基于信息檢索與 K 均值聚類的化工產(chǎn)品精準推薦算法研究
2023-07-04 07:06:21高云梅張淑慧
粘接 2023年3期
關(guān)鍵詞:信息檢索
高云梅 張淑慧


摘要:傳統(tǒng)K均值聚類對客戶聚類精度不高,直接影響化工產(chǎn)品精準推薦的質(zhì)量。基于此,采用信息檢索系統(tǒng)來確定K 均值聚類的初始聚類中心點,消除特殊消費者與數(shù)據(jù)中的噪聲數(shù)據(jù),提出了聯(lián)合信息檢索與K 均值聚類的化工產(chǎn)品精準推薦算法。將該算法和Top-N 算法分別應(yīng)用于化工產(chǎn)品精準營銷中,結(jié)果表明,提出的算法比Top-N 算法平均絕對誤差低,準確率、召回率以及綜合平均值高,能夠為化工企業(yè)實施精準營銷提供數(shù)據(jù)參考。
關(guān)鍵詞:信息檢索;K均值聚類;化工產(chǎn)品;精準營銷;相似度
中圖分類號:O213??????? 文獻標志碼:A????? 文章編號:1001-5922(2023)03-0132-04
Research on precision marketing strategy of chemical products based on information retrieval andK-means clustering
GAO Yunmei1,ZHANG Shuhui2,3
(1. Yantai Vocational College,Yantai 264670,China;2. Shanghai Lixin Institute of Accounting and Finance,Shanghai 201620,China;3. Southwest University,Chongqing 400715,China)
Abstract:Traditional K-means clustering has low clustering accuracy for customers,which directly affects thequal? ity of accurate recommendation of chemical products. Based on this,an information retrieval system is used to deter? mine the initial clustering center point of K-means clustering and eliminate the noise data in special consumers and data,and a precise recommendation algorithm of chemical products based on joint information retrieval and K-means clustering is proposed. The algorithm and the top-N algorithm are applied to the precision marketing of chemical products respectively. The results show that the proposed algorithm has lower average absolute error than the top-N algorithm,and higher accuracy,recall and comprehensive average. It can provide data reference for chem? ical enterprises to implement precision marketing.
Keywords:information retrieval;K-means clustering;chemical products;precision marketing;similarity
近年來,伴隨著國家產(chǎn)能機制的健全以及環(huán)境保護政策的有效落實,一些產(chǎn)能落后、污染嚴重的化工企業(yè)被淘汰。面對環(huán)境與技術(shù)的雙重壁壘,化工企業(yè)要想在激烈的市場競爭中占據(jù)一席之地,就必須實施精準營銷,通過精準定位客戶,從而不斷地提升自身的競爭實力。市場經(jīng)濟環(huán)境下,精準營銷受到了學(xué)術(shù)界的廣泛關(guān)注。研究對商品精準營銷中聚類分析和關(guān)聯(lián)規(guī)則分析的應(yīng)用進行研究,指出通過聚類分析和關(guān)聯(lián)規(guī)則技術(shù)的運用能夠挖掘海量數(shù)據(jù)中隱藏的有用信息,更加精準地了解客戶的需求,從而結(jié)合客戶的需求來開展營銷,提升客戶對產(chǎn)品的忠誠度與依賴度[1]。通過研究指出企業(yè)實施精準營銷能夠有效降低營銷成本,提高營銷效率與市場競爭力,同時對關(guān)聯(lián)規(guī)則、聚類技術(shù)、分類分析、估值與預(yù)測等數(shù)據(jù)挖掘技術(shù)在企業(yè)精準營銷中的應(yīng)用方法進行了分析[2]。對社會化商務(wù)中消費者感知推薦信任的聚類方法進行研究,將推薦信息轉(zhuǎn)化為感知推薦信任,從社交網(wǎng)絡(luò)中抽取感知推薦信任相似度和關(guān)系親密度網(wǎng)絡(luò),并采用譜平分的方法來進行聚類,從而為營銷平臺制定精準化營銷策略提供參考[3]。對化工產(chǎn)品市場營銷組合策略進行研究,將化工產(chǎn)品和日用百貨進行類比,剖析了營銷過程中的洽談技巧、客情關(guān)系,為化工產(chǎn)品的營銷提供了借鑒[4]。從目前來看,學(xué)術(shù)界對化工產(chǎn)品精準營銷的研究比較少且主要是定性的分析,缺乏定量化的研究。基于此,構(gòu)建信息檢索與K 均值聚類的化工產(chǎn)品客戶識別算法,通過精準定位客戶來高效開展化工產(chǎn)品的精準化營銷。
1 信息檢索系統(tǒng)
1.1? 營銷數(shù)據(jù)處理
影響消費者消費行為的因素是多方面的,如消費者的文化程度、可支配收入、工作環(huán)境等,不同消費者的行為具有一定的差異性,通過消費者信息的數(shù)據(jù)處理來獲得營銷數(shù)據(jù)檢索結(jié)果。對消費者營銷數(shù)據(jù)處理的流程如圖1所示。
1.2 信息檢索模型
信息檢索系統(tǒng)是開展化工產(chǎn)品精準營銷的關(guān)鍵,通過信息檢索系統(tǒng)來精準、全方位把握客戶需求,從而結(jié)合客戶的需求來開展更具針對性的營銷活動。由化工產(chǎn)品客戶對產(chǎn)品進行評分,將評分結(jié)果寫成矩陣的形式作為信息檢索模型的輸入。客戶與產(chǎn)品之間的關(guān)系反映了客戶對化工產(chǎn)品的需求,對于具有同樣功能的化工產(chǎn)品,客戶的選擇也是多樣化的。當客戶和多個化工產(chǎn)品產(chǎn)生關(guān)聯(lián)時就會產(chǎn)生一個多元化的網(wǎng)絡(luò)模型。
在信息檢索模型中,每一個節(jié)點的添加或刪除都會對整個的模型產(chǎn)生影響,其具體包括3個方面的內(nèi)容:首先是延伸,即每增加1個新節(jié)點,那么其均會和原有網(wǎng)絡(luò)中的 m 個節(jié)點構(gòu)建連接關(guān)系;其次是局域范圍的界定,在網(wǎng)絡(luò)的所有節(jié)點中隨機選擇 n 個節(jié)點,那么界定 LW 為與隨機選擇 n 個節(jié)點所在的范圍;最后為考慮連接的優(yōu)化,設(shè) p為新增節(jié)點與范圍內(nèi)節(jié)點連接概率,1-p 為新增節(jié)點與范圍外節(jié)點連接概率,得到節(jié)點連接之間概率關(guān)系為[5]:
式中:ki 為節(jié)點度。
基于局域范圍的優(yōu)先連接概率為:
式中:m0為初始網(wǎng)絡(luò)中節(jié)點數(shù)量;t 為時間間隔;rij為節(jié)點i與節(jié)點8(j),公式:
式中:d 為消費者 i 、j 的共有鄰域;R(-)i 和 R(-)j 分別為消費者 i 、j 的平均評分;Ri.d 和 Rj.d 分別為用戶 d 對 i 和 j 的評分。
局域范圍外的隨機連接概率為:
2 信息檢索與 K 均值聚類的精準營銷模型
K 均值聚類是最常使用的無監(jiān)督學(xué)習(xí)算法,通過 K 均值聚類來將具有同樣需求的客戶聚集在一起,劃分為多個種類,從而對具有不同種類的消費者開展精準化營銷。不妨設(shè) U 為包含 n 個消費者節(jié)點的集合,那么任意2個節(jié)點i和j之間的相似度sim(i .j)為[6]:
式中:Ii為消費者i評價的產(chǎn)品集合;Ij為消費者j 評價的產(chǎn)品集合;Ri.j為同時被消費者i、j評價的產(chǎn)品集合。
根據(jù)相似度定義消費者i的節(jié)點加權(quán)度 Di 和加權(quán)聚集度 Ki ,即[7]:
式中:ui、uj、uk分別為用戶i、j 、k 節(jié)點;E 為信息檢索系統(tǒng)網(wǎng)絡(luò)邊集合;y 為一組節(jié)點對所構(gòu)成的集合。
考慮到特殊消費者以及營銷數(shù)據(jù)中的噪聲數(shù)據(jù)對K 均值聚類效果所產(chǎn)生的干擾,常常是選擇信息檢索系統(tǒng)網(wǎng)絡(luò)中節(jié)點綜合特征值作為聚類的初始中心,節(jié)點綜合特征值(CFVi)為:
K 均值算法無監(jiān)督,通過反復(fù)迭代求解,具有易實現(xiàn)、易操作、聚類效果良好的優(yōu)點,通過聚類分析結(jié)果將具有同樣消費愛好的消費者聚集為一類,從而使得企業(yè)更高質(zhì)量地開展精準營銷。假設(shè)將原始數(shù)據(jù)簇劃分為(C1. C2.…. Ck ),K 均值聚類的目標是使得平方誤差 E 最小,即:
式中:ui 為簇 Ci 的均值向量,計算式為:
K 均值聚類算法是將原始數(shù)據(jù)中隨機選擇 k 個作為初始聚類中心,根據(jù)相似度計算公式計算其余數(shù)據(jù)與聚類中心的相似度大小,并對數(shù)據(jù)進行聚類劃分。更新聚類中心,再次對數(shù)據(jù)進行聚類劃分。通過反復(fù)迭代來更換數(shù)據(jù)的聚類中心,使得平方誤差(E)最小,算法的流程如圖2所示[8]。
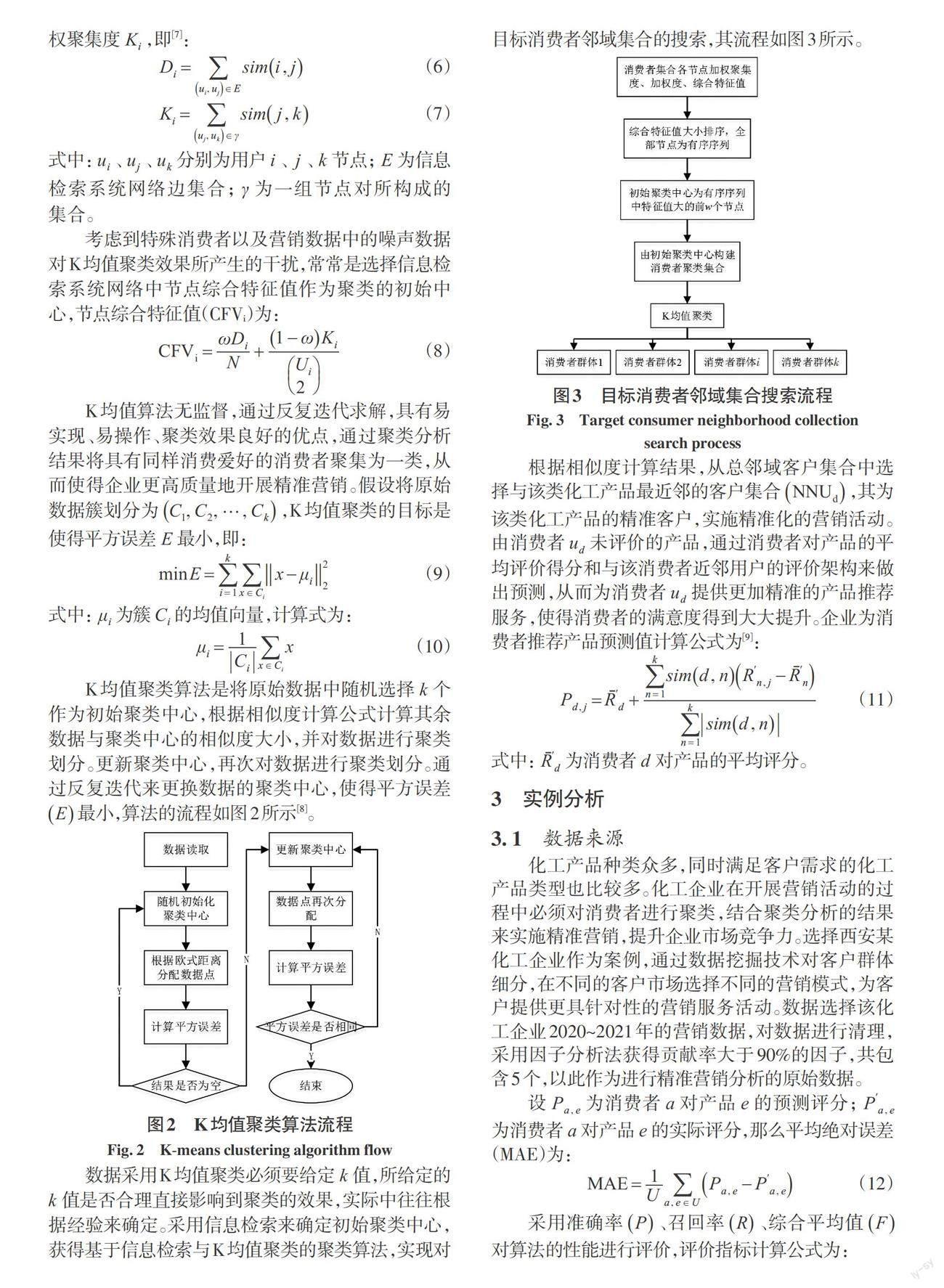
數(shù)據(jù)采用K均值聚類必須要給定 k 值,所給定的 k 值是否合理直接影響到聚類的效果,實際中往往根據(jù)經(jīng)驗來確定。采用信息檢索來確定初始聚類中心,獲得基于信息檢索與K 均值聚類的聚類算法,實現(xiàn)對目標消費者鄰域集合的搜索,其流程如圖3所示。
根據(jù)相似度計算結(jié)果,從總鄰域客戶集合中選擇與該類化工產(chǎn)品最近鄰的客戶集合(NNUd ),其為該類化工產(chǎn)品的精準客戶,實施精準化的營銷活動。由消費者ud未評價的產(chǎn)品,通過消費者對產(chǎn)品的平均評價得分和與該消費者近鄰用戶的評價架構(gòu)來做出預(yù)測,從而為消費者ud提供更加精準的產(chǎn)品推薦服務(wù),使得消費者的滿意度得到大大提升。企業(yè)為消費者推薦產(chǎn)品預(yù)測值計算公式為[9]:
式中:R(-)'d 為消費者 d 對產(chǎn)品的平均評分。
3 實例分析
3.1 數(shù)據(jù)來源
化工產(chǎn)品種類眾多,同時滿足客戶需求的化工產(chǎn)品類型也比較多。化工企業(yè)在開展營銷活動的過程中必須對消費者進行聚類,結(jié)合聚類分析的結(jié)果來實施精準營銷,提升企業(yè)市場競爭力。選擇西安某化工企業(yè)作為案例,通過數(shù)據(jù)挖掘技術(shù)對客戶群體細分,在不同的客戶市場選擇不同的營銷模式,為客戶提供更具針對性的營銷服務(wù)活動。數(shù)據(jù)選擇該化工企業(yè)2020~2021年的營銷數(shù)據(jù),對數(shù)據(jù)進行清理,采用因子分析法獲得貢獻率大于90%的因子,共包含5個,以此作為進行精準營銷分析的原始數(shù)據(jù)。
設(shè)Pa.e為消費者 a 對產(chǎn)品 e 的預(yù)測評分;P'a.e為消費者 a 對產(chǎn)品 e 的實際評分,那么平均絕對誤差(MAE)為:
采用準確率(P)、召回率(R)、綜合平均值(F)對算法的性能進行評價,評價指標計算公式為:
3.2精準營銷算法性能
為了研究算法的有效性,將基于信息檢索與 K 均值聚類的精準營銷算法和基于標簽的Top-N個性化推薦算法[10-15]進行對比,結(jié)果如圖4所示。
從圖4可以看出,精準營銷算法相對于Top-N算法具有明顯的優(yōu)勢。由平均絕對誤差可知,不論是精準營銷算法還是Top-N算法,均可以達到幫助企業(yè)實施精準營銷的目的,但是精準營銷算法的平均絕對誤差更小,其實施經(jīng)營的精準性更高。由準確率可知,2種算法的準確率均和最近鄰域數(shù)量成正比。聯(lián)合信息檢索與K均值聚類算法將節(jié)點綜合特征值作為初始聚類中心,能夠有效解決孤立點及含噪聲數(shù)據(jù)對聚類結(jié)果的影響,導(dǎo)致聚類結(jié)果的準確率更高。由召回率可知,2種算法召回率的波動均比較小,但是精準營銷算法召回率始終處于比較高的水平,即該算法能夠更加精準地推薦消費者感興趣的產(chǎn)品[16-20]。由綜合平均值可知,聯(lián)合信息檢索與K均值聚類算法具有相對較高的綜合性能,為化工企業(yè)開展精準營銷提供數(shù)據(jù)參考。
4結(jié)語
化工企業(yè)數(shù)量的增多使得企業(yè)競爭越來越激烈,同一功能的化工產(chǎn)品種類眾多,這使得化工企業(yè)必須對客戶實施精準營銷,才能夠達到提高客戶粘性、降低營銷成本的目的。針對傳統(tǒng)K均值算法初始聚類中心選擇困難、特殊消費者以及營銷數(shù)據(jù)中噪聲數(shù)據(jù)干擾導(dǎo)致聚類效果不理想的問題,采用信息檢索系統(tǒng)來獲取初始聚類中心,提出了基于信息檢索與K均值聚類的化工產(chǎn)品精準營銷算法。將該算法和Top-N 算法進行對比,該算法的平均絕對誤差比較低,準確率、召回率以及綜合平均值均比較高,對消費者提供的精準推薦服務(wù)質(zhì)量更高。這對化工企業(yè)開展產(chǎn)品精準營銷,提升企業(yè)市場競爭力具有一定的參考。
【參考文獻】
[1] 范生萬,劉放.商品精確營銷中聚類分析與關(guān)聯(lián)規(guī)則分析應(yīng)用研究[J].華東經(jīng)濟管理,2019,31(5):182-184.
[2] 袁陽春,劉森.基于數(shù)據(jù)挖掘技術(shù)的虛擬企業(yè)審計風(fēng)險評估模型[J].微型電腦應(yīng)用.2021,37(9):103-106.
[3] 尹進,胡祥培,鄭毅,等.社會化商務(wù)中消費者感知推薦信任的聚類方法研究[J].運籌與管理,2021,30(2):16-24.
[4] 吳小榮.化工產(chǎn)品市場營銷組合策略研究[J].熱固性樹脂,2021,36(5):78-80.
[5] 王濤,劉星亮,王泓淇,等.于志軍.基于機器學(xué)習(xí)的富硒茶評論文本消費者滿意度感知研究[J].湖北農(nóng)業(yè)科學(xué).2022,61(1):146-152.
[6] 李輝,羅敏,岳佳欣.基于計算機視覺技術(shù)的水稻病害圖像識別研究進展[J].湖北農(nóng)業(yè)科學(xué),2022,61(4):9-15.
[7] 陳源毅,馮文龍,黃夢醒,等.基于知識圖譜的行為路徑協(xié)同過濾推薦算法[J].計算機科學(xué),2021,48(11):176-183.
[8] 鐘志峰,李明輝,張艷.機器學(xué)習(xí)中自適應(yīng)k值的k均值算法改進[J].計算機工程與設(shè)計,2021,42(1):136-141.
[9] 王粵,黃俊,鄭小楠,等.基于用戶興趣和評分差異的改進混合推薦算法[J].計算機工程與設(shè)計,2021,42(10):2830-2836.
[10] 馬聞鍇,李貴,李征宇,等.一種基于標簽的Top-N個性化推薦算法[J].計算機科學(xué),2019,46(S2):224-229.
[11] 何昕雷.基于模糊 PID 算法的自動控制研究[J].粘接,2022,49(3):177-181.
[12] 謝樺,亞夏爾·吐爾洪,陳昊,等.基于支持向量機算法的配電線路時變狀態(tài)預(yù)測方法[J].電力系統(tǒng)自動化,2020,44(18):74-80.
[13] 鄭茂然,余江,陳宏山,等.基于大數(shù)據(jù)的輸電線路故障預(yù)警模型設(shè)計[J].南方電網(wǎng)技術(shù),2017,11(4):30-37.
[14]? LI H J,HABIBI S,ASCHEID G. Handover prediction for long-term windowscheduling based on SINR maps[C]//2013 IEEE 24th Annual International Symposium on Per? sonal,Indoor,and Mobile Radio Communications(PIM? RC). London,UK:IEEE Press,2013.
[15] 王毅星.基于深度學(xué)習(xí)和遷移學(xué)習(xí)的電力數(shù)據(jù)挖掘技術(shù)研究[D].杭州:浙江大學(xué),2019.
[16] DHIMISH M,HOLMES V,MEHRDADI B,et al. Photo? voltaic fault detection algorithm based on theoretical curves modelling and fuzzy classification system [J]. En? ergy,2017,140(1):276-290.
[17] 胡程平,陳婧,胡劍地,等.配電臺區(qū)線損率異常自動檢測系統(tǒng)設(shè)計[J].粘接,2022,49(5):188-192.
[18] 曹海紅.基于雙DSP的異步電機控制系統(tǒng)設(shè)計[J].粘接,2021,47(8):143-146.
[19] 李振璧,張坤,姜媛媛,等.基于變分模態(tài)分解與近似熵的輸電線路兩相接地故障診斷[J].科學(xué)技術(shù)與工程,2018,18(5):70-75.
[20]? DOOSTAN M,CHOWDHURY B H. Power distribution system fault cause analysis by using association rule min? ing [J]. Electric Power Systems Research.2017,152(1):140-147.
猜你喜歡
華東理工大學(xué)學(xué)報(自然科學(xué)版)(2025年1期)2025-02-26 00:00:00
吉林化工學(xué)院學(xué)報(2021年8期)2021-09-06 09:35:12
科教導(dǎo)刊·電子版(2021年30期)2021-01-03 17:32:37
電腦與電信(2018年11期)2018-02-16 05:41:16
山西青年(2018年5期)2018-01-25 16:53:40
新聞傳播(2016年18期)2016-07-19 10:12:06
新聞傳播(2016年11期)2016-07-10 12:04:01
現(xiàn)代計算機(2016年11期)2016-02-28 18:35:15
地理與地理信息科學(xué)(2015年4期)2015-10-13 08:29:20
河南科技(2014年11期)2014-02-27 14:10:19
