支持重規(guī)劃的戰(zhàn)時(shí)保障動(dòng)態(tài)調(diào)度研究
2023-08-04 13:57:30李厚樸
自動(dòng)化學(xué)報(bào) 2023年7期
曾 斌 樊 旭 李厚樸
作為作戰(zhàn)力量的倍增器,后裝保障系統(tǒng)在現(xiàn)代戰(zhàn)場(chǎng)上扮演著非常重要的角色.它的主要功能是利用有限的保障資源,在最短時(shí)間內(nèi)及時(shí)高效地為前線部隊(duì)提供急需的作戰(zhàn)物質(zhì).在海上分布式殺傷和大規(guī)模登陸作戰(zhàn)等戰(zhàn)場(chǎng)背景下,由于遠(yuǎn)離本土作戰(zhàn),前進(jìn)基地或預(yù)置基地保障資源有限,在分布式協(xié)同作戰(zhàn)模式下,保障需求點(diǎn)增多,而且保障需求頻率也大幅提高.這種情況下,一個(gè)高效的戰(zhàn)時(shí)后裝保障系統(tǒng)需要解決的問(wèn)題包括:
1)當(dāng)作戰(zhàn)部隊(duì)發(fā)出保障需求時(shí),如何選擇合適的保障分隊(duì)處理該需求;
2)每一個(gè)保障基地需要分配多少保障分隊(duì)(負(fù)責(zé)投送作戰(zhàn)物質(zhì)或維修作戰(zhàn)裝備);
3)當(dāng)作戰(zhàn)部隊(duì)發(fā)出保障需求時(shí),如何選擇合適的保障分隊(duì)處理該需求;
4)當(dāng)保障分隊(duì)不夠時(shí),如果出現(xiàn)優(yōu)先級(jí)高的保障需求,能否中斷當(dāng)前保障任務(wù)重新規(guī)劃;
5)當(dāng)保障分隊(duì)完成任務(wù)后,如何根據(jù)當(dāng)前戰(zhàn)場(chǎng)態(tài)勢(shì)部署至更為優(yōu)化的地址.
以上問(wèn)題中,前3 個(gè)問(wèn)題已經(jīng)有較多研究并得到較好解決,例如,昝翔等[1]和何巖等[2]分別利用遺傳算法解決了維修任務(wù)-維修單元的指派,曹繼平等[3]給出了資源沖突時(shí)的優(yōu)化調(diào)度方案;曾斌等[4]利用混合Petri 網(wǎng)建立了流程模型并提出了基于退火進(jìn)化的保障單元調(diào)度算法,任帆等[5]指出巡回維修中“預(yù)測(cè)性”策略要優(yōu)于“最近修理組”策略,但沒(méi)有給出具體的預(yù)測(cè)算法.
而后2 個(gè)問(wèn)題可以看作前3 個(gè)問(wèn)題的延伸,即在給定一定數(shù)量預(yù)置保障基地及每個(gè)保障基地預(yù)分配了一定數(shù)量的保障分隊(duì)情況下,當(dāng)出現(xiàn)新的保障申請(qǐng)時(shí),如果當(dāng)前沒(méi)有空閑的保障分隊(duì),如何重分配保障任務(wù)及重部署保障分隊(duì).這一直以來(lái)也是后裝保障的一個(gè)老大難問(wèn)題,陳春良等[6]在研究展望中專(zhuān)門(mén)指出目前關(guān)于裝備維修任務(wù)調(diào)度的研究大多將其視為非搶占調(diào)度,易導(dǎo)致維修任務(wù)調(diào)度不合理、維修資源利用不充分等問(wèn)題,急需開(kāi)展搶占調(diào)度方向研究.
由于允許搶占拓展了解空間,所以需要尋優(yōu),而常規(guī)方法難以優(yōu)化裝備的搶占調(diào)度及重規(guī)劃,因此需要從智能化保障技術(shù)入手,只有能夠?qū)笱b保障與配屬情況進(jìn)行合理性預(yù)測(cè),才能制定魯棒性強(qiáng)的保障計(jì)劃與投送方案[7],從而能夠根據(jù)戰(zhàn)場(chǎng)環(huán)境變化,預(yù)見(jiàn)性地做出重規(guī)劃決策.
作為預(yù)測(cè)決策的關(guān)鍵技術(shù)之一,以馬爾科夫決策過(guò)程(Markov decision process,MDP)為基礎(chǔ)結(jié)構(gòu)的強(qiáng)化學(xué)習(xí)逐漸在智能化應(yīng)急服務(wù)中得到了應(yīng)用并取得顯著成果[8-9],包括: 救護(hù)車(chē)的調(diào)度[10]、醫(yī)療資源的分配[11-12]、災(zāi)后救援優(yōu)化策略[13-14]、戰(zhàn)場(chǎng)傷員的疏散方案[15]以及應(yīng)急電力系統(tǒng)的自適應(yīng)控制[16-17]等,這些研究給予本文以智能決策技術(shù)上的啟發(fā),但同樣也沒(méi)有解決重規(guī)劃問(wèn)題.
本文的思路如下: 首先建立戰(zhàn)時(shí)保障動(dòng)態(tài)調(diào)度問(wèn)題的MDP 模型;其次提出了該MDP 模型的求解方法.基于強(qiáng)化學(xué)習(xí)的試探-獎(jiǎng)勵(lì)-修正(策略迭代)自學(xué)習(xí)方式,生成不同保障需求事件下的狀態(tài)-動(dòng)作序列,以此作為樣本數(shù)據(jù)來(lái)訓(xùn)練保障調(diào)度神經(jīng)網(wǎng)絡(luò)模型.這樣在實(shí)戰(zhàn)過(guò)程中,當(dāng)戰(zhàn)場(chǎng)環(huán)境發(fā)生變化引發(fā)新的保障需求時(shí),不同的保障決策動(dòng)作將導(dǎo)致系統(tǒng)狀態(tài)發(fā)生改變,通過(guò)訓(xùn)練好的保障調(diào)度神經(jīng)網(wǎng)絡(luò)可以快速計(jì)算改變后狀態(tài)的價(jià)值,其中導(dǎo)致?tīng)顟B(tài)價(jià)值最大的決策即為最優(yōu)決策.
本文主要貢獻(xiàn)包括:
1)定義了支持重規(guī)劃的后裝保障動(dòng)態(tài)調(diào)度問(wèn)題,建立了支持重規(guī)劃(搶占調(diào)度、重分配及重部署)決策的MDP 模型和求解算法;
2)在重規(guī)劃MDP 模型中綜合考量了任務(wù)排隊(duì)、保障優(yōu)先級(jí)以及油料約束等問(wèn)題的影響;
3)為了解決重規(guī)劃MDP 模型狀態(tài)動(dòng)作空間過(guò)大引起的“維度災(zāi)”問(wèn)題,借鑒了深度學(xué)習(xí)思想[18],提出利用神經(jīng)網(wǎng)絡(luò)對(duì)基函數(shù)進(jìn)行非線性組合,從而逼近MDP 值函數(shù),降低了計(jì)算復(fù)雜度;
4)采用決策后狀態(tài)思想[19]降低了隨機(jī)事件引起的計(jì)算復(fù)雜度.
1 馬爾科夫決策模型
1.1 狀態(tài)空間
MDP 的狀態(tài)設(shè)計(jì)非常重要,如果維度過(guò)大會(huì)影響求解算法的收斂,過(guò)小則可能不足以用來(lái)描述系統(tǒng)的決策函數(shù)、狀態(tài)轉(zhuǎn)移函數(shù)以及獎(jiǎng)勵(lì)函數(shù).本文設(shè)計(jì)保障系統(tǒng)的狀態(tài)S(t,e,M,R),其中,t為當(dāng)前時(shí)間,e表示當(dāng)前事件類(lèi)型,M為列表類(lèi)型,表示各個(gè)保障分隊(duì)的所處狀態(tài),R為列表類(lèi)型,表示當(dāng)前待處理的各個(gè)保障需求的狀況.
1.1.1 事件類(lèi)型
系統(tǒng)狀態(tài)隨著事件的產(chǎn)生而變化,為此本文定義7 種事件類(lèi)型,即e(S)1,2,···,7}.e(S)1表示產(chǎn)生了保障需求需要處理;e(S)2 表示保障分隊(duì)到達(dá)保障倉(cāng)庫(kù) (如果保障倉(cāng)庫(kù)與保障分隊(duì)處于同一保障基地,則不用產(chǎn)生此事件);e(S)3 表示保障分隊(duì)在保障倉(cāng)庫(kù)領(lǐng)取到本次任務(wù)需要的物質(zhì)或備品備件;e(S)4表示保障分隊(duì)到達(dá)需求點(diǎn);e(S)5表示保障分隊(duì)完成當(dāng)前保障任務(wù);e(S)6 表示保障分隊(duì)返回保障基地;e(S)7 表示有保障分隊(duì)處于待命狀態(tài).
1.1.2 保障分隊(duì)狀態(tài)
保障分隊(duì)狀態(tài)列表表示為:M[Mm]m∈M′[M1,M2,···],其中,M′{1,2,···},表示系統(tǒng)中所有保障分隊(duì)集合,列表中每個(gè)組成元素都為一個(gè)數(shù)組,可表示為
1.1.3 保障需求狀態(tài)
保障需求狀態(tài)列表可表示為:R[Rr]r∈R′[R1,R2,···],其中,R′{1,2,···},表示保障需求隊(duì)列中待處理的所有保障需求集合,列表中每個(gè)組成元素都為一個(gè)數(shù)組,可表示為
如果當(dāng)前沒(méi)有保障需求,Rr(0,0,0,0,0);如果某個(gè)保障需求已被完成,則該需求將會(huì)移出隊(duì)列.另外保障隊(duì)列中等待的需求有一個(gè)最大閾值rmax|R′|,它表示保障系統(tǒng)能夠支持的保障需求最大數(shù)量.
以上狀態(tài)相對(duì)獨(dú)立,可以假設(shè)其滿足馬爾科夫過(guò)程無(wú)后效性性質(zhì).其中時(shí)間狀態(tài)即指當(dāng)前的時(shí)刻,因?yàn)檩^簡(jiǎn)單,可以忽略.
1.2 決策空間
1.2.1 決策變量
為了描述決策空間,首先定義如下集合.
1)B{1,2,···,|B|}表示保障基地集合;
2)Q(S){r:′,0}表示當(dāng)系統(tǒng)狀態(tài)為S時(shí),在隊(duì)列中等待分派保障分隊(duì)處理的保障需求集合;
3)A1(S){m:′,1,6,7,8}}表示當(dāng)系統(tǒng)狀態(tài)為S時(shí),可以分派執(zhí)行保障任務(wù)的保障分隊(duì)集合;
4)A2(S){m:′,2,3}}表示當(dāng)系統(tǒng)狀態(tài)為S時(shí),可以重規(guī)劃保障任務(wù)的保障分隊(duì)集合;
5)A3(S){m:′,6}表示當(dāng)系統(tǒng)狀態(tài)為S時(shí),可以重部署的保障分隊(duì)集合.
本文中決策變量設(shè)計(jì)為3 個(gè)布爾變量,定義如下:
1)Xmr1表示第m支保障分隊(duì)被分派執(zhí)行保障需求r,否則為0;
2)Ymr1表示第m支保障分隊(duì)被命令中斷當(dāng)前保障任務(wù),重規(guī)劃執(zhí)行新的保障任務(wù)r,否則為0;
3)Zmb1表示第m支保障分隊(duì)被重部署至保障基地b,否則為0.
1.2.2 決策約束
決策約束分以下4 種情況討論.
情況 1.當(dāng)Q(S)?(存在待處理保障需求) 且發(fā)生事件類(lèi)型為e(S)1,2,3,4,6,7}時(shí),保障指揮人員需要執(zhí)行2 個(gè)決策: 分派任務(wù)和重規(guī)劃任務(wù).其中,分派任務(wù)負(fù)責(zé)分派哪一個(gè)保障分隊(duì)執(zhí)行隊(duì)列中等待處理的保障任務(wù);當(dāng)沒(méi)有可用保障分隊(duì)且出現(xiàn)高優(yōu)先級(jí)任務(wù)時(shí),由重規(guī)劃任務(wù)決定中斷哪一個(gè)保障分隊(duì)的當(dāng)前任務(wù),轉(zhuǎn)去執(zhí)行新的保障任務(wù).
這種情況下存在如下5 種決策約束:
1)約束一個(gè)任務(wù)只需要一支分隊(duì)處理,如果需要多支分隊(duì)處理一個(gè)任務(wù),可以組合成一個(gè)分隊(duì),或放松此約束,即
2)約束一支保障分隊(duì)一次只能分派執(zhí)行一個(gè)保障任務(wù),如果需要一支分隊(duì)一次執(zhí)行多個(gè)保障任務(wù)時(shí),可以把一個(gè)保障分隊(duì)分解為多支分隊(duì),或放松此約束,即
3)約束一支保障分隊(duì)一次只能重規(guī)劃執(zhí)行一個(gè)保障任務(wù),即
4)約束保障分隊(duì)一次只能分派執(zhí)行或重規(guī)劃執(zhí)行剩余油料距離之內(nèi)的保障任務(wù),設(shè)dmr表示保障支隊(duì)m與需求點(diǎn)r之間的距離,即
設(shè)分派調(diào)度決策列表為
設(shè)重規(guī)劃決策列表為
情況1 下的決策空間表述為
情況 2.當(dāng)Q(S)?(不存在待處理保障需求)且發(fā)生事件類(lèi)型為e(S)5 (有保障分隊(duì)完成當(dāng)前保障任務(wù)) 時(shí),保障指揮人員需要決策保障分隊(duì)m的重部署地點(diǎn).注意此時(shí)A3(S){m}.設(shè)dmb為保障分隊(duì)m到基地b的距離,Imb為指示函數(shù),如果保障分隊(duì)m剩余油料可以到達(dá)某基地b,則為1,否則為0,其表達(dá)式為
因此,有決策約束式為
該約束表示每一個(gè)保障分隊(duì)只能部署到一個(gè)保障基地.設(shè)該情況下重部署決策列表為
情況2 下的決策空間表述為
情況 3.當(dāng)Q(S)?(存在待處理保障需求) 且發(fā)生事件類(lèi)型為e(S)5 (有保障分隊(duì)完成當(dāng)前保障任務(wù)) 時(shí),保障指揮人員可以選擇以下3 種決策:
1)分派任務(wù): 分派哪一個(gè)保障分隊(duì)執(zhí)行隊(duì)列中等待處理的保障任務(wù);
2)重規(guī)劃任務(wù): 中斷哪一個(gè)保障分隊(duì)的當(dāng)前任務(wù),重安排其執(zhí)行新的保障任務(wù);
3)重部署保障分隊(duì): 如果保障分隊(duì)m沒(méi)有分派執(zhí)行隊(duì)列中等待處理的保障需求,重部署m到哪一個(gè)基地.
注意此時(shí)有A3(S){m}.約束表示為
約束(7)表示如果存在可重部署的保障分隊(duì),且其沒(méi)有分派執(zhí)行隊(duì)列中的保障需求,則只能將它重部署到最多一個(gè)保障基地.此時(shí)決策空間表示為
情況 4.如果沒(méi)有出現(xiàn)以上事件,也沒(méi)有發(fā)生以上3 種情況,則約束空間D4?.
1.3 狀態(tài)轉(zhuǎn)移
設(shè)第k個(gè)事件發(fā)生時(shí)保障系統(tǒng)所處狀態(tài)為Sk,保障系統(tǒng)通過(guò)決策動(dòng)作dk使得系統(tǒng)狀態(tài)從Sk演進(jìn)到Sk+1,并設(shè)隨機(jī)元素W(Sk,dk)表示系統(tǒng)處于Sk+1時(shí)發(fā)生的隨機(jī)事件信息,整個(gè)保障系統(tǒng)的演進(jìn)動(dòng)力模型可以表示為
式中,ST表示狀態(tài)遷移函數(shù).
1.4 獎(jiǎng)勵(lì)函數(shù)
按照MDP 模型,當(dāng)有保障分隊(duì)調(diào)度 (分派或重規(guī)劃) 執(zhí)行保障任務(wù)時(shí),該決策行為將會(huì)獲得獎(jiǎng)勵(lì).獎(jiǎng)勵(lì)值的設(shè)計(jì)也是影響強(qiáng)化學(xué)習(xí)能力的重要因素,本文保障系統(tǒng)中需求優(yōu)先級(jí)、期望保障時(shí)間以及需求產(chǎn)生時(shí)刻等因素都會(huì)影響決策動(dòng)作的獎(jiǎng)勵(lì)值.設(shè)C(Sk,dk)表示在系統(tǒng)處于狀態(tài)Sk時(shí),如果采取決策dk將會(huì)獲得的立即獎(jiǎng)勵(lì)值,它的計(jì)算式設(shè)計(jì)為
1.5 目標(biāo)函數(shù)及優(yōu)化方程
基于給定策略π(一系列決策的組合),Dπ(Sk)(Sk)為從狀態(tài)空間到?jīng)Q策空間的決策函數(shù),用以指導(dǎo)在狀態(tài)Sk下采取策略dk.MDP 模型的目的也就是從所有可行策略中計(jì)算得到優(yōu)化策略π*,從而最大化系統(tǒng)的長(zhǎng)遠(yuǎn)回報(bào).因此,系統(tǒng)目標(biāo)函數(shù)為
式中,γ為一個(gè)固定的折扣因子,為了便于計(jì)算,Bellman 優(yōu)化方程利用迭代方式計(jì)算目標(biāo)函數(shù),其表達(dá)式為
式中,V(Sk)為狀態(tài)Sk的值函數(shù).
2 求解算法
由于維度災(zāi)(式(11)的狀態(tài)空間維度過(guò)大)的影響,利用常規(guī)動(dòng)態(tài)規(guī)劃方法無(wú)法取得式(11)的精確解.為此,本文采用近似動(dòng)態(tài)規(guī)劃[20]的方法逼近式(11)的值函數(shù).
2.1 隨機(jī)事件的計(jì)算
另外,式(11)中還需要對(duì)期望值E[V(Sk+1)|Sk,dk]求極值,不僅計(jì)算量巨大而且會(huì)帶來(lái)較大的統(tǒng)計(jì)誤差,為此本文采用決策后狀態(tài)思想[21-22],將先求期望值后求極值問(wèn)題轉(zhuǎn)換為先求極值后求期望值問(wèn)題,從而降低了計(jì)算量和誤差.該思想在前后兩個(gè)狀態(tài)之間 (Sk和Sk+1) 引入了一個(gè)中間狀態(tài),即決策后狀態(tài)該狀態(tài)在決策發(fā)生后事件發(fā)生前出現(xiàn),屬于確定性狀態(tài),因此,原來(lái)式(8)的一步狀態(tài)轉(zhuǎn)移轉(zhuǎn)換為兩步,即
其中,ST,x為確定性函數(shù),ST,x和ST,w組合后與式(8)的ST等價(jià).設(shè)決策后狀態(tài)的價(jià)值為
將式(12)代入式(11),優(yōu)化方程修改為
下面進(jìn)一步討論式(13)決策后狀態(tài)價(jià)值的計(jì)算,由于式(12)為迭代過(guò)程,可以有
式(13)代入式(14)右邊,引入決策后狀態(tài)價(jià)值的優(yōu)化方程可表示為
2.2 基函數(shù)的設(shè)計(jì)
盡管式(15)通過(guò)引入決策后狀態(tài)變量減小了隨機(jī)事件帶來(lái)的計(jì)算復(fù)雜性和統(tǒng)計(jì)誤差,但是對(duì)于式(15)而言,復(fù)雜的狀態(tài)空間導(dǎo)致的維度災(zāi)問(wèn)題仍然存在.為此,本文通過(guò)構(gòu)造基函數(shù)捕捉?jīng)Q策后狀態(tài)的特征,再以基函數(shù)為基礎(chǔ)來(lái)設(shè)計(jì)近似函數(shù)以便逼近式(15)表示的價(jià)值函數(shù).這里基函數(shù)的設(shè)計(jì)尤為重要[23-24],關(guān)系到最后近似價(jià)值函數(shù)的求解質(zhì)量.為此本文設(shè)計(jì)了6 種基函數(shù),通過(guò)它們的非線性組合(參見(jiàn)第2.3 節(jié)的神經(jīng)網(wǎng)絡(luò))來(lái)表示價(jià)值函數(shù).設(shè)φf(shuō)()表示基函數(shù),f為基函數(shù)特征,f.
1)第1 種基函數(shù)直接表示保障分隊(duì)狀態(tài),數(shù)量為|M′|,計(jì)算式為
2)第2 種基函數(shù)捕捉保障分隊(duì)執(zhí)行保障任務(wù)(服務(wù)-客戶對(duì))的期望服務(wù)時(shí)間,數(shù)量為|M′|.設(shè)Imr為指示函數(shù),如果保障分隊(duì)m當(dāng)前執(zhí)行的保障任務(wù)為r,則為1,否則為0,計(jì)算式為
3)第3 種基函數(shù)捕捉保障分隊(duì)執(zhí)行保障任務(wù)的優(yōu)先級(jí),數(shù)量為|M′|,計(jì)算式為
4)第4 種基函數(shù)捕捉當(dāng)前在隊(duì)列中等待處理的保障需求優(yōu)先級(jí),數(shù)量為|R′|,計(jì)算式為
5)第5 種基函數(shù)捕捉每一個(gè)需求在系統(tǒng)中的逗留時(shí)間,數(shù)量為|R′|,計(jì)算式為
6)第6 種基函數(shù)捕捉每一個(gè)保障分隊(duì)與保障申請(qǐng)點(diǎn)的距離,數(shù)量為|M′|×|R′|,該基函數(shù)結(jié)合保障分隊(duì)的狀態(tài)可以知道哪一個(gè)保障分隊(duì)有足夠油料分派或重規(guī)劃到某需求點(diǎn),其計(jì)算式為
2.3 神經(jīng)網(wǎng)絡(luò)的設(shè)計(jì)
由于保障系統(tǒng)狀態(tài)空間和決策空間較為復(fù)雜,常規(guī)線性基函數(shù)組合的效果將會(huì)因此受到較大影響.所以本文以基函數(shù)的輸出結(jié)果作為神經(jīng)網(wǎng)絡(luò)輸入,即利用神經(jīng)網(wǎng)絡(luò)對(duì)基函數(shù)進(jìn)行非線性組合[25],從而達(dá)到逼近式(15)值函數(shù)的目的.
為了使學(xué)習(xí)后的神經(jīng)網(wǎng)絡(luò)能夠近似表達(dá)值函數(shù),本文設(shè)計(jì)了3 層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu): 輸入層、隱藏層和輸出層.如圖1 所示,輸入層包含|F| 個(gè)輸入,它的值為基函數(shù)的輸出,如圖1 中?1,1表示第1 類(lèi)基函數(shù)的第1 個(gè)函數(shù)輸出值,輸入節(jié)點(diǎn)個(gè)數(shù)為6 類(lèi)基函數(shù)的總個(gè)數(shù),輸入層沒(méi)有激活單元.為了減小基函數(shù)評(píng)估值的波動(dòng),幫助神經(jīng)網(wǎng)絡(luò)反向傳播算法能夠快速找到權(quán)重矩陣,在輸入到輸入層之前,本文對(duì)基函數(shù)評(píng)估值進(jìn)行了均值歸一化.
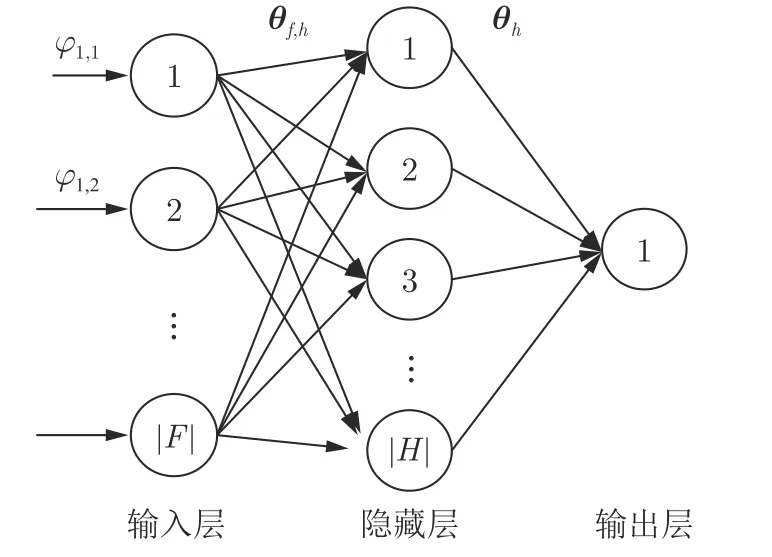
圖1 神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)示例Fig.1 Illustration of neural network structure
隱藏層包括H{1,2,···,|H|}個(gè)神經(jīng)元,其個(gè)數(shù)|H| 為超參數(shù),所以隱藏層的輸入表達(dá)式為
式中,Ih表示隱藏層中第h個(gè)神經(jīng)元的輸入,θf(wàn),h為|F|×|H| 的權(quán)重矩陣,控制輸入層到隱藏層的映射關(guān)系,隱藏層神經(jīng)元的激活函數(shù)為sigmoid 函數(shù),表示為
因此,隱藏層的輸出表達(dá)式為
其中,Oh為第h個(gè)神經(jīng)元的輸出,|H| 個(gè)隱藏層神經(jīng)元輸出與輸出層權(quán)重組合生成輸出層的輸入,其表達(dá)式為
式中,θh為|H|×1 的權(quán)重矩陣,控制隱藏層到輸出層的映射關(guān)系,輸出層只有一個(gè)神經(jīng)元,激活函數(shù)與隱藏層的相同,也為sigmoid 函數(shù),其表達(dá)式為
式中,θ(θf(wàn),h,θh) 為神經(jīng)網(wǎng)絡(luò)中需要學(xué)習(xí)的權(quán)重參數(shù).
2.4 神經(jīng)網(wǎng)絡(luò)權(quán)重學(xué)習(xí)算法的設(shè)計(jì)
本文設(shè)計(jì)了基于強(qiáng)化學(xué)習(xí)策略迭代[26]的神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)算法,如圖2 所示,算法分為2 層循環(huán),第1 層循環(huán)(內(nèi)層循環(huán))為策略評(píng)估,利用給定策略(上一次循環(huán)更新的神經(jīng)網(wǎng)絡(luò)),在模擬產(chǎn)生的事件驅(qū)動(dòng)下,生成動(dòng)態(tài)演進(jìn)的狀態(tài)價(jià)值并作為樣本點(diǎn)保存;第2 層循環(huán)(外層循環(huán))為策略改進(jìn),利用內(nèi)層循環(huán)保存的樣本點(diǎn)改進(jìn)神經(jīng)網(wǎng)絡(luò)的權(quán)重矩陣.
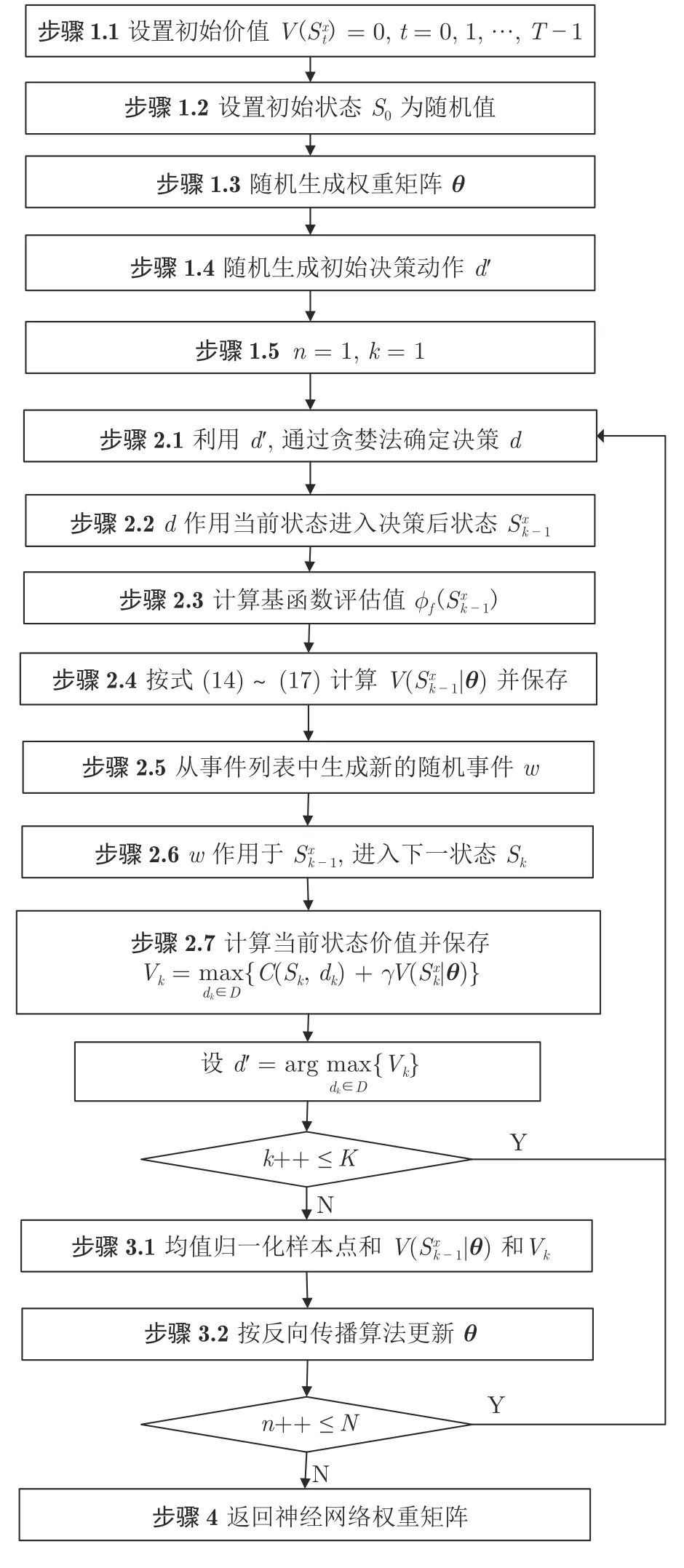
圖2 策略迭代算法流程Fig.2 Workflow of policy iteration algorithm
策略迭代算法外循環(huán)每次進(jìn)行策略改進(jìn)時(shí)都需要調(diào)用神經(jīng)網(wǎng)絡(luò)反向傳播算法對(duì)權(quán)重參數(shù)進(jìn)行訓(xùn)練,為了防止出現(xiàn)過(guò)擬合和泛化誤差,本文在神經(jīng)網(wǎng)絡(luò)代價(jià)函數(shù)中加入了懲罰項(xiàng),即
其中,K個(gè)樣本點(diǎn)中,在步驟2.4 中存儲(chǔ),為神經(jīng)網(wǎng)絡(luò)估算值;Vk在步驟2.7 中存儲(chǔ),為標(biāo)簽值;正則化參數(shù)η用于平衡模型復(fù)雜度和邊際誤差.本文采用了自適應(yīng)預(yù)估方法來(lái)計(jì)算合適的η值,計(jì)算式為
式中,v為樣本數(shù)據(jù)的均值,σv為樣本數(shù)據(jù)的標(biāo)準(zhǔn)差.
需要計(jì)算得到θ*值,使得代價(jià)函數(shù)最小,即θ*argmin{L(θ)}.為了提高計(jì)算速度,本文采用擬牛頓法求解,擬牛頓法需要的梯度信息可以利用神經(jīng)網(wǎng)絡(luò)的反向傳播算法計(jì)算得到.
為了平滑θ權(quán)重矩陣,本文采用式(20) 來(lái)更新θ:
其中,an1/nβ,β(0.3,1],an的下標(biāo)值n與策略改進(jìn)外循環(huán)次數(shù)n一致,通過(guò)an控制θ值,在歷史值 (θ)與新估計(jì)值 (θ*) 之間取得平衡.隨著策略改進(jìn)迭代次數(shù)n的增加,本算法越來(lái)越偏重于過(guò)去n-1 次迭代得到的歷史值.
在策略迭代算法的每一次外循環(huán) (策略改進(jìn))中,都會(huì)按式(18)對(duì)神經(jīng)網(wǎng)絡(luò)的權(quán)重進(jìn)行更新,如果n<N,則算法開(kāi)始下一輪循環(huán).算法中可調(diào)節(jié)參數(shù)包括N、K、|H|、η和β,其中,N為策略改進(jìn)的迭代次數(shù),K為策略評(píng)估的迭代次數(shù),|H| 為隱藏層節(jié)點(diǎn)的個(gè)數(shù),η是樣本估計(jì)的正則化項(xiàng),β是步長(zhǎng)參數(shù).
2.5 調(diào)度算法的使用時(shí)機(jī)及步驟
建立的神經(jīng)網(wǎng)絡(luò)模型可以看作一個(gè)具有預(yù)測(cè)能力的調(diào)度機(jī).其使用時(shí)機(jī)為: 當(dāng)戰(zhàn)場(chǎng)態(tài)勢(shì)變化,例如出現(xiàn)新的保障申請(qǐng),如第1.1 節(jié)描述的當(dāng)前系統(tǒng)狀態(tài)隨之改變.使用步驟如下:
1)在第1.2.2 節(jié)描述的決策約束下,生成各種可能的決策動(dòng)作;
2) 按第1.3 節(jié)狀態(tài)轉(zhuǎn)移矩陣,基于當(dāng)前狀態(tài),采取步驟1)生成的各種可能的決策動(dòng)作,形成下一步狀態(tài)集合S;
3)將下一步狀態(tài)集合中的每一個(gè)狀態(tài)作為第2.2 節(jié)敘述的基函數(shù)輸入,基函數(shù)的輸出為第1 階段的線性預(yù)測(cè)值,用于降低計(jì)算復(fù)雜性;
4)為了具有非線性預(yù)測(cè)能力,如圖1 所示,基函數(shù)的輸出作為神經(jīng)網(wǎng)絡(luò)模型的輸入,此時(shí)神經(jīng)網(wǎng)絡(luò)的輸出為下一步狀態(tài)的價(jià)值V(S),該價(jià)值為第2.4 節(jié)Bellman 方程迭代計(jì)算的 “期望” 價(jià)值;
5)當(dāng)狀態(tài)集合S中的每一個(gè)狀態(tài)都經(jīng)過(guò)步驟3)和步驟4),計(jì)算出相應(yīng)期望價(jià)值后(該過(guò)程可以并行執(zhí)行),導(dǎo)致下一步狀態(tài)價(jià)值最大的決策可看作當(dāng)前最優(yōu)決策.
3 實(shí)驗(yàn)驗(yàn)證
本節(jié)通過(guò)一個(gè)分布式戰(zhàn)場(chǎng)保障場(chǎng)景來(lái)驗(yàn)證動(dòng)態(tài)調(diào)度算法的適用性.由于MDP 求解算法超參數(shù)較多,通過(guò)實(shí)驗(yàn)設(shè)計(jì)測(cè)試了不同參數(shù)設(shè)置對(duì)動(dòng)態(tài)算法的影響,并比較了動(dòng)態(tài)算法與兩個(gè)比對(duì)策略的性能差異.
3.1 實(shí)驗(yàn)參數(shù)設(shè)置
本文以圖3 所示的一個(gè)典型的分布式作戰(zhàn)行動(dòng)為背景,當(dāng)交戰(zhàn)區(qū)域中我方部隊(duì)發(fā)出保障申請(qǐng)后,使用上文提出的數(shù)學(xué)模型及逼近算法計(jì)算調(diào)度結(jié)果,即決定是否接受該申請(qǐng),如果接受該申請(qǐng),分派哪一支分隊(duì)處理.出于安全考慮,刪除了圖3 的背景地圖,圖3 中有2 個(gè)保障基地和2 個(gè)前進(jìn)基地,與保障基地相比,前進(jìn)基地較小,當(dāng)沒(méi)有申請(qǐng)所需物資裝備時(shí),需要從保障基地補(bǔ)充.圖3 中還包括54 個(gè)交戰(zhàn)地點(diǎn),即保障申請(qǐng)點(diǎn),分屬12 個(gè)區(qū)域,由其發(fā)出保障申請(qǐng).
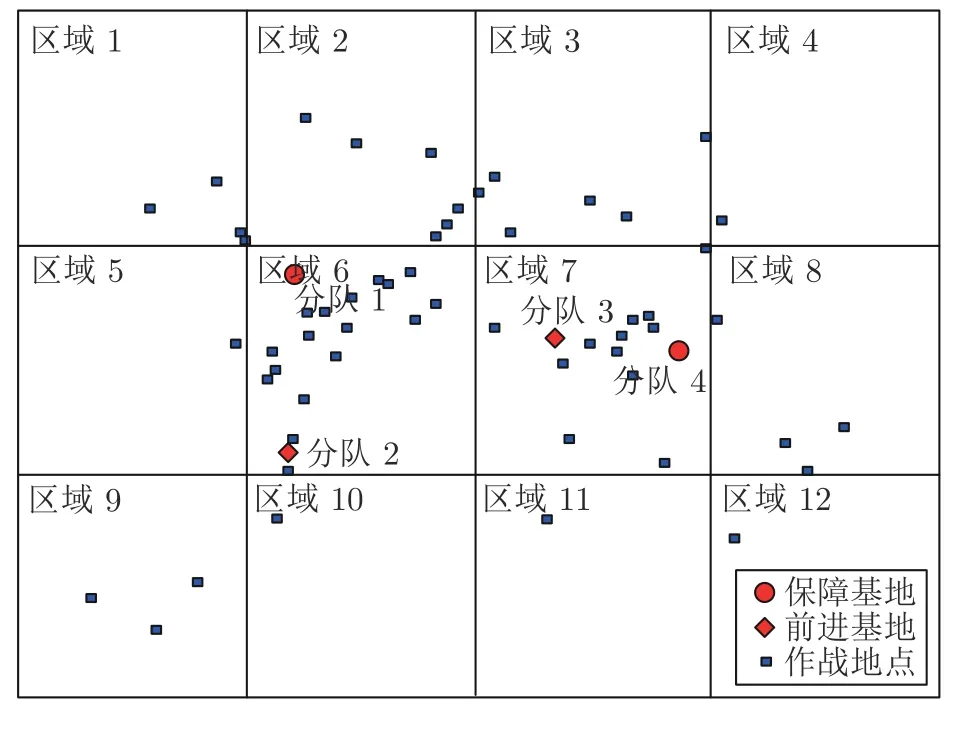
圖3 實(shí)驗(yàn)案例Fig.3 Experiment case
本文使用泊松分布生成保障需求的產(chǎn)生概率,為了能夠接近實(shí)戰(zhàn)背景,泊松分布的到達(dá)率參數(shù)由式(21)生成,即
式中,λ為保障申請(qǐng)發(fā)生率;pz為條件概率,表示當(dāng)發(fā)生保障申請(qǐng)時(shí),該申請(qǐng)是從交戰(zhàn)區(qū)域z發(fā)出的概率;pkz為條件概率,表示當(dāng)出現(xiàn)保障申請(qǐng)且該申請(qǐng)從交戰(zhàn)區(qū)域z發(fā)出時(shí),該申請(qǐng)優(yōu)先級(jí)為k的概率.實(shí)驗(yàn)中保障申請(qǐng)發(fā)生率λ設(shè)為1/45,即平均每隔45 min發(fā)出一個(gè)保障申請(qǐng),請(qǐng)求保障分隊(duì)執(zhí)行任務(wù).為了集中反映系統(tǒng)的調(diào)度能力,條件概率pkz中緊急保障和一般保障的比例為0.8和0.2.式(9)中緊急保障的優(yōu)先級(jí)權(quán)重為0.9,一般保障的權(quán)重為0.1,式(10)中折扣因子γ在實(shí)驗(yàn)中設(shè)為0.99,該設(shè)置使得系統(tǒng)重視未來(lái)事件的影響.
為了檢驗(yàn)動(dòng)態(tài)算法的性能,實(shí)驗(yàn)設(shè)計(jì)了2 個(gè)比對(duì)策略.比對(duì)策略A 采用常規(guī)的最近分配原則,該策略認(rèn)為當(dāng)前沒(méi)有執(zhí)行任務(wù)的保障分隊(duì)為可用資源,當(dāng)出現(xiàn)保障申請(qǐng)時(shí),分配離該申請(qǐng)點(diǎn)(交戰(zhàn)區(qū)域)最近的可用分隊(duì)執(zhí)行此項(xiàng)保障任務(wù),比對(duì)策略A 不具備搶占調(diào)度能力.比對(duì)策略B 將比對(duì)策略A 進(jìn)行了擴(kuò)展,當(dāng)出現(xiàn)優(yōu)先級(jí)更高的保障申請(qǐng)時(shí),允許其搶占其他保障分隊(duì)當(dāng)前執(zhí)行的低優(yōu)先級(jí)任務(wù).兩個(gè)比對(duì)策略使用的都是最近分配原則,該原則實(shí)際上只考慮當(dāng)前的立即獎(jiǎng)勵(lì)進(jìn)行決策(與式(9)相似),沒(méi)有用到預(yù)測(cè)的未來(lái)信息(式(10)).另外,由于立即獎(jiǎng)勵(lì)沒(méi)有考慮重部署決策,所以這兩個(gè)比對(duì)策略都不具備重部署能力.
3.2 超參數(shù)調(diào)整
本文采用了全因子實(shí)驗(yàn)設(shè)計(jì)來(lái)檢驗(yàn)不同的超參數(shù)對(duì)算法性能的影響,主要超參數(shù)設(shè)置如下: 策略改進(jìn)迭代次數(shù)N{1,2,···,40},策略評(píng)估迭代次數(shù)K{500,1 000,2 000,4 000},步長(zhǎng)參數(shù)β{0.3,0.5,0.7,0.9},隱藏層節(jié)點(diǎn)數(shù)|H|7,正則化項(xiàng)η采用自適應(yīng)預(yù)估方法計(jì)算.為了能夠得到合理的置信度,每一個(gè)組合運(yùn)行100 遍仿真,每次仿真時(shí)長(zhǎng)為1 000 min 以上.仿真實(shí)驗(yàn)結(jié)果如表1 所示,其中,性能相對(duì)改進(jìn)量計(jì)算式為
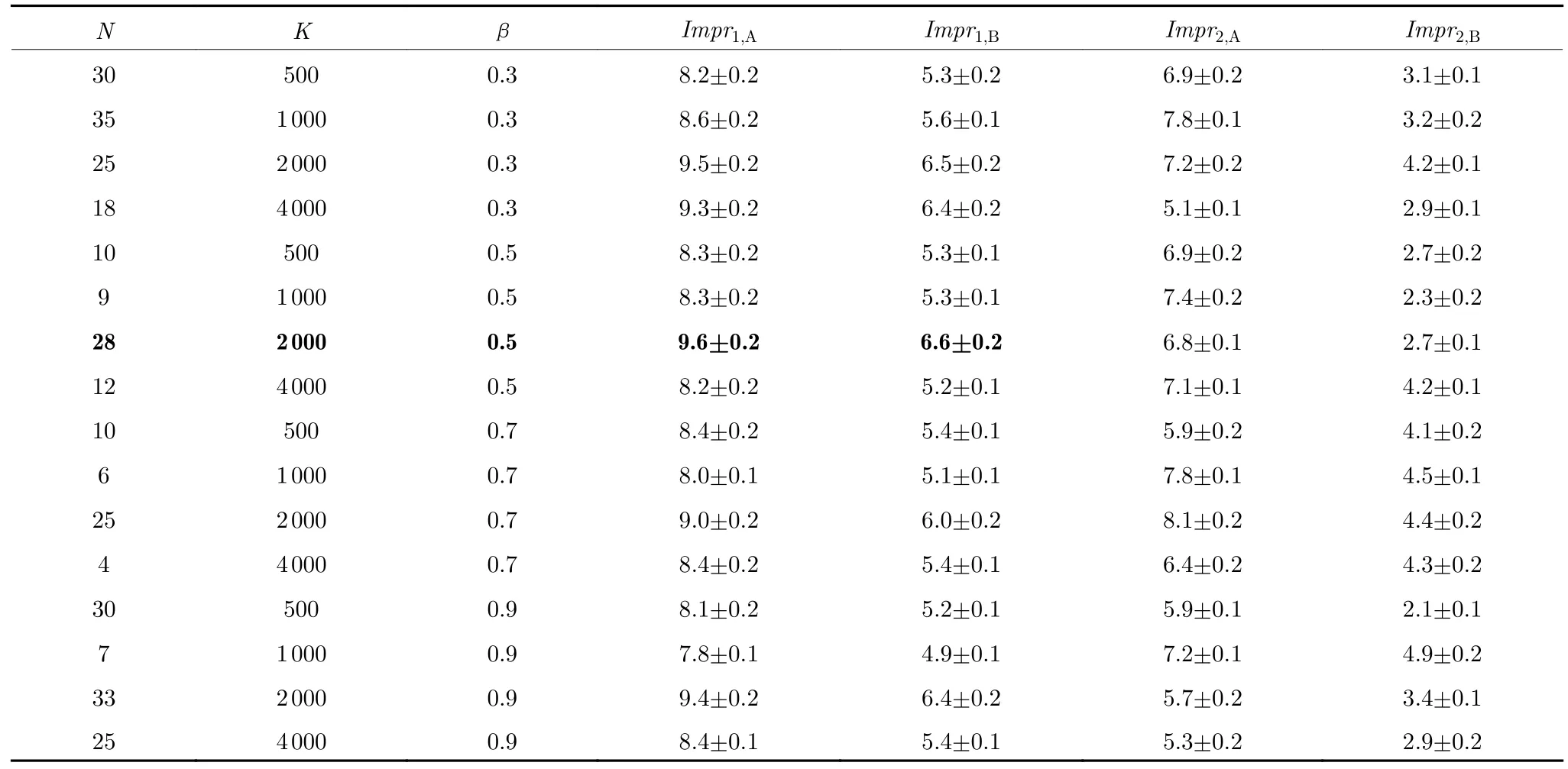
表1 仿真實(shí)驗(yàn)結(jié)果Table 1 Simulation results
其中,Vi為采用i算法計(jì)算得到的價(jià)值,Vj為采用j算法計(jì)算得到的價(jià)值,表1 中Impr1,A和Impr1,B分別為本文基于神經(jīng)網(wǎng)絡(luò)的動(dòng)態(tài)算法相較于比對(duì)策略A和策略B 得到的性能相對(duì)改進(jìn)量.
另外,為了考量神經(jīng)網(wǎng)絡(luò)模型的性能,設(shè)計(jì)了基函數(shù)的線性回歸模型作為比較算法,Impr2,A和Impr2,B分別為線性回歸模型相較于比對(duì)策略A和策略B 得到的性能相對(duì)改進(jìn)量.表1 中仿真結(jié)果數(shù)據(jù)的置信度都為95%.
表1 中左邊3 列為仿真實(shí)驗(yàn)中設(shè)置的算法參數(shù)組合,為了節(jié)省篇幅,其中N值只取 (K,β) 因子組合中算法性能最大的取值,其他4 列表示動(dòng)態(tài)算法相較于兩個(gè)比對(duì)策略的總獎(jiǎng)勵(lì)回報(bào) (式(15)) 的提高率,取置信度為95%的置信區(qū)間.從表1 中可以看出,當(dāng)λ1/45 時(shí),無(wú)論哪一種參數(shù)組合,重規(guī)劃動(dòng)態(tài)調(diào)度算法生成的方案都要優(yōu)于比對(duì)策略,特別是當(dāng)N28,K2 000,β0.5 時(shí) (表1 中粗體字所示) 效果最好.另外,近似函數(shù)為神經(jīng)網(wǎng)絡(luò)模型時(shí),調(diào)度性能要明顯超過(guò)基于線性回歸模型的近似函數(shù),這主要是因?yàn)檎{(diào)度算法中用基函數(shù)表示的影響因素相互交織,呈非線性關(guān)系,所以用神經(jīng)網(wǎng)絡(luò)擬合效果較好.
3.3 性能指標(biāo)比較測(cè)試
圖4 顯示了策略評(píng)估迭代次數(shù)K2 000 時(shí),無(wú)論步長(zhǎng)參數(shù)β取何值,相較于比對(duì)策略A,動(dòng)態(tài)調(diào)度算法的性能都為最佳值.當(dāng)K在增加到2 000前,動(dòng)態(tài)算法的性能逐漸提高;當(dāng)大于2 000 后,性能開(kāi)始下降;在4 000 次迭代時(shí)性能明顯下降.主要原因是在K4 000 時(shí),本仿真實(shí)驗(yàn)的樣本數(shù)據(jù)集增加到一定閾值,導(dǎo)致神經(jīng)網(wǎng)絡(luò)模型過(guò)擬合,從而產(chǎn)生低效率的調(diào)度結(jié)果.另外,從表1和圖4 都可以看出,β取較小值 (0.3 或0.5) 時(shí),算法收斂速度較慢,能夠增加算法的調(diào)度效果.
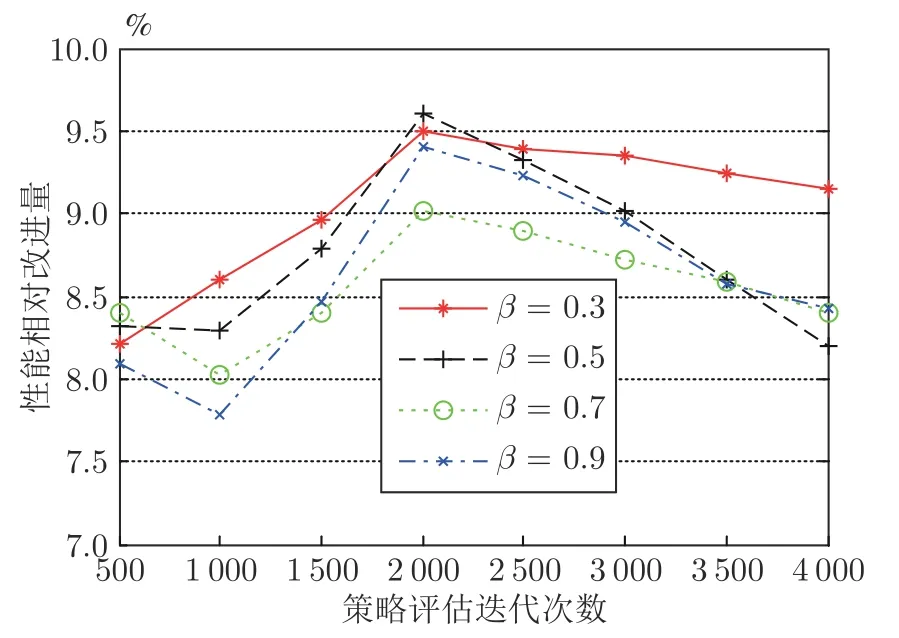
圖4 相較于比對(duì)策略A 的性能改進(jìn)Fig.4 Improvement compared to policy A
表2 的第1 列為調(diào)度策略;第2 列和第3 列分別為當(dāng)N28,K2 000,β0.5 時(shí),不同優(yōu)先級(jí)的保障申請(qǐng)響應(yīng)時(shí)間 (從發(fā)出申請(qǐng)至保障分隊(duì)到達(dá)的時(shí)間間隔) 的置信區(qū)間 (置信度為95%);第4 列為調(diào)度方案V值提高百分比的置信區(qū)間.從表2 可以看出,具備搶占調(diào)度能力的策略B和動(dòng)態(tài)調(diào)度算法都比不具備搶占能力的策略A 性能好,另外還有一個(gè)現(xiàn)象也需要引起注意,隨著第4 列顯示的性能提高,在緊急保障申請(qǐng)的響應(yīng)時(shí)間減少的同時(shí),一般保障申請(qǐng)的響應(yīng)時(shí)間卻在增加.估計(jì)這與搶占調(diào)度特性有關(guān),它搶占低優(yōu)先級(jí)保障任務(wù)轉(zhuǎn)而去執(zhí)行高優(yōu)先級(jí)任務(wù),導(dǎo)致低優(yōu)先級(jí)任務(wù)服務(wù)時(shí)間延長(zhǎng).
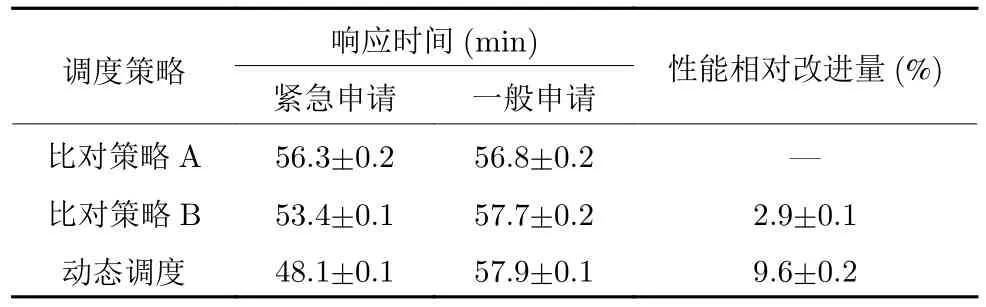
表2 動(dòng)態(tài)算法和比對(duì)策略的性能比較Table 2 Comparison of the algorithms and policies
為了進(jìn)一步檢驗(yàn)算法的魯棒性,在模擬一天24 小時(shí)的保障仿真中,對(duì)保障申請(qǐng)發(fā)生率λ和交戰(zhàn)區(qū)域位置進(jìn)行了數(shù)次改變.從圖5 中可以看出,響應(yīng)時(shí)間也相應(yīng)發(fā)生了較大波動(dòng),但是動(dòng)態(tài)調(diào)度算法性能還是明顯好于比對(duì)策略.
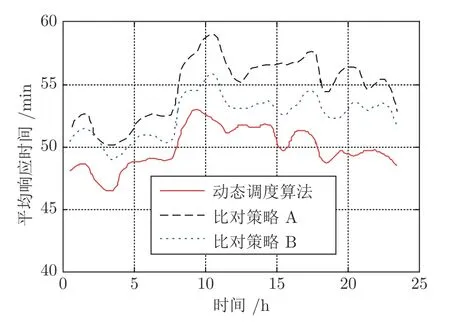
圖5 響應(yīng)時(shí)間變化情況Fig.5 Response delay with time
保障申請(qǐng)率的變化對(duì)調(diào)度系統(tǒng)也有較大影響,為此,設(shè)置保障申請(qǐng)發(fā)生率λ從1/25 減小到1/65,圖6 反映了動(dòng)態(tài)調(diào)度算法和比對(duì)策略B 相較于策略A 的性能相對(duì)改進(jìn)量變化情況.λ減小意味著保障申請(qǐng)發(fā)生率減小,動(dòng)態(tài)調(diào)度算法和策略B 的性能相對(duì)改進(jìn)量也逐漸減小,表示搶占調(diào)度和重部署帶來(lái)的性能優(yōu)勢(shì)也在減小,因此在低強(qiáng)度戰(zhàn)場(chǎng)上動(dòng)態(tài)調(diào)度算法性能優(yōu)勢(shì)不明顯,在保障申請(qǐng)率較高的高強(qiáng)度戰(zhàn)場(chǎng)上搶占調(diào)度和重部署能力才能取得較明顯的效果.
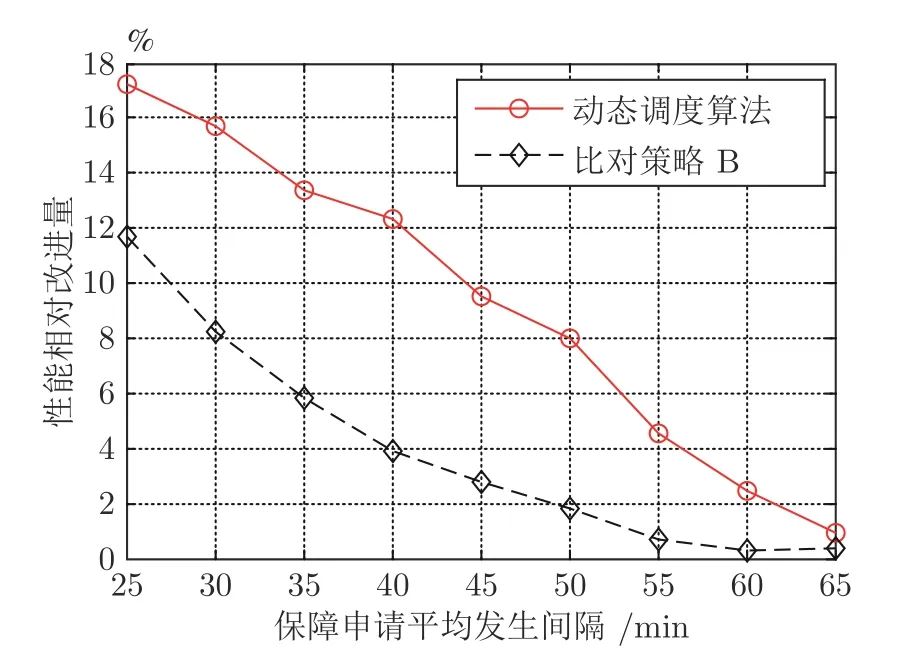
圖6 保障申請(qǐng)發(fā)生率的敏感性分析Fig.6 Sensitivity analysis of maintenance request occurrence rate
4 性能定性分析
最后通過(guò)4 個(gè)場(chǎng)景來(lái)定性分析重規(guī)劃能力的優(yōu)勢(shì).第1 個(gè)場(chǎng)景狀態(tài)中,假設(shè)某作戰(zhàn)部隊(duì)申請(qǐng)后裝保障,此時(shí)只有離它較遠(yuǎn)的保障分隊(duì)空閑,離它較近的保障分隊(duì)預(yù)測(cè)能在較短時(shí)間內(nèi)完成正在執(zhí)行的任務(wù).由于比對(duì)策略A和B 缺乏預(yù)測(cè)能力,會(huì)把較遠(yuǎn)的空閑保障分隊(duì)分派出去,而動(dòng)態(tài)調(diào)度算法需要最大化基于長(zhǎng)期回報(bào)的獎(jiǎng)勵(lì)函數(shù),所以先把該次申請(qǐng)放入隊(duì)列,等候較近的保障分隊(duì)空閑后再分派.
在第2 個(gè)場(chǎng)景的系統(tǒng)狀態(tài)中,某保障分隊(duì)剛被分派執(zhí)行某高烈度區(qū)域的一個(gè)低優(yōu)先級(jí)保障任務(wù),這時(shí)同樣區(qū)域發(fā)出了一個(gè)高優(yōu)先級(jí)保障申請(qǐng),此狀態(tài)下,除非指揮員發(fā)出新的分派指令,否則策略A將保持該保障分隊(duì)的任務(wù)不變.很明顯此時(shí)好的調(diào)度算法應(yīng)該主動(dòng)中斷保障分隊(duì)的當(dāng)前任務(wù),重新分派它執(zhí)行高優(yōu)先級(jí)的緊急任務(wù),從而取得更高的回報(bào)價(jià)值.
考慮第3 個(gè)場(chǎng)景的系統(tǒng)狀態(tài),某保障分隊(duì)剛被分派執(zhí)行某高烈度區(qū)域的一個(gè)低優(yōu)先級(jí)保障任務(wù),這時(shí)另一個(gè)較遠(yuǎn)距離的低烈度區(qū)域發(fā)出高優(yōu)先級(jí)保障申請(qǐng),此狀態(tài)下動(dòng)態(tài)調(diào)度算法需要根據(jù)神經(jīng)網(wǎng)絡(luò)模型的預(yù)測(cè)結(jié)果權(quán)衡,如果 “重規(guī)劃” 動(dòng)作產(chǎn)生的狀態(tài)價(jià)值較小,則不應(yīng)該實(shí)施搶占.
考慮第4 個(gè)場(chǎng)景的系統(tǒng)狀態(tài),某保障分隊(duì)快要完成當(dāng)前任務(wù)準(zhǔn)備返回基地,這時(shí)一個(gè)離它較遠(yuǎn)(超過(guò)剩余油料支持路程)的區(qū)域發(fā)出保障申請(qǐng).該狀態(tài)下,比對(duì)策略的調(diào)度方案是要求該保障分隊(duì)返回原基地補(bǔ)充后再執(zhí)行新任務(wù).而具有重部署能力的動(dòng)態(tài)調(diào)度算法會(huì)指示保障分隊(duì)前往距離申請(qǐng)點(diǎn)近的地方補(bǔ)充油料,從而更快地執(zhí)行新任務(wù).
綜上所述,與比對(duì)策略不同,動(dòng)態(tài)調(diào)度算法的決策基礎(chǔ)是通過(guò)基函數(shù)組合的神經(jīng)網(wǎng)絡(luò)模型,它能夠捕捉當(dāng)前事件和可預(yù)測(cè)的未來(lái)事件帶來(lái)的影響,因此能夠產(chǎn)生更優(yōu)的調(diào)度結(jié)果.
5 結(jié)束語(yǔ)
本文主要研究了戰(zhàn)時(shí)后裝保障中重規(guī)劃(搶占調(diào)度、重分配及重部署)問(wèn)題,以便生成高質(zhì)量的保障資源調(diào)度策略,提高后裝保障智能化水平.針對(duì)重規(guī)劃問(wèn)題設(shè)計(jì)了一個(gè)無(wú)限時(shí)域馬爾科夫決策過(guò)程模型,其目標(biāo)是最大化保障調(diào)度系統(tǒng)的長(zhǎng)期折扣獎(jiǎng)勵(lì).為了解決重規(guī)劃模型的維度災(zāi)問(wèn)題,利用神經(jīng)網(wǎng)絡(luò)對(duì)基函數(shù)進(jìn)行非線性組合,從而達(dá)到逼近值函數(shù)的目的,并提出了基于強(qiáng)化學(xué)習(xí)策略迭代的神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)算法.最后設(shè)計(jì)了一個(gè)高強(qiáng)度分布作戰(zhàn)仿真場(chǎng)景,檢驗(yàn)了不同問(wèn)題特征及算法參數(shù)對(duì)調(diào)度性能的影響,驗(yàn)證了動(dòng)態(tài)調(diào)度算法的適用性.
本文中MDP 模型的描述是對(duì)保障調(diào)度適用的對(duì)象或場(chǎng)景的限制條件,對(duì)于超出該模型描述的保障調(diào)度,也具有一定的借鑒意義.另外,如果調(diào)度場(chǎng)景與對(duì)象變化較大,如作戰(zhàn)規(guī)模過(guò)大,保障基地?cái)?shù)量位置動(dòng)態(tài)變化時(shí),由于機(jī)器學(xué)習(xí)能力限制,逼近函數(shù)(本文采用基函數(shù)+神經(jīng)網(wǎng)絡(luò))也需要相應(yīng)調(diào)整.
下一步工作需要改進(jìn)當(dāng)前研究的一些不足之處,例如在高強(qiáng)度作戰(zhàn)中,可能某次保障申請(qǐng)需要的資源較大,超過(guò)了一個(gè)保障分隊(duì)或基地的能力,需要調(diào)度多個(gè)分隊(duì)協(xié)同保障.協(xié)同保障方面已經(jīng)有一些相關(guān)研究成果,正在考慮如何與之結(jié)合.另一個(gè)重要研究方向是進(jìn)一步擴(kuò)展保障分隊(duì)的類(lèi)型及相應(yīng)特性,這樣可以比較不同保障分隊(duì)的調(diào)度性能.另外,錯(cuò)誤定義的保障需求優(yōu)先級(jí)會(huì)影響保障分隊(duì)的調(diào)度,這也是下一步需要解決的難點(diǎn).
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
教學(xué)考試(高考化學(xué))(2021年2期)2021-05-30 06:15:52
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
中學(xué)生數(shù)理化·高一版(2020年3期)2020-04-21 08:03:20
中學(xué)生數(shù)理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學(xué)生作文(低年級(jí)適用)(2019年9期)2019-10-08 08:37:10
數(shù)學(xué)大世界(2018年1期)2018-04-12 05:39:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03