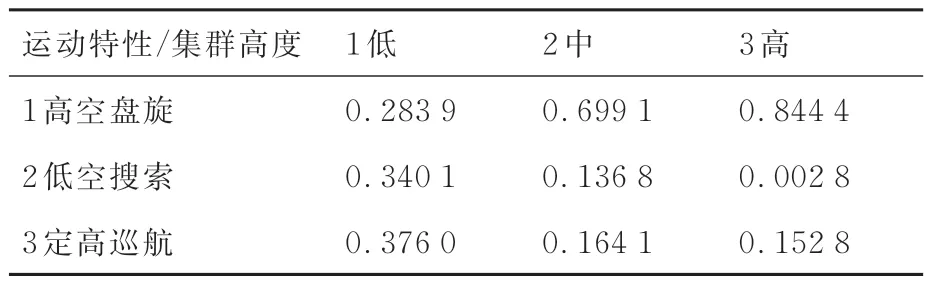
表5 集群高度條件概率Table 5 Conditional probability of cluster height
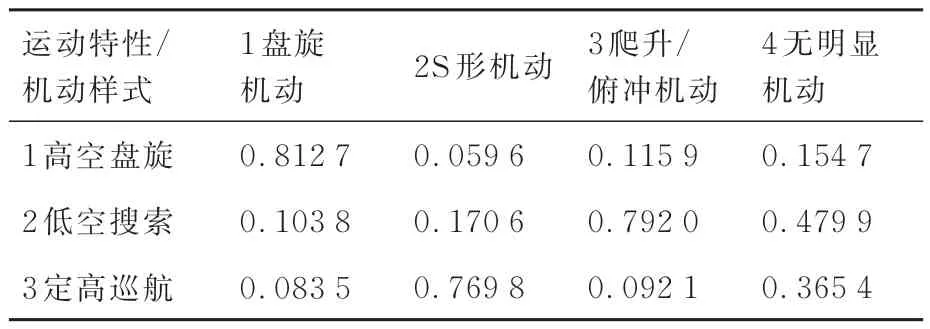
表6 機動樣式條件概率Table 6 Conditional probability of maneuver
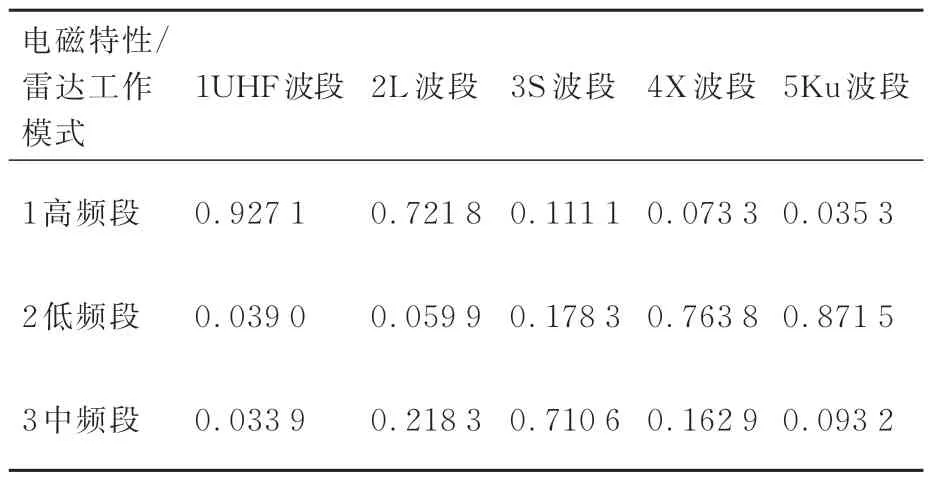
表7 雷達工作模式條件概率Table 7 Conditional probability of radar mode
上述條件轉移概率表是通過本文參數學習方法所得,本文完成參數的學習,得到了完整的動態貝葉斯網絡推理網絡,為驗證所提框架和方法的有效性,下節給出相應的仿真驗證。
3 仿真驗證
為了驗證算法性能,本文在典型場景下通過推理置信度和正確率兩項指標進行說明,驗證了所提框架和算法的有效性。
3.1 場景設置
本文仿真的場景依據研究所提供的數據特性和場景要求進行測試,集群編隊包括了預警編隊、壓制編隊、掃蕩編隊等典型的編隊類型,且符合集群目標的實際運動特點,場景描述如圖6所示。
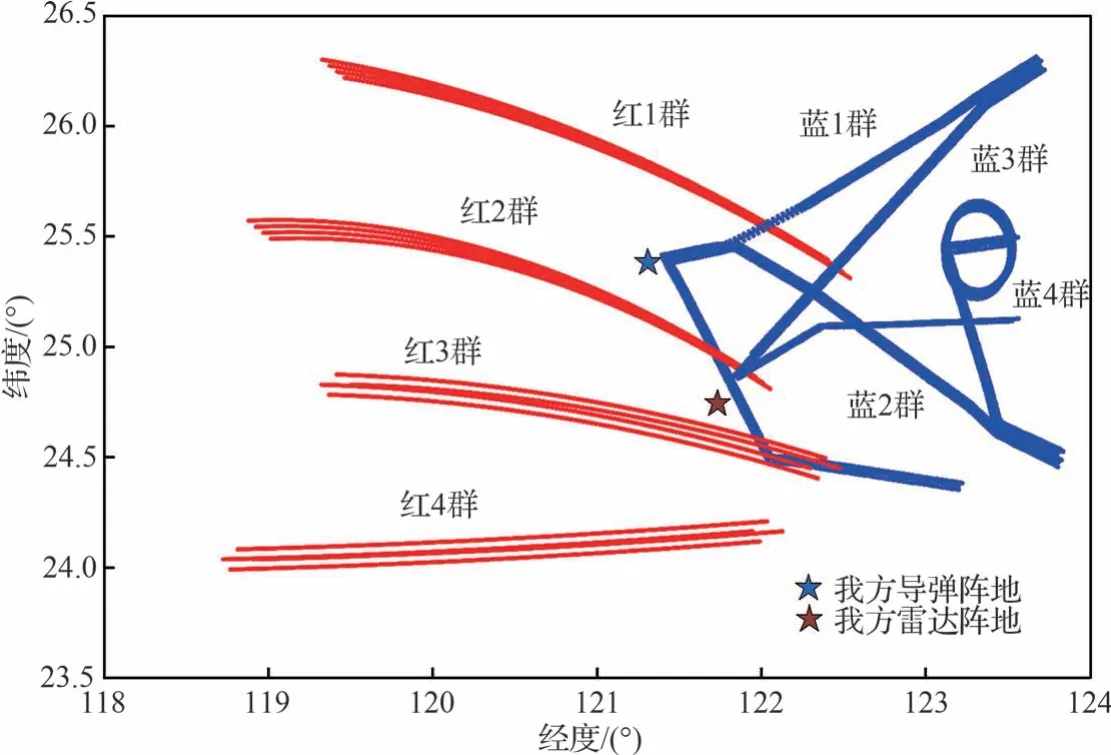
圖6 任務場景下的敵我雙方飛行軌跡Fig.6 Block diagram of target flight track segmentation algorithm based on two-layer segmentation
紅方為我方,藍方為敵方目標,目標主要意圖是攻擊中國導彈陣地和雷達陣地,目標最后分成了2 個掃蕩集群,一個壓制集群,一個預警集群。紅方出動4 個戰斗集群,并在圖示區域實施攔截。由于紅方4 個集群快速出擊迎敵并擊落2 架敵機,藍方認為第一任務無法順利完成,在執行任務一的過程中,預警機編隊的預警機表現出一定區域盤旋機動,第一任務失敗后,進而實施第二任務攻擊紅方某秘密基地(上圖紅色五角星),集群3 在靠近過程中釋放干擾信號。藍方戰機在攻擊紅方地面目標過程中,被紅方地對空導彈擊落一架飛機。任務結束后,藍方掉頭撤退。
同時給出本文所設計聚類方法的關鍵參數:α=0.5,β=0.2,k=2,dc=4。
3.2 性能評估
本文實驗是在一臺聯想PC 機上完成,采用64 位Windows 10 操作系統。參考文獻[28],主要以推理的置信度為主要指標進行對比,來說明本文所提算法的有效性。若有C個真實情況,無誤推理次數為B次,則推理精確度為
提升程度定義為
下面給出隨機參數推理算法定義[29]:不完美先驗信息即先驗信息不充分、不準確甚至無先驗信息的情況,部分參數隨機給定;經驗參數定義[27,30-31]:依據先驗信息對貝葉斯網絡參數調整和指定。隨機參數下推理結果如圖7~圖10 所示。
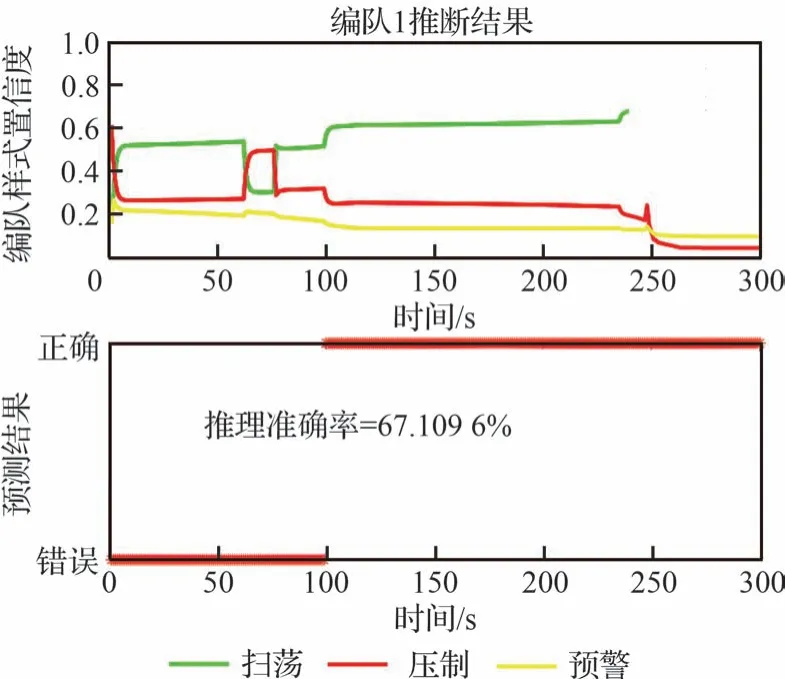
圖7 隨機參數下編隊1 的推理情況Fig.7 Inference of Formation 1 with random parameters
由圖7 和圖8 可知,集群編隊1 從原始位置起飛開始,考慮集群組成占比,整體集群傾向于干擾機編隊,但是集群飛行目的地不明確,且推理網絡參數為隨機參數,總體來說此時模式不可分。第60 s 開始編隊1 開始分群,分為集群編隊1和集群編隊3,在分群期間集群編隊1 依然被識別是干擾機編隊,而集群編隊3 明顯飛向我方高價值的雷達陣地,接近趨勢愈加明顯,在隨機參數推理的前提下,推理結果為壓制編隊的置信度增大。第78 s 分群完成,集群編隊1 的運動模式特征明顯、飛行目的地逐漸明確,掃蕩編隊的置信度急劇增大,也是從此時開始,推理正確,但是整體推理準確率偏低。
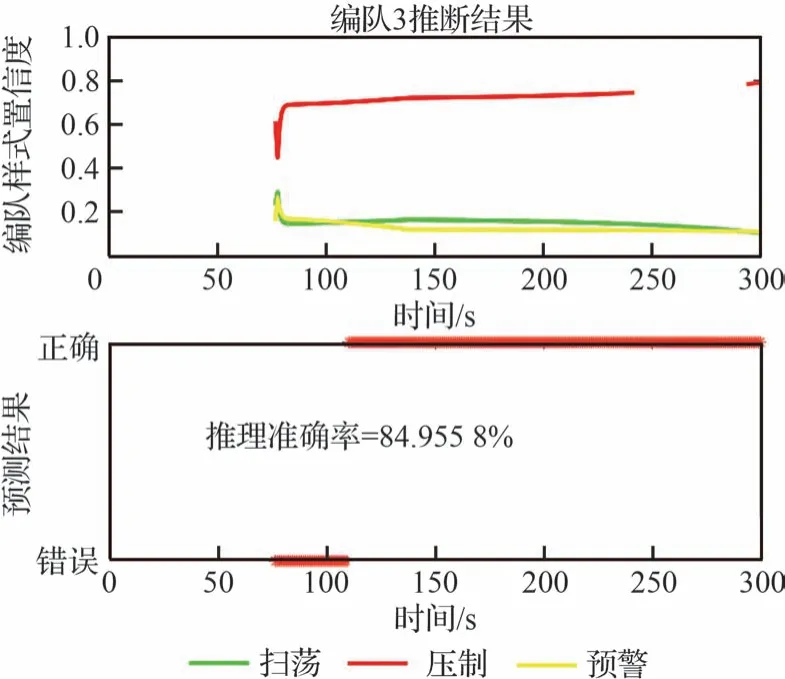
圖8 隨機參數下編隊3 的推理情況Fig.8 Inference of Formation 3 with random parameters
編隊2 起初由6 架戰斗機2 架預警機組成,此時集群整體傾向識別為預警機編隊,但是由于飛行目的地明確為我方重要陣地,且飛行速度快,運動屬性表現為掃蕩編隊特性,但是由于網絡參數并未反映出模型實際情況,整體集群模式不可分。直到分群結束,集群編隊表現出俯沖和加速的機動模式,飛行目的地明確,特征綜合分析之后,編隊更符合掃蕩編隊特性,結果對應圖9。
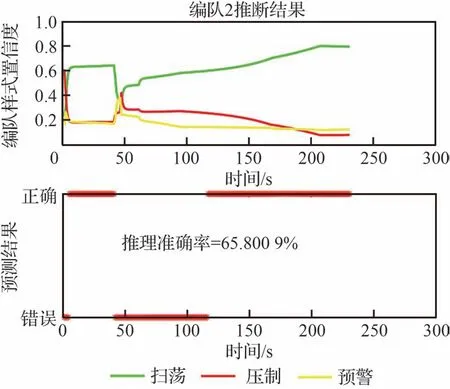
圖9 隨機參數下編隊2 的推理情況Fig.9 Inference of Formation 2 with random parameters
集群編隊4 由集群編隊2 在第48 s 完全分離,從不同特性分析,集群編隊表現出飛行高度大,速度慢,加之任務特性和機動模式表現出預警編隊特有的機動形式,此時推理為預警編隊,結果對應圖10。
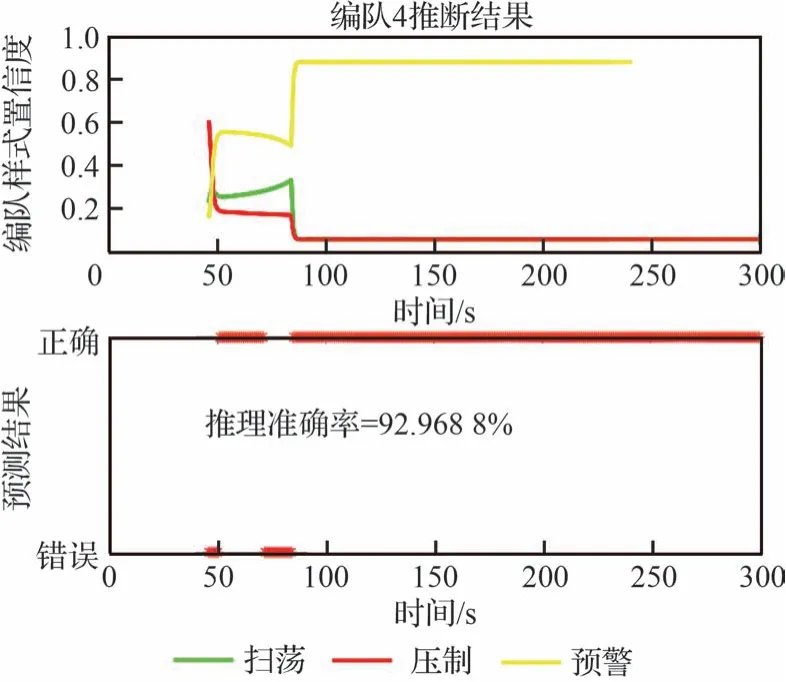
圖10 隨機參數下編隊4 的推理情況Fig.10 Inference of Formation 4 with random parameters
此外,本文又與經驗參數推理方法進行了對比,節點參數估計相比隨機參數方法較準確,因此經驗參數的推理結果優于隨機參數的集群推理,推理的準確率平均提升了10%以上。為進一步說明方法的有效性,與文獻[21]采用的多實體分層模型推理方法進行對比,仿真結果如圖11~圖14 所示。
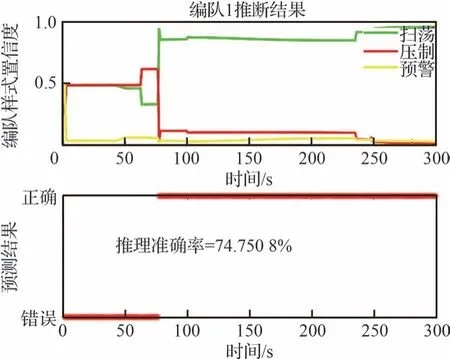
圖11 多實體分層模型推理下編隊1 的情況Fig.11 Formation 1 with multi-entity hierarchical inference
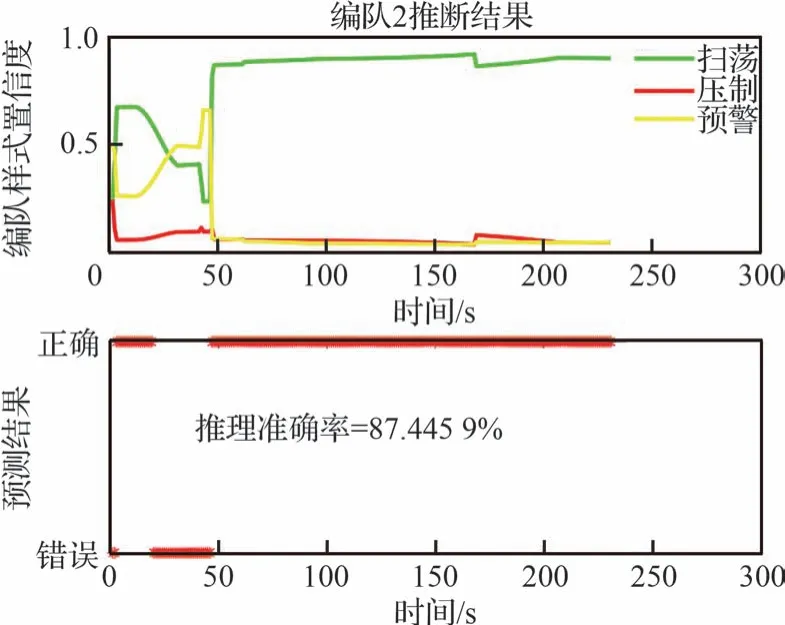
圖12 多實體分層模型推理下編隊2 的情況Fig.12 Formation 2 with multi-entity hierarchical inference
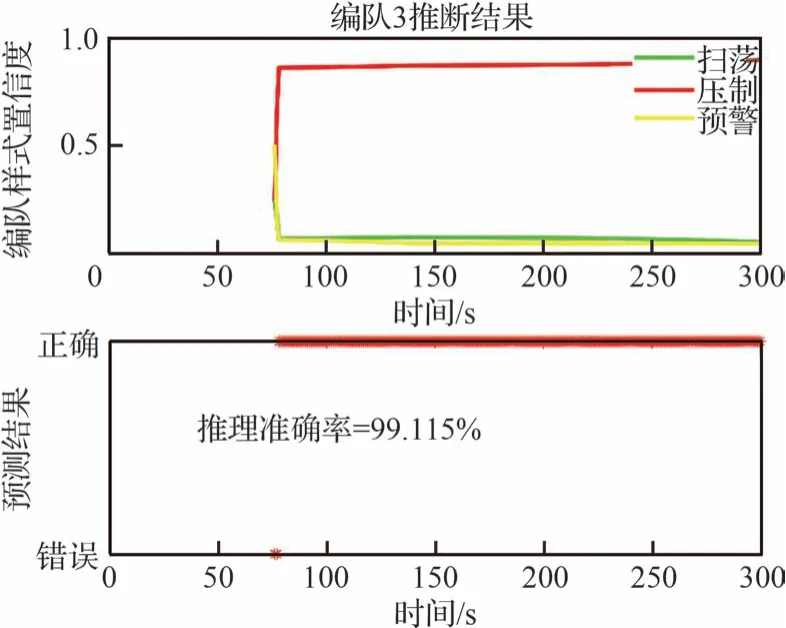
圖13 多實體分層模型推理下編隊3 的情況Fig.13 Formation 3 with multi-entity hierarchical inference
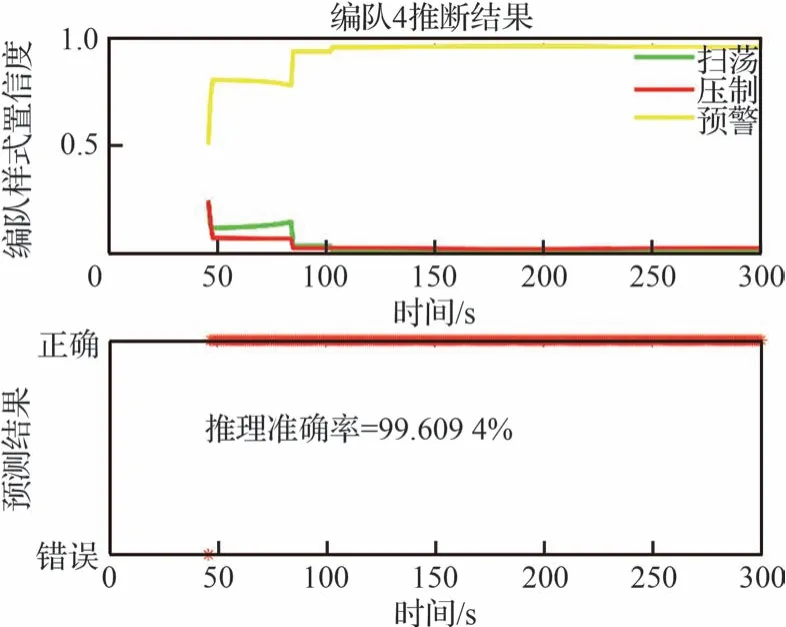
圖14 多實體分層模型推理下編隊4 的情況Fig.14 Formation 4 with multi-entity hierarchical inference
根據圖11~圖14 的仿真結果分析可知,文獻[21]中設計的集群類型推理結果優于隨機參數的集群推理,推理網絡的參數是依據經驗約束,模型參數更加準確,且從集群編隊1~編隊4的仿真圖結果,推理準確率平均提升了6%以上。
根據圖15~圖16 分析可知,編隊1 未出現分群動作之前,所提算法的推理結果高于其他幾種算法。即使出現集群裂變/分群現象,本文所提算法推理結果的置信度依舊優于其他方法。
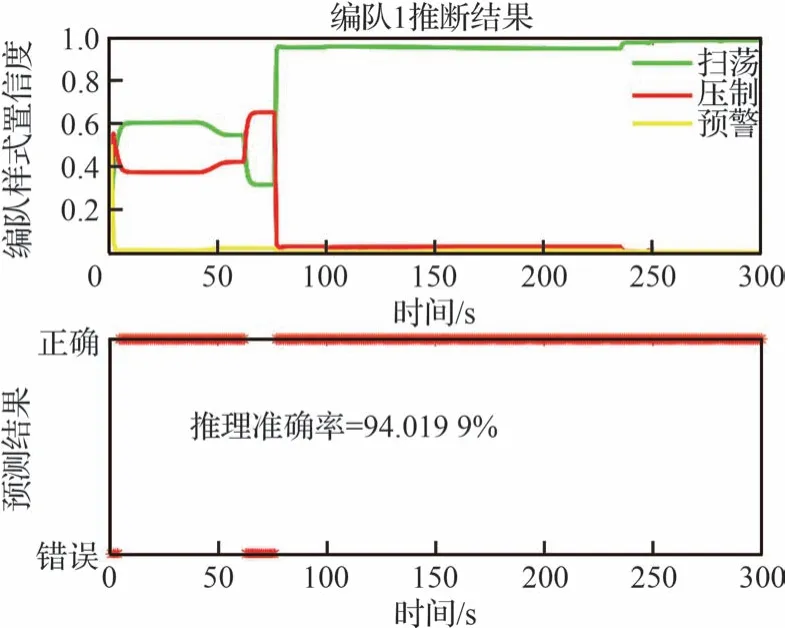
圖15 參數學習下編隊1 的推理情況Fig.15 Inference of Formation 1 with empirical parameters
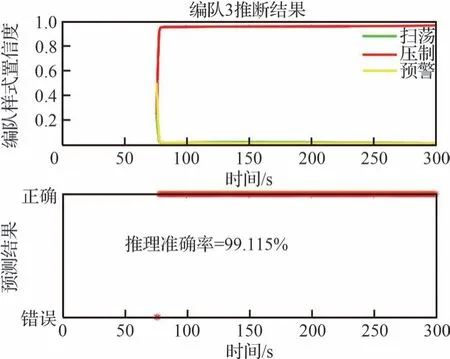
圖16 參數學習下編隊3 的推理情況Fig.16 Inference of Formation 3 with learning of inference network parameters
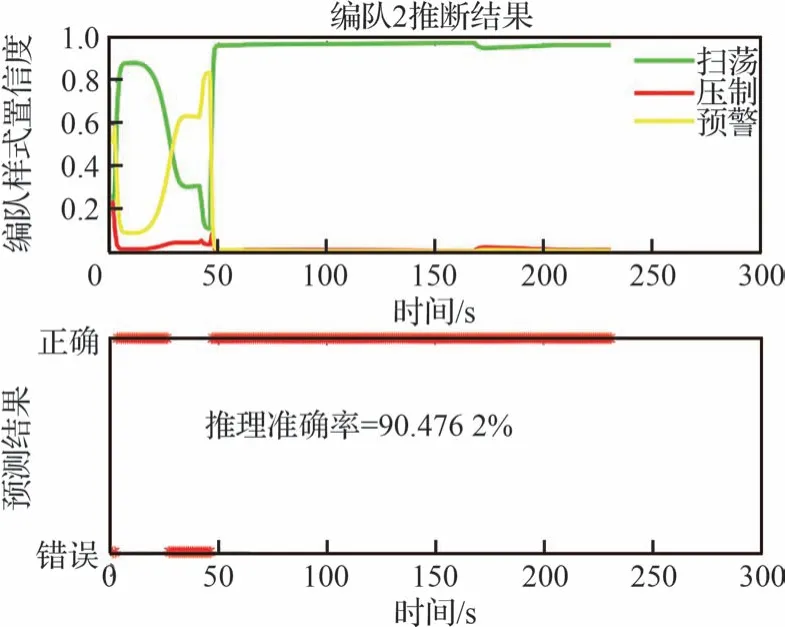
圖17 參數學習下編隊2 的推理情況Fig.17 Inference of Formation 2 with learning of inference network parameters
根據圖15~圖18 的結果分析可知,作戰想定下的集群類型判斷過程中,從集群編隊整體飛行到執行不同任務出現分群,本文所提算法在經驗參數方法和現有數據基礎上,融合約束知識、模型知識等修正了專家經驗知識下推理網絡的參數,使集群平均識別準確占比為90%以上,置信度均高于95%。隨著目標逐漸靠近,集群目標任務性明確。
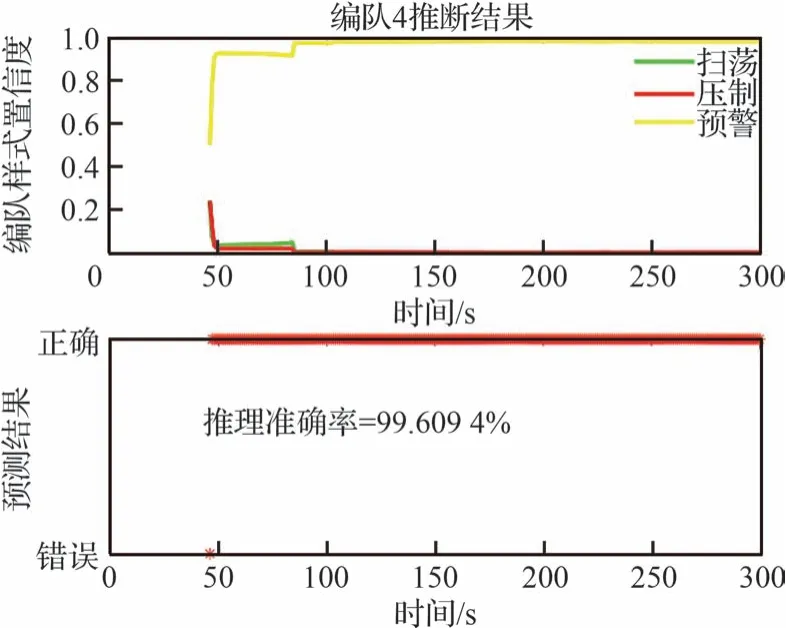
圖18 參數學習下編隊4 的推理情況Fig.18 Inference of formation 4 with learning of inference network parameters
此外,為有效說明目標集群涉及分析因素(速度、高度等)數據來源的有效性,圖19 和圖20展示標集群1 和集群2 的軌跡變化及估計值。根據圖19 和圖20 的目標集群的跟蹤軌跡,本文獲得的估計值較為準確,因此獲得目標集群量測信息可以作為目標集群速度、任務方向等因素提取值的基礎。綜合上述,本文推理網絡參數學習過后的推理識別結果又進一步得到了提高,針對上述仿真結果,將性能匯總如表8[21,29,31]所示。
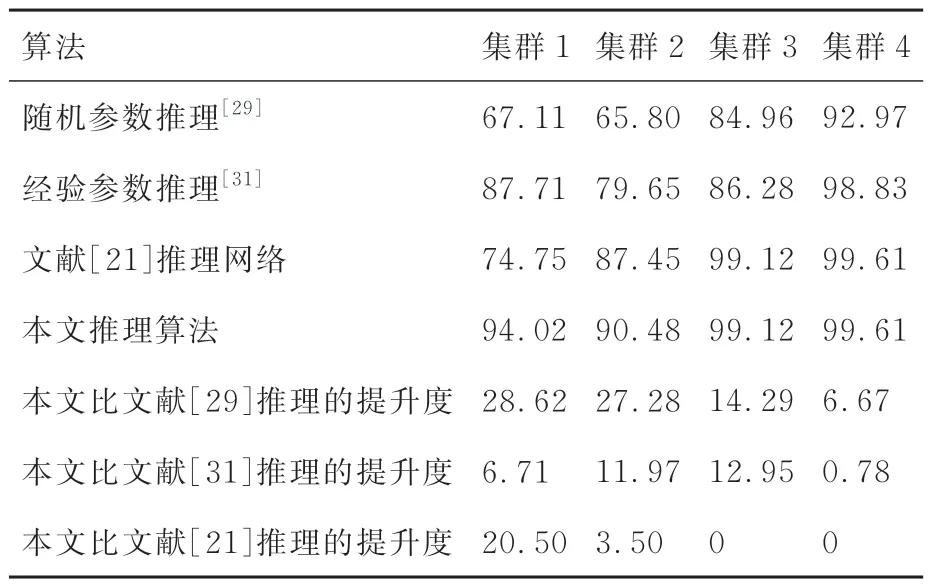
表8 算法性能比較Table 8 Performance comparison of algorithms %
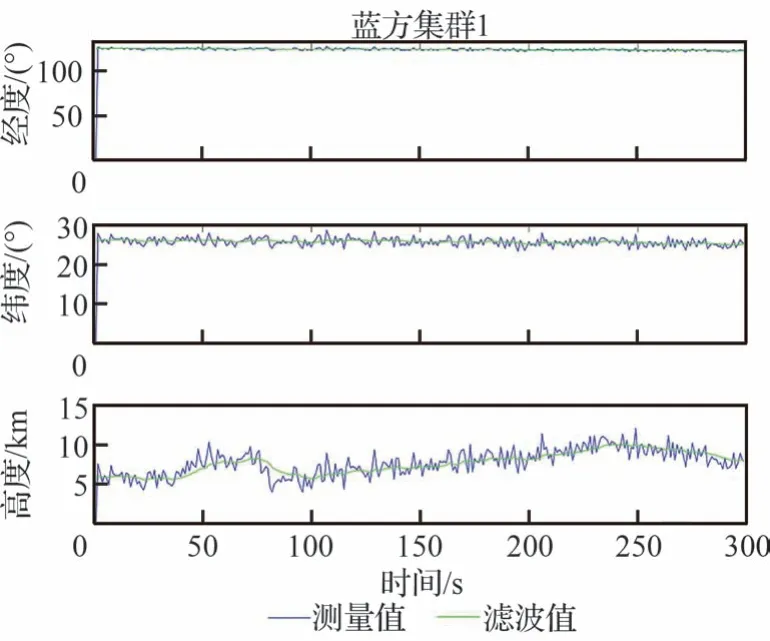
圖19 目標集群1 的跟蹤軌線Fig.19 Tracking trajectory of target cluster 1
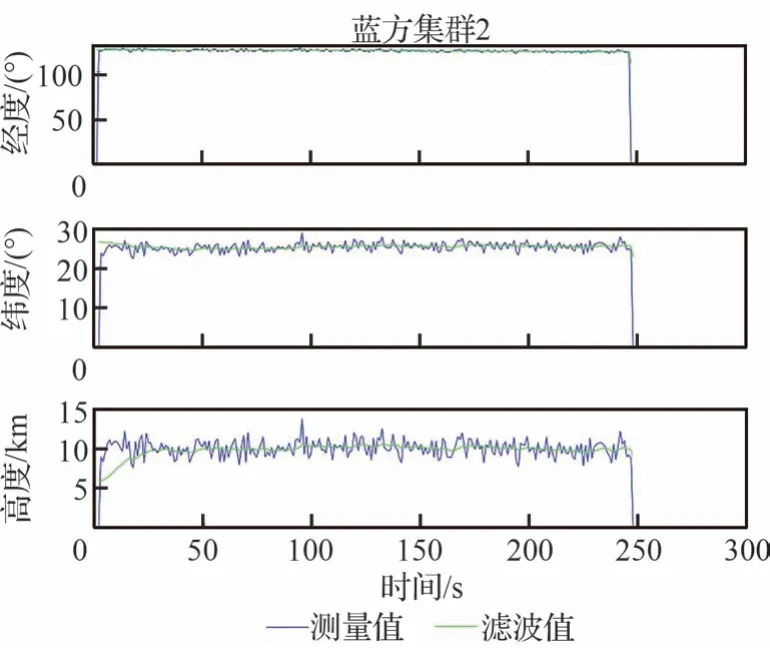
圖20 目標集群2 的跟蹤軌線Fig.20 Tracking trajectory of target cluster 2
對比隨機參數、經驗參數算法,本文方法推理準確率平均提高8%,相比文獻[21]推理的結果,因為考慮了數據之間時間的相關性,集群推理準確率平均提高6%。本文所提方法得到的推理結果置信度也更高,且置信度至少提高4%。
4 結 論
本文重點研究了如何利用數據和知識進行目標集群推理問題,對集群編隊作戰中多種特性進行了分析,構建了分層精細化推理的集群場景識別框架。首先,預識別層檢測目標運動過程中的集群的分群/合群;然后,利用知識和數據互補性,在再識別層利用所設計的動態推理網絡參數學習方法,得到所需的推理網絡。本文有效利用了多特征綜合推理機制對目標集群進行推理分析,實現了對于集群的精細化識別,提高了集群類型識別的置信度和準確度。最后,通過典型仿真場景測試驗證了所提方法的有效性。集群類型的識別是態勢評估的重要因素,在未來工作中考慮在獲得集群類型的基礎上如何綜合分析更多因素評估出整體集群作戰態勢變化。
