ChatGPT支持的學生論證內容評價與反饋
2023-07-26 00:31:30王麗李艷陳新亞徐翎衲
現代遠程教育研究 2023年4期
王麗 李艷 陳新亞 徐翎衲
摘要:在論證式教學中,由于學生生成的論證內容量大且復雜,教師評價與反饋往往滯后且難以保證質量。生成式人工智能聊天工具ChatGPT的出現為解決該問題提供了可能。與ChatGPT互動的質量取決于提問設計,如何向其提問成為獲得有效反饋的關鍵。基于“初始提問”和“優化提問”兩種提問設計,利用ChatGPT對50份學生論證內容進行評價與反饋,從反饋精準度和反饋類型兩方面對其效果展開實證比較發現:“優化提問”下ChatGPT的反饋精準度(含精確度和召回率)高于“初始提問”,但在兩種提問設計下的反饋召回率均低于精確度,且在量化評價維度上的精準度表現優于質性評價維度;基于兩種提問設計,ChatGPT均能針對論證內容生成任務型反饋、過程型反饋、建議型反饋和情感型反饋,但相較于“初始提問”,其基于“優化提問”所生成的反饋更具組織性、解釋性和針對性,而兩種提問設計下的情感型反饋均表現出“就事論事”“中庸”的特點。為有效發揮ChatGPT在教學評價與反饋中的潛能,教師需做好提問設計,發揮其在情感反饋上的優勢,并對機器反饋進行把關,同時注重培育學生的反饋素養。
關鍵詞:ChatGPT;教學評價;教學反饋;論證式教學;提問設計
中圖分類號:G434? ?文獻標識碼:A? ? 文章編號:1009-5195(2023)04-0083-09? doi10.3969/j.issn.1009-5195.2023.04.010
一、引言
由OpenAI推出的生成式人工智能(Artificial Intelligence Generated Content,AIGC)聊天工具ChatGPT,自發布以來引發了教育界的持續熱議。作為一種基于大規模語言模型的智能對話系統,ChatGPT采用提示學習與人類反饋相結合的訓練方式,能夠根據提問提供多輪次、流暢、自然的回答。這種基于自然語言的對話能力使其在教學評價與反饋中具備良好的應用潛力,能夠對文本類型的學生作業進行評分和反饋,從而在減輕教師教學負擔的同時,為學生提供更加個性化和便捷的學習體驗(Guo et al.,2023;王佑鎂等,2023;鐘秉林等,2023)。可以預見,ChatGPT基于用戶提問進行個性化知識生產的能力(沈書生等,2023),有可能顛覆以往“搜索就是學習”的模式,將古老的對話式學習重新帶回當下的教育生態之中,而學生與ChatGPT對話溝通的能力將直接影響其學習效果與質量(焦建利,2023)。這也意味著如何向ChatGPT提問變得尤為重要——只有好的提問設計,才能激發ChatGPT生成質量較好的回答(Liu et al.,2023)。因此,有學者開始探索如何針對ChatGPT進行提問設計,并指出提問應結合領域知識,相較于一般性的提問,具體、明確的提問更能激發ChatGPT生成高質量的回答(White et al.,2023)。
論證式教學是指教師將論證活動引入課堂,讓學生經歷類似科學家的評價資料、提出主張、為主張進行辯駁等過程,從而培養學生的科學思維方式(何嘉媛等,2012)。論證式教學有助于學生進行知識建構、培養學生的論證能力和批判性思維能力(彭正梅等,2020)。然而,在傳統的論證式教學評價中,由于學生在論證過程中生成的論證內容量大且復雜,教師需耗費大量時間甄別和梳理出論證內容中的評價要點,受到時間、精力、個人經驗的限制,評價與反饋往往滯后且難以保證質量,容易出現評價要點遺漏以及反饋單一、片面、過于主觀等問題。
鑒于此,本研究嘗試使用ChatGPT對論證式教學中的學生論證內容進行評價和反饋。考慮到提問設計對ChatGPT反饋質量的影響,本研究借鑒前人文獻中的提問設計原則,結合論證式教學評價的現實經驗,嘗試設計兩種提問(“初始提問”和“優化提問”),比較ChatGPT在不同提問設計下對論證內容的評價與反饋存在何種差異,由此探索其在教學評價中的應用潛能,為AIGC技術和工具融入未來教育教學提供思路和參考。
二、文獻綜述
1.論證內容評價研究
所謂“論證”,是一種溝通和互動的活動,即論證者通過提供證據來證明其主張成立的過程,目的是消除受眾之間的意見分歧(Van Eemeren et al.,1987)。圖爾敏論證模型為論證內容的評價提供了基本依據。該模型由六要素構成,分別是:主張、論據、理據、支持、限定和反駁(Toulmin,1958)。一般認為論證結構中包含的要素越多,內容越復雜,論證的質量越好(Bell et al.,2000)。然而,有學者指出,利用圖爾敏論證模型評價論證內容時,難以明確地區分以上六要素,尤其是界限較為模糊的論據、理據、支持三要素(Voss et al.,2001);另外,圖爾敏論證模型更關注論證的結構而非論證的具體內容,且沒有考慮特定人群和場景(Erduran et al.,2004)。
針對教育場景,已有研究將圖爾敏論證模型中的要素進行優化,提出了不同形式的論證內容評價標準。庫恩(Kuhn,1991)認為完整的論證結構應該包括三個部分:主張的陳述,指對某事所持的觀點或態度;可靠的證據,用以支持主張的相關證據;推理的過程,用以解釋主張與證據之間的因果關系。庫恩等(Kuhn et al.,1997)認為評價論證內容的質量應從論證的功能性出發,功能性較好的論證能夠對某事做出明確的判斷,并給出可靠的證據和合理的解釋,功能性較弱的論證則反之。庫恩(Kuhn,2010)還特別關注論證過程中的反駁,認為反駁是評估論證內容質量的重要指標。克拉克等(Clark et al.,2008)同樣強調反駁的重要性,但更強調解釋或推理的充分性以及證據的充分性,認為高水平的論證內容應該包含充分的解釋以及合理的證據。薩德勒等(Sadler et al.,2006)認為評價學生的論證內容需關注主張的合法性,為此,應通過提供足夠的證據以及合理的解釋使主張更具說服力。
此外,一些學者關注論證內容的完整性,依據論證內容所包含的觀點、證據、反駁的次數對論證內容做出評價。澤德勒等(Zeidler et al.,2003)將論證內容的質量由低到高分為5個等級:第1級只包含觀點;第2級由觀點和至少一個證據組成;第3級由觀點、至少一個證據和反駁組成;第4級由觀點、多個證據和至少一個反駁組成;第5級由觀點、多個證據和多個反駁組成。林樹生(Lin,2014)讓學生總結新聞觀點并寫出反駁理由,在對學生論證內容進行評分時,強調反駁次數越多則論證內容越清晰,因此加入了對反駁次數的計分。
通過以上文獻梳理發現,現有對論證內容的評價存在質性評價與量化評價兩種形式:質性評價強調論證內容的合理性,從解釋充分性與證據充分性等方面進行評價;量化評價關注論證內容的完整性,依據論證內容中所包含的觀點、證據、反駁的數量進行評價。
2.教學反饋有效性研究
教學反饋是指針對學習者的行為或表現提供的信息,使學習者能夠了解當前學習狀態,改進學習進程,縮小與學習目標之間的差距(Sadler,1989)。已有研究將教學反饋分為不同的類型,來探究其效果。利薩科夫斯基等(Lysakowski et al.,1982)通過對54個研究進行元分析,發現糾正性反饋是一種非常有效的反饋類型,它能夠根據任務完成情況或學生行為表現,指出學生在特定任務中哪里做得對,哪里做錯了,以便學生能夠修正錯誤,提高學習效果。哈蒂等(Hattie et al.,2007)通過元分析發現,有效的教學反饋往往與任務目標相關,并基于此提出了有效的教學反饋應該回答的三個基本問題:一是“任務的目標是什么”,即幫助學生明確學習目標與評價標準;二是“目前進展如何”,即幫助學生了解執行學習任務過程中的行為表現和任務進展情況,及時發現問題并改進;三是“接下來該怎么做”,即為學生提供具體的指導與建議,支持其發展自我調節能力,以完成更高的學習目標。同時,哈蒂等強調自我調節型反饋是一種有效的反饋類型,能夠為學生提供學習策略、認知層面更高的目標與建議(Hattie et al.,2007)。此外,情感反饋因其能夠促進學生的學業表現和學習動機,也被認為是一種有效的反饋類型(Nelson et al.,2009)。情感反饋可分為表揚性反饋和批評性反饋:表揚性反饋有助于促進學業表現、提高學習動機、增強自信心和消除學業焦慮(Duijnhouwer,2010);批評性反饋則能夠幫助學習者反思當前的學習表現并制定更高的學習目標,特別是當學習者面對并不熱衷的學習任務時,批評性反饋更有助于其獲得學習動力(Van-Dijk et al.,2000)。
隨著在線教育的推廣與普及,在線學習環境下的機器反饋質量及其評估日益受到關注。精準度是評估機器反饋質量的重要標準,具體包括精確度和召回率。兩者均以人工標注為“金標準”,精確度是指系統正確識別出的人工標注項數除以系統識別出的總項數,召回率是指系統正確識別出的人工標注項數除以人工標注的總項數(Hoang et al.,2016)。精確度和召回率越高,則表明機器反饋的質量越好。通常情況下,精確度達到90%~100%被認為是可接受的閾值范圍;相對于不能識別出更多的人工標注,錯誤的反饋可能對學生產生更大的負面影響,因此精確度比召回率更受重視(Chodorow et al.,2010)。
三、研究目的與問題
學界普遍認為,與ChatGPT互動的質量取決于提問設計,即好的提問設計會激發ChatGPT生成質量較好的回答。因此,本研究嘗試通過“初始提問”和“優化提問”兩種提問設計,從精準度和反饋類型兩個層面來分析ChatGPT對大學生論證內容評價與反饋的效果和質量差異。“初始提問”指的是研究者參考論證內容評價標準,同時基于自身多年的教學經驗進行的首次提問;“優化提問”指的是研究者在獲得“初始提問”的反饋信息后,基于初始提問進行優化后的提問。研究通過對以上兩種提問設計下ChatGPT產生評價和反饋內容的比較,來探究不同的提問設計下ChatGPT對學生論證內容的評價與反饋效果有何差異,具體問題包括:(1)基于“初始提問”與“優化提問”,ChatGPT對學生論證內容的反饋精準度有何差異?(2)基于“初始提問”與“優化提問”,ChatGPT對學生論證內容會產生哪些類型的反饋?這些反饋類型各自有什么特點?
四、研究設計
1.研究對象
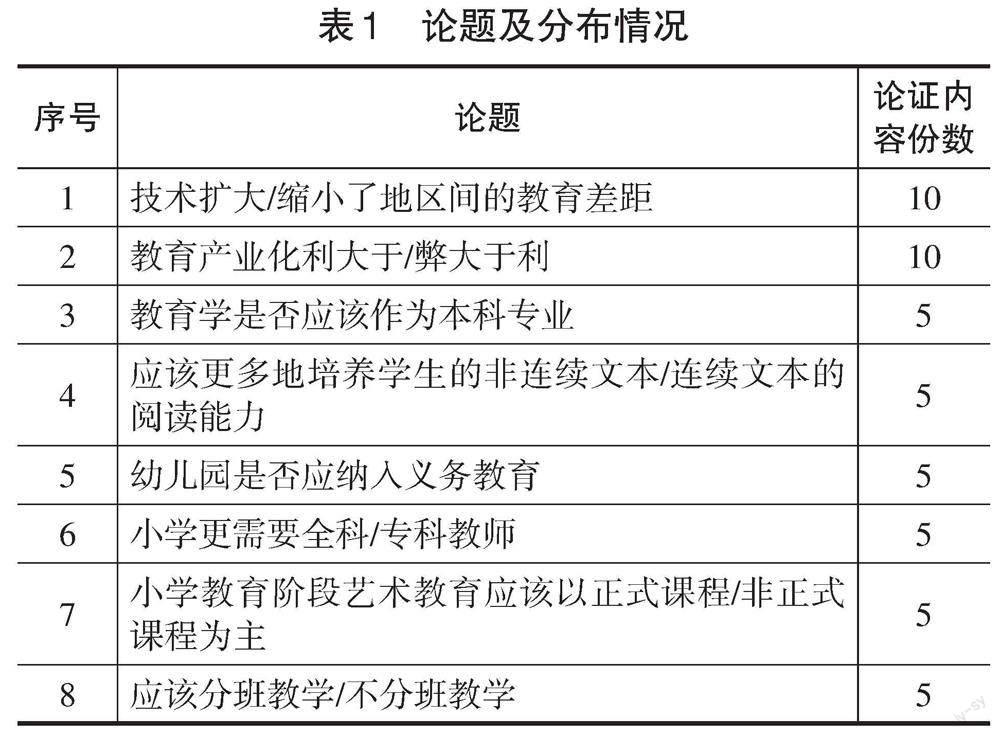
本研究以Z校42名大二本科生在“浙大語雀”平臺上完成的50份論證內容為評價樣本。所有學生以自由組合的方式分為10個4~5人的論證小組,每兩組(分為正反方)在“浙大語雀”的辯論區進行論證,歷時8周。期間,由A教師引導學生選定論題,并制定學習目標。學生圍繞表1所示的8個論題進行論證,共產生50份論證內容,共計約8.4萬字,其中,短篇論證內容(800~1300字)13份,中篇論證內容(1300~1800字)16份,長篇論證內容(1800~2300字)21份。論題及分布情況如表1所示。
2.提問設計
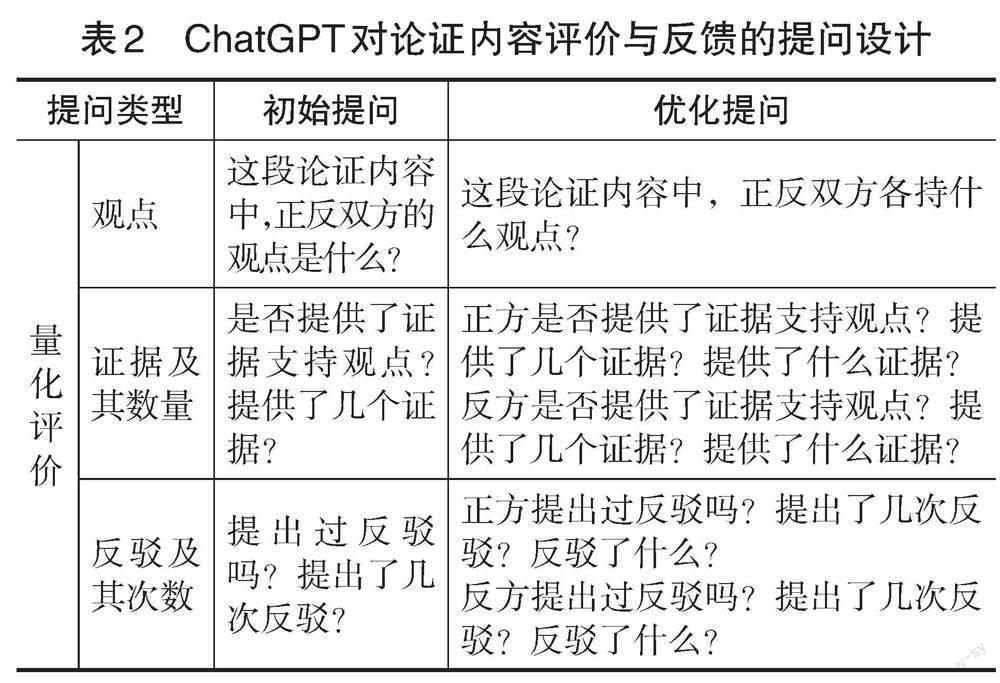
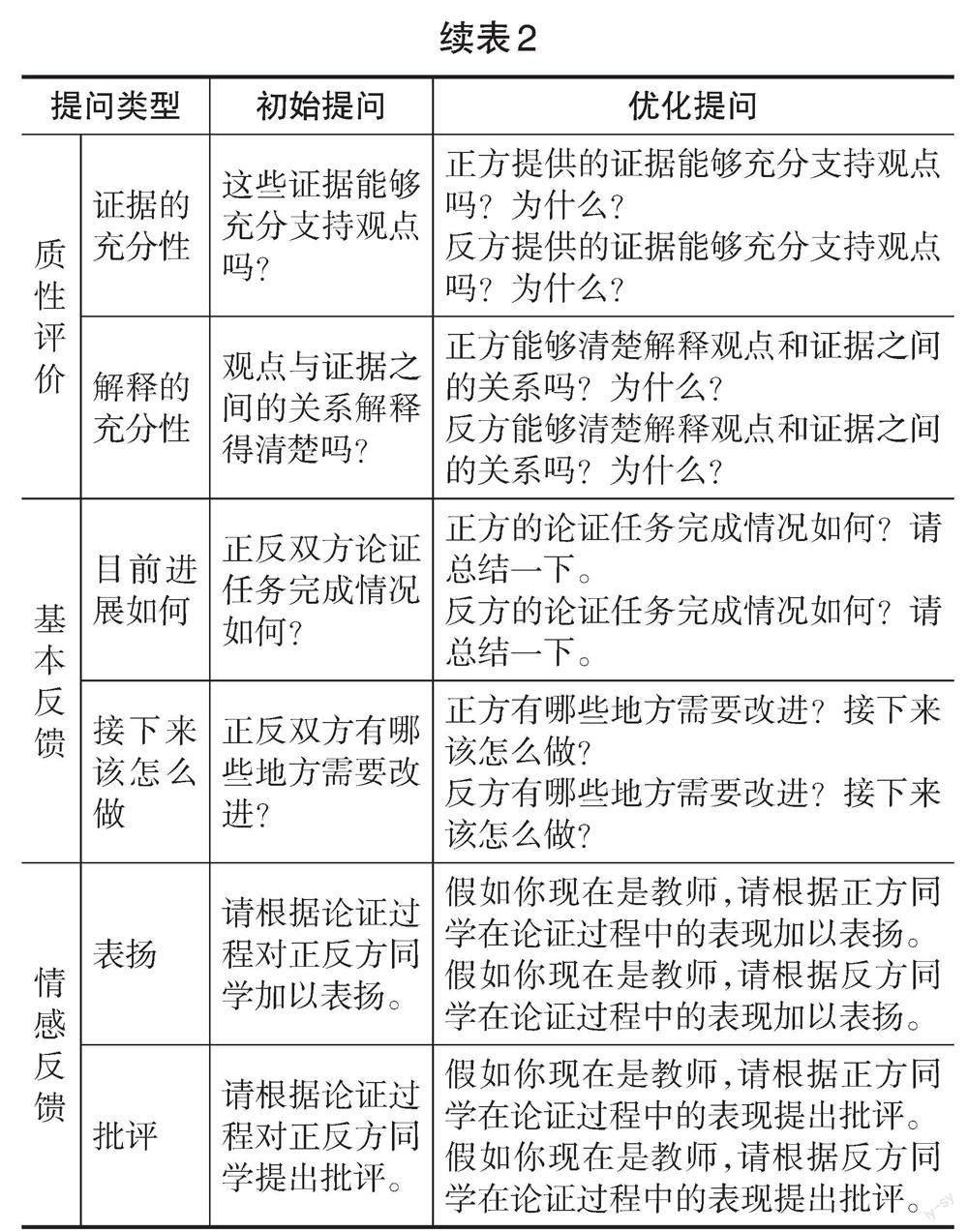
研究者采取以下四個步驟進行提問設計:(1)參考澤德勒等人(Zeidler et al.,2003)和庫恩等人(Kuhn et al.,1997)的評價標準,分別從量化評價和質性評價兩個方面進行提問設計。其中,量化評價的維度包括有無觀點、有無證據及其數量、有無反駁及其次數;質性評價的維度包括證據的充分性、解釋的充分性。(2)參考哈蒂等人(Hattie et al.,2007)所提出的有效反饋須回答的三個問題設計提問,即“任務的目標是什么”“目前進展如何”“接下來該怎么做”,考慮到任務目標的設定已在論證活動開始前完成,因此,研究只針對后兩個問題進行提問設計。(3)參考尼爾森等人(Nelson et al.,2009)對表揚性反饋與批評性反饋的研究,要求ChatGPT做出表揚性與批評性反饋。(4)基于以上三個步驟,研究者首先完成了“初始提問”設計,并在獲得“初始提問”的反饋信息后,再根據懷特等人(White et al.,2023)的“提示語模式分類框架”對初始提問進行優化,產生“優化提問”設計,具體采用指明所問對象、不斷追問、設定角色三種優化策略。根據以上程序,最終確定了如表2所示的“初始提問”與“優化提問”兩種提問設計。
3.數據收集與分析
(1)ChatGPT的反饋信息收集
基于兩種提問設計,研究者將50份學生論證內容(編號為A01至A50)依次輸入ChatGPT獲取其對論證內容的反饋信息。具體操作程序如下:研究者首先將論證內容與“初始提問”合并輸入ChatGPT,逐一獲得反饋信息后,將反饋信息錄入Excel文檔,獲得50份ChatGPT對論證內容的反饋信息(編號為P1F1至P1F50);接著遵循前人文獻中反饋單元的拆分操作程序(Hayes et al.,2010),將反饋信息拆分為586個反饋單元;遵循同樣的步驟,研究者基于“優化提問”獲得50份反饋信息(編號為P2F1至P2F50),并將其拆分為965個反饋單元。
(2)對論證內容的標注與分析
為了建立客觀科學的論證內容檢驗標準,研究者與A教師合作對50份學生論證內容進行標注,操作程序如下:首先,研究者與A教師參考澤德勒等人(Zeidler et al.,2003)和庫恩等人(Kuhn et al.,1997)的評價標準,先抽取5份論證內容,分別對其中的觀點、證據及數量、反駁及次數、證據的充分性和解釋的充分性等評價要點進行標注;隨后,研究者與A教師比對標注結果,對不一致的標注進行協商并達成共識;最后,研究者與A教師獨立對其他論證內容進行標注。經一致性計算發現,論證內容評價要點的標注一致性達到0.81,表明人工標注結果較為準確。
研究者將ChatGPT對兩種提問設計的反饋信息與學生論證內容的人工標注結果進行逐一比對,根據觀點、證據、反駁、證據的充分性、解釋的充分性進行分類統計,計算出兩種提問設計下,ChatGPT對論證內容反饋的精確度和召回率。本研究對精確度和召回率的計算以人工標注結果為金標準,即精確度為ChatGPT正確識別出的人工標注項數除以其識別出的總項數,召回率為ChatGPT正確識別出的人工標注項數除以人工標注的總項數。
(3)反饋類型的扎根分析
研究者分別將ChatGPT對“初始提問”和對“優化提問”的反饋信息分別輸入Nvivo 12進行編碼分析。具體步驟如下:首先,對反饋信息進行開放式編碼,即對反饋信息進行逐句歸納與總結,提煉出初始概念;接著,對初始概念進行主軸式編碼,將初始概念歸納為范疇化類屬;最后,對所有類屬進行分析與比較,梳理出兩種提問設計下ChatGPT針對學生論證內容所生成的反饋類型及其差異。
五、研究發現
1.基于兩種提問設計的反饋精準度比較
基于兩種提問設計,ChatGPT對學生論證內容的反饋精準度如表3所示。整體而言,“優化提問”的反饋精確度(91.8%)與召回率(63.2%)高于“初始提問”的反饋精確度(79.6%)與召回率(38.4%)。可見,ChatGPT對論證內容的反饋精準度受到提問設計的影響。
具體來看,“初始提問”的反饋中,觀點的反饋精確度達100%,其次是證據及其數量(88.2%)、反駁及其次數(81.3%),證據的充分性與解釋的充分性相對偏低,分別是68.0%與53.0%。“優化提問”的反饋中,觀點的反饋精確度達100%,其次是證據及其數量(95.8%)、反駁及其次數(91.0%),最后是證據的充分性(85.3%)與解釋的充分性(85.0%)。可見,兩種提問設計下,ChatGPT對論證內容的量化評價表現均優于質性評價表現。
然而,從反饋的整體召回率來看,“優化提問”只有63.2%,這意味著36.8%的評價要點沒有被識別。具體來看,觀點的反饋召回率最高(100%),其次是證據及其數量(89.2%)與反駁及其次數(75.9%),在證據的充分性和解釋的充分性兩方面的召回率均較低,分別是47.4%和29.8%。相較而言,“初始提問”反饋的整體召回率更低,只有38.4%,這說明ChatGPT忽略了61.6%的評價要點。基于“初始提問”,ChatGPT在觀點上的反饋召回率高達100%,其次是證據及其數量(53.9%)與反駁及其次數(36.8%),證據的充分性與解釋的充分性的反饋召回率僅有22.2%和18.6%。這意味著基于“初始提問”,ChatGPT沒有識別出絕大多數論證內容中的質性評價要點。總體而言,ChatGPT對論證內容評價的反饋召回率還有較大的提升空間。
2.基于兩種提問設計的反饋類型比較
通過對兩種提問設計的反饋信息進行梳理與分析,研究發現ChatGPT生成的反饋信息包括4種類型:任務型反饋、過程型反饋、建議型反饋和情感型反饋。在兩種提問設計下,上述4類反饋的占比情況如表4所示。整體上看,兩種提問設計下的各類反饋占比差異不大。研究分別對兩種提問設計下的4類反饋信息進行比較后發現,相較于“初始提問”下的反饋信息,“優化提問”下的反饋信息更具組織性、解釋性和針對性,而兩種提問設計下的情感型反饋均表現出“就事論事”“中庸”的特點。
(1)任務型反饋
任務型反饋是ChatGPT針對論證任務的完成情況所做出的評價與反饋。相較于“初始提問”,基于“優化提問”生成的任務型反饋更能按照一定的邏輯順序梳理和列舉出論證內容的評價要點,總結和提煉出論證內容的基本框架,呈現出更強的組織性。例如,基于“優化提問”,ChatGPT針對論證內容A30輸出的反饋中,首先對正反雙方觀點進行陳述,接著列舉出正反雙方所提供的觀點以及證據、反駁及其數量。“正方觀點:幼兒園不應該被納入義務教育。反方觀點:幼兒園應該被納入義務教育。正方提供了三個證據支持觀點:學前教育產品的部分私有性與義務教育產品為純公共產品存在沖突;幼兒園教育的成本不應且不能做到政府單方面承擔,而應由家庭、社會各方面分擔;強制進行幼兒園教育不利于部分幼兒成長。反方提供了兩個證據支持觀點:幼兒園員工招聘參差不齊;學前教育產品本質上擁有更多的公共產品特征。正反雙方都提出了反駁,各提出了至少一次反駁。”(P2F30)同樣是針對A30,ChatGPT根據“初始提問”所給出的反饋雖然能夠明確指出正反方觀點,但卻將正反方證據混為一談。“這段論證內容存在明確的觀點,正方認為幼兒園不應納入義務教育,反方認為幼兒園將來一定會納入義務教育的范疇。這段論證內容提供了多個證據支持觀點,例如幼兒園師資、質量和設備的不足,家長選擇學前教育機構的私人性質等。”(P1F30)
除此之外,ChatGPT輸出的任務型反饋還表現為對論證任務的完成情況進行了總結性評價。根據“優化提問”,針對A14的反饋中,ChatGPT對雙方的任務完成情況做出了總結。“正方的論證比較全面,既強調了教育學的重要性,也回應了反方的質疑和批評。反方的論證較為簡單和片面,沒有很好地回應正方的質疑和批評,也沒有提出充分的證據來支持自己的觀點。”(P2F14)相應地,基于“初始提問”,ChatGPT對A14所做出的反饋并未具體指出雙方各自的任務完成情況。“雙方都完成了他們的論證任務,雖然其中可能存在一些可以改進的地方。”(P1F14)
(2)過程型反饋
過程型反饋是ChatGPT針對論證學習目標實現的過程所做出的評價與反饋,具體包括針對證據使用情況、推理過程的反饋信息。基于“優化提問”,ChatGPT所生成的過程型反饋能夠針對證據使用情況、推理過程進行評價與反饋,且能夠給出合理的解釋,呈現出較強的解釋性。例如,ChatGPT針對論證內容A10輸出的反饋中提到:“雙方觀點和證據之間的關系解釋得較為清楚,但反方提到的一些證據并不能完全支持其觀點,例如非洲地區的互聯網使用率的例子并沒有直接證明技術的發展能夠縮小教育差距。”(P2F10)如P2F10所示,ChatGPT所提供的過程型反饋不但能夠對證據使用情況和推理過程進行評價,并且能夠通過舉例的方式來解釋證據的充分性。而基于“初始提問”的反饋并未給出明確的解釋,相對籠統。“這些證據部分能夠支持觀點,但還不夠充分,正反雙方需要更多的數據和事實來支持這個觀點。”(P1F10)
(3)建議型反饋
建議型反饋是ChatGPT在對學生論證內容進行分析與評價的基礎上,提出的具有針對性的建議類反饋。基于“優化提問”,ChatGPT輸出的建議型反饋涉及論證內容中多個要素,包括觀點、證據、反駁、證據的使用情況以及推理過程等,可以識別出論證過程中存在的問題和不足,能夠為學生提供更有針對性和更具個性化的指導和建議。例如,“正反雙方可以在論證過程中提出更多的反駁,進一步強化自己的觀點。例如,反方可以提出更多的反駁來回應正方關于評價體系和學業壓力的擔憂,正方可以提出更多的反駁來回應反方關于多樣化需求的擔憂。”(P2F50)從P2F50來看,ChatGPT根據論證內容,建議正反雙方分別以“反方關于多樣化需求的擔憂”和“正方關于評價體系和學業壓力的擔憂” 為切入口進行反駁。這說明ChatGPT能夠理解反駁在論證過程中的作用,可以結合論證內容的具體情況,為正反雙方提供具有針對性和個性化的建議,幫助他們更好地運用反駁策略和方法,強化自己的觀點,提高論證的說服力和效果。然而,基于“初始提問”,ChatGPT生成的建議型反饋常會流于表面,沒有具體和有深度的內容。例如,“正反雙方需要更清晰地說明觀點和證據之間的關系,提供更多證據來支持觀點。同時,正方需要更明確地對反方觀點進行反駁。”(P1F50)
(4)情感型反饋
根據提問設計,ChatGPT能夠針對學生論證內容做出包括表揚性反饋和批評性反饋的情感型反饋,但此類反饋也表現出“就事論事”的特點。例如,基于“優化提問”,針對論證內容A22生成的表揚性反饋中,ChatGPT先以教師的口吻,對正反方同學加以鼓勵,隨后對正反方同學的論證表現加以總結,最后就雙方的能力優勢加以肯定。“作為教師,我要為正反方同學的表現點個贊。正方同學在陳述觀點時運用了大量的數據和案例,凸顯了獨立思考和自主學習的能力。反方同學也在論證中采用了大量的個人經驗,體現了對現實問題的理解和思考。這些都是優秀論證所需要的要素,值得肯定和表揚。”(P2F22)相比之下,在“初始提問”的反饋信息中,雖然出現了“值得肯定”“值得表揚”“討論得很好”等類似于教師在評價過程中常用來表達情感的語句,但ChatGPT更多關注論證內容中觀點的優劣,而非關注正反方的論證過程、策略及個人表現。例如,“正方主張應該更多地培養學生閱讀非連續性文本的技能,并指出非連續性文本閱讀具有明顯的實用性,正方的觀點值得表揚。反方認為小學生對文字的理解能力較差,非連續性文本對學生閱讀要求較高,不適宜編寫進課本進行統一教授,反方的觀點值得部分肯定。”(P1F22)
兩種提問設計下,ChatGPT所生成的批評性反饋數量較少,且遵循一種“中庸之道”,鮮少有明顯的情感表達,類似于一種“建議性”的批評。例如,在要求ChatGPT針對論證內容A16給出的批評性反饋中,基于“優化提問”其反饋“正方同學在反駁反方同學的觀點時,存在不夠全面、甚至是一些錯誤的理解和表述,在今后的辯論中,正方同學需要更加注重論據的準確性和全面性,同時需要更好地理解和反駁反方同學的觀點”(F2F16);基于“初始提問”則反饋“正方同學在辯論過程中存在過于僵化的現象,只是堅守自己的觀點,缺乏對反方觀點的充分理解和對話。在未來的論證中,建議正方同學更開放地接受對方的觀點,積極地展開對話。”(F1F16)
六、研究結論與啟示
1.研究結論
通過比較兩種提問設計下ChatGPT對學生論證內容的評價與反饋效果,得出以下結論:
第一,ChatGPT對學生論證內容的反饋精準度受到提問設計的影響,良好的提問設計有助于ChatGPT生成質量較好的反饋。首先,基于“優化提問”的反饋精準度高于“初始提問”,這說明根據提問設計原則,采用指明所問對象、追問、設定角色等策略能夠有效地提高ChatGPT生成回答的質量(White et al.,2023)。其次,基于“優化提問”,ChatGPT對論證內容評價的精確度已達到智能反饋工具的有效閾值范圍(90%~100%)(Burstein et al.,2003),這說明良好的提問設計有助于ChatGPT針對論證內容做出較為準確的評價。盡管兩種提問設計下的反饋召回率相對偏低,但也已超過多個智能反饋工具的召回率(Dikli et al.,2014;Hoang et al.,2016;Liu et al.,2016)。以往的智能反饋工具多運用自然語言處理和機器學習技術,通過基于已有語料庫的訓練和學習,為學生提供評價與反饋。這些工具高度依賴于人工標注,只能針對特定情境進行反饋,例如錯別字、標點格式、句式語法等可以指定語義特征的文本,其適用范圍受到局限。相比之下,ChatGPT因其基于大語言模型構建的優勢,對文本具有更強的理解能力。因此,ChatGPT較少受到論證內容主題的限制,能夠通過理解論證內容的上下文,從中提取觀點、證據、反駁等評價要點,在評價過程中表現出良好的潛力。總體上看,兩種提問設計下,ChatGPT對論證內容的量化評價表現均優于其對論證內容的質性評價表現。這反映出ChatGPT在本質上依然是一個語言模型,其底層工作原理基于數學概率,當面對“證據是否充分”和“解釋是否充分”等問題時,ChatGPT遵循一種“中庸之道”,從文本數據中提取更為常見和能被普遍接受的觀點以提高答案的適用性。ChatGPT雖然在某些方面表現出良好的性能,但它仍然難以像人一樣充分理解信息與分析信息的內在邏輯關系,因此會生成不合理甚至違反事實的錯誤回答。這也反映出生成式人工智能的運算過程仍然是“黑箱”,其生成的內容不具備可解釋性與明確的依據(盧宇等,2023)。
第二,基于兩種提問設計,ChatGPT能夠生成包括任務型反饋、過程型反饋、建議型反饋和情感型反饋在內的四類反饋信息。相較于“初始提問”,ChatGPT基于“優化提問”所生成的各類反饋信息更具組織性、解釋性和針對性,具體表現為:在任務型反饋方面,基于“優化提問”,ChatGPT能夠針對論證內容提供更為具體、準確的反饋信息,幫助學生了解論證學習目標的完成情況,這種針對任務細節做出的反饋能夠幫助學生建立對當前學習狀態的認知,是學生進行自我調節學習的基礎(Lysakowski et al.,1982)。在過程型反饋方面,基于“優化提問”,ChatGPT生成的反饋信息能夠針對證據使用情況、推理過程進行評價與反饋,且能夠給出合理的解釋,有助于促進學生重新評估并調整論證策略,進而促進他們進行自我反思、調整計劃并提高達成任務目標的可能性(Carver et al.,1990)。在建議型反饋方面,ChatGPT基于“優化提問”的反饋信息具有個性化、可操作性強等特點,有利于提高學生的自我調節能力和自我效能感,幫助學生實現更高的任務目標。已有研究指出,有效的建議型反饋不但能夠提出策略層面的更高目標與建議,還能夠改善通常反饋只關注當前問題的局限性,把目標擴展到更加關注學習者長遠發展的全局視野(Hattie et al.,2007;董艷等,2021)。不過,值得注意的是,在情感型反饋方面,ChatGPT雖然能夠針對論證內容提供此類反饋,但無法像人類教師那樣關注到學生的日常表現和情感需求,給出真正具有意義的表揚或批評。然而,情感型反饋是教育中至關重要的因素,它不僅涉及師生之間的有效互動和協作,還直接關系到學生的學習情緒和心理狀態,對于促進學生的情感投入和提高教學效果至關重要(Nelson et al.,2009;Duijnhouwer,2010)。雖然ChatGPT可以在文字層面上生成某些情感反饋內容,例如語氣詞、表情符號、情感詞匯等,但是這些反饋缺乏情感深度,距離真正有價值的情感反饋還有較大差距。
2.研究啟示
基于以上研究發現,針對ChatGPT等AIGC技術和工具應用于教學評價與反饋的可能潛力,本研究得出以下兩方面的啟示:
第一,教師需扮演好“提問設計者”角色,注重發揮在情感反饋上的優勢,并做好機器反饋的“把關人”。首先,在將AIGC工具應用于教學評價與反饋的過程中,教師應當扮演好“提問設計者”的角色,通過優化提問設計來充分發揮AIGC工具的潛能,使其更為準確地生成反饋信息。例如,教師在使用ChatGPT對學生論證內容進行評價時,需結合評價標準以及教學情境進行提問設計,通過指明所問對象、不斷追問、設定角色等優化策略對提問設計進行迭代優化,以確保提問設計的針對性和實用性。其次,教師應注重補充情感型反饋與前饋。在將AIGC工具融入教學評價時,教師需強化在情感反饋上的優勢,成為“情感型反饋專家”;由于機器反饋更關注學生當前的學習狀態和效果評估(董艷等,2021),AIGC工具也只能針對實際的學習成果(如文本)生成反饋,卻無法關注到學習任務之前學生的表現,因此教師應注重補充前饋(董艷等,2023),幫助學生獲得全方位的評價與反饋。最后,教師應做好機器反饋的“把關人”。例如,在利用ChatGPT對學生論證內容進行評價時,教師需要將精力轉移到對反饋信息的評估、篩選與完善中去,基于反饋信息進行再反饋,進而提升反饋的質量和效果。
第二,學生需提升反饋素養,以便可以更加積極主動地參與到學習評價環節中并從中獲益。反饋素養是指學生理解、解釋和應用反饋信息的能力,它能保證學生更好地利用反饋信息達到提高學習效果的目的。首先,AIGC工具能夠為學生提供實時、大量且多元的反饋信息,這需要學生具備較高的反饋素養,才能快速地理解這些反饋信息并對學習策略進行有效的調整。其次,將AIGC工具應用于教學評價與反饋,也要求學生主動參與評價過程,能夠基于反饋進一步提出問題和尋求幫助。提升學生反饋素養有以下三種路徑:一是教學過程中加強對學生反饋素養的培養,引導學生更好地理解、解釋和應用人機反饋的各種有價值信息。二是組織開展有針對性的培訓,指導學生正確解讀反饋信息,掌握根據反饋信息調整學習策略的方法。三是為學生創建反饋詞匯表、反饋信息指南等工具,有針對性地解決學生在理解反饋中可能遇到的困難。
參考文獻:
[1]董艷,李心怡,鄭婭峰等(2021).智能教育應用的人機雙向反饋:機理、模型與實施原則[J].開放教育研究,27(2):26-33.
[2]董艷,吳佳明,趙曉敏等(2023).學習者內部反饋的內涵、機理與干預策略[J].現代遠程教育研究,35(3):55-64.
[3]何嘉媛,劉恩山(2012).論證式教學策略的發展及其在理科教學中的作用[J].生物學通報,47(5):31-34.
[4]焦建利(2023).ChatGPT助推學校教育數字化轉型——人工智能時代學什么與怎么教[J].中國遠程教育,43(4):16-23.
[5]盧宇,余京蕾,陳鵬鶴等(2023).生成式人工智能的教育應用與展望——以ChatGPT系統為例[J]中國遠程教育,43(4):24-31,51.
[6]彭正梅,伍紹楊,付曉潔等(2020).如何提升課堂的思維品質:邁向論證式教學[J].開放教育研究,26(4):45-58.
[7]沈書生,祝智庭(2023).ChatGPT類產品:內在機制及其對學習評價的影響[J].中國遠程教育,43(4):8-15.
[8]王佑鎂,王旦,梁煒怡等(2023).“阿拉丁神燈”還是“潘多拉魔盒”:ChatGPT教育應用的潛能與風險[J].現代遠程教育研究,35(2):48-56.
[9]鐘秉林,尚俊杰,王建華等(2023).ChatGPT對教育的挑戰(筆談)[J].重慶高教研究,11(3):3-25.
[10]Bell, P., & Linn, M. C. (2000). Scientific Arguments as Learning Artifacts: Designing for Learning from the Web with KIE[J]. Intrnational Journal of Science Education, 22(8):797-817.
[11]Burstein, J., Chodorow, M., & Leacock, C. (2003). CriterionSM Online Essay Evaluation: An Application for Automated Evaluation of Student Essays[C]// Proceedings of the Fifteenth Annual Conference on Innovative Applications of Artificial Intelligence. Acapulco, Mexico: Association for the Advancement of Artificial Intelligence:1-8.
[12]Carver, C. S., & Scheier, M. F. (1990). Origins and Functions of Positive and Negative Affect: A Control-Process View[J]. Psychological Review, 97(1):19-35.
[13]Chodorow, M., Gamon, M., & Tetreault, J. (2010). The Utility of Article and Preposition Error Correction Systems for English Language Learners: Feedback and Assessment[J]. Language Testing, 27(3):419-436.
[14]Clark, D. B., & Sampson, V. (2008). Assessing Dialogic Argumentation in Online Environments to Relate Structure, Grounds, and Conceptual Quality[J]. Journal of Research in Science Teaching, 45(3):293-321.
[15]Dikli, S., & Bleyle, S. (2014). Automated Essay Scoring Feedback for Second Language Writers: How Does It Compare to Instructor Feedback?[J]. Assessing Writing, 22:1-17.
[16]Duijnhouwer, H. (2010). Feedback Effects on StudentsWriting Motivation, Process, and Performance[D]. Utrecht: Utrecht University:12-62.
[17]Erduran, S., Simon, S., & Osborne, J. (2004). TAPping into Argumentation: Developments in the Application of Toulmins Argument Pattern for Studying Science Discourse[J]. Science Education, 88(6):915-933.
[18]Guo, B., Zhang, X., & Wang, Z. et al. (2023). How Close Is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection[J/OL]. https://doi.org/10.48550/arXiv.2301.07597.
[19]Hattie, J., & Timperley, H. (2007). The Power of Feedback[J]. Review of Educational Research, 77(1):81-112.
[20]Hayes, J. R., & Berninger, V. W. (2010).Relationships Between Idea Generation and Transcription: How the Act of Writing Shapes What Children Write[M]// Bazerman, C., Krut, R.,? & Lunsford, K. et al. (Eds.). Traditions of Writing Research. New York: Routledge:166-180.
[21]Hoang, G. T. L., & Kunnan, A. J. (2016). Automated Essay Evaluation for English Language Learners: A Case Study of MY Access[J]. Language Assessment Quarterly, 13(4):359-376.
[22]Kuhn, D. (1991). The Skills of Argument[M]. Cambridge, UK: Cambridge University Press:22-43.
[23]Kuhn, D. (2010). Teaching and Learning Science as Argument[J]. Science Education, 94(5):810-824.
[24]Kuhn, D., Shaw, V., & Felton, M. (1997). Effects of Dyadic Interaction on Argumentive Reasoning[J]. Cognition and Instruction, 15(3):287-315.
[25]Lin, S. S. (2014). Science and Non-Science Undergraduate StudentsCritical Thinking and Argumentation Performance in Reading a Science News Report[J]. International Journal of Science and Mathematics Education, 12(5):1023-1046.
[26]Liu, S., & Kunnan, A. J. (2016). Investigating the Application of Automated Writing Evaluation to Chinese Undergraduate English Majors: A Case Study of WriteToLearn[J]. Calico Journal, 33(1):71-91.
[27]Liu, P., Yuan, W., & Fu, J. et al. (2023). Pre-Train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing[J]. ACM Computing Surveys, 55(9):1-35.
[28]Lysakowski, R. S., & Walberg, H. J. (1982). Instructional Effects of Cues, Participation, and Corrective Feedback: A Quantitative Synthesis[J]. American Educational Research Journal, 19(4):559-572.
[29]Nelson, M. M., & Schunn, C. D. (2009). The Nature of Feedback: How Different Types of Peer Feedback Affect Writing Performance[J]. Instructional Science, 37(4):375-401.
[30]Sadler, D. R. (1989). Formative Assessment and the Design of Instructional Systems[J]. Instructional Science, 18(2):119-144.
[31]Sadler, T. D., & Fowler, S. R. (2006). A Threshold Model of Content Knowledge Transfer for Socioscientific Argumentation[J]. Science Education, 90(6):986-1004.
[32]Toulmin, S. E. (1958). The Uses of Argument[M]. London: Cambridge University Press:87-99.
[33]Van-Dijk, D., & Kluger, A. N. (2000). Positive (Negative) Feedback: Encouragement or Discouragement[EB/OL]. [2023-04-18].
https://scholars.huji.ac.il/testmihal/publications/gative-feedback-
encouragement-or-discouragement.
[34]Van Eemeren, F. H., Grootendorst, R., & Kruiger, T. (1987). Handbook of Argumentation Theory: A Critical Survey of Classical Backgrounds and Modern Studies[M]. Dordrecht: Springer:260-273.
[35]Voss, J. F., & Van Dyke, J. A. (2001). Argumentation in Psychology: Background Comments[J]. Discourse Processes, 32(2-3):89-111.
[36]White, J., Fu, Q., & Hays, S. et al. (2023). A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT[J/OL]. https://doi.org/10.48550/arXiv.2302.11382.
[37]Zeidler, D. L., Osborne, J., & Erduran, S. et al. (2003). The Role of Argument During Discourse About Socioscientific Issues[M]// Zeidler, D. L. (Ed.). The Role of Moral Reasoning on Socioscientific Issues and Discourse in Science Education. Dordrecht: Springer:97-116.
收稿日期 2023-04-19 責任編輯 譚明杰
Effectiveness of Feedback on StudentsArgumentation Contents Based on ChatGPT:
Comparison of Two Types of Prompt Designs
WANG Li, LI Yan, CHEN Xinya, XU Lingna
Abstract: In argumentative teaching, due to the large volume and high complexity of students argumentation contents, teachers evaluation and feedback often lag behind and are difficult to ensure the quality. The emergence of such chat tools based on generative artificial intelligence as ChatGPT provides the possibility to solve this problem. The quality of interaction with ChatGPT depends on the prompt design. How to design prompts becomes the key to obtaining effective feedback. Based on two types of prompt designs (“initial prompts”and“optimized prompt”), ChatGPT was used to evaluate and provide feedback on 50 copies of students argumentation contents. Empirical comparison was conducted on its effectiveness from two aspects: feedback accuracy and feedback type. It was found that ChatGPTs feedback accuracy (including precision rate and recall rate) under “optimized prompt” was much higher than that under “initial prompt”. The feedbacks recall rates under both types of prompt designs were lower than corresponding precision rates. The feedbacks precision rates of the quantitative evaluation dimension were higher than those of the qualitative evaluation dimension under both types of prompt designs. Based on the two types of prompt designs, ChatGPT could generate four kinds of feedback for argumentation contents: task-oriented feedback, process-oriented feedback, suggestion-oriented feedback, and emotion-oriented feedback. However, compared to feedback based on the“initial prompt”, the feedback generated based on “optimized prompt” was more organized, explanatory, and targeted. The emotion-oriented feedback under both types of prompt designs exhibits such characteristics as “confining merely to the facts” and “the doctrine of the mean”. To effectively unleash the potential of ChatGPT in teaching evaluation and feedback, teachers need to improve their prompt designs, leverage their advantages in emotion-oriented feedback, monitor feedback from ChatGPT and focus on cultivating students feedback literacy.
Keywords: ChatGPT; Teaching Evaluation; Teaching Feedback; Argumentative Teaching; Prompt Design
