一種優化的Hadoop數據放置策略
2023-07-12 08:44:22吳岳
軟件工程 2023年7期
關鍵詞:策略
吳 岳
(國家林業和草原局產業發展規劃院,北京 100010)
0 引言(Introduction)
大數據系統的作用是存儲和分析大量的數據,同時確保數據的安全性和可訪問性。大數據系統將數據存儲管理委托給分布式文件系統(DFS)執行,例如Apache Hadoop的數據存儲基于Hadoop分布式文件系統(HDFS)[1]。Hadoop可以實現擴展集群上的復雜計算,它的工作原理是將復雜的計算分布在多臺機器上,并且使計算靠近數據,而不是將數據送至計算,最大限度地減少對網絡帶寬的占用,從而提高全局性能[2]。
HDFS的數據放置策略會將數據塊分條和復制,可在發生故障時盡可能地保護數據。該策略的數據保護原則是為相同數據創建多個副本,并將副本分布放置在多個機架的多臺計算機上。然而,該策略放置副本時沒有考慮到隨著時間變化,每個數據的被需求程度也會變化,有可能導致沒有發揮集群的最優性能。本文通過深入研究Hadoop和HDFS的整體工作機制,提出一種綜合考慮需求和處理性能實現重新放置副本的算法,并通過實驗證明,該算法可以將集群的處理性能提高20%以上。
1 Hadoop分布式文件系統(Hadoop Distributed File System)
1.1 HDFS的架構
HDFS的架構由單個活動的Master(Name Node)和多個Slave(Data Node)組成[3]。Name Node負責管理集群中Data Node的狀態,并處理整個集群中的存儲分布。用戶的每次讀寫操作都從向NameNode發起請求開始[4]。文件系統元信息(包含數據塊定位)與數據塊分別存儲在NameNode和Data Node上,Name Node只是將用戶查詢的Data Node列表作為元數據塊傳輸給用戶,之后用戶在不重復讀取NameNode的情況下與Data Node通信。Name Node不參與用戶和Data Node之間的數據傳輸,這種方法簡化了HDFS 的架構,避免了NameNode成為瓶頸[5]。
1.2 HDFS的復制
HDFS在復制過程中,將文件分成幾個大小相等的數據塊,這個操作稱為數據條帶化[6]。HDFS通過將這些數據塊存儲在不同DataNode上實現并行化數據訪問,從而縮短響應時間。將每個數據塊復制成多個副本(默認是3個,可修改配置),并將每個副本存放在根據預定義策略確定的Data Node上[7]。這樣可以降低由于硬件發生故障導致數據丟失的風險。Data Node能通過心跳機制向NameNode匯報狀態信息,當某個DataNode發生故障時,NameNode可在其他DataNode上重構該DataNode上的數據塊,保持每個數據塊的副本數量正常[8]。
副本的數量也稱為復制因子,由NameNode管理,可以隨時針對每個文件進行單獨更改[9]。創建文件時,NameNode會向用戶提供可以存儲該數據的Data Node列表,該列表包含N個DataNode,其中N是復制因子。用戶先將數據塊傳輸到第一個本地的Data Node,之后該Data Node將數據塊副本傳輸到列表中的第二個Data Node,第二個Data Node繼續傳輸副本,直到第N個Data Node,數據就像在一個管道中傳遞。
1.3 HDFS默認的副本放置策略
HDFS通常被配置為由多個機架組成的集群,每個機架裝配有多個DataNode。不同機架之間的節點通信需要依靠交換機等網絡設備,所以同一機架節點之間的數據交換速度會快于不同機架中的節點。如果只考慮網絡帶寬的占用和數據訪問時間,可以從同一個機架上選擇幾個Data Node存儲所有數據塊的副本,但是這樣的系統是脆弱的,如果該機架出現故障,則數據將會全部丟失。
HDFS在執行數據塊寫入操作時,應用了一種平衡故障風險和訪問速度的策略。如果復制因子為3,第一個副本放置在與客戶端相同節點的Data Node上,第二個副本放置在同一個機架的另一個Data Node上,第三個副本放置在不同機架的DataNode上。如果復制因子大于3,第四個及后續的副本都隨機放置在集群中。這種策略可以在網絡、機架或交換機出現故障時提供更好的數據健壯性,并且優化了寫入時間,因為2/3的數據量是在同一機架間交換的(復制因子為3時)。
這種策略存在一個問題,它在確定放置副本的Data Node時,沒有考慮對副本的訪問需求,事實上在創建數據塊時,第一個副本總是放置在靠近“寫入者”的Data Node上。這種副本放置策略可能會因集群上數據分布不均而影響處理性能。本文提出一種分析副本需求的方法,并開發一種綜合考慮需求和處理性能實現重新放置副本的算法。通過模擬實驗表明,通過對集群操作中對副本的需求進行分析后,將請求量最多的數據轉移到能夠最快處理它們的節點上,可以將處理性能顯著提高[10]。
2 算法設計(Algorithm design)
2.1 評估數據塊需求
在HDFS管理的數據塊元數據中增加2個元數據C和T C。在一段可配置時間(比如一個月)內,C是數據塊被查詢率,即某數據塊被下載的次數;T C是該數據塊在這段時間內的平均讀取時間。T C的計算公式參見公式(1)。其中,C是數據塊被查詢次數,t i是數據塊第i次被查詢時的讀取時間。
Data Node在每次讀取操作后計算這些元數據,并隨數據塊報告傳輸給Master。每當一個數據塊被查詢時,它相應的C和T C都會更新。NameNode使用一個包含所有數據塊合并排序的數據表維護這兩個元數據值,示例詳見表1。
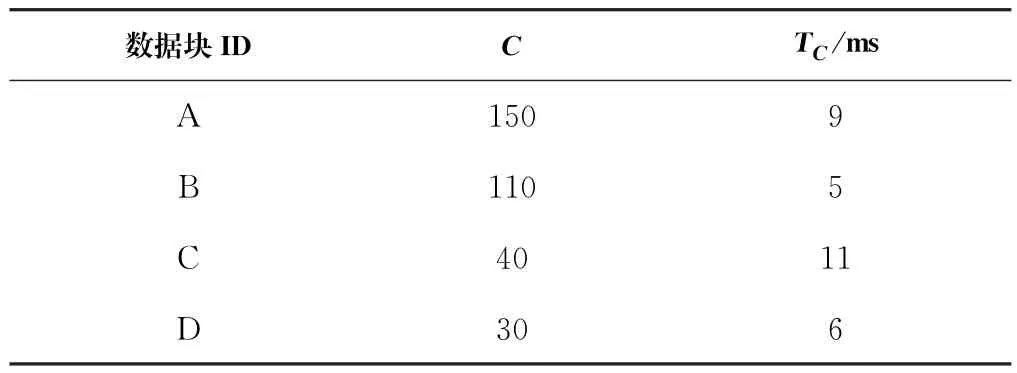
表1 數據塊需求統計示例表Tab.1 Sample table of data chunk requirement statistics
理想狀態下,統計表的每行應該是按照最大的請求數C對應最小的響應時間T C有序排列的。然而,通過對從模擬集群中回調的數據進行分析發現,高請求率的數據塊響應時間相對較長。本文的目標是將請求最多的數據塊移動到能提供最優讀取時間的節點中。利用元數據計算每個節點平均性能的方法詳見公式(2)。其中,P n是節點n的平均性能;k是節點n中數據塊的數量;Ci是節點n中第i個數據塊的被查詢次數;是節點n中查詢第i個數據塊的平均讀取時間。
將數據塊移動到具有更快讀取時間的位置,并不代表該數據塊的響應時間會提高,因為平均響應時間還取決于客戶端請求的性質(如發起讀取請求的位置、數據處理性能等),但評估算法將繼續收集被移動的數據塊在其新位置上的響應時間,并重新評估是否需要將其移動到更好的位置。在數據塊迭代進行幾次移動后,平均查詢時間會明顯提高或者停滯在其最小值,這表示數據塊在響應時間方面已處于最佳位置。數據塊的移動操作應該在數據訪問較少或沒有的時候進行,這樣網絡帶寬就不會被該操作過度占用。
2.2 算法設計
優化放置算法的流程:函數從最大查詢次數開始掃描數據塊,查詢次數統計表,檢索出請求數量最多的數據塊。算法同時嘗試檢索具有最佳性能P n的可用節點,在理想情況下,具有最高被查詢數C的數據塊將被移動到具有最優平均性能P n的節點上。
優化放置算法步驟如下。第1步:讀取數據塊需求統計表chunks_Table(ChunkId,T C,C);第2步:按照C值對統計表進行降序排序,得到表chunks_Ordred Table;第3步:按順序讀取chunks_Ordred Table中ChunkId;第4步:當ChunkId不為空時,循環執行第5步,否則,執行第6步;第5步:移動數據塊至節點(ChunkId,Get Best Node(ChunkId));第6 步:返回null。
上述算法中調用了獲取最佳節點(Get Best Node)算法。這個算法可以為選定數據塊建議一個能夠提供最佳平均性能P n的節點。遍歷表中數據塊的平均查詢時間,為統計表中的每個節點計算P n值,并根據P n值升序排序,檢查每個節點是否與待放置數據塊的參數匹配。
基于以下四個標準判斷節點是否匹配,這些標準均符合Hadoop的基本策略,即同一機架中的副本不超過兩個。①該節點與待放置數據塊所在節點不是同一個;②該節點有充足的可用空間;③該節點尚未存儲待放置數據塊的副本;④該節點與待放置數據塊的其他兩個副本都不在同一個機架中。
Get Best Node算法步驟如下。第1步:讀取待放置數據塊C m;第2步:讀取數據塊需求統計表chunks_Table(ChunkId,T C,C);第3步:計算chunks_Table中每個數據塊的P n值;第4步:按照P n值對統計表進行升序排序得到表chunks_Ordred Table;第5 步:按順序讀取chunks_Ordred Table中ChunkId;第6步:循環選擇chunks_Ordred Table中下一個數據塊所在節點N;第7步:當節點N的P n值小于C m的T C值且符合4個判斷標準,返回節點N;第8步:循環結束。
3 實驗與結果(Experiments and results)
3.1 實驗設置
實驗中模擬了一個由12個節點組成的集群,結構詳見圖1。使用Hadoop版本為2.5.0,Hadoop的數據塊配置為64 MB,復制因子為3。實驗中使用12個大小為64 MB的文件模擬待處理數據。該集群由3個機架組成,每個機架由4個節點組成,每個節點的存儲容量等于數據塊的3倍,即192 MB。每個節點的性能是不同的,每個機架上4個節點的配置見表2。同一機架內的帶寬設為1 GB/s,機架之間的帶寬配置見圖1。
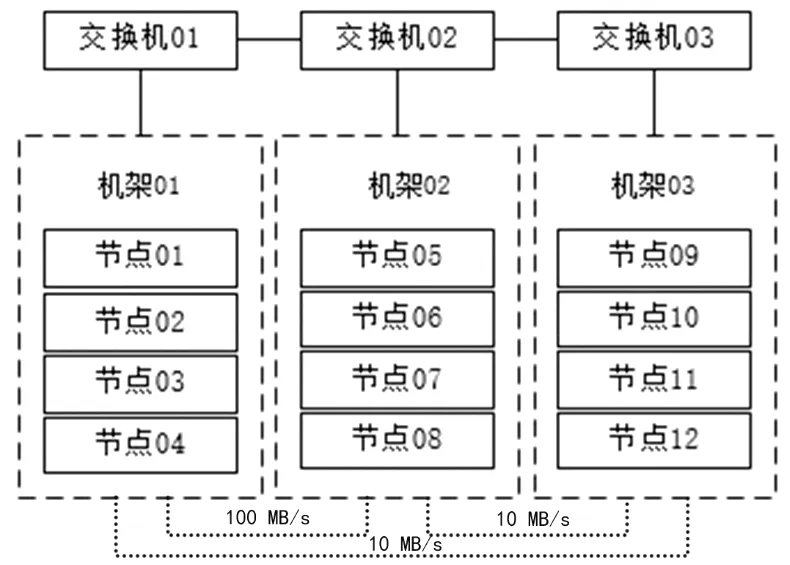
圖1 實驗模擬集群結構圖Fig.1 Cluster structure in experiment
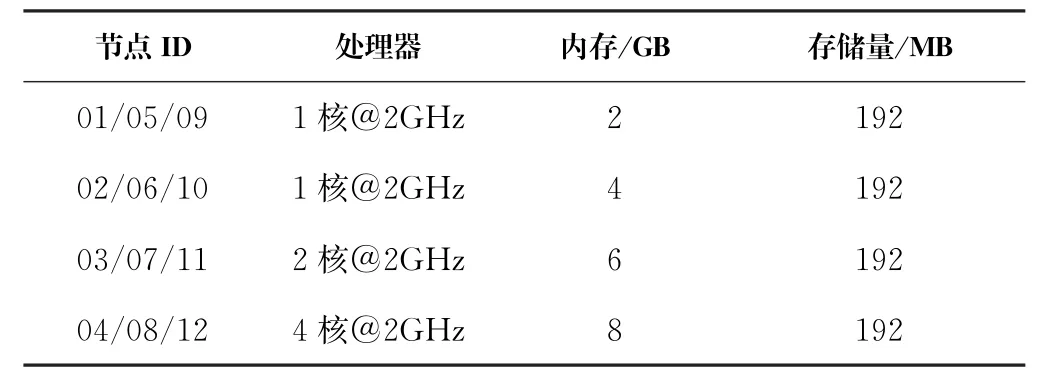
表2 節點配置表Tab.2 Nodes configuration table
由于每個節點最多只能存儲三個數據塊,所以在實驗中可以迅速使節點存儲達到飽和,便于更加準確地測試算法的性能。
測試作業為集群中的12個節點對每一個均勻分布存儲在集群上的文件執行不同數量的Map任務。每個作業只調用一個文件,因此被請求數C等于執行的作業數。
實驗步驟如下。第1步:在集群中按照Hadoop默認放置策略存儲12個文件;第2步:運行測試作業;第3步:收集執行時間,并創建/更新統計表;第4步:計算平均性能值P;第5步:如果P值不理想,使用算法找出數據塊的建議放置點,否則,實驗結束;第6步:移動數據塊至建議放置點,并由第2步開始重新執行。
上述步驟會迭代幾次,在每次迭代后都會計算集群的整體性能P n值。通過比較默認副本放置策略和優化后的放置算法的P值評估優化算法的有效性。
3.2 試驗結果
測試作業第一次運行后收集的結果見表3。
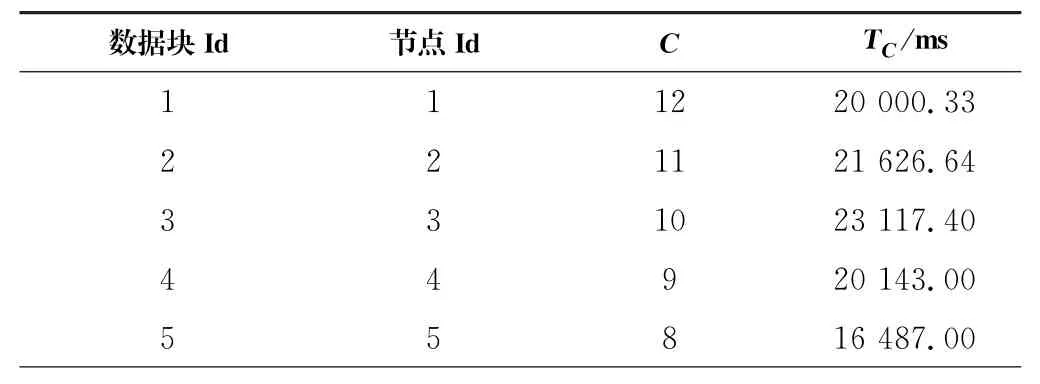
表3 數據塊初始統計表Tab.3 Initial statistics table of data chunk
由于實驗選用文件的大小與Hadoop數據塊配置相同,一個文件對應一個數據塊,所以每個作業只調用一個文件,C是執行作業的次數,也就等于數據塊被請求數。將表4的數值代入公式(2)可以計算出集群的整體性能P1為25 594.86 ms,其中的T C值反映了Hadoop默認放置策略下的平均讀取時間。
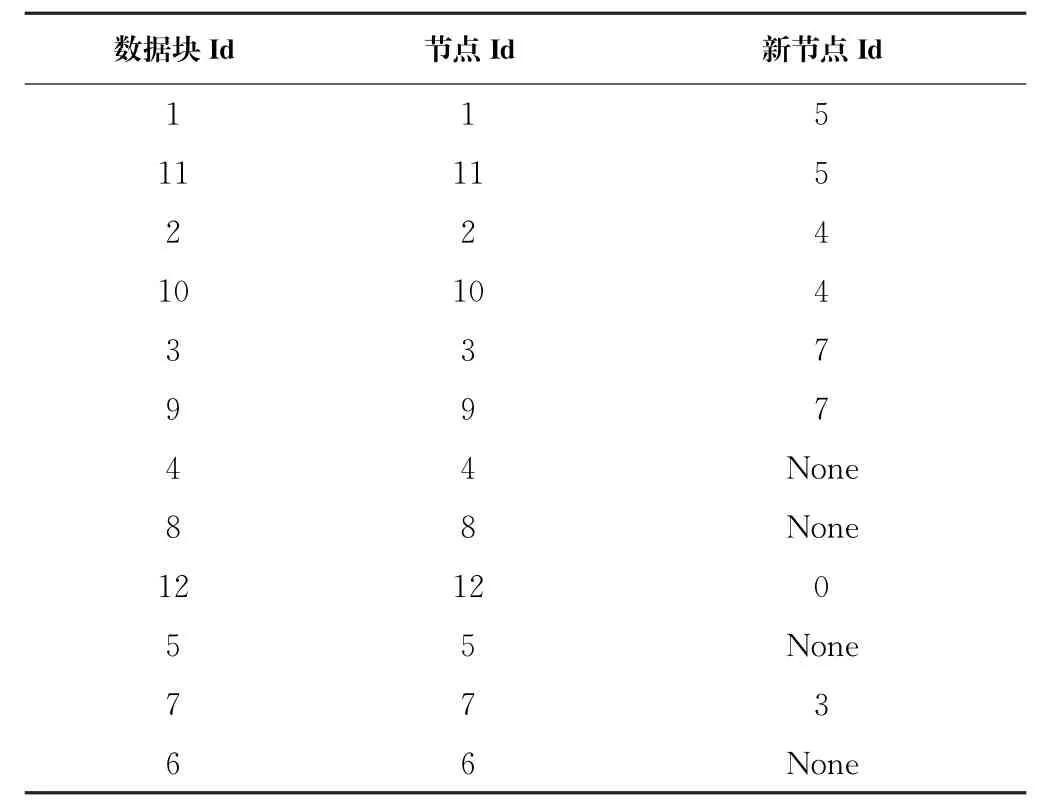
表4 數據塊建議放置位置表Tab.4 Recommended placement table of data chunks
應用優化的數據放置算法后,得到的數據塊放置建議見表4。算法建議將其中8個數據塊放置到新的位置,剩下的4個數據塊沒有建議新位置,因為將它們放置到當前集群中的任何可用節點都不會縮短任務執行時間。
按照算法建議位置移動數據塊后,再次運行相同的測試任務,重新計算的響應時間T C,結果見表5。
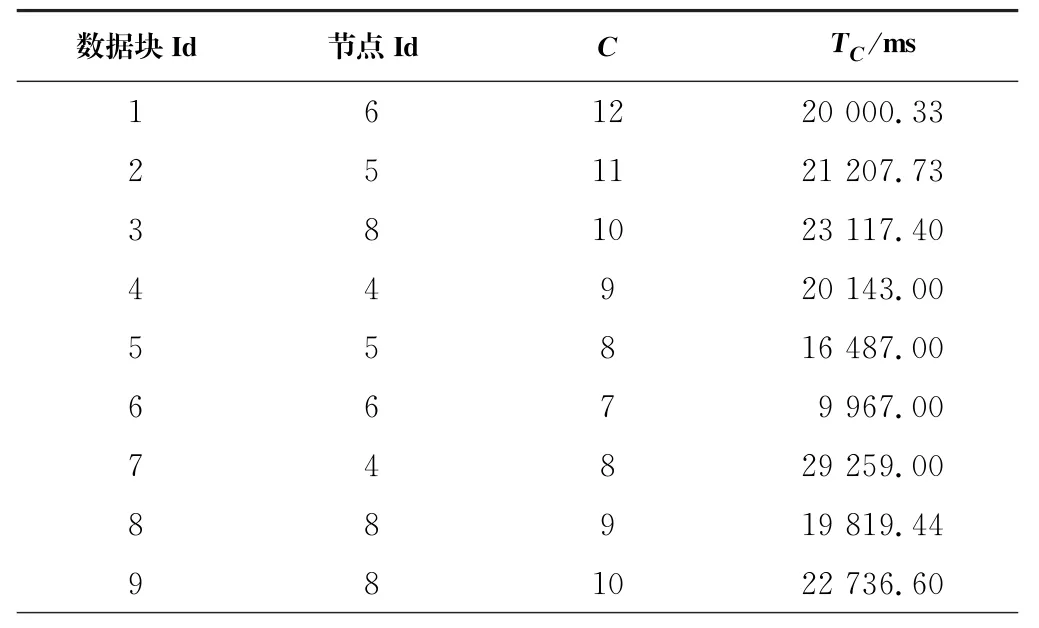
表5 第一次重新放置后數據塊統計表Tab.5 Data chunks statistics table after the first replacement
將表5的數值代入公式(2)可以計算出集群的整體性能P2為20 125.21 ms,與集群初始整體性能P1相比,提高了21.37%。在執行5次測試任務后,后4次的集群整體性能P值依次為20 125.21 ms、20 098.96 ms、20 964.57 ms、20 732.94 ms。由此可看出,在第一次執行測試任務后,P值處于穩定狀態,之后的數據塊位置改變幾乎不會再影響集群的整體性能,那么,可以認為數據塊在第一次執行優化算法后就被放置在了最佳位置。
4 結論(Conclusion)
實驗數據證明,在符合HDFS默認數據放置算法基本規則的前提下,提出的優化的數據放置策略算法,可以使集群的整體性能提高20%以上。并且,該算法執行一次即可使集群整體性能接近最優值,不會因為數據塊頻繁移動而過多占用集群的網絡帶寬。實驗結果符合預期,優化后的數據塊放置算法能夠有效優化集群整體性能。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
